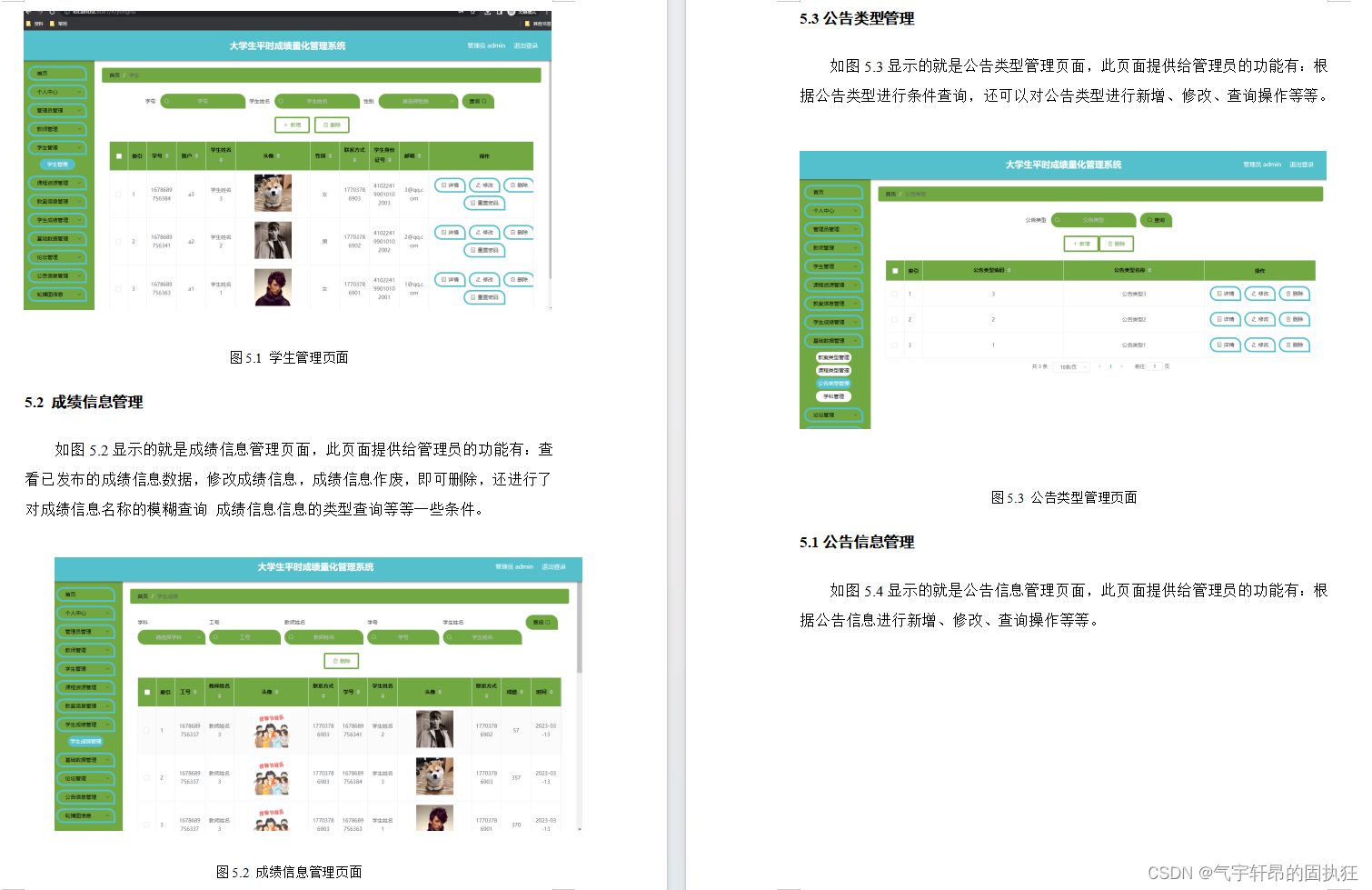
前置知识:树的基本概念及性质
为了保证学习效果,请保证已经掌握前置知识之后,再来学习本章节!如果在阅读中遇到困难,也可以回到前面章节查阅。
学习目标
- 掌握图的基本概念
- 掌握图的一些性质
图的概念
基本概念
图 (Graph) 是一个二元组 𝐺=(𝑉(𝐺),𝐸(𝐺))G=(V(G),E(G)) 。其中 𝑉(𝐺)V(G) 是非空集,称为 点集 (Vertex set) ,对于 𝑉V 中的每个元素,我们称其为 顶点 (Vertex) 或 节点 (Node) ,简称 点 ; 𝐸(𝐺)E(G) 为 𝑉(𝐺)V(G) 各结点之间边的集合,称为 边集 (Edge set) 。
常用 𝐺=(𝑉,𝐸)G=(V,E) 表示图。
当 𝑉,𝐸V,E 都是有限集合时,称 𝐺G 为 有限图 。
当 𝑉V 或 𝐸E 是无限集合时,称 𝐺G 为 无限图 。
图有多种,包括 无向图 (Undirected graph) , 有向图 (Directed graph) , 混合图 (Mixed graph) 等
若 𝐺G 为无向图,则 𝐸E 中的每个元素为一个无序二元组 (𝑢,𝑣)(u,v) ,称作 无向边 (Undirected edge) ,简称 边 (Edge) ,其中 𝑢,𝑣∈𝑉u,v∈V 。设 𝑒=(𝑢,𝑣)e=(u,v) ,则 𝑢u 和 𝑣v 称为 𝑒e 的 端点 (Endpoint) 。
若 𝐺G 为混合图,则 𝐸E 中既有向边,又有无向边。
若 𝐺G 的每条边 𝑒𝑘=(𝑢𝑘,𝑣𝑘)ek=(uk,vk) 都被赋予一个数作为该边的 权 ,则称 𝐺G 为 赋权图 。如果这些权都是正实数,就称 𝐺G 为 正权图 。
形象地说,图是由若干点以及连接点与点的边构成的。
图上的关系
点与点——邻接
在无向图 𝐺=(𝑉,𝐸)G=(V,E) 中,对于两顶点 𝑢u 和 𝑣v ,若存在边 (𝑢,𝑣)(u,v) ,则称 𝑢u 和 𝑣v 是 相邻(邻接)的 。
一个顶点 𝑣∈𝑉v∈V 的 邻域 (Neighborhood) 是所有与之相邻的顶点所构成的集合,记作 𝑁(𝑣)N(v) 。
PS:邻接表存储的就是邻域,并且由此得名。
点与边——关联
在无向图 𝐺=(𝑉,𝐸)G=(V,E) 中,若点 𝑣v 是边 𝑒e 的一个端点,则称 𝑣v 和 𝑒e 是 关联的。
度数
与一个顶点 𝑣v 关联的边的条数称作该顶点的 度 (Degree) ,记作 𝑑(𝑣)d(v) 。特别地,对于边 (𝑣,𝑣)(v,v) ,则每条这样的边要对 𝑑(𝑣)d(v) 产生 22 的贡献。
对于无向简单图,有 𝑑(𝑣)=∣𝑁(𝑣)∣d(v)=∣N(v)∣ 。
握手定理(又称图论基本定理):对于任何无向图 𝐺=(𝑉,𝐸)G=(V,E) ,有 ∑𝑣∈𝑉𝑑(𝑣)=2∣𝐸∣∑v∈Vd(v)=2∣E∣ ,即无向图中结点度数的总和等于边数的两倍。有向图中结点的入度之和等于出度之和等于边数。
推论: 在任意图中,度数为奇数的点必然有偶数个。
证明:反证法
简单图
自环 (Loop) :对 𝐸E 中的边 𝑒=(𝑢,𝑣)e=(u,v) ,若 𝑢=𝑣u=v ,则 𝑒e 被称作一个自环。
重边/平行边 (Multiple edge) :若 𝐸E 中存在两个完全相同的元素(边) 𝑒1,𝑒2e1,e2 ,则它们被称作(一组)重边。
简单图 (Simple graph) :若一个图中 没有自环和重边,它被称为简单图。非空简单无向图中一定存在度相同的结点。
如果一张图中有自环或重边,则称它为 多重图 (Multigraph) 。

在无向图中 (𝑢,𝑣)(u,v) 和 (𝑣,𝑢)(v,u) 算一组重边,而在有向图中, 𝑢→𝑣u→v 和 𝑣→𝑢v→u 不为重边。
在题目中,如果没有特殊说明,是可以存在自环和重边的,在做题时需特殊考虑。
路径
途径 (Walk) / 链 (Chain) :一个点和边的交错序列,其中首尾是点—— 𝑣0,𝑒1,𝑣1,𝑒2,𝑣2,…,𝑒𝑘,𝑣𝑘v0,e1,v1,e2,v2,…,ek,vk ,有时简写为 𝑣0→𝑣1→𝑣2→⋯→𝑣𝑘v0→v1→v2→⋯→vk 。其中 𝑒𝑖ei 的两个端点分别为 𝑣𝑖−1vi−1 和 𝑣𝑖vi 。通常来说,边的数量 𝑘k 被称作这条途径的 长度 (如果边是带权的,长度通常指路径上的边权之和,题目中也可能另有定义)。(以下设 𝑤=[𝑣0,𝑒1,𝑣1,𝑒2,𝑣2,⋯,𝑒𝑘,𝑣𝑘]w=[v0,e1,v1,e2,v2,⋯,ek,vk] 。)
迹 (Trail) :对于一条途径 𝑤w ,若 𝑒1,𝑒2,⋯,𝑒𝑘e1,e2,⋯,ek 两两互不相同,则称 𝑤w 是一条迹。
路径 (Path) (又称 简单路径 (Simple path) ):对于一条迹 𝑤w ,除了 𝑣0v0 和 𝑣𝑘vk 允许相同外,其余点两两互不相同,则称 𝑤w 是一条路径。
回路 (Circuit) :对于一个迹 𝑤w ,若 𝑣0=𝑣𝑘v0=vk ,则称 𝑤w 是一个回路。
环/圈 (Cycle) (又称 简单回路/简单环 (Simple circuit) ):对于一条简单路径 𝑤w ,若 𝑣0=𝑣𝑘v0=vk ,则称 𝑤w 是一个环。
!!! warning
关于路径的定义在不同地方可能有所不同,如,“路径”可能指本文中的“途径”,“环”可能指本文中的“回路”。如果在题目中看到类似的词汇,且没有“简单路径”/“非简单路径”(即本文中的“途径”)等特殊说明,最好询问一下具体指什么。
连通
无向图
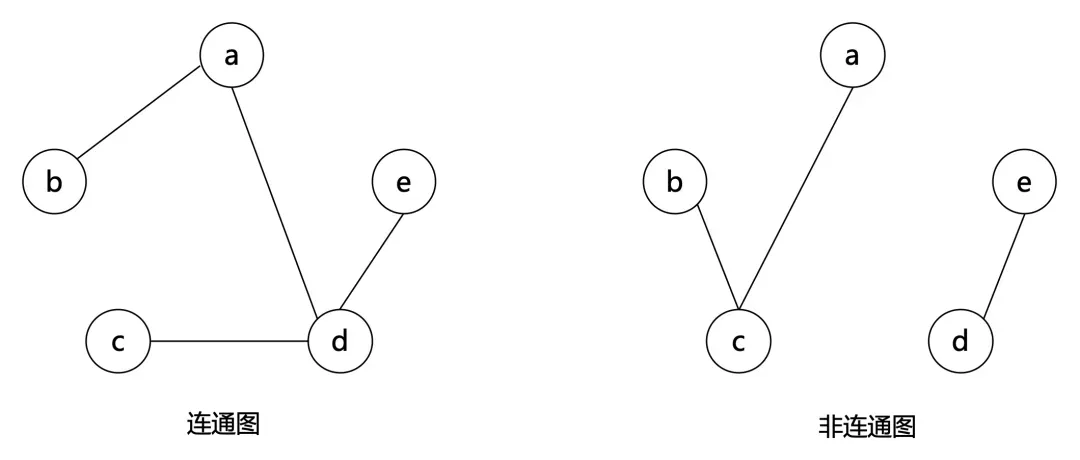
对于一张无向图 𝐺=(𝑉,𝐸)G=(V,E) ,对于 𝑢,𝑣∈𝑉u,v∈V ,若存在一条途径使得 𝑣0=𝑢,𝑣𝑘=𝑣v0=u,vk=v ,则称 𝑢u 和 𝑣v 是 连通的 (Connected) 。由定义,任意一个顶点和自身连通,任意一条边的两个端点连通。
若无向图 𝐺=(𝑉,𝐸)G=(V,E) ,满足其中任意两个顶点均连通,则称 𝐺G 是 连通图 (Connected graph) , 𝐺G 的这一性质称作 连通性 (Connectivity) 。
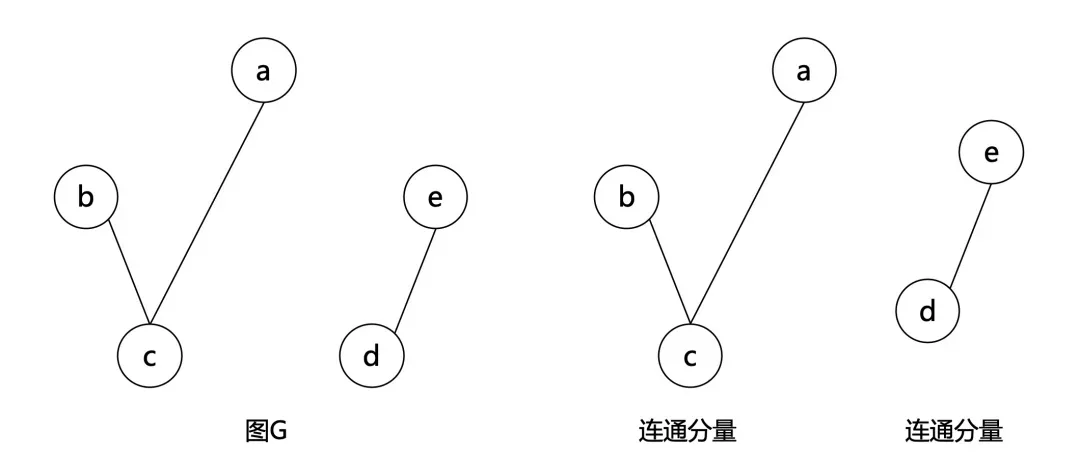
若 𝐻H 是 𝐺G 的一个连通子图,且不存在 𝐹F 满足 𝐻⊊𝐹⊆𝐺H⊊F⊆G 且 𝐹F 为连通图,则 𝐻H 是 𝐺G 的一个 连通块/连通分量 (Connected component) (极大连通子图)。
有向图
对于一张有向图 𝐺=(𝑉,𝐸)G=(V,E) ,对于 𝑢,𝑣∈𝑉u,v∈V ,若存在一条途径使得 𝑣0=𝑢,𝑣𝑘=𝑣v0=u,vk=v ,则称 𝑢u 可达 𝑣v 。由定义,任意一个顶点可达自身,任意一条边的起点可达终点。(无向图中的连通也可以视作双向可达。)
若一张有向图的节点两两互相可达,则称这张图是 强连通的 (Strongly connected) 。
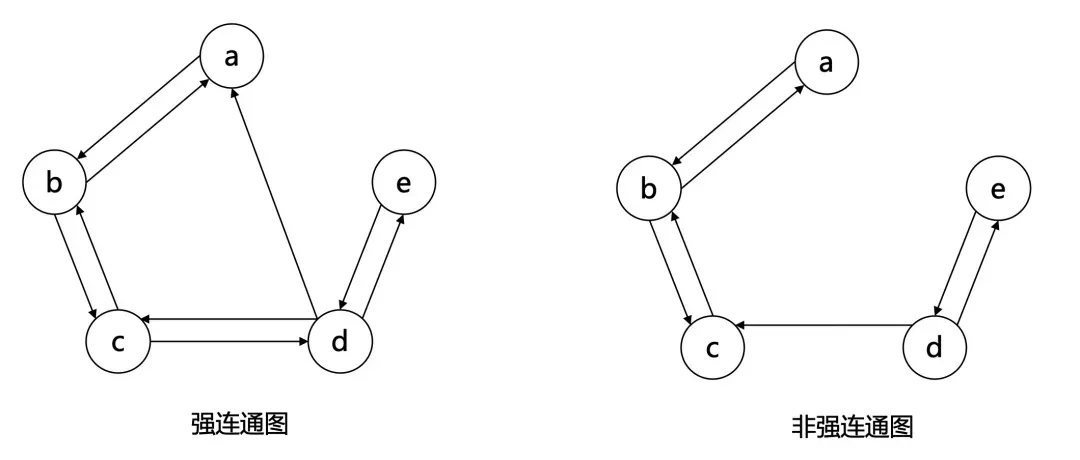
若一张有向图的边替换为无向边后可以得到一张连通图,则称原来这张有向图是 弱连通的 (Weakly connected) 。
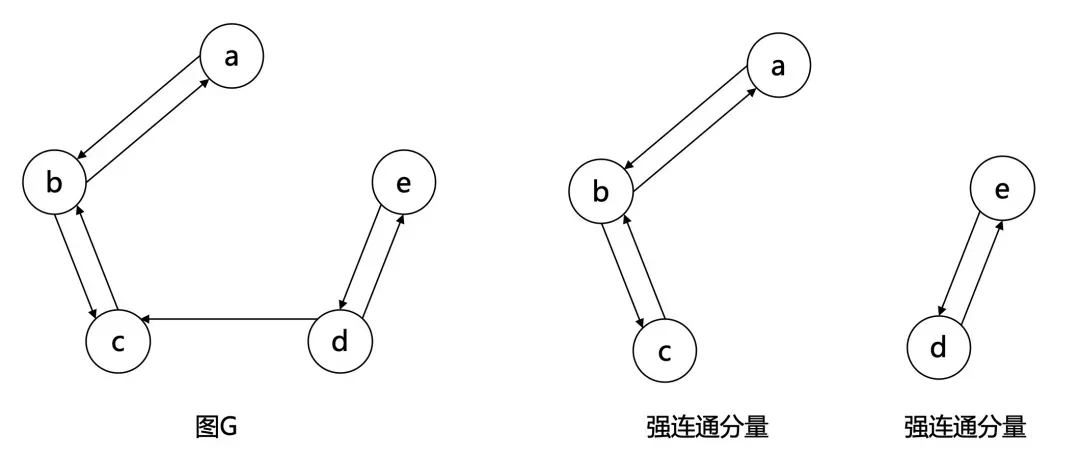
与连通分量类似,也有 弱连通分量 (Weakly connected component) (极大弱连通子图)和 强连通分量 (Strongly Connected component) (极大强连通子图)。
𝑛n 个顶点的强连通图最多 𝑛(𝑛−1)n(n−1) 条边,最少 𝑛n 条边。
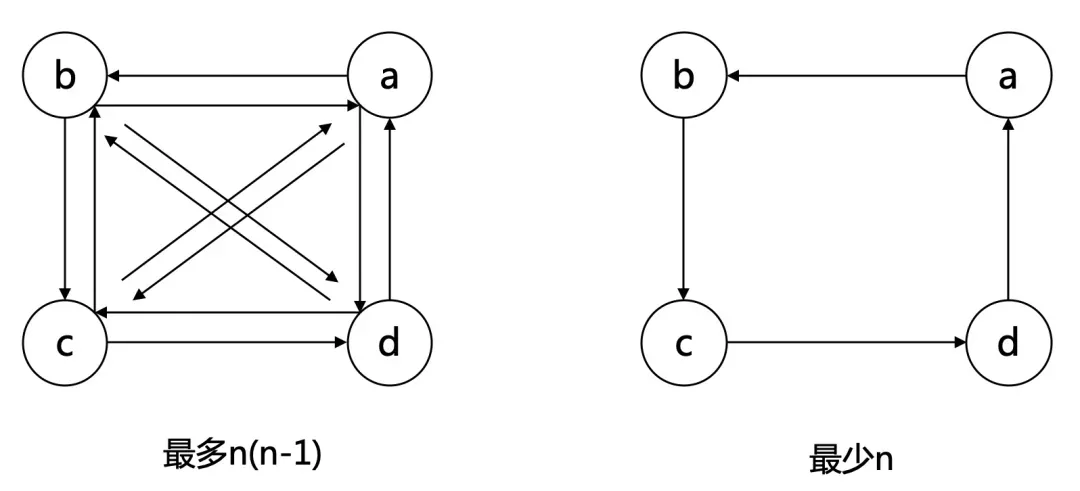
图的连通性也是竞赛的一个常见考点,相关算法请后面将学习,现在先理解其概念即可。
稀疏图/稠密图
若一张图的边数远小于其点数的平方,那么它是一张 稀疏图 (Sparse graph) 。
若一张图的边数接近其点数的平方,那么它是一张 稠密图 (Dense graph) 。
这两个概念并没有严格的定义,一般用于讨论 时间复杂度 为 𝑂(∣𝑉∣2)O(∣V∣2) 的算法与 𝑂(∣𝐸∣)O(∣E∣) 的算法的效率差异(在稠密图上这两种算法效率相当,而在稀疏图上 𝑂(∣𝐸∣)O(∣E∣) 的算法效率明显更高)。
特殊的图
完全图
若无向简单图 𝐺G 满足任意不同两点间均有边,则称 𝐺G 为 完全图 (Complete graph) , 𝑛n 阶完全图记作 𝐾𝑛Kn 。若有向图 𝐺G 满足任意不同两点间都有两条方向不同的边,则称 𝐺G 为 有向完全图 (Complete digraph) 。
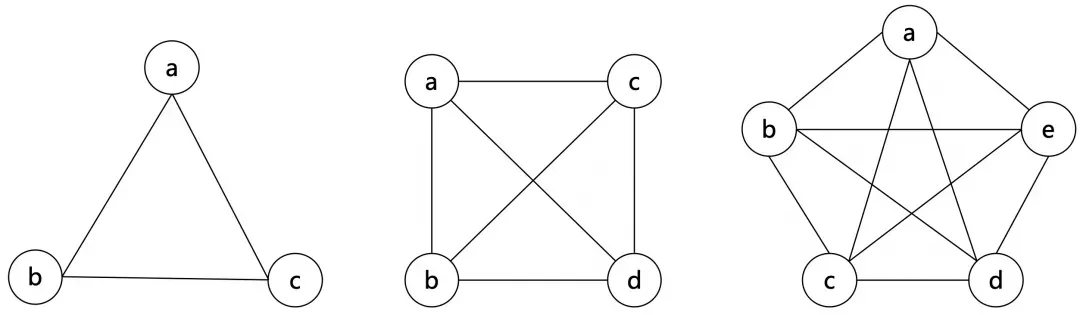
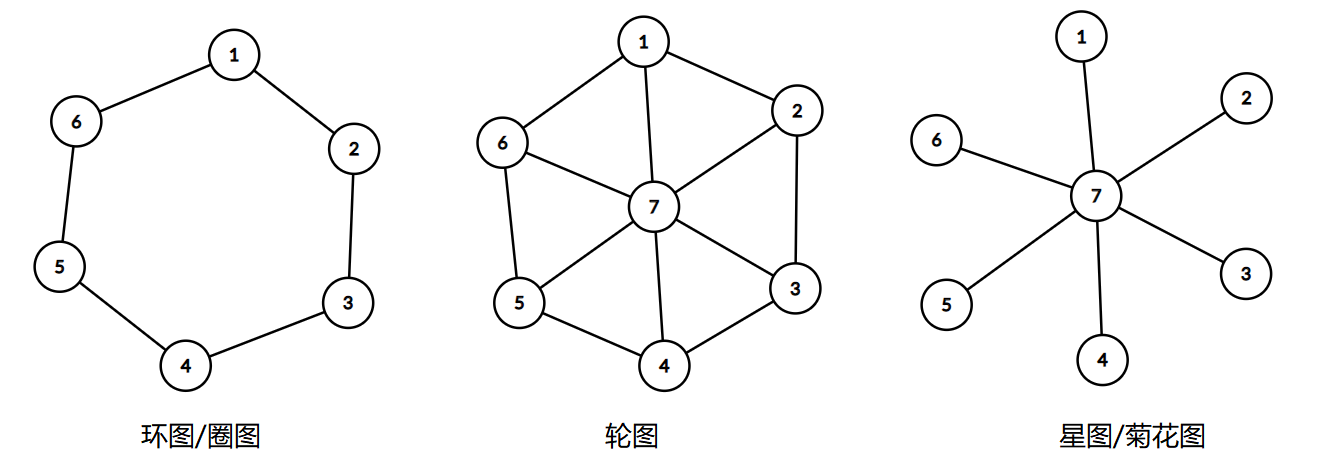
环图/圈图
若无向简单图 𝐺=(𝑉,𝐸)G=(V,E) 的所有边恰好构成一个圈,则称 𝐺G 为 环图/圈图 (Cycle graph) , 𝑛n ( 𝑛≥3n≥3 ) 阶圈图记作 𝐶𝑛Cn 。易知,一张图为圈图的充分必要条件是,它是 22 - 正则连通图。
星图/菊花图
若无向简单图 𝐺=(𝑉,𝐸)G=(V,E) 满足,存在一个点 𝑣v 为支配点,其余点之间没有边相连,则称 𝐺G 为 星图/菊花图 (Star graph) , 𝑛+1n+1 ( 𝑛≥1n≥1 ) 阶星图记作 𝑆𝑛Sn 。
轮图
若无向简单图 𝐺=(𝑉,𝐸)G=(V,E) 满足,存在一个点 𝑣v 为支配点,其它点之间构成一个圈,则称 𝐺G 为 轮图 (Wheel Graph) , 𝑛+1n+1 ( 𝑛≥3n≥3 ) 阶轮图记作 𝑊𝑛Wn 。
链
若无向简单图 𝐺=(𝑉,𝐸)G=(V,E) 的所有边恰好构成一条简单路径,则称 𝐺G 为 链 (Chain/Path Graph) , 𝑛n 阶的链记作 𝑃𝑛Pn 。易知,一条链由一个圈图删去一条边而得。
树
如果一张无向连通图不含环,则称它是一棵 树 (Tree) 。相关内容详见 树基础 。
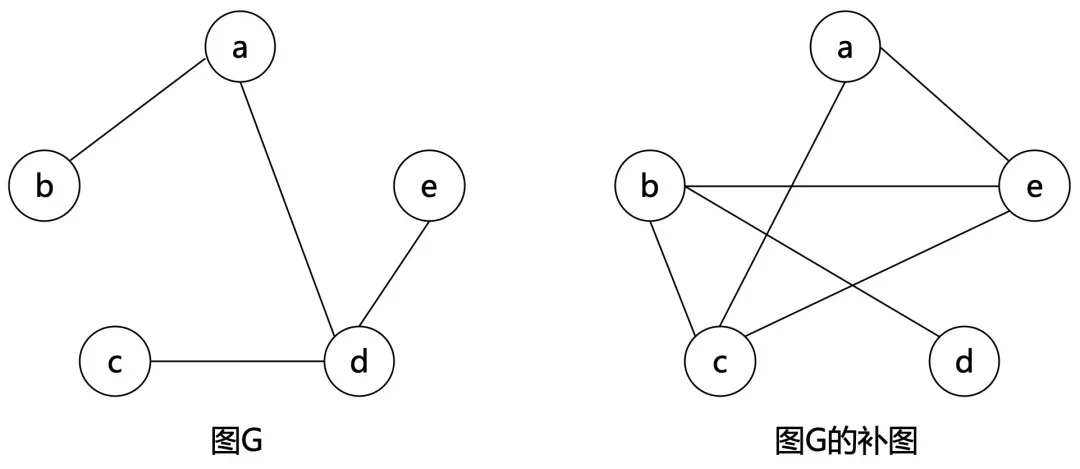
补图
对于无向简单图 𝐺=(𝑉,𝐸)G=(V,E) ,它的 补图 (Complement graph) 指的是这样的一张图:记作 𝐺ˉGˉ ,满足 𝑉(𝐺ˉ)=𝑉(𝐺)V(Gˉ)=V(G) ,且对任意节点对 (𝑢,𝑣)(u,v) , (𝑢,𝑣)∈𝐸(𝐺ˉ)(u,v)∈E(Gˉ) 当且仅当 (𝑢,𝑣)∉𝐸(𝐺)(u,v)∈/E(G) 。
反图
对于有向图 𝐺=(𝑉,𝐸)G=(V,E) ,它的 反图 (Transpose Graph) 指的是点集不变,每条边反向得到的图,即:若 𝐺G 的反图为 𝐺′=(𝑉,𝐸′)G′=(V,E′) ,则 𝐸′={(𝑣,𝑢)∣(𝑢,𝑣)∈𝐸}E′={(v,u)∣(u,v)∈E} 。
平面图
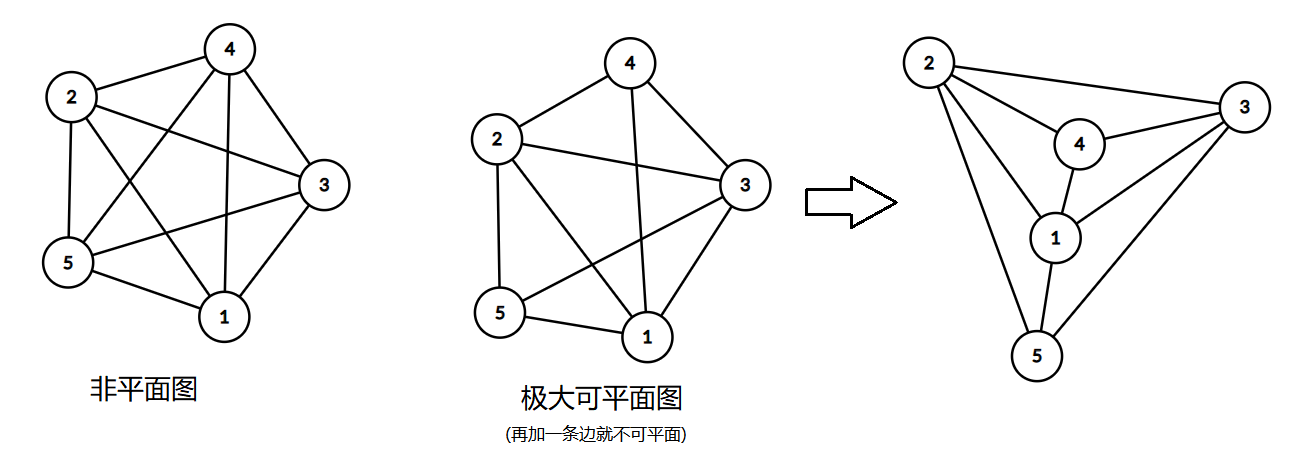
如果一张图可以画在一个平面上,且没有两条边在非端点处相交,那么这张图是一张 平面图 (Planar graph) 。一张图的任何子图都不是 𝐾5K5 或 𝐾3,3K3,3 是其为一张平面图的充要条件。对于简单连通平面图 𝐺=(𝑉,𝐸)G=(V,E) 且 𝑉≥3V≥3 , ∣𝐸∣≤3∣𝑉∣−6∣E∣≤3∣V∣−6 。
学习目标
- 掌握图的四种存储方法的代码实现
- 理解图的四种存储方法各自的时间空间复杂度
- 能够根据题目的要求和数据范围,选择合适存图方式
图的逻辑结构
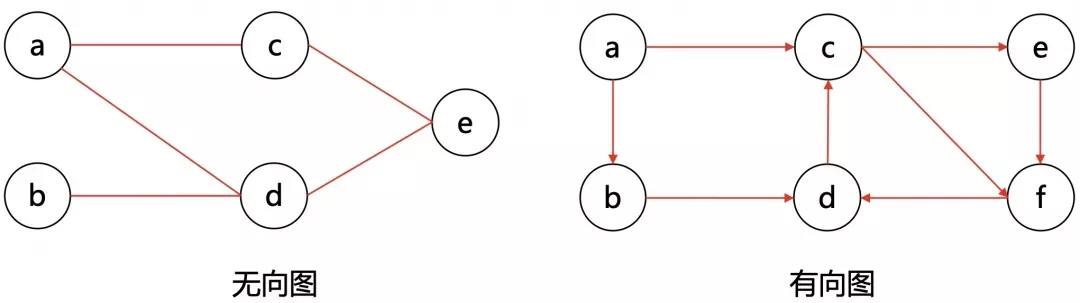
一张图是由节点和边构成的,一个无向图如下图所示:
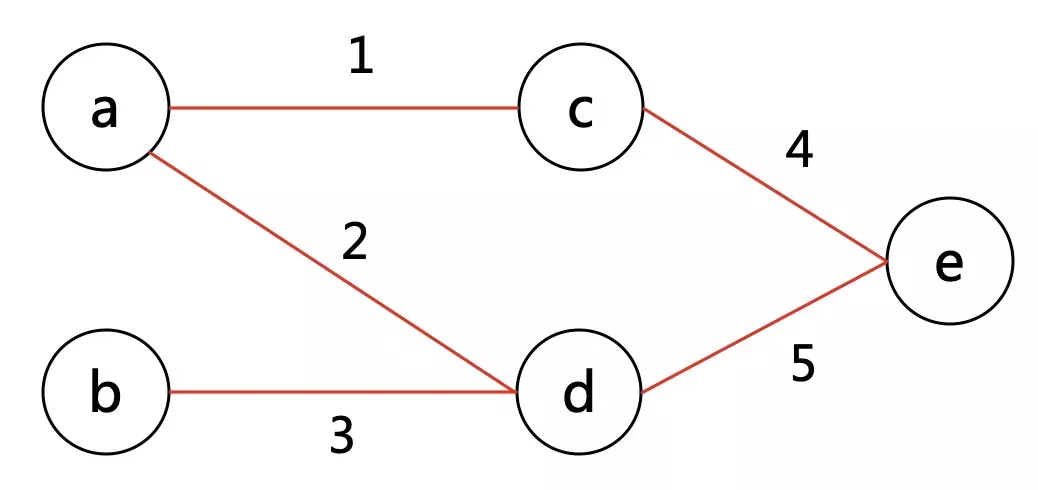
什么叫 「逻辑结构」?就是说为了方便研究,我们把图 抽象 成这个样子。
根据这个逻辑结构,我们可以认为每个节点的实现如下:
// 图节点的逻辑结构
struct node {
int data; // 存当前结点信息
vector<int> neighbors; // 存邻接的所有结点
}
看到这个实现,你有没有很熟悉?它和我们之前说的多叉树节点几乎完全一样:
// 树节点的逻辑结构
struct node {
int data; // 存当前结点信息
vector<int> son; // 存所有的子结点
}
Copy
不过呢,上面的这种实现是「逻辑上的」,实际上我们很少用这个node类实现图,而是用接下来介绍的几种方法去存储。其中包含我们前面经常提到的 邻接表和邻接矩阵。
图的存储方法
接下来描述图的具体四种存储方式,这四种方式是我们今后和图这种数据结构打交道的接口,请一定要掌握。
首先约定,用 𝑛n 代指图的点数,用 𝑚m 代指图的边数,用 𝑑+(𝑢)d+(u) 代指点 𝑢u 的出度,即以 𝑢u 为出发点的边数。
直接存边
方法
使用一个数组来存边,数组中的每个元素都包含一条边的起点与终点(带边权的图还包含边权)。(或者使用多个数组分别存起点,终点和边权。)
#include <iostream>
#include <vector>
using namespace std;
struct Edge {
int u, v, w; // 一条边的 起点、终点、权值
};
int n, m;
vector<Edge> e;
vector<bool> vis;
// 函数功能:判断 u,v 之间有没有边
bool find_edge(int u, int v) {
for (int i = 1; i <= m; ++i) {
if (e[i].u == u && e[i].v == v) {
return true;
}
}
return false;
}
// 遍历图
void dfs(int u) {
if (vis[u]) return;
vis[u] = true;
for (int i = 1; i <= m; ++i) {
if (e[i].u == u) {
dfs(e[i].v);
}
}
}
int main() {
cin >> n >> m;
// 初始化 vector 数组,也可以将 vis 定义成: “bool vis[N];” 以省去初始化。下同
vis.resize(n + 1, false);
e.resize(m + 1);
for (int i = 1; i <= m; ++i) cin >> e[i].u >> e[i].v >> e[i].w;
return 0;
}
复杂度
查询是否存在某条边: 𝑂(𝑚)O(m) 。
遍历一个点的所有出边: 𝑂(𝑚)O(m) 。
遍历整张图: 𝑂(𝑛𝑚)O(nm) 。
空间复杂度: 𝑂(𝑚)O(m) 。
应用
由于直接存边的遍历效率低下,一般不用于遍历图。
在 Kruskal 算法中,由于需要将边按边权排序,需要直接存边。
在有的题目中,需要多次建图(如建一遍原图,建一遍反图),此时既可以使用多个其它数据结构来同时存储多张图,也可以将边直接存下来,需要重新建图时利用直接存下的边来建图。
邻接矩阵
方法
使用一个二维数组 g 来存边,其中 g[u][v] 为 1 表示存在 𝑢u 到 𝑣v 的边,为 0 表示不存在。
如果是带边权的图,可以在 g[u][v] 中存储 𝑢u 到 𝑣v 的边的边权,0 表示没有连接,其他值表示权重。
如果是无向图,则将一条无向边拆成两条方向相反的边即可。(所谓的「无向」,也就等同于「双向」)
#include <iostream>
#include <vector>
using namespace std;
const int N = 1e5+5;
int n, m;
bool vis[N];
bool g[N][N];
bool find_edge(int u, int v) { return g[u][v]; }
void dfs(int u) {
if (vis[u]) return;
vis[u] = true;
for (int v = 1; v <= n; ++v) {
if (g[u][v]) {
dfs(v);
}
}
}
int main() {
cin >> n >> m;
fill_n(vis, N, false); // 将 vis 数组清 false,类似 memset
fill_n(g, N*N, false);
for (int i = 1; i <= m; ++i) {
int u, v;
cin >> u >> v;
g[u][v] = true; // u->v 有条单向边
// 如果是双向边
// g[u][v] = g[v][u] = true;
}
return 0;
}
复杂度
查询是否存在某条边: 𝑂(1)O(1) 。
遍历一个点的所有出边: 𝑂(𝑛)O(n) 。
遍历整张图: 𝑂(𝑛2)O(n2) 。
空间复杂度: 𝑂(𝑛2)O(n2) 。
应用
邻接矩阵只适用于没有重边(或重边可以忽略)的情况。
其最显著的优点是可以 𝑂(1)O(1) 查询一条边是否存在。
由于邻接矩阵在稀疏图上效率很低(尤其是在点数较多的图上,空间无法承受),所以一般只会 在稠密图上使用邻接矩阵。并且,在稠密图上使用邻接矩阵的运行效率远高于邻接表,这是因为 CPU 中顺序访问的速度是远高于随机访问的(缓存命中)。
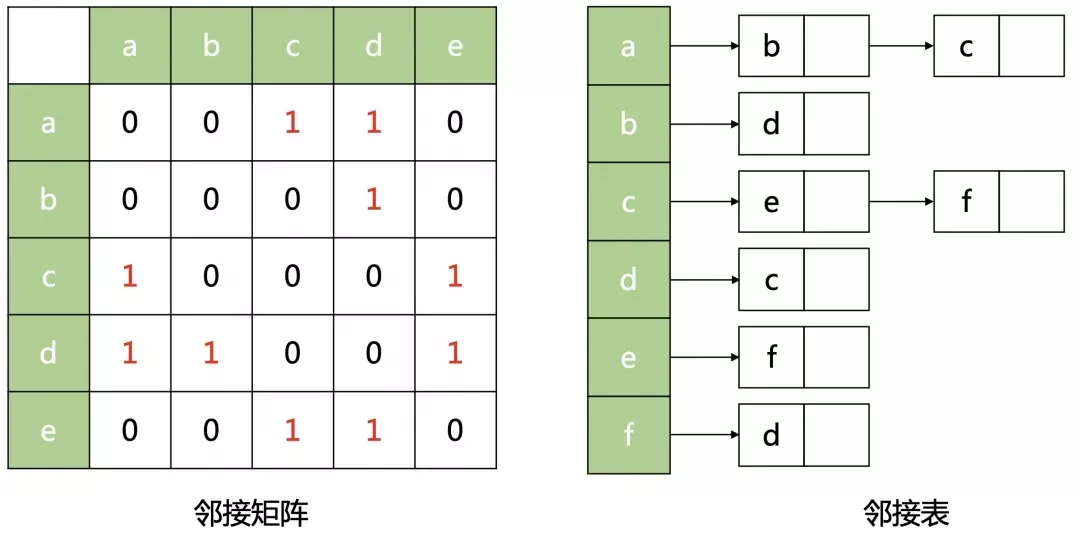
邻接表
方法
使用一个支持动态增加元素的数据结构构成的数组,如 vector<int> g[N] 来存边,其中 g[u] 存储的是点 𝑢u 的所有出边的相关信息(终点、边权等)。
#include <iostream>
#include <vector>
using namespace std;
const int N = 1e5+5;
int n, m;
bool vis[N];
vector<int> g[N];
bool find_edge(int u, int v) {
for (int i = 0; i < g[u].size(); ++i) {
if (g[u][i] == v) {
return true;
}
}
return false;
}
void dfs(int u) {
if (vis[u]) return;
vis[u] = true;
for (int i = 0; i < g[u].size(); ++i) dfs(g[u][i]);
}
int main() {
cin >> n >> m;
vis.resize(n + 1, false);
g.resize(n + 1);
for (int i = 1; i <= m; ++i) {
int u, v;
cin >> u >> v;
g[u].push_back(v);
// 如果是无向图,还须:
// g[v].push_back(u);
}
return 0;
}
复杂度
查询是否存在 𝑢u 到 𝑣v 的边: 𝑂(𝑑+(𝑢))O(d+(u)) (如果事先进行了排序就可以使用 二分查找 做到 𝑂(log(𝑑+(𝑢)))O(log(d+(u))) )。
遍历点 𝑢u 的所有出边: 𝑂(𝑑+(𝑢))O(d+(u)) 。
遍历整张图: 𝑂(𝑛+𝑚)O(n+m) 。
空间复杂度: 𝑂(𝑚)O(m) 。
应用
存各种图都很适合,除非有特殊需求(如需要快速查询一条边是否存在,且点数较少,可以使用邻接矩阵)。
尤其适用于需要对一个点的所有出边进行排序的场合。
链式前向星
方法
本质上是用链表实现的邻接表,示例代码如下:
#include <iostream>
#include <vector>
using namespace std;
const int N = 1e5+5;
int n, m;
bool vis[N];
int head[N], nxt[N], to[N], cnt; // 链式前向星三要素
void add(int u, int v) { // 添加一条 u->v 的边
nxt[++cnt] = head[u]; // cnt 这条边的后继(同是 u 的出边的上一条边)
to[cnt] = v; // 当前边的终点是 v
head[u] = cnt; // 起点 u 的第一条边放到了下标 cnt 处(其实是最后一条)
}
bool find_edge(int u, int v) {
for (int i = head[u]; ~i; i = nxt[i]) { // ~i 表示 i != -1
if (to[i] == v) {
return true;
}
}
return false;
}
void dfs(int u) {
if (vis[u]) return;
vis[u] = true;
cout << u << ' ';
for (int i = head[u]; ~i; i = nxt[i])
dfs(to[i]);
}
int main() {
cin >> n >> m;
fill_n(vis, N, false);
fill_n(head, N, -1);
for (int i = 1; i <= m; ++i) {
int u, v;
cin >> u >> v;
add(u, v);
}
dfs(1);
return 0;
}
如果图是赋权图,即边带有权重时,此时数组定义过多,也可以写成结构体去保存,参考代码如下:
#include<bits/stdc++.h>
using namespace std;
const int N = 1e5; //点数最大值
int n, m; //n个点,m条边
int head[N], cnt = -1; //head[i],表示以i为起点的第一条边在边集数组的位置(编号)
struct Edge
{
int to, w, next; // 终点,边权,同起点的上一条边的编号
}edge[N];//边集
void add_edge(int u, int v, int w)// 加边,u 起点,v 终点,w 边权
{
edge[++cnt].next = head[u]; // 以u为起点上一条边的编号,也就是与这个边起点相同的上一条边的编号
edge[cnt].to = v; // 终点
edge[cnt].w = w; // 权值
head[u] = cnt; // 更新以u为起点上一条边的编号
}
int main()
{
cin >> n >> m;
int u, v, w;
fill_n(head, N, -1);
for (int i = 1; i <= m; i++) // 输入m条边
{
cin >> u >> v >> w;
add_edge(u, v, w); // 加边
// 加双向边
// add_edge(u, v, w);
// add_edge(v, u, w);
}
// 输出每个结点的出边
for (int i = 1; i <= n; i++)
{
cout << i << endl;
for (int j = head[i]; ~j; j = edge[j].next) // 遍历以 i为起点的边
{
cout << i << " " << edge[j].to << " " << edge[j].w << endl;
}
cout << endl;
}
return 0;
}
/*
5 7
1 2 1
2 3 2
3 4 3
1 3 4
4 1 5
1 5 6
4 5 7
*/
复杂度
查询是否存在 𝑢u 到 𝑣v 的边: 𝑂(𝑑+(𝑢))O(d+(u)) 。
遍历点 𝑢u 的所有出边: 𝑂(𝑑+(𝑢))O(d+(u)) 。
遍历整张图: 𝑂(𝑛+𝑚)O(n+m) 。
空间复杂度: 𝑂(𝑚)O(m) 。
应用
注意:利用链式前向星遍历的边的顺序和输入顺序是相反的!
存各种图都很适合,但是缺点也很明显, 不能快速查询一条边是否存在,也不能方便地对一个点的出边进行排序。
优点是边是带编号的,有时会非常有用,而且如果边是从数组的偶数位开始存储( 按上面示例代码写法是从 0 开始存储的,cnt 的初始值为 -1),存双向边时 i ^ 1 即是 i 的反边(常用于网络流 )。
总结
图的存储方法比较多,每种方法各有优缺点,对比如下:
| 直接存边 | 邻接矩阵 | 邻接表 | 链式前向星 | |
|---|---|---|---|---|
| 使用场合 | 需要将边按边权排序时;需要重新建图时利用直接存下的边来建图 | 只适用于没有重边(或重边可以忽略)的情况;可以 𝑂(1)O(1) 查询边;在稠密图上效率很高 | 消耗空间较小,各种场合都适用,尤其适用于需要对点的出边排序的场合 | 消耗空间小,各种场合都适用 |
| 缺点 | 遍历效率低下,一般不用于遍历图 | 只适用于没有重边(或重边可以忽略)的情况。 | 需熟练掌握 vector 操作? | 不能迅速查询边和对一个点的出边排序 |
总的来说,就是:
- 需要对所有边进行排序时,直接存边;
- 图很稠密,用邻接矩阵;
- 其他一般情况,用邻接表或链式前向星都可以。
请在理解各种方法的优缺点并掌握其代码实现以后,面对具体问题应思考选择合适的方法。