论文信息
论文名:Projecting Your View Attentively: Monocular Road Scene Layout Estimation via Cross-view Transformation
中文:通过交叉视图变换(crossview transform module)估计单目道路场景布局
数据集:KITTI
paper:github
帧率:35 FPS
输入:单张摄像头前向图
输出:road layout estimation and vehicle occupancy estimation
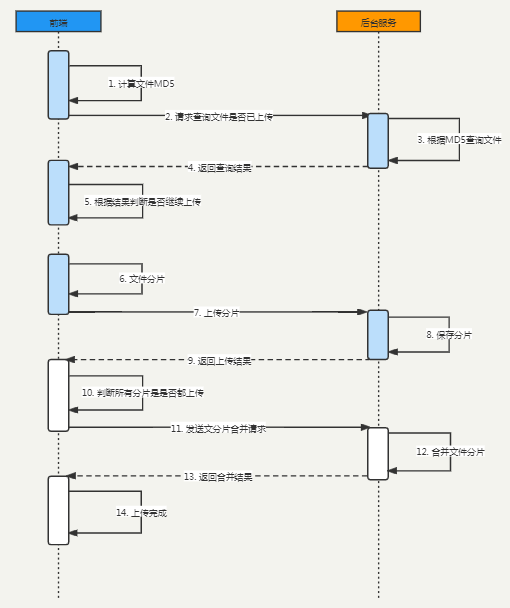
PYVA 是第一个明确提到 cross-attention decoder可用于视图转换以将图像特征提升到 BEV 空间的方法之一。PYVA 首先使用 MLP 将透视空间中的图像特征 X 提升到BEV 空间中的 X’。第二个 MLP 将 X’ 映射回图像空间 X’‘,并使用 X 和 X’ 之间的循环一致性损失来确保此映射过程保留尽可能多的相关信息。PYVA使用的 Transformer 是一个cross-attention模块,query Q要映射到BEV空间中的BEV特征X’。
文章目录
- 论文信息
- Abstract
- Introduce
- 2. Related Work
- 基于BEV的道路布局估计与车辆检测
- View transformation and synthesis
- Transformer for vision tasks.
- 3. Our Proposed Method
- 3.1. Network Overview
- 3.2. Cross-view Transformation Module
- Cycled View Projection (CVP).
- Cross-View Transformer (CVT).
- 3.3. Context-aware Discriminator
- 3.4. Loss Function
- 4. Experimental Results
- 4.1. Implementation Details
- 4.2. Datasets and Comparison Methods
- 4.3. Performance Evaluation
- 4.4. Ablation Study
- 4.5. Panorama HD Map Generation
- 5. Conclusion
Abstract
我们提出了一种新颖的框架,该框架可以在仅给定前视单眼图像的情况下,在鸟瞰视图中重建由道路布局和车辆占用率形成的本地地图。特别地,我们提出了一个跨视图转换模块,该模块考虑了视图之间循环一致性的约束,并充分利用它们的相关性来加强视图转换和场景理解。考虑到车辆与道路之间的关系,我们还设计了上下文感知判别器以进一步完善结果。
Introduce
我们的工作旨在解决这个现实但具有挑战性的问题,即在给定单个单眼前视图像的情况下,以俯视图或鸟瞰图 (BEV) 估算道路布局和车辆占用率 (见图1)。
但是,由于大的视距和严重的视场变形,即使对于人类观察者来说,从前视图像理解和估计顶视图场景布局也是一个极其困难的问题。特别是,同一场景在鸟瞰和正面视图的图像中具有明显不同的外观。因此,将正面视图的道路场景解析和投影到俯视图需要充分利用正面视图图像的信息并先天推理看不见的区域的能力。

传统方法 (例如 [23,45]) 专注于通过估计相机参数和执行图像坐标变换来研究透视变换,但由于几何翘曲而导致的所得BEV特征图中的间隙导致较差的结果。
最近基于深度学习的方法 [35,56] 主要依赖于深度卷积神经网络的幻觉能力 来推断视图之间看不见的区域。
通常,这些方法不是对视图之间的相关性进行建模,而是直接利用cnn以监督的方式学习视图投影模型。这些模型需要深层网络结构来通过多层传播和转换正面视图的特征,以在空间上与顶视图布局对齐。但是,由于卷积层的局部受限的感受野,因此难以拟合视图投影模型并识别小规模车辆。此外,道路布局提供了重要的上下文信息,以推断车辆 (例如,停在道路旁边的车辆) 的位置和方向。然而,现有的道路场景解析方法通常会忽略车辆与道路之间的空间关系。
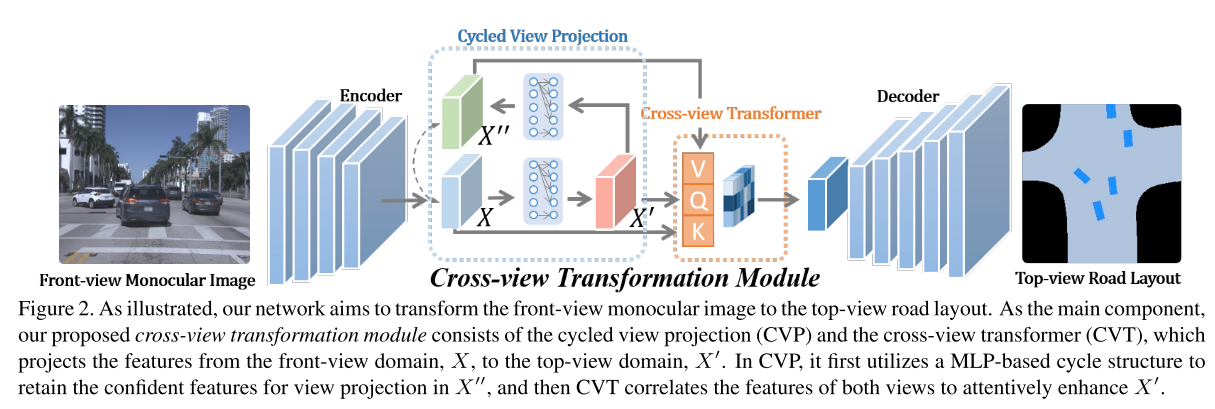
为了解决上述问题,我们推导了一种新颖的基于GAN的框架,以在给定单个单眼前视图像的情况下,从顶视图估算道路布局和车辆占用率。为了处理视图之间的巨大差异,我们在Transform 网络中提出了一个cross-view transform 模块,该模块由两个子模块组成: Cycled View Projection (CVP) 模块桥接各自域中的视图特征,Cross-View Transformer (CVT) 关联视图,具体地,如图1所示,
- CVP利用多层感知器 (MLP) 来投影视图,该视图超过了通过卷积层的标准信息流,并且涉及循环一致性的约束以保留与视图投影相关的特征。换句话说,将正面视图转换为顶视图需要对视觉特征进行全局空间转换。
- 标准CNN层仅允许对特征图进行局部计算,因此需要几个层才能获得足够大的接收场。另一方面,全连接层可以更好地促进跨视图转换。然后,CVT明确地关联了从CVP获得的投影前后视图的特征,这可以显着增强视图投影后的特征。特别是,我们在CVT中涉及一种特征选择方案,该方案利用两个视图的关联来提取最相关的信息。此外,为了利用车辆与道路之间的空间关系,我们提出了一种上下文感知的鉴别器,该鉴别器不仅评估了估计的车辆遮罩,还评估了它们的相关性。
在实验结果中,我们表明我们的交叉视图转换模块和上下文感知鉴别器可以提高道路布局和车辆占用率估计的性能。对于这两项任务,我们将模型与公共基准上的最新方法进行比较,并证明我们的模型优于所有其他方法。
我们还表明,我们的框架能够使用单个GPU以35 FPS处理1024 × 1024图像,并且适用于全景高清地图的实时重建。我们论文的贡献总结为:
- 我们提出了一种新颖的框架,该框架仅使用单个单目前视图像来重建由顶视图道路场景布局和车辆占用形成的本地地图。特别是,我们提出了一个跨视图转换模块,该模块利用视图之间的周期一致性及其相关性来加强视图转换。
- 我们还提出了一种上下文感知的鉴别器,该鉴别器在估计车辆占用率的任务中考虑了车辆与道路之间的空间关系。
- 在公共基准上,证明了我们的模型在道路布局和车辆占用率估算方面达到了最先进的性能。
2. Related Work
在本节中,我们调查了有关道路布局估计,车辆检测和俯视图表示的街景综合的相关文献。我们还介绍了Transform 在视觉任务方面的最新进展。
基于BEV的道路布局估计与车辆检测
大多数道路场景解析作品都专注于语义分割 [8,9,44,50,51],而有一些尝试可以得出道路布局的俯视图表示 [11,13,25,28,38,39,48,52]。在这些方法中,Schulter等人。[38] 建议通过深度估计和语义分割从单个彩色图像中估计顶视图上的遮挡合理的道路布局。[25] 提出了一种变分自动编码器 (VAE) 模型,用于从给定的图像中预测道路布局,但无需尝试从观察中推断出看不见的布局。Pan等人 [32] 通过转换和融合来自多个摄像机的观察结果,提出了跨视图语义分割。[34,36] 直接将特征从图像转换到3D空间,最后转换到鸟瞰图 (BEV) 网格。另一方面,已经开发了许多基于单眼图像的3D车辆检测技术 (例如,[5,21,29])。有几种方法通过将单目图像映射到顶视图来解决此问题。例如,[37] 提出将单眼图像映射到顶视图表示,并将3D对象检测视为2D分割的任务。BirdGAN [41] 还利用对抗性学习将图像映射到鸟瞰图。作为另一项相关工作,[47] 不关注显式场景布局估计,而是更多地关注运动规划方面。
与我们的工作最相关的是,[27] 提出了一个统一的模型来 从单个图像中处理道路布局 (静态场景) 和交通参与者 (动态场景) 估计的任务。
View transformation and synthesis
已经提出了传统方法 (例如 [17,23,45]) 来处理交通场景中的视角转换。随着基于深度学习的方法的进展,[56] 提出了基于驾驶员视图生成鸟瞰图的开创性工作。他们将跨视图合成视为图像翻译任务,并采用基于GAN的框架来完成它。由于难以收集真实数据的注释,因此它们的模型是从视频游戏的数据中训练的。[1] 仅专注于将相机图像变形为BEV图像,而无需执行任何下游任务,例如对象检测。最近对视图合成的尝试 [35,43] 旨在将航空图像转换为街景图像,反之亦然。与这些作品相比,我们的目的大不相同,不仅需要从正面到俯视图的隐式视图投影,还需要在统一的框架下估算道路布局和车辆占用率。
Transformer for vision tasks.
随着transformer [46] 最近的成功,它对序列中的元素进行显式建模成对交互的能力已在许多视觉任务中得到利用 [3,10,49,53,55]。与这些基于transformer 的模型不同,我们提出的cross-view trans-
former 试图建立视图特征之间的相关性。此外,我们将特征选择方案与非局部交叉视图相关方案结合在一起,从而显着增强了特征的代表性。
3. Our Proposed Method
3.1. Network Overview
我们的工作目标是在给出单眼正面视图图像的情况下,以语义遮罩的形式估算鸟瞰图上的道路场景布局和车辆占用率。
我们的网络架构基于基于GAN的框架。具体地,如图2所示,生成器是编码器-解码器架构,其中输入的正面视图图像I首先通过采用ResNet [14] 作为主干网络的编码器来提取视觉特征,然后,我们提出了跨视图转换模块,该模块增强了视图投影的功能,最后由解码器产生顶视图蒙版m。
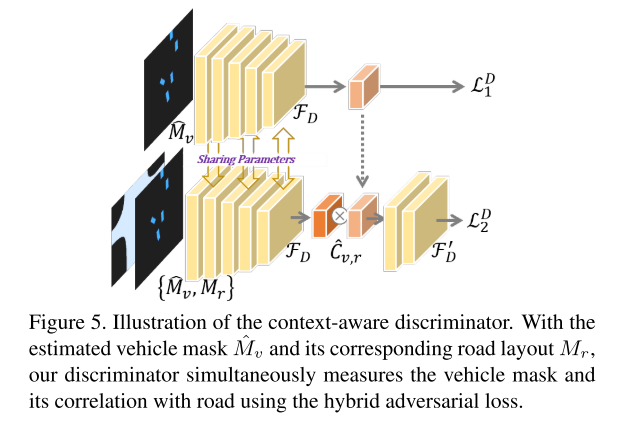
另一方面,我们提出了一个上下文感知鉴别器 (见图5),它通过考虑道路上下文来区分车辆的面罩。在以下小节中,我们将详细阐述我们的交叉视图转换模块和上下文感知鉴别器的细节。
3.2. Cross-view Transformation Module
由于正面和俯视图之间的差距很大,在视图投影过程中存在大量的图像内容缺失,因此传统的视图投影技术导致了结果的缺陷。为此,已经利用基于CNN的方法的幻觉能力来解决该问题,但是两个视图的补丁级相关性对于在深度网络中建模并非易事。
为了在利用深度网络能力的同时加强视图相关性,我们在基于GANbased框架的生成器中引入了一个交叉视图转换模块,该模块增强了提取的视觉特征,用于将正面视图投影到俯视图。我们提出的交叉视图变换模块的结构如图2所示,该模块由两部分组成: cycled view projection and cross-view transformer。
Cycled View Projection (CVP).
由于正面视图的特征由于其较大的间隙而与俯视图的特征在空间上不一致,因此按照 [31] 的实践,我们部署了由两个完全连接的层组成的MLP结构,以将正面视图的特征投影到俯视图,它可以超过堆叠卷积层的标准信息流。如图2所示,X和X ′ 分别表示视图投影之前和之后的特征图。
因此,整体视图投影可以
be achieved by:
X
′
=
F
M
L
P
(
X
)
X^{′} = F_{MLP}(X)
X′=FMLP(X),
where X refers to the features extracted from the ResNet backbone.
然而,如此简单的视图投影结构不能保证正面视图的信息被有效地传递。在这里,我们引入了一种循环自我监督方案 cycled self-supervision 来巩固视图投影,该方案将顶视图特征投影回正面视图的领域。
如图2所示,通过经由相同的MLP结构将 X ′ X^{'} X′循环回到正面视图域来计算 X ′ ′ X^{'′} X′′,
即, X ′ ′ = F ′ M L P ( X ′ ) X^{'′}= F′_{MLP}(X′) X′′=F′MLP(X′) 。
为了保证
X
′
′
X^{'′}
X′′和
X
′
X^{′}
X′之间的域一致性,我们加入了循环loss,即Lcycle,如下所示。
L
c
y
c
l
e
=
∣
∣
X
−
X
′′
∣
∣
.
Lcycle = ||X −X^{′′}||.
Lcycle=∣∣X−X′′∣∣.
周期结构的好处是双重的。
- 首先,类似于基于周期一致性的方法 [7,54],周期损失可以天生地提高特征的代表性,因为将顶视图特征循环回正面视图域将加强两个视图之间的联系。
- 其次,当不能进一步缩小X和X ′ ′ 的差异时,X ′ ′ 实际上保留了与视图投影最相关的信息,因为X ′ 是从X ′ 相互投影的。因此,X和X ′ 指的是视图投影之前和之后的特征。X ′ ′ 包含正面视图最相关的特征,用于视图投影。在图3中,我们通过可视化前视图和顶视图的特征来显示两个示例。具体地,我们使它们可视化的方式是选择特征图的典型通道 (即,图3的两个示例的第7和第92),并将它们与输入图像对齐。如所观察到的,X和X ′ ′ 相似,但由于域差异而与X ′ 大不相同。我们还可以观察到,通过骑自行车,x ′ ′ 更加集中在道路和车辆上。X,X ′ 和X ′ ′ 将被馈入交叉视图变压器。
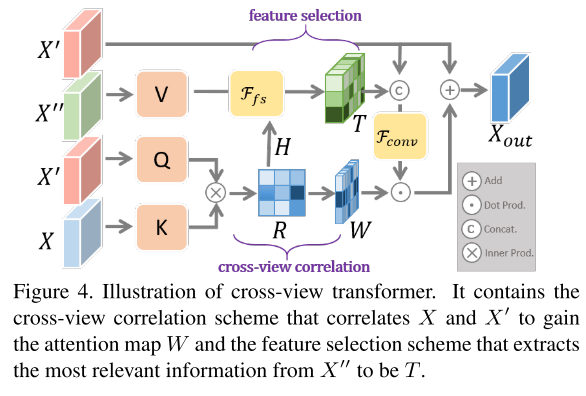
Cross-View Transformer (CVT).
CVT的主要目的是将视图投影前的特征 (即X) 和视图投影后的特征 (即X ′) 相关联,以加强后者。因为x ′ ′ 包含子 正面视图的基础信息用于视图投影,还可以进一步增强特征。
如图4所示,CVT可以大致分为两种方案:
- 明确地关联视图的特征以实现注意图W以增强 X ′ X' X′ 的交叉视图相关方案,
- 以及从 X ′ ′ X'' X′′提取最相关信息的特征选择方案。
特别地,X、X ′ 和X ′ ′ 用作CVT的键K (K ≡ X) 、查询Q (Q ≡ X ′) 和值V (V ≡ X ′)。在我们的模型中,X,X ′ 和X ′ ′ 的尺寸设置为相同。X ′ 和X都被展平为补丁,每个补丁都表示为X ′ i ∈ X ′(i ∈ [1,.,hw]) 和xj ∈ X(j ∈ [1,.,hw]),其中hw指的是X的宽度乘以其高度。
因此,可以估计X和X ′ 的任何成对补丁之间的相关性矩阵R,即,对于X ′ 中的每个补丁X ′ i和X中的xj,它们的相关性rij (∈ rij ∈ R) 由归一化内积测量:
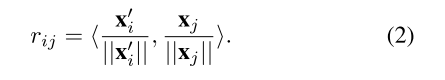
利用相关性矩阵R,我们创建两个向量W (W = {wi},∈ i ∈ [1,.,hw]) 和H (H = {hi},∈ i ∈ [1,.,hw]) 分别基于R的每一行的最大值和相应的索引:
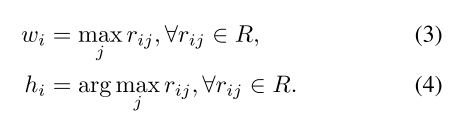
W的每个元素都暗示了x ′ 的每个补丁与x的所有补丁之间的相关程度,可以用作关注图。H的每个元素表示X中关于X ′ 的每个补丁的最相关补丁的索引。
回想一下,X和X ′ ′ 都是正面视图的特征,只是X包含其完整信息,而X ′ ′ 保留了用于视图投影的相关信息。假设X与X ′ 之间的相关性类似于X ′ ′ 与X ′ 之间的相关性,则利用X与X ′ 的相关性 (即R) 从X ′ 中提取最重要的信息是合理的。
为此,我们介绍了一种特征选择方案Ffs。使用H和x′′,Ffs可以通过从x ′ 中检索最相关的特征来产生新的特征图T (T = {ti},∈ i ∈ [1,.,hw]):
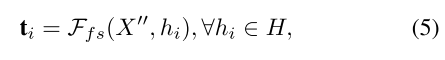
where Ffs retrieves the feature vector ti from at the hi-th position of X′′.
因此,T为x ′ 的每个补丁存储x ′ 的最相关信息。可以将其重塑为与x ′ 相同的尺寸,并与x ′ 连接。然后,连接的特征将由注意图W加权,并最终通过残差结构与X′ 聚合。
the process can be formally expressed as below:
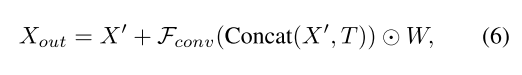
where ⊙ denotes the element-wise multiplication and Fconv refers to a convolutional layer with 3 × 3 kernel size. Xout is the final output of CVT and will then be passed to the decoder network to produce the segmentation mask of the top view.
3.3. Context-aware Discriminator
在基于GAN的框架的鉴别器中,为了进一步完善车辆的合成掩模,可以利用车辆与其上下文 (即道路) 之间的空间关系。为此,我们提出了一种上下文软件鉴别器,该鉴别器不仅试图区分输出的车辆遮罩和地面真相遮罩,而且还明确利用车辆与道路之间的相关性来增强辨别能力。
特别是,在同一场景中,通过估计的车辆的掩码
M
v
^
\hat{Mv}
Mv^ 和 地面真相掩码 Mr,我们部署了一个共享的CNN FD来分别提取
M
v
^
\hat{Mv}
Mv^ 的特征以及的
M
v
^
\hat{Mv}
Mv^和Mr的串联,然后计算其特征的内积以评估其相关性,即
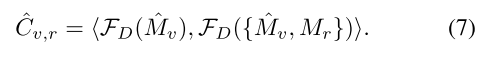
同样,车辆 M v Mv Mv的地面真相掩码以及 M v Mv Mv和Mr的串联通过具有共享参数的同一网络进行馈送,然后以相同的方式评估地面真相车辆与道路的相关性 C v . r Cv.r Cv.r。
为此, M v ^ \hat{Mv} Mv^ 和 M v Mv Mv被馈送到分类器FD中用于前景对象识别,而相关性 C v . r ^ \hat{Cv.r} Cv.r^和 C v . r Cv.r Cv.r被发送到另一个分类器FD’ 中用于识别。实际上,对于这两个分类器,我们都采用多个卷积层,并在每层之后插入归一化以及hinge损耗以稳定训练
因此,判别器的损失为:
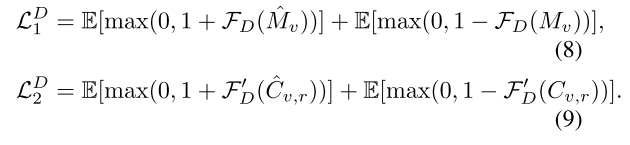
因此,我们的上下文感知鉴别器使我们能够区分估计的和地面真相的车辆,同时区分车辆与道路之间的各自相关性,这强调了车辆与道路之间的空间关系。
3.4. Loss Function
Overall, the loss function of our framework is defined as:
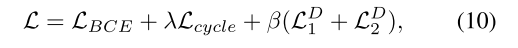
其中LBCE是二进制交叉熵损失,它是生成网络的主要目标,以缩小合成语义掩码和地面真相掩码之间的差距。Λ 和 β 分别是循环损失和对抗损失的平衡权重。实际上,λ 和 β 被设置为0.001和1。
4. Experimental Results
为了评估我们提出的模型,我们针对各种具有挑战性的场景进行了多次实验,并针对公共基准上的最新方法进行了实验。我们还进行了广泛的消融实验,以深入研究我们的网络结构
4.1. Implementation Details
We implement our framework using Pytorch on a workstation with a single NVIDIA 1080Ti GPU card. In particular, we adopt ResNet-18 [14] without bottleneck layers as our backbone. Each input ofCVT utilizes one convolutional layer with kernel size 1 × 1. All the input images are normalized to 1024×1024 and the output size is 256×256.
网络参数是随机初始化的,我们采用Adam优化器 [20],并使用6的小批量大小。初始学习率被设置为1 × 10-4,并且在25个时期之后衰减0.1。实际上,我们的模型能够在我们的单GPU平台上实时运行 (35 FPS)。
4.2. Datasets and Comparison Methods
我们在两个数据集上评估我们的方法,即KITTI [12] 和Argoverse [4]。
由于KITTI没有为道路布局或可以在我们的任务中使用的车辆提供足够的注释,因此我们通常遵循 [27] 的实践,其中将结果分类为以下数据集。
- 为了与最先进的3D车辆检测方法进行比较,我们评估了Chen等人 [5] 的KITTI 3D对象检测 (KITTI 3D对象) 拆分的性能,即3712训练图像和3769验证图像。
- KITTI测距数据集用于评估道路布局,其注释来自语义KITTI数据集 [2]。
- 除了前两个数据集外,我们还评估了 [38] 中使用的KITTI Raw split的性能,即10156训练图像和5074验证图像。由于其地面真相是通过注册不够密集的激光雷达扫描的深度和语义分割来产生的,因此我们应用图像扩张和侵蚀来产生更好的地面真相注释。
此外,我们还比较了Argoverse上的方法,这些方法提供了高分辨率语义占用网格和车辆检测的顶视图,用于评估道路和车辆的空间布局,6723训练图像和2418验证图像。
对于绩效评估,我们采用交集-过结合的均值 (mIOU) 和平均精度 (mAP) 作为评估指标。
Comparison Methods.
为了评估我们的任务,我们将我们的模型与一些最先进的方法进行了比较,包括单占用 [25],单占用 [27],Pan等人 [32],Mono3D [5] 和OFT [37]。在这些方法中,Mono3D [5] 和OFT [37] 专门用于在顶视图中检测车辆。至于定量结果,我们遵循 [27] 中报道的结果。对于MonoLayout [27],我们将其最新的在线报告结果进行比较,通常比原始论文中报告的结果要好。Pan等人 [32] 最初采用来自不同相机的多个视图来生成俯视图表示。我们将其模型调整为单视图输入,然后使用相同的训练协议对其进行重新训练。同样,单占用 [25] 也针对道路布局估算基准进行了重新训练,我们获得了与 [27] 中报告的结果相当或更好的结果。
4.3. Performance Evaluation
Road layout estimation
关于KITTI Raw和KITTI里程计的数据集。请注意,由于我们对KITTI Raw的地面真相注释进行了后处理,因此我们在相同的训练协议下对所有比较方法进行了重新训练。比较结果如表1所示。此外,我们还在Argoverse Road上对它们进行了比较,如表2所示。如所观察到的,在这三个基准中,我们的模型在mIOU和mAP上都显示出优于竞争对手的优势。示例如图6所示。请注意,基本原理可能包含噪声,因为它们是从激光雷达的测量值转换而来的。即使这样,我们的方法仍然可以产生令人满意的结果。
Vehicle occupancy estimation
与道路布局估计相比,估计车辆占用率是一项更具挑战性的任务,因为车辆的规模各不相同,并且场景中存在相互遮挡。为了进行评估,我们对KITTI 3D对象和Argoverse车辆的基准进行了比较实验,以对抗单占用 [25],Mono3D [5],OFT [37],MonoLayout [27] 和Pan等人 [31]。结果如表2和表3所示。在表3中,我们的模型证明了与比较方法相比的卓越性能。由于KITTI 3D对象包含几个具有挑战性的场景,大多数比较方法几乎无法获得30% 的mIOU,而我们的模型获得38.79%,这显示出比现有方法至少28.5% 的改进。对于Argoverse车辆的评估,我们的模型在很大程度上优于其他模型,即与mIOU和mAP中的比较方法相比,至少有48.8% 和25.4% 的提升。请注意,数据集Argoverse提供了车辆占用率和相应的道路布局。
我们的上下文感知鉴别器起着重要的作用。
在图7的前三行上,我们示出了关于KITTI 3D对象上的车辆占用估计的示例。对于多辆车停在路边的具有挑战性的案例,我们的模型仍然可以表现良好。在图7的最后四行中,我们显示了Argoverse上道路和车辆的联合估计的示例,并且我们强调了结果的优势。
4.4. Ablation Study
为了深入研究我们的网络结构,我们针对交叉视图转换模块和上下文感知鉴别器进行了一些消融实验。
Cross-view transformation module.
回想一下,我们的跨视图转换模块由CVP和CVT组成。具体而言,CVP可分为MLP和循环结构。CVT可以分解为交叉视图相关方案和特征选择方案。在下文中,我们将基于表4中的数据集KITTI 3D对象来研究这些模块的必要性。
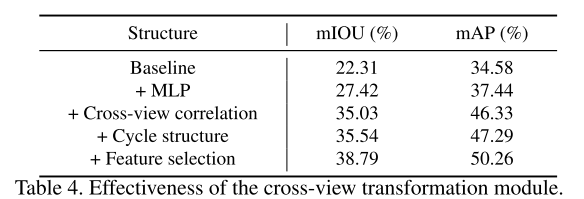
首先,基线是使用与我们的模型相同的编码器和解码器的香草编码器-解码器网络。然后,我们将MLP结构插入基线。如表4所示,它明显提高了视图投影的有效性。接下来,我们在网络中添加一个交叉视图相关方案,该方案测量X和X ′ 的相关性,并将其作为注意力图来增强X ′。如所观察到的,在crossview相关方案的参与下,性能得到了显着提高。之后,我们将循环结构以及循环损耗引入网络,其中x ′ ′ 将被馈送到交叉视图相关方案中。最后,我们插入了特征选择方案,进一步加强了
Cross-view transformer.
我们验证了CVT的K,Q,V的不同输入组合。我们在表5中演示了结果。
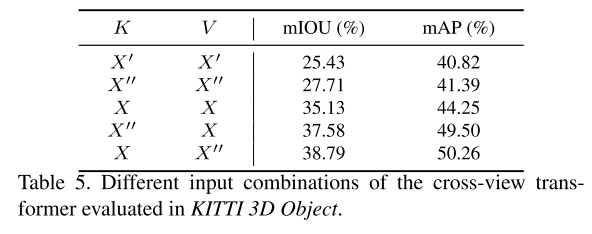
更具体地说,使用X作为键更好地生成精确的相关性嵌入,而应用X ′ ′ 作为值鼓励大多数相关特征的参与,从而导致最优结果。
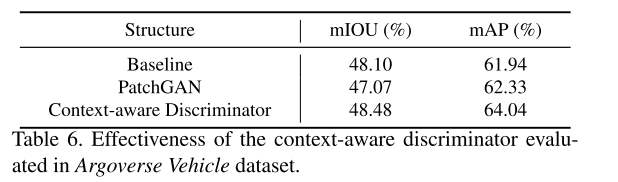
Context-aware discriminator.
我们在表6中显示了上下文感知鉴别器的有效性,并应用Argoverse车辆数据集进行分析,因为它是唯一提供车辆及其相应道路布局的数据集。我们将我们的模型与我们的生成器进行比较,而不应用任何鉴别器 (即表6中的基线) 和与标准鉴别器配对的生成器 (即PatchGAN [18])。如表所示,我们提出的鉴别器在mIOU和mAP方面均取得最佳结果。
4.5. Panorama HD Map Generation
我们展示了我们的模型在数据集Argoverse上的应用,用于在给定连续正面视图图像的情况下,通过拼接道路布局估计来生成全景高清地图。生成的高清地图如图8所示,它显示了我们应用于生成全景高清地图的方法的潜力。

5. Conclusion
在本文中,我们提出了一种新颖的框架,可以在给出前视单眼图像的情况下估算俯视图中的道路布局和车辆占用率。特别地,我们提出了一种由循环视图投影结构和交叉视图变换器组成的交叉视图变换模块,其中投影前后视图的特征被明确地关联,并且充分利用了与视图投影最相关的特征,以增强变换后的特征。此外,我们提出了一种上下文软件鉴别器,该鉴别器考虑了车辆和道路的空间关系。我们证明了我们提出的模型可以实现最先进的性能,并在单个GPU上以35 FPS的速度运行,这非常有效,适用于实时 HD地图重建。