这个函数和我们之前提到的【Pytorch】6.torch.nn.functional.conv2d的使用的作用相似,都是完成CV领域的卷积操作,这里就不在过多赘述
torch.nn.conv2d的使用
打开pytorch的官方文档,我们可以看到


torch.nn.conv2d包含了若干参数
- in_channels:代表输入的通道数
- out_channels:代表输出的通道数
- kernel_size:代表卷积核的大小,既可以是
int类型,也可以是tuple元组类型,比如(2,5)代表卷积核大小为两行五列 - stride:代表卷积每次的步长
- padding:代表输入层的边缘填充
- padding_mode:代表边缘填充的规则,默认为
用0填充 - dilation:代表膨胀,默认为1
我们也可以通过官方的这个链接link来对每个参数进行了解
具体的使用方法为
# With square kernels and equal stride
m = nn.Conv2d(16, 33, 3, stride=2)
# non-square kernels and unequal stride and with padding
m = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2))
# non-square kernels and unequal stride and with padding and dilation
m = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2), dilation=(3, 1))
input = torch.randn(20, 16, 50, 100)
output = m(input)
具体用例
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root='./dataset', transform=torchvision.transforms.ToTensor(), train=False,
download=False)
dataLoader = DataLoader(dataset, batch_size=64, shuffle=True)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
net = Net()
writer = SummaryWriter(log_dir='./logs')
i = 0
for data in dataLoader:
img, target = data
output = net.forward(img)
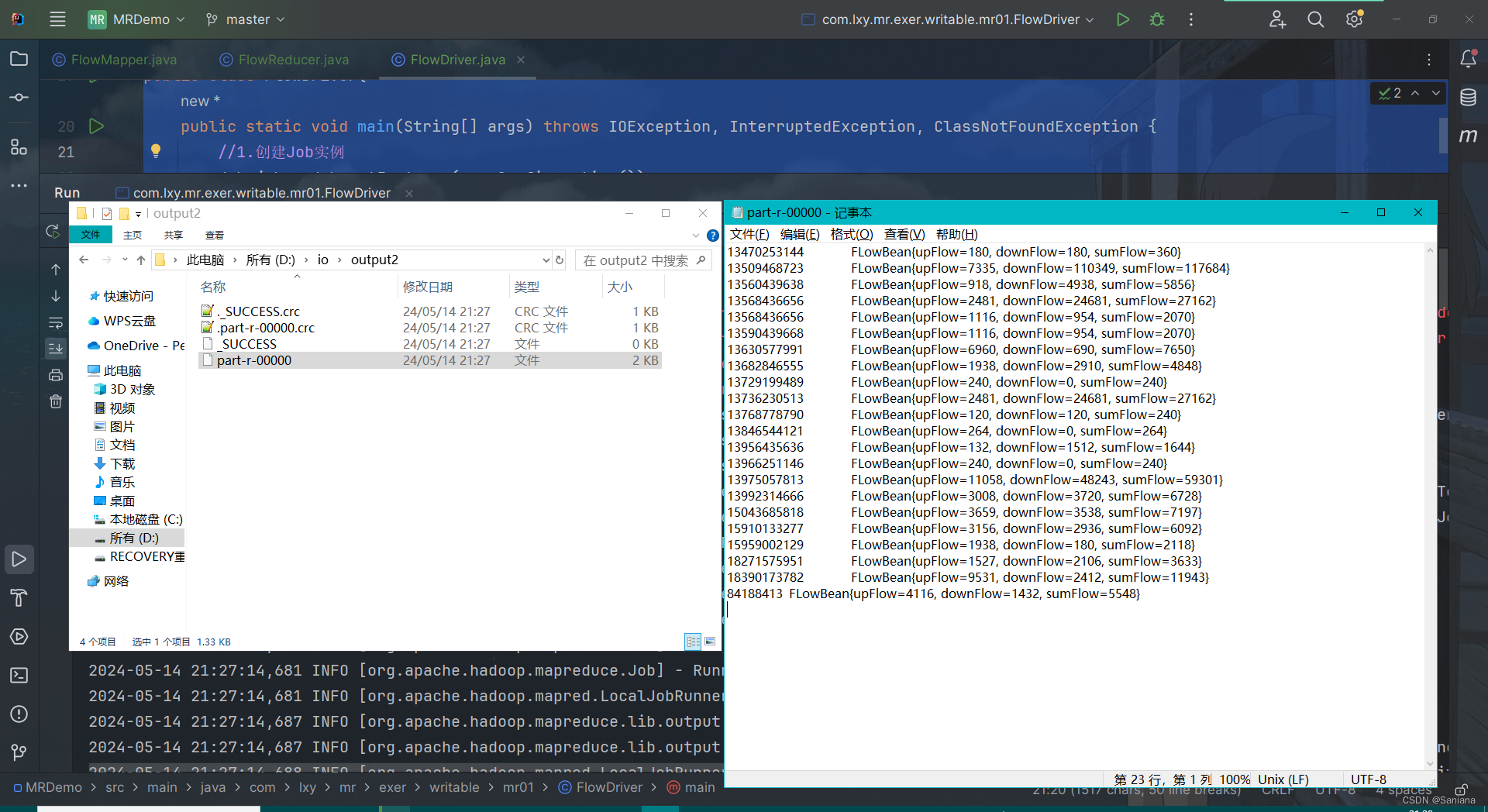
# print(output.shape)
writer.add_images('input', img, i)
# -1是一个占位符,让Pytorch自动计算维度大小
output = torch.reshape(output,(-1, 3, 30, 30))
# 无法直接传入6通道,只能3通道
writer.add_images("output", output, i)
i = i + 1
writer.close()
需要注意一下几点
- 再使用
TensorBoard进行可视化时,需要使用writer.add_images而不是writer.add_image要加s - 再使用
writer进行可视化时,tensor格式只支持3通道,如果是其他通道数,需要使用torch.reshape来进行通道数转换

因为output上是64个图片为一组,通道数为6,所以转化为通道数为3的话,有64*2的图片
下面附上输入输出通道数与像素数的计算方法







![RT-DETR改进教程|加入SCNet中的SCConv[CVPR2020]自校准卷积模块!](https://img-blog.csdnimg.cn/direct/63a159e6ed564e378e517bbf645362aa.png)