FusionVision: A Comprehensive Approach of 3D Object Reconstruction and Segmentation from RGB-D Cameras Using YOLO and Fast Segment Anything
FusionVision:使用 YOLO 和 Fast Segment Anything 从 RGB-D 相机重建和分割 3D 对象的综合方法
toread:Real-time 3D Object Detection from Point Clouds using an RGB-D Camera
Abstract
在计算机视觉领域,鉴于不同的环境条件和不同的物体外观所产生的固有复杂性,将先进技术集成到 RGB-D 相机输入的预处理中提出了重大挑战。因此,本文介绍了 FusionVision,这是一种适用于 RGB-D 图像中对象的鲁棒 3D 分割的详尽管道。传统的计算机视觉系统主要针对 RGB 相机,因此在同时捕获精确的物体边界和在深度图上实现高精度物体检测方面面临着局限性。为了应对这一挑战,FusionVision 采用了一种集成方法,将最先进的对象检测技术与先进的实例分割方法相结合。这些组件的集成可以对 RGB-D 数据进行整体(对从颜色 RGB 和深度 D 通道获得的信息进行统一分析)解释,有助于提取全面且准确的对象信息,以改进对象 6D 等后处理姿态估计、同步定位和建图 (SLAM) 操作、精确的 3D 数据集提取等。所提出的 FusionVision 管道采用 YOLO 来识别 RGB 图像域内的对象。随后,应用创新的语义分割模型 FastSAM 来描绘对象边界,从而产生精细的分割掩模。这些组件之间的协同作用及其与 3D 场景理解的集成确保了对象检测和分割的紧密融合,从而提高了 3D 对象分割的整体精度。
1. Introduction
点云处理的重要性已在各个领域激增,例如机器人[1,2]、医疗领域[3,4]、自动驾驶[5,6]、计量[7,8,9]等。在过去几年中,视觉传感器的进步带来了显着的改进,使这些传感器能够提供周围环境的实时 3D 测量,同时保持良好的精度 [10, 11]。因此,点云处理通过促进强大的对象检测、分割和分类操作,形成了众多应用的重要枢纽。
在计算机视觉领域,两个广泛研究的支柱很突出:对象检测和对象分割。这些子领域在过去几十年中吸引了研究界的关注,帮助计算机理解视觉数据并与之交互[12,13,14]。对象检测涉及识别和定位图像或视频流中的一个或多个对象,通常采用先进的深度学习技术,例如卷积神经网络(CNN)[15]和基于区域的CNN(R-CNN)[16]。对实时性能的追求导致了更高效模型的开发,例如 Single Shot MultiBox Detector (SSD) [17] 和 You Only Look Once (YOLO) [18],它们展示了准确性和速度之间的平衡性能。另一方面,对象分割超越了检测过程,允许描绘每个已识别对象的精确边界[19]。分割过程可以更好地理解视觉场景并在给定图像中精确定位对象。在文献中,两种分割类型是有区别的:语义分割为每个像素分配一个类标签[20],而实例分割则区分同一类的各个实例[21]。
最流行的目标检测模型之一是(YOLO)。 YOLO 的最新已知版本是 YOLOv8,它是一种实时目标检测系统,使用单个神经网络同时预测边界框和类概率 [22, 23]。它的设计速度快、准确,适合自动驾驶汽车和安全系统等应用。 YOLO 的工作原理是将输入图像划分为一个单元格网格,其中每个单元格预测固定数量的边界框,然后使用定义的置信度阈值对这些边界框进行过滤。然后调整剩余边界框的大小并重新定位以适合它们预测的对象。最后一步是对剩余的边界框执行非极大值抑制[24]以消除重叠的预测。 YOLO 使用的损失函数是两个术语的组合:定位损失和置信度损失。定位损失衡量预测的边界框坐标和地面实况坐标之间的差异,而置信度损失衡量预测的类概率和地面实况类别之间的差异。
另一方面,SAM [25]是最近流行的用于图像分割任务的深度学习模型。它基于医疗应用中常用的 U-Net 架构 [26,27,28]。 U-Net是专门为图像分割而设计的CNN,由编码器和解码器组成,编码器和解码器通过跳跃连接连接[29]。编码器负责从输入图像中提取特征,而解码器则处理分割掩模的生成。跳跃连接允许模型使用编码器在不同抽象级别学习到的特征,这有助于生成更准确的分割掩模。 SAM 之所以受欢迎,是因为它在各种图像分割基准和许多领域(例如医学领域 [30])以及其他已知数据集(例如 PASCAL VOC 2012 [31])上实现了最先进的性能。它在分割城市环境中常见的复杂对象(例如建筑物、道路和车辆)时特别有效。该模型跨不同数据集和任务的泛化能力极大地促进了其受欢迎程度。
科学界仍在广泛研究 YOLO 和 SAM 的使用并在 2D 计算机视觉任务中进行现场应用 [32,33,34]。然而,在本文中,我们重点研究两种最先进算法在 RGB-D 图像上的参与可能性。 RGB-D 相机是深度感应相机,可捕获场景的 RGB 通道(红、绿、蓝)和 D 映射(深度信息)(示例如图 1 所示)。这些相机使用红外 (IR) 投影仪和传感器来测量物体与相机的距离,从而以足够的精度为 RGB 图像提供额外的深度维度。例如,根据 F. Pan 等人的说法。 [35],在用于面部扫描的 RGB-D 相机上评估了 0.61 ± 0.42 mm 的估计精度。与传统 RGB 相机相比,RGB-D 相机具有多项优势,包括:
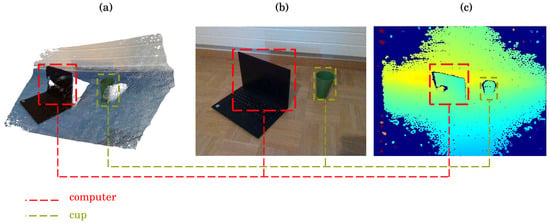
图 1. RGB-D 相机场景捕获和 3D 重建示例。 (a) 从 RGB-D 深度通道进行 3D 重建。 (b) 从 RGB 传感器捕获 RGB 流。 © 使用 ColorMap JET 进行深度视觉估计(较近的物体用绿色表示,较远的物体用深蓝色区域表示)。
(1)改进的对象检测和跟踪 [36]:RGB-D 相机提供的深度信息可以实现更准确的对象检测和跟踪,即使在具有遮挡和变化的照明条件的复杂环境中也是如此。
(2)3D 重建 [37, 38]:RGB-D 相机可用于创建对象和环境的 3D 模型,从而实现增强现实 (AR) 和虚拟现实 (VR) 等应用。
(3)人机交互[39, 40]:RGB-D相机提供的深度信息可用于检测和跟踪人体运动,从而实现更自然、直观的人机交互。
RGB-D 相机具有广泛的应用,包括机器人、计算机视觉、游戏和医疗保健。在机器人技术中,RGB-D 相机用于对象操纵 [41]、导航 [42] 和映射 [43]。在计算机视觉中,它们用于 3D 重建 [37]、对象识别和跟踪 [44, 45]。所有这些算法都利用深度信息来处理 3D 数据而不是图像。点云处理可以提高对象跟踪的准确性,从而提高有关其在 3D 空间中的位置、方向和尺寸的知识。与传统的基于图像的系统相比,这具有明显的优势。此外,由于使用了红外照明,RGB-D 技术还能够超越各种照明条件[46]。
本文介绍了 RGB-D 以及对象检测和分割领域的贡献。主要贡献在于 FusionVision 的开发和应用,这是一种将最初为 2D 图像提出的模型与 RGB-D 类型数据链接起来的方法。具体来说,已经实施、验证和调整了两个已知模型,以便通过使用英特尔实感摄像头的深度和 RGB 通道来处理 RGB-D 数据。这种组合增强了对场景的理解,从而实现了 3D 对象隔离和重建,而没有失真或噪音。此外,还集成了点云后处理技术,包括去噪和下采样,以消除由反射率或不准确的深度测量引起的异常和失真,从而提高FusionVision管道的实时性能。代码和预训练模型可在 https://github.com/safouaneelg/FusionVision/ 上公开获取(于 2024 年 2 月 28 日访问)。
本文的其余部分安排如下。尽管所提出的管道具有独特性,并且缺乏与本文提出的方法类似的方法,但第 2 节中讨论的相关工作很少。第 3 节给出了 FusionVision 管道的详细而全面的描述,其中讨论了这些过程一步步。接下来,第 4 节介绍和讨论了框架的实施和结果。最后,第 5 节总结了本文的研究结果。
2.Related Work
前面提到的YOLO和SAM模型主要是针对2D计算机视觉操作而提出的,缺乏对RGB-D图像的适应性。因此,物体的 3D 检测和分割超出了它们的能力,从而需要 3D 物体检测方法。在此背景下,针对 RGB-D 相机的 3D 对象检测和分割研究的方法很少。谭Z.等人。 [47]提出了一种用于 3D 对象定位的改进的 YOLO(版本 3)。该方法旨在使用单个 RGB-D 相机从点云实现实时高精度 3D 物体检测。作者提出了一种结合 2D 和 3D 物体检测算法的网络系统,以改善实时物体检测结果并提高速度。所使用的两种最先进的对象检测方法的组合是 [48] 从 RGB 传感器执行对象检测和 Frustum PointNet [49],这是一种使用视锥体约束来预测物体的 3D 边界框的实时方法。目的。方法框架可概括如下(图2):
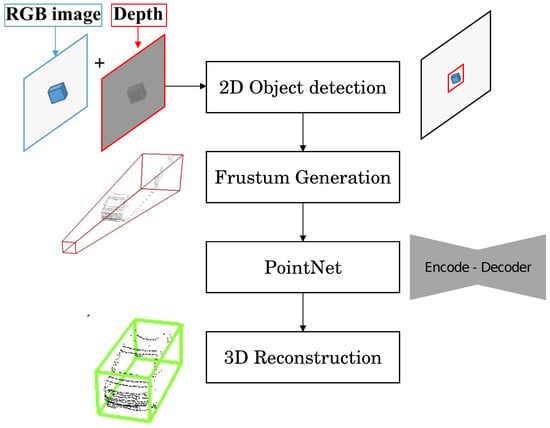
图 2. 用于 3D 对象重建和定位的复杂 YOLO 框架 [47]。
1.该系统首先从单个 RGB-D 相机获取 3D 点云以及 RGB 流。
2.2D 对象检测算法用于检测和定位 RGB 图像中的对象。这提供了有关对象的有用先验信息,包括它们的位置、宽度和高度。
3.来自 2D 对象检测的信息随后用于生成 3D 平截头体。平截头体是一个金字塔形状的体积,它基于 2D 边界框表示对象在 3D 空间中的可能位置。
4.生成的视锥体被输入到 PointNets 算法中,该算法执行实例分割并预测视锥体内每个对象的 3D 边界框。
通过结合 2D 和 3D 物体检测算法的结果,该系统实现了室内和室外的实时物体检测性能。对于方法评估,作者表示使用英特尔实感 D435i RGB-D 相机实现实时 3D 物体检测,算法在基于 NVIDIA GTX 1080 ti GPU 的系统上运行。然而,这种提出的方法有局限性,并且通常由于深度和物体反射率的估计不佳而受到噪声的影响。
3. FusionVision Pipeline
除了第一步数据采集之外,所实施的 FusionVision 流程可概括为六个步骤(图 3):

1.数据采集和注释:这个初始阶段涉及获取适合训练对象检测模型的图像。该图像集合可以包括单类或多类场景。作为准备所获取数据的一部分,需要分成指定用于训练和测试目的的单独子集。如果感兴趣的对象位于 Microsoft COCO(上下文中的通用对象)数据集 [50] 的 80 个类别内,则此步骤可能是可选的,从而允许利用现有的预训练模型。否则,如果要检测特殊物体,或者物体形状不常见或与数据集中的物体形状不同,则需要执行此步骤。
2.YOLO模型训练:数据采集后,YOLO模型接受训练以增强其检测特定物体的能力。此过程涉及根据获取的数据集优化模型的参数。
3.应用模型推理:训练成功后,YOLO 模型将部署在 RGB-D 相机的 RGB 传感器的实时流上,以实时检测物体。此步骤涉及应用经过训练的模型来识别相机视野内的物体。
4.FastSAM应用:如果在RGB流中检测到任何对象,则估计的边界框将作为FastSAM算法的输入,以便于提取对象掩模。此步骤利用 FastSAM 的功能完善对象分割过程。
5.RGB 和深度匹配:RGB 传感器生成的估计掩模与 RGB-D 相机的深度图对齐。这种对齐是通过利用已知的内在和外在矩阵来实现的,从而提高了后续 3D 对象定位的准确性。
6.深度图 3D 重建的应用:利用对齐的掩模和深度信息,生成 3D 点云,以便于在三个维度上实时定位和重建检测到的对象。最后一步会产生 3D 空间中对象的孤立表示。
3.1. Data Acquisition
对于需要检测特定物体的应用,数据采集包括使用特定物体的相机在不同角度、位置和变化的照明条件下收集大量图像。随后需要使用与图像中对象的位置相对应的边界框对图像进行注释。此步骤可以使用多个注释器,例如 Roboflow [51]、LabelImg [52] 或 VGG Image Annotator [53]。
3.2. YOLO Training
训练 YOLO 模型进行稳健的目标检测构成了 FusionVision 管道的强大支柱。获取的数据分为 80% 用于训练,20% 用于验证。为了进一步增强模型的泛化能力,通过水平和垂直翻转图像以及应用轻微的角度倾斜来采用数据增强技术[54]。


在整个训练过程中,图像及其相应的注释被输入 YOLO 网络 [22]。网络依次生成边界框、类概率和置信度分数的预测。然后使用上述损失函数将这些预测与真实数据进行比较。这个迭代过程逐渐提高模型的目标检测精度,直到达到总损失的最小值。
3.3. FastSAM Deployment
训练 YOLO 模型后,其边界框将作为涉及 FastSAM 模型的后续步骤的输入。处理完整图像时,FastSAM 会估计所有查看对象的实例分割掩码。因此,不需要处理整个图像,而是使用 YOLO 估计的边界框作为输入信息,将注意力集中在对象所在的相关区域,从而显着减少计算开销。然后,其基于 Transformer 的架构深入研究这个裁剪后的图像补丁,以生成像素级掩模。训练 YOLO 模型后,其边界框将作为涉及 FastSAM 模型的后续步骤的输入。处理完整图像时,FastSAM 会估计所有查看对象的实例分割掩码。因此,不需要处理整个图像,而是使用 YOLO 估计的边界框作为输入信息,将注意力集中在对象所在的相关区域,从而显着减少计算开销。然后,其基于 Transformer 的架构深入研究这个裁剪后的图像补丁,以生成像素级掩模。
3.4. RGB and Depth Matching
RGB-D 成像设备通常包含一个负责捕获传统 2D 彩色图像的 RGB 传感器,以及一个集成左右摄像头以及位于中间的红外 (IR) 投影仪的深度传感器。投射到物理对象上的红外图案会因其形状而扭曲,然后被左右摄像机捕获。然后,利用两幅图像中对应点之间的视差信息来估计场景中每个像素的深度。作为 FastSAM 输出的提取片段通过相机 RGB 通道中的二进制掩码表示。 DS 中物理对象的识别是通过对齐二进制掩模和深度帧来实现的(图 4)。
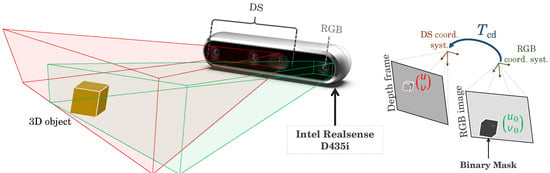
在此对准过程中,需要使用校准过程或基于默认工厂值来估计 RGB 相机和深度传感器的坐标系之间的转换。很少有校准技术可以用于改进矩阵估计,例如[55, 56]。该变换在数学上用等式(5)表示:


3.5. 3D Reconstruction of the Physical Object
一旦 FastSAM 掩模与深度图对齐,识别出的物理对象就可以在 3D 坐标中重建,仅考虑感兴趣区域 (ROI)。该过程涉及几个关键步骤,包括:(1) 下采样,(2) 去噪,以及 (3) 为点云中每个识别的对象生成 3D 边界框。
下采样过程应用于原始点云数据,可以降低计算复杂性,同时保留基本的对象信息。所选择的下采样技术涉及体素化,其中点云被分为规则的体素网格,并且每个体素仅保留一个点[57]。下采样之后,实施基于统计异常值去除的去噪程序[58]以提高生成的点云的质量。识别可能由传感器噪声引起的异常值并将其从点云中删除。最后,对于在对齐的 FastSAM 掩模中检测到的每个物理对象,在去噪点云内生成一个 3D 边界框。边界框生成涉及创建一组沿每个轴连接最小和最大坐标的线。这组线与去噪点云中对象的位置对齐。生成的边界框提供了检测到的对象的 3D 空间表示。
4. Results and Discussion
4.1. Setup Configuration
在实验研究中,所提出的框架在三种常用物理对象的检测上进行了测试:杯子、计算机和瓶子。表 1 总结了已使用的设置配置。
表 1. 实时 FusionVision 管道的设置配置。

4.2. Data Acquisition and Annotation
在数据采集步骤中,使用 RealSense 相机的 RGB 流捕获了总共 100 张具有常见物体(即杯子、电脑和瓶子)的图像。记录的图像包括所选 3D 物理对象的多个姿势和照明条件,以确保模型训练的稳健和全面的数据集。使用 YOLO 对象检测模型的 Roboflow 注释器对图像进行注释。此外,还应用数据增强技术来丰富数据集,包括水平和垂直翻转以及角度倾斜(图 5)。

图 5. YOLO 训练获取的图像示例:顶部两张图像是原始图像,底部两张图像是增强图像。
4.3. YOLO Training and FastSAM Deployment
4.3.1. Model Training and Deployment
对象检测的训练是在获取的图像和增强的图像的情况下进行的。图 6 总结了训练结果和验证曲线,包括损失函数 𝐶𝐿𝑆𝐿𝐶𝐿𝑆𝐿 和 𝐵𝑏𝑜𝑥𝐿𝐵𝑏𝑜𝑥𝐿 、精度和召回率,以及最后的 mAP50 和 mAP50-95 指标。 mAP50 测量当预测边界框和地面实况边界框之间的重叠阈值(IoU - 并集交集)设置为 50% 时,模型在不同对象类中的平均精度。 mAP50-95 是 mAP50 的扩展,它考虑了从 50% 到 95% 的 IoU 阈值范围,通过考虑更广泛的重叠标准来提供对模型性能的更全面的评估。使用最小的 YOLO 模型变体 yolov8n(学习率为 0.01)和 Adam 优化器[59]对 YOLO 算法进行了 300 个 epoch 的训练。
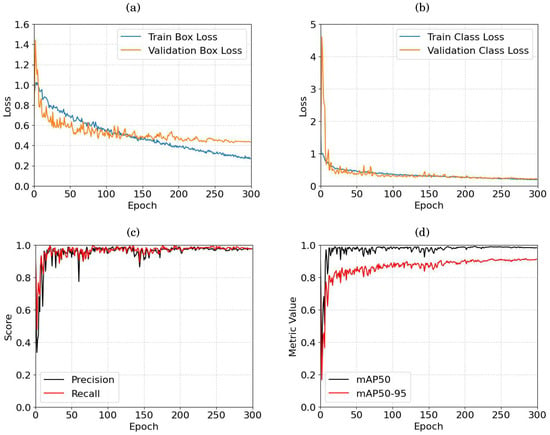
图 6. YOLO 训练曲线:(a) bbox 损失,(b) cls 损失,© 精度和召回率,以及 (d) mAP50 和 mAP50-95。
对于bbox损失(图6a),train box损失表现出持续减少,需要考虑额外的epoch。相比之下,validation box 损失大约在第 200 个时期稳定在 0.48 左右,此后达到稳定水平。类别损失曲线(图 6b)展示了更快的收敛速度,训练损失曲线和验证损失曲线都迅速下降。在第 100 个时期左右,曲线开始稳定,在随后的时期中显示出轻微的持续下降。检查精确度和召回率(图 6c),观察到两个参数在 206 纪元左右稳定,估计值分别为 97.08% 和 96.94%。关于 mAP50 和 mAP50-95(图 6d),两个指标在 170 纪元左右达到稳定状态,值相继达到 97.92% 和 87.9%。
训练完成后,获得的权重将用于 RGB 帧实时流上的对象检测。 FastSAM 的部署是集成的,将检测到的边界框作为 FastSAM 模型的输入。检测到掩码后,将其转换为二进制掩码。 YOLO、FastSAM 和二进制掩码提取的结果如图 7 所示。

图 7a 展示了使用预先训练的 YOLO 模型的物体检测结果,突出了其在检测某些物体(主要是瓶子)同时实现其他两个物体杯子和笔记本电脑的高精度(平均值为 90%)方面的挑战。另一方面,图 7b 展示了自定义训练是一种用于检测预训练模型未覆盖的特定对象的解决方案,对瓶子实现了 91% 的最低准确率。
4.3.2. Quantitative Analysis
对经过训练的目标检测 YOLO 模型进行了全面评估,以评估不同环境条件下的鲁棒性和泛化能力。评估过程涉及三组不同的图像。每组包含 20 到 30 个图像,旨在代表实际部署中遇到的不同场景。 (1) 第一组图像包含与模型训练期间使用的环境和照明条件相似的环境和照明条件。这些图像可作为评估模型在熟悉环境中的性能的基线,并提供对其处理训练领域内变化的能力的见解。 (2) 与训练数据相比,第二组图像引入了对象位置、方向和照明条件的变化。通过捕获更广泛的场景,该集合能够评估模型对物体位置、方向和照明变化的适应性,同时模拟遮挡和阴影等现实世界的挑战。 (3) 第三组图像通过合并完全不同的背景、表面和照明条件,呈现出与训练数据更显着的偏差。该集旨在测试模型在其训练领域之外的泛化能力,例如评估其在具有不同视觉特征的新环境中准确检测对象的能力。
表 2 全面分析了 YOLO 模型在不同测试子集的交并集 (IoU) 和精度指标方面的性能。
表 2. 与真实注释的三个测试子集相比,YOLO 在边界框估计方面的性能总结。

在这些场景中,“cup”类始终表现出卓越的性能,在所有测试集上均获得了较高的 IoU 和 Precision 分数(IoU 和 Precision 分别为 0.96 和 0.99)。这一性能表明模型准确定位和分类杯子实例的能力具有鲁棒性,无论环境因素或对象配置如何。相反,“瓶子”类表现出最低的 IoU 和 Precision 分数,特别是对于测试集 (3),其值分别为 0.52 和 0.31。它表明在更复杂的环境条件或对象方向下准确定位和分类瓶子实例面临额外的挑战。
除了 YOLO 评估之外,FastSAM 还通过一个子集的注释进行分析,以创建一组地面实况实例分割掩模。这些掩模已重叠并分组在单个阵列中,然后转换为二值图像,从而可以对掩模预测质量进行总体评估。之后,FastSAM 通过将预测的 YOLO 边界框作为输入来预测对象掩模。生成的掩模也会转换为二值图像,然后与地面真实图像进行比较。分割算法的评估涉及评估各种指标以衡量其性能。 Jaccard 指数(也称为并集交集)和 Dice 系数 [60] 是评估预测和真实掩模之间重叠的关键指标,值越高表示一致性越好。精确度量化了积极预测的准确性,而召回率衡量了识别对象的所有相关实例的能力[61]。 F1 分数平衡了精确度和召回率,提供了同时考虑误报和漏报的单一指标。 ROC 曲线下面积 (AUC) 通过绘制真阳性率与假阳性率的关系来评估不同阈值设置下的分割性能 [62]。逐像素准确度(PA)提供了像素级别分割准确度的总体衡量标准[63]。
在评估分割算法时,获得的结果总结在图 8 中。平均指标在各种评估标准中都显示出较高的值:杰卡德指数 (IoU) 为 0.94,骰子系数为 0.92,AUC 为 0.95,精度为 0.93,召回率为 0.94 ,F1 分数为 0.92,像素精度为 0.96。然而,考虑指标的标准差有助于理解结果的可变性。尽管平均指标总体上令人满意,但标准差在评估中显示出一些可变性(范围从像素准确度的 0.12 到 0.20),并表明算法中需要改进或优化的领域。在评估分割算法时,获得的结果总结在图 8 中。由于标准偏差分析假设数据呈高斯分布,因此任何干扰(由于某些传感器姿态下的 FastSAM 掩模估计不准确而导致的异常值)都可能导致错误估计(图 7 中的示例) 9).在这种情况下,中值绝对偏差值(范围从 0.0029 到 0.0097)可以进一步了解数据的分布并补充标准偏差分析。
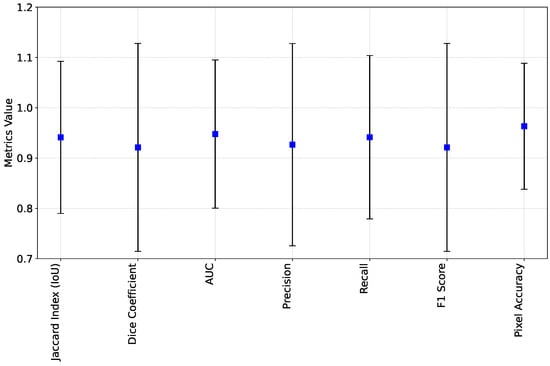
图 8. FastSAM 的总体评估指标应用于提取的 YOLO 边界框,并与地面实况注释进行比较。蓝点指的是指标值,黑色部分是标准差。
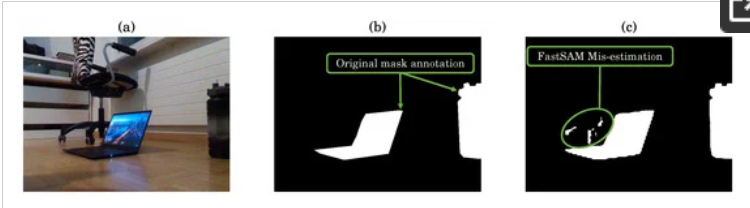
图 9. FastSAM 分割掩码错误估计的示例:(a) 原始图像,(b) 真实注释掩码,以及 © FastSAM 估计掩码。
4.4. 3D Object Reconstruction and Discussion
然后使用默认的实感参数 𝑟𝑠.𝑎𝑙𝑖𝑔𝑛_𝑡𝑜𝑟𝑠.𝑎𝑙𝑖𝑔𝑛_𝑡𝑜 和K矩阵[64]将生成的掩模与深度帧对齐。 RGB 和深度图像的所选原始分辨率均为 640×480 ,这会在全视图重建点云中产生大约 300k 3D 点。应用 FusionVision 管道时,背景已被移除,点数减少至 32k 左右,并且仅将检测集中在感兴趣的区域,从而实现更准确的对象识别。
在执行 3D 对象重建之前,点云会经过下采样和去噪程序,以增强可视化和准确性。下采样是使用 Open3D 的体素下采样方法实现的,体素大小为 5 个单位。随后,使用以下参数将统计异常值去除应用于下采样的点云:邻居 =300 和标准偏差比 =2.0。这些过程会产生精细且去噪的点云,解决噪声和冗余数据点等常见问题。这种精致的点云是精确 3D 对象重建的基础。 YOLO和FastSAM的实时性能已接近 130.6ms≈32.68fps130.6ms≈32.68fps ,因为图像处理涉及三个主要部分:预处理(1毫秒)、运行推理(27.3毫秒)和后处理结果(2.3 毫秒)。当将原始、未处理的 3D 对象点云的 3D 处理和可视化结合起来时,实时性能降低至 5 fps。因此,需要额外的点云后处理,包括下采样和去噪。结果如图 10 所示。
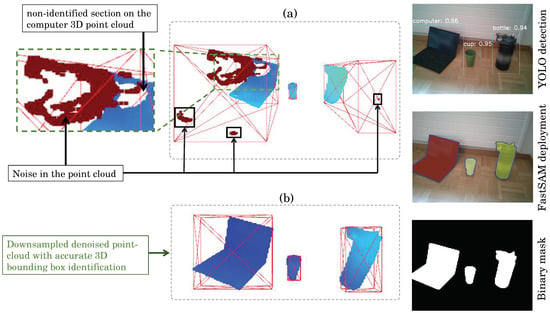
图 10. 根据对齐的 FastSAM 掩模重建三维对象:(a) 原始点云和 (b) 通过体素下采样和统计降噪技术进行后处理点云。左侧图像可视化帧内物理对象特定位置处的 YOLO 检测、FastSAM 掩模提取和二进制掩模估计。
在图10a中,我们可以区分噪声的存在和错误的深度估计,这主要是由于物体反射率和视差计算不准确造成的。因此,后处理提高了 3D 边界框检测的准确性,如图 10b 所示,同时保持 3D 对象的准确表示。
图 11 说明了不同处理技术对源自原始点云的点分布和对象重建的影响:(a) 原始点云,(b) 下采样点云,以及 © 下采样 + 去噪点云:
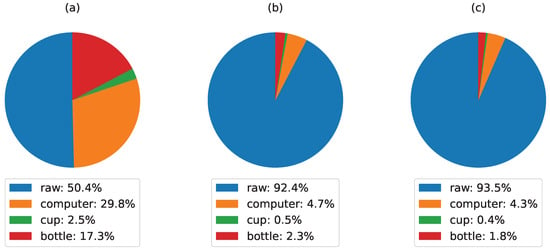
图 11. 后处理对 3D 对象重建的影响:(a) 原始点云,(b) 下采样点云,以及 © 下采样 + 去噪点云。
在图 11a 中,原始点云在不同对象类别之间显示出相对平衡的分布。值得注意的是,电脑和瓶子类别贡献显着,分别占总分的 29.8% 和 17.3%。与此同时,杯子和其他物体所占的比例较小。该点云存在一些噪声和不准确的 3D 估计。
在图 11b 中,原始点云在没有去噪的情况下使用 𝑣𝑜𝑥𝑒𝑙=5𝑣𝑜𝑥𝑒𝑙=5 进行下采样,观察到分配给计算机和瓶子类别的点大幅减少(分别为 4.7% 和 2.3%),这提高了实时性能,同时保持对物体 3D 结构的良好估计。
在图 11c 中,下采样的点云进一步进行去噪。该分布与图 11b 相对相似,其中计算机和瓶子类别略有下降(分别为 4.3% 和 1.8%),同时消除了每个检测到的对象的点云噪声。
表 3 总结了逐步应用 FusionVision Pipeline 时的帧速率演变。
2D 图像处理和 3D 点云数据的融合使得对象检测和分割有了显着的改进。通过结合这两种不同的信息源,我们已经能够消除超过 85% 的组合无趣和嘈杂的点云,从而获得场景内对象的高度准确和集中的表示。这可以增强场景理解,并实现单个对象的可靠定位,然后可以将其用作 6D 对象姿势识别、3D 跟踪、形状和体积估计以及 3D 对象识别的输入。 FusionVision 管道的准确性和效率使其特别适合实时应用,例如自动驾驶、机器人和增强现实。
5. Conclusions
FusionVision 是 3D 对象检测、分割和重建领域的综合方法。概述的 FusionVision 管道包含一个多步骤过程,包括基于 YOLO 的对象检测、FastSAM 模型执行以及随后使用点云处理技术集成到三维空间中。这种整体方法不仅提高了物体识别的准确性,而且丰富了对环境的空间理解。通过实验和评估获得的结果强调了FusionVision框架的效率。首先,YOLO 模型在自定义创建的数据集上进行训练,然后部署在实时 RGB 帧上。随后将 FastSAM 模型应用于该帧,同时考虑检测到的对象边界框来估计其掩模。最后,点云处理技术已添加到管道中,以增强 3D 分割和场景理解。这消除了特定物理对象 3D 重建中超过 85% 的不必要点云。估计的对象 3D 边界框很好地定义了空间中 3D 对象的形状。所提出的 FusionVision 方法展示了高实时性能,特别是在室内场景中,可用于多种应用,包括机器人、增强现实和自主导航。通过部署 FusionVision(具有 11 GB 内存的 NVIDIA GPU RTX 2080 Ti),它可以达到约 27.3 fps(每秒帧数)的实时性能,同时从 RGB-D 视图准确地重建 3D 对象。这样的性能强调了所提出的框架在实际部署中的可扩展性和多功能性。 从角度来看,FusionVision 的持续发展可能涉及利用最新的零样本探测器来增强其物体识别能力。此外,针对基于提示的特定对象识别和实时 3D 重建等操作的语言模型 (LLM) 集成的研究是未来增强的一个有希望的途径。











![[蓝桥杯]真题讲解:数三角(枚举+STL)](https://img-blog.csdnimg.cn/direct/27129fb34d6a405bbb527ec6d2253fa9.png)