目录
- 第 10 周 17、 大规模机器学习(Large Scale Machine Learning)
- 17.1 大型数据集的学习
- 17.2 随机梯度下降法
第 10 周 17、 大规模机器学习(Large Scale Machine Learning)
17.1 大型数据集的学习
如果我们有一个低方差的模型,增加数据集的规模可以帮助你获得更好的结果。我们应该怎样应对一个有 100 万条记录的训练集?
以线性回归模型为例,每一次梯度下降迭代,我们都需要计算训练集的误差的平方和,如果我们的学习算法需要有 20 次迭代,这便已经是非常大的计算代价。
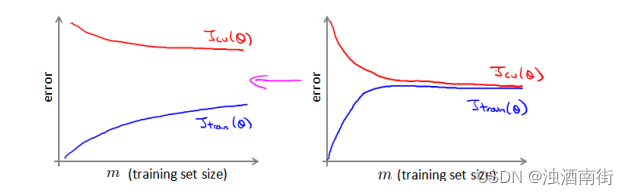
首先应该做的事是去检查一个这么大规模的训练集是否真的必要,也许我们只用 1000个训练集也能获得较好的效果,我们可以绘制学习曲线来帮助判断。
17.2 随机梯度下降法
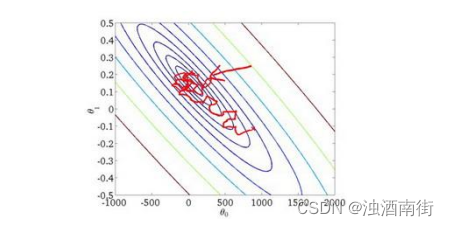
如果我们一定需要一个大规模的训练集,我们可以尝试使用随机梯度下降法(SGD)来代替批量梯度下降法。
在随机梯度下降法中,我们定义代价函数为一个单一训练实例的代价:
c
o
s
t
(
θ
,
(
x
(
i
)
,
y
(
i
)
)
)
=
1
2
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
cost (θ, (x^{(i)}, y^{(i)})) =\frac{1}{2}(h_θ(x^{(i)}) − y^{(i)})^2
cost(θ,(x(i),y(i)))=21(hθ(x(i))−y(i))2
随机梯度下降算法为:首先对训练集随机“洗牌”,然后:
Repeat (usually anywhere between1-10){
for i = 1: m{
θ: =
θ
j
−
α
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
θ_j − α(h_θ(x^{(i)}) − y^{(i)})x_j^{(i)}
θj−α(hθ(x(i))−y(i))xj(i)
(for 𝑗 = 0: 𝑛)
}
}
随机梯度下降算法在每一次计算之后便更新参数 𝜃 ,而不需要首先将所有的训练集求和,在梯度下降算法还没有完成一次迭代时,随机梯度下降算法便已经走出了很远。但是这样的算法存在的问题是,不是每一步都是朝着”正确”的方向迈出的。因此算法虽然会逐渐走向全局最小值的位置,但是可能无法站到那个最小值的那一点,而是在最小值点附近徘徊。