Git 的原理与使用(上)中介绍了Git初识,Git的安装与初始化以及工作区、暂存区、版本库相关的概念与操作,本文接着上篇的内容,继续深入介绍Git在的分支管理与远程操作方面的应用。
目录
五、分支管理
1.理解分支
2.创建分支 branch
3.切换分支
4.合并分支
5.创建、切换、合并分支流程图
6.删除分支
7.合并冲突
补充:查看分支合并的情况
8.分支管理策略
Fast Forward 模式(ff模式)
非Fast Forward模式(no-ff模式)
9.分支策略
10.bug分支
疑问解决
11.删除临时分支
12.分支小结
六、远程操作
1.理解分布式版本控制系统
2.远程仓库
新建远程仓库
Issues
Pull Request
克隆远程仓库
HTTPS协议克隆
SSH协议克隆
向远程仓库推送 push
拉取远程仓库
3.配置Git
忽略特殊文件
给命令配置别名
**小结
**下篇内容
五、分支管理
1.理解分支
分支是Git的杀手级功能之一。
它就像是科幻电影里面的平行宇宙,当你正在电脑前努力学习C++的时候,也许另一个平行宇宙里的另一个你正在努力学习JAVA。这两个平行宇宙互不干扰,而在某个时间点,它俩发生了合并——于是,你既精通了C++,又精通了JAVA!
在版本回退章节里我们已经知道,Git会把每次提交串成一条时间线,这条时间线就可以理解为是一个分支。截止到目前我们的Git仓库里中只有一条时间线,这个分支叫主分支,即master分支(也叫main分支)。
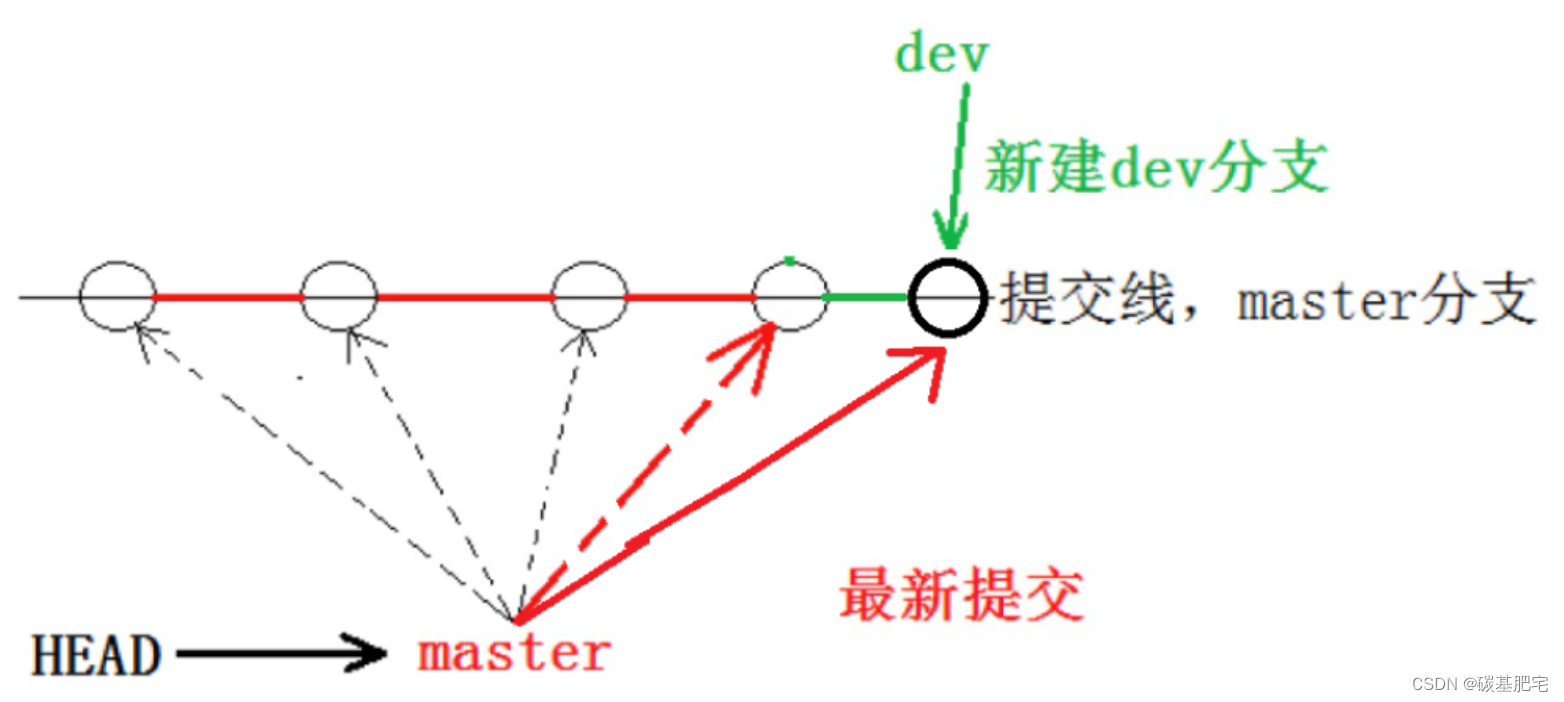
然后再来理解一下HEAD。HEAD严格来说指向的不是“提交(commit)”,而是当前所在的分支,而分支才是指向“提交(commit)”的。比如当前我们所在的分支是master,那么HEAD指向的就是master,master指向的才是“提交”。如下图所示:

每次执行commit操作,master分支都会向前移动一步以指向最新的“提交”。这样,随着你不断commit,master分支的线也会越来越长。而HEAD则一直指向指向当前分支不变,即现在我们所在的master分支。

可以通过
git cat-file -p <commit ID>命令来查看提交信息:
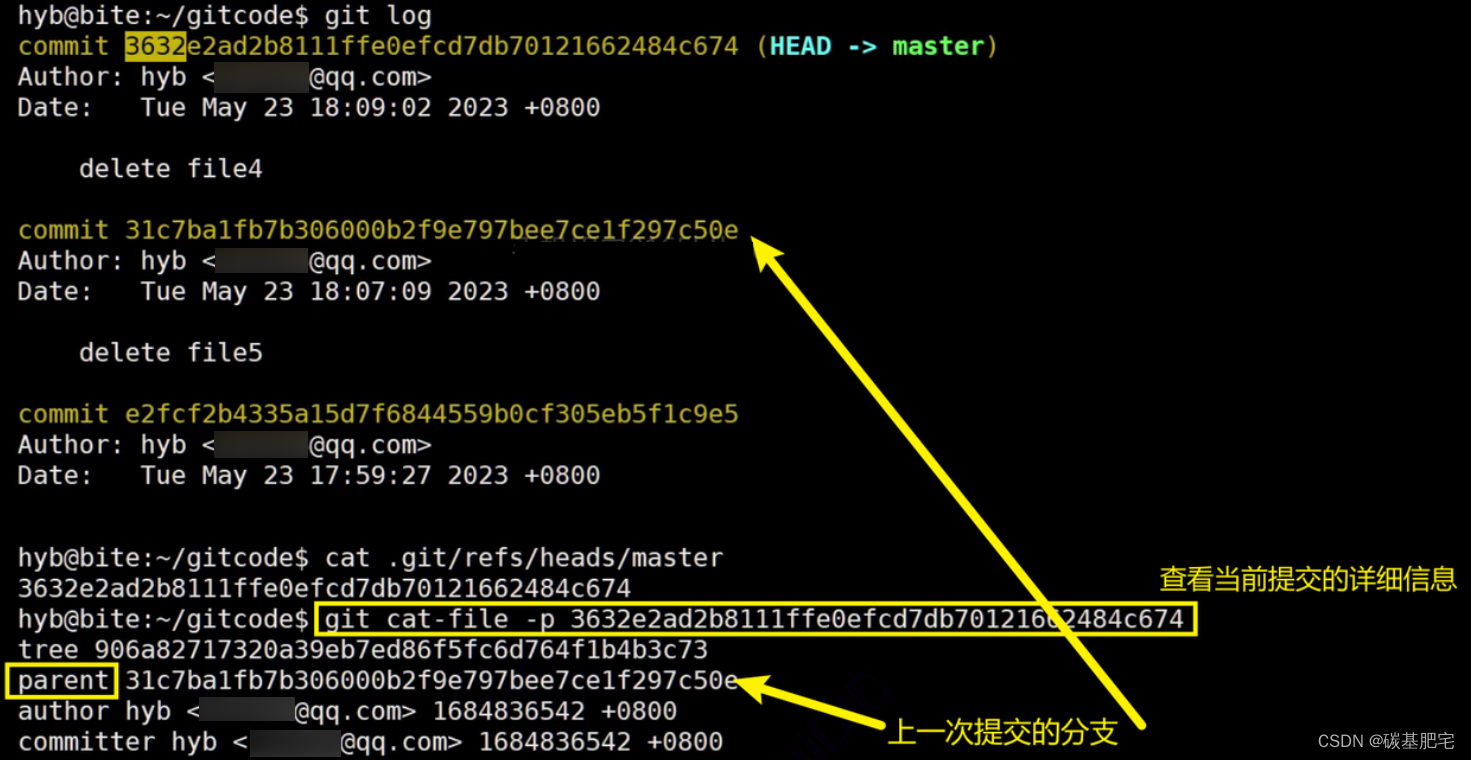
2.创建分支 branch
如何查看当前本地仓库中已有的所有分支?
在工作目录下执行
git branch命令,系统就能为我们打印出当前本地仓库中有哪些分支:
hyb@139-159-150-152:~/gitcode$ git branch #查看当前本地所有分支
* master # 显示结果这里查询到当前本地仓库中只有一个master主分支。
在我们创建本地仓库时,git会自动给我们创建出一个master主分支。master前面有一个 * ,*master 既表示master是当前的工作分支,也表示master分支正在被HEAD指针所指向。
关于HEAD:
HEAD不仅可以指向master主分支,也可以指向其它任意分支。
被HEAD指向的分支是当前正在工作的分支。由于之前我们的HEAD一直指向的是master分支,因此add操作、commit操作都是在master主分支上完成的。
为了演示多分支的情况,这里我们来创建第一个新的分支dev,对应的命令为:
git branch <分支名>hyb@139-159-150-152:~/gitcode$ git branch dev #新建分支dev
hyb@139-159-150-152:~/gitcode$ git branch
dev
* master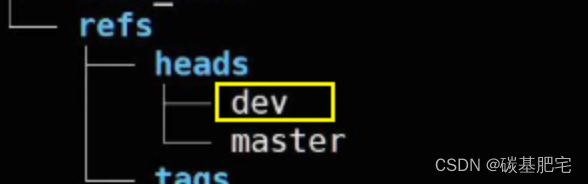
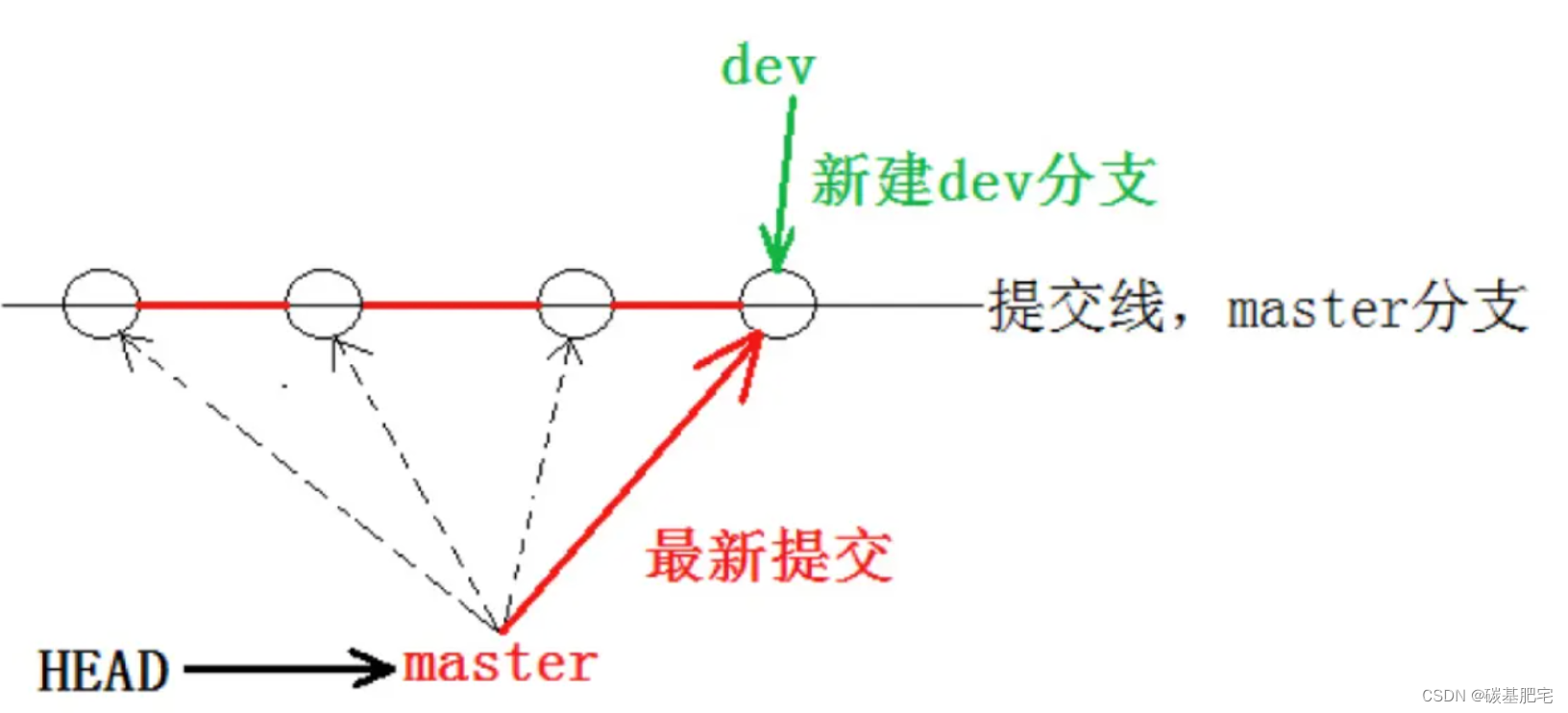
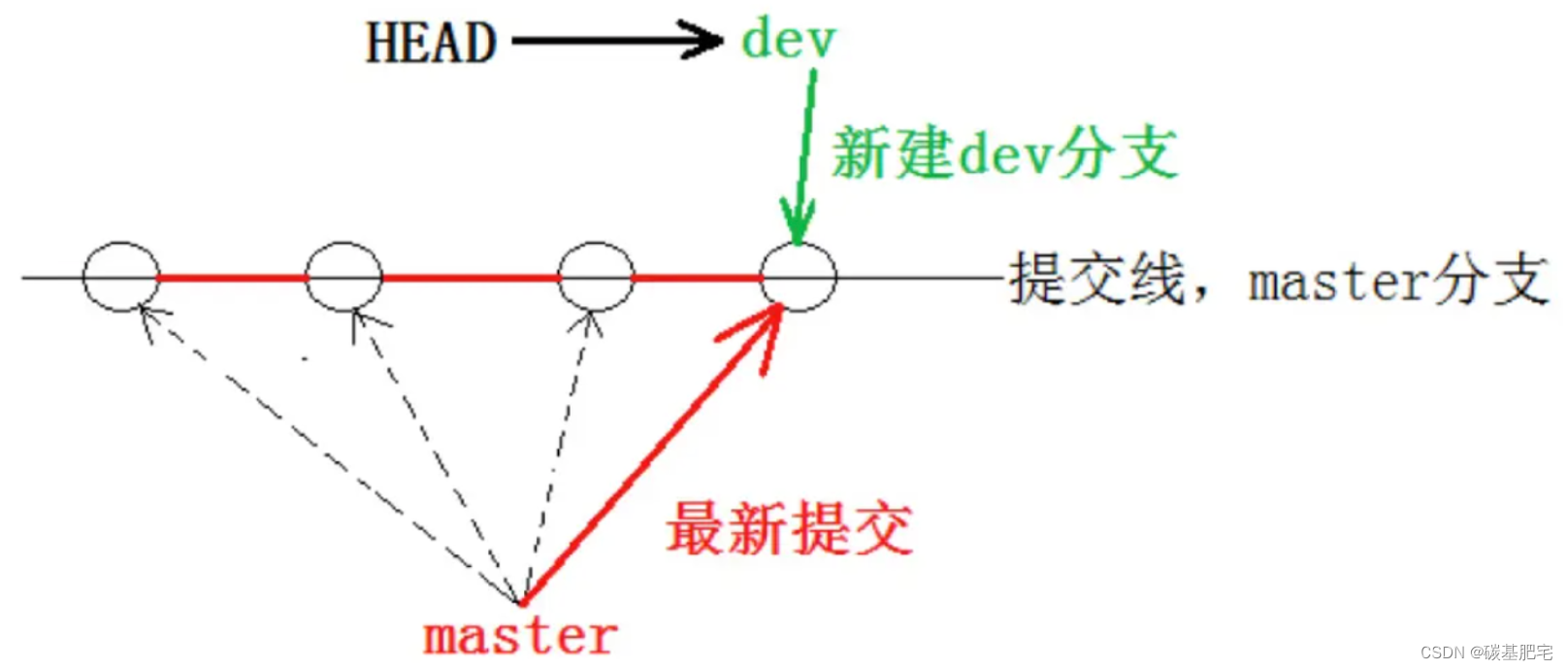
当我们创建新的分支后,Git 便新建了一个指针叫 dev。而 *HEAD 表示当前的 HEAD 仍然指向 master 分支,并没有发生变化。
也就是说,单纯的创建分支,是不会自动切换分支的。
# 打印一下HEAD指针的内容,可见HEAD指向的还是master
hyb@139-159-150-152:~/gitcode$ cat .git/HEAD
ref: refs/heads/master此时,cat一下dev和master的内容,会发现它们两个指向的是同一个修改(即commit Id),这是因为dev分支是站在当前的版本去创建的,所以dev分支初始情况下也指向了最新的提交:

一张图总结:
3.切换分支
我们要想在dev上进行操作,就必须把dev分支当作工作分支。那如何切换到dev分支下进行开发呢?使用
git checkout <分支名>命令即可完成切换。示例如下:
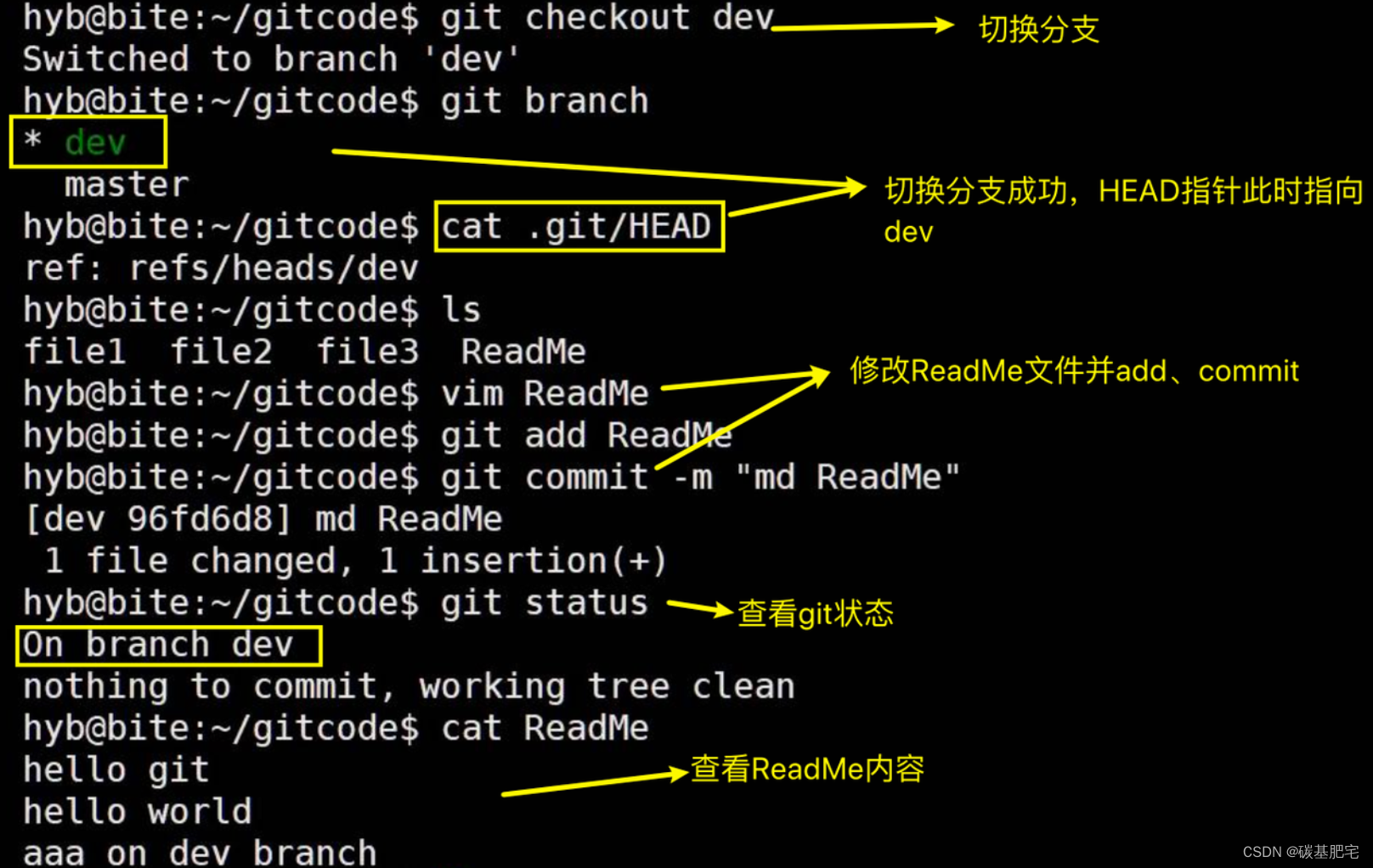
执行 git checkout dev切换分支后,HEAD就指向了dev,表示我们已经成功地切换到了dev上。随后,我们在dev分支下修改ReadMe文件,在末尾新增了一行内容 aaa on dev branch,并进行了一次提交操作。
现在,dev分支的工作完成,我们切换回master分支:
hyb@139-159-150-152:~/gitcode$ git checkout master
Switched to branch 'master'切换回master分支后再查看ReadMe文件内容,此时发现ReadMe文件中刚才新增的内容不见了:

而再切回dev查看,刚才新增的内容又有了:
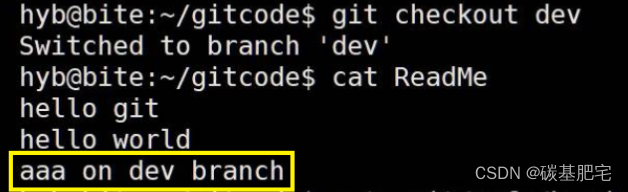
为什么会出现这个现象呢?
我们来看看dev分支和master分支的指向,发现dev和master两者此时指向的提交已经不一样了:
hyb@139-159-150-152:~/gitcode$cat.git/refs/heads/dev
bdaf528ffbb8e05aee34d37685408f0e315e31a4 # dev和刚创建时相比已经发生了改变
hyb@139-159-150-152:~/gitcode$cat.git/refs/heads/master
5476bdeb12510f7cd72ac4766db7988925ebd302进一步的,可以通过命令
git cat-file -p bdaf528ffbb8e05aee34d37685408f0e315e31a4来查看此时dev所指向的提交的详情。查询到的详情中,parent关键字标识了当前commit的上一个commit是哪一个。可以看到,dev当前指向的上一个指向,正是刚创建dev时dev的指向。因为我们是在dev分支上提交的,所以dev会指向最新的提交;而master分支此刻的指向并没有改变(正如两个平行宇宙之间彼此独立的)。
master的视角下,当然就看不到在dev下的提交了,因此在master和dev两个分支下的ReadMe文件内容会有差别。
4.合并分支
为了在master主分支上能看到新的提交,就需要将dev分支合并到master分支。
使用
git merge dev命令,示例如下:
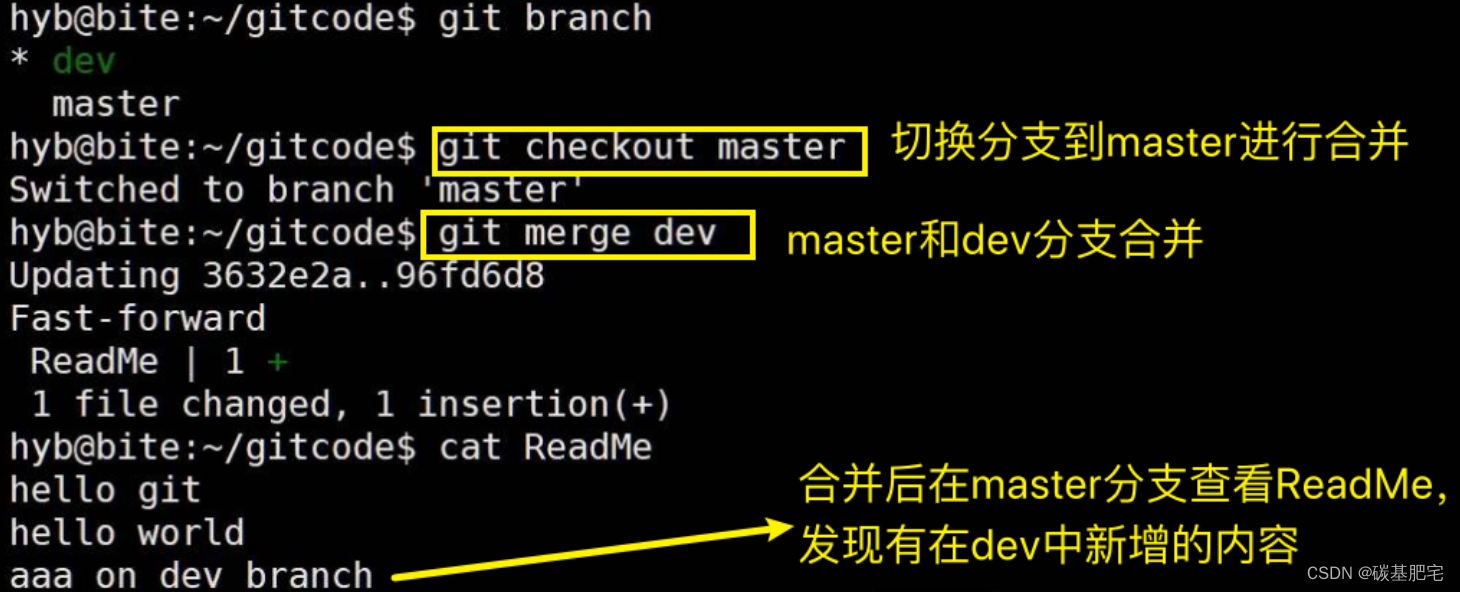
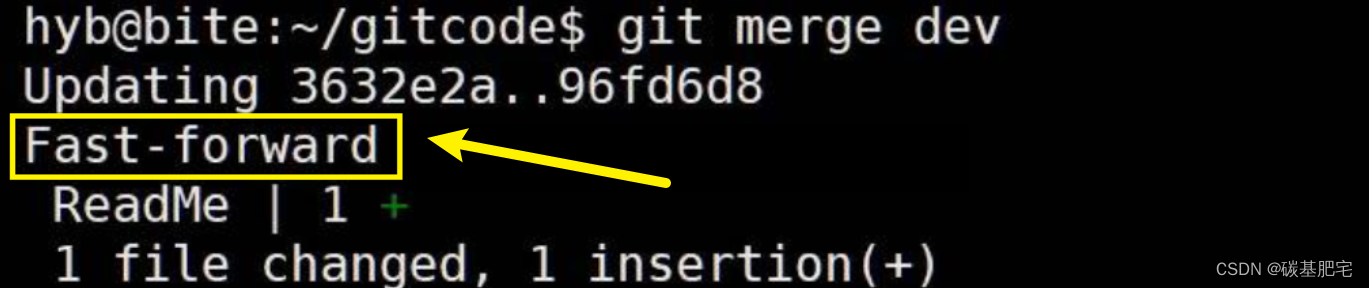
git merge命令用于合并指定分支到当前分支。合并后,master分支上就能看到dev分支提交的内容了。此时的状态如图如下所示:
仍然可以用 cat .git/refs/heads/master命令和 cat .git/refs/heads/dev命令分别查看master和dev的指向,此时发现二者指向再次相同,dev中存储的commitID也被同步给了master。
By the way,细心的朋友可能注意到,刚才
merge操作后,结果其实有些特殊:
这里的 Fast-forward 代表“快进模式”,它是Git分支合并的一种方式。快进模式意味着合并的方式是直接把master指向dev的当前提交,所以合并速度非常快。当然,也不是每次合并都是Fast-forward,我们后面会讲其他方式的合并。
5.创建、切换、合并分支流程图
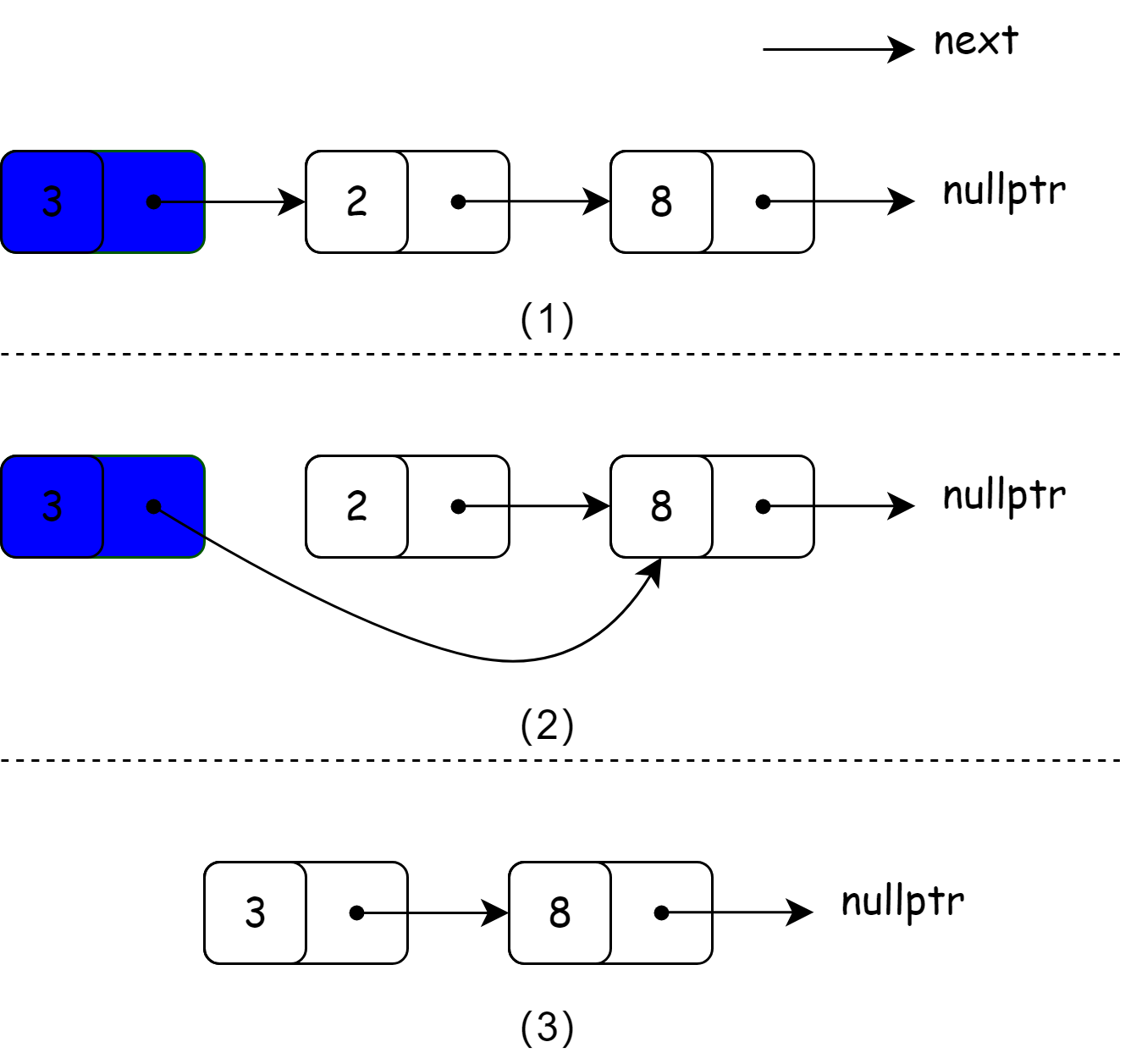
1、创建新的dev分支。
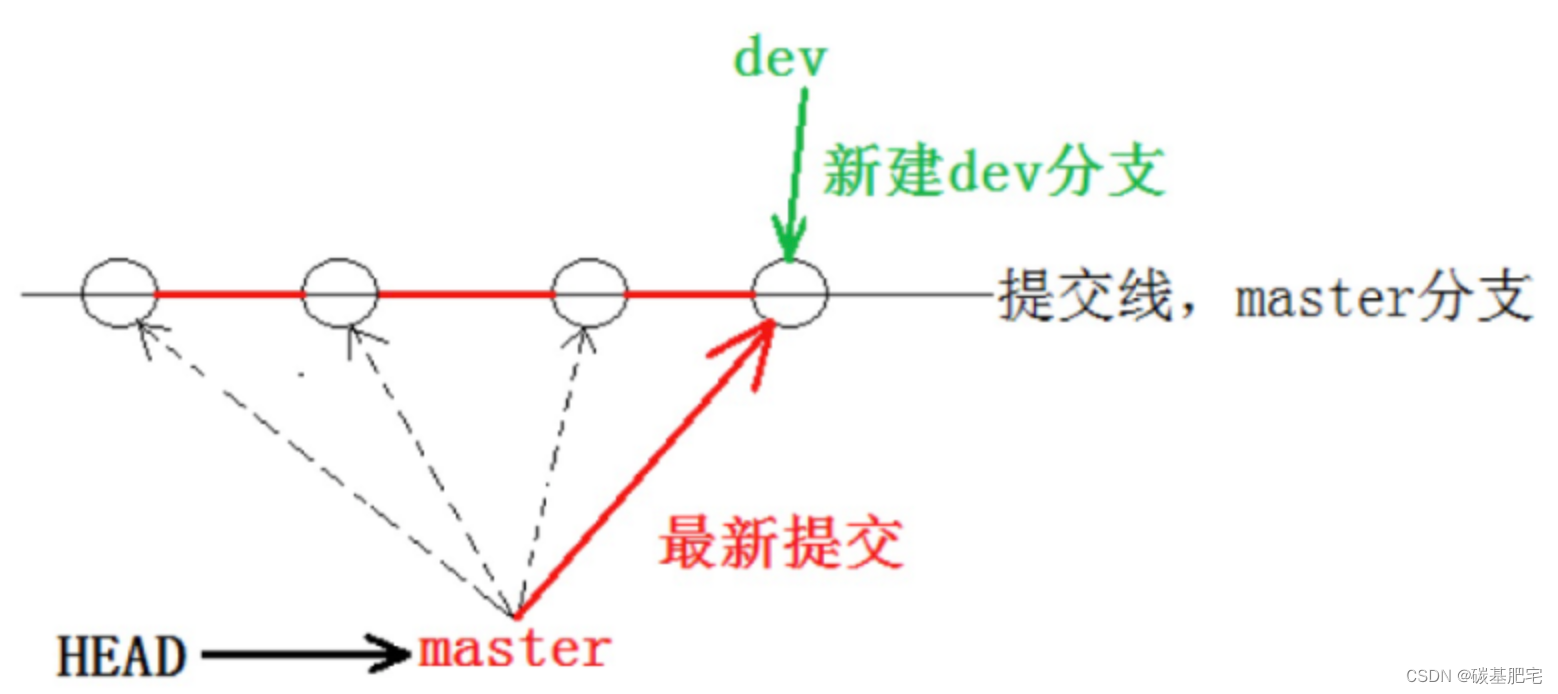
2、git checkout dev:切换至dev分支。
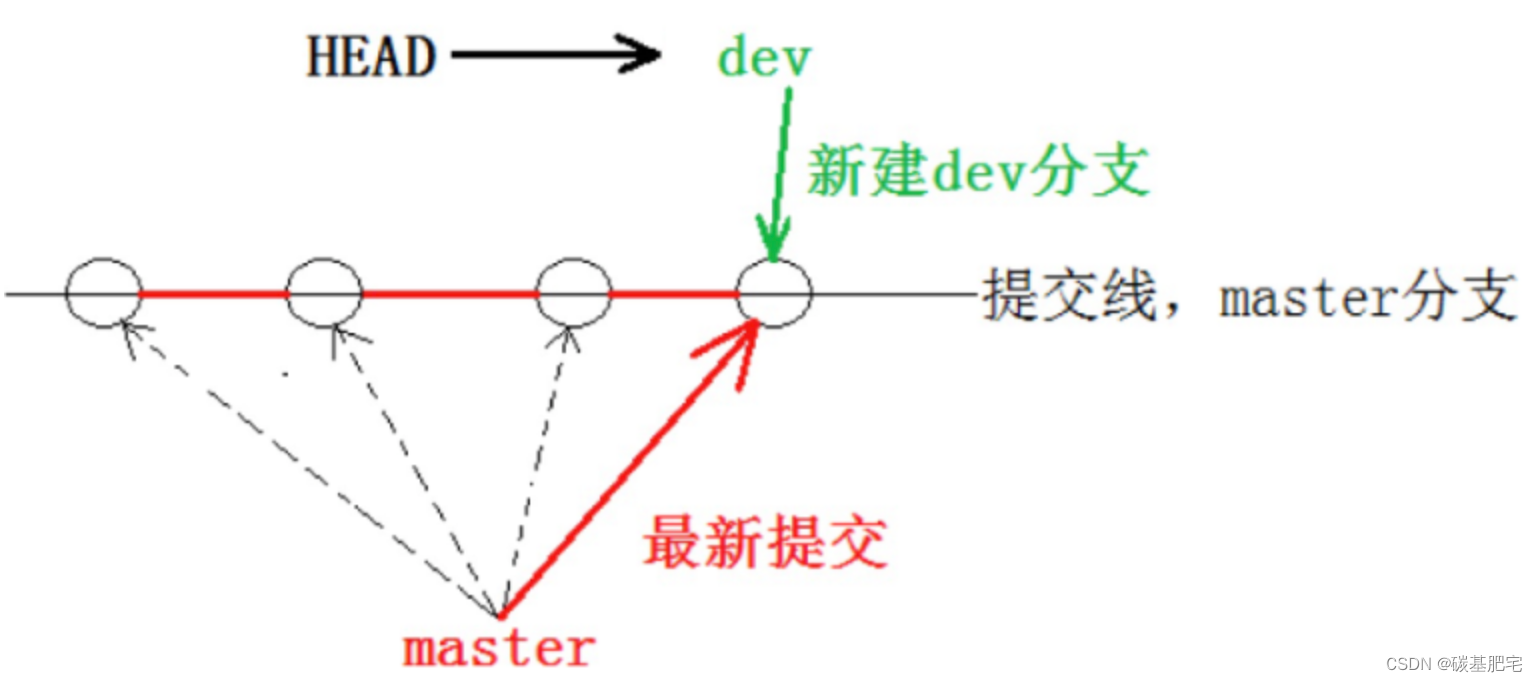
3、在dev分支上commit。
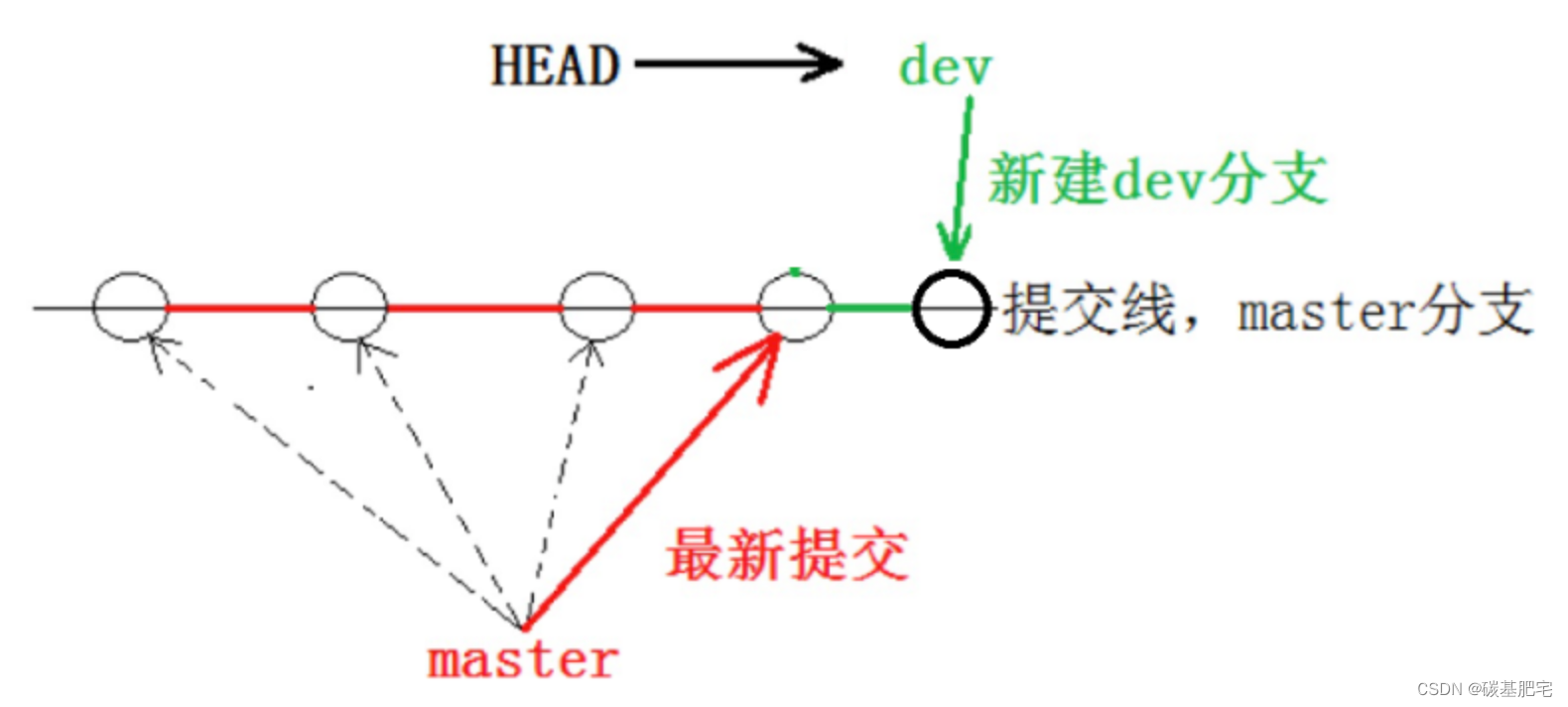
4、切换回master分支,git merge dev
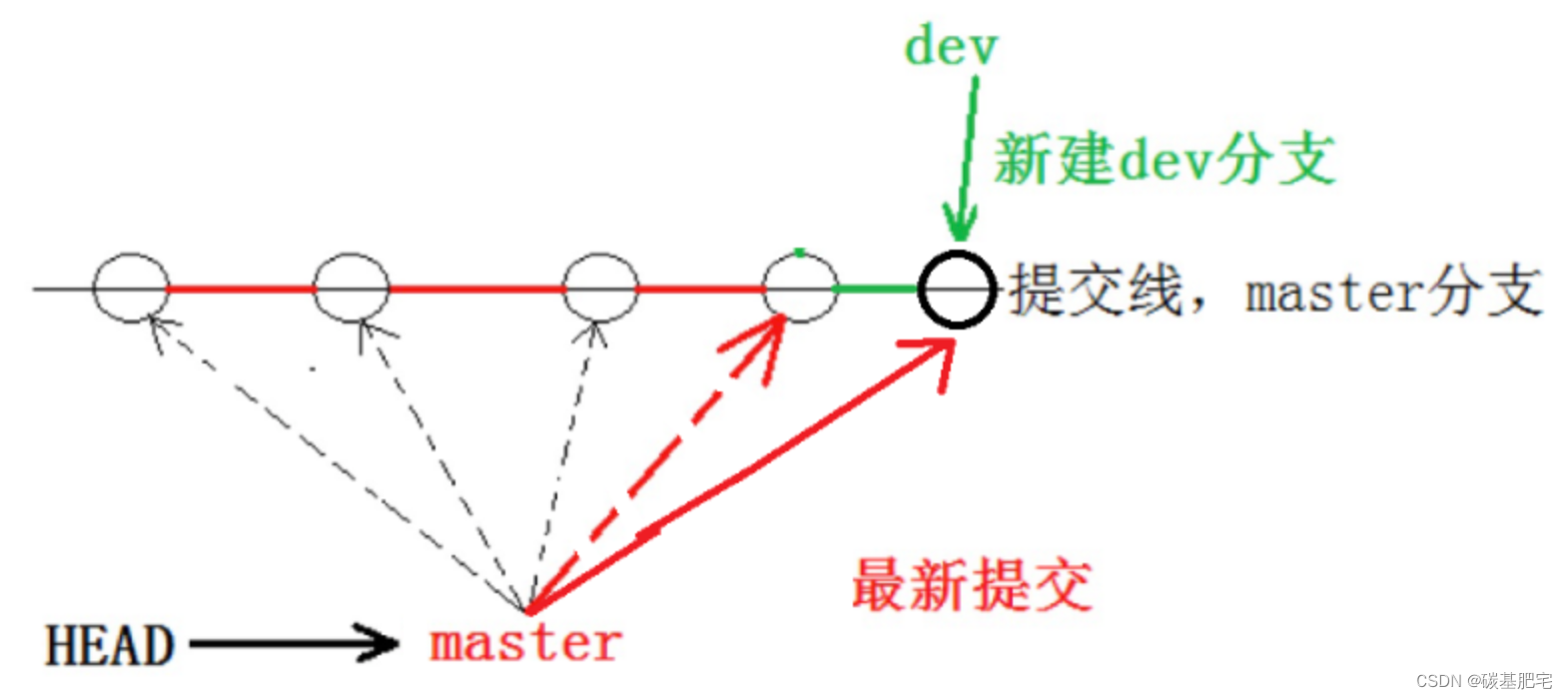
6.删除分支
合并完成后,dev分支对于我们来说就没用了,那么dev分支就可以被删除掉。删除分支的命令为:
git branch -d <分支名>注意,如果当前正处于dev分支下,是不能删除dev分支本身的:
hyb@139-159-150-152:~/gitcode$ git branch
*dev
master
hyb@139-159-150-152:~/gitcode$ git branch -d dev
error:Cannot delete branch 'dev' checked out at'/home/hyb/gitcode'要删除当前分支,只能先切换到其他分支下,再执行删除操作,如:
hyb@139-159-150-152:~/gitcode$ git checkout master
Switched to branch 'master'
hyb@139-159-150-152:~/gitcode$ git branch -d dev
Deleted branch dev(was bdaf528).
hyb@139-159-150-152:~/gitcode$ git branch
* master此时的状态如图如下所示:
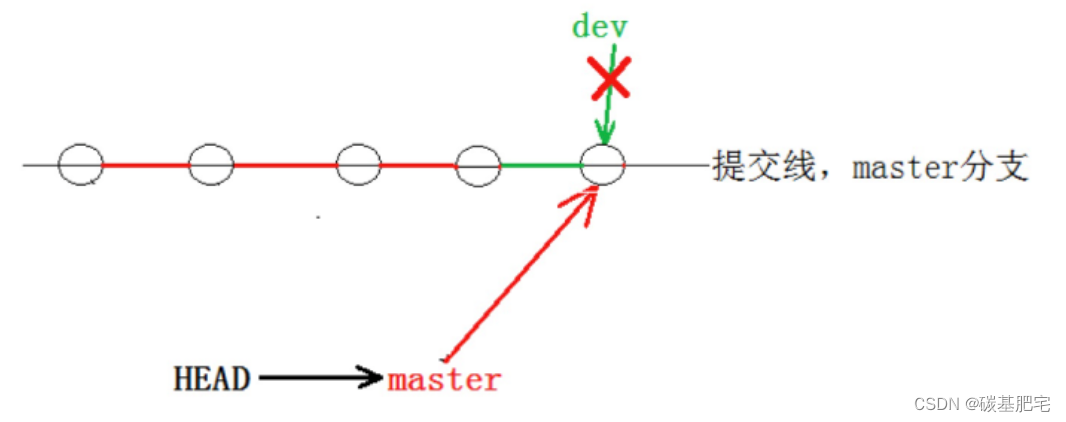
因为创建、合并和删除分支非常快,所以Git鼓励你使用分支完成某个任务,合并后再删掉分支,这和直接在master分支上工作效果是一样的,但过程更安全(“安全”正是使用分支的一个原因)。
7.合并冲突
在实际中,分支并不是想合并就一定能合并成功的,有时可能会遇到代码冲突的问题。
为了演示这问题,我们创建一个新的分支 dev1 ,并切换至目标分支。
注意,可以使用
git checkout -b dev1一步完成创建并切换的动作,示例如下:

git checkout -b dev1
和
git branch dev1 + git checkout dev1
效果是相等的。
我们在dev1分支下修改ReadMe文件,将 aaa on dev branch 改为 bbb on dev branch,然后提交:
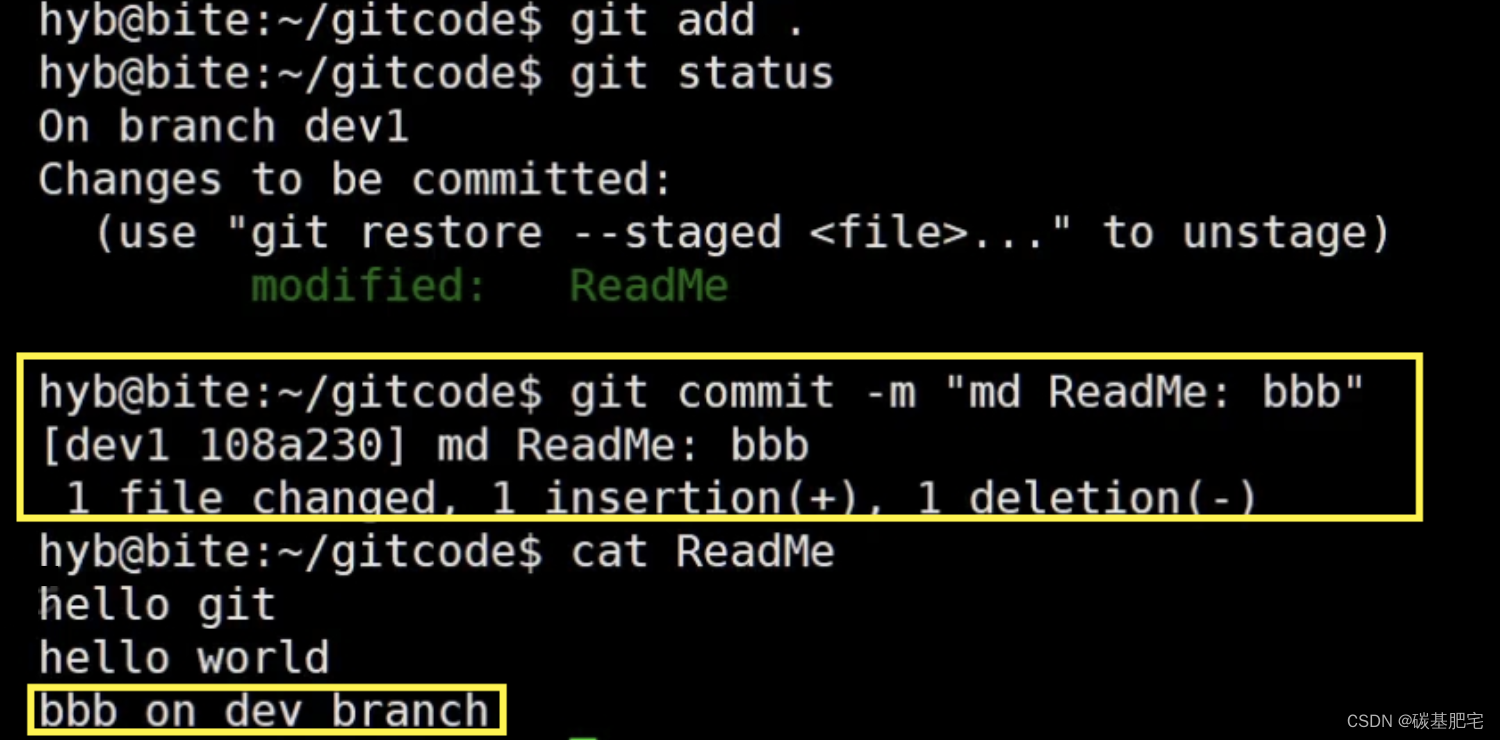
此时在dev1分支中,ReadMe文件最终修改并提交的结果为 bbb on dev branch。
切回master分支,然后在master分支下将ReadMe文件最终修改并提交为 ccc on dev branch:

现在master分支和dev1分支中都各自有了新的提交:
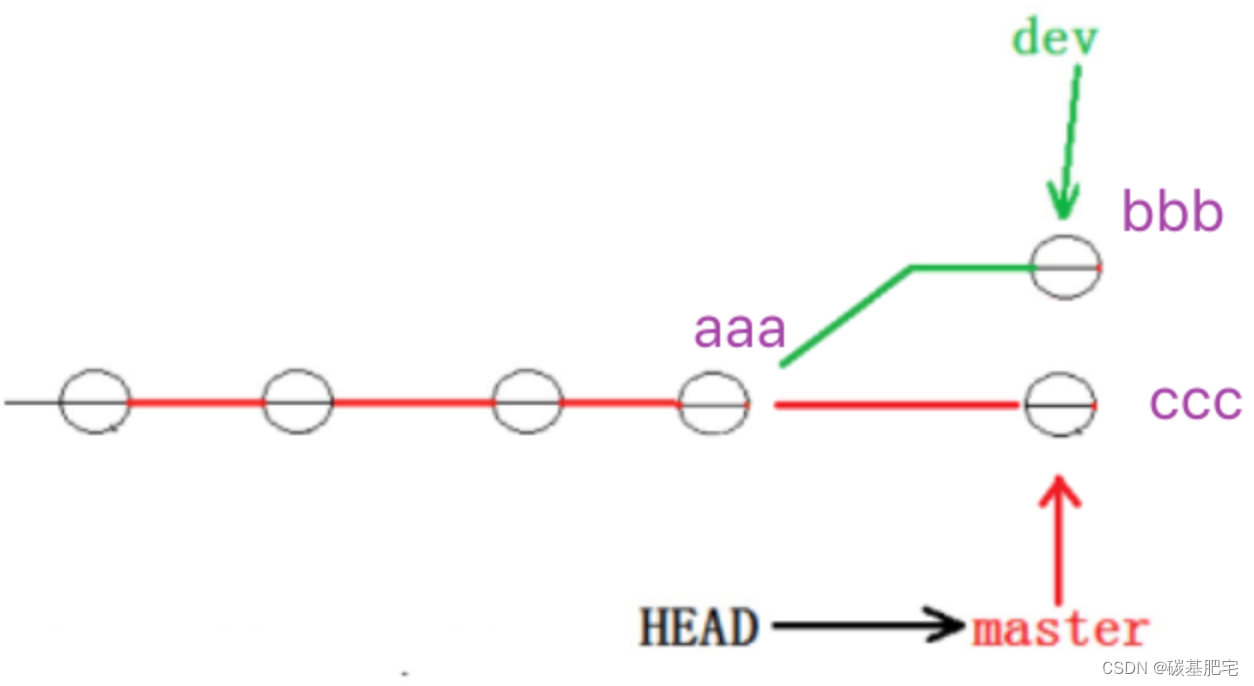
Git只能试图把各自的修改合并起来,但这种合并可能会有冲突。
在master分支中执行 git merge dev1 ,将dev1分支与master分支上提交的修改合并,结果如下:

发现ReadMe文件有冲突后,可以直接查看文件内容来查看冲突详情。Git会用<<<<<<<,=======,>>>>>>>来标记出不同分支冲突的具体内容,如下所示:
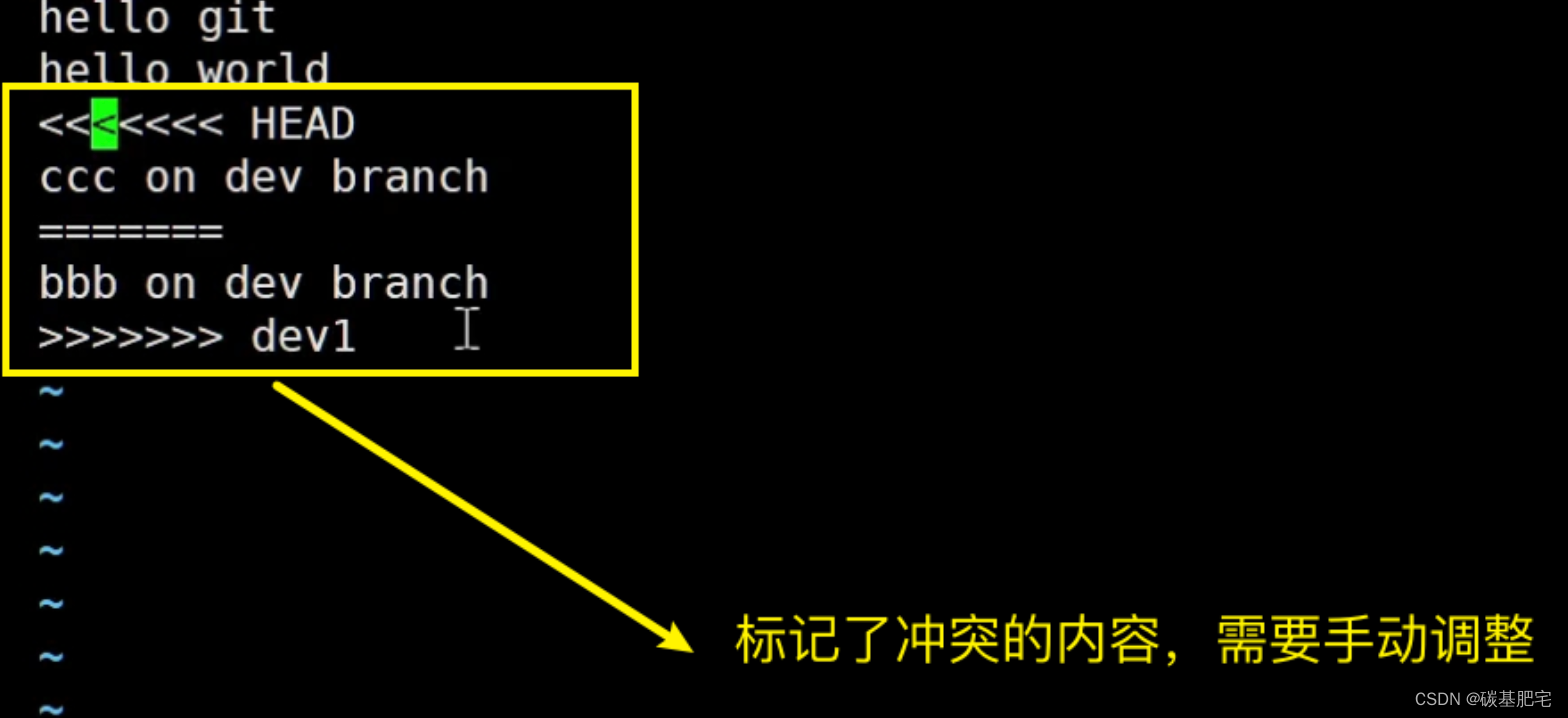
此时我们要做的是手动调整发生冲突的代码(将不要的内容手动删除,把要的内容保留下来),并需要再次提交修正后的结果!!
(再次提交很重要,切勿忘记)
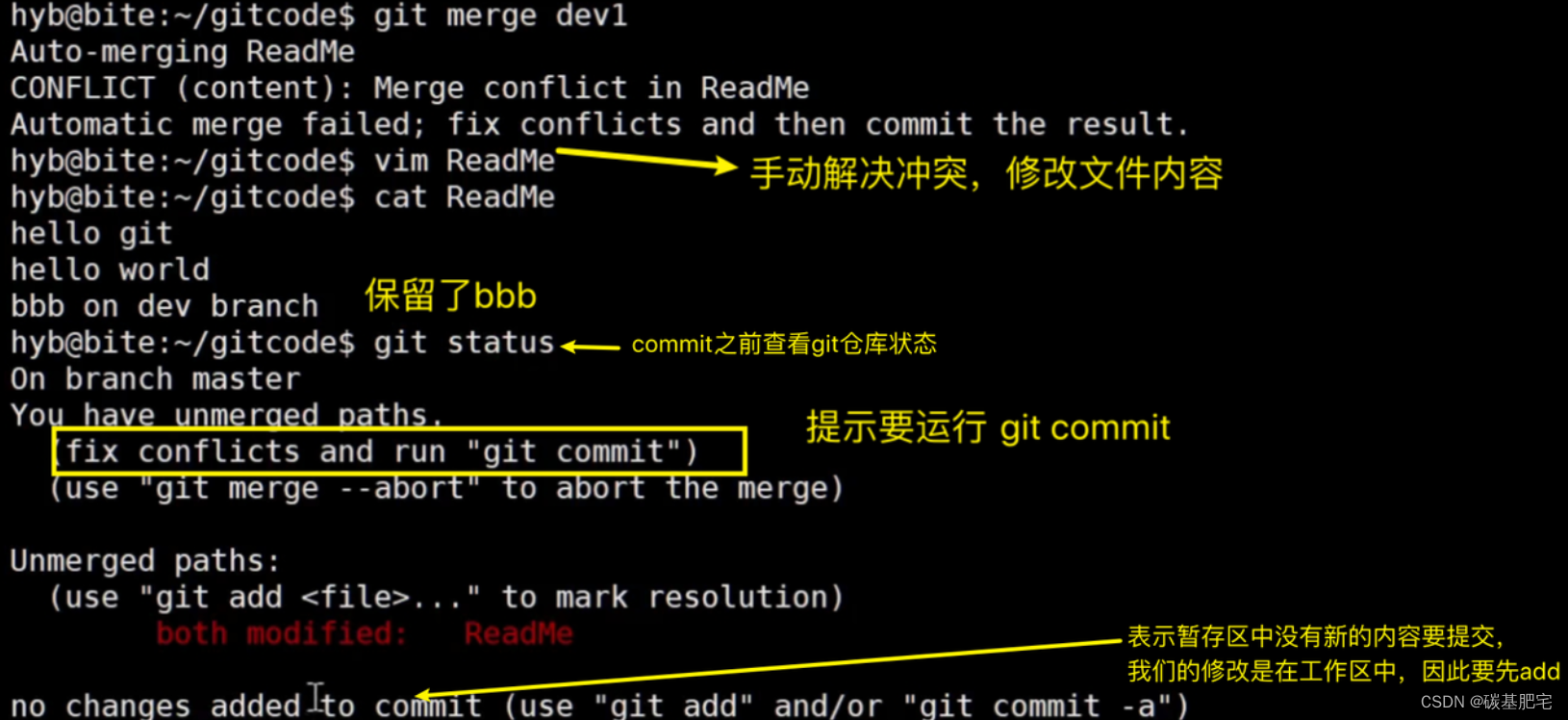
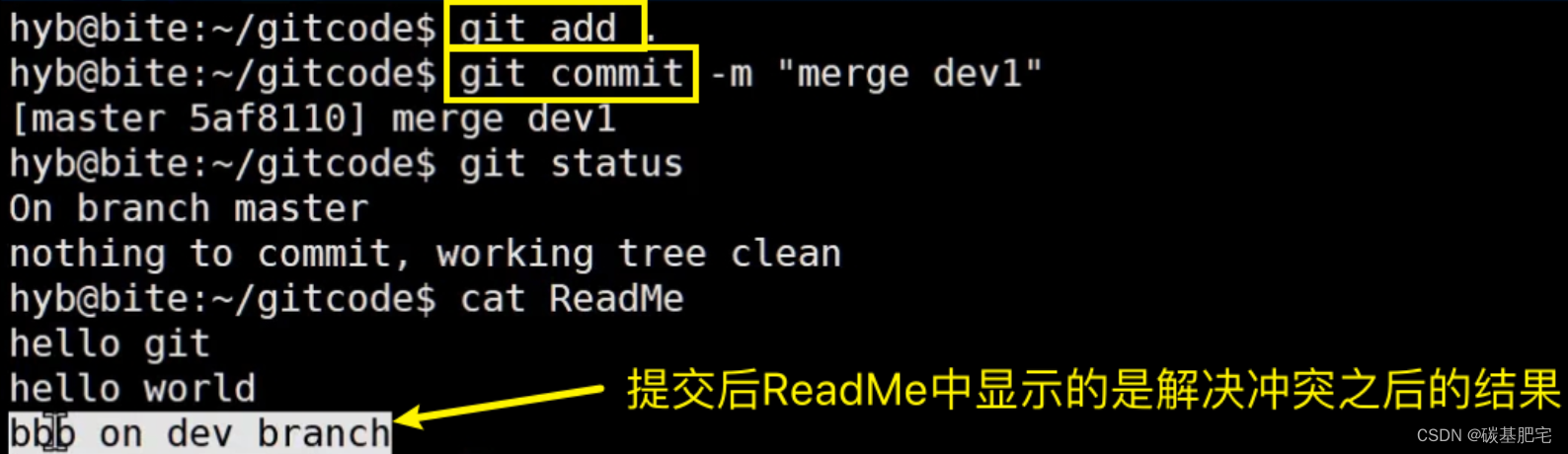
到这里冲突就解决完成,此时的状态变成了:
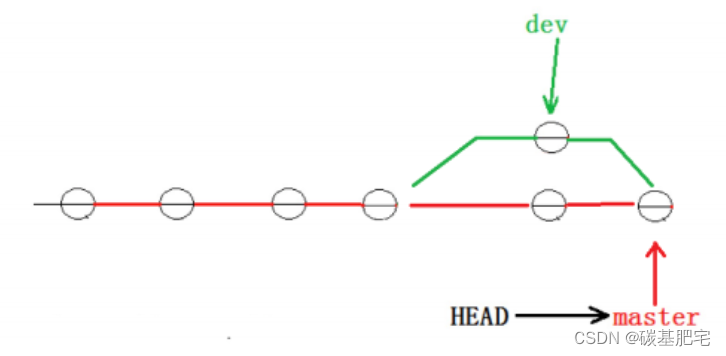
补充:查看分支合并的情况
用带参数的 git log 命令可以看到分支的合并情况:
命令:git log --graph --abbrev-commit
上图中,星号 * 代表的就是之前的“提交(commit)”。
最后,不要忘记dev1分支使用完毕后就可以删除了:git branch -d dev
8.分支管理策略
Fast Forward 模式(ff模式)
通常合并分支时,如果可以,Git 会采用 Fast forward 模式。
Fast forward 模式形成的合并结果:

在Fast forward模式下,当我们合并分支后查看分支历史时,分支历史的展示中会丢失部分分支信息,即看不出来最新的提交到底是merge进来的还是正常提交的。

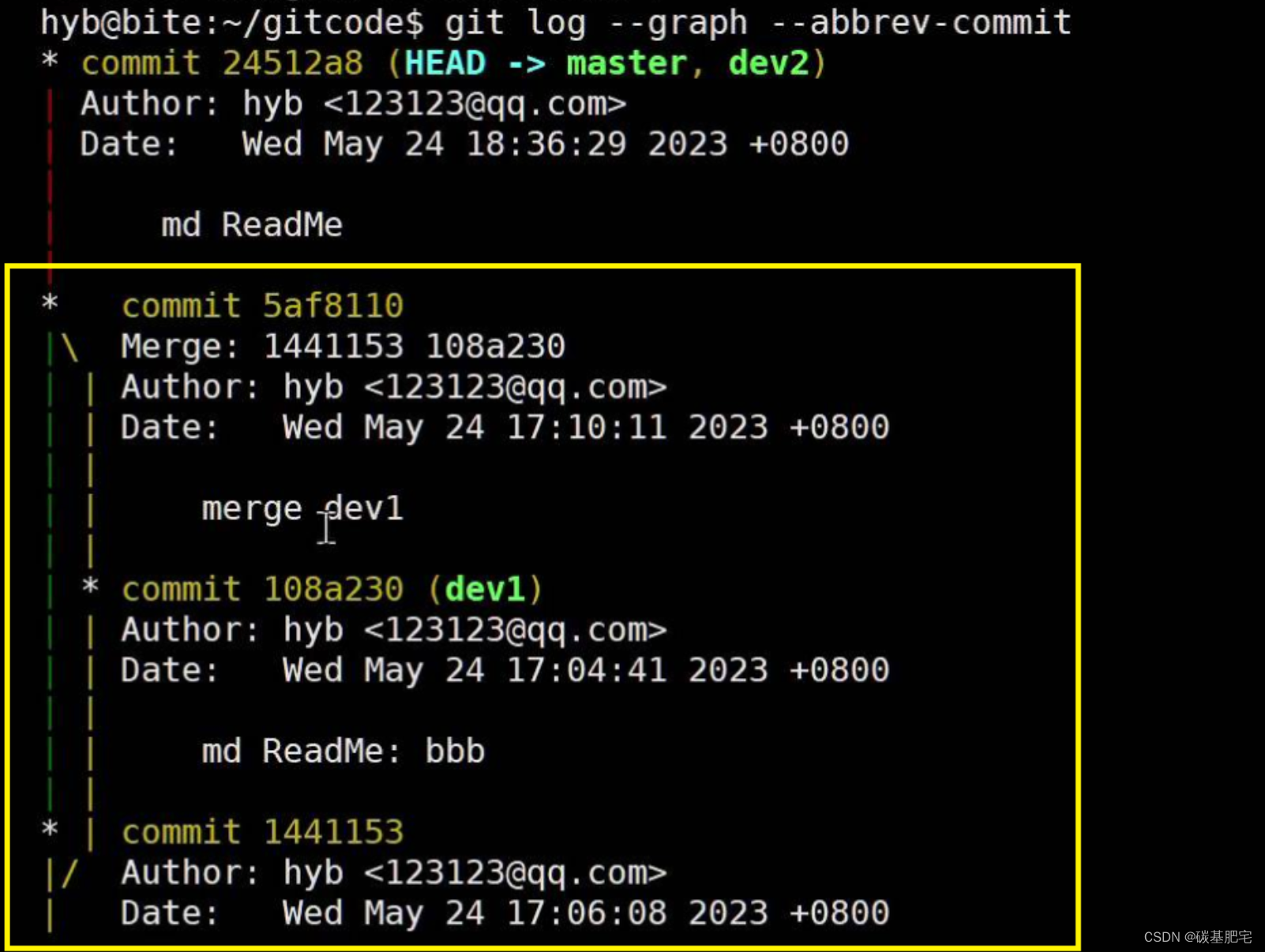
非Fast Forward模式(no-ff模式)
我们知道,当发生合并冲突时,在解决冲突问题后还需要再进行一次新的commit,然后才能得到最终状态:

这里就不是 Fast forward 模式了。
在非 Fast forward 模式中,从分支历史上是可以看出分支信息的。例如我们现在已经删除了在合并冲突部分创建的 dev1 分支,但依旧能看到 master 其实是由其他分支合并得到的:
如何在正常提交的时也选择no-ff模式呢?
Git支持我们强制禁用fast forward,那么就会在 merge 时生成⼀个新的 commit 。这样,从分⽀历史中就可以看出分支信息。
在执行 git merge 时添加 --no-ff 选项,就表示不使用ff模式。--no-ff选项表示的就是禁用 Fast forward 模式。禁用 Fast forward 模式后,在合并分支后会创建一个新的 commit ,所以要加上-m参数,把描述(message)也写进去:

由下面的图可知,在no-ff模式下生成一个新的commit,最终master也会指向一个新的提交:
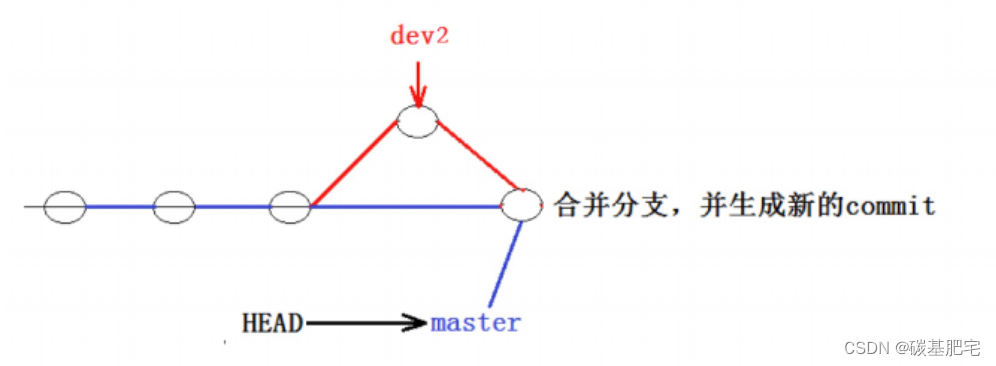

ff模式和no-ff模式最大的区别是,用
git log --graph --abbrev-commit命令查看提交日志时,能否区别出git的master中的每个commit是merge进来的还是正常提交的。
(在企业实操中一般更建议使用no-ff模式。)
9.分支策略

在实际开发中,我们应该按照几个基本原则进行分支管理:
-
首先,master分支应该是非常稳定的,也就是仅用来发布新版本,平时不能在上面干活。
-
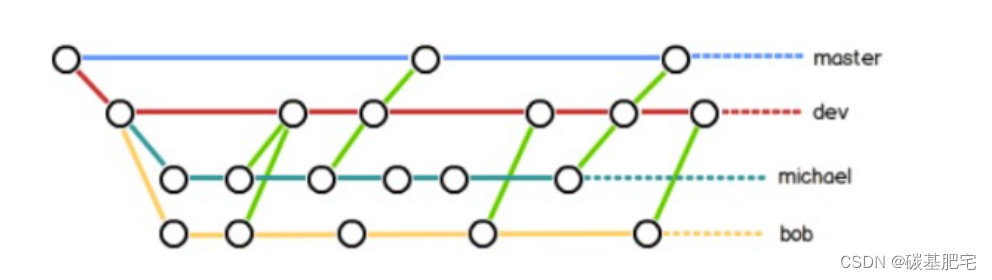
干活都在dev分支上。(dev分支是不稳定的,到某个时候,比如1.0版本发布时,再把dev分支合并到master上,在master分支发布1.0版本)。
你和你的小伙伴们每个人都在dev分支上干活,每个人都有自己的分支,时不时地往dev分支上合并就可以了。

所以,团队合作的分支看起来就像这样:
10.bug分支
假设我们现在正在 dev2 分支上进行开发,开发到一半还没提交,突然发现 master 分支(即线上环境的代码)上有严重的 bug(如闪退之类的),需要马上解决。
直接在master主分支上编辑代码进行bug修复,这肯定是不可以的。
安全起见,必须遵守分支的策略,即在本地创建一个新的临时分支来修复,修复后,经过测试团队的测试后将稳定的代码合并到master分支,然后将临时分支删除。
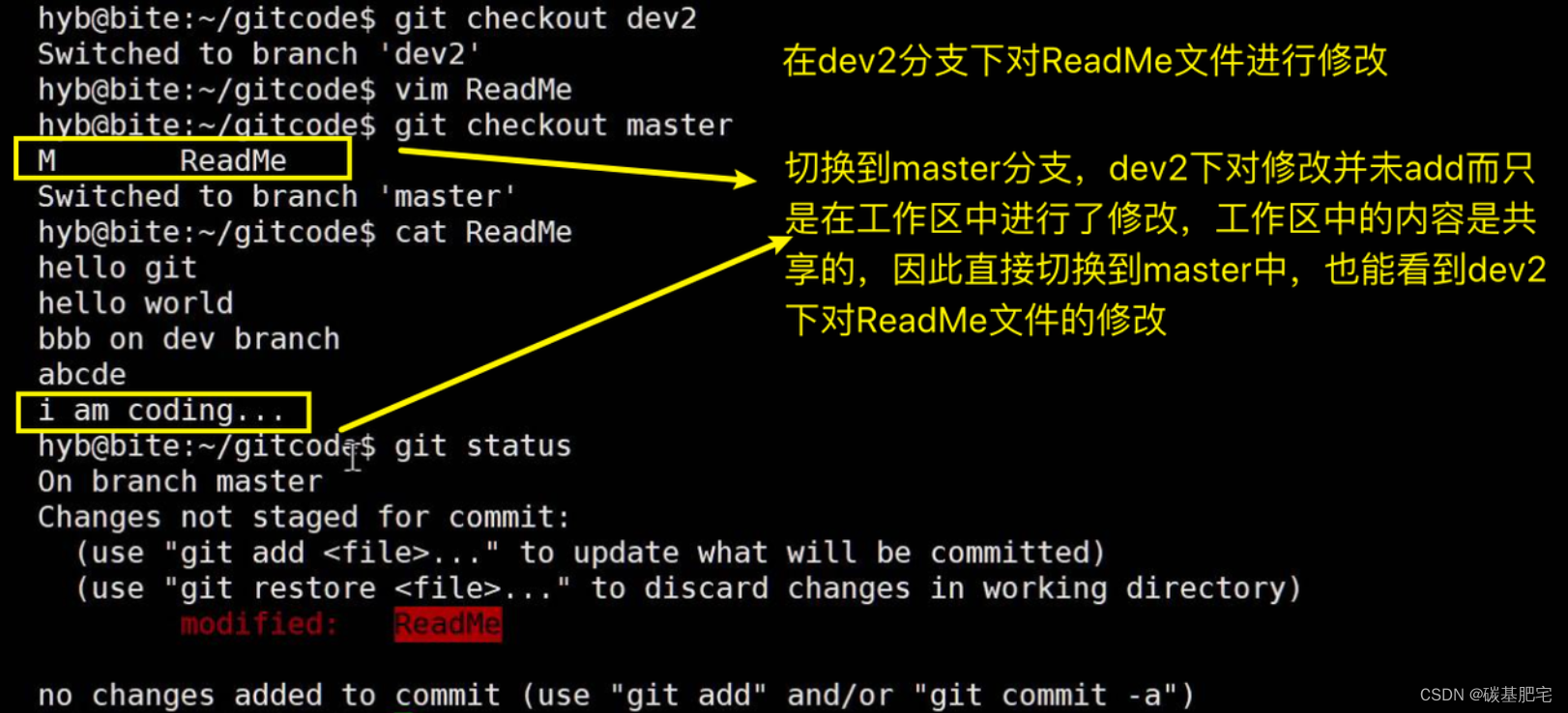
可现在dev2的代码在工作区中开发了一半,还无法提交,而要修复master中的bug怎么办?
dev2中的修改都在工作区中,dev2在工作区中的做的修改会影响在其余分支的工作区进行工作。此时就需要先对dev2工作区中的内容进行保存。Git 提供了
git stash命令,可以将当前的工作区信息进行储藏,被储藏的内容可以在将来某个时间恢复出来:

执行完git stash命令后,tree ./git,可以查看到当前git目录下多了一个stash目录,dev2的修改就被存储在这个stash目录中:

git stash后用git status查看工作区,工作区是干净的(除非有没有被 Git 管理的文件),因此可以放心地创建分支来修复bug:

注意,如果工作区还有没被 git 管理起来的文件,则该文件不能被暂存起来:

储藏dev2工作区之后,由于我们要基于master分支修复bug,所以需要切回分支,再新建临时分支来修复bug,示例如下:

修复完成后,切换回master主分支,并将bug分支合并到master分支,最后删除bug分支即可:
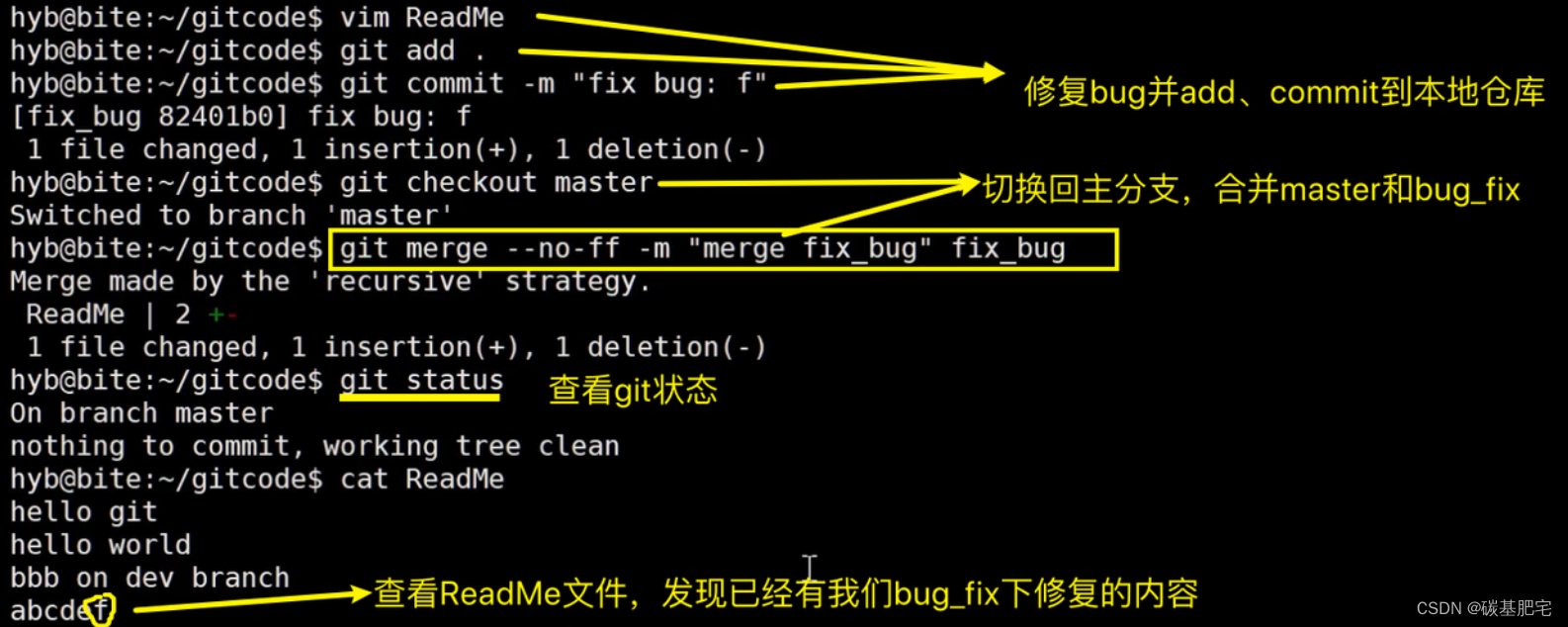
至此,针对master主分支上的bug修复工作(即:切回主分支,拉一个bug_fix新分支,在bug_fix上修复完bug后再合并到master这样的一系列操作)已经做完了,我们还要继续回到dev2分支进行一开始未完成的内容的开发。
切换回dev2分支:

在dev2分支下检查 git status会发现,工作区是干净的:
hyb@bite:~/gitcode$ git status
On branch dev2
nothing to commit, working tree clean可以用git stash list查看stash存放哪些内容,使用
git stash pop命令来恢复现场,恢复的同时会把stash中的内容删了,示例如下:
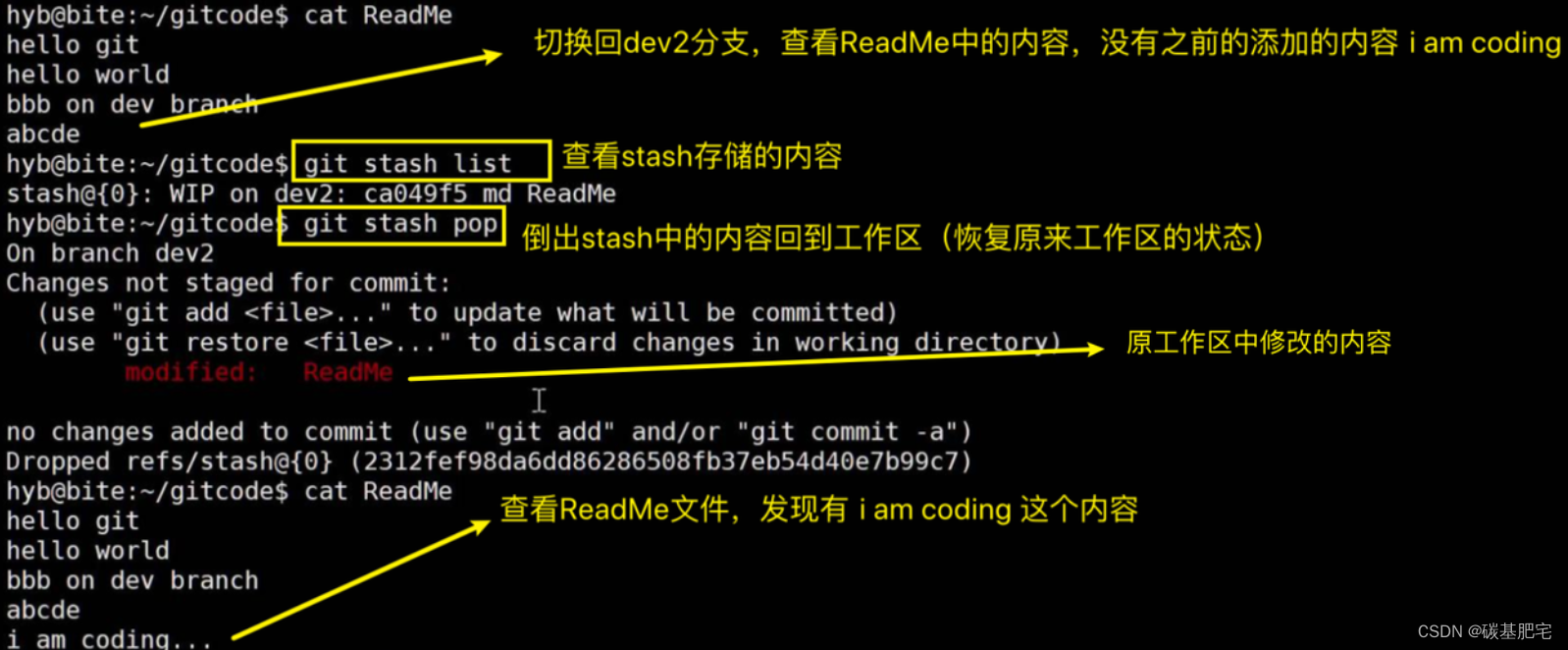
补充: 恢复现场除了
git stash pop,也可以采⽤git stash apply。但是,用git stash apply恢复后,stash内容并不删除,需要我们自己调⽤git stash drop来删除。可以多次进行git stash,恢复的时候,先⽤git stash list查看,然后恢复指定的stash,⽤命令git stash apply stash@{0}即可。
再次查看stash中的内容,我们已经发现已经没有现场可以恢复了:
hyb@bite:~/gitcode$ git stash list
# 没有内容显示恢复完工作区的代码之后,我们便可以继续在dev2完成开发,开发完成后便可以进行提交:


但修复bug的内容并没有在 dev2 上显示。
为什么dev2下的ReadMe文件中,内容还是abcde而不是abcdef呢?这是因为创建dev2的时候,是基于还未修复的master的,也就是还有bug的master的。
此时的状态图为:
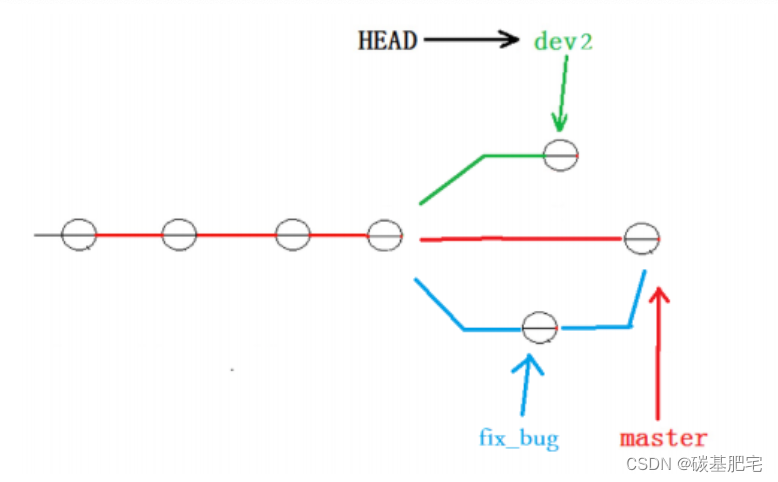
最终目的是要让 master 分支和 dev2 分支合并。正常情况下我们切回 master 分支,直接将dev2分支的内容合并到master中即可,但这样其实是有一定风险的。
因为在master分支与dev2分支合并时可能会发生冲突,而代码冲突需要我们手动解决(在 master 上解决)。我们无法保证对于冲突问题可以正确地一次性解决掉,因为在实际的项目中,代码冲突不只一两行那么简单,有可能几十上百行,甚至更多,解决的过程中难免手误出错,导致错误的代码被合并到 master 上。此时的状态为:
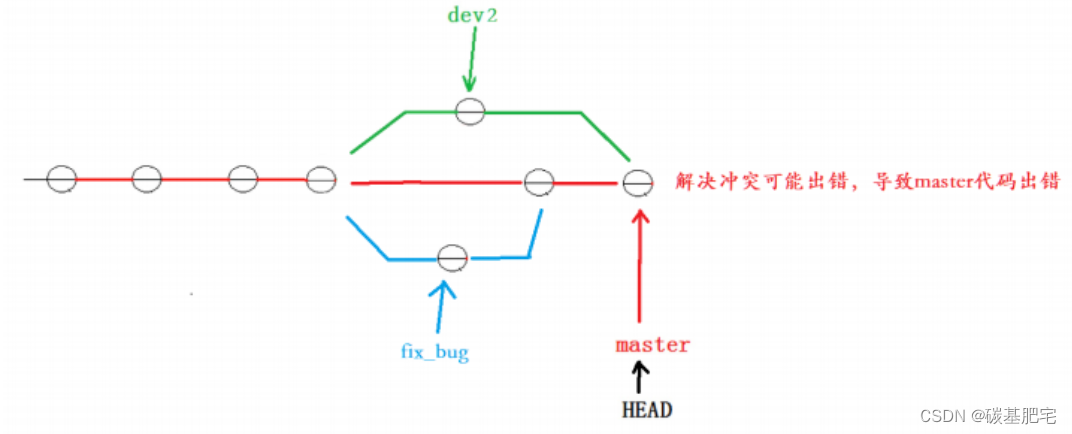
解决这个问题的一个好的建议是:先在自己的dev2分支上合并 master主分支,再让 master 去合并dev2分支。这样做的目的是,一旦有冲突可以在本地分支dev2上解决并进行测试,而不影响 master 。
此时的状态为:

实操演示如下:
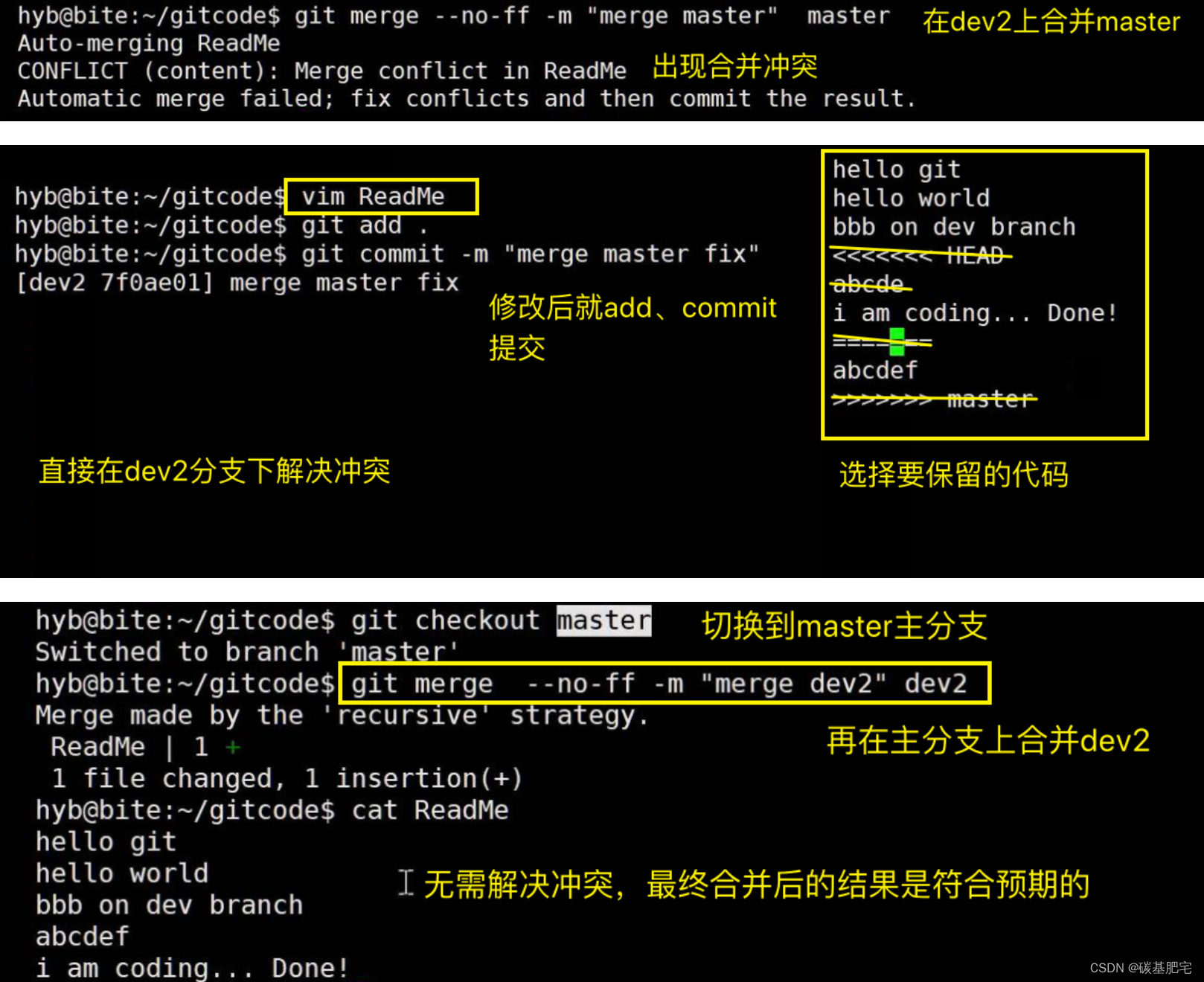
最后执行 git branch -d ,将已经完成使命的dev2分支和bug_fix分支合并即可。
疑问解决
对于上述分支策略下的一系列操作,有的朋友可能会有疑问:dev2从master中拉出来的时候,ReadMe文件内容是abcde;但是master后来又拉了bug_fix分支,并把内容改成了 abcdef。如果工作区是共享的话,在bug_fix分支更改为abcdef的时候为什么没有影响到dev2分支呢?
原因:
abcdef已经提交了,属于版本库的内容,对于master来说,此时工作区是干净(clean)的,无变动。工作区是干净的,那么dev2分支的工作区也是干净的。git是基于提交来管理文件的,提交之前工作区共享。提交之后,提交的内容就已经被隔离了。
也就是说,如果bug_fix分支改成abcdef之后,没有进行add操作,那么bug_fix、master和dev2三个分支工作区的内容都会是abcdef;而如果bug_fix提交修改之后,工作区变成干净的,其他的分支的工作区也会变回原本的样子。
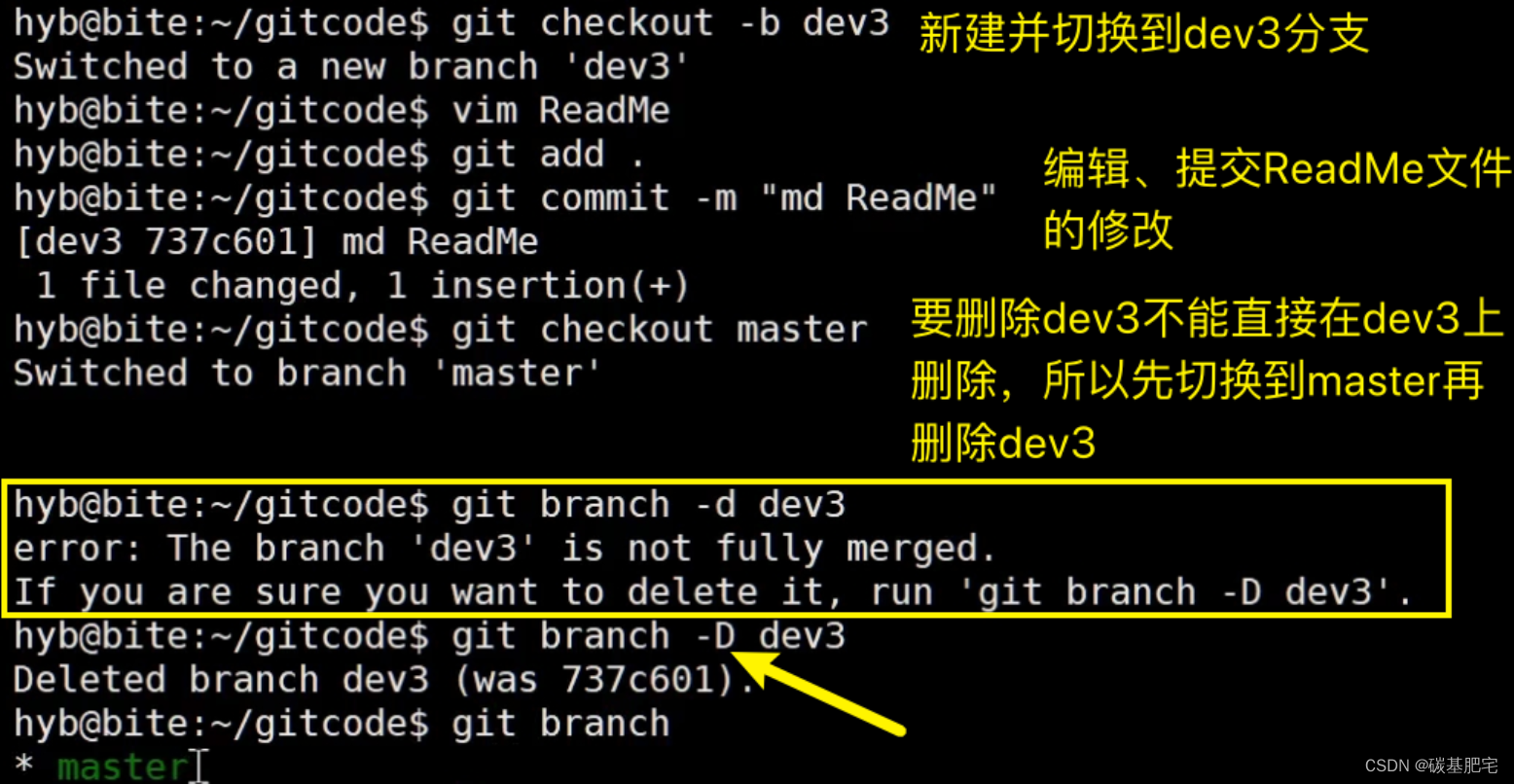
11.删除临时分支
软件开发中,总有无穷无尽的新的功能要不断添加进来。
添加一个新功能时,我们肯定不希望一些实验性质的代码把主分支搞乱了。所以,每添加一个新功能,最好新建一个分支,我们可以将其称之为 feature 分支。在feature 分支上进行开发,开发完成后再合并,最后删除该 feature 分支。
可是,如果我们今天正在某个 feature 分支上开发了一半,被产品经理突然叫停,说是要停止新功能的开发。虽然白干了,但是这个 feature 分支还是必须就地销毁,留着无用了。
这时使用原来的 git branch -d 命令删除分支的方法是不行的。
之前之所以有可以用git branch -d删除分支的情况,是因为当时已经把分支和master主分支merge过了。而如果当前分支没有和master主分支merge过、且已在当前分支进行过一些提交的时,git是会在删除时保护当前分支的(git认为只要分支被创建出来了且在上面有过提交,那么这个分支就是有用的,不能随便删除)。
使用
git branch -D命令则可以强制删除:
12.分支小结
分支在实际中有什么用呢?
假设你准备开发一个新功能,但是需要两周才能完成,第一周你写了50%的代码,如果立刻提交,由于代码还没写完,不完整的代码库会导致别人不能干活了。如果等代码全部写完再一次提交,又存在丢失每天进度的巨大风险。现在有了分支,就不用怕了。你创建了一个属于你自己的分支,别人看不到,还继续在原来的分支上正常工作,而你在自己的分支上干活,想提交就提交,直到开发完毕后,再一次性合并到原来的分支上,这样既安全,又不影响别人工作。
并且 Git 无论创建、切换和删除分支,Git在1秒钟之内就能完成!无论你的版本库是1个文件还是1万个文件。
六、远程操作
1.理解分布式版本控制系统
我们目前所说的所有内容(工作区,暂存区,版本库等等),都是在本地,也就是在你的笔记本或者计算机上。而我们的Git其实是分布式版本控制系统。什么意思呢?
可以简单理解为,我们每个人的电脑上都是一个完整的版本库,这样你工作的时候,就不需要联网了,因为版本库就在你自己的电脑上。既然每个人电脑上都有一个完整的版本库,那多个人如何协作呢?比方说你在自己电脑上改了文件A,你的同事也在他的电脑上改了文件A,这时,你们俩之间只需把各自的修改推送给对方,就可以互相看到对方的修改了。

分布式版本控制系统的安全性要高很多,因为每个人电脑里都有完整的版本库,某一个人的电脑坏掉了不要紧,随便从其他人那里复制一个就可以了。
在实际使用分布式版本控制系统的时候,其实很少在两人之间的电脑上推送版本库的修改,因为可能你们俩不在一个局域网内,两台电脑互相访问不了。也可能今天你的同事病了,他的电脑压根没有开机。因此,分布式版本控制系统通常也有一台充当“中央服务器”的电脑,但这个服务器的作用仅仅是用来方便“交换”大家的修改,没有它大家也一样干活,只是交换修改不方便而已。有了这个“中央服务器”的电脑,这样就不怕本地出现什么故障了(比如运气差,硬盘坏了,上面的所有东西全部丢失,包括git的所有内容)。
2.远程仓库
Git是分布式版本控制系统,同一个Git仓库,可以分布到不同的机器上。怎么分布呢?最早,肯定只有一台机器有一个原始版本库,此后,别的机器可以“克隆”这个原始版本库,而且每台机器的版本库其实都是一样的,并没有主次之分。
你肯定会想,至少需要两台机器才能玩远程库不是?但是我只有一台电脑,怎么玩?
其实一台电脑上也是可以克隆多个版本库的,只要不在同一个目录下。不过,现实生活中是不会有人这么傻的在一台电脑上搞几个远程库玩,因为一台电脑上搞几个远程库完全没有意义,而且硬盘挂了会导致所有库都挂掉,所以我也不告诉你在一台电脑上怎么克隆多个仓库。
实际情况往往是这样,找一台电脑充当服务器的角色,每天24小时开机,其他每个人都从这个“服务器”仓库克隆一份到自己的电脑上,并且各自把各自的提交推送到服务器仓库里,也从服务器仓库中拉取别人的提交。
完全可以自己搭建一台运行Git的服务器,不过现阶段,为了学Git先搭个服务器绝对是小题大作。好在这个世界上有个叫GitHub的神奇的网站,从名字就可以看出,这个网站就是提供Git仓库托管服务的,所以,只要注册一个GitHub账号,就可以免费获得Git远程仓库。
这里贴一个博主本人的Github主页:GitHub,里面分享了一些开源项目,欢迎来访交流。
不过,Github是国外的网站,速度比较慢。而国内也有好用的开源平台,即Gitee(码云)。
这里采用码云来托管代码,我们从零开始来使用一下码云远程仓库。
新建远程仓库
1、新建远程项目仓库:
2、填写基本信息:

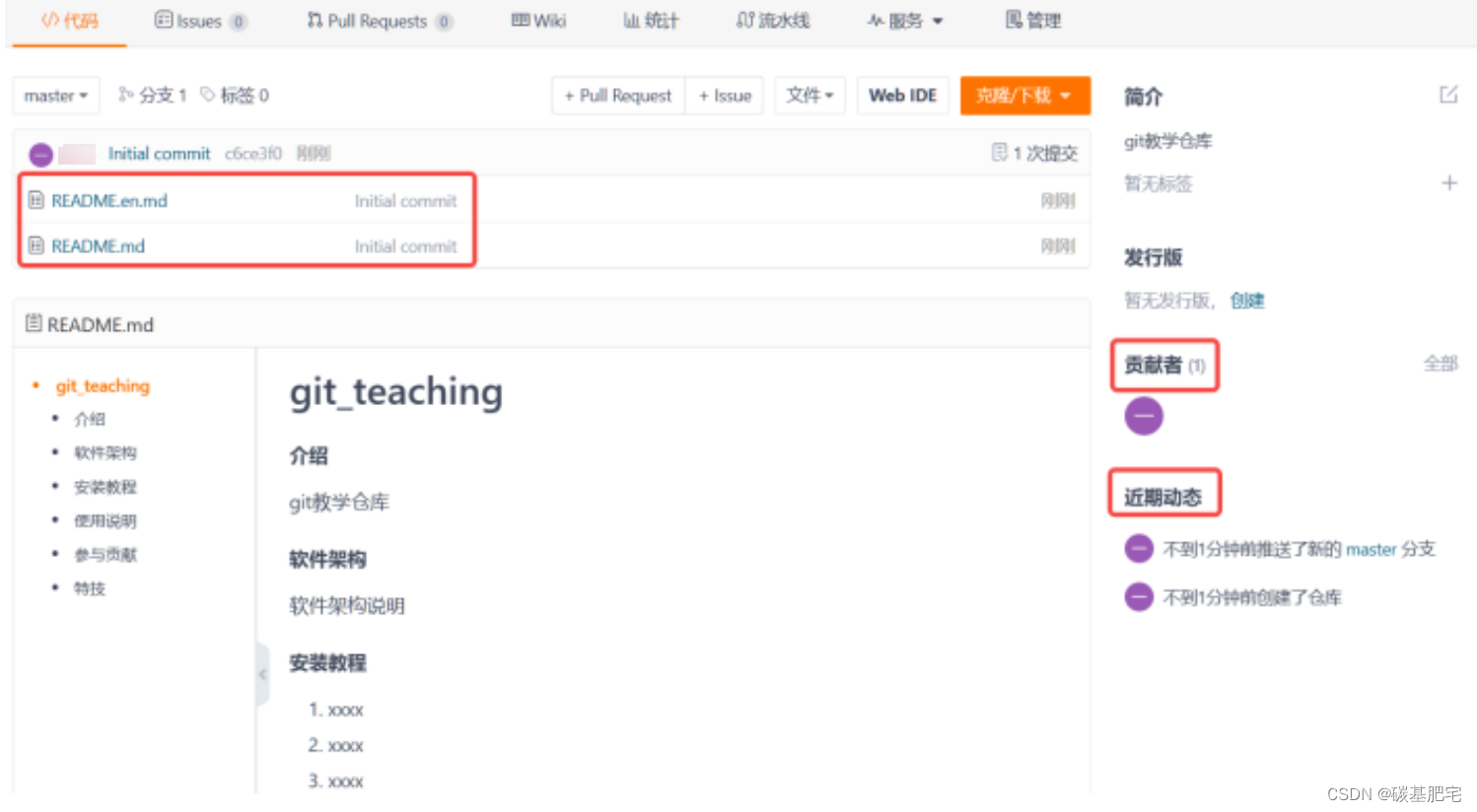
3、创建成功:
4、创建成功后,我们可以对远程仓库进行一个基本的设置:开源or私有


5、也可以在设置-仓库成员管理中管理协作者:

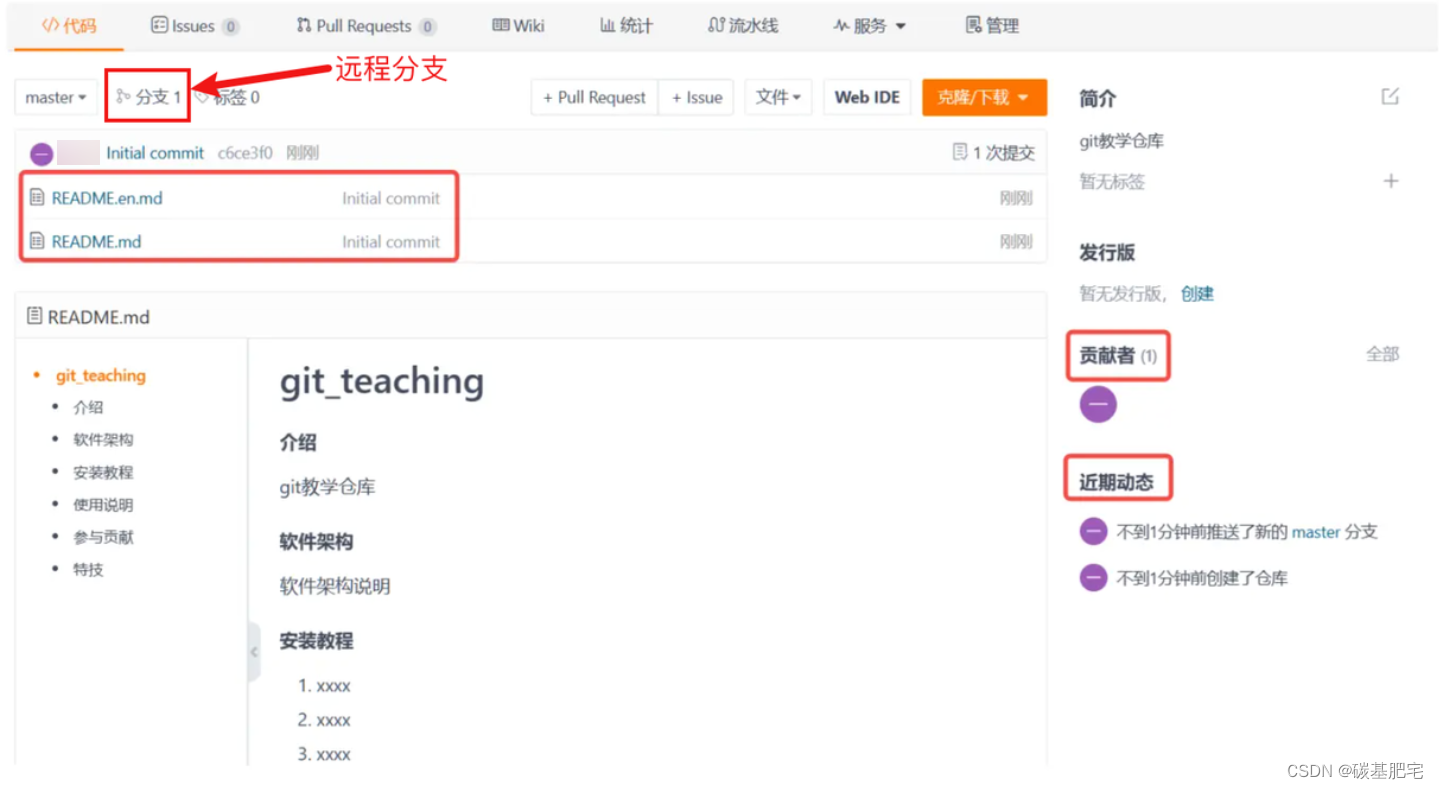
6、从创建好的远程仓库中我们便能看到,之前在本地学习过的分支,也存在于远程仓库中并被管理起来了。刚创建的仓库有且只有一个默认的master分支:

Issues
当把仓库设置为开源后,所有的用户都可以浏览这个仓库的内容。如果浏览者发现了你仓库中代码的bug,该怎么和你联系呢?
gitee和github都提供了Issues功能,这个功能是让仓库的浏览者和仓库的成员进行交流的地方。
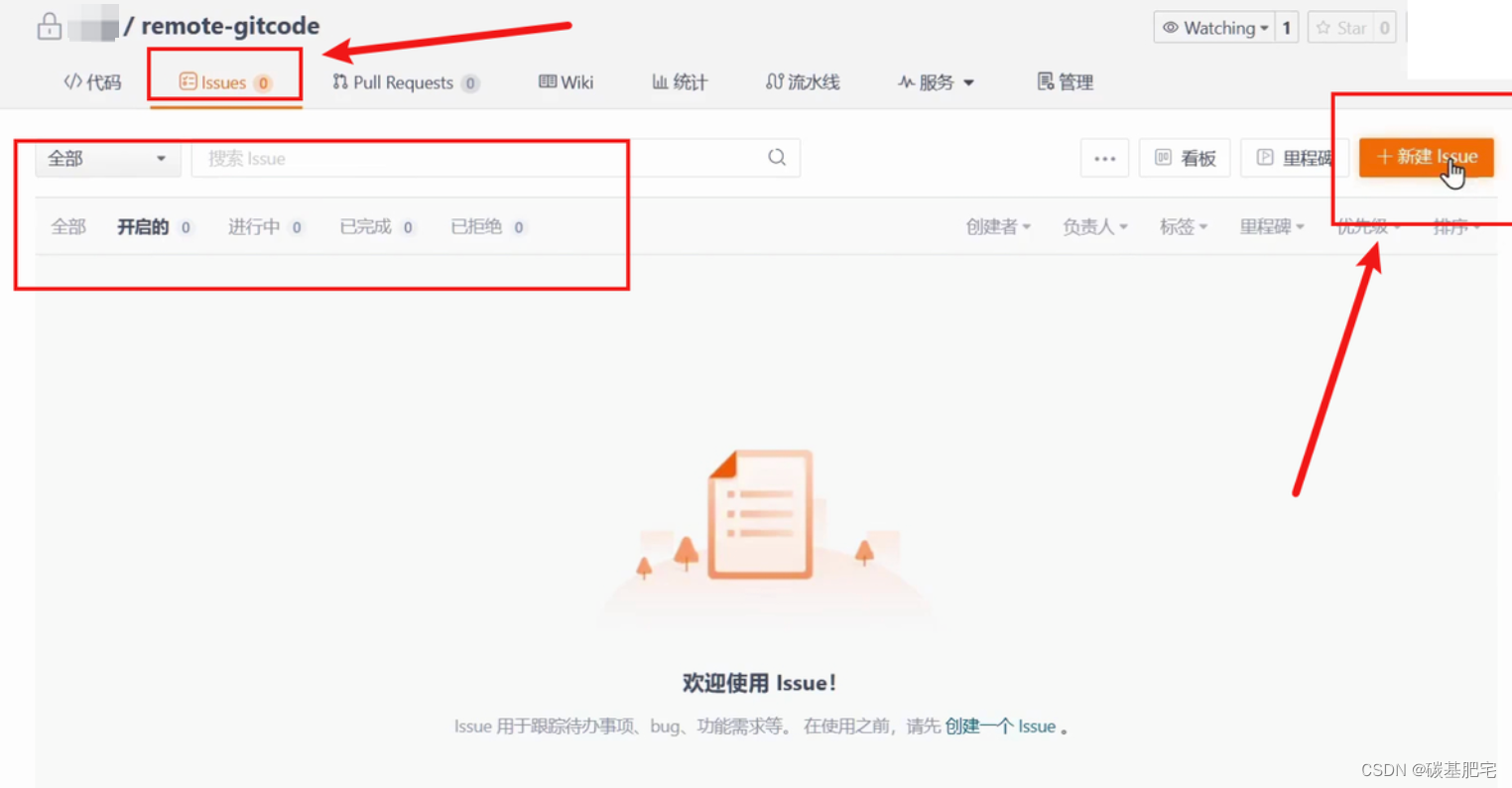
点击「新建Issue」,就进入编辑Issue的页面:
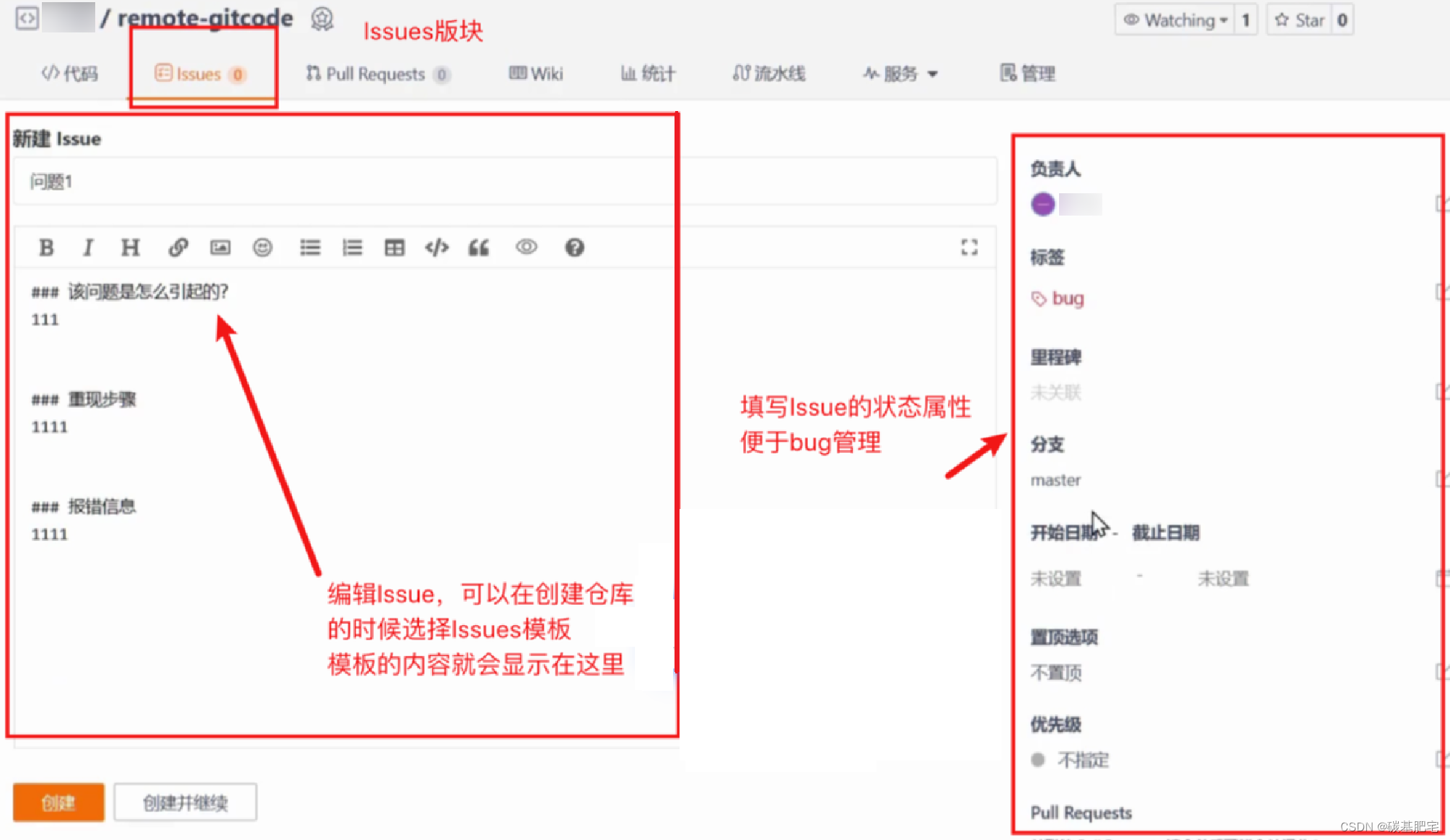
选择完毕之后,点击「创建」,在Issues版块中就会显示刚才提交的问题:

如果已经处理完这个bug,那么可以继续进入问题详情更改问题的状态:

Pull Request
实际开发中,直接允许dev分支的内容合并到master分支上是非常不安全的,很容易影响master分支上代码的稳定性。
因此,在有dev分支与master分支合并的需要时,应当由开发者提出一个dev分支的PR(即Pull Request,合并申请单)给仓库的管理员,PR中需要包含dev分支的一些信息,如做了什么改动、为什么要合并等。只有仓库管理员同意了,才能将dev中的代码merge到master中去。
仓库的PR信息在Pull Request版块可以看:

在创建项目时,也可以选择Pull Request的模板。
克隆远程仓库
克隆/下载远端仓库到本地,需要使用 git clone 命令,后面跟上我们的远端仓库的链接。
远端仓库的链接可以从仓库中找到:选择“克隆/下载”获取远程仓库链接:
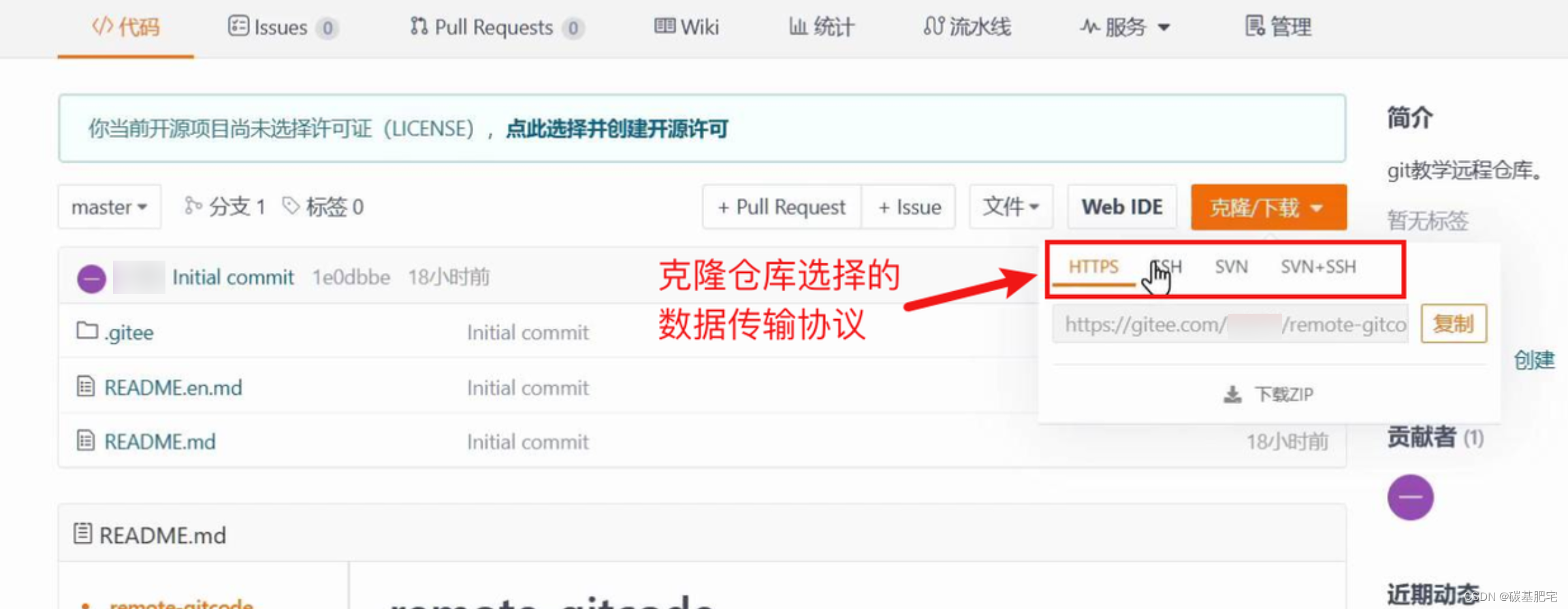
SSH协议和HTTPS协议是Git最常使用的两种数据传输协议。
SSH协议使用了公钥加密和公钥登录机制,体现了其实用性和安全性,使用此协议需要将我们的公钥放上服务器,由Git服务器进行管理(Git服务器就由gitee平台代替了,gitee平台上有地方可以配置本地服务器的公钥,等到使用ssh协议的时候再来配置)。
使用HTTPS方式时,没有任何要求,可以直接克隆下来。
HTTPS协议克隆
在执行克隆 git clone 操作时,不能在本地仓库(.git)所在的目录下执行,其他地方都可以执行:
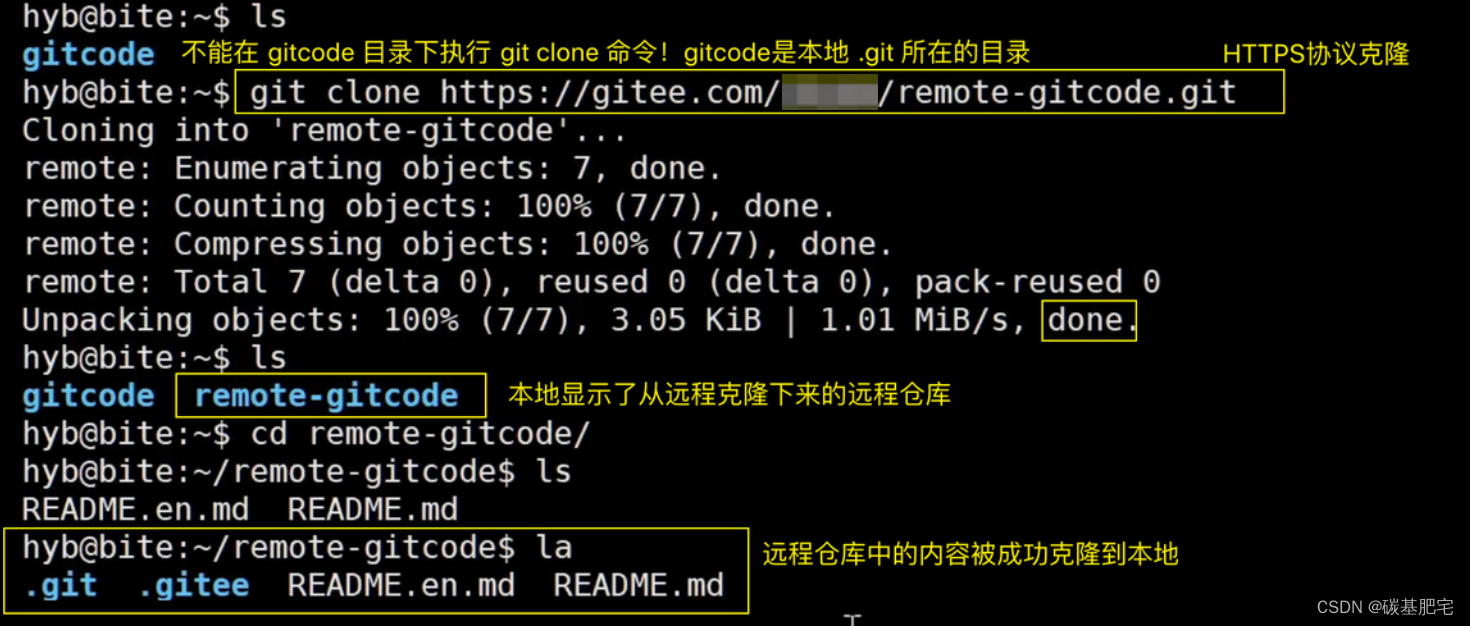
origin是远程仓库默认的仓库名,可以用 git remote 命令来查询远程仓库信息:

上面显示了可以抓取和推送的origin的地址。如果没有push / fetch权限,就看不到相应的push / fetch的地址。fetch和push表示当前本地仓库拥有对远程仓库的抓取权限和推送权限:
-
克隆远程仓库后,所有的操作是在本地来完成的,本地提交的修改如何推送到远端呢?就要使用到push权限去push远端仓库的地址
-
fetch表示抓取,如果远程仓库中存在一些本地没有的内容时,就需要去远程仓库获取新的内容,这就要使用到fech权限。
有了这两个权限,才能让本地仓库和远程仓库之间有一些交互的操作。
SSH协议克隆
SSH协议使用的是公钥加密和公钥登录的机制。
如果要使用SSH协议来进行git仓库克隆,必须要把自己本地服务器上的公钥放到git服务器上来进行管理,才可以克隆成功。
可以在设置页中查看公钥的使用情况:

在没有配置任何公钥的情况下进行SSH克隆:

使用SSH方式克隆仓库,由于我们没有添加公钥到远端库中,服务器拒绝了我们的clone链接。需要我们设置一下。
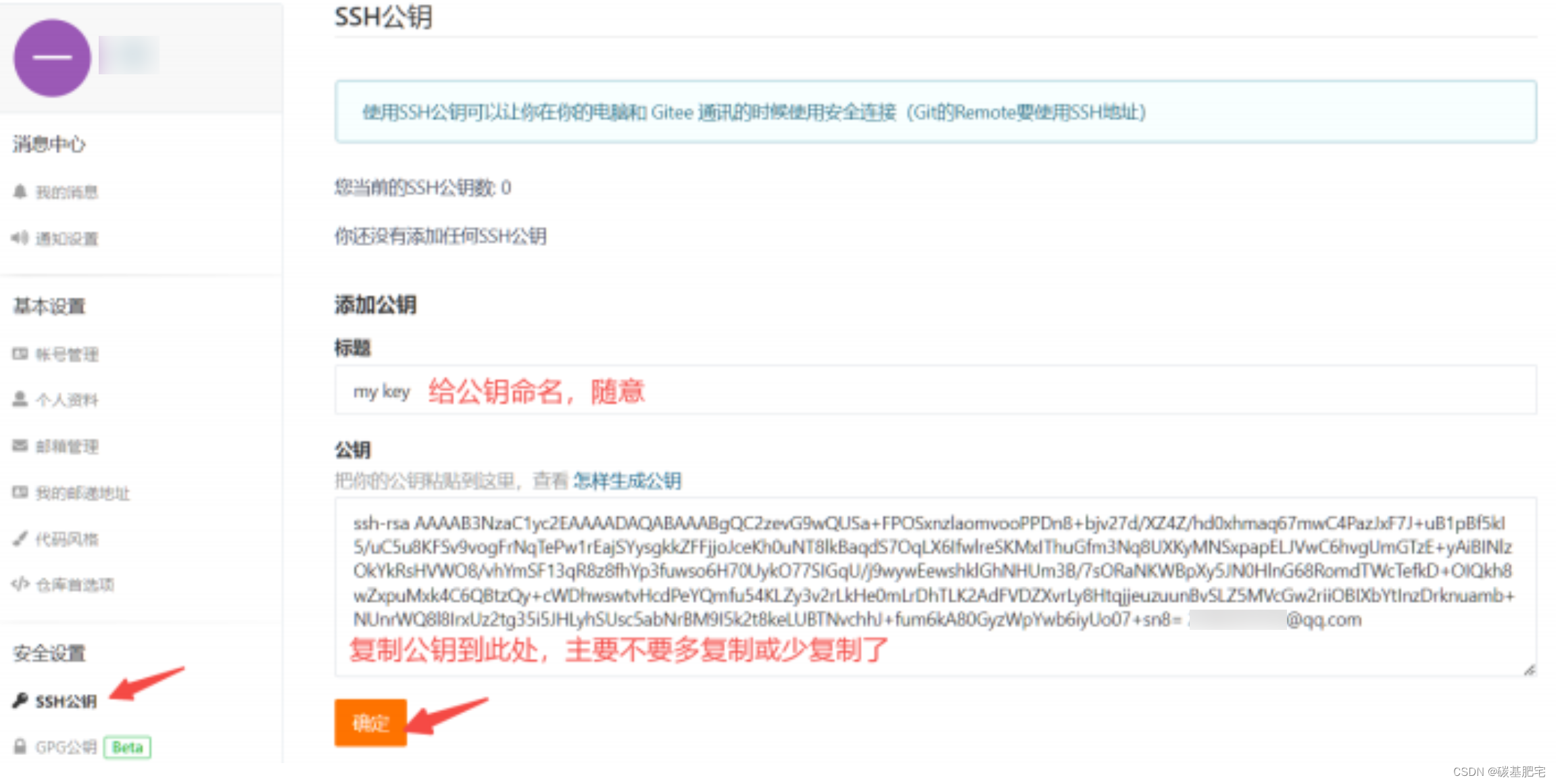
如何在本地服务器上查看公钥的内容?
首先在用户主目录(即家目录,cd ~)下,看看有没有.ssh目录,如果有,再看看这个目录下有没有id_rsa(私钥,保存在自己的服务器上,不对外展示)和id_rsa.pub(公钥)这两个文件。如果有公钥,那直接把公钥的内容复制到上面的页面中即可。

如果已经有了,可直接跳到下一步。如果没有,需要创建SSHKey。
在~目录下使用命令:
ssh-keygen -t rsa -C "<你在gitee上绑定的邮箱地址>"gitee上绑定的个人邮箱地址在设置页中查看:

此时命令就是:
ssh-keygen -t rsa -C "xxxxxxxxxx@qq.com"注意输入自己的邮箱,然后一路回车,都使用默认值即可:

此时就把我们的公钥和私钥都创建好了。可以在用户主目录里找到 .ssh 目录,里面有 id_rsa 和 id_rsa.pub 两个文件,这两个就是SSH Key的秘钥对, id_rsa 是私钥,不能泄露出去;id_rsa.pub 是公钥,可以放心地告诉任何人。

cat一下公钥,将其中的内容一字不差地复制粘贴到gitee的公钥配置页面即可。

然后添加自己的公钥到远端仓库:

配置好后可见:
点击确认后,需要对你进行认证,输入你的账号密码即可。至此,我们的准备工作全部做完,可以开始欢快地clone了~

done,成功!
如果有多个人协作开发,GitHub/Gitee允许添加多个公钥,只要把每个人的电脑上的公钥都添加到GitHub/Gitee,就可以在每台电脑上往GitHub/Gitee上提交推送了。
向远程仓库推送 push
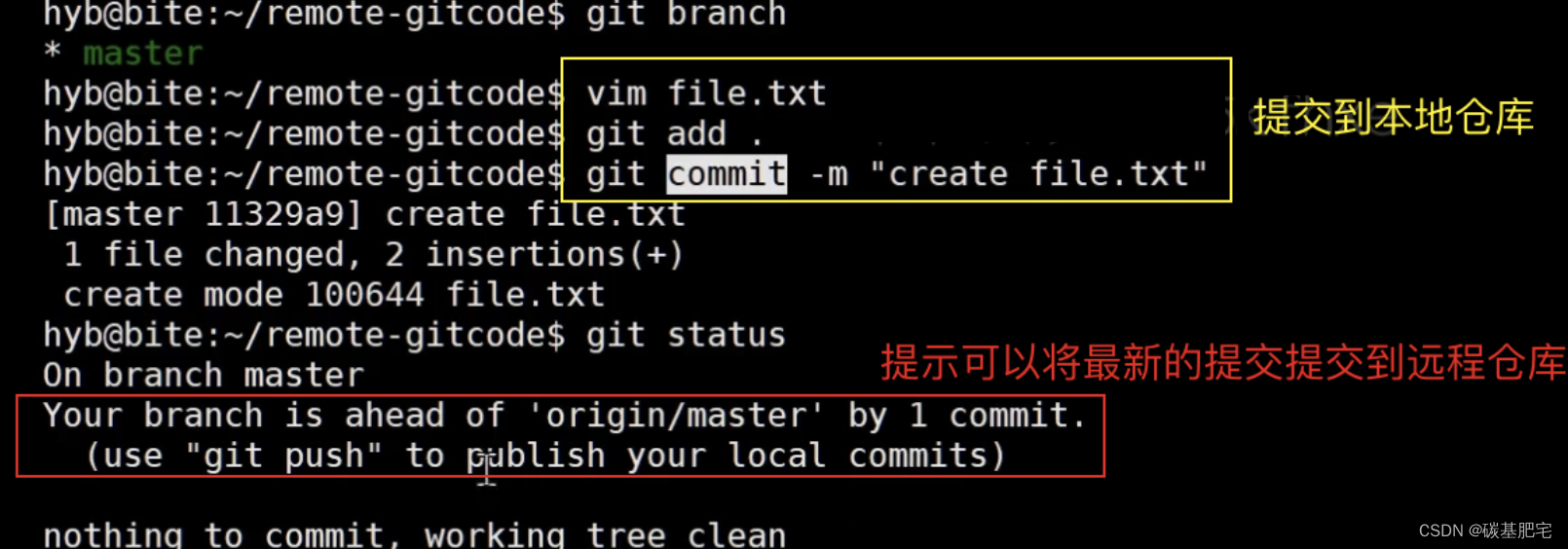
当本地仓库的内容领先于远程仓库时,就可以通过本地向远程仓库推送的方式把本地最新的修改推送上去。
将远程仓库克隆下来后,依然要先配置本地git仓库的配置项,使用 git config -l 命令:
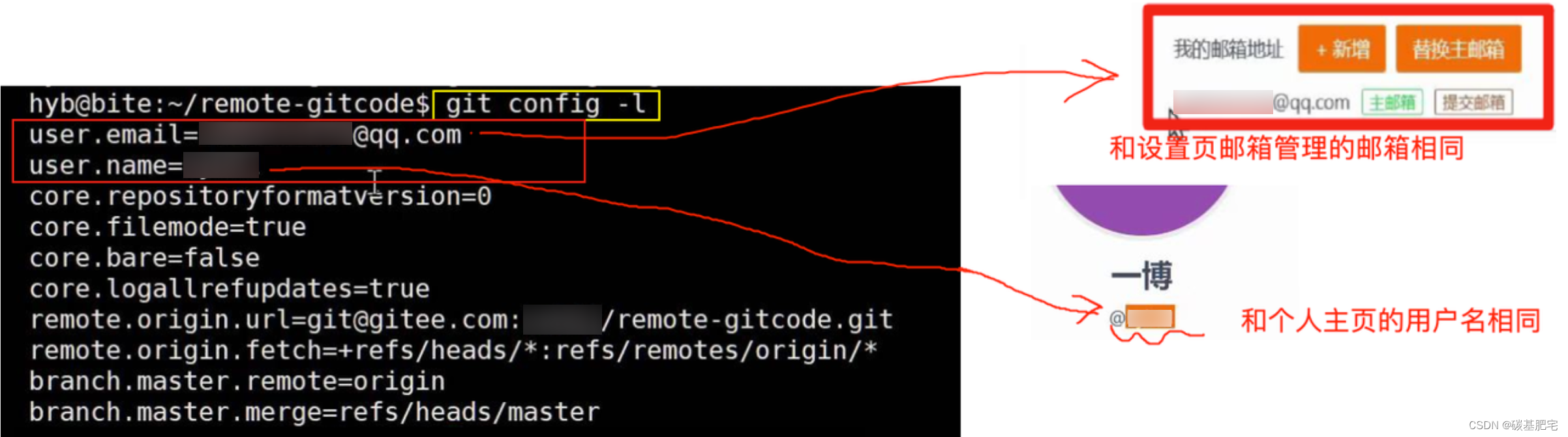
本地仓库的邮箱和用户名必须与远程仓库的邮箱用户名一致。如果之前配置过 --global 的config,那么远程仓库拉到本地时,user和email也会自动使用之前配置的global配置项。若本地的配置和远程仓库的配置不一样,则会出错;若从来没有配置过global配置项,那么克隆到本地的本地仓库是没有用户名和邮箱配置项的,第一次提交时也会报错,需要重新配置。
可直接更改:
git config --global user.email "<邮箱地址>"
git config --global user.name "<用户名>"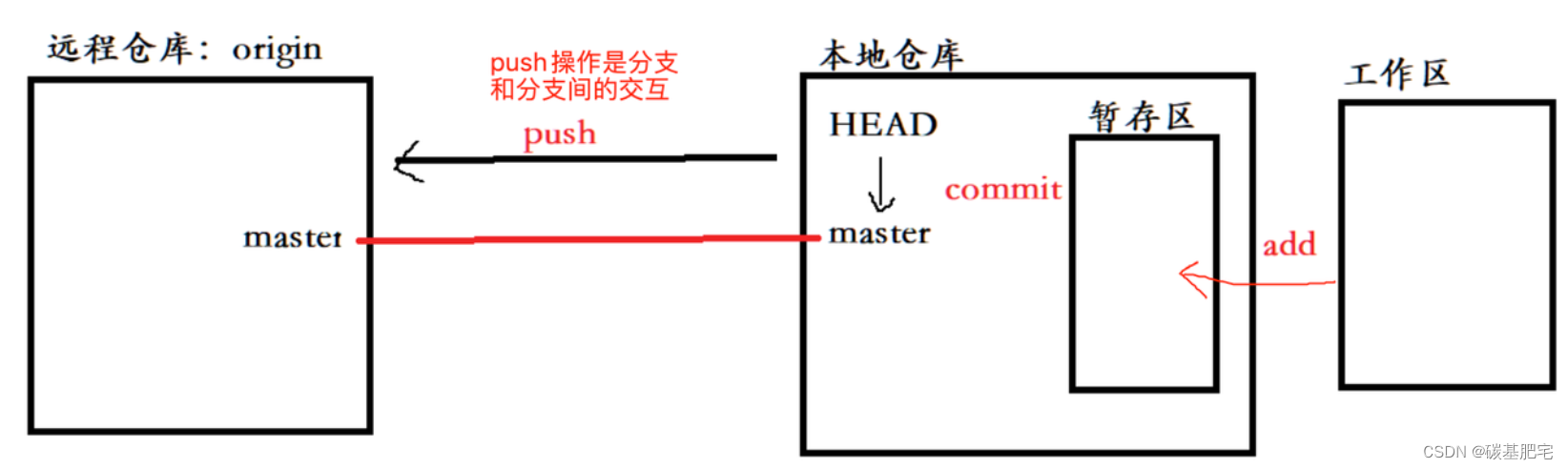
当我们从远程仓库克隆后,Git会自动把本地的master分支和远程的master分支对应起来,并且,远程仓库的默认名称是origin。
在本地我们仍然可以使用git remote命令来查看远程库的信息,或者用git remote -v显示更详细的信息。
如何把本地仓库中的修改推送到远程仓库中?
将本地仓库的内容推送至远程仓库,需要使用push命令,该命令用于将本地的分支版本上传到远程并合并,如果远程仓库下当前并没有push命令中指定的远程分支名,则会自动在远程创建。
命令格式如下:
git push <远程主机名> <本地分支名>:<远程分支名>
# 如果本地分支名与远程分支名相同,则可以省略冒号
git push <远程主机名> <本地分支名>此时我们要将本地的master分支推送到origin主机的master分支:

推送成功!这里由于我们使用的是SSH协议,是不用每一次推送都输入密码的,方便了我们的推送操作。如果你使用的是HTTPS协议,有个麻烦地方就是每次推送都必须输入口令。
接下来看码云远端,就能看到本地的代码已经被推送上来了。
拉取远程仓库
当远程仓库的内容领先于本地仓库时,可以通过拉取远程仓库来把远程仓库的修改拉取到本地。
使用 pull 命令。
注意:不要直接在远程仓库更改任何的代码,如果要改,也要在本地改完再推送上去。
这里用于模拟远程仓库内容领先于本地仓库的情况:
1、在gitee上点击README.md文件并在线修改它。

2、修改内容。
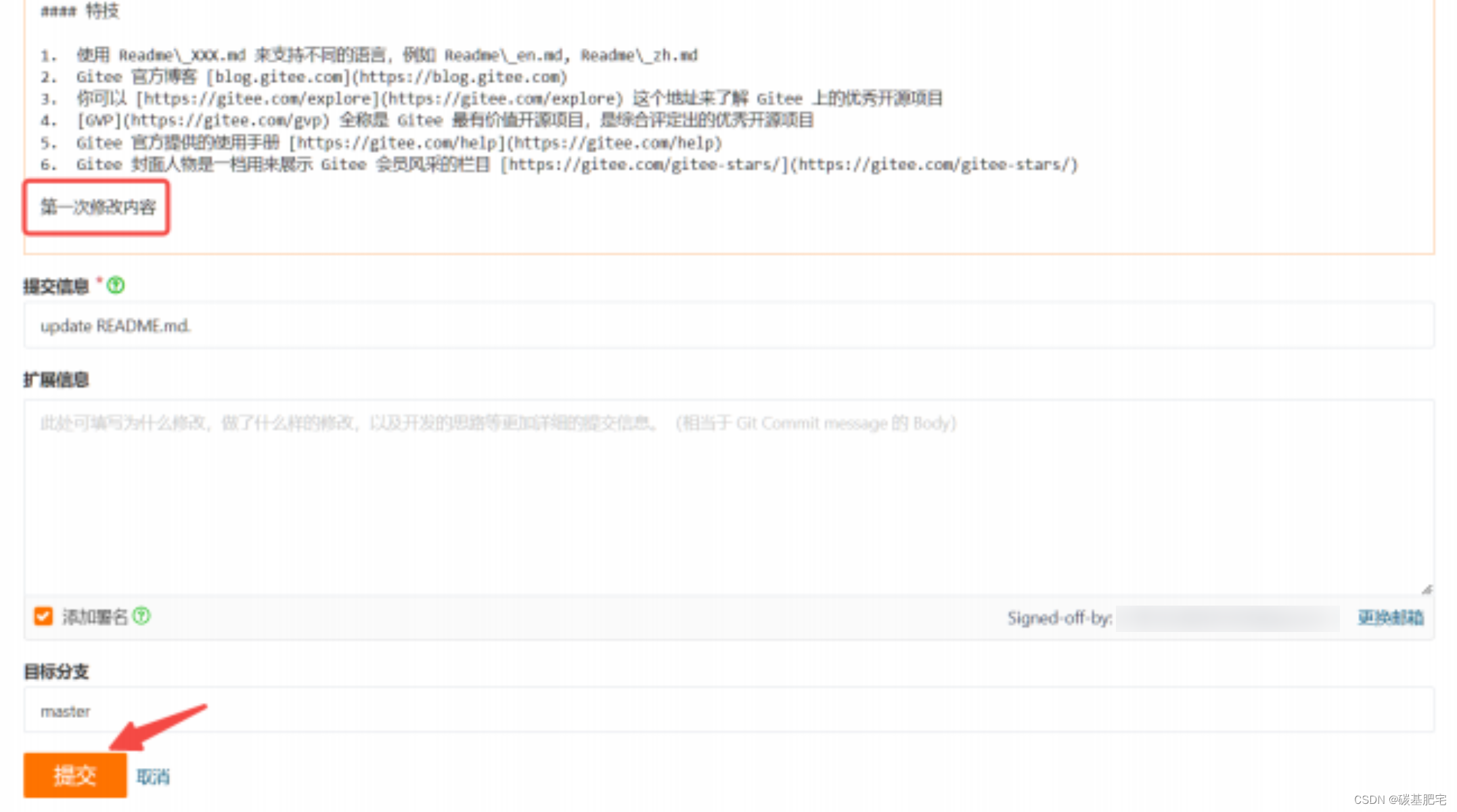
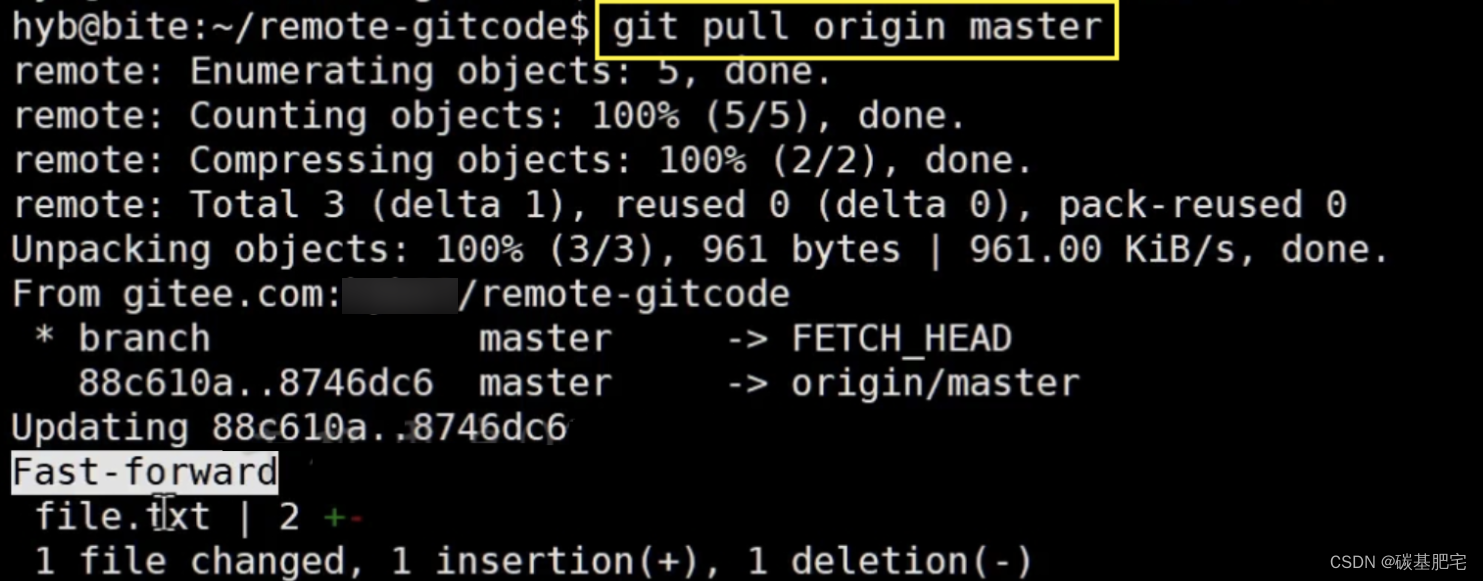
此时,远程仓库是要领先于本地仓库一个版本,为了使本地仓库保持最新的版本,我们需要拉取下远端代码,并合并到本地。
git pull命令会从远程仓库获取更新,并自动将这些更新合并到当前所在的本地分支。【pull等于拉取+合并】
当运行 git pull 时,它其实执行了两个操作:git fetch 和 git merge。
首先,它使用 git fetch 从远程仓库获取最新的提交和文件,并将这些更新存储在本地的远程跟踪分支中(例如origin/main(远程跟踪分支的名称由远程仓库名和分支名组成,它们用斜杠 / 分隔))。
接着,它自动使用 git merge 将远程跟踪分支的内容合并到当前所在的本地分支。
Git提供了命令,该命令用于从远程获取代码并合并本地的版本。格式如下:
git pull <远程主机名> <远程分支名>:<本地分支名>
# 如果远程分支与当前分支名称相同,则冒号后面的部分可以省略。
git pull <远程主机名> <远程分支名>
同名分支对应关系时冒号可以省略:如果你当前的本地分支与远程分支存在同名且已经建立了追踪关系,那么可以直接执行 git pull,Git 会自动识别并拉取对应的远程分支。例如:
如果你当前在本地的 master 分支上,并且要拉取远程仓库的 origin/master 分支,那么可以省略冒号的使用。
通常情况下,如果没有指定远程仓库和分支,则会将与当前本地分支相关联的远程分支合并到本地分支。
如果你不在 dev 分支上,也可以使用以下方式在不用切换到dev分支的前提下就能将远程 origin 的 dev 分支到本地的 dev 分支上。
git pull origin dev:dev3.配置Git
忽略特殊文件
在日常开发中,我们有些文件不想或者不应该提交到远端,比如保存了数据库密码的配置文件。
那怎么让Git知道呢?在Git工作区的根目录下创建一个特殊的.gitignore文件,然后把要忽略的文件名填进去,Git就不会追踪管理这些文件了。
不需要我们自己从头写.gitignore文件,gitee在创建仓库时就可以为我们生成。在创建git仓库时,有一个初始化仓库的选项,里面有一个“添加 .gitignore模板”:
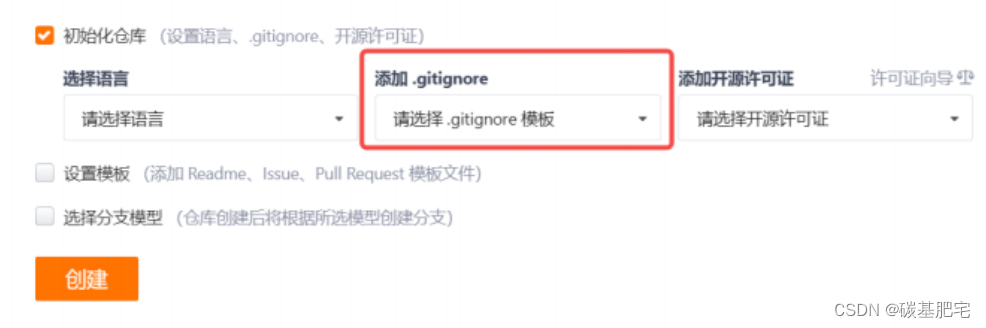
当然,如果我们要写的是Java程序,那么就可以选择Java的.gitignore文件模板。
选择完毕后点击创建,就会在仓库中自动生成一个.gitignore文件,并且文件中的内容会根据我们所选的模板来进行初始化。
如果当时创建仓库的时候没有选择.gitignore文件模板,那么自己在工作区创建一个也是可以的。
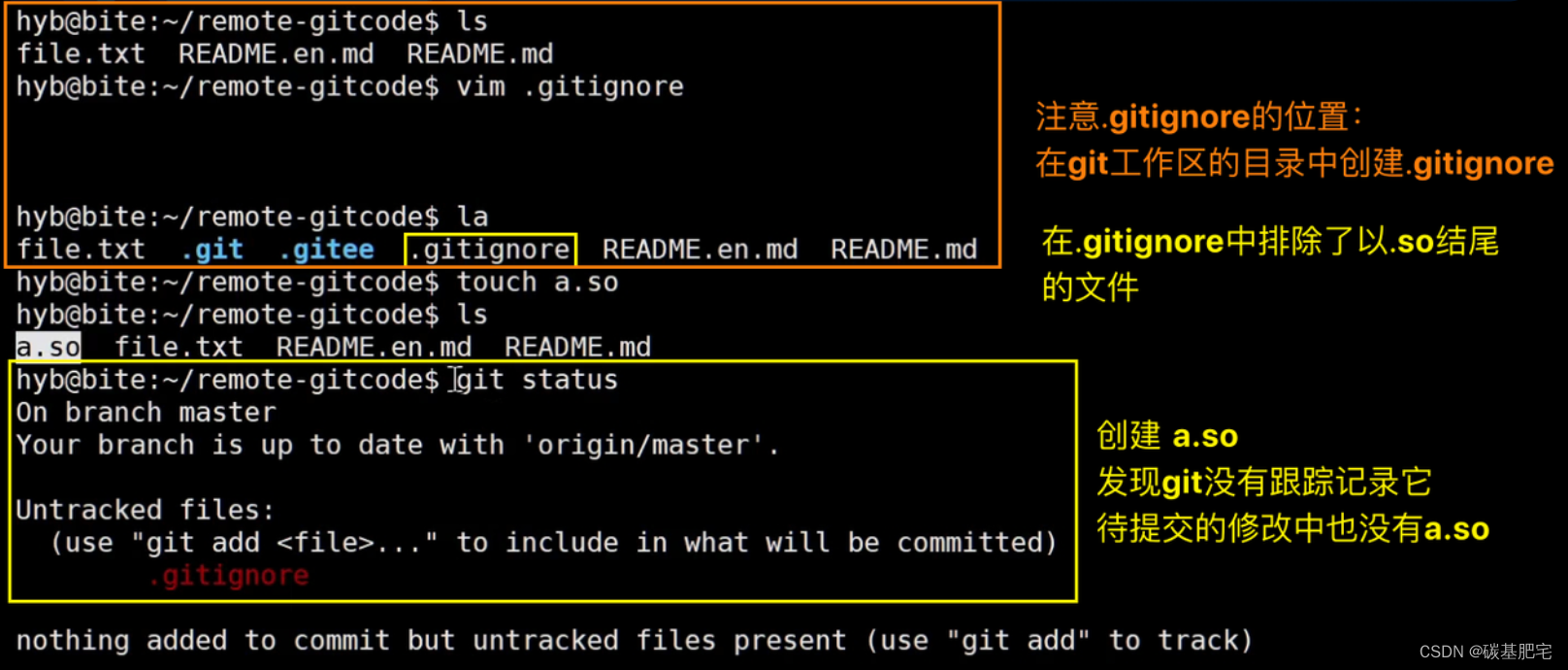
例如我们想忽略以 .so 和 .ini 结尾所有文件,.gitignore 的内容如下:
#省略选择模本的内容
...
# Myconfigurations:
# 可以直接写文件名(指定某个确定的文件),也可以用通配符
*.ini
*.so检验 .gitignore 的标准是 git status 命令是不是说 working tree clean 。我们发现Git 并没有提示在工作区中有文件新增,说明 .gitignore 生效了:

以下的演示中,.gitignore文件是本地新创建的,还没有commit或推送给远端,因此它本身的修改也会被记录,就没有显示working tree clean了。
但有些时候,你就是想添加一个文件到 Git,但由于这个文件被 .gitignore 忽略了,根本添加不了怎么办呢?
1、方法一
可以在add时加上 -f 选项进行强制add:
git add -f b.so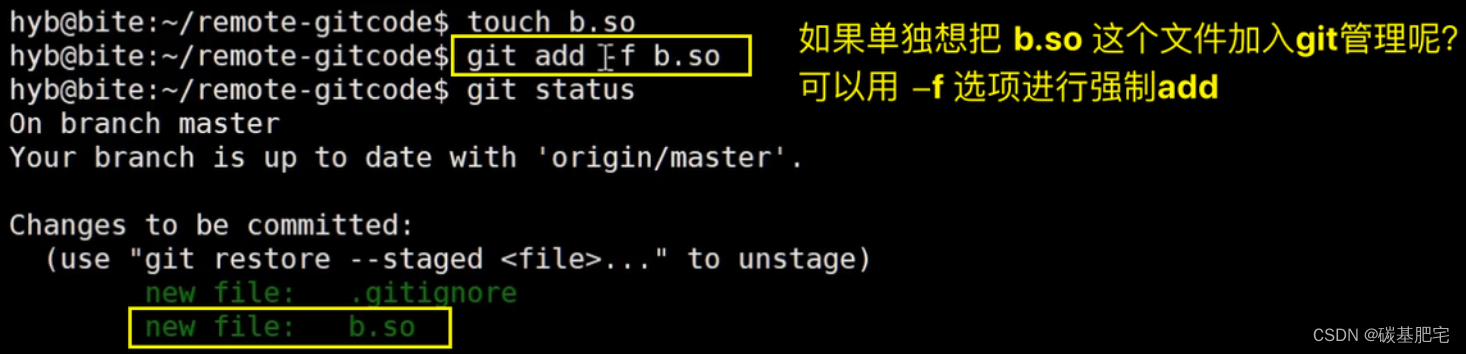
但不建议使用这种方式,因为最好不要违背.gitignore文件中的配置。
2、方法二
有些时候,当我们编写了规则排除了部分文件时,比如.*,但是我们发现 .* 这个规则把 .gitignore 也排除了。此时不想更改.gitignore规则又要做到不把.gitignore排除,可以在.gitignore文件中编辑规则:

把指定文件排除在 .gitignore 规则外的写法就是 ! +文件名,所以,只需把例外文件添加进去即可。

Changes to be commited:已经add了,提示需要commit
Changes not staged for commit:曾经已经提交过的文件,已经被git管理了,然后再去修改就会有这个提示。
Untracked files:新建的文件,git还未追踪管理它
如果一个文件没有被git管理,但又忘记是否存入.gitignore中,可以使用命令进行ignore规则检查:
git check-ignore -v <文件名>来查看原因。

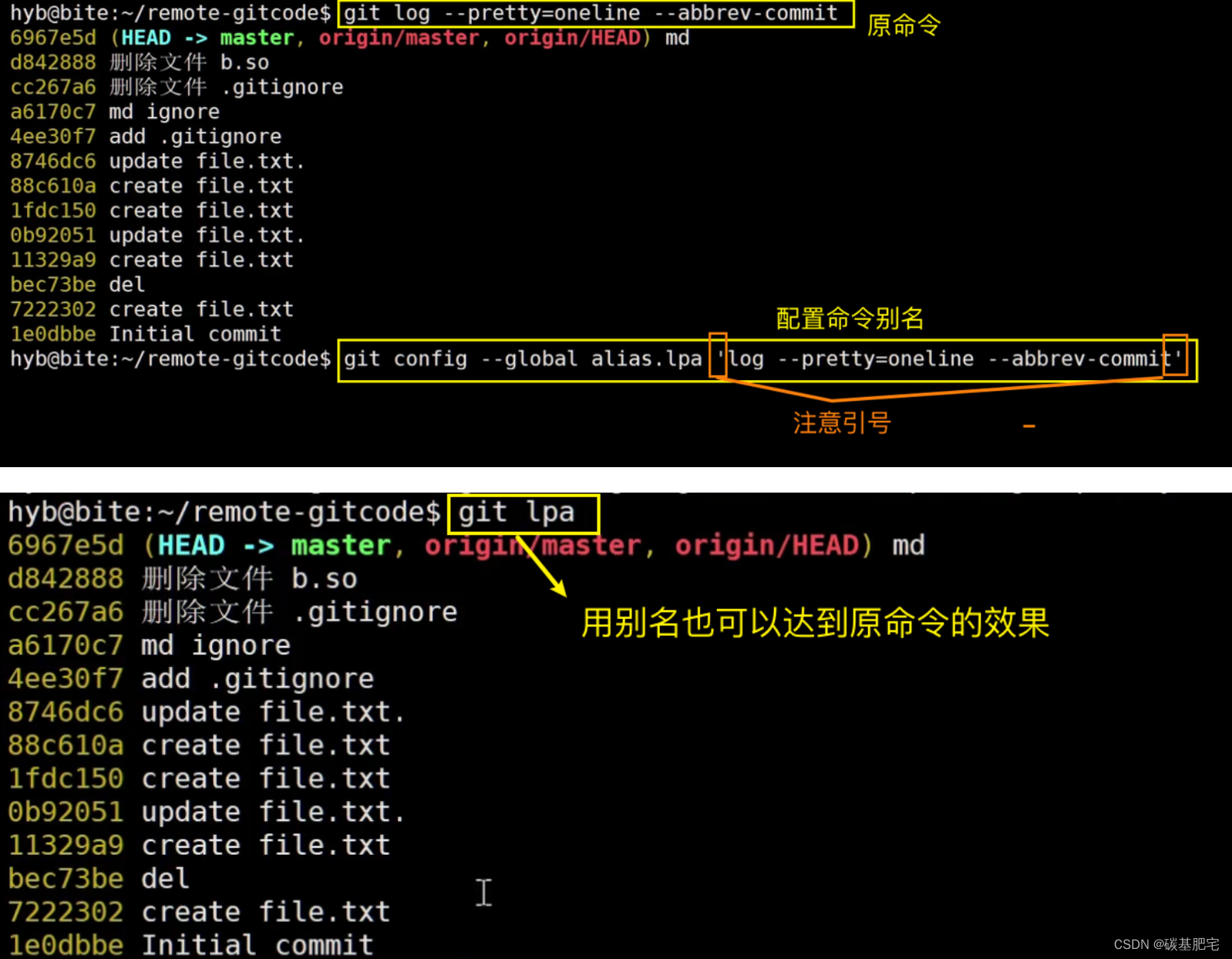
给命令配置别名
我们可以通过
git config [--global] alias.别名 原命令名的方式来给git命令配置别名。
如将 git status 简化为 git st ,对应的命令为:
git config --global alias.st status--global参数是全局参数,也就是这些命令在这台电脑的所有Git仓库下都有用。如果不加,那只针对当前的仓库起作用。

再来将git log -l配置为 git last ,让其显示最后一次提交信息:
git config --global alias.last 'log -1'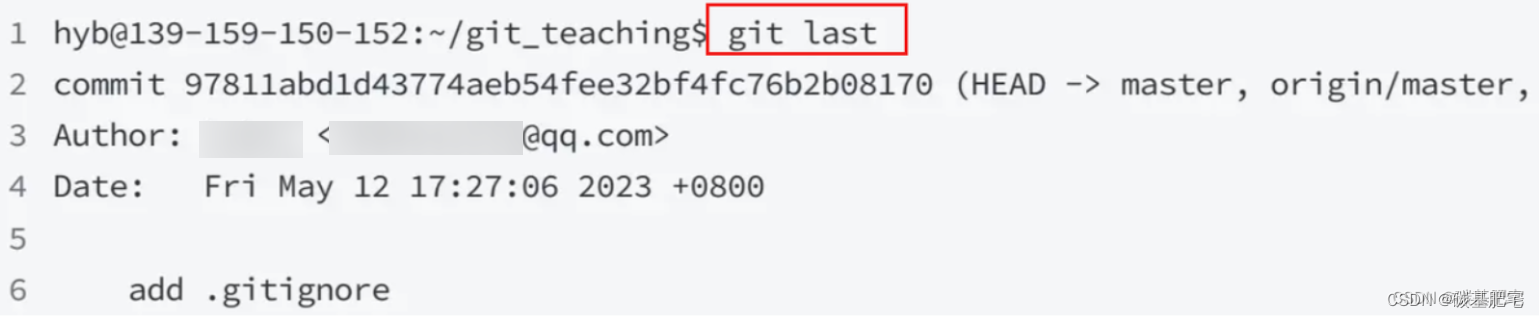
再将查看提交日志(--pretty=oneline意思是以一行的格式打印, --abbrev-commit意思是只打印commit id的前几位数)
git log --pretty=oneline --abbrev-commit这一命令配置为更为简短的git lpa:
不过还是不推荐大家太早去使用它,还是应当所有的Git命令都手动输入,以尽快熟悉Git。
**小结
本篇涉及的部分git命令:
git cat-file -p <commit ID>:查看提交信息
git branch:显示当前所有分支
git branch <分支名>:创建分支
git checkout <分支名>:切换分支
git merge <分支名>:合并分支
git checkout <分支名>:切换分支
git branch -d <分支名>:删除分支(非强制)
git branch -D <分支名>:删除分支(强制)
git checkout -b <分支名>:创建并切换分支
git log --graph --abbrev-commit:查看分支合并情况
git stash:储藏工作区内容
git stash list:查看stash存放哪些内容
git stash pop:恢复工作区内容
git clone:克隆远程仓库
git push:将本地的分支版本上传到远程并合并
git fetch:从远程仓库获取最新的提交和文件
**下篇内容
七、标签管理
八、多人协作
九、企业级开发模型









064:添加字符065:数组变换066:装箱问题](https://img-blog.csdnimg.cn/direct/6dc326485bb246f2bb9225f22ce39a23.png)