目录
需求:
思路:
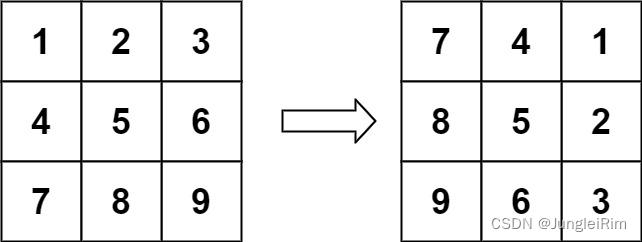
原数据集结构:
代码1(效率低,但不用提前知道需要分多少个类别):
代码2(效率相对高点,但类别数量如果超过设定的11个,则需要改下代码) :
分类后的数据集结构:
需求:
现有的数据集一张图片上往往有多个标注类别,这样训练出的模型可以识别多个类别目标,我们需要只能识别单一类别的模型
思路:
将原有的数据集按照类别分开,重新进行训练
原数据集结构:
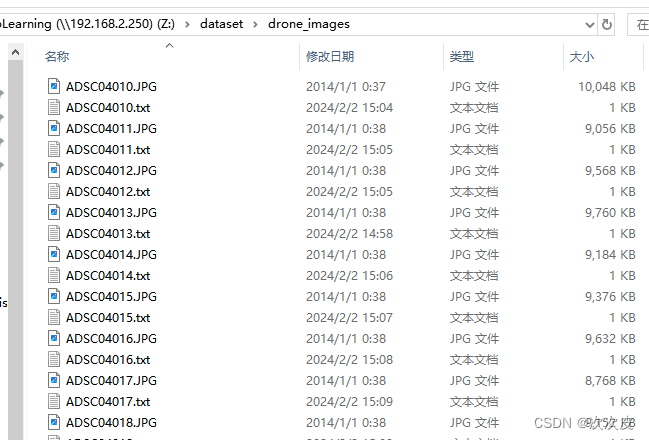
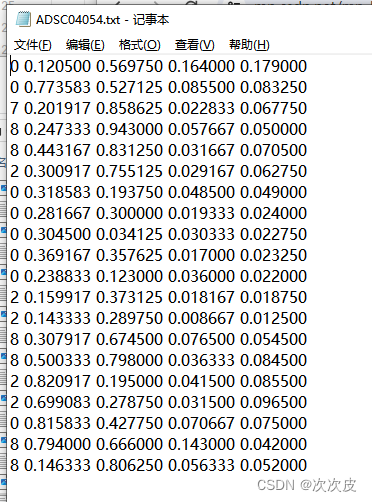
标注信息(yolo格式的五列标注信息:类别、中心点的x、中心点的y、宽、高):
代码1(效率低,但不用提前知道需要分多少个类别):
# -*- coding: utf-8 -*-
"""
Created on Fri Dec 29 14:06:08 2023
@author: DIY-PC
"""
import os
import random
import shutil
# 原数据集目录
root_dir = 'Z:\dataset\drone_images'
# 使用时仅需创建target_path
target_path = 'Z:\dataset\drone_images_classify'
label_path = 'labels'
images_path = 'images'
for file in os.listdir(root_dir):
name, ext = os.path.splitext(file)
if name == 'classes':
break
if file.endswith('.txt'):
# 读取每一行
with open(os.path.join(root_dir, file), "r") as annofile:
for line in annofile:
line = line.strip()
rects = line.split(" ")
target_labels_path = os.path.join(target_path, rects[0], label_path)
target_images_path = os.path.join(target_path, rects[0], images_path)
# 文件不存在,创建新文件并写入内容
if not os.path.exists(target_labels_path):
os.makedirs(target_labels_path, exist_ok=True)
os.makedirs(target_images_path, exist_ok=True)
if not os.path.exists(os.path.join(target_labels_path, file)):
shutil.copy(os.path.join(root_dir, name + '.JPG'), target_images_path)
with open(os.path.join(target_labels_path, file), 'a') as classify_annofile:
classify_annofile.write(line + "\n") # 写入内容并换行
代码2(效率相对高点,但类别数量如果超过设定的11个,则需要改下代码) :
# -*- coding: utf-8 -*-
"""
Created on Fri Dec 29 14:06:08 2023
@author: DIY-PC
"""
import os
import shutil
# 原数据集目录
root_dir = 'Z:\dataset\drone_images'
# 使用时仅需创建target_path
target_path = 'Z:\dataset\drone_images_classify'
label_path = 'labels'
images_path = 'images'
anno_0_list = []
anno_1_list = []
anno_2_list = []
anno_3_list = []
anno_4_list = []
anno_5_list = []
anno_6_list = []
anno_7_list = []
anno_8_list = []
anno_9_list = []
anno_10_list = []
anno_list_dict = {
'0': anno_0_list,
'1': anno_1_list,
'2': anno_2_list,
'3': anno_3_list,
'4': anno_4_list,
'5': anno_5_list,
'6': anno_6_list,
'7': anno_7_list,
'8': anno_8_list,
'9': anno_9_list,
'10': anno_10_list
}
for file in os.listdir(root_dir):
name, ext = os.path.splitext(file)
if name == 'classes':
break
if file.endswith('.txt'):
# 读取每一行
with open(os.path.join(root_dir, file), "r") as annofile:
class_list = []
for line in annofile:
line = line.strip()
rects = line.split(" ")
anno_list_dict[rects[0]].append(line)
if rects[0] not in class_list:
class_list.append(rects[0])
print(file + "文件读取完毕")
# 遍历类别
for cla in class_list:
# 如果不存在则创建文件夹,写入文件
target_labels_path = os.path.join(target_path, cla, label_path)
target_images_path = os.path.join(target_path, cla, images_path)
# 文件不存在,创建新文件并写入内容
if not os.path.exists(target_labels_path):
os.makedirs(target_labels_path, exist_ok=True)
os.makedirs(target_images_path, exist_ok=True)
with open(os.path.join(target_labels_path, file), 'a') as classify_annofile:
for item in anno_list_dict[cla]:
classify_annofile.write(item + "\n") # 写入内容并换行
if not os.path.exists(os.path.join(target_images_path, name + '.JPG')):
shutil.copy(os.path.join(root_dir, name + '.JPG'), target_images_path)
print(file + "文件写入完毕")
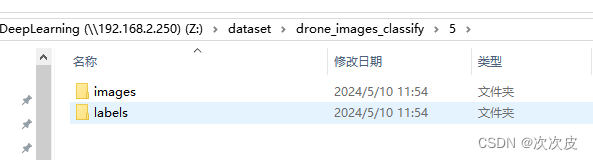
分类后的数据集结构:


![[AIGC] 压缩列表了解吗?快速列表 quicklist 了解吗?](https://img-blog.csdnimg.cn/img_convert/7c70dfe31cd6cefffd2b2ffcd0dd652d.png)