一、每日一题

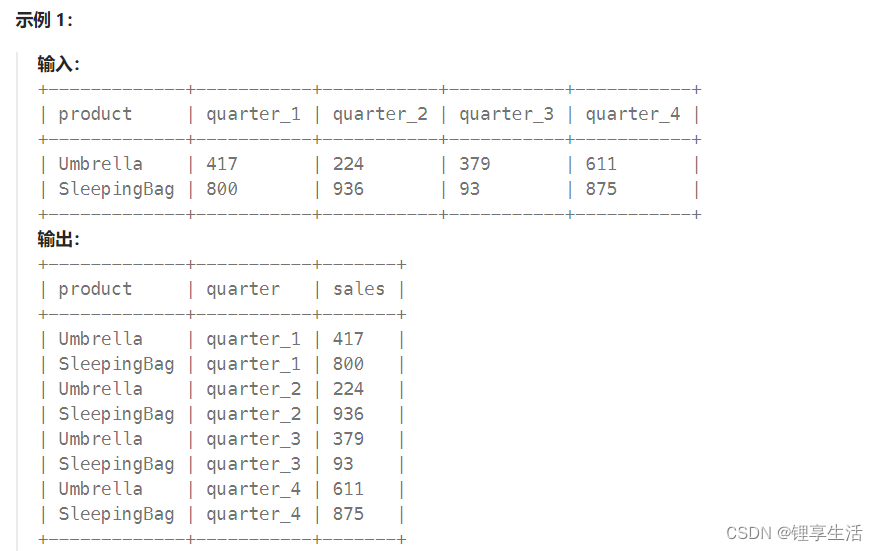
解答:
import pandas as pd
def meltTable(report: pd.DataFrame) -> pd.DataFrame:
reshaped_report = report.melt(id_vars='product', var_name='quarter', value_name='sales')
return reshaped_report题源:Leetcode
二、总结
melt()函数是Pandas库中的一个非常实用的功能,用于将宽格式(wide format)的数据转换为长格式(long format),也被称为“unpivot”操作。这对于数据分析中需要按行组织特定变量的数据尤其有用,比如在时间序列分析、数据可视化或准备数据进行统计建模时。
基本语法
pd.melt(frame, id_vars=None, value_vars=None, var_name=None,
value_name='value', col_level=None, ignore_index=True)参数说明:
-
frame:这是你想要重塑的DataFrame。
-
id_vars:这是一个列表,包含你希望保持不变(作为标识列)的列名。这些列不会被重铸过程影响,每一行都会对应这些列的一个唯一值。
-
value_vars:这也是一个列表,包含了你想要融化的列名,即你想把它们从列名变成实际数据值的列。默认为DataFrame中除id_vars外的所有列。如果你只想融化特定的几列,就指定它们。
-
var_name:新DataFrame中用于存储原列名(被融化的列)的列名,默认为'variable'。
-
value_name:新DataFrame中用于存储被融化的列的值的列名,默认为'value'。
-
col_level:如果DataFrame的列有MultiIndex,这个参数指定了哪一层应该被当作id_vars或value_vars处理。
-
ignore_index:布尔值,默认为True,表示重置新DataFrame的索引。如果设置为False,则保留原始DataFrame的索引。
实例:
例一:
df = pd.DataFrame({'A': {0: 'a', 1: 'b', 2: 'c'},
'B': {0: 1, 1: 3, 2: 5},
'C': {0: 2, 1: 4, 2: 6}})
>>> df
A B C
0 a 1 2
1 b 3 4
2 c 5 6
df.melt(id_vars=['A'], value_vars=['B'],
var_name='myVarname', value_name='myValname')
A myVarname myValname
0 a B 1
1 b B 3
2 c B 5例二:
import pandas as pd
data = {
'product': ['Widget A', 'Widget B'],
'Q1': [100, 150],
'Q2': [120, 160],
'Q3': [80, 170],
'Q4': [90, 180]
}
df = pd.DataFrame(data)
# 使用melt转换为长格式
long_df = pd.melt(df, id_vars=['product'], value_vars=['Q1', 'Q2', 'Q3', 'Q4'],
var_name='Quarter', value_name='Sales')
# 执行结果为:
product Quarter Sales
0 Widget A Q1 100
1 Widget B Q1 150
2 Widget A Q2 120
3 Widget B Q2 160
4 Widget A Q3 80
5 Widget B Q3 170
6 Widget A Q4 90
7 Widget B Q4 180官方文档
2024.5.15
![Python 机器学习 基础 之 监督学习 [线性模型] 算法 的简单说明](https://img-blog.csdnimg.cn/direct/824311c328f94832b5bfc93660d0c294.png)


![数字集成电路物理设计[陈春章]——知识总结与精炼01](https://img-blog.csdnimg.cn/direct/c15ed59eb22645bc847acafc859a67af.png)