1 介绍
- pipeline() 是使用预训练模型进行推理的最简单和最快速的方式。
- 可以针对不同模态的许多任务直接使用 pipeline()
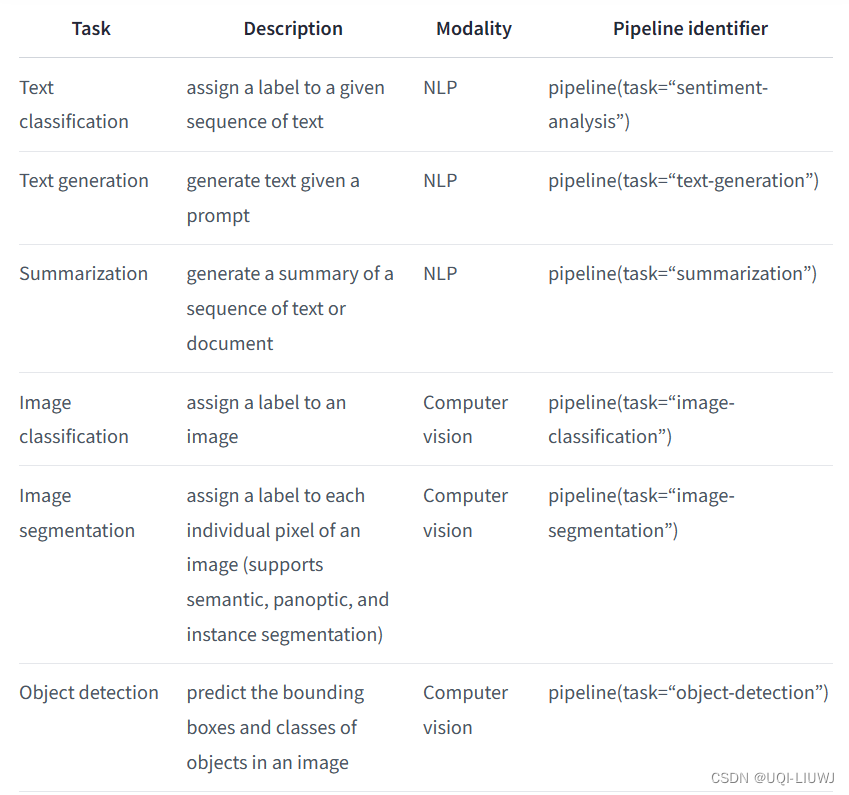
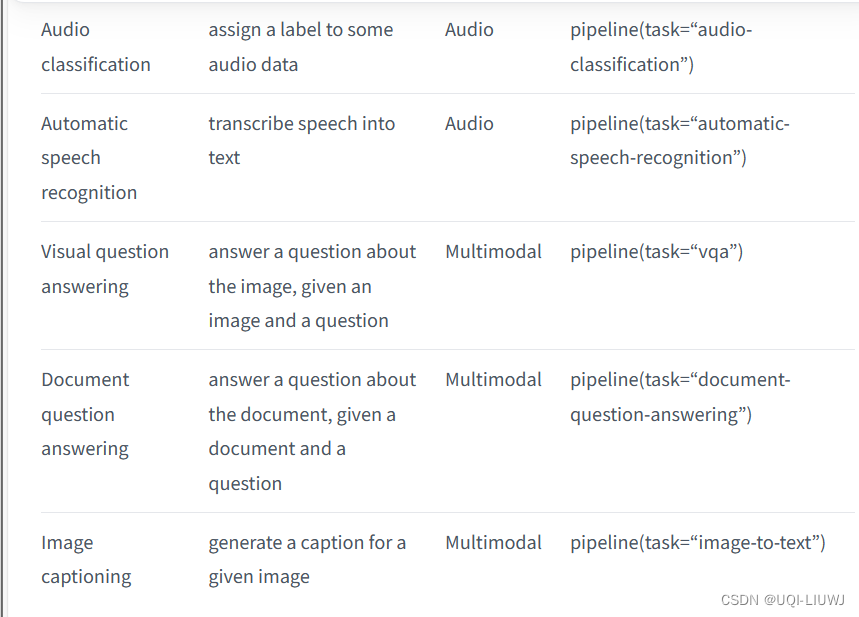
2 举例:情感分析
2.1 创建pipeline实例
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
#首先创建一个 pipeline() 实例,并指定您想要使用它的任务
#pipeline() 将下载并缓存情感分析的默认预训练模型和分词器

2.2 使用pipeline实例
然后就可以在目标文本上使用分类器了:
# 单个文本
classifier('Today is a shiny day!')
'''
[{'label': 'POSITIVE', 'score': 0.9992596507072449}]
'''# 多个文本
classifier(['Today is a shiny day!','What a bad day it is!'])
'''
[{'label': 'POSITIVE', 'score': 0.9992596507072449},
{'label': 'NEGATIVE', 'score': 0.999808132648468}]
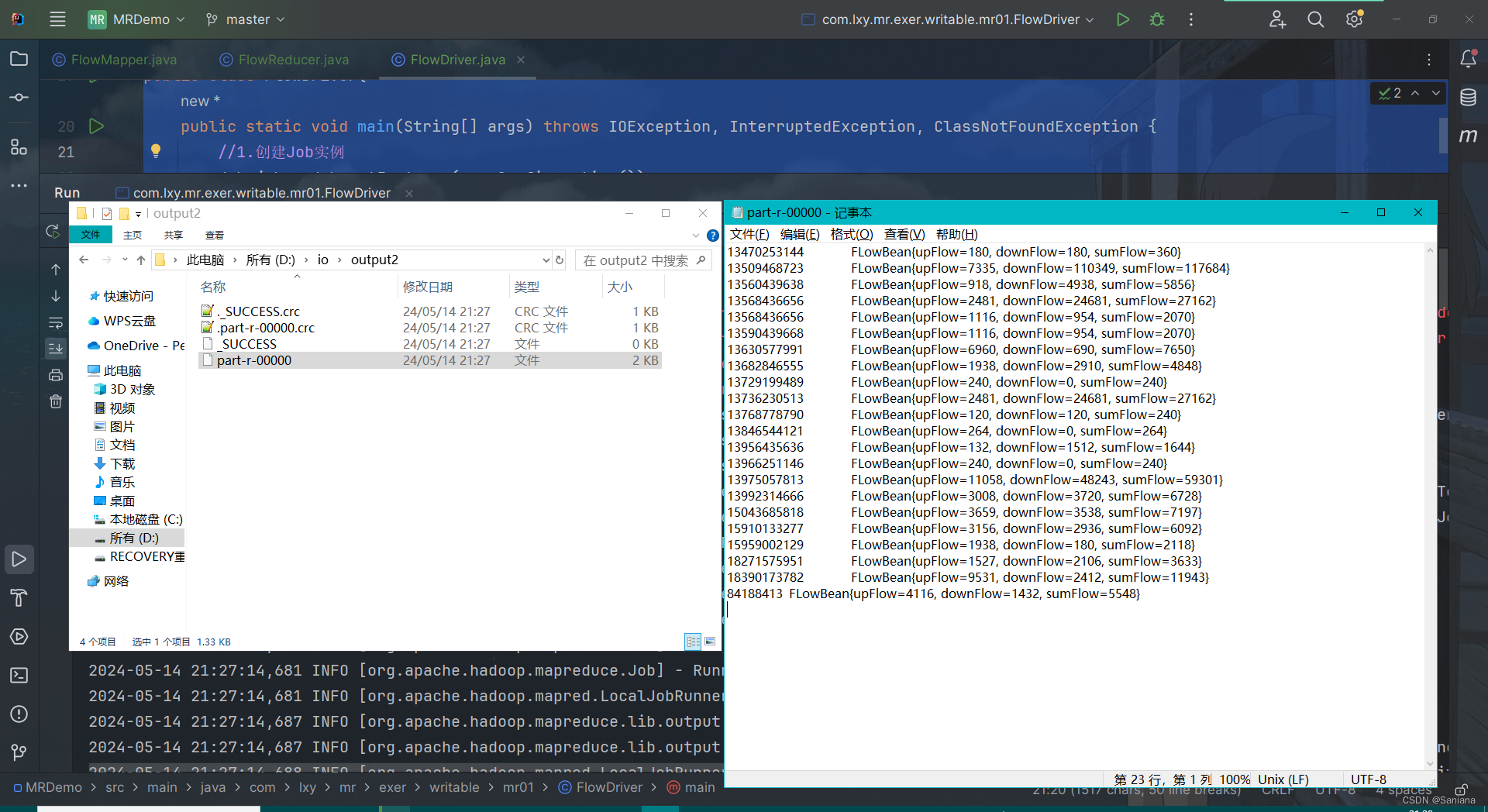
'''3 使用别的模型和分词器
- pipeline() 可以容纳来自 Models - Hugging Face的任何模型
- eg:能够处理法语文本的模型
以下两种方式都可以
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from transformers import pipeline
model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
classifier = pipeline("sentiment-analysis", model=model_name)
classifier("Nous sommes très heureux de vous présenter la bibliothèque Transformers.")
#[{'label': '5 stars', 'score': 0.7236300706863403}]from transformers import AutoTokenizer, AutoModelForSequenceClassification
model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
classifier("Nous sommes très heureux de vous présenter la bibliothèque Transformers.")
#[{'label': '5 stars', 'score': 0.7236300706863403}]
4 device相关
- 使用 device=n——>pipeline会自动将模型放置在指定的设备上
classifier = pipeline("sentiment-analysis", model=model_name,device=2)- 如果模型对于单个 GPU 来说太大,并且使用 PyTorch——>可以设置 device_map="auto",以自动确定如何加载和存储模型权重
classifier = pipeline("sentiment-analysis", model=model_name,device_map="auto")- 如果传递了 device_map="auto",在实例化pipeline时不需要添加参数 device=device