文章目录
- 前言
- 链表
- 简介
- 头节点与尾节点
- 特性
- 分类
- 单向链表
- 双向链表
- 循环链表
- 单链表基本操作
- 定义并初始化单链表
- 读取节点
- 插入节点
- 删除节点
- 修改节点
- 参考资料
- 写在最后
前言
本系列专注更新基本数据结构,现有以下文章:
【算法与数据结构】数组.
【算法与数据结构】链表.
【算法与数据结构】哈希表.
链表
简介
链表是一种线性结构,但不同于数组在内存中占据一块连续的内存,链表使用的是内存中一组任意的存储单元来存储具有相同的数据类型的元素。这组任意的存储单元可以是连续的,也可以不是连续的。
以单链表为例,链表的存储方式如下图所示。

链表将一组任意的存储单元串联在一起。每一个存储单元被称为链表的一个节点,节点是一个结构体。结构体内存储两个变量,一个是节点的值,另一个是指向链表下一个节点的指针。一个节点值为整型的链表结构体可以这样定义:
struct ListNode {
int val;
ListNode* next;
}
头节点与尾节点
链表的头节点指的是链表的第一个节点(有的资料中将第一个元素之前的节点称为头节点,就是我们会面要讲到的呀节点),通常给一个链表的头节点,我们就可以通过遍历得到链表中的每一个节点。这里需要区分一下头节点与头指针。
头指针是指向链表第一个节点的指针。在单向链表中,头指针指向链表的头节点,就是后面会提到的呀节点的next指针,即 dummy->next。在双向链表中,头指针同样指向链表的头节点。
链表的尾节点是指链表中最后一个节点。在单向链表中,尾节点的 next 指针通常指向空指针 nullptr,表示链表的末尾。在双向链表中,尾节点的 next 指针同样指向空指针 nullptr,而 prev 指针则指向倒数第二个节点,表示双向链表的末尾。
特性
链表不需要实现事先分配内存,在需要存储空间时可以临时申请。因为链表不需要内存中一块连续的存储空间,所以相比数组可以更好的利用内存中零散的空间。相比于数组,使用链表执行数据的插入、删除以及移动效率会高一点。但是空间开销相比数组会大一点,因为链表的每一个节点需要存储两个变量,而数组的每个位置只需要存储一个变量。
分类
单向链表
定义
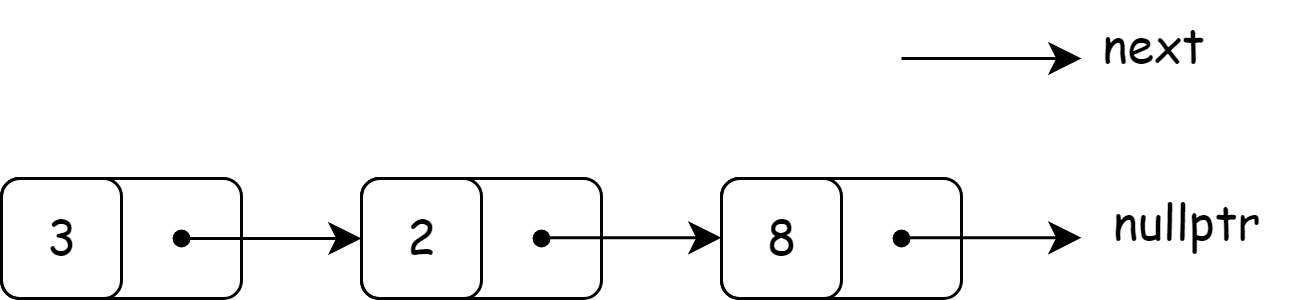
单向链表指的是链表的每一个节点里的指针都会指向下一个节点的链表。
单向链表节点类设计如下所示, C++11 \texttt{C++11} C++11 的标准库中虽然也定义了 forward_list \texttt{forward\_list} forward_list 单向链表,但因为单向链表的定义与操作相对简单,所有我们通常自己定义节点。
struct ListNode {
int val;
ListNode* next;
ListNode() : val(0), next(nullptr) {}
ListNode(int x) : val(x), next(nullptr) {}
ListNode(int x, ListNode* _next) : val(x), next(_next) {}
};
结构图
双向链表
定义
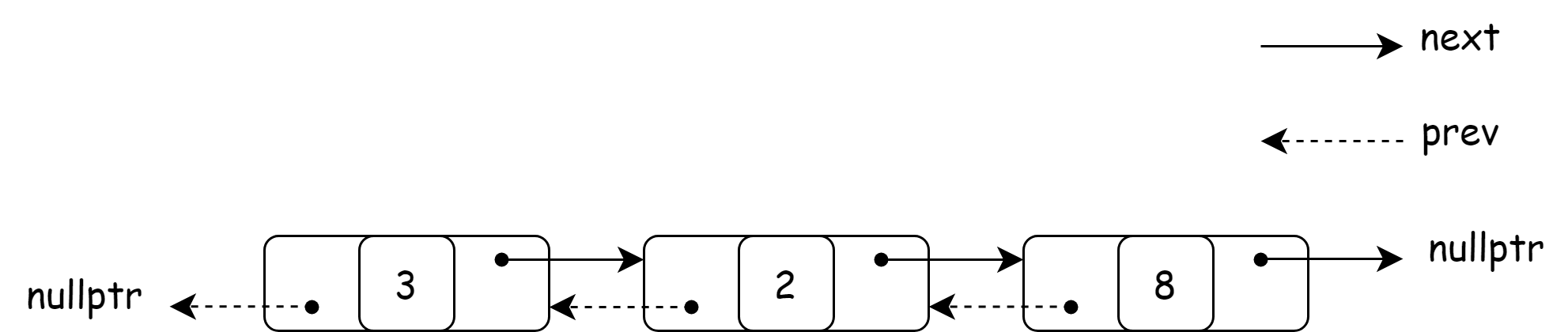
双向链表是对单向链表的升级,除了具备单向链表的 next 节点之外,还有一个 prev 指针,该指针指向当前节点的上一个节点。头节点的上一个节点为 nullptr 节点,尾节点的下一个节点为 nullptr。
双向链表的节点类设计如下所示。 C++11 \texttt{C++11} C++11 的标准库中虽然也定义了 list \texttt{list} list 双向链表.
struct ListNode {
int val;
ListNode* next;
ListNode* prev;
ListNode() : val(0), next(nullptr), prev(nullptr) {}
ListNode(int x) : val(x), next(nullptr), prev(nullptr) {}
ListNode(int x, ListNode* _next, ListNode* _prev) : val(x), next(_next), prev(_prev) {}
};
结构图
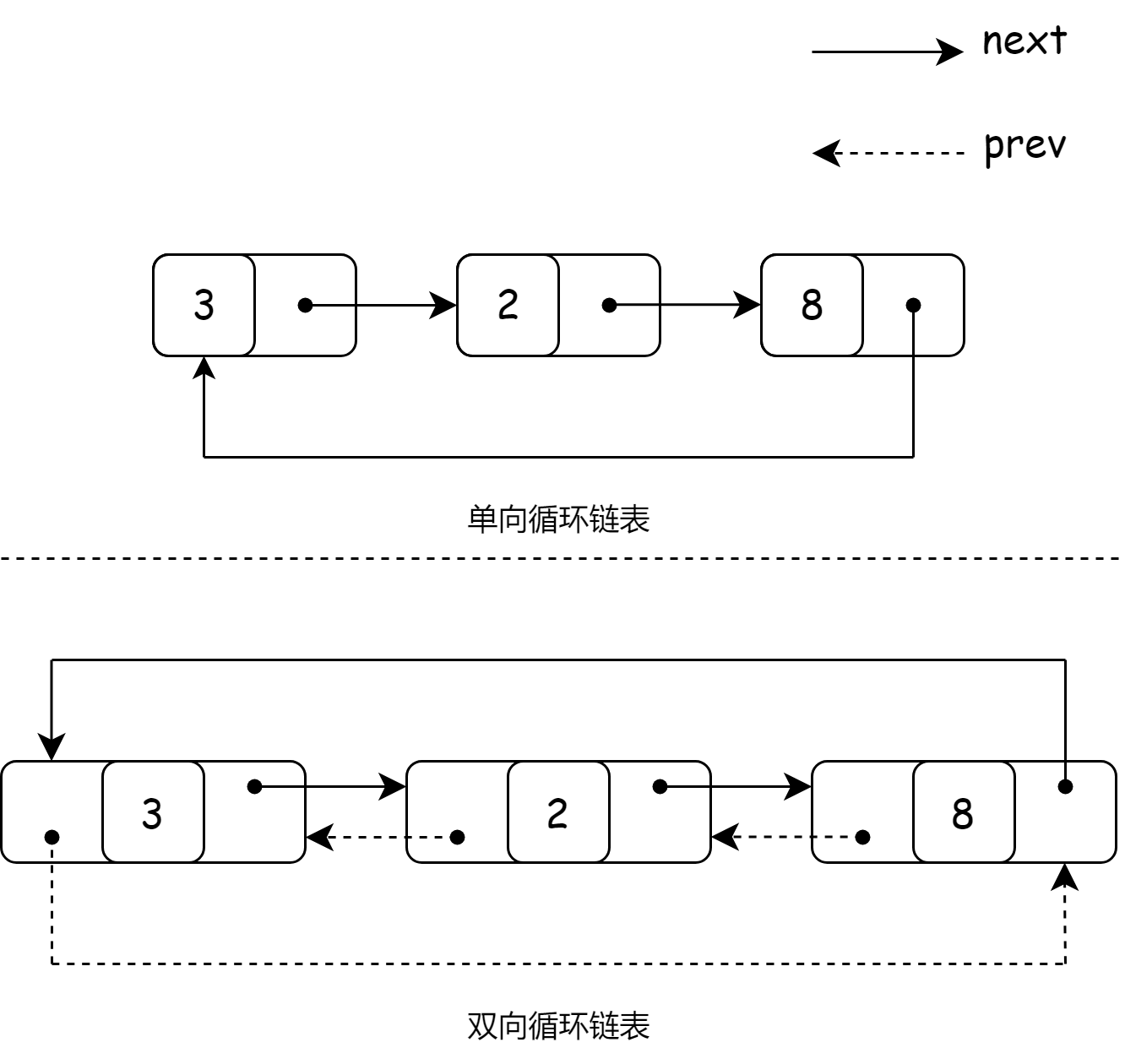
循环链表
定义
循环链表有两种,一种是在单向链表中将尾节点的 next 指针指向由空指针改为指向头节点形成的单向循环链表,另一种指的是双向循环链表。
双向循环循环链表是在双向链表的基础上,将链表的头节点和尾节点连接在一起,即将头节点的 prev 指针指向尾节点,尾节点的 next 指针指向头节点。通过这样的操作可以实现从循环链表的任何一个节点出发都能找到其他的任意节点。
循环链表的节点类设计与双向链表的节点类设计一致。
结构图
单链表基本操作
链表是一种具有增、删、改、查这四种基本操作的基本数据结构。单链表作为一种形式最简单的链表自然也具备这四种操作。本节会介绍定义并初始化单链表以及提到的四种基本操作,中间还会穿插介绍如何计算链表的长度。
在这单向链表、双向链表和循环链表中,单向链表最为基础,并且是算法类面试题中链表这一块的考察重点,需要重点掌握。
定义并初始化单链表
// 定义节点
struct ListNode {
int val;
ListNode* next;
ListNode() : val(0), next(nullptr) {}
ListNode(int x) : val(x), next(nullptr) {}
ListNode(int x, ListNode* _next) : val(x), next(_next) {}
};
// 定义链表头节点
ListNode* head = new ListNode(0);
在此例子中,我们首先定义了链表的节点类,然后定义了一个节点 head 作为链表的头节点,头节点的 next 指针指向一个空节点。
读取节点
在数组这种顺序结构中,我们计算任意一个元素的存储位置是很容易的(C/C++ 中虽然是通过下标进行索引的,但其底层是通过数组的首地址与下标之间的计算获得对应位置的地址,再取地址中的元素)。但是在单链表中我们无法像数组那样通过索引得知第 N 个节点是什么,只能从头节点开始一个节点一个节点的查找。
获得链表的第 N 个节点(N >= 1 )的算法思路:
- 在查找链表的第
N个节点之前需要先统计链表中的节点总数,如果总数cnt < N,则直接返回nullptr,否则接着执行以下步骤。 - 声明一个指向链表头节点的节点
cur,使用 for 循环或者 while 循环(迭代),将节点向后移动N-1次(将 cur 更新为 cur->next)。 - 循环结束后,返回
cur即为需要查找的节点。
// 计算以 head 为头节点的链表的节点数
int getN(ListNode* head) {
int cnt = 0;
while (head != nullptr) {
++cnt;
head = head->next;
}
return cnt;
}
ListNode* getNthNode(ListNode* head, int N) {
int cnt = getN(head);
if (N > cnt) {
return nullptr;
}
ListNode* cur = head;
while (N > 1) {
cur = cur->next;
}
return cur;
}
在此例子中,我们使用函数 getN 计算链表的长度(节点的数量)。我们从链表的头节点开始遍历链表,只要当前的链表不为空(nullptr),就更新 cnt = cnt + 1,并更改 head 为下一个节点。
插入节点
在给定链表中的指定位置插入一个节点,需要考虑以下几个问题:
- (1)给定的链表是否为空;
- (2)指定位置是否越界;
- (3)指定的位置位于链表的头部、中间还是尾部。
如果给定的链表为空,则直接返回新插入的节点;如果指定的位置越界,直接返回给定链表的头节点即可。对于问题(3)中的三种情况,我们逐条进行分析。
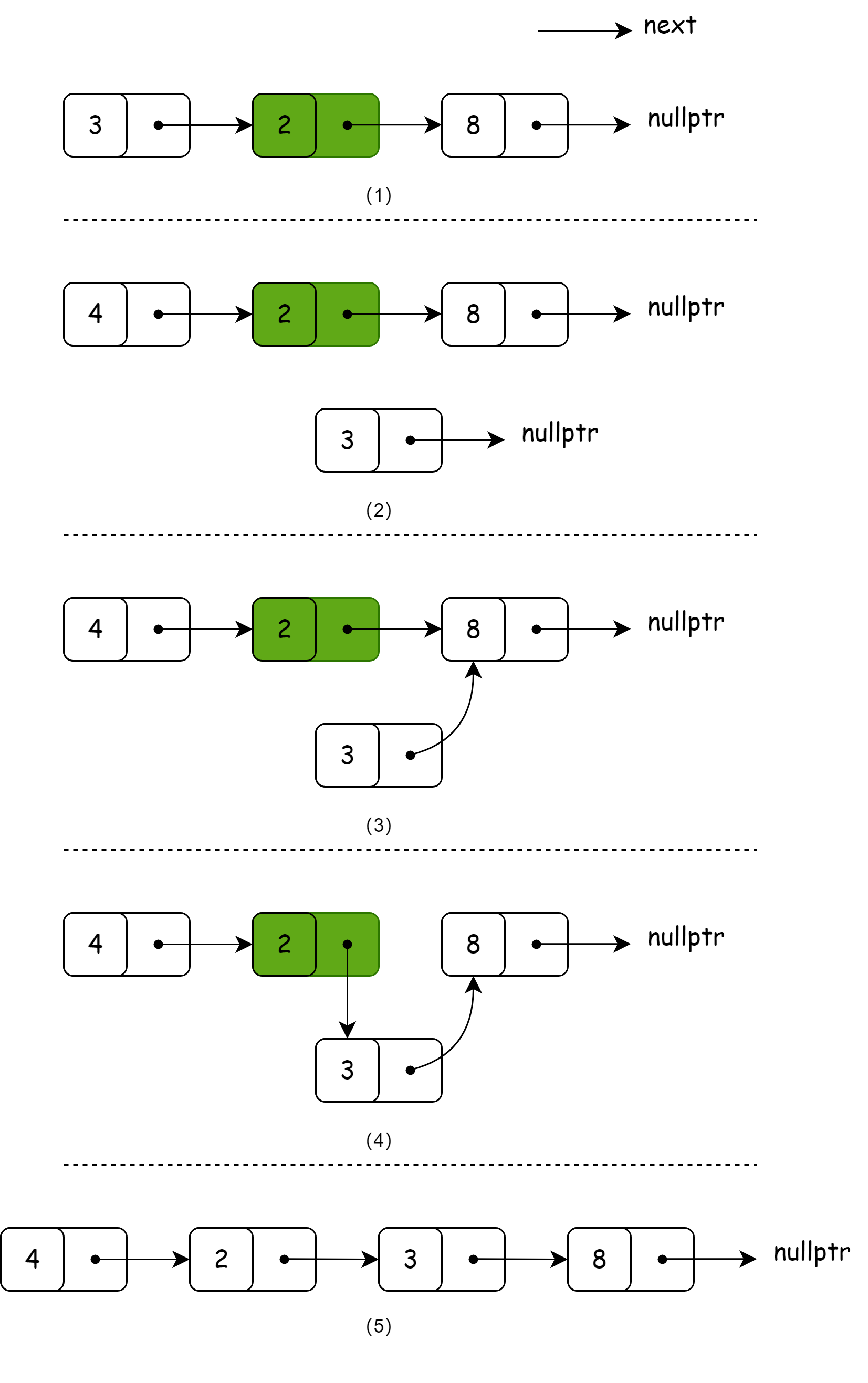
在链表中间插入元素
顾名思义,插入节点的位置位于链表的中间位置,在链表第 i 个位置(头节点被称为第一个位置)之前插入值为 val 的链节点,通常:
- (1)遍历链表找到第
i-1个节点preNode; - (2)新建需要插入的节点
newNode; - (3)将节点
newNode的 next 指针连接到(指向)preNode节点的下一个节点; - (4)将节点
preNode的 next 指针连接到newNode节点; - (5)最后返回头节点
head。
一图胜千言,上述变换过程见下图所示:
在链表头部插入节点
在链表头部插入节点更加简单:
- 新建需要插入的节点
newNode; - 将节点
newNode的 next 指针连接到(指向)head节点,newNode作为链表新的头节点。
在链表尾部插入元素
遍历找到链表的最后一个节点,将该节点的 next 指针指向新建的节点 newNode 即可。
总结
下面就是一个往给定链表中指定位置插入一个元素的示例:
ListNode* insertNode(ListNode* head, int pos, int newVal) {
// 问题(1)
if (head == nullptr) {
return new ListNode(newVal);
}
// 问题(2)
int N = getN(head); // 获取链表长度
if (pos < 0 || pos > N+1) { // 注意这里的 大于 N+1 是考虑到要在尾部插入节点
return head;
}
// 问题(3)
ListNode* cur = head;
int i = 1;
while (i < pos-1) { // 找到第 pos 个节点后退出循环
cur = cur->next;
++i;
}
ListNode* newNode = new ListNode(newVal);
// 在链表头部插入节点
if (cur == head) {
cur->next = head;
return newNode;
}
// 在链表中间或尾部插入节点
newNode->next = cur->next; // 当在在链表尾部插入节点时,此时 cur->next = nullptr
cur->next = newNode;
return head;
}
Note:以上代码中 在链表中间插入元素 是在链表的第
i个位置之前插入节点,如果是在第i个位置之后插入节点,代码会有细微的变换,请读者注意。
删除节点
删除链表中的节点与插入节点操作一样都需要考虑一下三个情况:
- 待删除的链表为空;
- 删除的节点是非法的(越界);
- 删除的节点分别位于链表的头部、中间位置或者尾部。
以下以图解的形式对第三种请款进行说明。前两种情况比较简单,将直接在代码中进行展示。
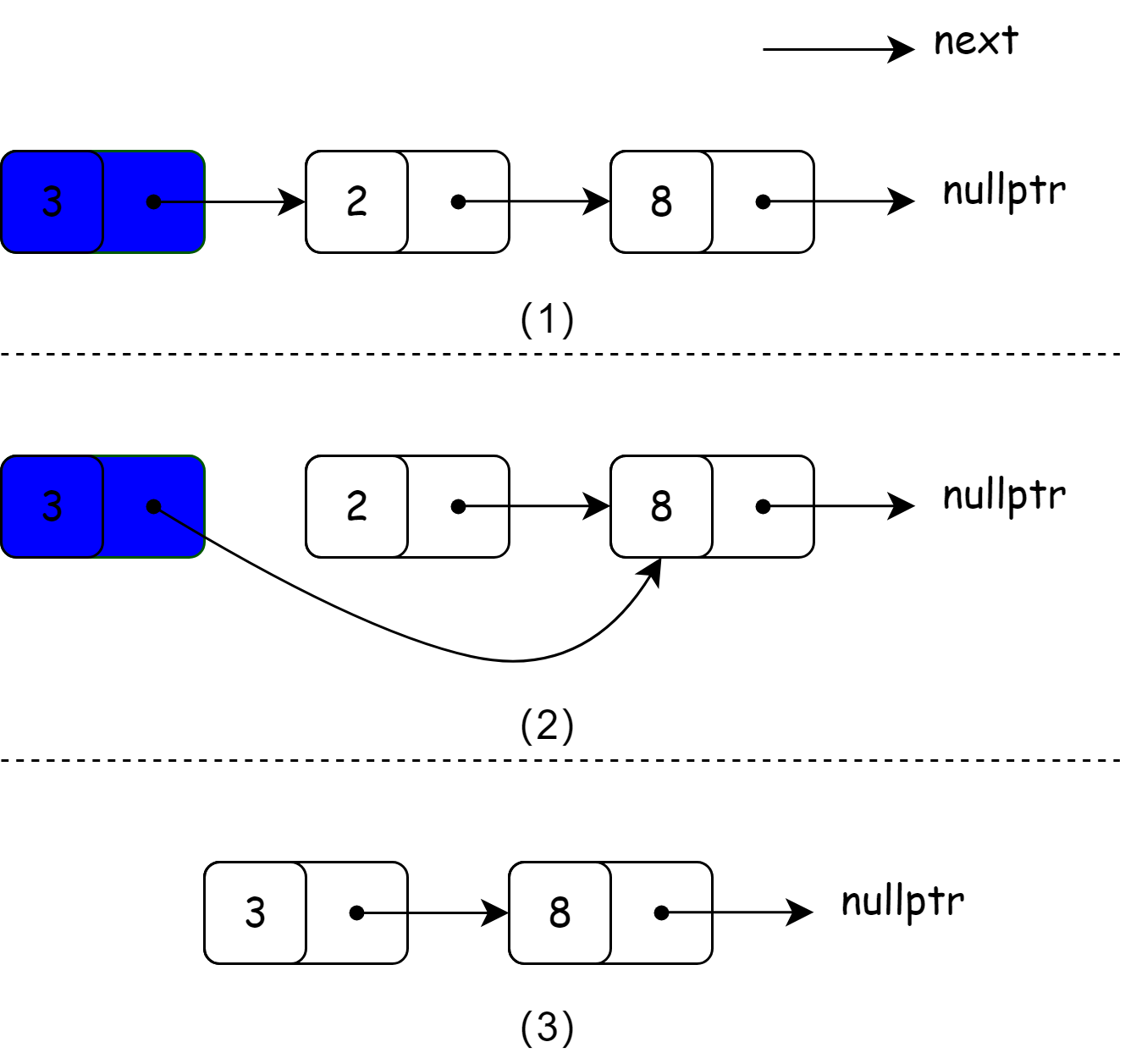
(1)删除链表中间位置的节点需要先找到被删除节点的上一个节点 `prevNode;
(2)将 prevNode 的 next 指针指向 prev->next->next;
(3)最后得到删除的链表。
示例代码
ListNode* removeNode(ListNode* head, int pos) {
// 链表为空
if (head == nullptr) {
return nullptr;
}
// 删除的节点是非法的
int N = getN(head); // 获取链表长度
if (pos < 0 || pos > N) {
return head;
}
// 情况三
ListNode* preNode = head;
int i = 1;
while (i < pos-1) { // 找到第 pos 个节点后提出循环
preNode = preNode->next;
++i;
}
// 删除头节点
if (preNode == head) {
return preNode->next;
}
// 删除链表中间或尾部的节点
preNode->next = preNode->next->next;
return head;
}
修改节点
修改主要指的是修改节点的值。比如将第 i 个节点的值修改为指定值 val。思路清晰直接看代码:
void modifyNthVal(ListNode* head, int n, int val) {
if (head == nullptr) {
return;
}
int N = getN(head); // 获取链表长度
if (n < 0 || n > N) { // 越界
return;
}
ListNode* cur = head;
while (--n) {
cur = cur->next;
}
cur->val = val;
}
参考资料
【书籍】大话数据结构
【文章】一文讲透链表操作,看完你也能轻松写出正确的链表代码
【文章】链表基础知识
写在最后
如果您发现文章有任何错误或者对文章有任何疑问,欢迎私信博主或者在评论区指出 💬💬💬。
如果大家觉得有些地方需要补充,欢迎评论区交流。
next;
}
cur->val = val;
}
# 参考资料
【书籍】大话数据结构
【文章】[一文讲透链表操作,看完你也能轻松写出正确的链表代码](https://www.cnblogs.com/lonely-wolf/p/15761239.html)
【文章】[链表基础知识](https://algo.itcharge.cn/02.Linked-List/01.Linked-List-Basic/01.Linked-List-Basic/)
---
# 写在最后
如果您发现文章有任何错误或者对文章有任何疑问,欢迎私信博主或者在评论区指出 💬💬💬。
如果大家觉得有些地方需要补充,欢迎评论区交流。
最后,感谢您的阅读,如果有所收获的话可以给我点一个 👍 哦。

064:添加字符065:数组变换066:装箱问题](https://img-blog.csdnimg.cn/direct/6dc326485bb246f2bb9225f22ce39a23.png)