24年5月谷歌WayMo论文“UniGen: Unified Modeling of Initial Agent States and Trajectories for Generating Autonomous Driving Scenarios”。
本文介绍 UniGen,一种生成交通场景的新方法,用于通过仿真评估和改进自动驾驶软件。 其方法在一个统一的模型中对所有驾驶场景元素进行建模:新智体的位置、它们的初始状态以及它们未来的运动轨迹。 通过从共享的全局场景嵌入中预测所有这些变量的分布,确保最终生成的场景完全取决于现有场景所有可用的上下文。 将统一建模方法与自回归智体注入相结合,该方法基于所有现存智体及其轨迹调节每个新智体的放置和运动轨迹,从而产生了低碰撞率的真实场景。
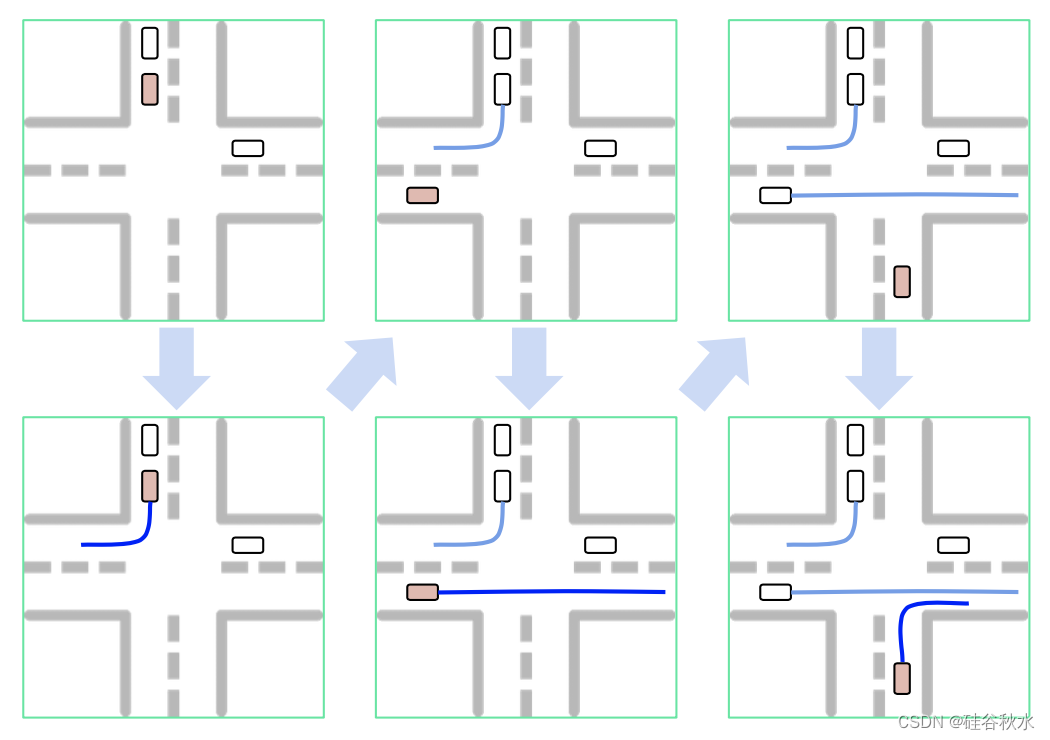
如图所示:UniGEN 的自回归过程,用于迭代地将新智体注入场景中。 在每次迭代中,模型都会完全实例化新智体(以粉色突出显示)的初始状态(顶部)和未来轨迹(底部)。 新智体的所有属性都以场景上下文和现有智体的整个轨迹为条件(以白色显示)。
将交通场景表示为(R,S),其中R表示场景上下文,包括道路布局以及交通灯的位置和状态,并且S = {si},i ∈ {1,…, N } 代表场景中存在的 N 个智体。 每个智体的状态 si 特征是其初始状态 si0 及其位于 T 个时间步 t ∈ {1,…,T}的未来轨迹。 初始智体状态 si0 捕获位置 (xit , y0i ) 和其他属性,包括宽度 wi、长度 li、航向角 θ0i 和速度 v0i。 每个智体的未来轨迹由 {si1,…,siT} 捕获。
任务是生成一个完整的驾驶场景 (R, S),给定场景上下文 R 和一组初始智体 Sc ⊂ S(可能为空)。 换句话说,希望生成所有智体状态 p(S|R, Sc) 的条件分布。
如图所示是UniGen的整体设计。 该模型由一个共享场景编码器和三个独立的解码器头组成:一个用于生成新智体位置的占用预测器,一个用于初始化智体状态的属性预测器,以及一个用于生成未来运动的轨迹预测器。 除了从所有输入生成嵌入的共享全场景编码器之外,还有一个每新智体的Transformer编码器,它从每个新智体位置的有利位置对表示道路布局的折线进行编码。 除了全局场景嵌入之外,该编码器生成的道路布局编码还传递给智体属性解码器和智体轨迹解码器。
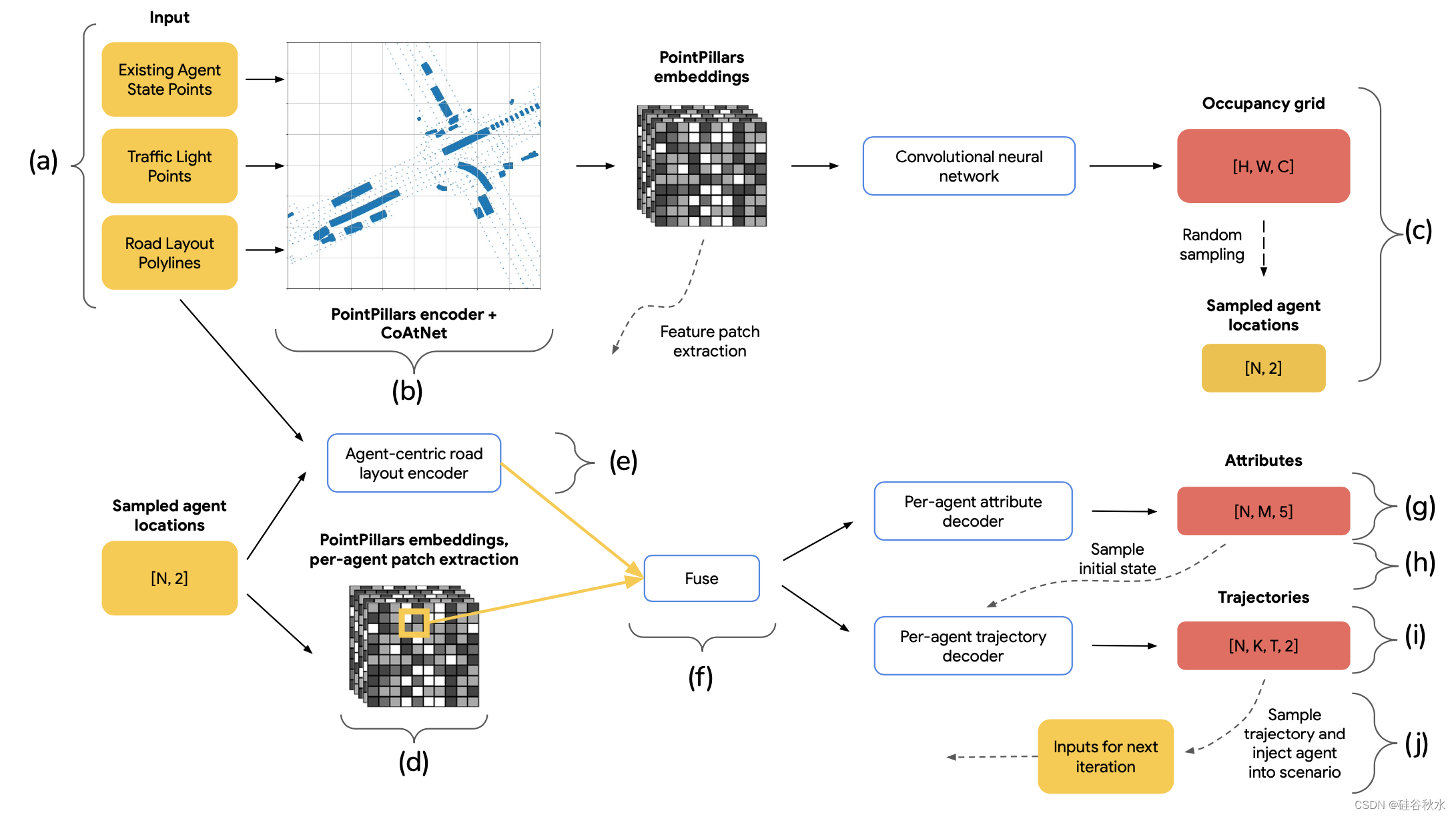
(a) 模型的稀疏输入包括道路布局的折线、代表交通信号灯的点以及从现有场景智体的 BEV 边框中均匀采样的点(如果有)。 (b) 这些点被编码成密集的场景嵌入。 三个独立的解码器预测要注入的新智体占用分布、它们的初始状态以及它们的未来轨迹。 © 占用解码器分别预测 C 个智体类的初始位置分布。 在每次迭代中,从占用热图中采样一个位置以注入新智体。 (d) 新智体的位置线性映射到密集场景嵌入中的位置,并提取该位置周围的特征块。 (e) 此外,以智体为中心的道路布局Transformer编码器提取并把归一化到注入位置坐标系的道路折线编码。 (f) 这种以智体为中心的道路布局编码与扁平化特征块融合,其通过1 层 MLP 从共享场景嵌入中提取。 (g) 将乘积馈送到属性解码器,将初始智体状态预测为 M模式的 5-D 多元混合分布。 (h) 对五个标量属性值进行采样,它们与采样的智体位置一起构成完整的初始智体状态。 (i) 除了来自 (f) 的融合特征编码之外,轨迹解码器还接收该初始智体状态,并预测一组 K 条轨迹以及跨越 T 个时间步长的相关概率。 每个轨迹路点都由 2D 高斯表示。 (j) 最后,从 K 个选择中采样单个轨迹。 至此,新智体已完全实例化。 新智体将添加到组件 (a) 中的场景输入中,并开始下一次迭代。 注意:在训练时,N 等于隐藏的真实智体数量。 在推理时,N 等于 1,用于在每次迭代中注入单个智体。
为了构建用于训练模型的真实数据,将真实智体随机分为两组输入和隐藏智体,将数据集中的每个真实场景转换为多个训练示例,如图所示。 被训练来预测隐藏智体的位置、属性和轨迹,仅将输入智体作为输入。 当生成每个真实示例时,首先对随机概率 pkeep 进行采样,以控制要保留在输入中的智体比例。 使用各种分数可以使模型在训练期间看到空旷和拥挤的场景。
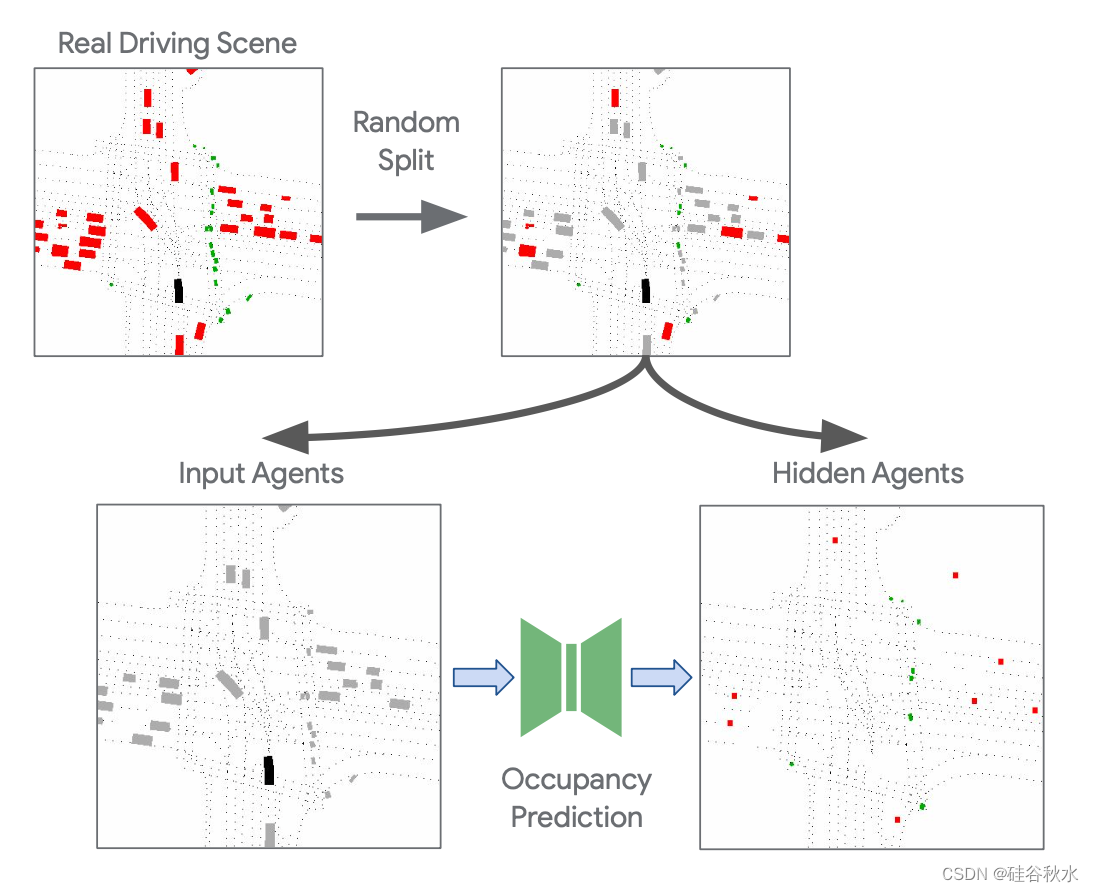
这种方法在概念上类似于 BERT [24] 和掩码自动编码器 [25]。 随机掩码鼓励模型学习场景动态,以便能够预测隐藏的智体信息。 此外,由于每个真实场景都可以以多种不同的方式进行分割,因此该策略有效地增加了可用的训练数据量。
遵循 StopNet [13],用稀疏输入,它可以充分捕获静态场景上下文以及由智体边框的位置和范围捕获的场景动态元素。 更具体地说,道路布局由多段线表示,这些多段线映射车道中心、车道边界、道路边界、人行横道、减速带和停车标志的位置。 交通信号灯的状态也作为放置在交通控制车道的末端点输入到模型中。 此外,该模型还接收从任何现有或之前注入的场景智体鸟瞰图 (BEV) 边框内部均匀采样的点作为输入。 为了对智体轨迹进行编码,为每个时间步长布置单独的边框,并为每个时间步长采样单独的点网格。 这些点携带对所有相关属性进行编码的特征向量,包括位置、航向、速度和表示时间步长的 one-hot 向量。 尽管很稀疏,但这种输入表示使模型可以轻松查看智体边框占据的区域。
所有稀疏输入均使用 PointPillars 编码器 [26] 立即进行编码,其中每个pillar使用多层感知器(MLP)对其中的点进行编码,并使用最大池化从它们中生成单个特征向量。 使用 CoAtNet 主干网 [27] 对密集特征图进行进一步编码,以对不同Pillar特征之间的全局交互进行编码,共享编码器的输出是密集特征图。
密集占用解码器输出初始位置的分布,供新智体插入到场景中。 它接收共享编码器的输出作为输入,并使用卷积神经网络将其解码为大小为 H × W 的 C 个不相交占用网格,对应于 C 个不同的智体类,例如车辆、行人、骑自行车的人。 真值占用网格是通过渲染隐藏(屏蔽)智体的中心点来构建的,如上图所示。
虽然共享场景嵌入对于捕获智体和道路元素之间的全局交互很有用,但其低空间分辨率对于回归位置敏感属性(如方向)并不理想,对于相反车道中的两个附近智体来说,这可能完全不同。 为此,在预测智体属性和轨迹时,用以智体为中心的道路布局嵌入来增强共享场景嵌入。
对于每个新智体,从共享编码器的输出中,双线性采样 k × k × Dd 特征块,其中 k 是固定的超参数。 共享嵌入中补丁的位置是将场景中的初始智体位置 (xi0, y0i) 线性映射到密集特征图 Hd × Wd 中的位置来确定的。 对于每个智体,从以智体为中心的道路布局编码器获得 1 × Dr 特征向量。 这两个特征图被展平并通过1层MLP以获得1×D特征向量。
当新智体的位置 (xi0 , y0i ) 是从占用网格中采样时,其他初始状态属性由属性解码器预测。属性解码器为每个初始状态属性 a 预测 M 个不同的模式和相关概率。 受轨迹预测方法[28]的启发,用分类和回归项组成的损失函数来学习属性的分布。
采用基于 Transformer 的轨迹解码器以及 MultiPath++ [29] 和 Wayformer [28] 的损失。 然而,这些轨迹预测方法需要智体当前和最近位置,而该方法可以仅根据在地图上任意位置采样的特征来预测轨迹。 轨迹解码器采用与属性解码器相同的输入,即来自共享场景嵌入的补丁以及智体周围道路布局折线的每智体编码。 轨迹解码器还接收智体的初始位置和航向作为初始状态。 此时初始位置已经确定。 在评估和推理时,初始方向由从属性解码器的输出采样的属性确定。 在训练时,只需使用隐藏智体的真实状态。
用一种自回归方法,通过每次向场景中注入一个新智体,在推理时生成新场景。对于每个新智体,首先从占用网格中预测的智体位置分布中采样初始位置 (xi0, y0i )。 该采样位置用于提取预测初始状态属性分布所需的融合特征向量。 从此分布中采样一组属性即可实例化智体的初始状态。 该初始智体状态与融合特征向量一起用于预测智体未来轨迹的分布。 然后从该分布中采样特定轨迹以完全实例化并注入智体,完成自回归生成的一次迭代。 在下一次迭代中,新生成的智体将作为模型输入的一部分包含在内,影响模型生成的后续智体所有属性。 这种自回归方法与统一模型相结合,产生了智体初始状态和未来轨迹彼此一致的现实场景。
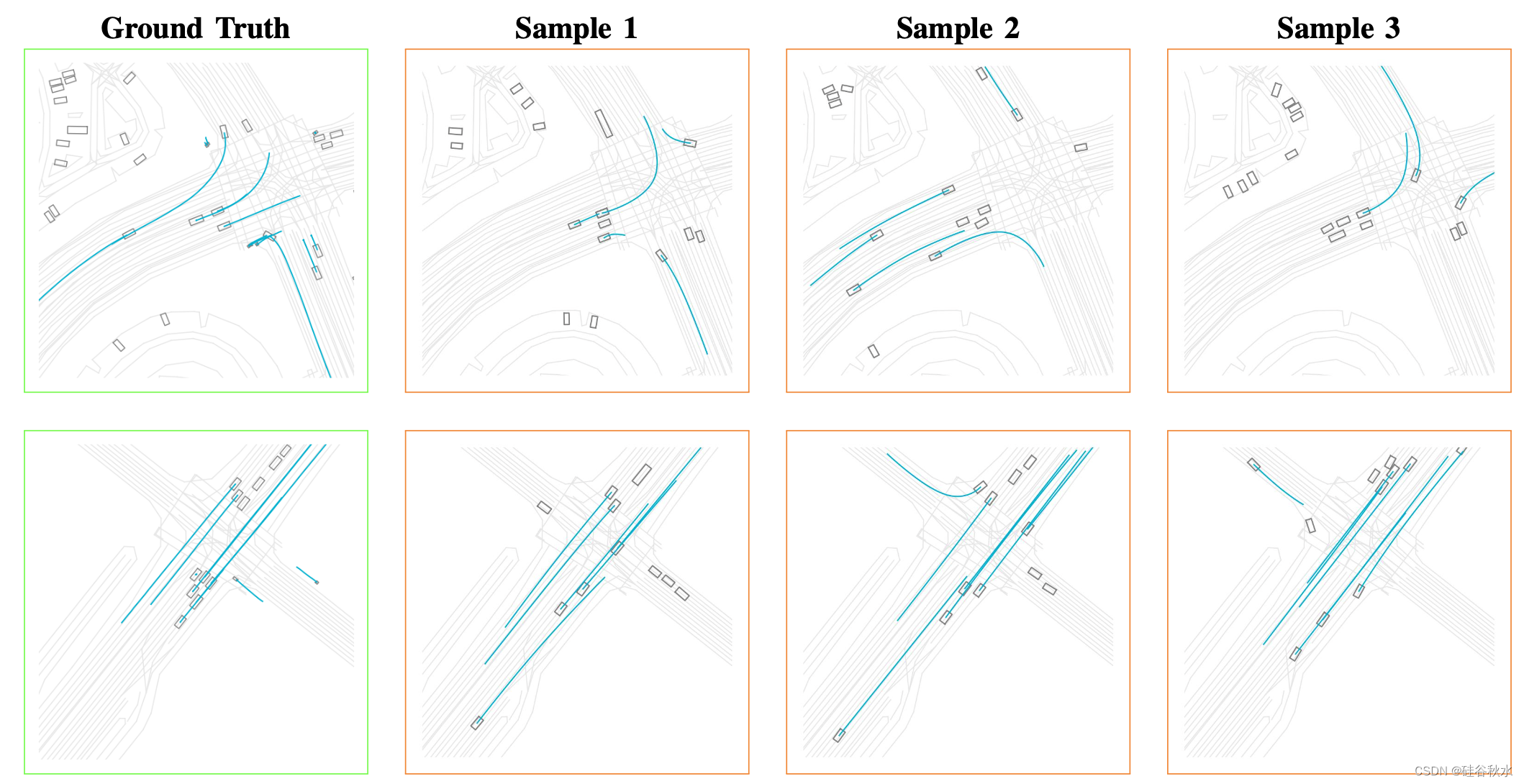
如图是一些UniGEN的例子:










![whisper报错:hp, ht, pid, tid = _winapi.CreateProcess [WinError 2] 系统找不到指定的文件。](https://img-blog.csdnimg.cn/direct/3ecb693da1d5461db89b80a3f53f6f35.png)