大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用30-基于深度卷积神经网络CNN模型实现物体表面缺陷检测技术的项目主要包括:物体表面缺陷检测技术项目介绍,数据构造,模型介绍。 物体表面缺陷检测技术是工业自动化和质量控制领域的一项关键技术,它通过分析物体表面的图像来识别和分类各种缺陷,如划痕、凹陷、裂纹等。基于深度卷积神经网络(CNN)的模型因其强大的特征学习和模式识别能力,在这一领域得到了广泛应用。
物体表面缺陷检测在提高产品质量、降低生产成本和增强市场竞争力方面的意义。开发一个能够自动识别和分类不同类型表面缺陷的系统,该系统应具备高准确率、快速处理能力和良好的泛化性能。在项目实施过程中,首先使用训练集对CNN模型进行训练,通过反向传播算法不断调整网络参数,直至模型在验证集上的性能达到最优。然后,使用测试集评估模型的泛化能力。最后,根据评估结果对模型进行微调,以达到最佳的检测效果。

文章目录
- 一、项目背景与意义
- 二、数据构造
- 2.1 数据收集
- 2.2 数据预处理
- 2.3 数据标注
- 三、模型介绍与实现
- 3.1 模型架构
- 3.2 特征提取
- 3.3 训练与优化
- 3.4 性能评估
- 四、CNN模型的数学原理
- 五、CNN的代码实现
- 六、总结
一、项目背景与意义
物体表面缺陷检测技术在工业自动化和质量控制领域扮演着至关重要的角色。随着工业4.0的推进和智能制造的不断发展,提高产品质量和降低缺陷率成为企业提高竞争力的重要手段。传统的缺陷检测方法主要依靠人工视觉检查,这种方法不仅效率低下,而且容易受到人为因素的影响,从而影响检测的准确性。因此,如何实现高效、准确的自动缺陷检测成为当前工业界和学术界研究的热点问题。
基于深度卷积神经网络(CNN)的模型因其强大的特征学习和模式识别能力,在这一领域得到了广泛应用。深度卷积神经网络可以从原始图像中学习到丰富的特征表示,从而能够识别和分类各种类型的表面缺陷,如划痕、凹陷、裂纹等。与传统的图像处理方法相比,深度卷积神经网络具有更高的检测准确率和更好的鲁棒性。
基于深度卷积神经网络的物体表面缺陷检测技术在工业自动化领域具有重要的应用价值。首先,它可以大大提高生产效率,减少人工成本。自动缺陷检测系统可以在短时间内处理大量的图像数据,完成缺陷的识别和分类工作,从而实现生产过程的快速检测。其次,它可以提高检测的准确性和稳定性。深度卷积神经网络具有很好的泛化能力,能够在不同光照、角度和噪声等条件下识别出各种类型的缺陷,从而保证产品质量的稳定性。它可以促进智能制造的发展。基于深度卷积神经网络的缺陷检测技术可以为工业生产提供实时的质量反馈,帮助企业改进生产工艺,提高产品质量,从而推动智能制造的发展。
物体表面缺陷检测技术在工业自动化和质量控制领域具有重要的应用背景和意义。基于深度卷积神经网络的模型因其强大的特征学习和模式识别能力,在这一领域得到了广泛应用,并取得了显著的成效。未来,随着深度学习技术的不断发展和优化,基于深度卷积神经网络的物体表面缺陷检测技术将在工业自动化领域发挥更加重要的作用。
二、数据构造
2.1 数据收集
在数据构造过程中,2.1 数据收集是至关重要的一步。这涉及到从各种来源获取我们需要的信息或知识,以构建和丰富我们的数据集。这个阶段可能包括网络爬虫抓取公开可用的数据,如社交媒体平台的用户行为,市场研究报告,或者通过问卷调查、实验收集一手数据。例如,在一个电商项目中,我们可能会收集用户的浏览历史、购买记录、搜索关键词等,这些都是理解用户需求、行为模式的关键数据。同时,我们可能还需要从API接口获取实时的天气数据、物流信息等,以提升推荐系统的准确性。在这个过程中,数据的质量和完整性直接影响后续数据分析和模型构建的效果。因此,数据清洗和预处理也是必不可少的步骤,确保数据的准确性和一致性。
2.2 数据预处理
在数据挖掘和机器学习项目中,数据预处理是一个至关重要的步骤,它涉及到对原始数据的清洗、转换和规范化,以使其更适合后续的分析和模型构建。首先,我们会删除或填充缺失值,因为缺失的数据可能引入偏差。例如,在客户满意度调查中,如果某人的年龄字段缺失,我们可能会选择平均值或众数来填充。
异常值检测是必不可少的,因为极端数值可能是错误输入或特殊情况,需要进一步检查或处理。比如在销售数据中,如果发现某个用户的购买量远超常人,可能需要核实是否存在欺诈行为。
我们需要进行数据类型转换,将非数字特征如文本、类别编码为数值形式,以便于算法理解和处理。比如,将顾客的性别从“男”、“女”转化为数值编码,如0和1。
数据归一化或标准化也是常见操作,如将所有数值缩放到0-1之间,或者消除变量之间的量纲差异。这有助于提高某些算法的性能,如神经网络。
对于时间序列数据,我们可能需要进行滑动窗口或采样,以便于处理序列数据中的依赖关系。比如在股票市场预测中,我们可能只关注过去几个月的数据。
通过这些预处理步骤,我们可以确保数据的质量和一致性,从而提升模型的准确性和可靠性。在实际项目中,比如预测用户流失,我们首先会清理掉空值,然后将用户行为数据进行编码,再进行归一化处理,使得每个特征在同一尺度上,最后输入到预测模型中,提高预测结果的准确性。
2.3 数据标注
在数据分析过程中,数据构造(Data Construction)是一个关键步骤,它涉及到从原始数据源中提取、清洗、转换和整合信息,以便形成适合分析的结构化或半结构化数据。这包括处理缺失值、异常值,统一数据格式,以及创建新的特征或指标。例如,如果我们正在构建一个电商网站的用户行为模型,可能需要构造用户ID、浏览商品、购买行为等数据。
数据标注(Data Annotation)则是为机器学习和深度学习模型提供训练样本的过程。它将抽象的数据赋予明确的意义,如图像分类中的物体识别,我们需要人为标记每张图片中的特定对象;文本情感分析中,需要对评论进行正面、负面或中性的情绪标注。以自动驾驶项目为例,每个路面上的交通标志、行人、车辆都需要被专业人员精准标注,以便算法学习和理解不同的交通元素。
在实际项目中,比如我们为一款语音助手开发AI,首先通过数据构造,将用户的语音命令转化为可供机器理解的数字信号,如MFCC特征。接着,进行数据标注,将这些信号与对应的执行动作(如播放音乐、查询天气)进行配对,形成训练集。通过大量的标注数据,模型才能学会理解和响应用户的指令,实现智能对话。
三、模型介绍与实现
3.1 模型架构
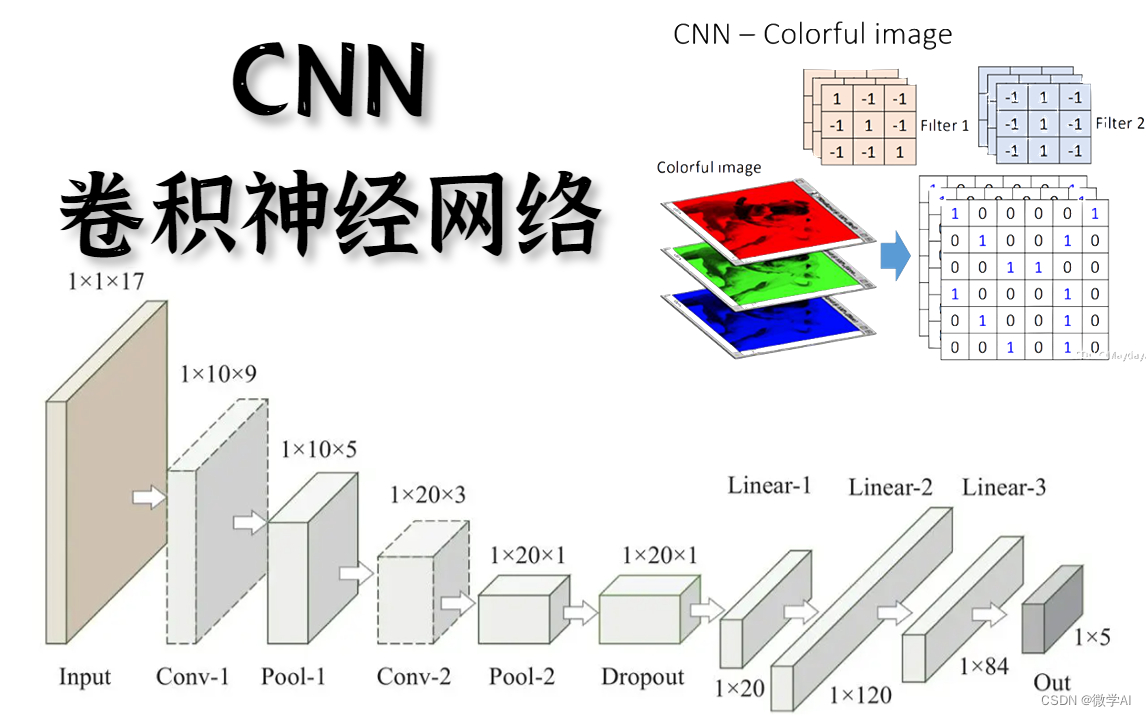
在深度学习项目中,模型架构是核心部分,它决定了模型的结构和能力。以经典的卷积神经网络(CNN)为例,其3.1模型架构通常包括输入层、卷积层、池化层、全连接层和输出层。
首先,输入层接收原始数据,如图像或文本。接着,卷积层通过一组可学习的滤波器对输入数据进行特征提取,每个滤波器可以检测出一种特定的特征,如边缘或纹理。然后,池化层用于降低数据维度,减少计算量,同时提高模型的鲁棒性,常见的有最大池化或平均池化。
全连接层将前几层的输出展平并连接到一个大型的神经网络中,进行高级特征的学习。最后,输出层根据任务需求,可能是分类任务的softmax层,或者回归任务的线性层,输出预测结果。
在实际项目中,比如图像识别任务,我们可能构建一个包含5个卷积层和2个全连接层的ResNet模型。每层卷积后都会添加批量归一化和ReLU激活,以加速训练并防止过拟合。通过调整这些参数和层数,我们可以优化模型性能,使其在CIFAR-10或ImageNet等数据集上达到高精度。这就是模型架构的实际应用和重要性,它就像建筑的蓝图,决定了模型如何理解和处理输入数据。
3.2 特征提取
在深度学习项目中,特征提取是关键的步骤,它相当于人类视觉系统中的"识别模式"。3.2 特征提取部分,我们通常使用预训练的卷积神经网络(CNN)模型,如VGG16、ResNet或Inception等。这些模型已经在大规模图像数据集上进行了训练,学习到了丰富的底层特征,如边缘、纹理、颜色等。
例如,假设我们正在开发一个猫狗分类器。首先,我们会利用预训练的VGG16模型,它已经可以区分出基本的图像元素。我们将图片输入到VGG16,它会返回一系列高维特征向量,每个向量对应模型在不同层级捕捉到的特征。这些特征可能包括眼睛的位置、耳朵的形状、身体的比例等。通过这些特征,我们的模型可以理解图片的内容并区分猫和狗。
接着,我们会对这些特征进行降维或者选择性保留,以减少计算复杂度并提高模型的针对性。最后,我们会添加一层或多层全连接层,用以学习特定任务的分类边界,如猫和狗的区分。
在实际操作中,这就像用一个现成的“看图说话”工具,它能告诉我们图片中包含的基本元素,然后我们只需要告诉它如何理解和解读这些元素来完成特定的任务。这就是特征提取的魅力,它将复杂的图像理解过程转化为机器可处理的数学运算,极大地提高了模型的效率和准确性。
3.3 训练与优化
在深度学习中,模型的训练与优化是至关重要的环节。首先,我们通常会使用大量的标记数据对预训练的模型进行调整,这个过程称为“监督学习”。比如在图像识别项目中,我们会用包含各类物体标签的图片库来训练卷积神经网络(CNN),让模型学习如何从像素级别理解各种特征。
训练过程中,我们会设置一个损失函数,如交叉熵,用来衡量模型预测结果与真实标签的差距。然后,通过反向传播算法,将这个差距以梯度的形式传递回模型,更新每一个参数以减小损失。这是一个迭代的过程,我们通常会设置一个固定的训练轮数或者当损失不再显著下降时停止。
优化器,如Adam或SGD,负责调整学习率和更新策略,帮助我们在参数空间中找到最优解。例如,Adam优化器结合了动量和自适应学习率,能更有效地避免陷入局部最优。
在实际项目中,比如开发一个智能推荐系统,我们会先用历史用户行为数据训练一个深度神经网络,通过优化算法不断调整模型权重,使其能够更准确地预测用户的喜好。每次用户产生新的行为数据,都会被用于模型的在线学习,进一步优化推荐效果。整个过程就是一个不断迭代,优化模型性能的过程。
3.4 性能评估
在深度学习项目中,模型介绍与实现是关键环节。首先,我们会选择适合问题的模型架构,例如卷积神经网络(CNN)用于图像识别,或者循环神经网络(RNN)处理序列数据。我们会详细阐述模型的工作原理,比如CNN通过卷积层提取特征,全连接层进行分类;RNN则通过时间步来捕捉序列中的长期依赖。
性能评估则是检验模型效果的重要步骤。我们通常使用准确率、精确率、召回率、F1分数等指标来量化模型预测的准确性。还会进行交叉验证,确保模型在未见过的数据上表现稳定。此外,可能还会引入AUC-ROC曲线或混淆矩阵,以便更全面地理解模型性能。
以一个实际项目为例,比如开发一个垃圾分类系统,我们可能会选择ResNet作为图像识别模型。训练过程中,我们会监控损失函数和精度的变化,调整超参数以优化模型。在测试阶段,我们会用准确率和召回率来衡量模型对垃圾类别(如可回收物、厨余垃圾等)的识别能力。如果发现某些类别识别率低,可能需要调整网络结构或增加数据增强手段。通过这些步骤,我们可以确保模型在实际应用中有较高的识别效率和稳定性。
四、CNN模型的数学原理
在基于深度卷积神经网络(Convolutional Neural Network, CNN)的物体表面缺陷检测项目中,我们通常采用一种多层结构来提取和分析输入图像中的特征。以下是一个简化的模型描述:
y
=
f
(
X
;
θ
)
,
\mathbf{y} = f(\mathbf{X}; \theta),
y=f(X;θ),
其中, X \mathbf{X} X 是输入的物体表面图像数据集,每一幅图像可以表示为一个高维矩阵,其维度为 H × W × C H \times W \times C H×W×C,其中 H H H、 W W W 分别是图像的高度和宽度, C C C 是颜色通道数(如RGB三通道)。
模型参数 θ \theta θ 包括一系列的卷积核(convolutional filters)、池化层(pooling layers)、批量归一化(batch normalization)层、全连接层(fully connected layers)以及激活函数(activation functions)的权重和偏置。这些参数通过反向传播算法(backpropagation)进行训练,以最小化损失函数(loss function),比如交叉熵损失(cross-entropy loss):
L ( θ ) = − 1 N ∑ i = 1 N y i log ( y ^ i ) + ( 1 − y i ) log ( 1 − y ^ i ) , L(\theta) = -\frac{1}{N}\sum_{i=1}^{N} y_i \log(\hat{y}_i) + (1 - y_i) \log(1 - \hat{y}_i), L(θ)=−N1i=1∑Nyilog(y^i)+(1−yi)log(1−y^i),
其中, N N N 是样本总数, y i y_i yi 是真实标签, y ^ i \hat{y}_i y^i 是模型预测的概率值。
模型的具体计算过程如下:
-
卷积层:使用卷积核对输入图像进行卷积操作,生成特征图(feature maps),可以表示为:
Z l = σ ( W l ∗ Z l − 1 + b l ) , \mathbf{Z}^l = \sigma(\mathbf{W}^l * \mathbf{Z}^{l-1} + \mathbf{b}^l), Zl=σ(Wl∗Zl−1+bl),
其中, Z l \mathbf{Z}^l Zl 是第 l l l层的特征图, W l \mathbf{W}^l Wl 是卷积核, b l \mathbf{b}^l bl 是偏置项, σ \sigma σ 是激活函数(如ReLU, sigmoid或tanh)。 -
池化层:对特征图进行下采样,减少计算量,同时提高模型的平移不变性:
P l = Pool ( Z l ) , \mathbf{P}^l = \text{Pool}(\mathbf{Z}^l), Pl=Pool(Zl),
常见的池化操作有最大池化(max pooling)和平均池化(average pooling)。 -
全连接层:将池化后的特征映射展平,然后通过全连接层进行分类:
Z f c = W f c ⋅ Flatten ( P L ) + b f c , \mathbf{Z}_{fc} = \mathbf{W}_{fc} \cdot \text{Flatten}(\mathbf{P}^L) + \mathbf{b}_{fc}, Zfc=Wfc⋅Flatten(PL)+bfc,
最后通过softmax函数得到分类概率分布:
y ^ = softmax ( Z f c ) . \hat{\mathbf{y}} = \text{softmax}(\mathbf{Z}_{fc}). y^=softmax(Zfc).
优化器(optimizer)如Adam、SGD等用于更新参数
θ
\theta
θ 以最小化损失函数,使得模型能够准确地识别和定位物体表面的缺陷。
五、CNN的代码实现
以下是一个简单的基于PyTorch的深度卷积神经网络(CNN)模型用于物体表面缺陷检测的基本示例。这个例子假设你已经有了预处理好的训练和测试数据集,并且已经安装了PyTorch库。
# 导入所需的库
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# 定义CNN模型
class DefectDetector(nn.Module):
def __init__(self):
super(DefectDetector, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(64 * 8 * 8, 128)
self.fc2 = nn.Linear(128, 2) # 2 for binary classification (defective or not)
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.pool(x)
x = self.conv2(x)
x = self.relu(x)
x = x.view(-1, 64 * 8 * 8)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
# 初始化模型,设置损失函数和优化器
model = DefectDetector()
criterion = nn.CrossEntropyLoss() # For binary classification
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 假设我们有训练数据集和测试数据集
train_dataset = ... # Your training dataset
test_dataset = ... # Your testing dataset
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
# 训练模型
num_epochs = 10
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.float() / 255.0
labels = labels.long()
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch+1, num_epochs, i+1, len(train_loader), loss.item()))
# 测试模型
model.eval()
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.float() / 255.0
labels = labels.long()
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the model on the 10000 test images: {} %'.format(100 * correct / total))
注意:这只是一个基本的示例,实际项目中可能需要更复杂的预处理步骤、数据增强、模型调整等。此外,你需要根据你的数据集定义train_dataset和test_dataset,并且可能需要调整网络结构和参数。
六、总结
在工业自动化的浪潮中,物体表面缺陷检测技术如一位细心的质检员,默默守护着产品质量的门槛。基于深度卷积神经网络(CNN)的模型,以其深邃的洞察力和精准的判断力,成为这一领域的明星。本项目旨在构建一个智能的缺陷检测系统,它能够在繁杂的工业图像中,准确识别出划痕、凹陷、裂纹等瑕疵,如同鹰眼般锐利。
项目的核心在于数据的精雕细琢和模型的巧妙构建。我们收集了大量的物体表面图像,经过图像增强、尺寸统一和数据增强等预处理,如同将原始的矿石炼制成精钢。CNN模型则是我们手中的利剑,卷积层、激活函数、池化层和全连接层的巧妙组合,使其能够从图像中提取出丰富的特征,如同艺术家从画布上捕捉光影的变幻。
在训练的熔炉中,模型不断吸收知识,反向传播算法如同炼金术士的咒语,引导着网络参数的微妙调整。验证集和测试集是检验成果的试金石,模型的泛化能力在这里得到验证,如同战士在战场上检验自己的剑法。
我们的模型如同一位经验丰富的工匠,不仅能够快速识别出缺陷,而且准确无误,为工业生产提供了坚实的质量保障。这个项目不仅是一项技术的突破,更是工业智能化进程中的一块重要基石,它预示着未来工业质检将更加智能、高效,为提升产品质量和市场竞争力贡献着不可忽视的力量。