实验7:目标检测算法2
一:实验目的与要求
1:了解一阶段目标检测模型-YOLOv3模型的原理和结构.
2:学习通过YOLOv3模型解决目标检测问题。
二:实验资源
pytorch代码各文件夹内容介绍
1. data_loader.py:能够传入模型的Dataloader构建函数。
2. data_operate.py: 数据操作。
3. get_box.py: 获取数据标记框函数。
4. Loss.py:训练主体程序。
5. main.py: 主函数。
6. metric.py: 评价指标函数,用于模型训练时,评价val数据集。
7. model_YOLOV3.py: 模型函数。
8. utils.py: 其他工具函数。
参考paddle版本代码
搭建YoloV3对螺母螺栓进行目标检测 - 飞桨AI Studio星河社区
三:实验要求
1:阅读示例代码,学习YOLOv3模型。
2:基于螺丝螺母数据集或昆虫数据集,调试运行模型代码。
3:调整各类参数,优化模型效果。
4:撰写实验报告。
三:实验环境
本实验所使用的环境条件如下表所示。
| 操作系统 | Ubuntu(Linux) |
| 程序语言 | Python(3.11.4) |
| 第三方依赖 | torch, torchvision, matplotlib等 |
四:实验原理
YOLOv3是一种高效的实时目标检测算法,其核心思想是将目标检测任务视为一个回归问题。通过一次前向传播,YOLOv3能够直接预测出图像中目标的边界框和类别概率,从而实现了快速且准确的目标检测。
(1)网络结构
YOLOv3的网络结构采用了Darknet-53作为特征提取网络。Darknet-53是一个深度卷积神经网络,包含53个卷积层和5个最大池化层。这些卷积层和池化层能够有效地提取图像中的特征信息。此外,YOLOv3还在Darknet-53的基础上添加了3个额外的卷积层,用于检测不同尺寸的目标。这些卷积层能够预测不同大小的目标框,以适应各种目标的检测需求。
YOLOv3的网络结构如下图所示。
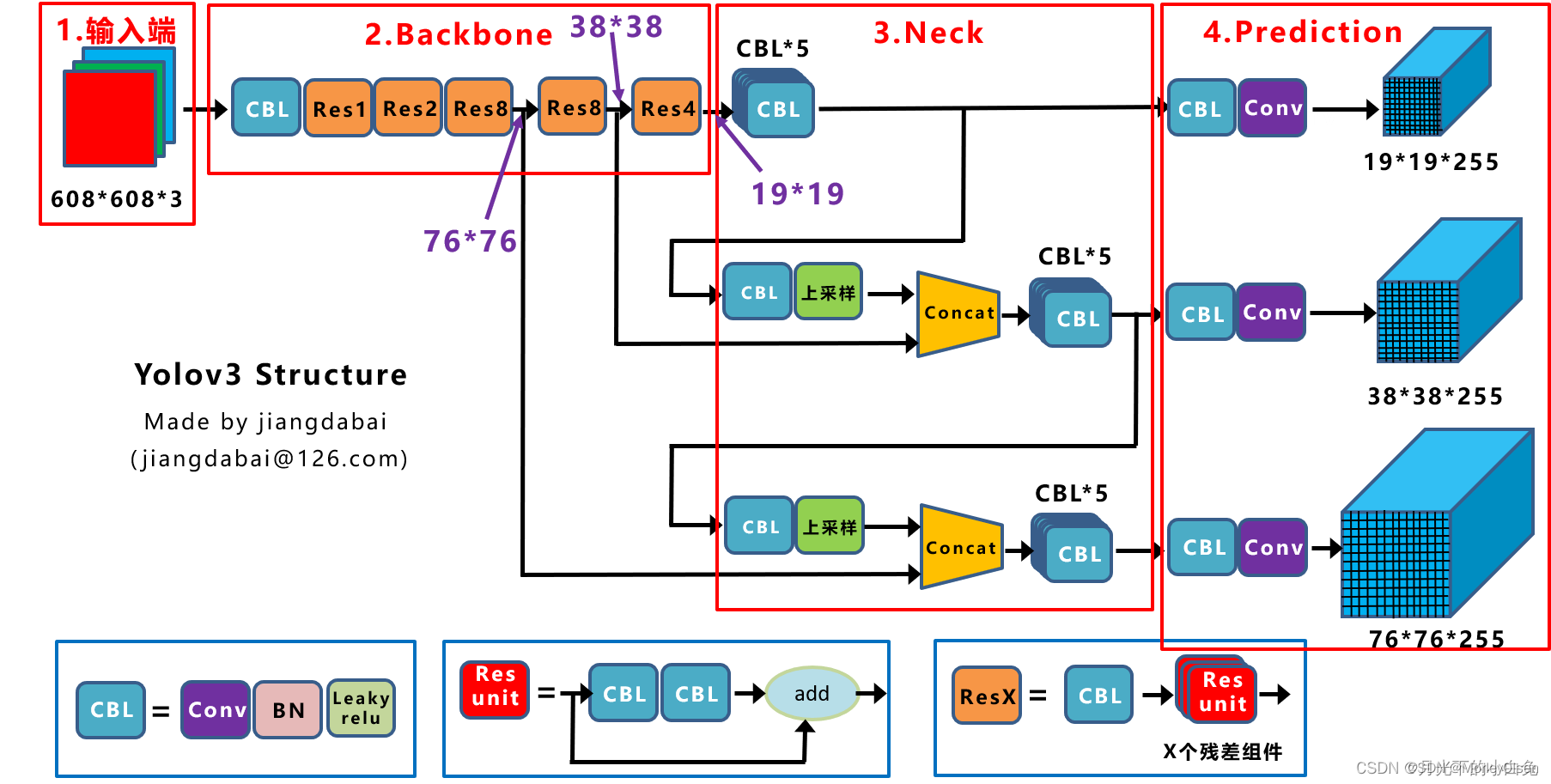
(2)目标检测原理
在YOLOv3中,目标检测任务是通过将输入图像划分为S×S个网格单元来完成的。每个网格单元负责预测B个边界框和对应的置信度分数,以及每个边界框的类别概率。这样,每个网格单元都能够独立地预测出目标的存在、位置以及类别。
为了得到准确的预测结果,YOLOv3采用了多尺度损失函数和非极大值抑制算法。多尺度损失函数能够综合考虑不同尺度的目标框,从而提高检测的准确性。非极大值抑制算法则用于去除冗余的边界框,保留最佳的检测结果。
(3)训练和检测
在训练阶段,YOLOv3需要大量的标注数据进行学习。标注数据包括图像中目标的类别、位置以及边界框的大小等信息。通过不断迭代和优化网络参数,YOLOv3能够逐渐提高目标检测的准确性。
在检测阶段,YOLOv3可以直接对输入的图像进行前向传播,得到目标的预测结果。这些预测结果包括目标的类别、位置以及边界框的大小等信息,可以用于后续的应用或处理。
五:算法流程
- 数据准备。准备训练所需的昆虫数据集,并确保每个图像都有对应的标注文件,即相应的边界框标注和类别信息。
- 数据预处理。对准备好的数据进行预处理,包括图像大小调整、归一化等操作,以便模型更好地学习和处理。
- 模型架构选择。选择YOLOv3-tiny作为目标网络结构,并修改相应yaml文件。
- 模型超参数调整。调整模型的超参数,如学习率、训练轮数(epoch)、正则化参数等。
- 模型训练。在前向传播中,模型接收输入图像并生成预测结果;在反向传播中,根据预测结果与实际标签之间的误差调整模型参数;参数更新则根据优化算法更新模型权重。
- 模型验证与测试。评估模型在未见过的数据上的性能。通过不断调整模型架构和超参数,优化模型在OOD数据集上的表现。
- 模型推理与后处理。
六:实验展示
本次实验采用YOLOv3-tiny网络结构,数据集为昆虫数据集。
【模型训练过程】
设置模型超参数如下:epoch为30,预训练权重为yolov3.pt(来自ultralytics官方),网络结构为yolov3-tiny.yaml,数据结构为voc.yaml,batch_size为16,优化器为SGD,线程为8。
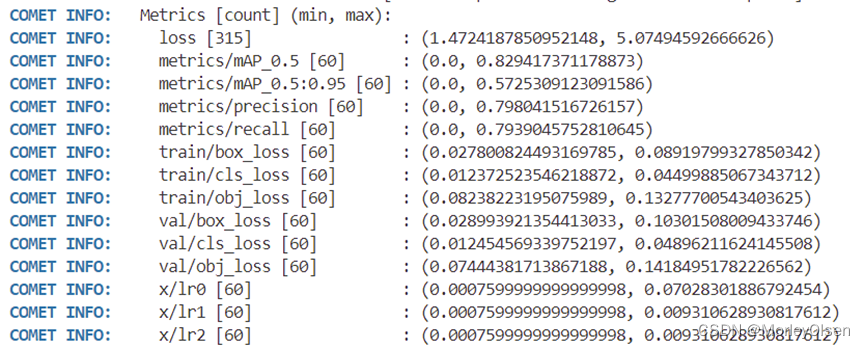
训练完成后的评价指标汇总如下图所示。
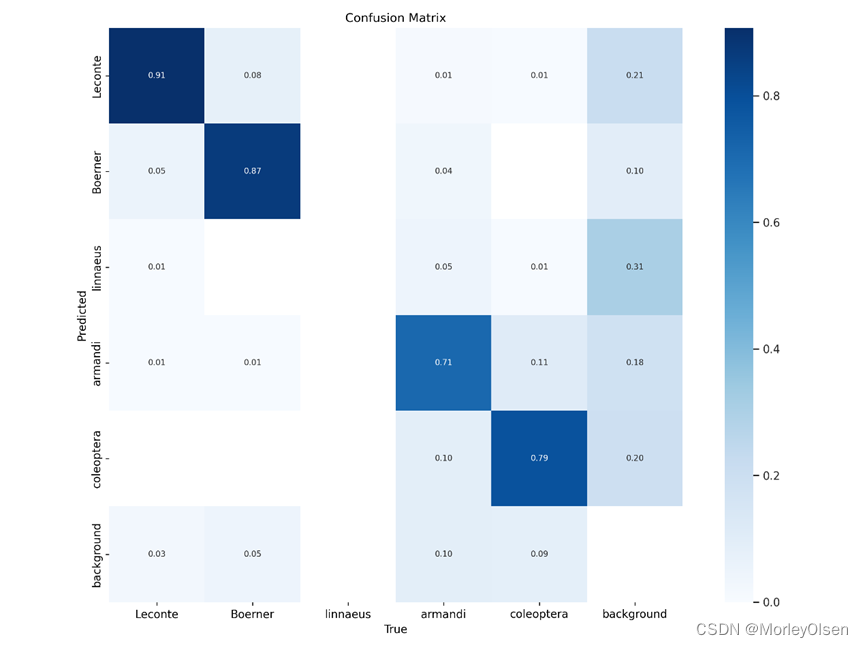
混淆矩阵,如下图所示。
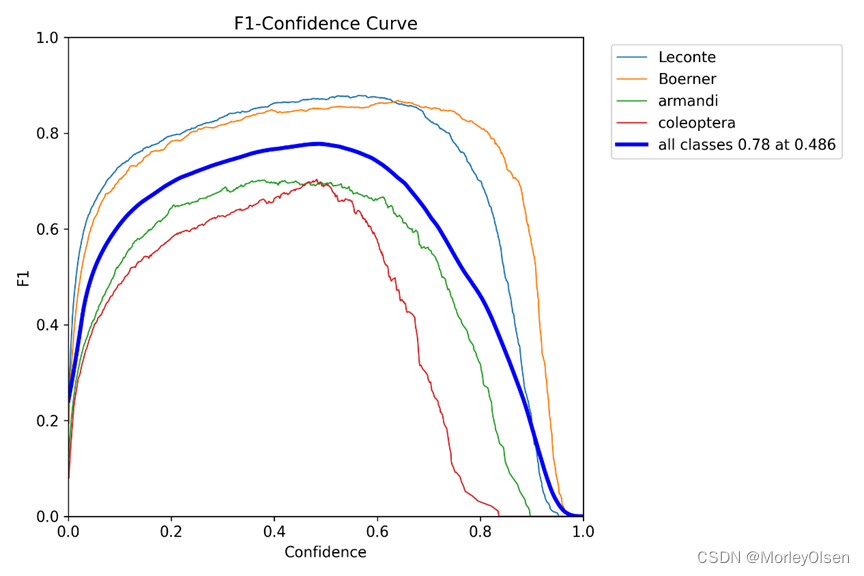
F1值的曲线,如下图所示。
Precision的曲线,如下图所示。
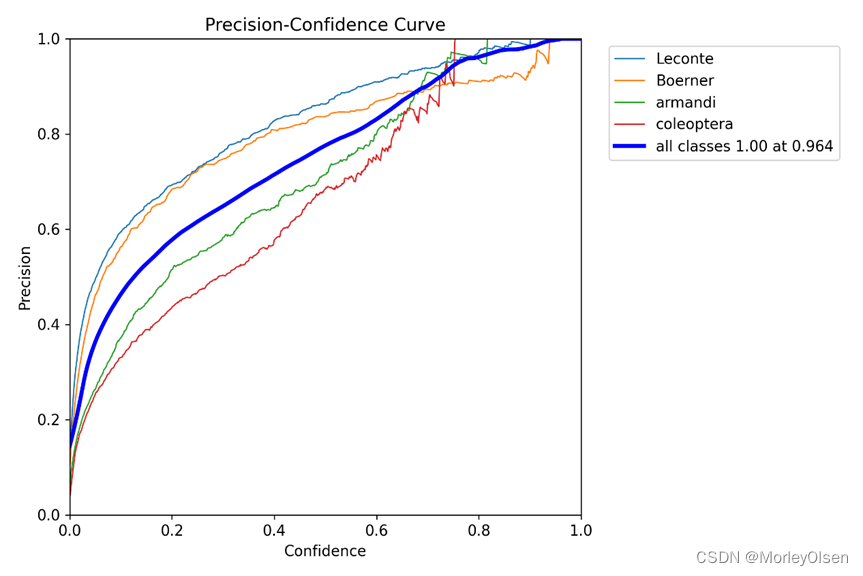
Recall的曲线,如下图所示。
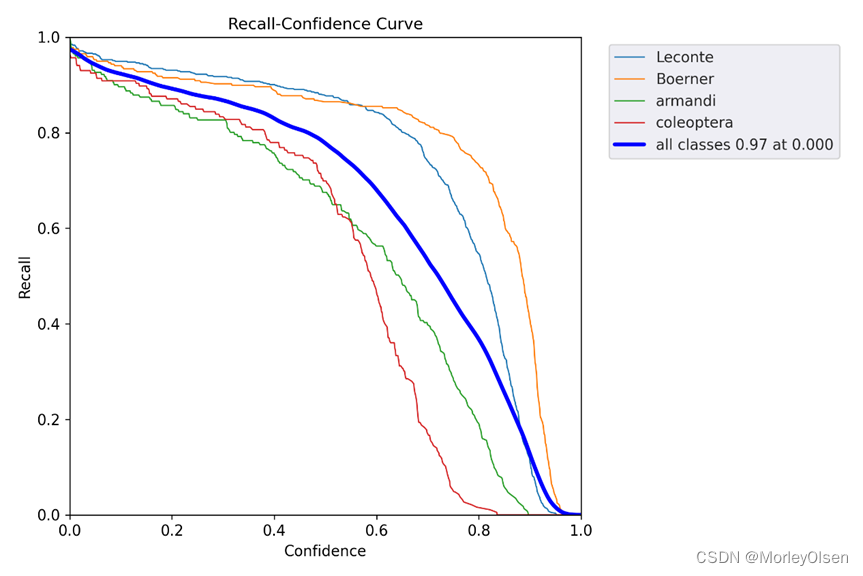
Precision- Recall的曲线,如下图所示。
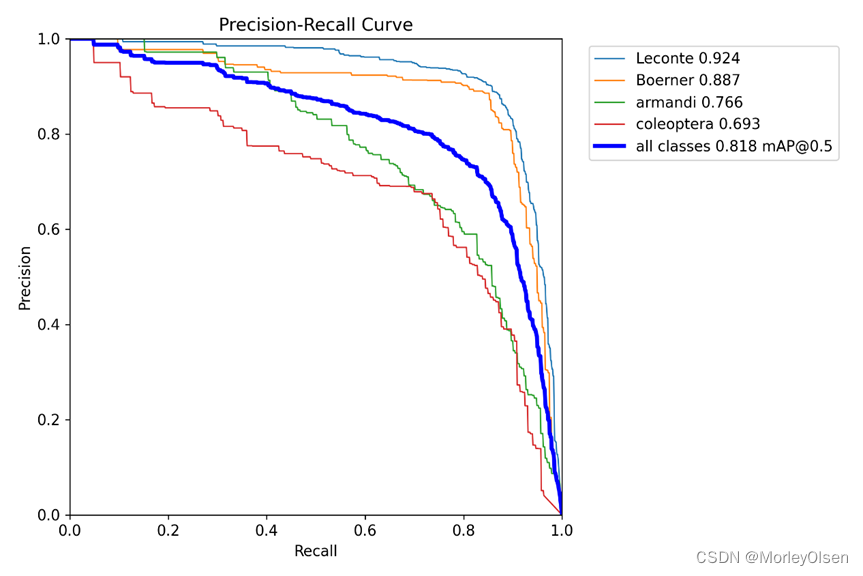
训练和验证时的锚框损失和分类损失,以及mAP等评价指标的曲线,如下图所示。

每个类别的数据量、标签、center xy、labels 标签的长和宽的信息,如下图所示。
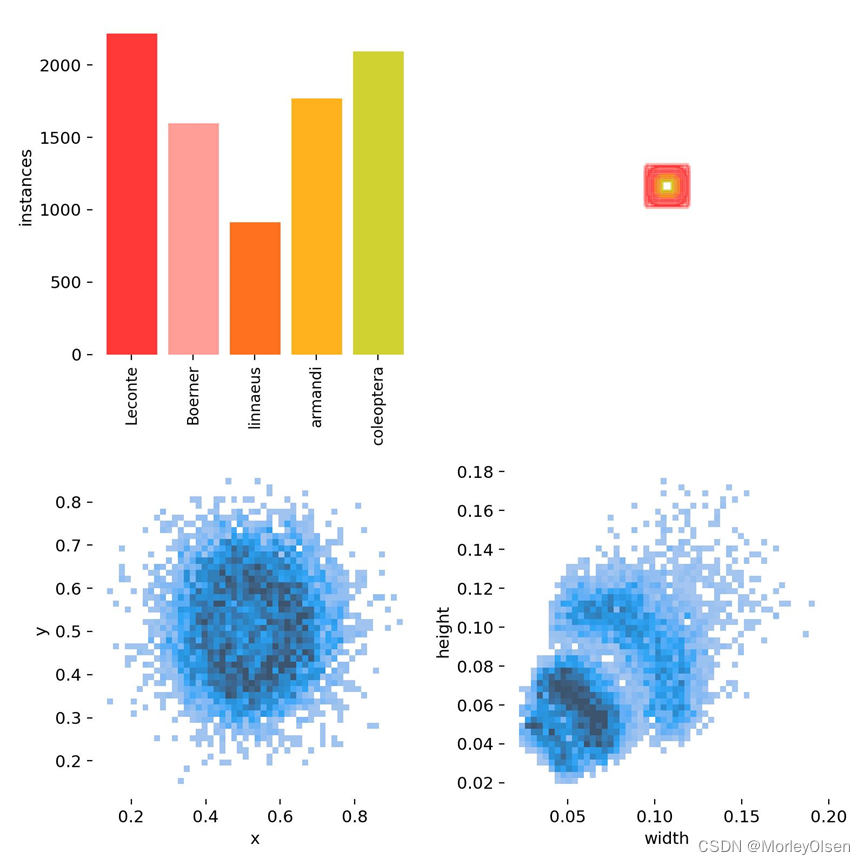
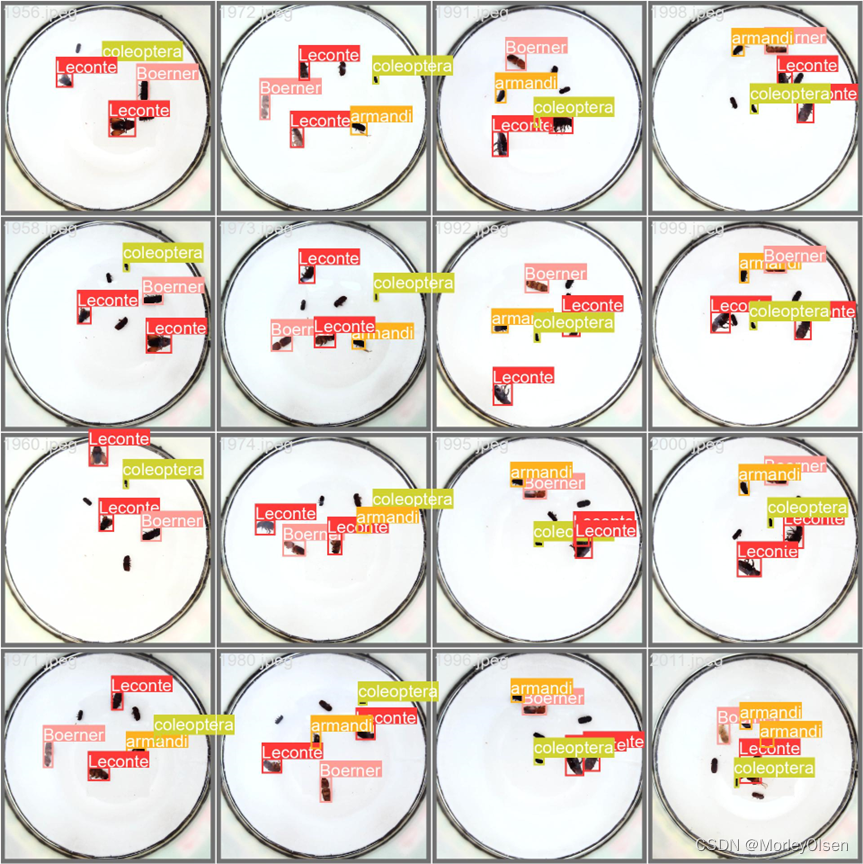
真实值的标签结果,如下图所示。
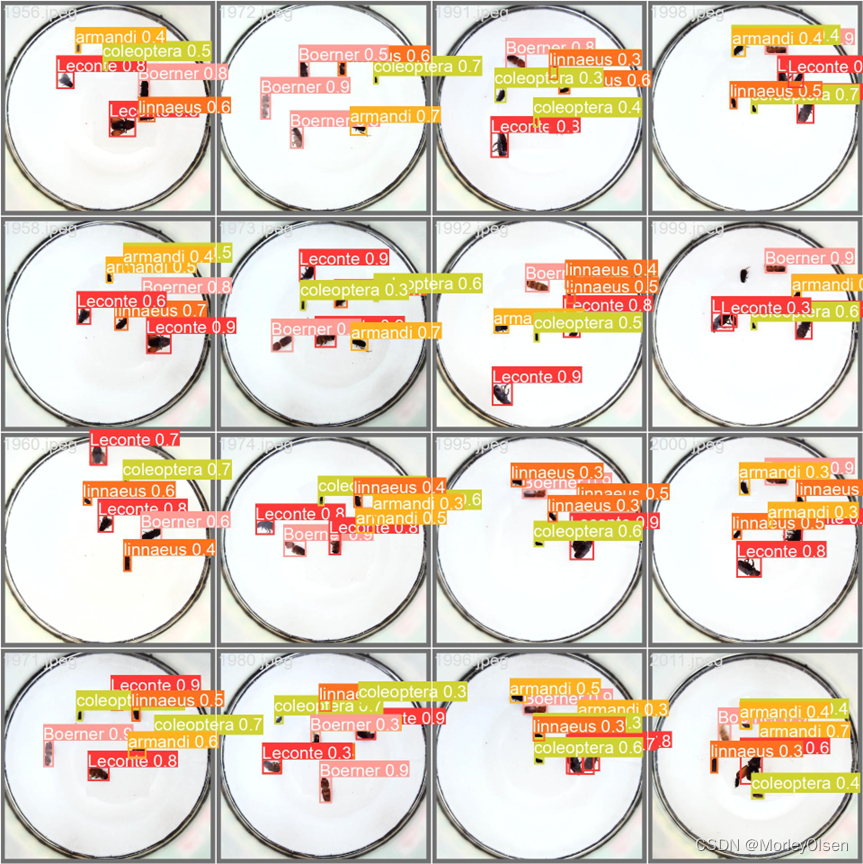
预测值的标签结果,如下图所示。
【模型测试过程】
由于测试集的数据量过大,因此此处仅展示具备代表性的一些案例结果。
案例1含有一些重复框,如下图所示。

案例2昆虫的排布较为分散,检测效果良好,如下图所示。

案例3存在漏检的昆虫,如下图所示。

七:实验结论与心得
1:one-stage算法由其算法结构决定了其准确率一般会低于two-stage算法, YOLO等one-stage算法凭借其更快的前向传播速度,获得了更加广泛的实际工业应用。
2:YOLO v3算法产生的预测框数目比Faster-RCNN少很多。Faster-RCNN中每个真实框可能对应多个标签为正的候选区域,而YOLO v3里面每个真实框只对应一个正的候选区域。
3:YOLOv3模型存在一些不足之处,如对小目标的检测能力相对较弱,以及在某些复杂场景下可能会出现误检或漏检的情况。
4:YOLOv3最主要的改进之处如下:
(1)更好的backbone:从YOLOv2的darknet-19到YOLOv3的darknet-53。
(2)多尺度预测:引入FPN。
(3)考虑到检测物体的重叠情况,用多标签的方式替代了之前softmax单标签方式,分类器不再使用softmax,损失函数中采用二分类交叉损失熵。
八:主要代码
| xml标注文件转txt |
| import os import xml.etree.ElementTree as ET def convert_xml_to_txt(xml_folder, txt_folder, class_list): if not os.path.exists(txt_folder): os.makedirs(txt_folder)
for xml_file in os.listdir(xml_folder): if xml_file.endswith('.xml'): tree = ET.parse(os.path.join(xml_folder, xml_file)) root = tree.getroot() txt_filename = os.path.splitext(xml_file)[0] + '.txt' with open(os.path.join(txt_folder, txt_filename), 'w') as txt_file: for obj in root.findall('object'): cls = obj.find('name').text if cls not in class_list: continue cls_id = class_list.index(cls) xmlbox = obj.find('bndbox') xmin = int(xmlbox.find('xmin').text) ymin = int(xmlbox.find('ymin').text) xmax = int(xmlbox.find('xmax').text) ymax = int(xmlbox.find('ymax').text) img_width = int(root.find('size').find('width').text) img_height = int(root.find('size').find('height').text) x_center = ((xmin + xmax) / 2) / img_width y_center = ((ymin + ymax) / 2) / img_height width = (xmax - xmin) / img_width height = (ymax - ymin) / img_height txt_file.write(f"{cls_id} {x_center:.6f} {y_center:.6f} {width:.6f} {height:.6f}\n") # 定义您的类别列表 classes = ['Leconte', 'Boerner', 'linnaeus', 'armandi', 'coleoptera'] # 转换 XML 文件 xmlpath = r"/home/ubuntu/yolov3/dataset/labels-xml/val" txtpath = r"/home/ubuntu/yolov3/dataset/labels/val" convert_xml_to_txt(xmlpath, txtpath, classes) |
| Data.yaml(数据加载) |
| # YOLOv5 🚀 by Ultralytics, AGPL-3.0 license # PASCAL VOC dataset http://host.robots.ox.ac.uk/pascal/VOC by University of Oxford # Example usage: python train.py --data VOC.yaml # parent # ├── yolov5 # └── datasets # └── VOC ← downloads here (2.8 GB) # Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..] path: ../datasets/VOC train: # train images (relative to 'path') 16551 images - /home/ubuntu/yolov3/dataset/images/train val: # val images (relative to 'path') 4952 images - /home/ubuntu/yolov3/dataset/images/val test: # test images (optional) # Classes names: 0: Leconte 1: Boerner 2: linnaeus 3: armandi 4: coleoptera |
| Yolov3-tiny.yaml(网络结构加载) |
| # YOLOv3 🚀 by Ultralytics, AGPL-3.0 license # Parameters nc: 5 # number of classes depth_multiple: 1.0 # model depth multiple width_multiple: 1.0 # layer channel multiple anchors: - [10, 14, 23, 27, 37, 58] # P4/16 - [81, 82, 135, 169, 344, 319] # P5/32 # YOLOv3-tiny backbone backbone: # [from, number, module, args] [ [-1, 1, Conv, [16, 3, 1]], # 0 [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 1-P1/2 [-1, 1, Conv, [32, 3, 1]], [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 3-P2/4 [-1, 1, Conv, [64, 3, 1]], [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 5-P3/8 [-1, 1, Conv, [128, 3, 1]], [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 7-P4/16 [-1, 1, Conv, [256, 3, 1]], [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 9-P5/32 [-1, 1, Conv, [512, 3, 1]], [-1, 1, nn.ZeroPad2d, [[0, 1, 0, 1]]], # 11 [-1, 1, nn.MaxPool2d, [2, 1, 0]], # 12 ] # YOLOv3-tiny head head: [ [-1, 1, Conv, [1024, 3, 1]], [-1, 1, Conv, [256, 1, 1]], [-1, 1, Conv, [512, 3, 1]], # 15 (P5/32-large) [-2, 1, Conv, [128, 1, 1]], [-1, 1, nn.Upsample, [None, 2, "nearest"]], [[-1, 8], 1, Concat, [1]], # cat backbone P4 [-1, 1, Conv, [256, 3, 1]], # 19 (P4/16-medium) [[19, 15], 1, Detect, [nc, anchors]], # Detect(P4, P5) ] |
| Train.py(模型训练) |
| # YOLOv3 🚀 by Ultralytics, AGPL-3.0 license """ Train a YOLOv3 model on a custom dataset. Models and datasets download automatically from the latest YOLOv3 release. Usage - Single-GPU training: $ python train.py --data coco128.yaml --weights yolov5s.pt --img 640 # from pretrained (recommended) $ python train.py --data coco128.yaml --weights '' --cfg yolov5s.yaml --img 640 # from scratch Usage - Multi-GPU DDP training: $ python -m torch.distributed.run --nproc_per_node 4 --master_port 1 train.py --data coco128.yaml --weights yolov5s.pt --img 640 --device 0,1,2,3 Models: https://github.com/ultralytics/yolov5/tree/master/models Datasets: https://github.com/ultralytics/yolov5/tree/master/data Tutorial: https://docs.ultralytics.com/yolov5/tutorials/train_custom_data """ import argparse import math import os import random import subprocess import sys import time from copy import deepcopy from datetime import datetime from pathlib import Path try: import comet_ml # must be imported before torch (if installed) except ImportError: comet_ml = None import numpy as np import torch import torch.distributed as dist import torch.nn as nn import yaml from torch.optim import lr_scheduler from tqdm import tqdm FILE = Path(__file__).resolve() ROOT = FILE.parents[0] # YOLOv3 root directory if str(ROOT) not in sys.path: sys.path.append(str(ROOT)) # add ROOT to PATH ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative import val as validate # for end-of-epoch mAP from models.experimental import attempt_load from models.yolo import Model from utils.autoanchor import check_anchors from utils.autobatch import check_train_batch_size from utils.callbacks import Callbacks from utils.dataloaders import create_dataloader from utils.downloads import attempt_download, is_url from utils.general import ( LOGGER, TQDM_BAR_FORMAT, check_amp, check_dataset, check_file, check_git_info, check_git_status, check_img_size, check_requirements, check_suffix, check_yaml, colorstr, get_latest_run, increment_path, init_seeds, intersect_dicts, labels_to_class_weights, labels_to_image_weights, methods, one_cycle, print_args, print_mutation, strip_optimizer, yaml_save, ) from utils.loggers import Loggers from utils.loggers.comet.comet_utils import check_comet_resume from utils.loss import ComputeLoss from utils.metrics import fitness from utils.plots import plot_evolve from utils.torch_utils import ( EarlyStopping, ModelEMA, de_parallel, select_device, smart_DDP, smart_optimizer, smart_resume, torch_distributed_zero_first, ) LOCAL_RANK = int(os.getenv("LOCAL_RANK", -1)) # https://pytorch.org/docs/stable/elastic/run.html RANK = int(os.getenv("RANK", -1)) WORLD_SIZE = int(os.getenv("WORLD_SIZE", 1)) GIT_INFO = check_git_info() def train(hyp, opt, device, callbacks): # hyp is path/to/hyp.yaml or hyp dictionary save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, freeze = ( Path(opt.save_dir), opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg, opt.resume, opt.noval, opt.nosave, opt.workers, opt.freeze, ) callbacks.run("on_pretrain_routine_start") # Directories w = save_dir / "weights" # weights dir (w.parent if evolve else w).mkdir(parents=True, exist_ok=True) # make dir last, best = w / "last.pt", w / "best.pt" # Hyperparameters if isinstance(hyp, str): with open(hyp, errors="ignore") as f: hyp = yaml.safe_load(f) # load hyps dict LOGGER.info(colorstr("hyperparameters: ") + ", ".join(f"{k}={v}" for k, v in hyp.items())) opt.hyp = hyp.copy() # for saving hyps to checkpoints # Save run settings if not evolve: yaml_save(save_dir / "hyp.yaml", hyp) yaml_save(save_dir / "opt.yaml", vars(opt)) # Loggers data_dict = None if RANK in {-1, 0}: loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance # Register actions for k in methods(loggers): callbacks.register_action(k, callback=getattr(loggers, k)) # Process custom dataset artifact link data_dict = loggers.remote_dataset if resume: # If resuming runs from remote artifact weights, epochs, hyp, batch_size = opt.weights, opt.epochs, opt.hyp, opt.batch_size # Config plots = not evolve and not opt.noplots # create plots cuda = device.type != "cpu" init_seeds(opt.seed + 1 + RANK, deterministic=True) with torch_distributed_zero_first(LOCAL_RANK): data_dict = data_dict or check_dataset(data) # check if None train_path, val_path = data_dict["train"], data_dict["val"] nc = 1 if single_cls else int(data_dict["nc"]) # number of classes names = {0: "item"} if single_cls and len(data_dict["names"]) != 1 else data_dict["names"] # class names is_coco = isinstance(val_path, str) and val_path.endswith("coco/val2017.txt") # COCO dataset # Model check_suffix(weights, ".pt") # check weights pretrained = weights.endswith(".pt") if pretrained: with torch_distributed_zero_first(LOCAL_RANK): weights = attempt_download(weights) # download if not found locally ckpt = torch.load(weights, map_location="cpu") # load checkpoint to CPU to avoid CUDA memory leak model = Model(cfg or ckpt["model"].yaml, ch=3, nc=nc, anchors=hyp.get("anchors")).to(device) # create exclude = ["anchor"] if (cfg or hyp.get("anchors")) and not resume else [] # exclude keys csd = ckpt["model"].float().state_dict() # checkpoint state_dict as FP32 csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersect model.load_state_dict(csd, strict=False) # load LOGGER.info(f"Transferred {len(csd)}/{len(model.state_dict())} items from {weights}") # report else: model = Model(cfg, ch=3, nc=nc, anchors=hyp.get("anchors")).to(device) # create amp = check_amp(model) # check AMP # Freeze freeze = [f"model.{x}." for x in (freeze if len(freeze) > 1 else range(freeze[0]))] # layers to freeze for k, v in model.named_parameters(): v.requires_grad = True # train all layers # v.register_hook(lambda x: torch.nan_to_num(x)) # NaN to 0 (commented for erratic training results) if any(x in k for x in freeze): LOGGER.info(f"freezing {k}") v.requires_grad = False # Image size gs = max(int(model.stride.max()), 32) # grid size (max stride) imgsz = check_img_size(opt.imgsz, gs, floor=gs * 2) # verify imgsz is gs-multiple # Batch size if RANK == -1 and batch_size == -1: # single-GPU only, estimate best batch size batch_size = check_train_batch_size(model, imgsz, amp) loggers.on_params_update({"batch_size": batch_size}) # Optimizer nbs = 64 # nominal batch size accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing hyp["weight_decay"] *= batch_size * accumulate / nbs # scale weight_decay optimizer = smart_optimizer(model, opt.optimizer, hyp["lr0"], hyp["momentum"], hyp["weight_decay"]) # Scheduler if opt.cos_lr: lf = one_cycle(1, hyp["lrf"], epochs) # cosine 1->hyp['lrf'] else: lf = lambda x: (1 - x / epochs) * (1.0 - hyp["lrf"]) + hyp["lrf"] # linear scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf) # plot_lr_scheduler(optimizer, scheduler, epochs) # EMA ema = ModelEMA(model) if RANK in {-1, 0} else None # Resume best_fitness, start_epoch = 0.0, 0 if pretrained: if resume: best_fitness, start_epoch, epochs = smart_resume(ckpt, optimizer, ema, weights, epochs, resume) del ckpt, csd # DP mode if cuda and RANK == -1 and torch.cuda.device_count() > 1: LOGGER.warning( "WARNING ⚠️ DP not recommended, use torch.distributed.run for best DDP Multi-GPU results.\n" "See Multi-GPU Tutorial at https://docs.ultralytics.com/yolov5/tutorials/multi_gpu_training to get started." ) model = torch.nn.DataParallel(model) # SyncBatchNorm if opt.sync_bn and cuda and RANK != -1: model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device) LOGGER.info("Using SyncBatchNorm()") # Trainloader train_loader, dataset = create_dataloader( train_path, imgsz, batch_size // WORLD_SIZE, gs, single_cls, hyp=hyp, augment=True, cache=None if opt.cache == "val" else opt.cache, rect=opt.rect, rank=LOCAL_RANK, workers=workers, image_weights=opt.image_weights, quad=opt.quad, prefix=colorstr("train: "), shuffle=True, seed=opt.seed, ) labels = np.concatenate(dataset.labels, 0) mlc = int(labels[:, 0].max()) # max label class assert mlc < nc, f"Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}" # Process 0 if RANK in {-1, 0}: val_loader = create_dataloader( val_path, imgsz, batch_size // WORLD_SIZE * 2, gs, single_cls, hyp=hyp, cache=None if noval else opt.cache, rect=True, rank=-1, workers=workers * 2, pad=0.5, prefix=colorstr("val: "), )[0] if not resume: if not opt.noautoanchor: check_anchors(dataset, model=model, thr=hyp["anchor_t"], imgsz=imgsz) # run AutoAnchor model.half().float() # pre-reduce anchor precision callbacks.run("on_pretrain_routine_end", labels, names) # DDP mode if cuda and RANK != -1: model = smart_DDP(model) # Model attributes nl = de_parallel(model).model[-1].nl # number of detection layers (to scale hyps) hyp["box"] *= 3 / nl # scale to layers hyp["cls"] *= nc / 80 * 3 / nl # scale to classes and layers hyp["obj"] *= (imgsz / 640) ** 2 * 3 / nl # scale to image size and layers hyp["label_smoothing"] = opt.label_smoothing model.nc = nc # attach number of classes to model model.hyp = hyp # attach hyperparameters to model model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc # attach class weights model.names = names # Start training t0 = time.time() nb = len(train_loader) # number of batches nw = max(round(hyp["warmup_epochs"] * nb), 100) # number of warmup iterations, max(3 epochs, 100 iterations) # nw = min(nw, (epochs - start_epoch) / 2 * nb) # limit warmup to < 1/2 of training last_opt_step = -1 maps = np.zeros(nc) # mAP per class results = (0, 0, 0, 0, 0, 0, 0) # P, R, mAP@.5, mAP@.5-.95, val_loss(box, obj, cls) scheduler.last_epoch = start_epoch - 1 # do not move scaler = torch.cuda.amp.GradScaler(enabled=amp) stopper, stop = EarlyStopping(patience=opt.patience), False compute_loss = ComputeLoss(model) # init loss class callbacks.run("on_train_start") LOGGER.info( f'Image sizes {imgsz} train, {imgsz} val\n' f'Using {train_loader.num_workers * WORLD_SIZE} dataloader workers\n' f"Logging results to {colorstr('bold', save_dir)}\n" f'Starting training for {epochs} epochs...' ) for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------ callbacks.run("on_train_epoch_start") model.train() # Update image weights (optional, single-GPU only) if opt.image_weights: cw = model.class_weights.cpu().numpy() * (1 - maps) ** 2 / nc # class weights iw = labels_to_image_weights(dataset.labels, nc=nc, class_weights=cw) # image weights dataset.indices = random.choices(range(dataset.n), weights=iw, k=dataset.n) # rand weighted idx # Update mosaic border (optional) # b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs) # dataset.mosaic_border = [b - imgsz, -b] # height, width borders mloss = torch.zeros(3, device=device) # mean losses if RANK != -1: train_loader.sampler.set_epoch(epoch) pbar = enumerate(train_loader) LOGGER.info(("\n" + "%11s" * 7) % ("Epoch", "GPU_mem", "box_loss", "obj_loss", "cls_loss", "Instances", "Size")) if RANK in {-1, 0}: pbar = tqdm(pbar, total=nb, bar_format=TQDM_BAR_FORMAT) # progress bar optimizer.zero_grad() for i, (imgs, targets, paths, _) in pbar: # batch ------------------------------------------------------------- callbacks.run("on_train_batch_start") ni = i + nb * epoch # number integrated batches (since train start) imgs = imgs.to(device, non_blocking=True).float() / 255 # uint8 to float32, 0-255 to 0.0-1.0 # Warmup if ni <= nw: xi = [0, nw] # x interp # compute_loss.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou) accumulate = max(1, np.interp(ni, xi, [1, nbs / batch_size]).round()) for j, x in enumerate(optimizer.param_groups): # bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0 x["lr"] = np.interp(ni, xi, [hyp["warmup_bias_lr"] if j == 0 else 0.0, x["initial_lr"] * lf(epoch)]) if "momentum" in x: x["momentum"] = np.interp(ni, xi, [hyp["warmup_momentum"], hyp["momentum"]]) # Multi-scale if opt.multi_scale: sz = random.randrange(int(imgsz * 0.5), int(imgsz * 1.5) + gs) // gs * gs # size sf = sz / max(imgs.shape[2:]) # scale factor if sf != 1: ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple) imgs = nn.functional.interpolate(imgs, size=ns, mode="bilinear", align_corners=False) # Forward with torch.cuda.amp.autocast(amp): pred = model(imgs) # forward loss, loss_items = compute_loss(pred, targets.to(device)) # loss scaled by batch_size if RANK != -1: loss *= WORLD_SIZE # gradient averaged between devices in DDP mode if opt.quad: loss *= 4.0 # Backward scaler.scale(loss).backward() # Optimize - https://pytorch.org/docs/master/notes/amp_examples.html if ni - last_opt_step >= accumulate: scaler.unscale_(optimizer) # unscale gradients torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=10.0) # clip gradients scaler.step(optimizer) # optimizer.step scaler.update() optimizer.zero_grad() if ema: ema.update(model) last_opt_step = ni # Log if RANK in {-1, 0}: mloss = (mloss * i + loss_items) / (i + 1) # update mean losses mem = f"{torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0:.3g}G" # (GB) pbar.set_description( ("%11s" * 2 + "%11.4g" * 5) % (f"{epoch}/{epochs - 1}", mem, *mloss, targets.shape[0], imgs.shape[-1]) ) callbacks.run("on_train_batch_end", model, ni, imgs, targets, paths, list(mloss)) if callbacks.stop_training: return # end batch ------------------------------------------------------------------------------------------------ # Scheduler lr = [x["lr"] for x in optimizer.param_groups] # for loggers scheduler.step() if RANK in {-1, 0}: # mAP callbacks.run("on_train_epoch_end", epoch=epoch) ema.update_attr(model, include=["yaml", "nc", "hyp", "names", "stride", "class_weights"]) final_epoch = (epoch + 1 == epochs) or stopper.possible_stop if not noval or final_epoch: # Calculate mAP results, maps, _ = validate.run( data_dict, batch_size=batch_size // WORLD_SIZE * 2, imgsz=imgsz, half=amp, model=ema.ema, single_cls=single_cls, dataloader=val_loader, save_dir=save_dir, plots=False, callbacks=callbacks, compute_loss=compute_loss, ) # Update best mAP fi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95] stop = stopper(epoch=epoch, fitness=fi) # early stop check if fi > best_fitness: best_fitness = fi log_vals = list(mloss) + list(results) + lr callbacks.run("on_fit_epoch_end", log_vals, epoch, best_fitness, fi) # Save model if (not nosave) or (final_epoch and not evolve): # if save ckpt = { "epoch": epoch, "best_fitness": best_fitness, "model": deepcopy(de_parallel(model)).half(), "ema": deepcopy(ema.ema).half(), "updates": ema.updates, "optimizer": optimizer.state_dict(), "opt": vars(opt), "git": GIT_INFO, # {remote, branch, commit} if a git repo "date": datetime.now().isoformat(), } # Save last, best and delete torch.save(ckpt, last) if best_fitness == fi: torch.save(ckpt, best) if opt.save_period > 0 and epoch % opt.save_period == 0: torch.save(ckpt, w / f"epoch{epoch}.pt") del ckpt callbacks.run("on_model_save", last, epoch, final_epoch, best_fitness, fi) # EarlyStopping if RANK != -1: # if DDP training broadcast_list = [stop if RANK == 0 else None] dist.broadcast_object_list(broadcast_list, 0) # broadcast 'stop' to all ranks if RANK != 0: stop = broadcast_list[0] if stop: break # must break all DDP ranks # end epoch ---------------------------------------------------------------------------------------------------- # end training ----------------------------------------------------------------------------------------------------- if RANK in {-1, 0}: LOGGER.info(f"\n{epoch - start_epoch + 1} epochs completed in {(time.time() - t0) / 3600:.3f} hours.") for f in last, best: if f.exists(): strip_optimizer(f) # strip optimizers if f is best: LOGGER.info(f"\nValidating {f}...") results, _, _ = validate.run( data_dict, batch_size=batch_size // WORLD_SIZE * 2, imgsz=imgsz, model=attempt_load(f, device).half(), iou_thres=0.65 if is_coco else 0.60, # best pycocotools at iou 0.65 single_cls=single_cls, dataloader=val_loader, save_dir=save_dir, save_json=is_coco, verbose=True, plots=plots, callbacks=callbacks, compute_loss=compute_loss, ) # val best model with plots if is_coco: callbacks.run("on_fit_epoch_end", list(mloss) + list(results) + lr, epoch, best_fitness, fi) callbacks.run("on_train_end", last, best, epoch, results) torch.cuda.empty_cache() return results def parse_opt(known=False): parser = argparse.ArgumentParser() parser.add_argument("--weights", type=str, default=ROOT / "weights/yolov3.pt", help="initial weights path") parser.add_argument("--cfg", type=str, default=ROOT / "models/yolov3-tiny.yaml", help="model.yaml path") parser.add_argument("--data", type=str, default=ROOT / "voc.yaml", help="dataset.yaml path") parser.add_argument("--hyp", type=str, default=ROOT / "data/hyps/hyp.scratch-low.yaml", help="hyperparameters path") parser.add_argument("--epochs", type=int, default=30, help="total training epochs") parser.add_argument("--batch-size", type=int, default=16, help="total batch size for all GPUs, -1 for autobatch") parser.add_argument("--imgsz", "--img", "--img-size", type=int, default=640, help="train, val image size (pixels)") parser.add_argument("--rect", action="store_true", help="rectangular training") parser.add_argument("--resume", nargs="?", const=True, default=False, help="resume most recent training") parser.add_argument("--nosave", action="store_true", help="only save final checkpoint") parser.add_argument("--noval", action="store_true", help="only validate final epoch") parser.add_argument("--noautoanchor", action="store_true", help="disable AutoAnchor") parser.add_argument("--noplots", action="store_true", help="save no plot files") parser.add_argument("--evolve", type=int, nargs="?", const=300, help="evolve hyperparameters for x generations") parser.add_argument("--bucket", type=str, default="", help="gsutil bucket") parser.add_argument("--cache", type=str, nargs="?", const="ram", help="image --cache ram/disk") parser.add_argument("--image-weights", action="store_true", help="use weighted image selection for training") parser.add_argument("--device", default="0", help="cuda device, i.e. 0 or 0,1,2,3 or cpu") parser.add_argument("--multi-scale", action="store_true", help="vary img-size +/- 50%%") parser.add_argument("--single-cls", action="store_true", help="train multi-class data as single-class") parser.add_argument("--optimizer", type=str, choices=["SGD", "Adam", "AdamW"], default="SGD", help="optimizer") parser.add_argument("--sync-bn", action="store_true", help="use SyncBatchNorm, only available in DDP mode") parser.add_argument("--workers", type=int, default=8, help="max dataloader workers (per RANK in DDP mode)") parser.add_argument("--project", default=ROOT / "runs/train", help="save to project/name") parser.add_argument("--name", default="exp", help="save to project/name") parser.add_argument("--exist-ok", action="store_true", help="existing project/name ok, do not increment") parser.add_argument("--quad", action="store_true", help="quad dataloader") parser.add_argument("--cos-lr", action="store_true", help="cosine LR scheduler") parser.add_argument("--label-smoothing", type=float, default=0.0, help="Label smoothing epsilon") parser.add_argument("--patience", type=int, default=100, help="EarlyStopping patience (epochs without improvement)") parser.add_argument("--freeze", nargs="+", type=int, default=[0], help="Freeze layers: backbone=10, first3=0 1 2") parser.add_argument("--save-period", type=int, default=-1, help="Save checkpoint every x epochs (disabled if < 1)") parser.add_argument("--seed", type=int, default=0, help="Global training seed") parser.add_argument("--local_rank", type=int, default=-1, help="Automatic DDP Multi-GPU argument, do not modify") # Logger arguments parser.add_argument("--entity", default=None, help="Entity") parser.add_argument("--upload_dataset", nargs="?", const=True, default=False, help='Upload data, "val" option') parser.add_argument("--bbox_interval", type=int, default=-1, help="Set bounding-box image logging interval") parser.add_argument("--artifact_alias", type=str, default="latest", help="Version of dataset artifact to use") return parser.parse_known_args()[0] if known else parser.parse_args() def main(opt, callbacks=Callbacks()): # Checks if RANK in {-1, 0}: print_args(vars(opt)) check_git_status() check_requirements(ROOT / "requirements.txt") # Resume (from specified or most recent last.pt) if opt.resume and not check_comet_resume(opt) and not opt.evolve: last = Path(check_file(opt.resume) if isinstance(opt.resume, str) else get_latest_run()) opt_yaml = last.parent.parent / "opt.yaml" # train options yaml opt_data = opt.data # original dataset if opt_yaml.is_file(): with open(opt_yaml, errors="ignore") as f: d = yaml.safe_load(f) else: d = torch.load(last, map_location="cpu")["opt"] opt = argparse.Namespace(**d) # replace opt.cfg, opt.weights, opt.resume = "", str(last), True # reinstate if is_url(opt_data): opt.data = check_file(opt_data) # avoid HUB resume auth timeout else: opt.data, opt.cfg, opt.hyp, opt.weights, opt.project = ( check_file(opt.data), check_yaml(opt.cfg), check_yaml(opt.hyp), str(opt.weights), str(opt.project), ) # checks assert len(opt.cfg) or len(opt.weights), "either --cfg or --weights must be specified" if opt.evolve: if opt.project == str(ROOT / "runs/train"): # if default project name, rename to runs/evolve opt.project = str(ROOT / "runs/evolve") opt.exist_ok, opt.resume = opt.resume, False # pass resume to exist_ok and disable resume if opt.name == "cfg": opt.name = Path(opt.cfg).stem # use model.yaml as name opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok)) # DDP mode device = select_device(opt.device, batch_size=opt.batch_size) if LOCAL_RANK != -1: msg = "is not compatible with YOLOv3 Multi-GPU DDP training" assert not opt.image_weights, f"--image-weights {msg}" assert not opt.evolve, f"--evolve {msg}" assert opt.batch_size != -1, f"AutoBatch with --batch-size -1 {msg}, please pass a valid --batch-size" assert opt.batch_size % WORLD_SIZE == 0, f"--batch-size {opt.batch_size} must be multiple of WORLD_SIZE" assert torch.cuda.device_count() > LOCAL_RANK, "insufficient CUDA devices for DDP command" torch.cuda.set_device(LOCAL_RANK) device = torch.device("cuda", LOCAL_RANK) dist.init_process_group(backend="nccl" if dist.is_nccl_available() else "gloo") # Train if not opt.evolve: train(opt.hyp, opt, device, callbacks) # Evolve hyperparameters (optional) else: # Hyperparameter evolution metadata (mutation scale 0-1, lower_limit, upper_limit) meta = { "lr0": (1, 1e-5, 1e-1), # initial learning rate (SGD=1E-2, Adam=1E-3) "lrf": (1, 0.01, 1.0), # final OneCycleLR learning rate (lr0 * lrf) "momentum": (0.3, 0.6, 0.98), # SGD momentum/Adam beta1 "weight_decay": (1, 0.0, 0.001), # optimizer weight decay "warmup_epochs": (1, 0.0, 5.0), # warmup epochs (fractions ok) "warmup_momentum": (1, 0.0, 0.95), # warmup initial momentum "warmup_bias_lr": (1, 0.0, 0.2), # warmup initial bias lr "box": (1, 0.02, 0.2), # box loss gain "cls": (1, 0.2, 4.0), # cls loss gain "cls_pw": (1, 0.5, 2.0), # cls BCELoss positive_weight "obj": (1, 0.2, 4.0), # obj loss gain (scale with pixels) "obj_pw": (1, 0.5, 2.0), # obj BCELoss positive_weight "iou_t": (0, 0.1, 0.7), # IoU training threshold "anchor_t": (1, 2.0, 8.0), # anchor-multiple threshold "anchors": (2, 2.0, 10.0), # anchors per output grid (0 to ignore) "fl_gamma": (0, 0.0, 2.0), # focal loss gamma (efficientDet default gamma=1.5) "hsv_h": (1, 0.0, 0.1), # image HSV-Hue augmentation (fraction) "hsv_s": (1, 0.0, 0.9), # image HSV-Saturation augmentation (fraction) "hsv_v": (1, 0.0, 0.9), # image HSV-Value augmentation (fraction) "degrees": (1, 0.0, 45.0), # image rotation (+/- deg) "translate": (1, 0.0, 0.9), # image translation (+/- fraction) "scale": (1, 0.0, 0.9), # image scale (+/- gain) "shear": (1, 0.0, 10.0), # image shear (+/- deg) "perspective": (0, 0.0, 0.001), # image perspective (+/- fraction), range 0-0.001 "flipud": (1, 0.0, 1.0), # image flip up-down (probability) "fliplr": (0, 0.0, 1.0), # image flip left-right (probability) "mosaic": (1, 0.0, 1.0), # image mixup (probability) "mixup": (1, 0.0, 1.0), # image mixup (probability) "copy_paste": (1, 0.0, 1.0), } # segment copy-paste (probability) with open(opt.hyp, errors="ignore") as f: hyp = yaml.safe_load(f) # load hyps dict if "anchors" not in hyp: # anchors commented in hyp.yaml hyp["anchors"] = 3 if opt.noautoanchor: del hyp["anchors"], meta["anchors"] opt.noval, opt.nosave, save_dir = True, True, Path(opt.save_dir) # only val/save final epoch # ei = [isinstance(x, (int, float)) for x in hyp.values()] # evolvable indices evolve_yaml, evolve_csv = save_dir / "hyp_evolve.yaml", save_dir / "evolve.csv" if opt.bucket: # download evolve.csv if exists subprocess.run( [ "gsutil", "cp", f"gs://{opt.bucket}/evolve.csv", str(evolve_csv), ] ) for _ in range(opt.evolve): # generations to evolve if evolve_csv.exists(): # if evolve.csv exists: select best hyps and mutate # Select parent(s) parent = "single" # parent selection method: 'single' or 'weighted' x = np.loadtxt(evolve_csv, ndmin=2, delimiter=",", skiprows=1) n = min(5, len(x)) # number of previous results to consider x = x[np.argsort(-fitness(x))][:n] # top n mutations w = fitness(x) - fitness(x).min() + 1e-6 # weights (sum > 0) if parent == "single" or len(x) == 1: # x = x[random.randint(0, n - 1)] # random selection x = x[random.choices(range(n), weights=w)[0]] # weighted selection elif parent == "weighted": x = (x * w.reshape(n, 1)).sum(0) / w.sum() # weighted combination # Mutate mp, s = 0.8, 0.2 # mutation probability, sigma npr = np.random npr.seed(int(time.time())) g = np.array([meta[k][0] for k in hyp.keys()]) # gains 0-1 ng = len(meta) v = np.ones(ng) while all(v == 1): # mutate until a change occurs (prevent duplicates) v = (g * (npr.random(ng) < mp) * npr.randn(ng) * npr.random() * s + 1).clip(0.3, 3.0) for i, k in enumerate(hyp.keys()): # plt.hist(v.ravel(), 300) hyp[k] = float(x[i + 7] * v[i]) # mutate # Constrain to limits for k, v in meta.items(): hyp[k] = max(hyp[k], v[1]) # lower limit hyp[k] = min(hyp[k], v[2]) # upper limit hyp[k] = round(hyp[k], 5) # significant digits # Train mutation results = train(hyp.copy(), opt, device, callbacks) callbacks = Callbacks() # Write mutation results keys = ( "metrics/precision", "metrics/recall", "metrics/mAP_0.5", "metrics/mAP_0.5:0.95", "val/box_loss", "val/obj_loss", "val/cls_loss", ) print_mutation(keys, results, hyp.copy(), save_dir, opt.bucket) # Plot results plot_evolve(evolve_csv) LOGGER.info( f'Hyperparameter evolution finished {opt.evolve} generations\n' f"Results saved to {colorstr('bold', save_dir)}\n" f'Usage example: $ python train.py --hyp {evolve_yaml}' ) def run(**kwargs): # Usage: import train; train.run(data='coco128.yaml', imgsz=320, weights='yolov5m.pt') opt = parse_opt(True) for k, v in kwargs.items(): setattr(opt, k, v) main(opt) return opt if __name__ == "__main__": opt = parse_opt() main(opt) |
| Detect.py(测试模型) |
| # YOLOv3 🚀 by Ultralytics, AGPL-3.0 license """ Run YOLOv3 detection inference on images, videos, directories, globs, YouTube, webcam, streams, etc. Usage - sources: $ python detect.py --weights yolov5s.pt --source 0 # webcam img.jpg # image vid.mp4 # video screen # screenshot path/ # directory list.txt # list of images list.streams # list of streams 'path/*.jpg' # glob 'https://youtu.be/LNwODJXcvt4' # YouTube 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream Usage - formats: $ python detect.py --weights yolov5s.pt # PyTorch yolov5s.torchscript # TorchScript yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn yolov5s_openvino_model # OpenVINO yolov5s.engine # TensorRT yolov5s.mlmodel # CoreML (macOS-only) yolov5s_saved_model # TensorFlow SavedModel yolov5s.pb # TensorFlow GraphDef yolov5s.tflite # TensorFlow Lite yolov5s_edgetpu.tflite # TensorFlow Edge TPU yolov5s_paddle_model # PaddlePaddle """ import argparse import os import platform import sys from pathlib import Path import torch FILE = Path(__file__).resolve() ROOT = FILE.parents[0] # YOLOv3 root directory if str(ROOT) not in sys.path: sys.path.append(str(ROOT)) # add ROOT to PATH ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative from ultralytics.utils.plotting import Annotator, colors, save_one_box from models.common import DetectMultiBackend from utils.dataloaders import IMG_FORMATS, VID_FORMATS, LoadImages, LoadScreenshots, LoadStreams from utils.general import ( LOGGER, Profile, check_file, check_img_size, check_imshow, check_requirements, colorstr, cv2, increment_path, non_max_suppression, print_args, scale_boxes, strip_optimizer, xyxy2xywh, ) from utils.torch_utils import select_device, smart_inference_mode @smart_inference_mode() def run( weights=ROOT / "yolov5s.pt", # model path or triton URL source=ROOT / "data/images", # file/dir/URL/glob/screen/0(webcam) data=ROOT / "data/coco128.yaml", # dataset.yaml path imgsz=(1262,1262), # inference size (height, width) conf_thres=0.25, # confidence threshold iou_thres=0.45, # NMS IOU threshold max_det=1000, # maximum detections per image device="", # cuda device, i.e. 0 or 0,1,2,3 or cpu view_img=False, # show results save_txt=False, # save results to *.txt save_conf=False, # save confidences in --save-txt labels save_crop=False, # save cropped prediction boxes nosave=False, # do not save images/videos classes=None, # filter by class: --class 0, or --class 0 2 3 agnostic_nms=False, # class-agnostic NMS augment=False, # augmented inference visualize=False, # visualize features update=False, # update all models project=ROOT / "runs/detect", # save results to project/name name="exp", # save results to project/name exist_ok=False, # existing project/name ok, do not increment line_thickness=3, # bounding box thickness (pixels) hide_labels=False, # hide labels hide_conf=False, # hide confidences half=False, # use FP16 half-precision inference dnn=False, # use OpenCV DNN for ONNX inference vid_stride=1, # video frame-rate stride ): source = str(source) save_img = not nosave and not source.endswith(".txt") # save inference images is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS) is_url = source.lower().startswith(("rtsp://", "rtmp://", "http://", "https://")) webcam = source.isnumeric() or source.endswith(".streams") or (is_url and not is_file) screenshot = source.lower().startswith("screen") if is_url and is_file: source = check_file(source) # download # Directories save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run (save_dir / "labels" if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir # Load model device = select_device(device) model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half) stride, names, pt = model.stride, model.names, model.pt imgsz = check_img_size(imgsz, s=stride) # check image size # Dataloader bs = 1 # batch_size if webcam: view_img = check_imshow(warn=True) dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride) bs = len(dataset) elif screenshot: dataset = LoadScreenshots(source, img_size=imgsz, stride=stride, auto=pt) else: dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride) vid_path, vid_writer = [None] * bs, [None] * bs # Run inference model.warmup(imgsz=(1 if pt or model.triton else bs, 3, *imgsz)) # warmup seen, windows, dt = 0, [], (Profile(), Profile(), Profile()) for path, im, im0s, vid_cap, s in dataset: with dt[0]: im = torch.from_numpy(im).to(model.device) im = im.half() if model.fp16 else im.float() # uint8 to fp16/32 im /= 255 # 0 - 255 to 0.0 - 1.0 if len(im.shape) == 3: im = im[None] # expand for batch dim # Inference with dt[1]: visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False pred = model(im, augment=augment, visualize=visualize) # NMS with dt[2]: pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det) # Second-stage classifier (optional) # pred = utils.general.apply_classifier(pred, classifier_model, im, im0s) # Process predictions for i, det in enumerate(pred): # per image seen += 1 if webcam: # batch_size >= 1 p, im0, frame = path[i], im0s[i].copy(), dataset.count s += f"{i}: " else: p, im0, frame = path, im0s.copy(), getattr(dataset, "frame", 0) p = Path(p) # to Path save_path = str(save_dir / p.name) # im.jpg txt_path = str(save_dir / "labels" / p.stem) + ("" if dataset.mode == "image" else f"_{frame}") # im.txt s += "%gx%g " % im.shape[2:] # print string gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh imc = im0.copy() if save_crop else im0 # for save_crop annotator = Annotator(im0, line_width=line_thickness, example=str(names)) if len(det): # Rescale boxes from img_size to im0 size det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], im0.shape).round() # Print results for c in det[:, 5].unique(): n = (det[:, 5] == c).sum() # detections per class s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string # Write results for *xyxy, conf, cls in reversed(det): if save_txt: # Write to file xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format with open(f"{txt_path}.txt", "a") as f: f.write(("%g " * len(line)).rstrip() % line + "\n") if save_img or save_crop or view_img: # Add bbox to image c = int(cls) # integer class label = None if hide_labels else (names[c] if hide_conf else f"{names[c]} {conf:.2f}") annotator.box_label(xyxy, label, color=colors(c, True)) if save_crop: save_one_box(xyxy, imc, file=save_dir / "crops" / names[c] / f"{p.stem}.jpg", BGR=True) # Stream results im0 = annotator.result() if view_img: if platform.system() == "Linux" and p not in windows: windows.append(p) cv2.namedWindow(str(p), cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO) # allow window resize (Linux) cv2.resizeWindow(str(p), im0.shape[1], im0.shape[0]) cv2.imshow(str(p), im0) cv2.waitKey(1) # 1 millisecond # Save results (image with detections) if save_img: if dataset.mode == "image": cv2.imwrite(save_path, im0) else: # 'video' or 'stream' if vid_path[i] != save_path: # new video vid_path[i] = save_path if isinstance(vid_writer[i], cv2.VideoWriter): vid_writer[i].release() # release previous video writer if vid_cap: # video fps = vid_cap.get(cv2.CAP_PROP_FPS) w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH)) h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) else: # stream fps, w, h = 30, im0.shape[1], im0.shape[0] save_path = str(Path(save_path).with_suffix(".mp4")) # force *.mp4 suffix on results videos vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h)) vid_writer[i].write(im0) # Print time (inference-only) LOGGER.info(f"{s}{'' if len(det) else '(no detections), '}{dt[1].dt * 1E3:.1f}ms") # Print results t = tuple(x.t / seen * 1e3 for x in dt) # speeds per image LOGGER.info(f"Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {(1, 3, *imgsz)}" % t) if save_txt or save_img: s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else "" LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}") if update: strip_optimizer(weights[0]) # update model (to fix SourceChangeWarning) def parse_opt(): parser = argparse.ArgumentParser() parser.add_argument( "--weights", nargs="+", type=str, default=ROOT / "runs/train/exp3/weights/best.pt", help="model path or triton URL" ) parser.add_argument("--source", type=str, default=ROOT / "dataset/test", help="file/dir/URL/glob/screen/0(webcam)") parser.add_argument("--data", type=str, default=ROOT / "voc.yaml", help="(optional) dataset.yaml path") parser.add_argument("--imgsz", "--img", "--img-size", nargs="+", type=int, default=[1262], help="inference size h,w") parser.add_argument("--conf-thres", type=float, default=0.25, help="confidence threshold") parser.add_argument("--iou-thres", type=float, default=0.45, help="NMS IoU threshold") parser.add_argument("--max-det", type=int, default=1000, help="maximum detections per image") parser.add_argument("--device", default="0", help="cuda device, i.e. 0 or 0,1,2,3 or cpu") parser.add_argument("--view-img", action="store_true", help="show results") parser.add_argument("--save-txt", action="store_true", help="save results to *.txt") parser.add_argument("--save-conf", action="store_true", help="save confidences in --save-txt labels") parser.add_argument("--save-crop", action="store_true", help="save cropped prediction boxes") parser.add_argument("--nosave", action="store_true", help="do not save images/videos") parser.add_argument("--classes", nargs="+", type=int, help="filter by class: --classes 0, or --classes 0 2 3") parser.add_argument("--agnostic-nms", action="store_true", help="class-agnostic NMS") parser.add_argument("--augment", action="store_true", help="augmented inference") parser.add_argument("--visualize", action="store_true", help="visualize features") parser.add_argument("--update", action="store_true", help="update all models") parser.add_argument("--project", default=ROOT / "runs/detect", help="save results to project/name") parser.add_argument("--name", default="exp", help="save results to project/name") parser.add_argument("--exist-ok", action="store_true", help="existing project/name ok, do not increment") parser.add_argument("--line-thickness", default=3, type=int, help="bounding box thickness (pixels)") parser.add_argument("--hide-labels", default=False, action="store_true", help="hide labels") parser.add_argument("--hide-conf", default=False, action="store_true", help="hide confidences") parser.add_argument("--half", action="store_true", help="use FP16 half-precision inference") parser.add_argument("--dnn", action="store_true", help="use OpenCV DNN for ONNX inference") parser.add_argument("--vid-stride", type=int, default=1, help="video frame-rate stride") opt = parser.parse_args() opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand print_args(vars(opt)) return opt def main(opt): check_requirements(ROOT / "requirements.txt", exclude=("tensorboard", "thop")) run(**vars(opt)) if __name__ == "__main__": opt = parse_opt() main(opt) |