一 原理
如果不采用group gemm的话,采用单流执行,则具体的硬件执行调度如下所示:
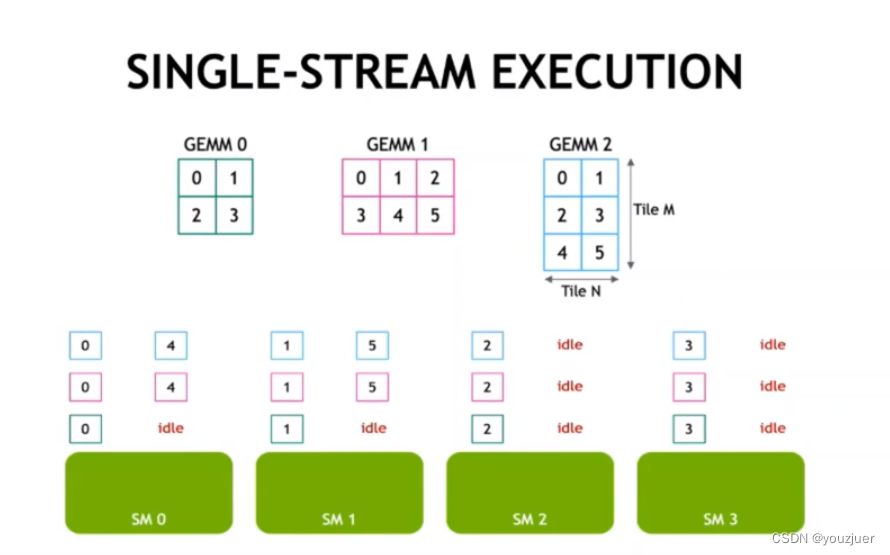
gemm0,gemm1,gemm2同时分配任务给sm做
第一轮:gemm0、gemm1和gemm2的0-4分给4个sm去做,都计算完成
第二轮:gemm0在上一轮已经计算完毕,gemm1和gemm2的45分给sm0,sm1去做,在这一轮可以发现,sm0和sm1针对gemm0的task出现了idel,而sm2和sm3对三个gemm的task都是idle状态
而如果采用group gemm,则可以实现:
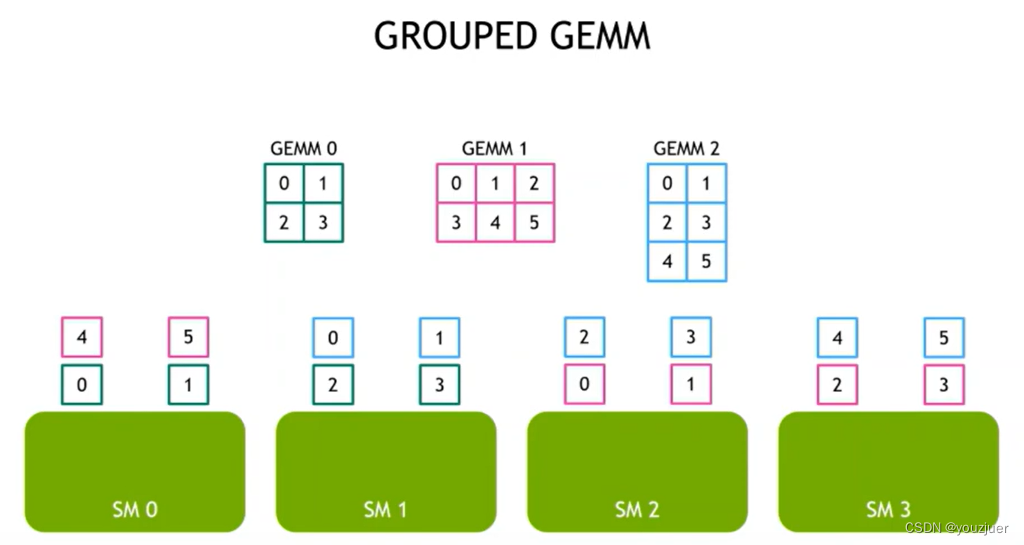
就是保证sm尽量满载,而不处于idle状态
二 源码分析
1 入口函数
def group_gemm_fn(group_A, group_B):
device = torch.device('cuda')
assert len(group_A) == len(group_B)
group_size = len(group_A)
# print("gs",group_si