Tips:"分享是快乐的源泉💧,在我的博客里,不仅有知识的海洋🌊,还有满满的正能量加持💪,快来和我一起分享这份快乐吧😊!
喜欢我的博客的话,记得点个红心❤️和小关小注哦!您的支持是我创作的动力!数据源存放在我的资源下载区啦!
数据可视化(十一):Pandas餐饮信息表分析——交叉表、离群点分析,多维分析等高级操作
目录
- 数据可视化(十一):Pandas餐饮信息表分析——交叉表、离群点分析,多维分析等高级操作
- 案例三:餐饮信息表分析
- 问题1:按类型聚合餐饮店数量并画出水平直方图
- 问题2:按城市聚合餐饮店数量,画出垂直柱状图
- 问题3:交叉表查看不同城市不同餐饮店的餐饮数量
- 问题4:找出点评最多的10个餐饮店
- 问题5:找出 人均 离群点(过大的数),并删除
- 问题6:按 类型 分组, 计算 人均 最高 最低 均值,画成对比水平直方图
- 问题7:以 服务 为横坐标,口味 为纵坐标,画出散点图
- 问题8:以 人均 为横坐标,服务 口味 环境 为纵坐标,以不同颜色画出散点图
- 问题9:一线城市北上广深,一个画幅小4个饼图,画出'川菜', '湘菜', '江浙菜', '东北菜', '粤菜', '徽菜', '客家菜', '赣菜', '湖北菜'的餐饮店占比
- 问题10:跟上相似,一线城市北上广深,一个画幅小4个饼图,画出每个城市餐饮店最多的10种类型的占比图
- 问题11:采用jieba分词,对所有店名进行分词,找出出现频率最高10个词,词长度要大于1
- 问题12:将上面分词结果绘制成词云
案例三:餐饮信息表分析
# 准备数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
import warnings
warnings.filterwarnings('ignore')
# 导入数据
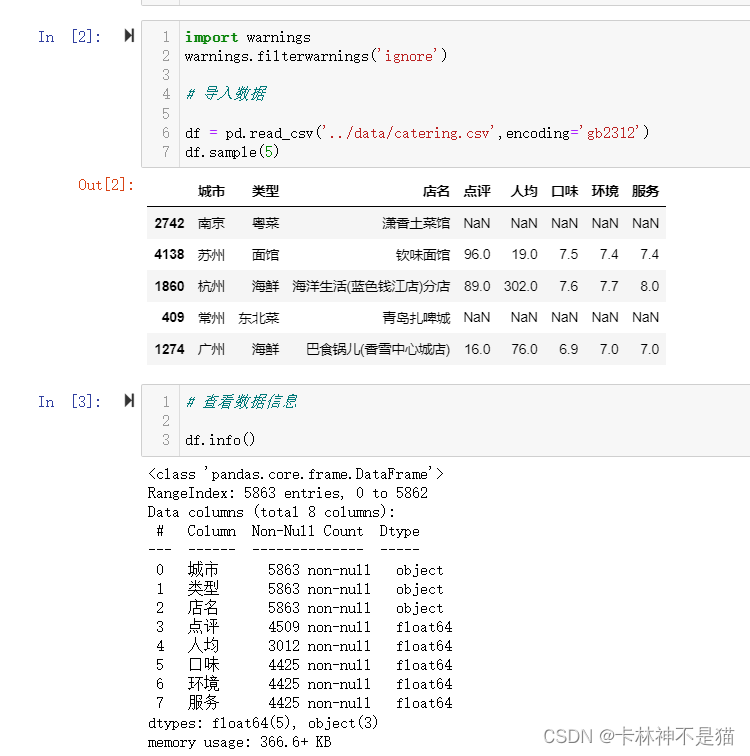
df = pd.read_csv('data/catering.csv',encoding='gb2312')
df.sample(5)
# 查看数据信息
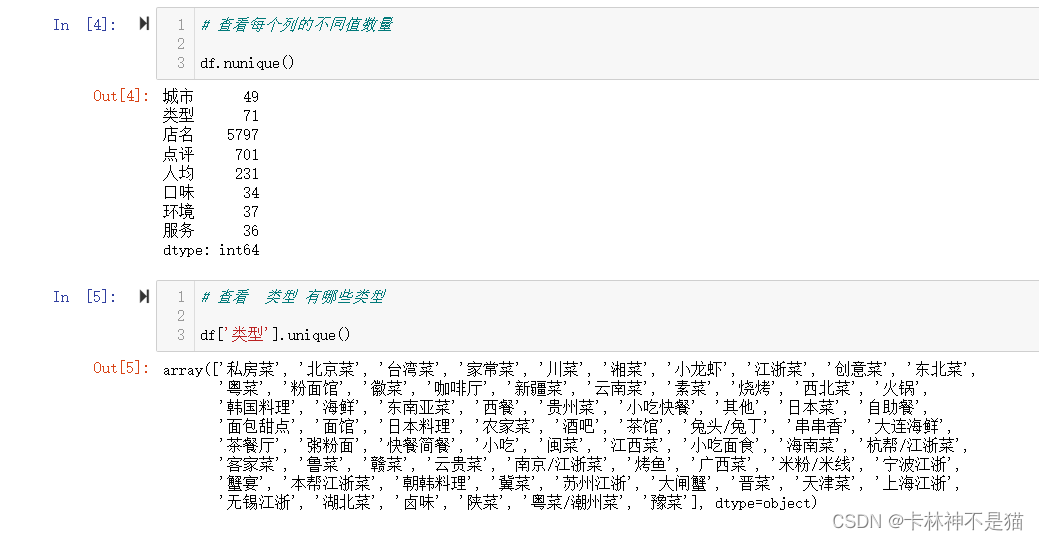
df.info()
# 查看每个列的不同值数量
df.nunique()
# 查看 类型 有哪些类型
df['类型'].unique()
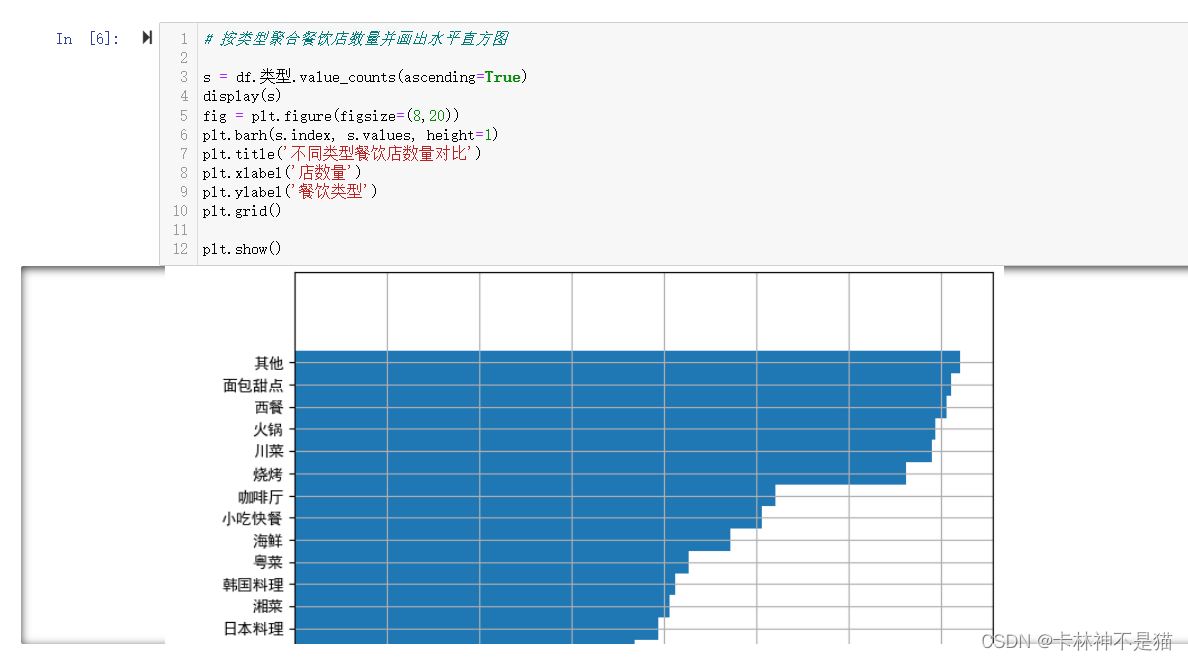
问题1:按类型聚合餐饮店数量并画出水平直方图
# 按类型聚合餐饮店数量并画出水平直方图
s = df.类型.value_counts(ascending=True)
display(s)
fig = plt.figure(figsize=(8,20))
plt.barh(s.index, s.values, height=1)
plt.title('不同类型餐饮店数量对比')
plt.xlabel('店数量')
plt.ylabel('餐饮类型')
plt.grid()
plt.show()
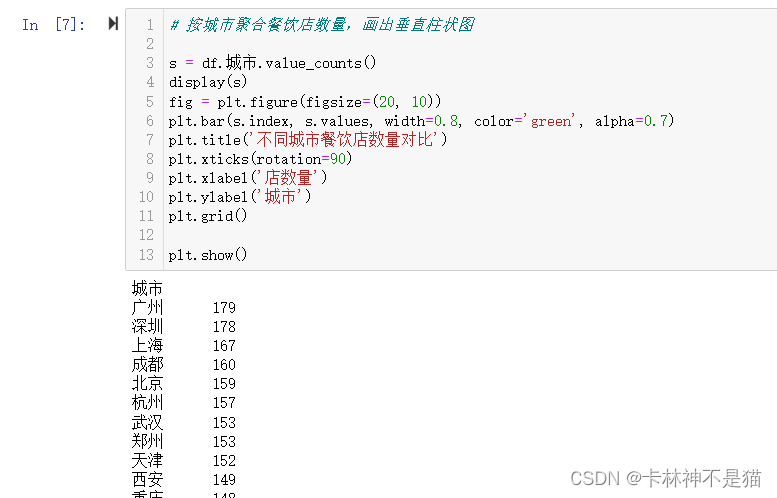
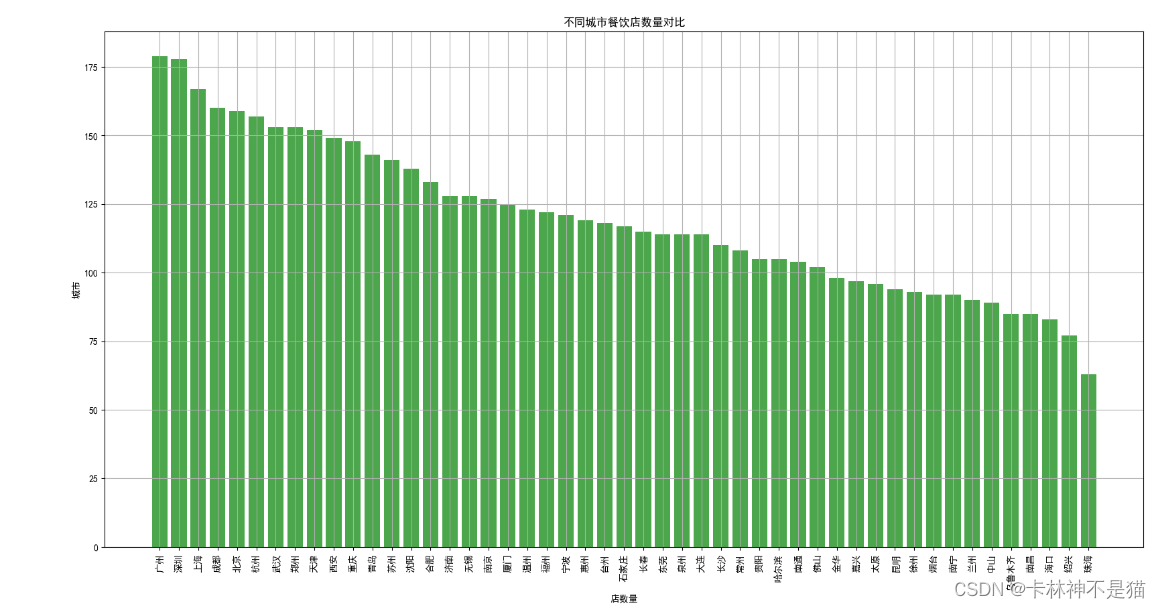
问题2:按城市聚合餐饮店数量,画出垂直柱状图
# 按城市聚合餐饮店数量,画出垂直柱状图
s = df.城市.value_counts()
display(s)
fig = plt.figure(figsize=(20, 10))
plt.bar(s.index, s.values, width=0.8, color='green', alpha=0.7)
plt.title('不同城市餐饮店数量对比')
plt.xticks(rotation=90)
plt.xlabel('店数量')
plt.ylabel('城市')
plt.grid()
plt.show()
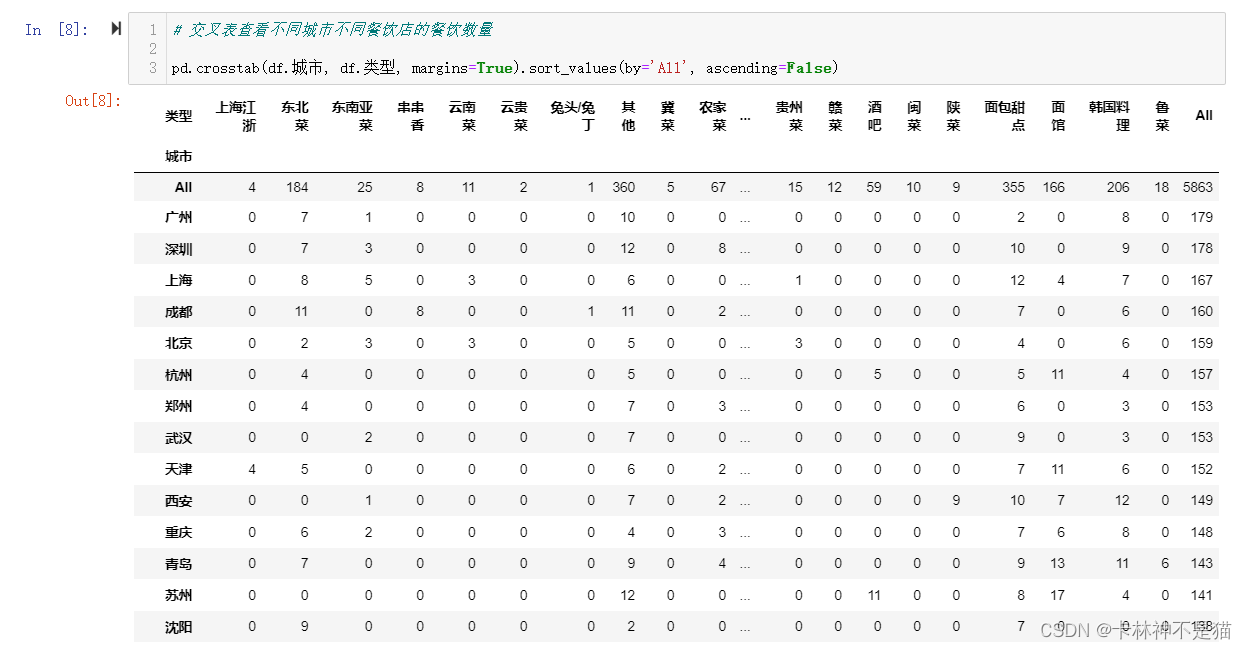
问题3:交叉表查看不同城市不同餐饮店的餐饮数量
# 交叉表查看不同城市不同餐饮店的餐饮数量
pd.crosstab(df.城市, df.类型, margins=True).sort_values(by='All', ascending=False)
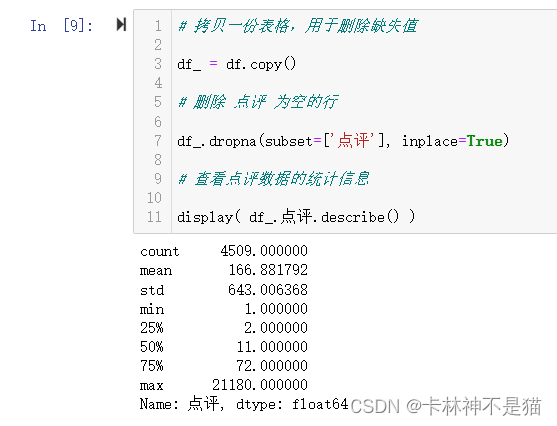
# 拷贝一份表格,用于删除缺失值
df_ = df.copy()
# 删除 点评 为空的行
df_.dropna(subset=['点评'], inplace=True)
# 查看点评数据的统计信息
display( df_.点评.describe() )
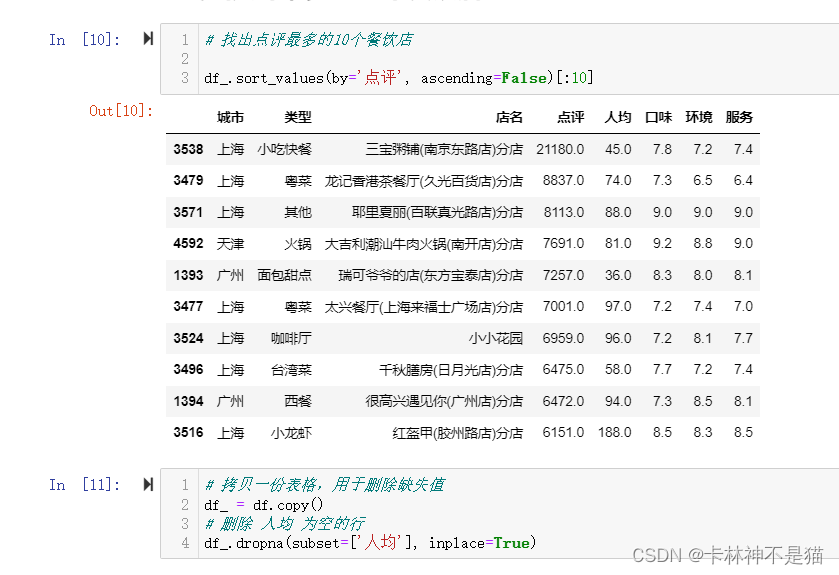
问题4:找出点评最多的10个餐饮店
# 找出点评最多的10个餐饮店
df_.sort_values(by='点评', ascending=False)[:10]
# 拷贝一份表格,用于删除缺失值
df_ = df.copy()
# 删除 人均 为空的行
df_.dropna(subset=['人均'], inplace=True)
问题5:找出 人均 离群点(过大的数),并删除
# 找出 人均 离群点(过大的数)
# 不去除利群点,画直方图时会出现图形缩小在一个小范围
def out_range(s:pd.Series, a:int):
bool_inds = (s<s.mean()-a*s.std())|(s>s.mean()+a*s.std())
return s[bool_inds].index
display( out_range(df_['人均'], 3) )
df_.drop(out_range(df_['人均'], 3), axis=0, inplace=True)

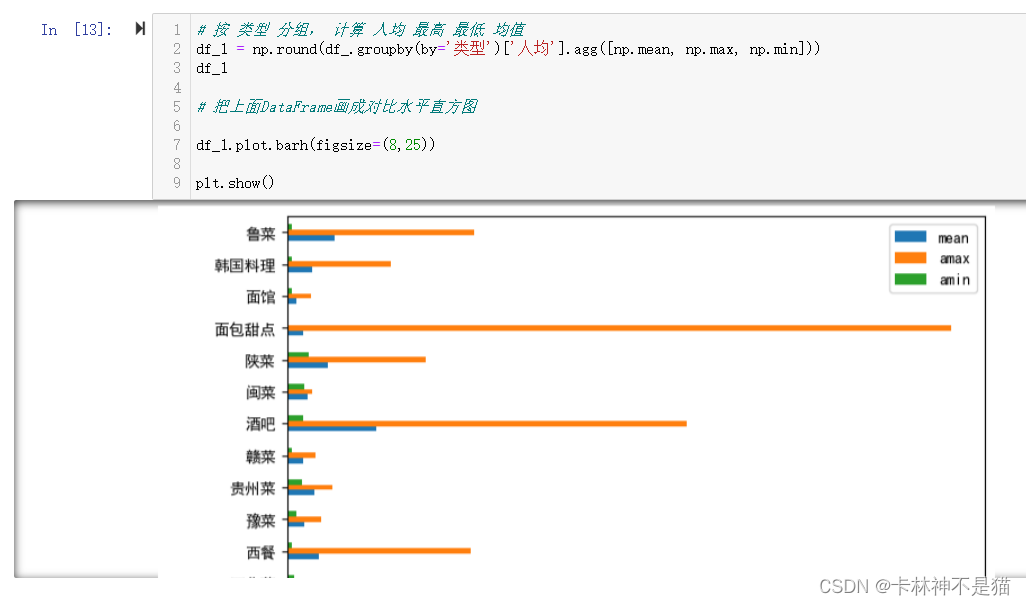
问题6:按 类型 分组, 计算 人均 最高 最低 均值,画成对比水平直方图
# 按 类型 分组, 计算 人均 最高 最低 均值
df_1 = np.round(df_.groupby(by='类型')['人均'].agg([np.mean, np.max, np.min]))
df_1
# 把上面DataFrame画成对比水平直方图
df_1.plot.barh(figsize=(8,25))
plt.show()
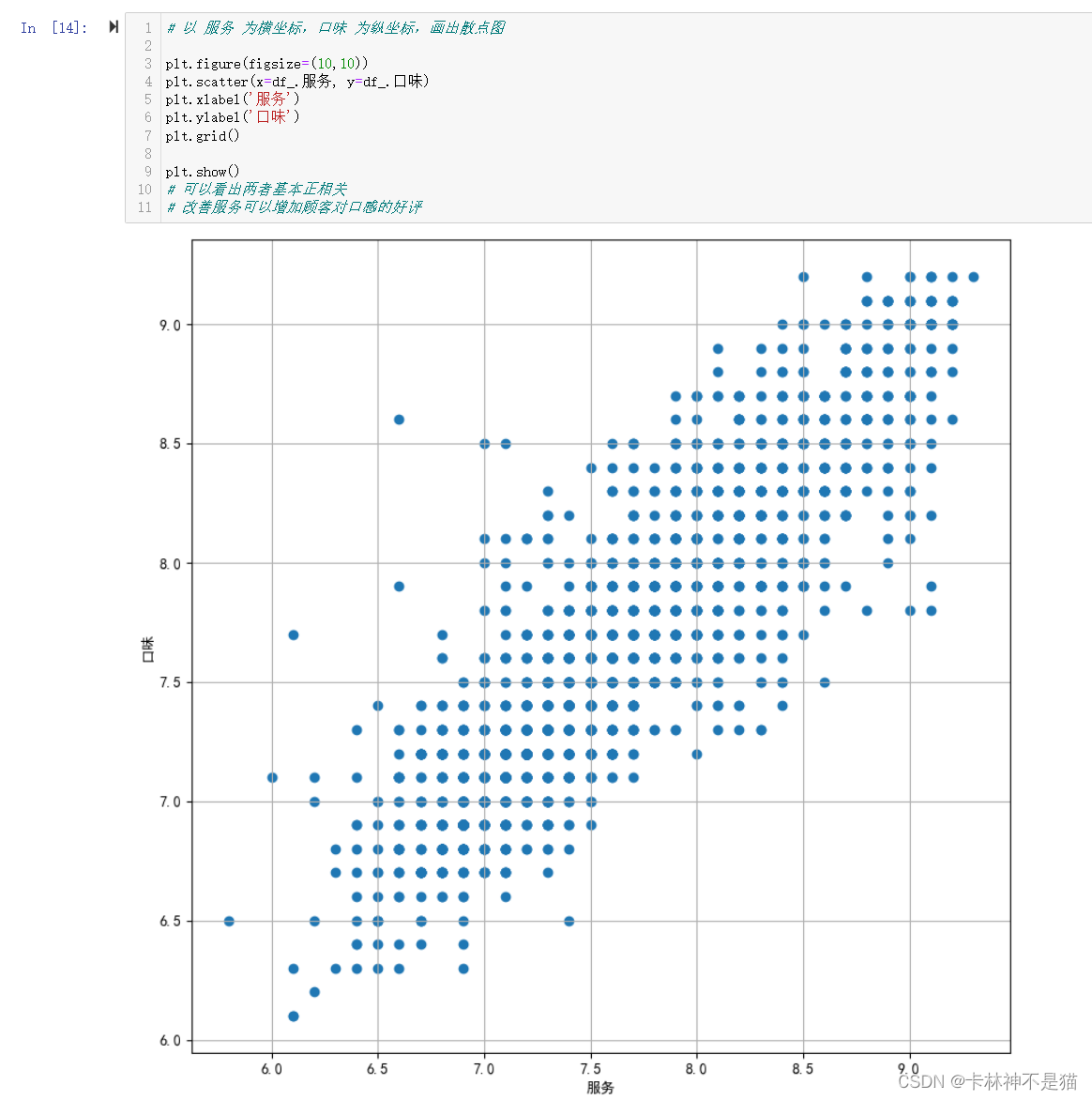
问题7:以 服务 为横坐标,口味 为纵坐标,画出散点图
# 以 服务 为横坐标,口味 为纵坐标,画出散点图
plt.figure(figsize=(10,10))
plt.scatter(x=df_.服务, y=df_.口味)
plt.xlabel('服务')
plt.ylabel('口味')
plt.grid()
plt.show()
# 可以看出两者基本正相关
# 改善服务可以增加顾客对口感的好评
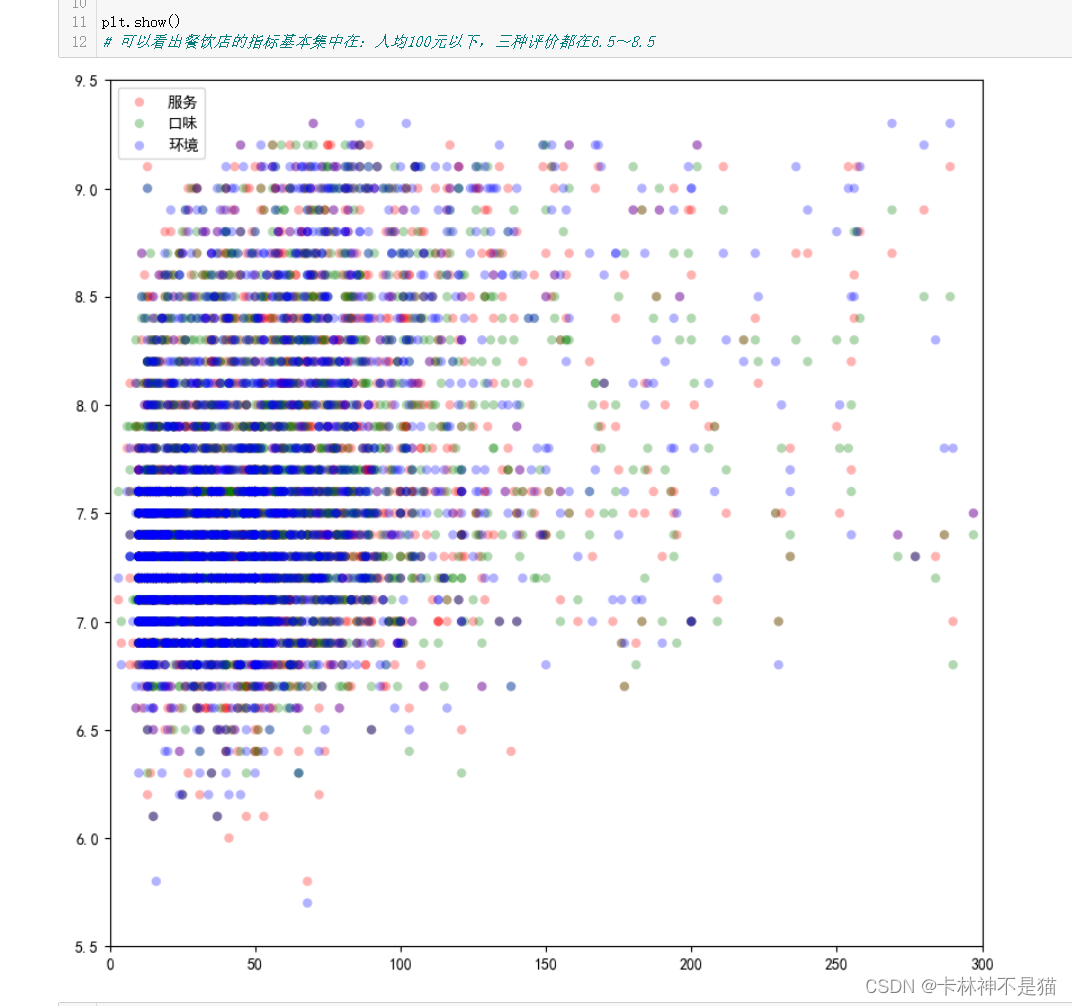
问题8:以 人均 为横坐标,服务 口味 环境 为纵坐标,以不同颜色画出散点图
# 以 人均 为横坐标,服务 口味 环境 为纵坐标,以不同颜色画出散点图
plt.figure(figsize=(10,10))
plt.scatter(df_.人均, df_.服务, color='r', label='服务', alpha=0.3, edgecolors='none')
plt.scatter(df_.人均, df_.口味, color='g', label='口味', alpha=0.3, edgecolors='none')
plt.scatter(df_.人均, df_.环境, color='b', label='环境', alpha=0.3, edgecolors='none')
plt.xlim(0, 300) # 防止点过于聚集
plt.ylim(5.5, 9.5) # 防止点过于聚集
plt.legend()
plt.show()
# 可以看出餐饮店的指标基本集中在:人均100元以下,三种评价都在6.5~8.5
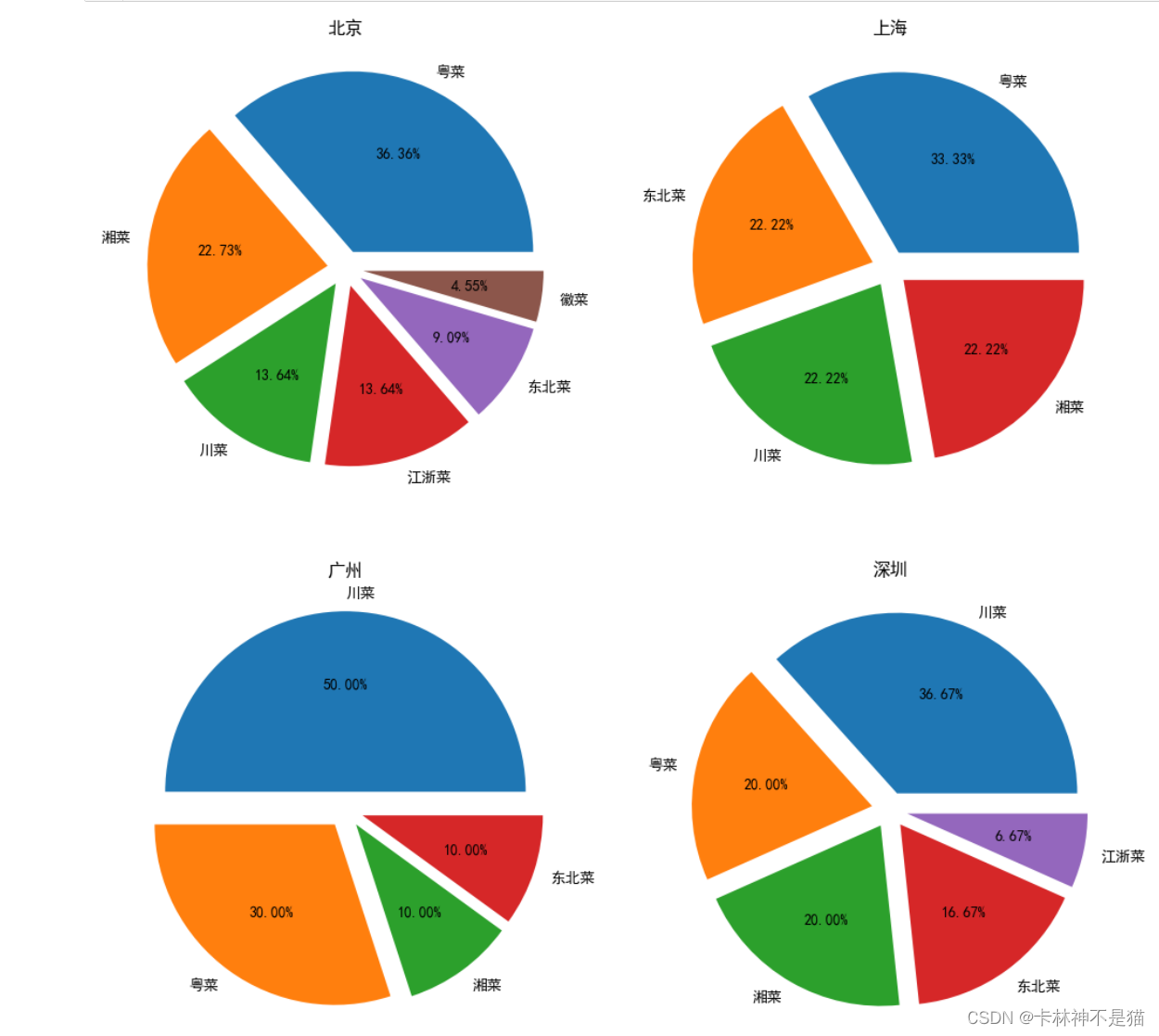
问题9:一线城市北上广深,一个画幅小4个饼图,画出’川菜’, ‘湘菜’, ‘江浙菜’, ‘东北菜’, ‘粤菜’, ‘徽菜’, ‘客家菜’, ‘赣菜’, '湖北菜’的餐饮店占比
# 一线城市北上广深,一个画幅小4个饼图,
# 画出'川菜', '湘菜', '江浙菜', '东北菜', '粤菜', '徽菜', '客家菜', '赣菜', '湖北菜'的餐饮店占比
types = ['川菜', '湘菜', '江浙菜', '东北菜', '粤菜', '徽菜', '客家菜', '赣菜', '湖北菜']
bj = df_[ df_['城市']=='北京' ][ df_['类型'].isin(types) ]['类型'].value_counts()
sh = df_[ df_['城市']=='上海' ][ df_['类型'].isin(types) ]['类型'].value_counts()
gz = df_[ df_['城市']=='广州' ][ df_['类型'].isin(types) ]['类型'].value_counts()
sz = df_[ df_['城市']=='深圳' ][ df_['类型'].isin(types) ]['类型'].value_counts()
fig = plt.figure(figsize=(12,12))
ax1 = fig.add_subplot(2,2,1)
ax1.pie(bj.values, labels=bj.index, explode=np.ones(len(bj.index))*0.1, autopct='%.2f%%')
ax1.set_title('北京')
ax2 = fig.add_subplot(2,2,2)
ax2.pie(sh.values, labels=sh.index, explode=np.ones(len(sh.index))*0.1, autopct='%.2f%%')
ax2.set_title('上海')
ax3 = fig.add_subplot(2,2,3)
ax3.pie(gz.values, labels=gz.index, explode=np.ones(len(gz.index))*0.1, autopct='%.2f%%')
ax3.set_title('广州')
ax4 = fig.add_subplot(2,2,4)
ax4.pie(sz.values, labels=sz.index, explode=np.ones(len(sz.index))*0.1, autopct='%.2f%%')
ax4.set_title('深圳')
plt.show()
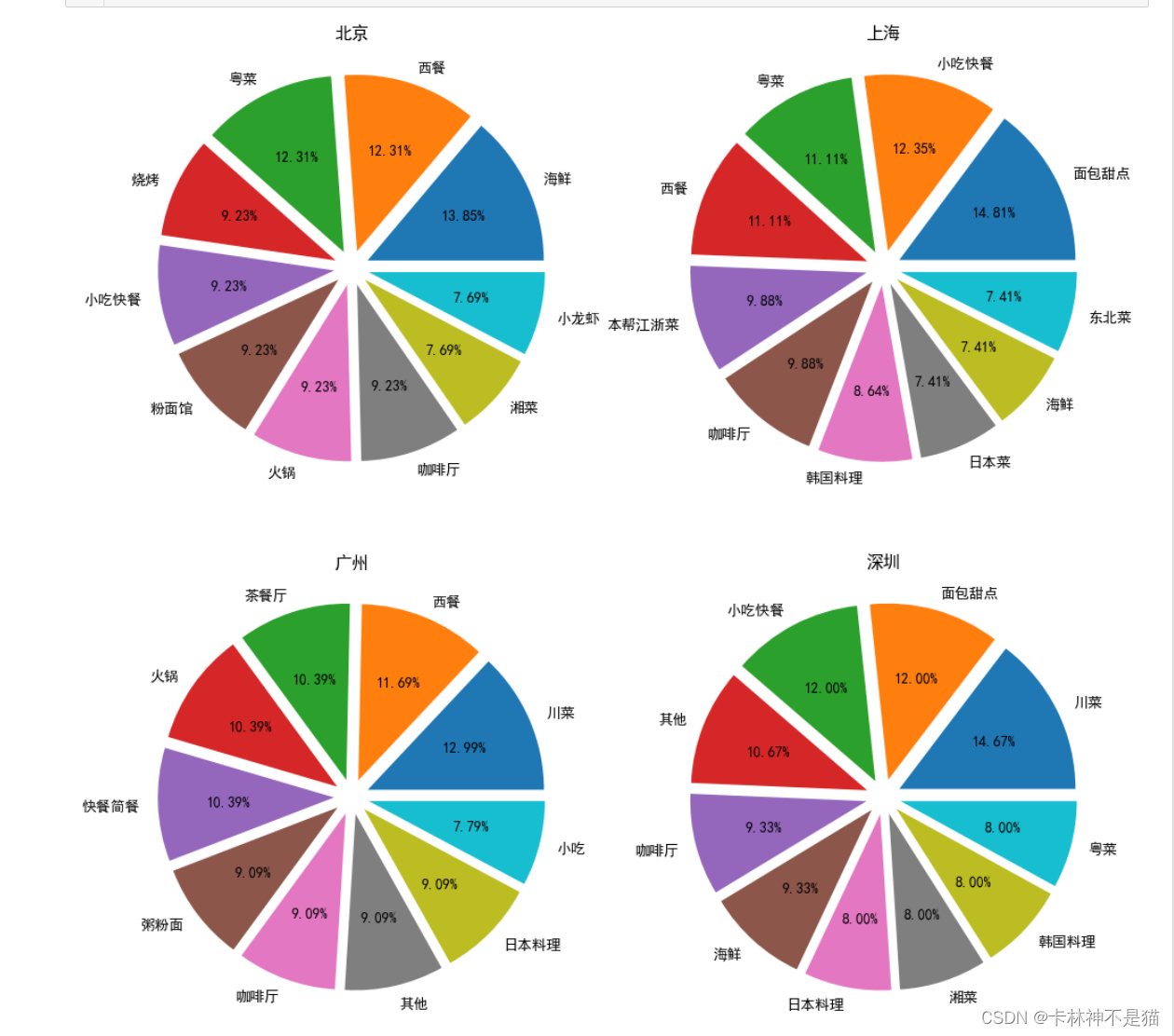
问题10:跟上相似,一线城市北上广深,一个画幅小4个饼图,画出每个城市餐饮店最多的10种类型的占比图
# 跟上相似,一线城市北上广深,一个画幅小4个饼图,
# 画出每个城市餐饮店最多的10种类型的占比图
bj = df_[ df_['城市']=='北京' ]['类型'].value_counts()[:10]
sh = df_[ df_['城市']=='上海' ]['类型'].value_counts()[:10]
gz = df_[ df_['城市']=='广州' ]['类型'].value_counts()[:10]
sz = df_[ df_['城市']=='深圳' ]['类型'].value_counts()[:10]
fig = plt.figure(figsize=(12,12))
ax1 = fig.add_subplot(2,2,1)
ax1.pie(bj.values, labels=bj.index, explode=np.ones(10)*0.1, autopct='%.2f%%')
ax1.set_title('北京')
ax2 = fig.add_subplot(2,2,2)
ax2.pie(sh.values, labels=sh.index, explode=np.ones(10)*0.1, autopct='%.2f%%')
ax2.set_title('上海')
ax3 = fig.add_subplot(2,2,3)
ax3.pie(gz.values, labels=gz.index, explode=np.ones(10)*0.1, autopct='%.2f%%')
ax3.set_title('广州')
ax4 = fig.add_subplot(2,2,4)
ax4.pie(sz.values, labels=sz.index, explode=np.ones(10)*0.1, autopct='%.2f%%')
ax4.set_title('深圳')
plt.show()
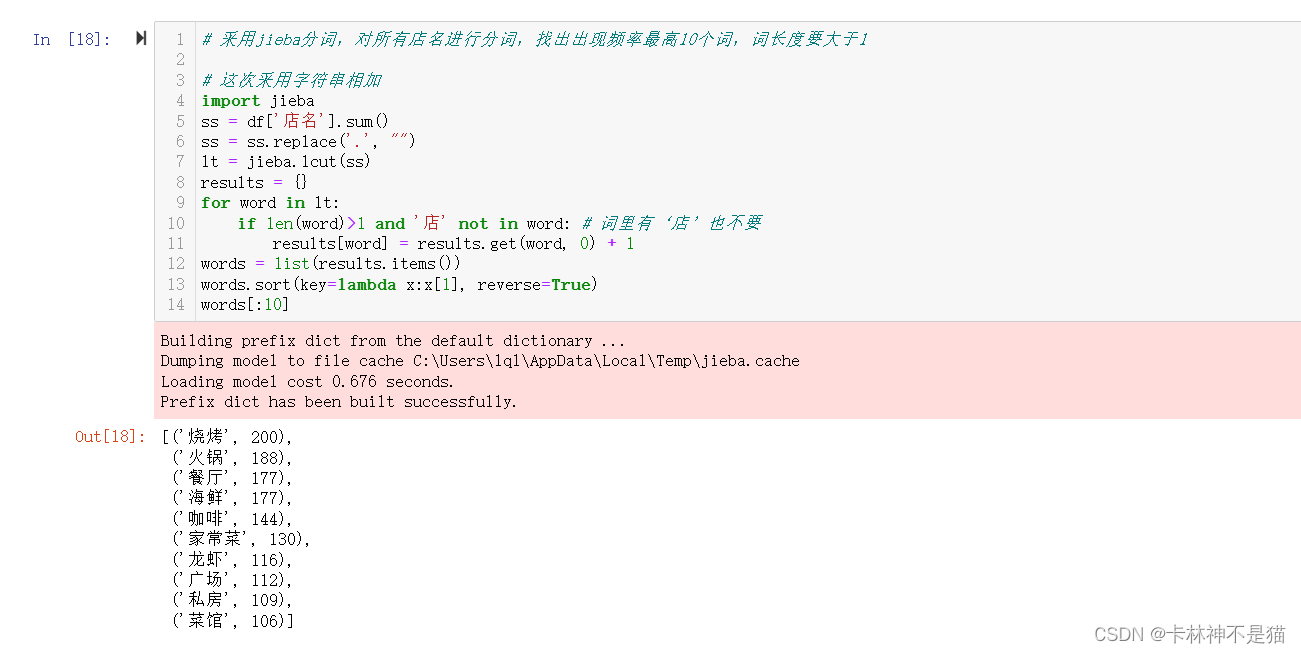
问题11:采用jieba分词,对所有店名进行分词,找出出现频率最高10个词,词长度要大于1
# 采用jieba分词,对所有店名进行分词,找出出现频率最高10个词,词长度要大于1
# 这次采用字符串相加
import jieba
ss = df['店名'].sum()
ss = ss.replace('.', "")
lt = jieba.lcut(ss)
results = {}
for word in lt:
if len(word)>1 and '店' not in word: # 词里有‘店’也不要
results[word] = results.get(word, 0) + 1
words = list(results.items())
words.sort(key=lambda x:x[1], reverse=True)
words[:10]
问题12:将上面分词结果绘制成词云
# 将上面分词结果绘制成词云
from wordcloud import WordCloud
wordcloud = WordCloud(font_path='./SimHei.ttf', width=1000,height=1000,background_color='white')
wordcloud.fit_words(results)
plt.figure(figsize=(15,15))
axs = plt.imshow(wordcloud)#正常显示词云
plt.axis('off')#关闭坐标轴
plt.show()