0.引言
AIM(Autoregressive Image Model)是一种自回归学习图像模型,它是对语言模型的图像版本进行了推广。该模型的预训练图像特征质量会随着模型大小和数据质量的提高而提高,从而带来更好的性能。同时,下游任务的性能也会随着预训练性能的提高而提高。
通过在大规模图像数据集上进行预训练,AIM 模型可以学习到丰富的图像特征,这些特征可以被迁移到各种下游视觉任务中,如图像分类、目标检测、语义分割等。据报道,在 20 亿张图像上预训练了 70 亿个 AIM 参数,并在 ImageNet-1k 任务中达到了 84% 的准确率,而且没有显示出性能饱和的迹象。
AIM 模型的性能和预训练质量的提高可能会带来视觉领域的重大进展,为各种图像理解任务提供更强大的基础模型。
论文地址:https://arxiv.org/abs/2401.08541
源码地址:https://github.com/apple/ml-aim
1.介绍
2012 年,多伦多大学推出了基于卷积神经网络(CNN)的 AlexNet,并在图像识别竞赛中获胜。这一成功给人们带来了希望:层数越深,图像识别的准确性就越高,深度学习研究迅速走红。
虽然在模型参数学习过程中,由于梯度损失,加深层数会导致性能下降,但微软研究院在 2015 年发布的 ResNet 短切连接建议证实,即使层数增加到 152 层,性能也能得到改善。
因此,图像识别任务带动了模型的大规模开发,2017 年,Transformer 作为解决自然语言处理任务的语言模型被提出。
2022 年,开放人工智能(Open AI)发布了基于 Transformer 的大规模语言模型 ChatGPT 的原型。ChatGPT 因其对所有问题的高度可信回答而备受关注,预示着通用人工智能的到来。ChatGPT 是一个原型,可用于多种应用。此外,没有迹象表明模型参数数量的增加会带来性能限制,于是一场追求更大模型规模的竞赛开始了,并迅速引发了大规模语言建模研究的热潮。
回顾历史,深度学习研究在图像识别研究中得到了发展,随后生成模型,尤其是变换器,在语言处理研究中得到了大规模发展,本文讨论的是语言处理研究的成果能否推广到图像识别研究中。
具体来说,我们讨论的是基于 Transformer 创建大规模 "图像 "模型,而不是大规模 "语言 "模型。不过,这并不意味着 Transformer 没有应用于图像识别。
变形金刚在图像识别领域的一个著名应用是视觉变形金刚(ViT)。该模型于 2021 年由谷歌发布。这项研究表明,如果有足够的图像数据进行预训练,变换器可以取代 CNN。
Vision Transformer 和大规模语言模型一样都是基于 Transformer 的,但其预学习方法与大规模语言模型不同。在大规模语言模型中,预学习采用的是自动回归学习法,即不从外部给出标签,系统通过在句子中显示到某个单词来学习预测下一个单词;而在视觉转换器中,图像识别的正确标签(分类类别,如狗或猫)与训练图像一起作为一个集合给出,从而进行学习。在视觉转换器中,图像识别的正确标签(分类类别,如狗或猫)与训练图像一起作为一个集合给出,以便进行学习。
在本文中,模型基础与 Vision Transfomer 相同,但与大规模语言模型一样,本文研究了苹果公司能否开发出一种技术,通过自回归学习,随着模型参数和训练数据数量的增加而提高图像识别准确率。
现在介绍所提出的自回归图像模型(AIM)及其评估结果。
2.自回归图像模型(AIM)
研究前程序
图 1 显示了使用拟议方法–自回归图像模型(AIM)–进行预训练的流程。

图 1.AIM 预研究流程。
变换器自回归学习每次都会从目前显示的单词中从左到右预测给定句子的下一个单词。要将这种变换器自回归学习应用于图像,需要将图像表示为由单词组成的句子。因此,AIM 将输入图像划分为图 1 所示的非重叠mask图像(子区域),对mask图像进行排序,并学习下一个mask图像的猜测。
对原始图像分割出的每个mask图像进行降维处理,并通过线性映射提取特征。mask图像特征输入变换器,变换器执行自注意处理(上下文感知mask特征更新。使用前缀因果掩码进行自我关注处理),具体说明如下。然后,MLP 根据提取的图像特征预测下一个mask图像。
模型预测光栅顺序(图 1 中分配给每个mask图像的数字顺序)。模型按光栅顺序预测下一个mask图像(从顶行开始依次读取)。
图 1 中 MLP 的输出显示了根据mask图像 1 预测mask图像 2 和根据mask图像 1 和 2 预测mask图像 3 之间的关系。如果没有给出mask图像,就无法预测mask图像,因此mask图像预测结果以 2 开始,以 9 结束,因为在给出mask图像 9 之前,没有mask图像可以预测下一个mask图像。
上一个模型输出的第二至第九个mask图像的预测和正确答案的误差函数(自回归目标函数)如公式 1 所示。

方程 1.自回归模型训练过程中的损失函数
x 帽子是用模型参数 θ 对 AIM 第 k 个mask图像的预测值,而无帽子则是正确mask图像的值。对 θ 的训练是为了最小化每个mask图像的预测值与正确像素值向量之间误差平方和的平均值。(如图 1 所示,如果模型的输出是第二到第九个mask,则可以认为开始时的 k=2 是有效的)。
前置因果掩码
在预测下一个mask图像的问题上,应注意从目前显示的mask图像中预测下一个mask图像的关系,如果获取了下一个mask图像的信息,这将是一种作弊行为。Transformer 的自我关注过程是对句子中不同单词的单词加权求和,并通过计算这些单词的加权和来更新每个单词的特征,因此简单地计算所有单词的加权和就会导致这种作弊行为。
因此,在预测第二个mask图像时,因果掩码在预训练期间计算下一个mask图像的预测误差时,只使用第一个mask图像,而在预测第三个mask图像时,它只使用第一个和第二个mask图像,在迄今显示的mask图像之间进行自我注意。请执行以下操作。
然而,因果掩码的问题在于,当它们适应下游任务(在本文中,是与预训练任务不同的新图像识别任务)时,效果并不好。
在预训练中,由于这是一项自回归任务,因此有一项限制条件,即不得显示未来的mask图像。而在下游任务(图像识别任务)中,与待识别图像相关的所有mask图像都可能被同时看到。因此,在做出图像识别决定之前,自然要考虑所有mask图像的特征。但是,如果在预训练时使用简单的因果掩码,就无法很好地学习考虑多个图像mask的特征。因此,将下游任务也考虑在内的预学习是可取的。
因此,本文使用了前缀因果掩码。前缀因果掩膜通过使用全部的mask图像,直到由均匀分布决定的一定数量的mask图像 = 前缀长度,来执行自注意处理。之后,它与因果掩码一样进行自注意处理。在计算预测误差时,会针对超出前缀长度的mask图像进行预测。
图 2 显示了前缀因果掩码预学习和下游适应的图像。
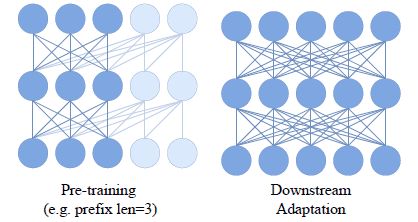
图 2:"带前缀因果掩码的预学习 "和下游适配
这是一种猜测,因为本文没有解释图中的圆圈和线条代表什么,但它很像神经网络的示意图。
如果我们把输入层、中间层和输出层看作是一个三层神经网络,从图的底部看有五个维度,那么我们可以把这里输入层的五个维度看作是与五个mask相对应的。换句话说,水平圆圈可视为与五个mask图像的排列相同,以神经网络的方式展示了在通过对五个mask图像的自我注意处理更新特征时,其他mask图像是如何参与其中的。
图 2 左图显示了使用前缀因果掩码进行预训练的情况。前缀因果掩码的前缀长度为 3,可视为一个神经网络,从左数起最多可将三个图像斑块组合在一起。
这意味着,可以认为左起的第一、第二和第三个图像mask的特征分别根据第一至第三个图像mask进行了更新(相对于第一和第二图像mask而言,就像在未来的某个mask中更新了特征一样)。
第四个和第五个图像mask被认为代表了用自身和之前的图像mask更新的图像(应用了因果掩码,第四个图像mask的特征没有用第五个图像mask更新,第五个图像mask是第四个图像mask的未来图像mask)。
图 2 右侧的图片显示了下游适应的图像。下游适配是一项自然任务,它将所有待识别图像的所有mask都视为完全合并,因此完全合并是可取的,但如果始终允许完全合并,预训练始终是在作弊状态下学习。
因此,如果使用前缀因果掩码,就可以认为是在使用因果掩码进行预训练,假定下游适应,在所有连接状态中部分保留了特征更新。
MLP 预测头
理想情况下,Transformer 预训练应能学习适用于各种下游任务的通用图像特征。如果在预训练时学习的图像特征是针对目标函数的,那么它们对下游任务的适应性就会降低。
因此,为了提高对下游任务的适应性,将一个 MLP(多层感知器)预测头连接到最后一层并进行预训练;MLP 预测头独立处理每个mask图像。
然后,在适应下游任务时,放弃预训练中的 MLP 预测头,将剩余的 Transformer 部分用作通用特征提取器。
下游适应
预训练大型模型需要消耗大量计算资源。微调也很费力。
因此,在训练下游任务时,预训练中学习到的变换器权重是固定的。只训练新连接的分类头。这样可以避免对少量下游任务数据集进行过度训练,并降低下游适应成本。
3.AIM 评估结果。
评估 AIM 是否能在模型参数和训练数据数量不断增加的情况下显示出可扩展的性能。
我们在 20 亿张无组织图像上对 AIM 进行了预训练,并将其调整为 15 项下游任务(各种图像识别(=图像类别分类)基准,包括细粒度识别、医疗图像、卫星图像、自然环境和信息图表),并评估了其在 15 项下游任务上的平均性能,如图 3 所示。

图 3.AIM 的预训练和下游任务性能对模型参数数量的可扩展性。
图 3 显示了 AIM 随模型参数数量变化的可扩展性。横轴是预训练中的验证损失,纵轴是 15 个下游任务的平均性能;图中标有 AIM-*B 的每个点代表 AIM 中模型参数的数量。数字越往右越大,依次为 6 亿、10 亿、30 亿和 70 亿个模型参数。
该图显示了当 AIM 中的模型参数数量增加时,预培训性能与下游任务性能之间的关系;可以看出,随着 AIM 中的模型参数数量增加,预培训性能得到改善,下游任务性能也得到改善。
顺便提一下,在 ImageNet-1k 基准测试中,AIM 在使用 70 亿个模型参数的情况下取得了 84.0 的准确率,优于使用名为 MAE 的自动编码器的现有方法 82.2 的准确率。另一方面,DiNOv2 方法的准确度为 86.4,优于 AIM。相比之下,论文指出,DiNOv2 的评估结果单独提高了 1 到 1.5%,因为它使用了高分辨率的训练图像。(目前还不清楚这是否意味着,如果 AIM 也使用高分辨率图像进行训练,其性能就会比 DiNOv2 有所提高)。
图 4 显示了 AIM 随模型参数数量变化的可扩展性。

图 4.AIM 下游任务性能随训练数据数量的可扩展性。
图 4 中的横轴是 AIM 的唯一训练图像数,纵轴是模型参数数为 6 亿时 AIM 在 15 个图像识别基准上的平均性能。换句话说,它显示了当模型参数数量为 6 亿时,AIM 训练数据数量与下游任务性能之间的关系:随着 AIM 训练数据数量从 100 万张图像增加到 1 亿张图像,再增加到 20 亿张图像,识别准确率也随之提高。没有迹象表明识别准确率达到饱和。
图 3 和图 4表明,在模型参数和训练数据数量不断增加的情况下,AIM 能以可扩展的方式提高图像识别精度。
4.模型应用
源码下载:
pip install git+https://git@github.com/apple/ml-aim.git
PyTorch用例:
from PIL import Image
from aim.utils import load_pretrained
from aim.torch.data import val_transforms
img = Image.open(...)
model = load_pretrained("aim-600M-2B-imgs", backend="torch")
transform = val_transforms()
inp = transform(img).unsqueeze(0)
logits, features = model(inp)
如果是Max本,可MXL有用例:
pip install mlx
from PIL import Image
import mlx.core as mx
from aim.utils import load_pretrained
from aim.torch.data import val_transforms
img = Image.open(...)
model = load_pretrained("aim-600M-2B-imgs", backend="mlx")
transform = val_transforms()
inp = transform(img).unsqueeze(0)
inp = mx.array(inp.numpy())
logits, features = model(inp)
5.结论
本文提出了一种基于视觉转换器的自回归图像模型(AIM,Autoregressive Image Models)方法,它能够利用自回归目标函数进行预训练,从而提高图像识别和 LLM 的预训练和下游任务性能。我们提出了一种基于视觉转换器的自回归图像模型(AIM)方法,它能够利用自回归目标函数进行预训练。
在使用 Transformer 学习自回归目标函数时,它使用简单的因果掩码进行自动注意处理,不能很好地利用图像识别目标图像之间的关系,也不能很好地适应下游任务,因此它将自动注意处理与前缀因果掩码相结合。
为了学习不过度拟合自回归目标函数的通用图像特征,变换器部分被用作通用图像特征提取器,而后一部分的 MLP 部分被用作下一个mask图像预测器。
此外,为了降低适应下游任务时的适应成本,预训练中的 MLP 部分由图像分类 MLP 代替,只训练图像分类 MLP 以适应下游任务。
评估结果表明,在 20 亿个训练数据和 70 亿个模型参数的情况下,前期训练和下游任务的性能都得到了提高,而且没有发现性能提高的极限。
如果随着我们不断扩展图像模型,图像识别的准确率确实能继续提高,那么为提高准确率而改进模型的竞赛基本上就结束了。回顾历史,通过深化深度学习来获得可扩展的性能提升本身就是一个重大挑战,而我认为这个问题已经迎刃而解。
如果是这样的话,剩下的研究方向很可能就只有一个,那就是用多少资源能实现多少图像识别,以及如何应用这项技术,因为投入更多资源就能提高性能。
不过,如果与大规模语言模型相比,这种图像版 LLM 在识别图像(对某些图像进行分类)方面的能力似乎不可避免地受到了限制。
大规模语言模型的好处是可以通过上下文学习回答各种问题,但这个大规模图像模型似乎仅限于图像识别,下游任务适应的学习是必须的,所以大规模语言模型的零镜头(无下游任务数据学习)还存在与预期不符的问题,可以非常准确地回答。
为了能够说它是图像版的 LLM,我觉得我需要一个惊喜,让我能够用这样的零镜头解决各种任务。












![[Algorithm][回溯][全排列][子集] + 回溯原理 详细讲解](https://img-blog.csdnimg.cn/direct/947c26560c604bebb8965ab49fbb77ae.png)
