Tips:"分享是快乐的源泉💧,在我的博客里,不仅有知识的海洋🌊,还有满满的正能量加持💪,快来和我一起分享这份快乐吧😊!
喜欢我的博客的话,记得点个红心❤️和小关小注哦!您的支持是我创作的动力!数据源存放在我的资源下载区啦!
数据可视化(十):Pandas数据分析师职位信息表分析——箱线图、水平柱状图、学历城市双维分析等高级操作
目录
- 数据可视化(十):Pandas数据分析师职位信息表分析——箱线图、水平柱状图、学历城市双维分析等高级操作
- 案例二:数据分析师职位信息表分析
- 问题1:将firstType列的 空值 填充为 "未知"
- 问题2:处理positionId列重复值(按照positionId去重),保留第一次出现的重复行
- 问题3:获取平均工资,形成新列 average_salary
- 问题4:城市分布情况画出水平柱状图对比
- 问题5:平均薪资概率图(将平均薪资分成50个柱子)
- 问题6:按城市画出平均工资箱线图
- 问题7:按学历画出平均工资箱线图
- 问题8:按工作年限画出平均工资箱线图
- 问题9:学历、城市双维度画出平均工资箱线图
- 问题10:直方图显示各个城市薪资最小值 最大值 平均值
- 问题11:直方图显示各个城市各学历平均值
- 问题12: 对薪资划分等级,然后作堆积百分比柱形图
- 问题13:将positionLables职位标签信息作为词云显示
本次作业绘图可采用seaborn、matplotlib库或者pandas内置绘图功能
案例二:数据分析师职位信息表分析
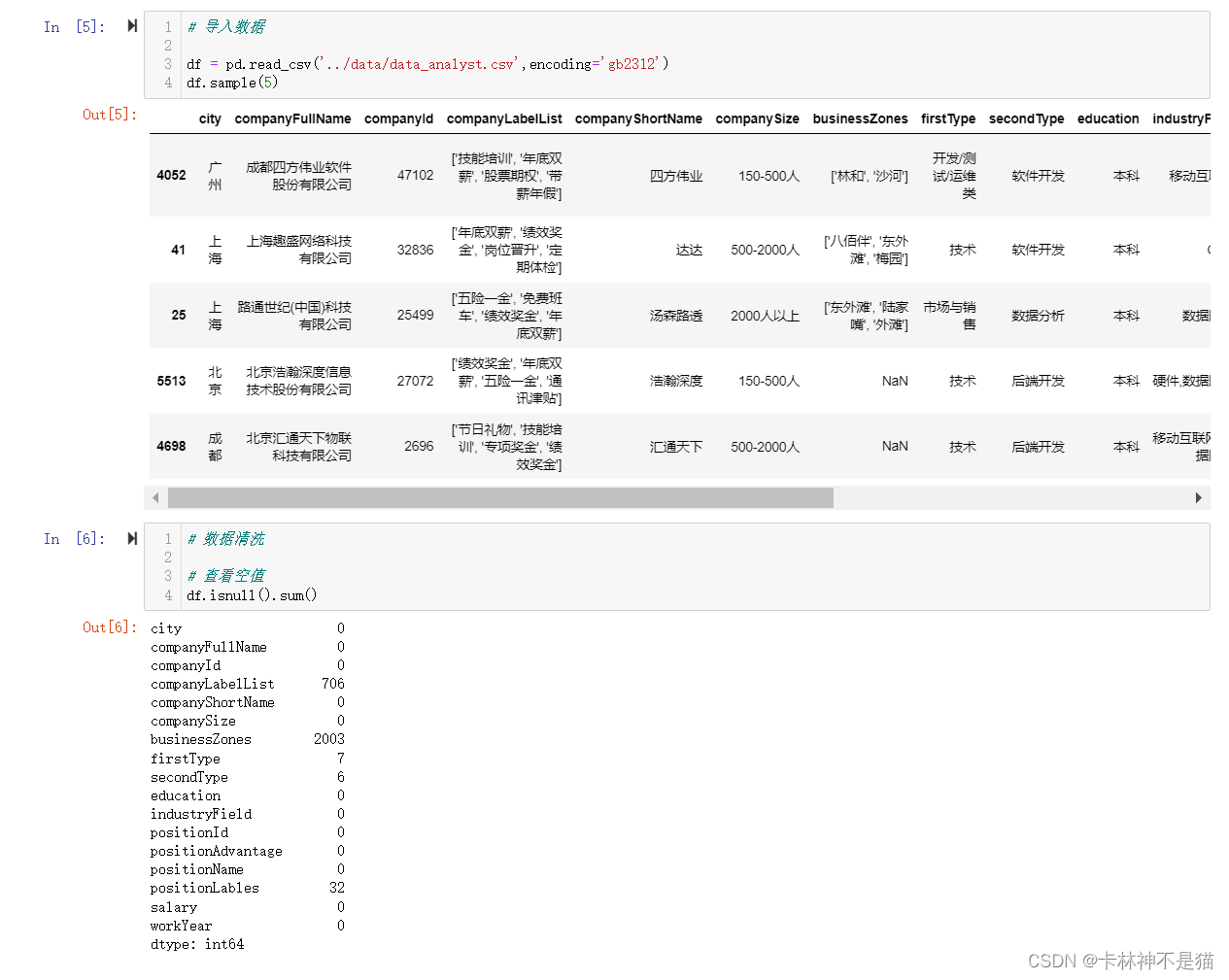
# 导入数据
df = pd.read_csv('data/data_analyst.csv',encoding='gb2312')
df.sample(5)
# 数据清洗
# 查看空值
df.isnull().sum()
问题1:将firstType列的 空值 填充为 “未知”
# 处理空值
display( df.firstType.unique() )
df['firstType'].fillna("未知", inplace=True)
df.fillna("未知", inplace=True)
# 处理重复值
len(df.positionId)-df.positionId.nunique()

问题2:处理positionId列重复值(按照positionId去重),保留第一次出现的重复行
# 去重
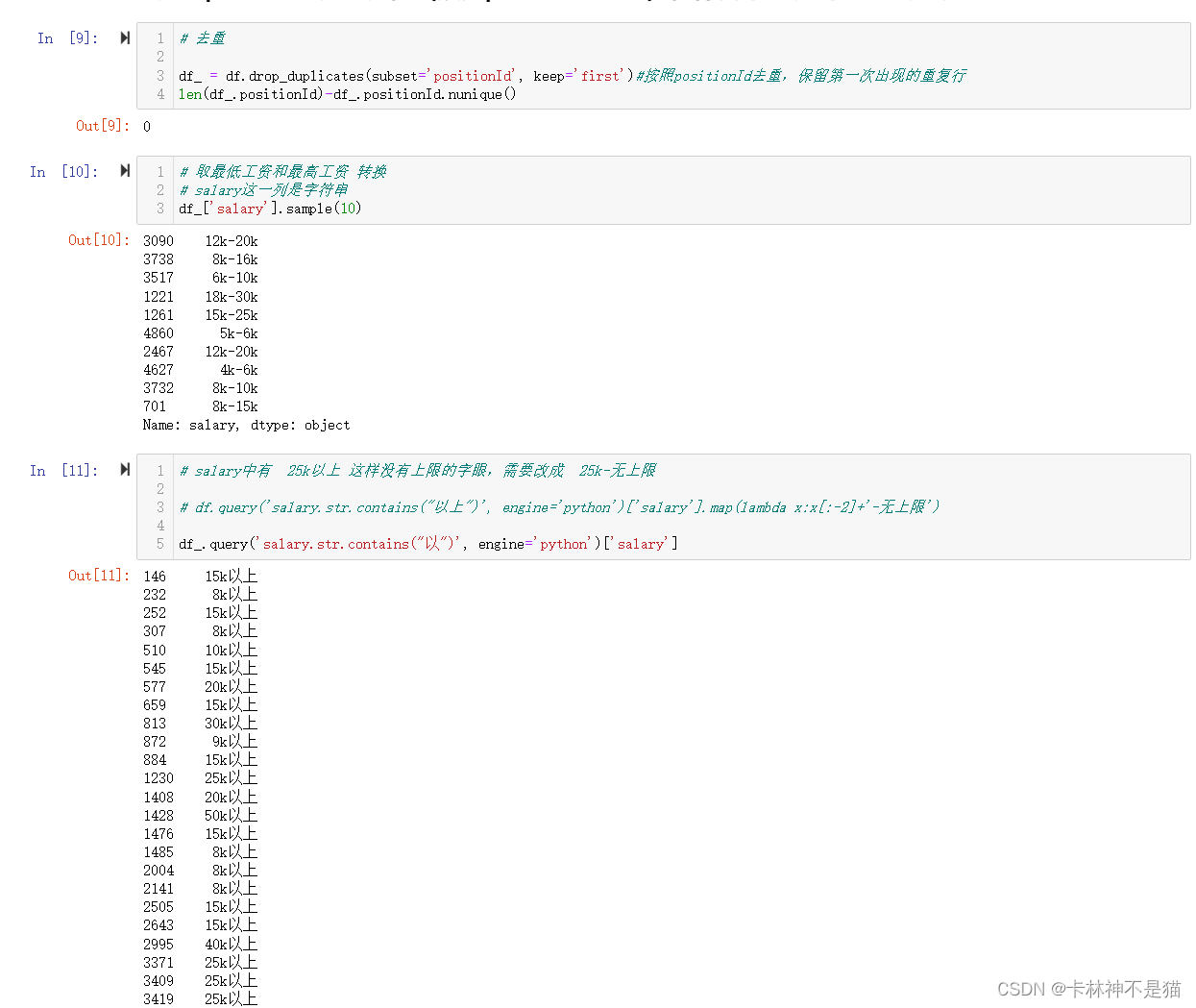
df_ = df.drop_duplicates(subset='positionId', keep='first')#按照positionId去重,保留第一次出现的重复行
len(df_.positionId)-df_.positionId.nunique()
# 取最低工资和最高工资 转换
# salary这一列是字符串
df_['salary'].sample(10)
# salary中有 25k以上 这样没有上限的字眼,需要改成 25k-无上限
# df.query('salary.str.contains("以上")', engine='python')['salary'].map(lambda x:x[:-2]+'-无上限')
df_.query('salary.str.contains("以")', engine='python')['salary']
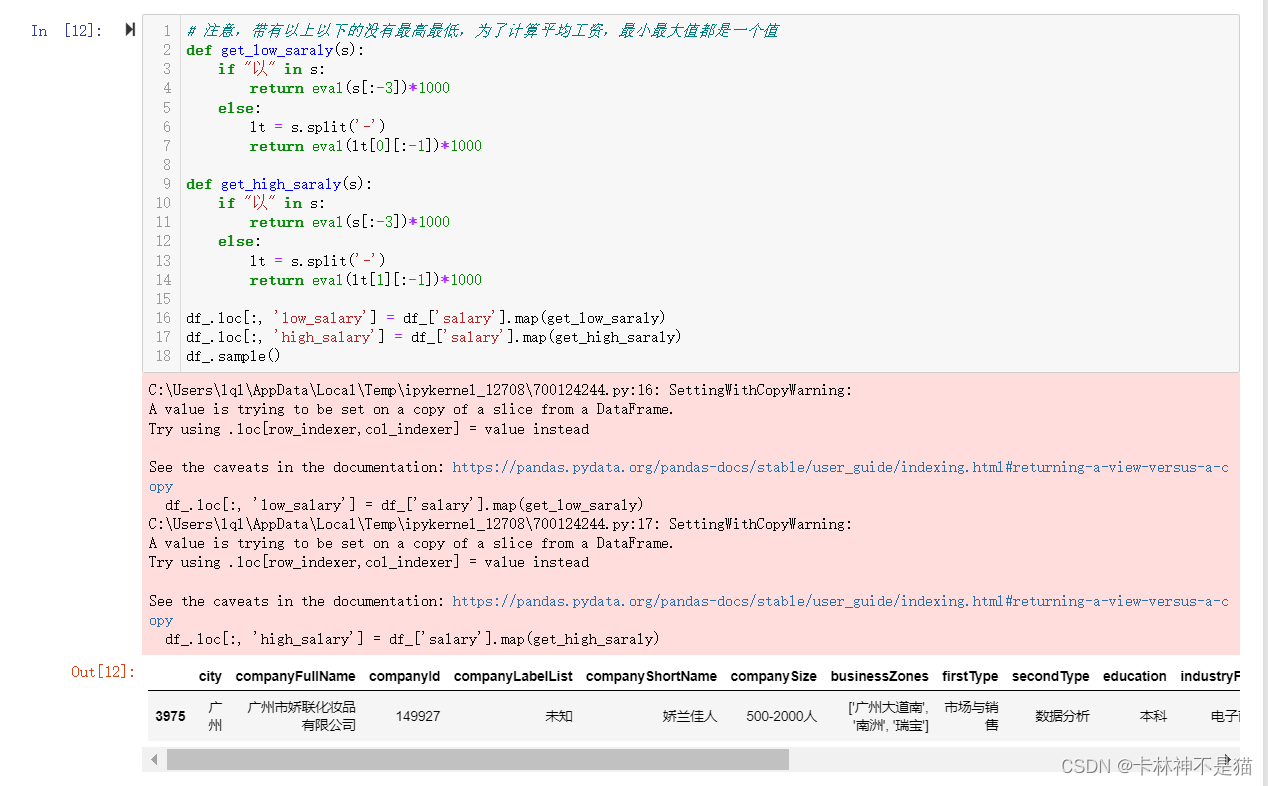
# 注意,带有以上以下的没有最高最低,为了计算平均工资,最小最大值都是一个值
def get_low_saraly(s):
if "以" in s:
return eval(s[:-3])*1000
else:
lt = s.split('-')
return eval(lt[0][:-1])*1000
def get_high_saraly(s):
if "以" in s:
return eval(s[:-3])*1000
else:
lt = s.split('-')
return eval(lt[1][:-1])*1000
df_.loc[:, 'low_salary'] = df_['salary'].map(get_low_saraly)
df_.loc[:, 'high_salary'] = df_['salary'].map(get_high_saraly)
df_.sample()
问题3:获取平均工资,形成新列 average_salary
# 获取平均工资
df_.loc[:, 'average_salary'] = (df_['low_salary'] + df_['high_salary'])/2
df_.sample(5)

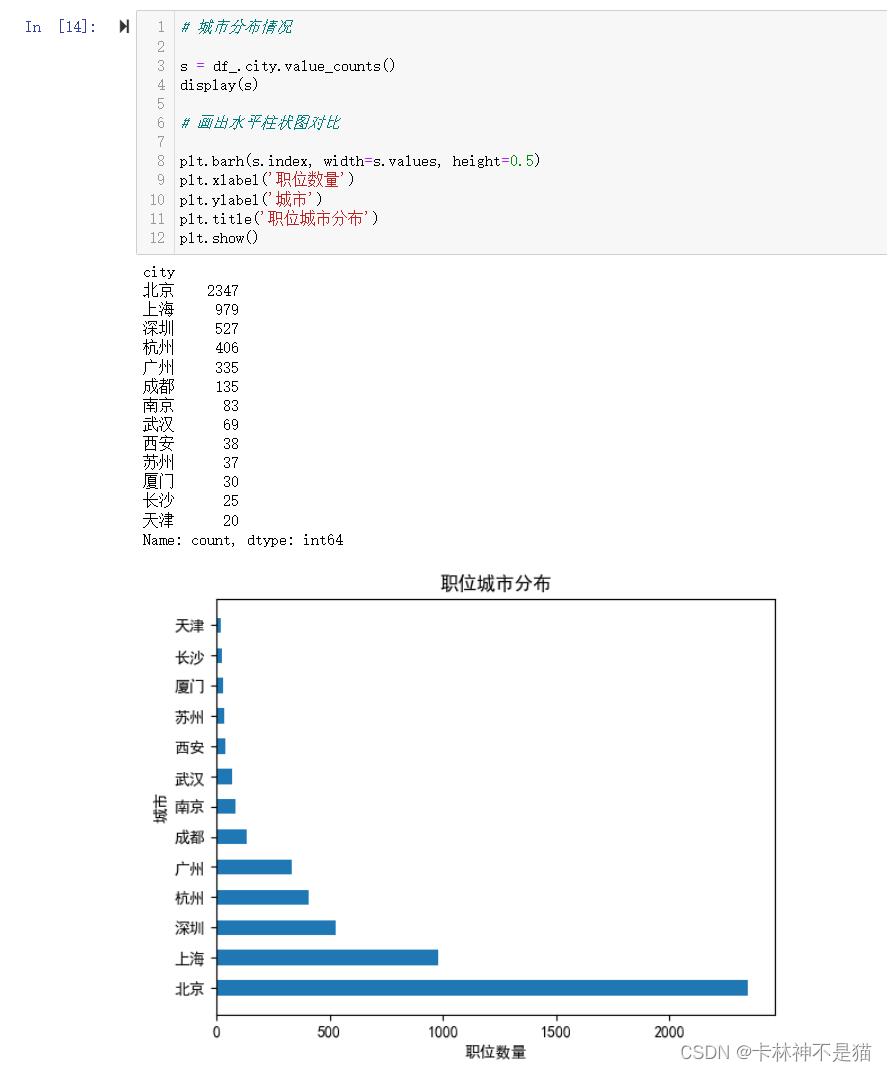
问题4:城市分布情况画出水平柱状图对比
# 城市分布情况
s = df_.city.value_counts()
display(s)
# 画出水平柱状图对比
plt.barh(s.index, width=s.values, height=0.5)
plt.xlabel('职位数量')
plt.ylabel('城市')
plt.title('职位城市分布')
plt.show()
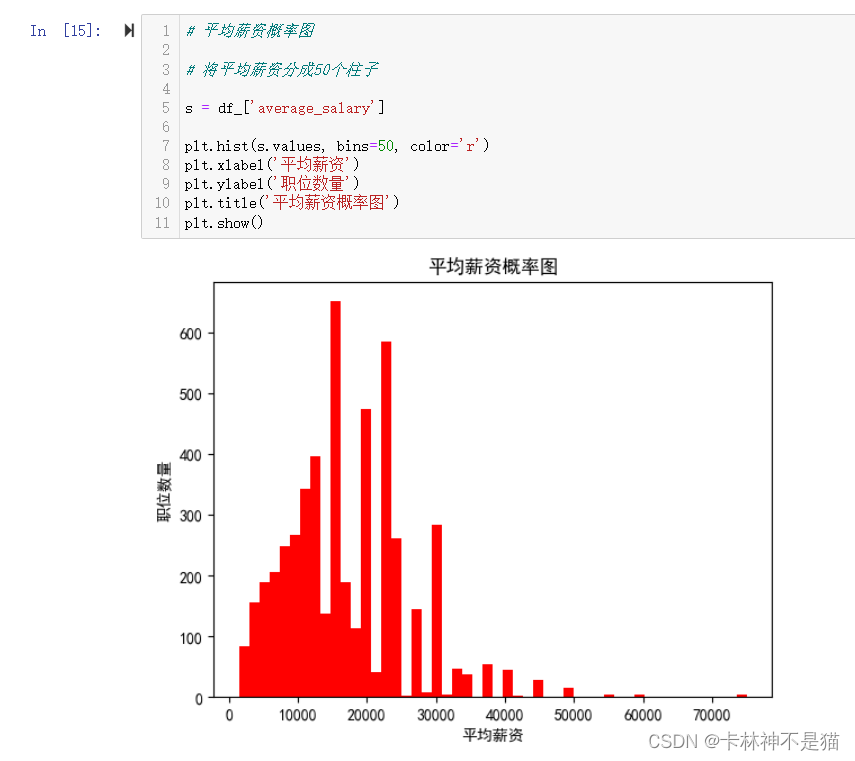
问题5:平均薪资概率图(将平均薪资分成50个柱子)
# 平均薪资概率图
# 将平均薪资分成50个柱子
s = df_['average_salary']
plt.hist(s.values, bins=50, color='r')
plt.xlabel('平均薪资')
plt.ylabel('职位数量')
plt.title('平均薪资概率图')
plt.show()
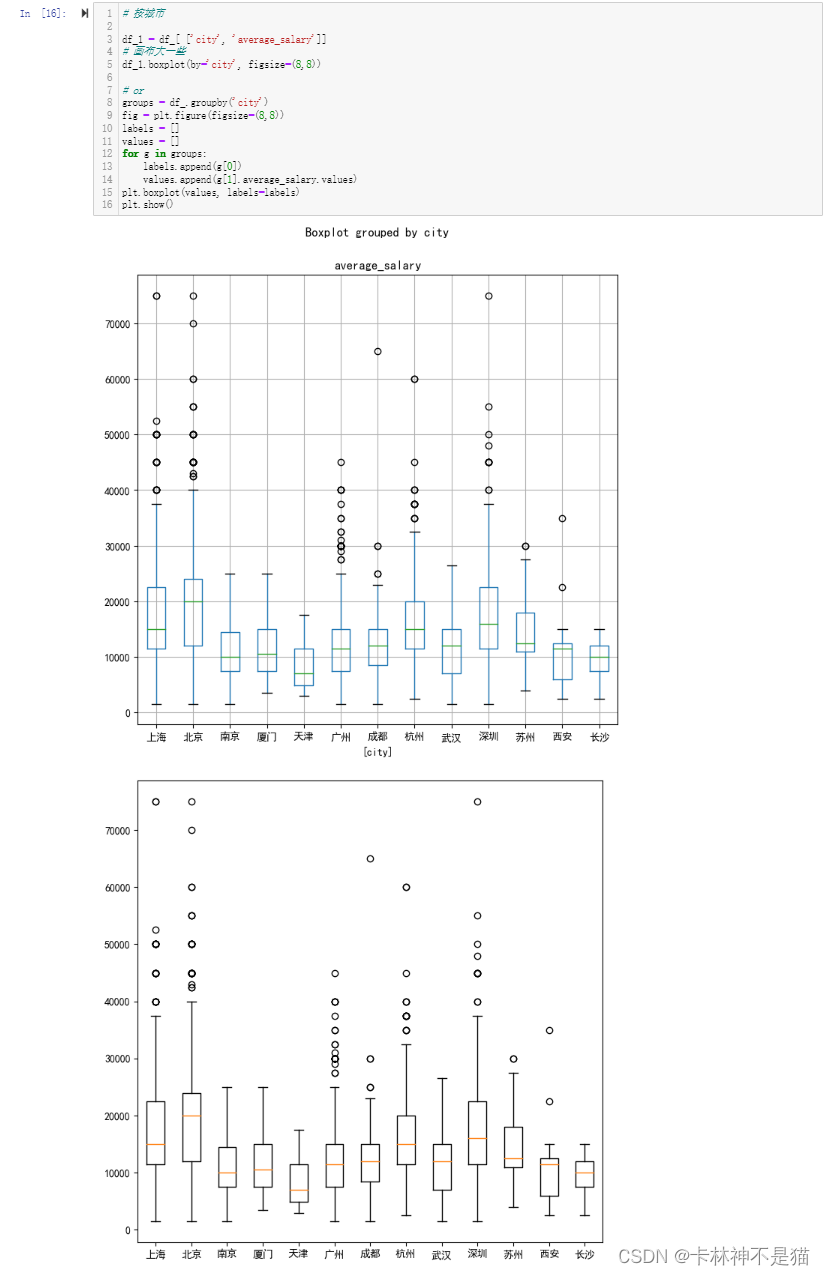
问题6:按城市画出平均工资箱线图
# 按城市
df_1 = df_[ ['city', 'average_salary']]
# 画布大一些
df_1.boxplot(by='city', figsize=(8,8))
# or
groups = df_.groupby('city')
fig = plt.figure(figsize=(8,8))
labels = []
values = []
for g in groups:
labels.append(g[0])
values.append(g[1].average_salary.values)
plt.boxplot(values, labels=labels)
plt.show()
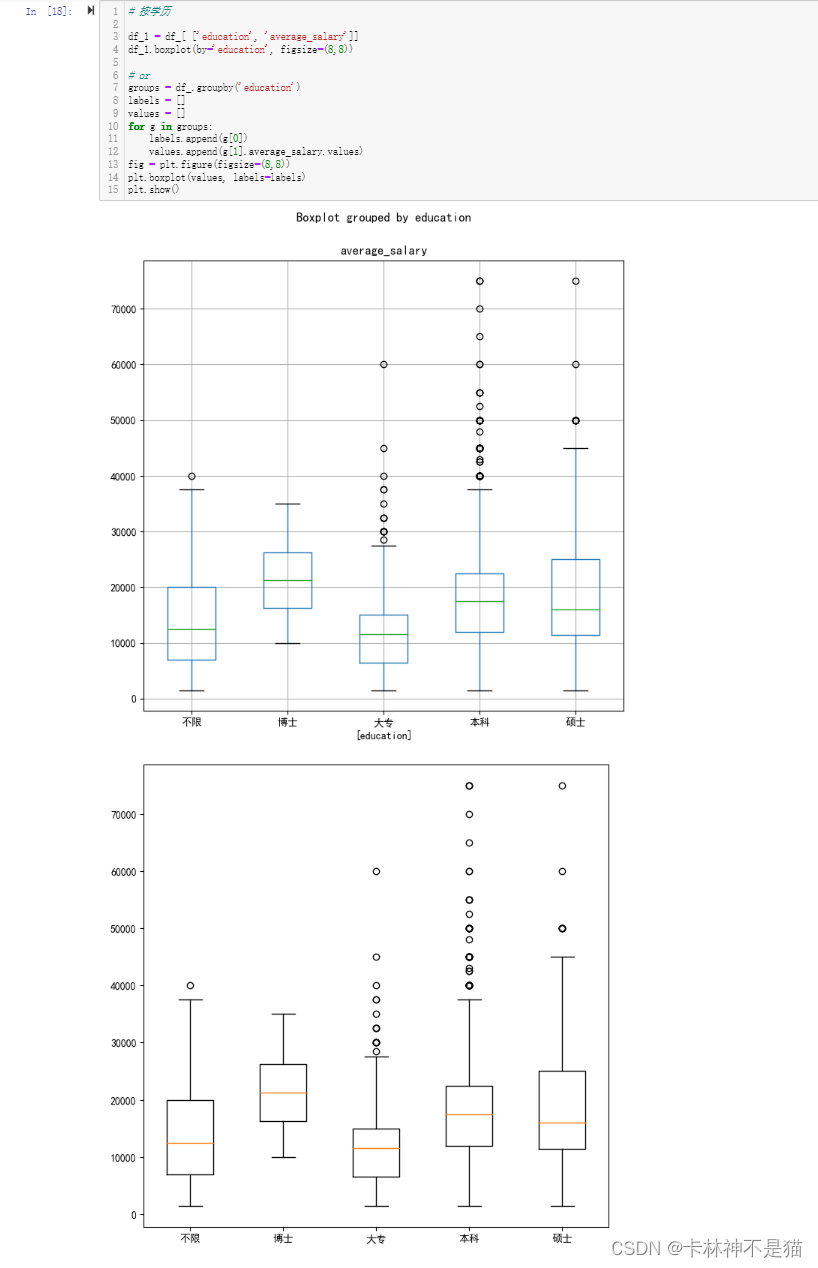
问题7:按学历画出平均工资箱线图
# 按学历
df_1 = df_[ ['education', 'average_salary']]
df_1.boxplot(by='education', figsize=(8,8))
# or
groups = df_.groupby('education')
labels = []
values = []
for g in groups:
labels.append(g[0])
values.append(g[1].average_salary.values)
fig = plt.figure(figsize=(8,8))
plt.boxplot(values, labels=labels)
plt.show()
问题8:按工作年限画出平均工资箱线图
# 按工作年限
df_1 = df_[ ['workYear', 'average_salary']]
df_1.boxplot(by='workYear', figsize=(8,8))
# or
groups = df_.groupby('workYear')
labels = []
values = []
for g in groups:
labels.append(g[0])
values.append(g[1].average_salary.values)
fig = plt.figure(figsize=(8,8))
plt.boxplot(values, labels=labels)
plt.show()
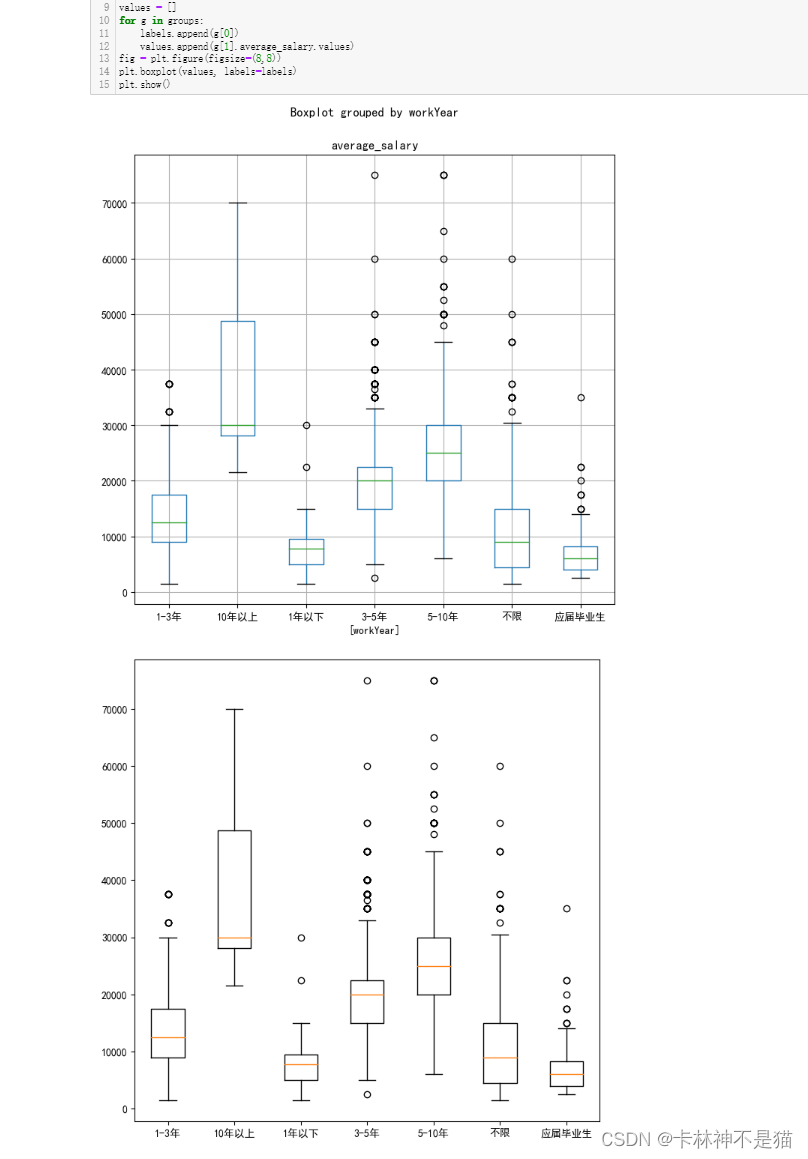
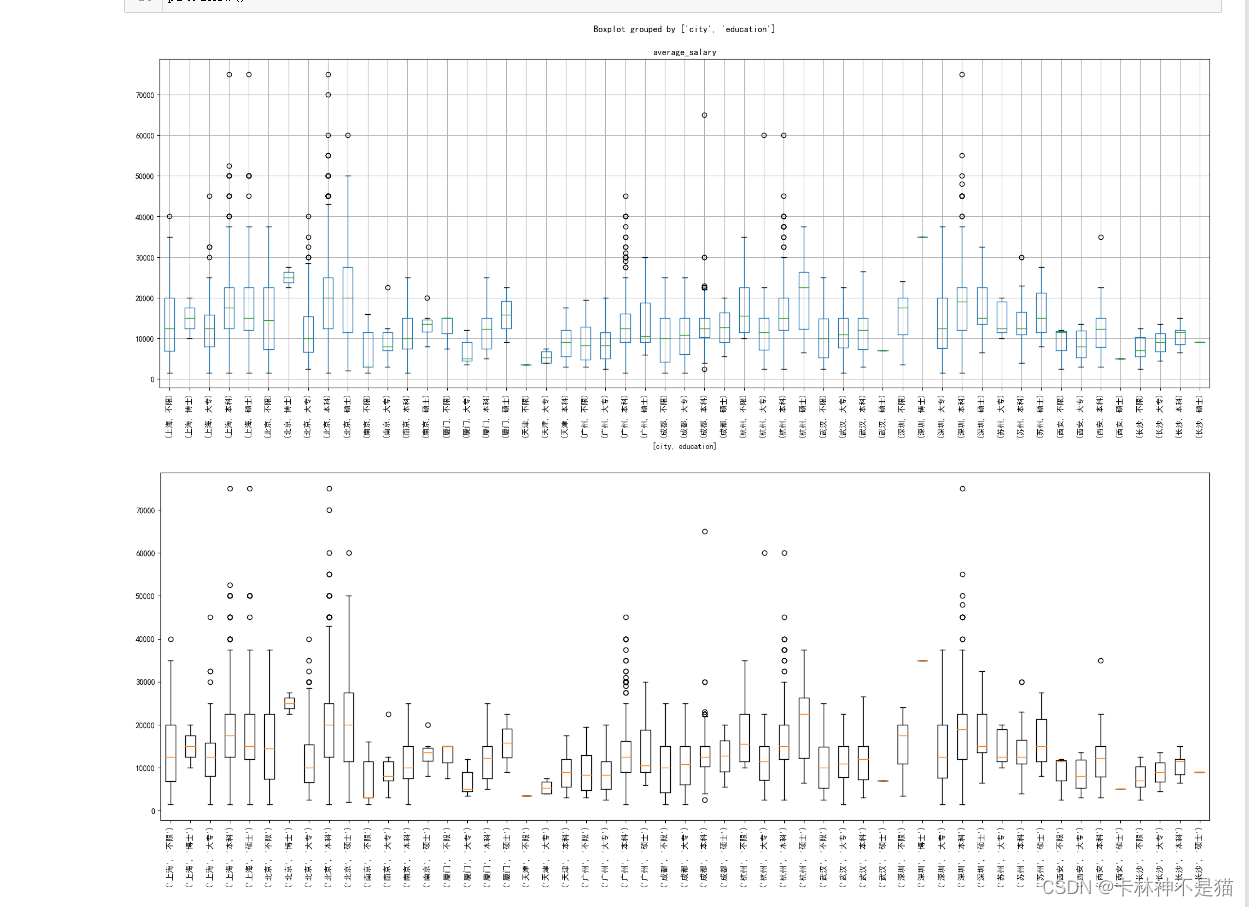
问题9:学历、城市双维度画出平均工资箱线图
# 学历、城市双维度
df_1 = df_[ ['city', 'education', 'average_salary']]
df_1.boxplot(by=['city', 'education'], figsize=(24,8), rot=90)
# or
groups = df_.groupby(['city', 'education'])
labels = []
values = []
for g in groups:
labels.append(g[0])
values.append(g[1].average_salary.values)
fig = plt.figure(figsize=(24,8))
plt.boxplot(values, labels=labels)
plt.xticks(rotation=90)
plt.show()
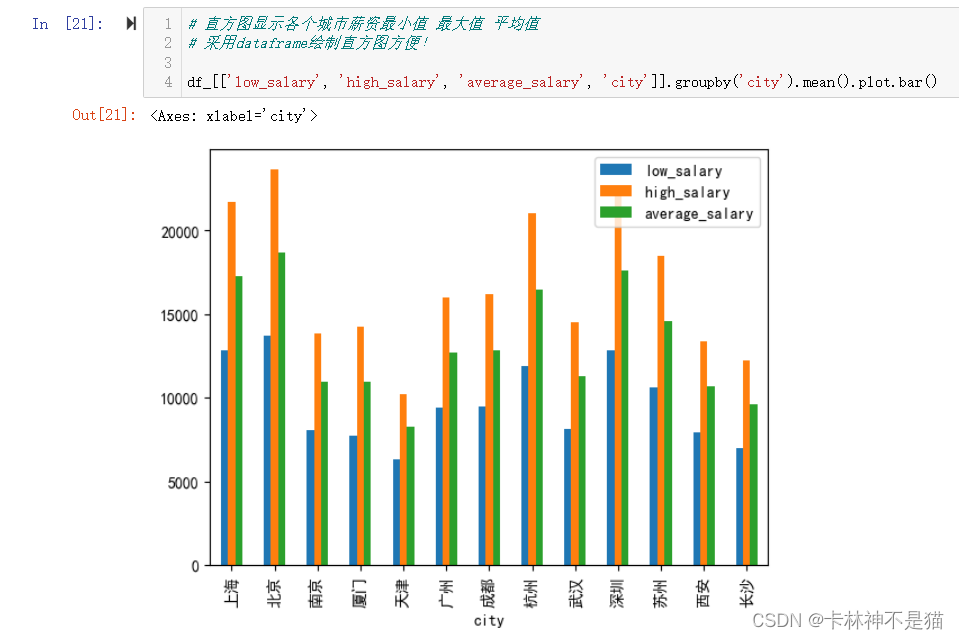
问题10:直方图显示各个城市薪资最小值 最大值 平均值
# 直方图显示各个城市薪资最小值 最大值 平均值
# 采用dataframe绘制直方图方便!
df_[['low_salary', 'high_salary', 'average_salary', 'city']].groupby('city').mean().plot.bar()
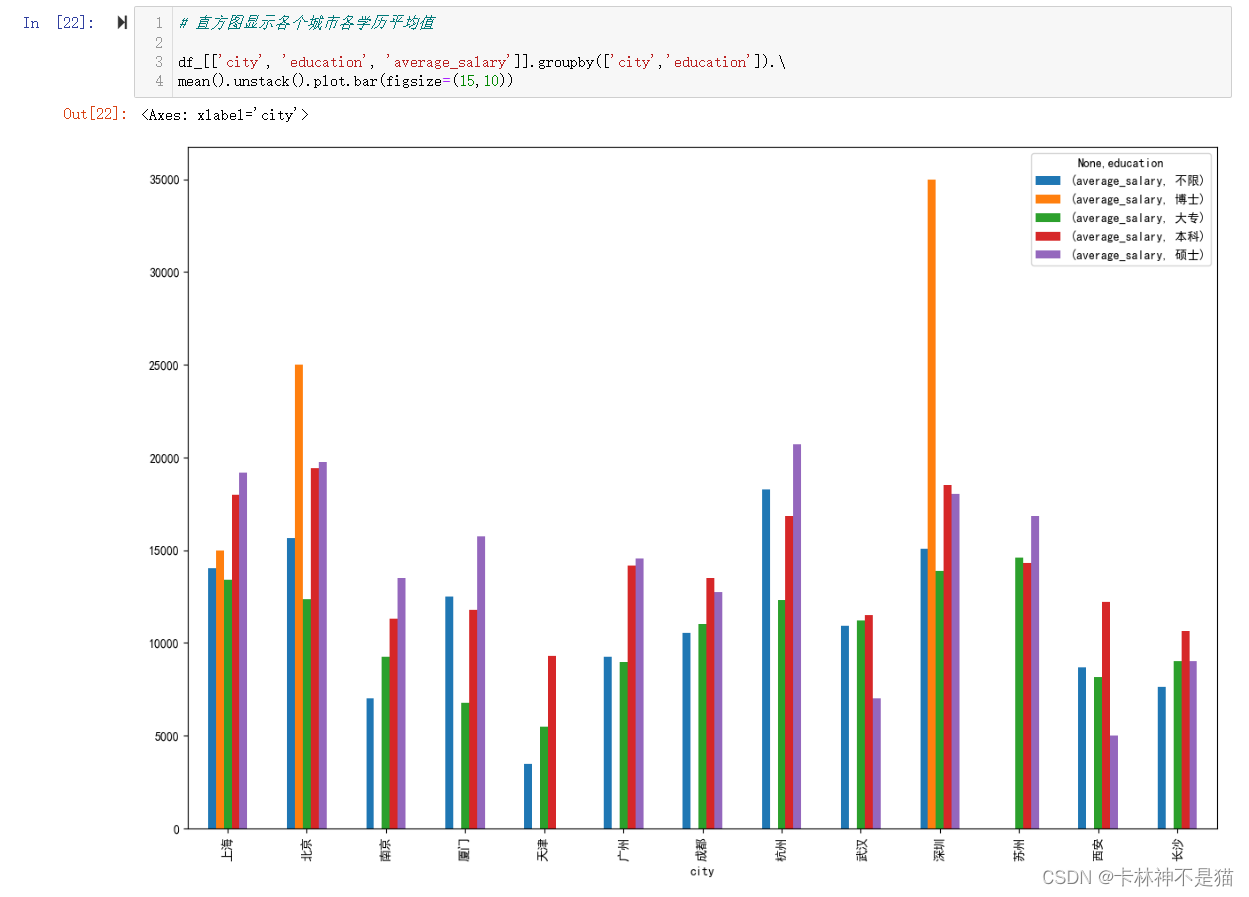
问题11:直方图显示各个城市各学历平均值
# 直方图显示各个城市各学历平均值
df_[['city', 'education', 'average_salary']].groupby(['city','education']).\
mean().unstack().plot.bar(figsize=(15,10))
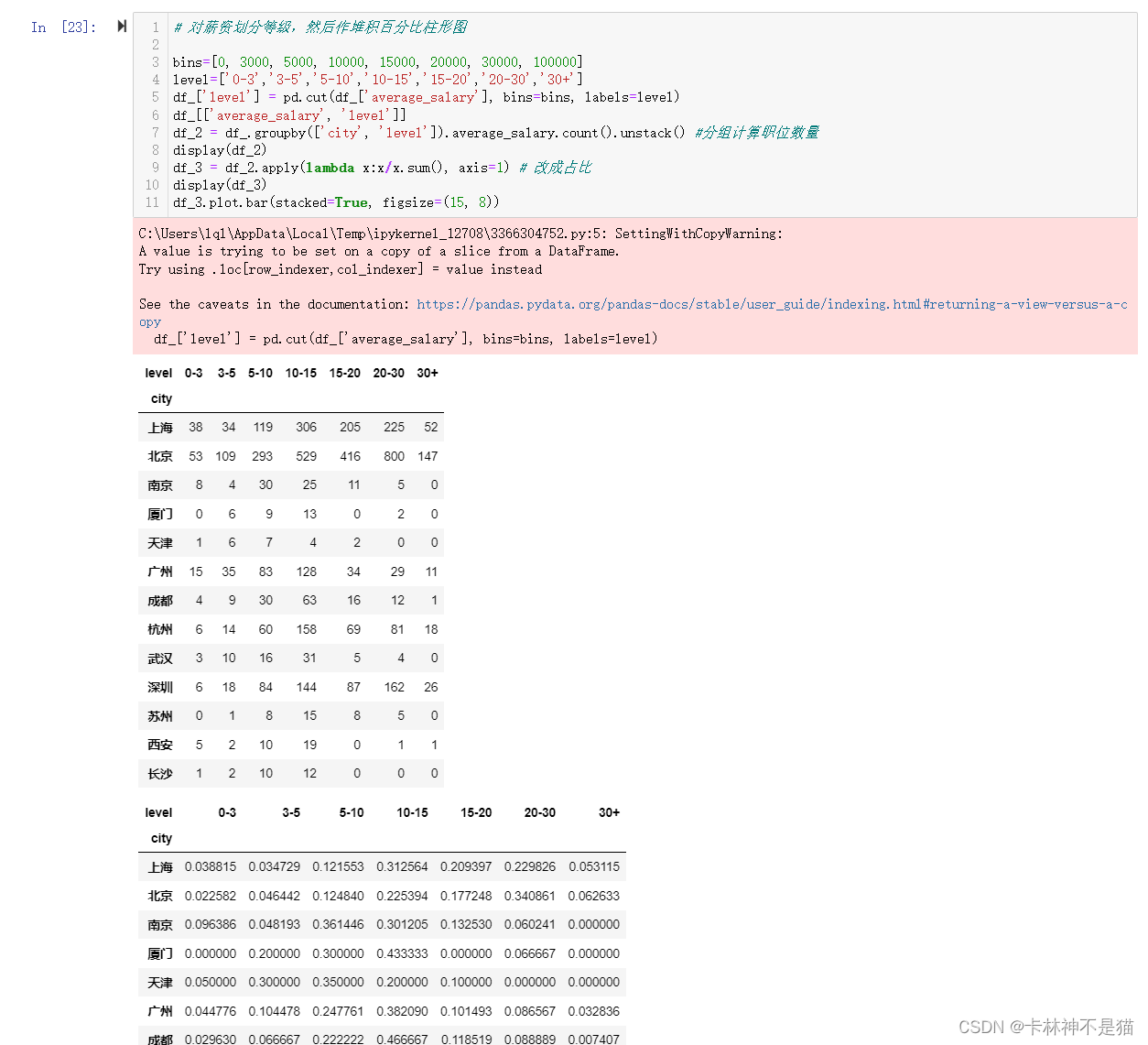
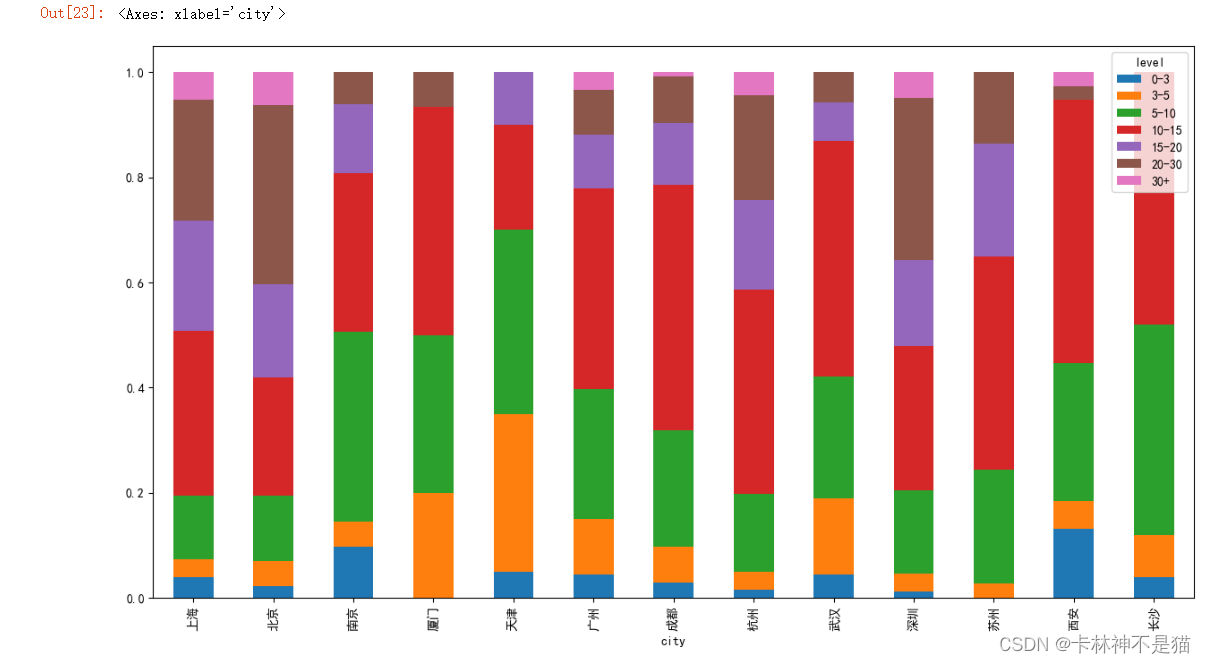
问题12: 对薪资划分等级,然后作堆积百分比柱形图
# 对薪资划分等级,然后作堆积百分比柱形图
bins=[0, 3000, 5000, 10000, 15000, 20000, 30000, 100000]
level=['0-3','3-5','5-10','10-15','15-20','20-30','30+']
df_['level'] = pd.cut(df_['average_salary'], bins=bins, labels=level)
df_[['average_salary', 'level']]
df_2 = df_.groupby(['city', 'level']).average_salary.count().unstack() #分组计算职位数量
display(df_2)
df_3 = df_2.apply(lambda x:x/x.sum(), axis=1) # 改成占比
display(df_3)
df_3.plot.bar(stacked=True, figsize=(15, 8))
问题13:将positionLables职位标签信息作为词云显示
# 将positionLables职位标签信息作为词云显示
from wordcloud import WordCloud
import jieba
from PIL import Image as img
#s = df_['positionLables'].dropna().str[1:-1].replace(" ","")
s = df_['positionLables'].sum()
words = dict()
lt = jieba.lcut(s)
for word in lt:
if len(word)>=2:
words[word] = words.get(word, 0) + 1
#display(words)
wordcloud = WordCloud(font_path='assets//SimHei.ttf',
width=1200, height=800,
background_color='white',
mask=np.array(img.open('assets/myimg.jpg')))
wordcloud.fit_words(words)
plt.figure(figsize=(15,15))
axs = plt.imshow(wordcloud)#正常显示词云
plt.axis('off')#关闭坐标轴
plt.show()