论文阅读
论文:https://arxiv.org/pdf/1403.6652
参考:【论文逐句精读】DeepWalk,随机游走实现图向量嵌入,自然语言处理与图的首次融合_随机游走图嵌入-CSDN博客
abstract
DeepWalk是干什么的:在一个网络中学习顶点的潜在表示。这些潜在表示编码了容易被统计学模型的在联系向量空间中的社会关系。
DeepWalk怎么做到的:使用从截断的随机游走中获得的局部信息,通过将行走视为句子来学习潜在表征。
统计学模型->指ML
introduction
网络表示的稀疏性既是优点也是缺点。稀疏性使得设计高效的离散算法成为可能,但也使得推广统计学习变得更加困难。因此ML就需要做到可以处理稀疏性。
在这篇文章中,通过对一系列短随机游走(short random walks)进行建模来学习图顶点的社会表示(social representations)。社会表征是捕获邻居相似性和社区成员的顶点的潜在特征。这些潜在表征将社会关系编码在一个具有相对较少维度的连续向量空间中。

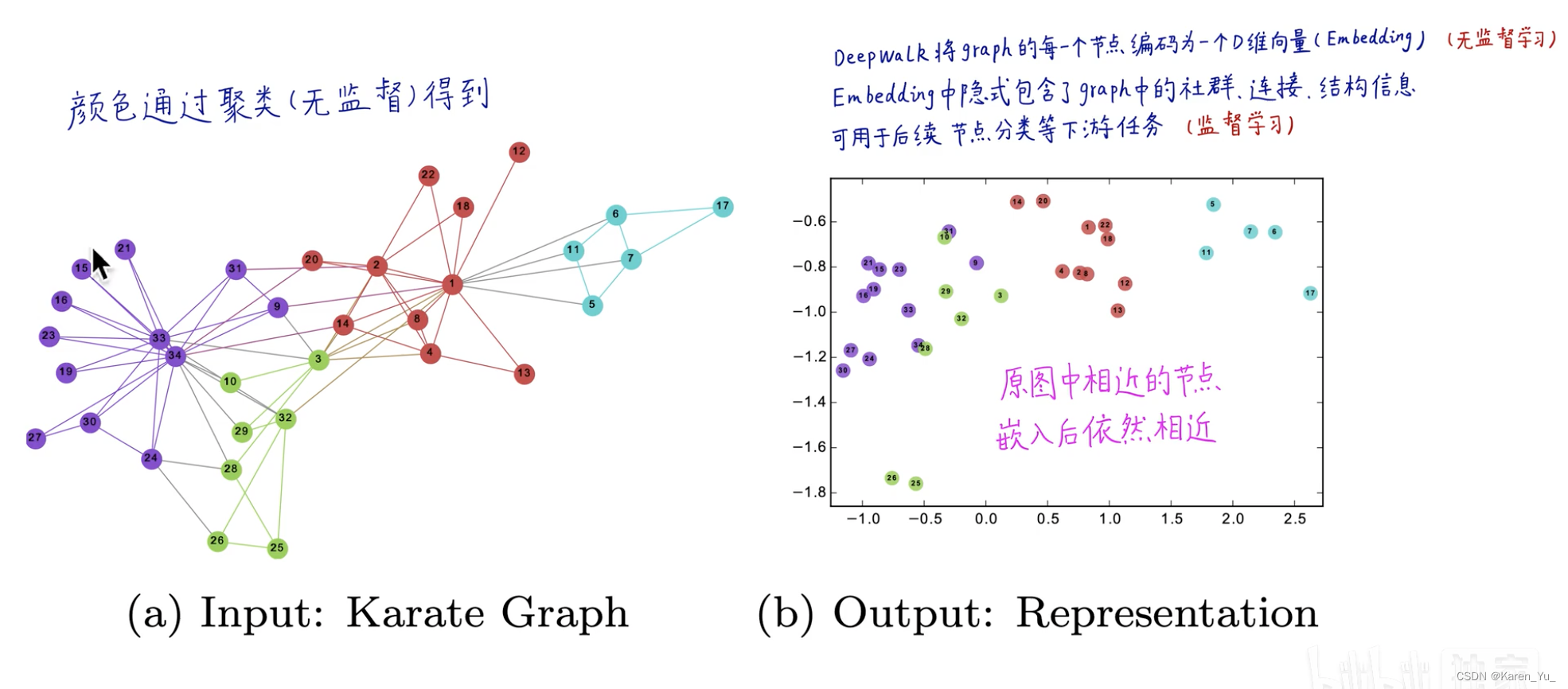
DeepWalk将一个图作为输入,并产生一个潜在的表示作为输出。空手道网络如图1a所示。图1b显示了我们的方法具有2个潜在维度的输出。
DeepWalk诞生背景和想要解决的问题
在DeepWalk诞生之前,往往是通过人工干预,创造的特征工程来进行图机器学习,在这种情况下面临两个问题:
(1)特征工程的好坏决定模型的好坏。并且特征工程并没有统一的标准,对于不同的数据集所需要做的特征工程是不一样的,因此图数据挖掘的模型的稳定性并不好。
(2)人工特征工程无非关注节点信息、边信息、图信息,且不论是否全部关注到,假设可以做到所有信息全部兼顾(实际上不可能)这样近乎完美的特征工程,但是节点的多模态属性信息无法得到关注。这意味着,即使是完美的特征工程,仍然只能兼顾到有限信息,数据挖掘的深度被严重限制。DeepWalk想要通过这么一种算法,把图中每一个节点编码成一个D维向量(embedding过程),这是一个无监督学习。同时,embedding的信息包含了图中节点、连接、图结构等所有信息,用于下游监督学习任务。
为什么可以借鉴NLP里面的方法?
图数据是一种具有拓扑结构的序列数据。既然是序列数据,那么就可以用序列数据的处理方式。这里所谓的序列数据是指,图网络总是具有一定的指向性和关联性,例如从磨子桥到火车南站,就可以乘坐3号线在省体育馆转1号线,再到火车南站,也可以在四川大学西门坐8号线转。这都是具备指向关系。那么,我们把“磨子桥-省体育馆-倪家桥-桐梓林-火车南站”就看作是一个序列。当然,这个序列是不唯一的,我们可以“四川大学望江校区-倪家桥-桐梓林-火车南站”。也可以再绕大一圈,坐7号线。总之,在不限制最短路径的前提下,我们从一个点出发到另外一个点,有无数种可能性,这些可能性构成的指向网络,等价于一个NLP中的序列,并且在这个图序列中,相邻节点同样具备文本信息类似的相关性。Embedding编码应该具有什么样的特性?
在前文已经有过类似的一句话,embedding的信息包含了图中节点、连接、图结构等所有信息,用于下游监督学习任务。 其实这个更是一个思想,具体而言,在NLP领域中,我们希望对文本信息,甚至单词的编码,除了保留他单词的信息,还应该尽可能保留他在原文中的位置信息,语法信息,语境信息,上下文信息等。因为只有这个基向量足够强大,用这个向量训练的模型解码出来才能足够强大。例如这么两句话:
Sentence1:今天天气很好,我去打篮球,结果不小心把新买的水果14摔坏了,但是没关系,我买了保险,我可以免费修手机。
Sentence2:我今天去修手机。
很显然,第一句话包含的信息更多,我们能够更加清晰的理解到这个事件的来龙去脉。对计算机而言也是一样,只有输入的信息足够完整,才能有更好的输出可靠性。
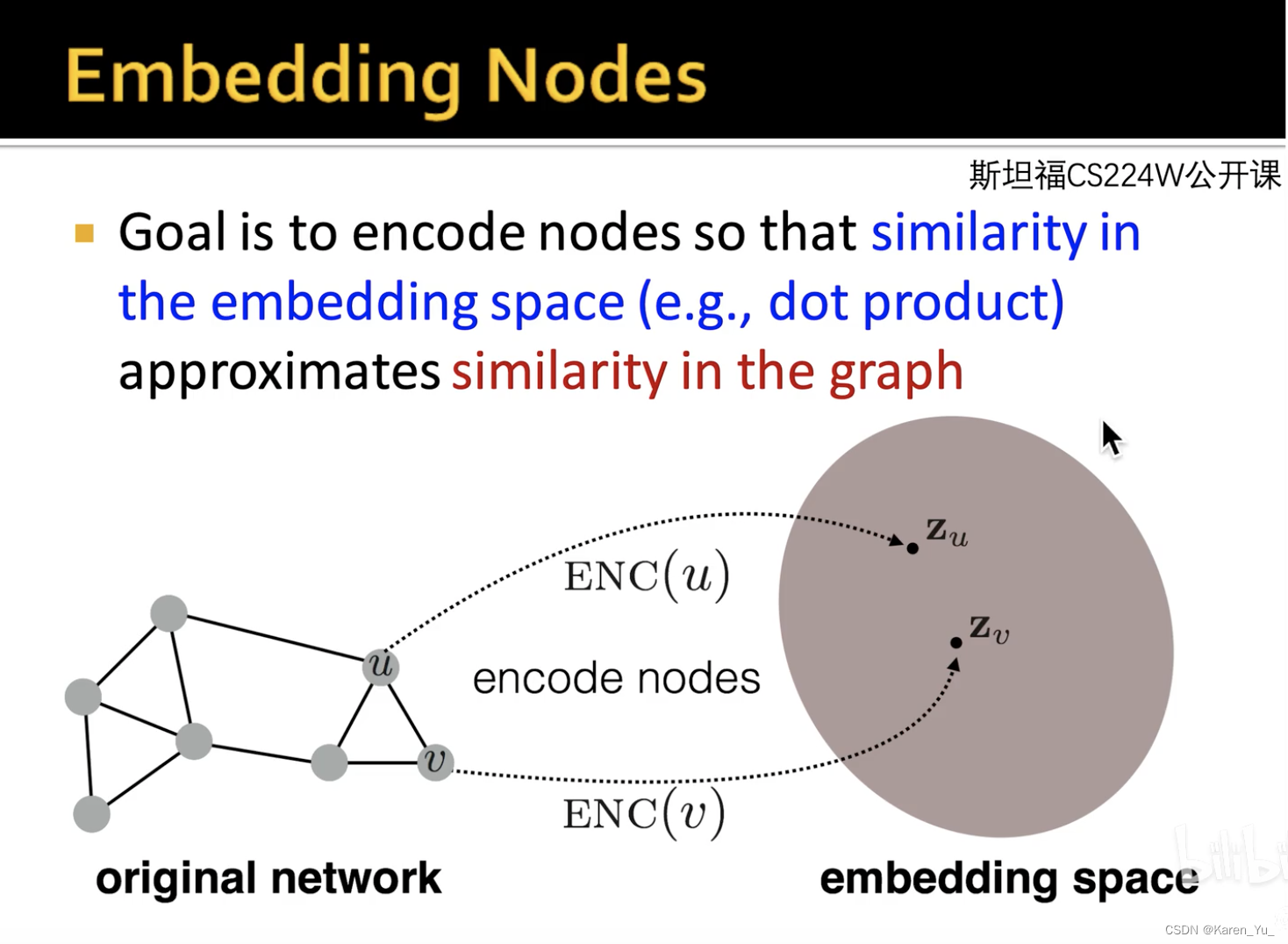
放到图网络里,假设有两个节点u和v,他们在图空间的信息应该和在向量空间的信息保持一致,这就是embedding最核心的特征(假设u和v在图空间是邻接点,那么在向量空间他们也应该是距离相近的;如果八竿子打不着关系,那么在向量空间应该也是看不出太多联系)。把映射的向量放在二维空间或者更高维空间进行下游任务的设计,会比图本身更加直观,把图的问题转化成了不需要特征工程的传统机器学习或者深度学习问题。什么是随机游走(Random Walk)
首先选择一个点,然后随机选择它的邻接节点,移动一步之后,再次选择移动后所在节点的邻接节点进行移动,重复这个过程。记录经过的节点,就构成了一个随机游走序列。
Question:为什么要随机游走?
Answer:一个网络图实际上可能是非常庞大的,通过无穷次采样的随机游走(实际上不可能无穷次),就可以”管中窥豹,可见一斑“。从无数个局部信息捕捉到整张图的信息。
Random Walk的假设和Word2Vec的假设保持一致,即当前节点应该是和周围节点存在联系。所以可以构造一个Word2Vec的skip-gram问题。
原文链接:【论文逐句精读】DeepWalk,随机游走实现图向量嵌入,自然语言处理与图的首次融合_随机游走图嵌入-CSDN博客
关于这里对为什么可以应用NLP的内容,个人理解就是,在NLP中,一句话说出来的顺序,或者说出来的方式,在一定程度上不影响句意,比如文言文里有倒装、通假、省略、互文等等,但是表达出来的意思是一样的,就像图中从A节点到达D节点,我们可以走不通的路径。
关于embedding编码这部分,简单回忆一下,关于语法信息,之前也提到过,比如位置编码:
11.6. Self-Attention and Positional Encoding — Dive into Deep Learning 1.0.3 documentation
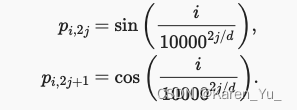
语法信息的话,BERT里面提过LeeMeng - 進擊的 BERT:NLP 界的巨人之力與遷移學習拆解不同的token,可以把单词拆成单词本身+ing或者+s这样(我猜作者是这个意思)
之后关于图的描述里面,确实在后续GNN的模型中都指出要让相邻的节点更相似(似乎PageRank也有关于相似度的应用)
关于随机游走的部分,在后续的GNN中也有提到,这似乎是用到的一种采样方法,当然在PageRank中也有提及(是一种迭代计算PageRank值的方法,但是因为其需要模拟的游走太多了,没有被使用。
在引用的这篇文章中,也指出totally random walk并不是一个好方法,因为节点之间的权重是不一样的,但是DeepWalk就完全均匀随机游走了(还没看后续怎么改,但是想想应该也是类似于加一个系数,让能一定概率跳到某些点)
由于计算量的限制,这个随机游走的长度并不是无限,所以对于一个巨大的网络,虽然管中窥豹可见一斑,但这也注定了当前位置和距离非常远的位置是完全无法构成任何联系信息的,这和Word2Vec的局限性是一致的,在图神经网络GCN中,解除了距离限制,好像Transformer解除了RNN的距离限制一样,极大释放了模型的潜力,后续也会讲到。
原文链接:【论文逐句精读】DeepWalk,随机游走实现图向量嵌入,自然语言处理与图的首次融合_随机游走图嵌入-CSDN博客
problem definition
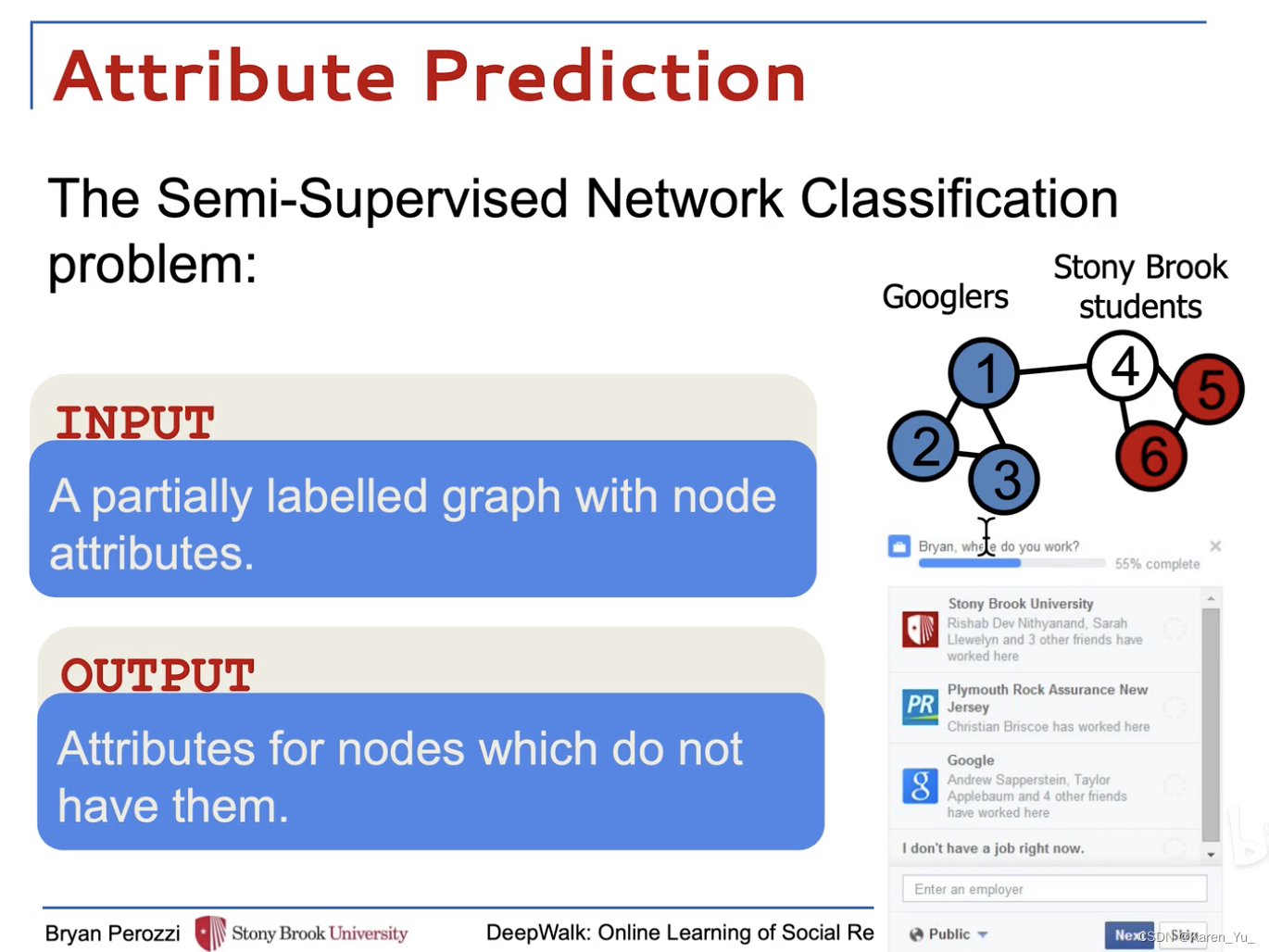
我们考虑将社交网络的成员划分为一个或多个类别的问题。
令,其中
表示网络中的成员,
表示边,
(笛卡尔积?元素表示节点对?
)。给定一个部分标记的社交网络
,其中属性
,这里的
表示的是每个属性向量的特征空间(即多少个特征),
,
表示标签的集合。(
是特征)
在传统的ML classification中,我们的目标是学习一个假设可以将元素
映射到标签集
。
在文中,可以利用关于G结构中嵌入的示例的依赖性的重要信息来实现优越的性能。在文献中,这被称为关系分类(或集体分类问题[37])。传统的关系分类方法将问题作为无向马尔可夫网络中的一个推理,然后使用迭代近似推理算法来计算给定网络结构的标签后向分布。
目标:学习,这里
是少量的潜在维度,这些低维表示是分布的,也就是说,每一个社会现象都是由维度的一个子集来表达的,而每一个维度都对空间所表达的社会概念的一个子集有所贡献。利用这些结构特征,扩大属性空间以帮助分类决策。

learning social representations
一些背景介绍,可移步【论文逐句精读】DeepWalk,随机游走实现图向量嵌入,自然语言处理与图的首次融合_随机游走图嵌入-CSDN博客
method
与任何语言建模算法一样,唯一需要的输出是一个语料库和一个词汇表V。DeepWalk将一组短截断的随机行走视为自己的语料库,并将图顶点作为自己的词汇表()。尽管在训练前知道
和频率分布是有好处的,但是对于hierarchical softmax方法而言是非必要的。
frequency distribution
频率分布:一种统计数据的排列方式,展示了变量值出现的频率。
Frequency Distribution: values and their frequency (how often each value occurs).
关于频率分布:
2.1: Organizing Data - Frequency Distributions - Statistics LibreTexts
Frequency Distribution | Tables, Types & Examples
Frequency Distributions – Math and Statistics Guides from UB’s Math & Statistics Center

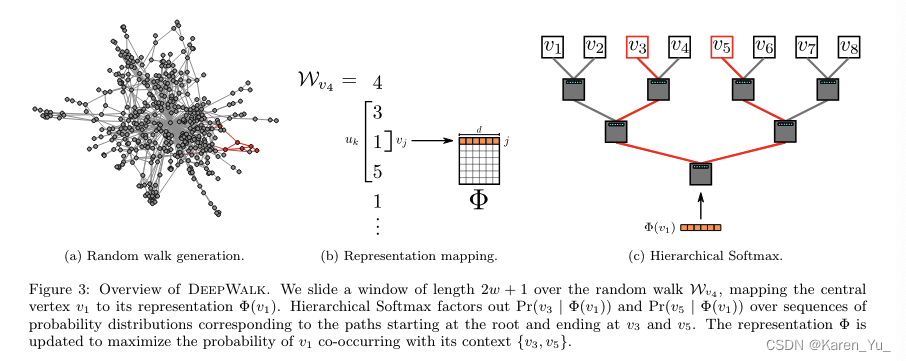
Algorithm: Deep Walk
算法包含了两个主要步骤,第一个是一个随机游走生成器(random walk generator),第二个是更新过程(update procedure)。
其中,随机游走生成器拿到图并均匀采样一个随机顶点
作为随机游走的根
。从最后访问的顶点的邻居中均匀采样,直到达到最大长度(t)。虽然我们将实验中随机游走的长度设置为固定值(这里更容易被理解成是随机游走的步数),但随机游走的长度不受限制(这里应该指的是路径的真实长度,因为可能跳回去)。这些行走可以有重新启动(即瞬间返回到根节点的概率),但是初步结果并没有显示使用重新启动的任何优势。

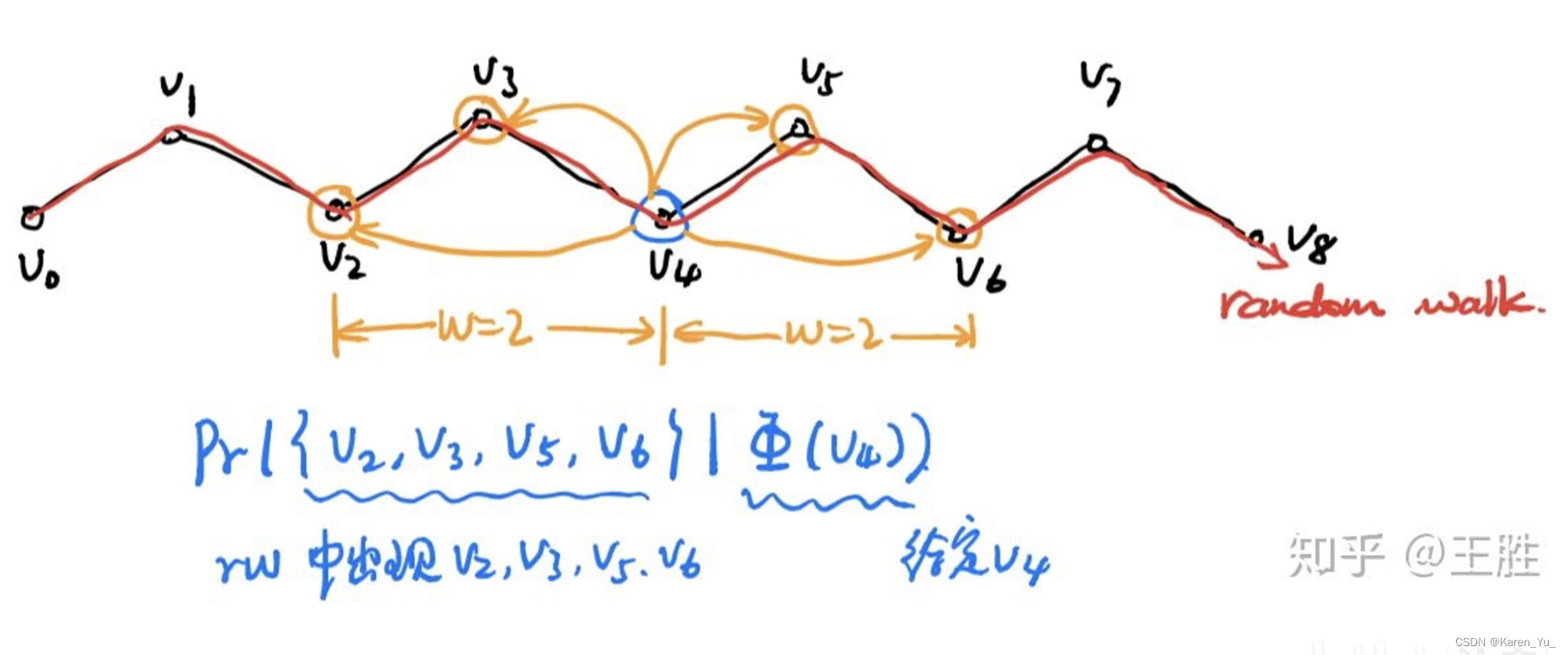
上图3-9行展示的是方法的核心。最外层的循环指定了在每个顶点开始随机游走的次数。将每次迭代视为对数据进行“传递”,并在此传递期间对每个节点进行一次采样。在每次“”传递开始的时候,我们生成一个随机的顺序来遍历顶点。这不是严格要求的,但众所周知,它可以加快随机梯度下降的收敛速度。
在内部循环中,我们遍历图的所有顶点。对于每个顶点,我们生成一个随机游动
,然后使用它来更新(第7行)->采用SkipGram算法⬇️。

SkipGram
SkipGram是一种语言模型,它最大限度地提高句子中窗口内出现的单词之间的共存概率
算法2在随机游走中遍历窗口(第1-2行)内出现的所有可能的搭配。对于每个顶点,我们将每个顶点
映射到其当前表示向量
(见图⬇️)。给定
的表示,我们希望最大化它在游走(第3行)中的邻居的概率。可以使用几种分类器来学习这种后验分布。
这里的指的是对应的embedding
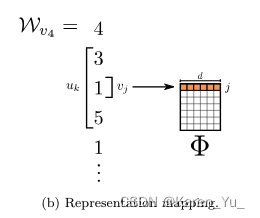
(这里没太读懂“maximize the probability of its neighbors in the walk”,按照前面的意思是SkipGram能够提高cooccurrence probability,但是为什么要提高呢?这里断一下去看看SkipGram)
参考:理解 Word2Vec 之 Skip-Gram 模型 - 知乎
Skip-gram Word2Vec Explained | Papers With Code
Skip-Gram Model in NLP - Scaler Topics
Word2Vec Tutorial - The Skip-Gram Model · Chris McCormick

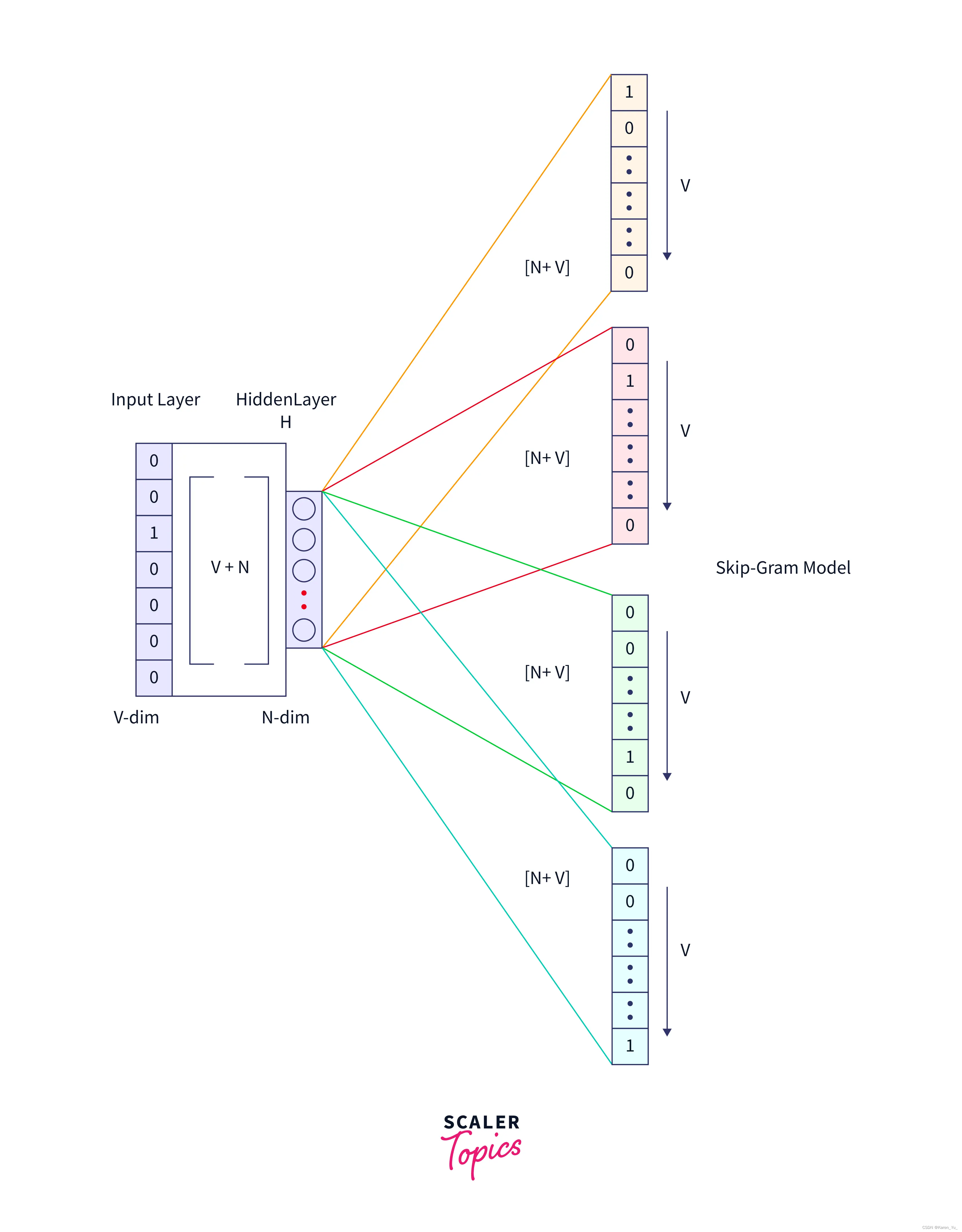
(目前的理解是,对于选择的节点j我希望节点j能够出现在节点i的随机游走的路径中)
Hierarchical Softmax
对于给定,计算
并不可行。计算partition function(归一化因子)是昂贵的。如果我们将顶点分配给二叉树的叶子,那么预测问题就变成了最大化树中特定路径的概率(参见图⬇️)。
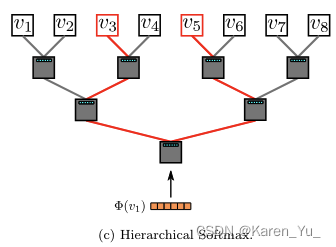
partition function-分区函数:在统计力学中的一种函数,用于表示系统的状态数或相关函数的生成函数。
如果到达顶点的路径被一系列数节点定义(
),(
),那么:
可以被分给其父节点的二分类器建模。
Optimization
随机梯度下降(SGD)
在Overview里,作者提出DeepWalk也需要和自然语言处理算法一样,构建自己的语料库和词库。这里的语料库就是随机游走生成的序列,词库就是每个节点本身。从这一点上看,其实图的Skip-Gram会更简单一点,因为词会涉及到分词,切词,例如”小明天天吃饭“,是小明还是明天,如果词库做不好,切割做不好,会非常影响模型性能;如果是英文单词,好一点的做法会切分#-ed -#ing这样的分词,但是节点都是一个一个单独的,不存在这样的问题。
原文链接:
【论文逐句精读】DeepWalk,随机游走实现图向量嵌入,自然语言处理与图的首次融合-CSDN博客


示例代码,请参考:
论文|DeepWalk的算法原理、代码实现和应用说明 - 知乎
其他:
【论文笔记】DeepWalk - 知乎
【Graph Embedding】DeepWalk:算法原理,实现和应用 - 知乎
DeepWalk【图神经网络论文精读】_哔哩哔哩_bilibili
DeepWalk【图神经网络论文精读】_哔哩哔哩_bilibili
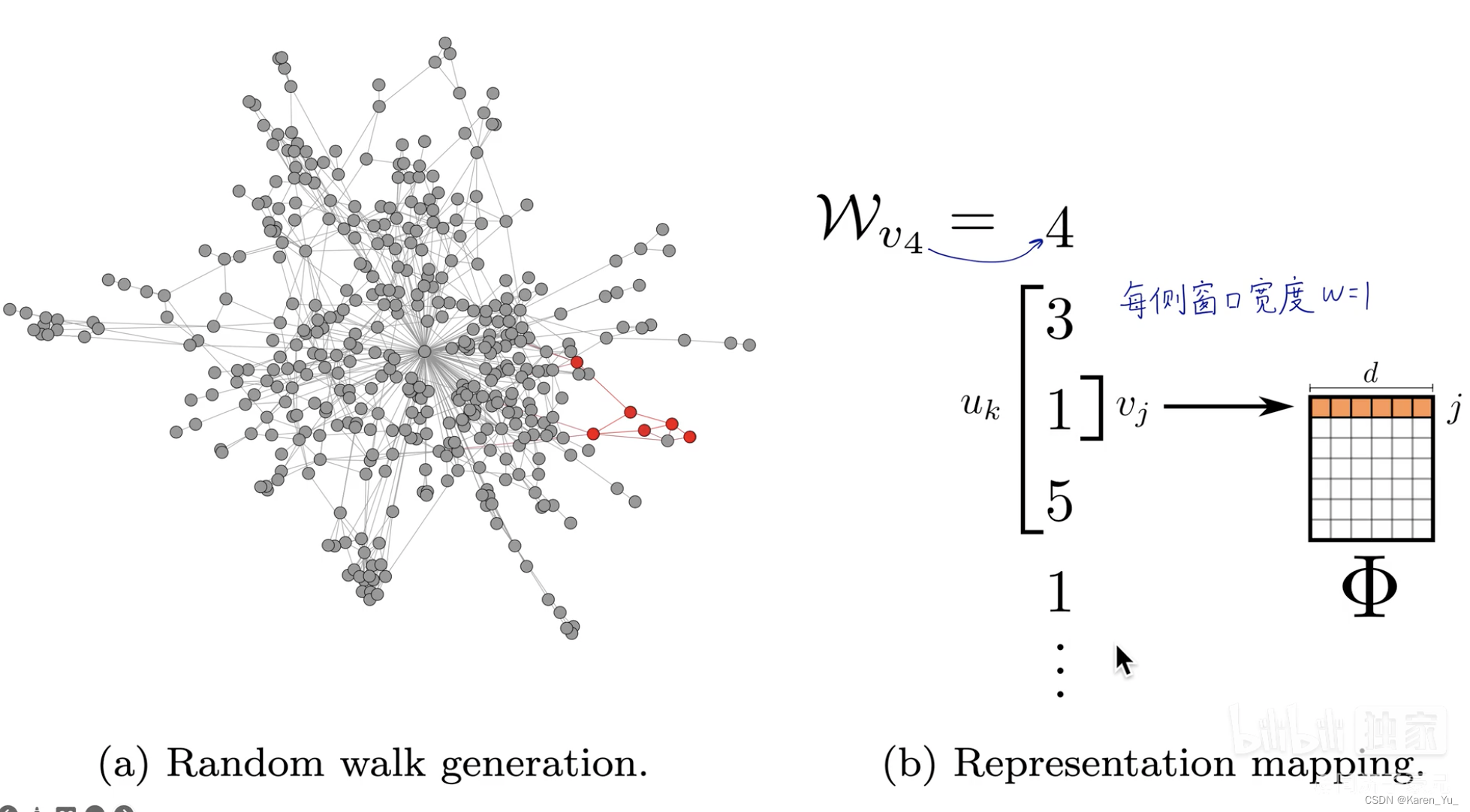
通过在图里随机游走,生成一连串随机游走的序列,每一个序列都类似一句话,序列中的每一个节点就类似word2vec中的单词,然后套用word2vec方法。word2vec中假设一句话中相邻的单词是相关的,deepwalk假设在一个随机游走中,相邻的节点是相关的。
比如图中,用,即1,预测3和5,通过这种,用中心节点去预测周围节点,就可以捕获相邻的关联信息,最后迭代优化
,
反映了相似关系
通过随机游走可以采样出来一个序列。
输入中心节点预测周围临近节点,那么我们就可以套用word2vec,把每一个节点编码成一个向量。
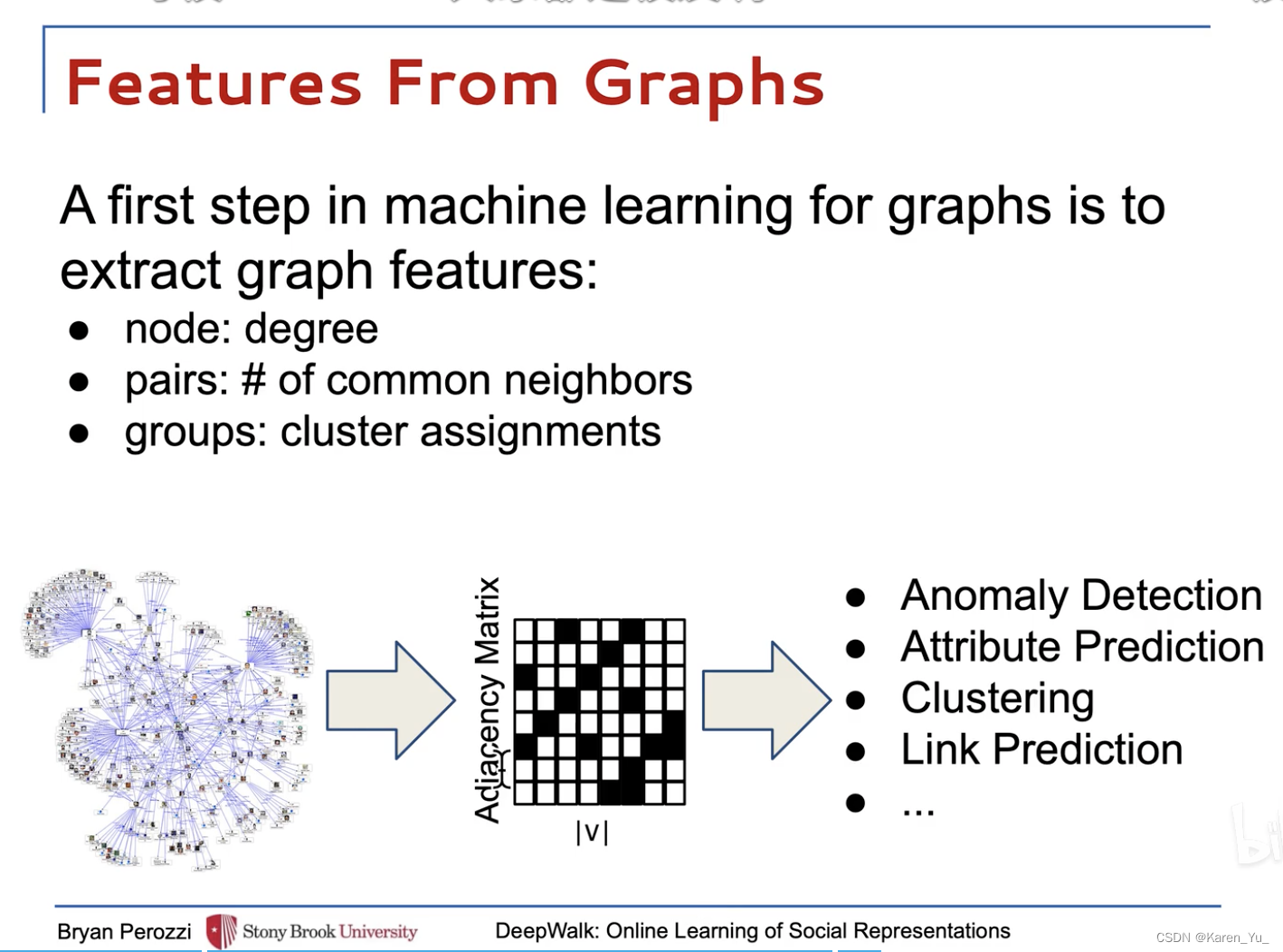
⬆️手动构造特征,⬇️学习特征
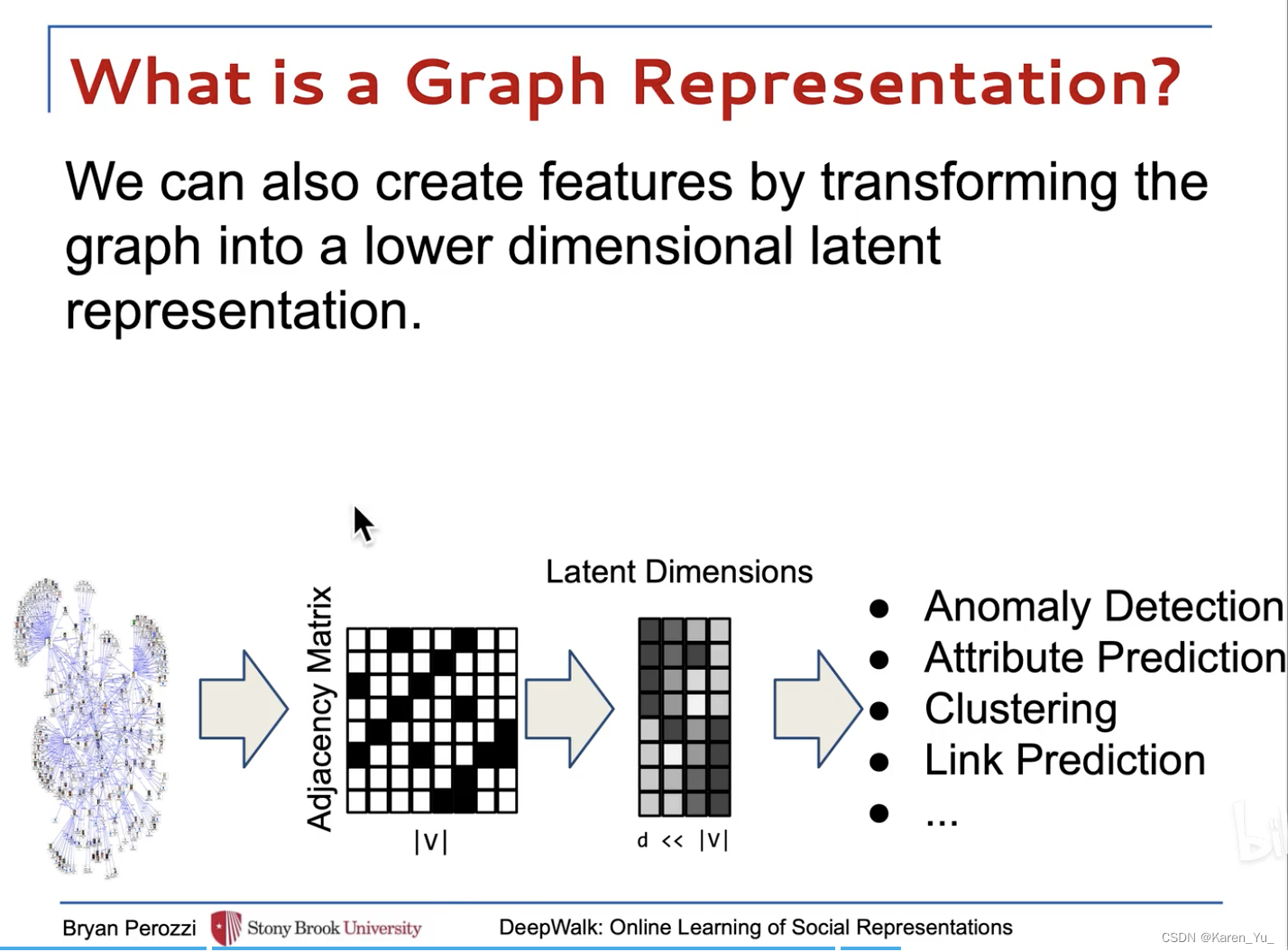
把词汇表维度降到d维
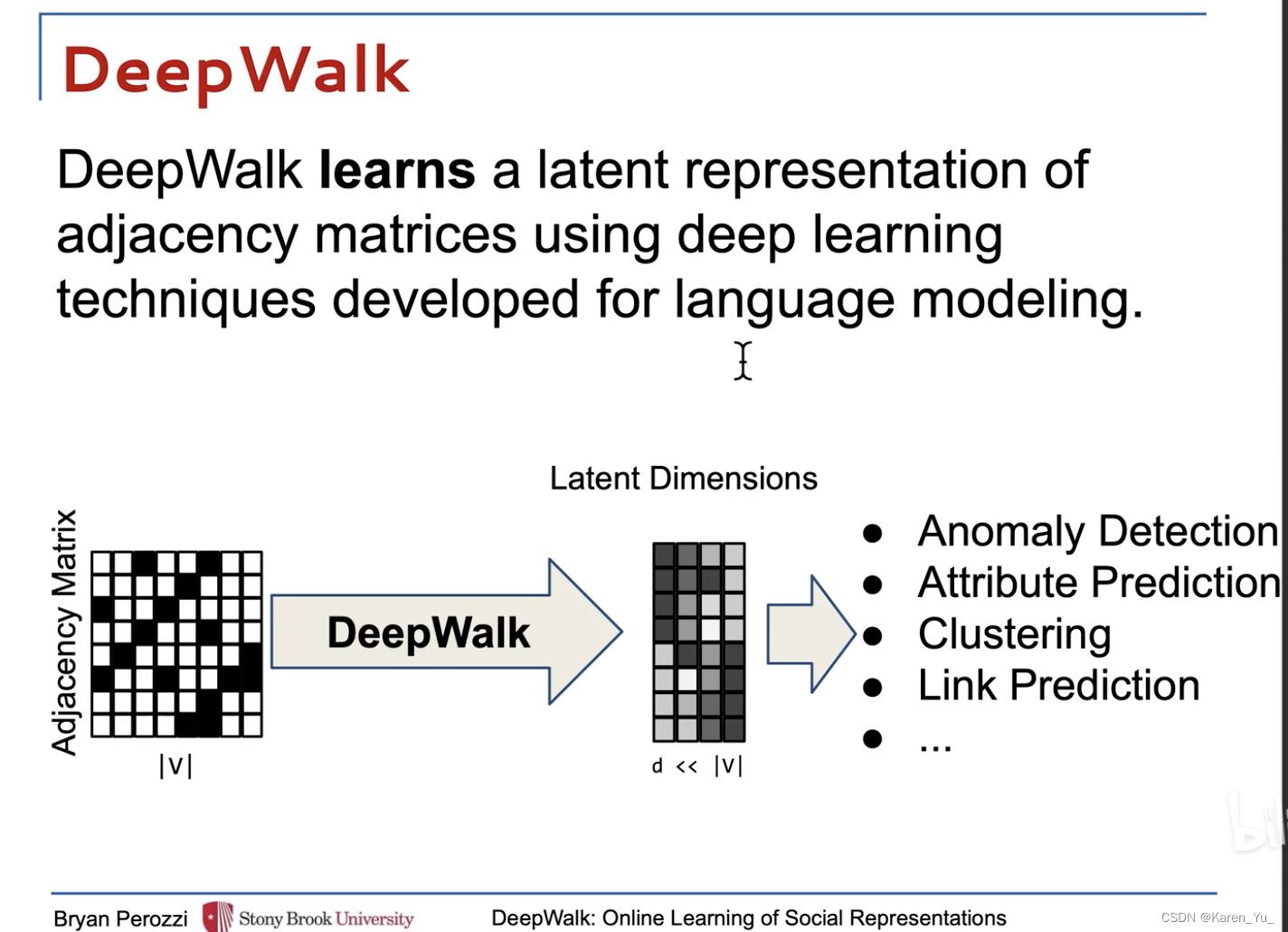
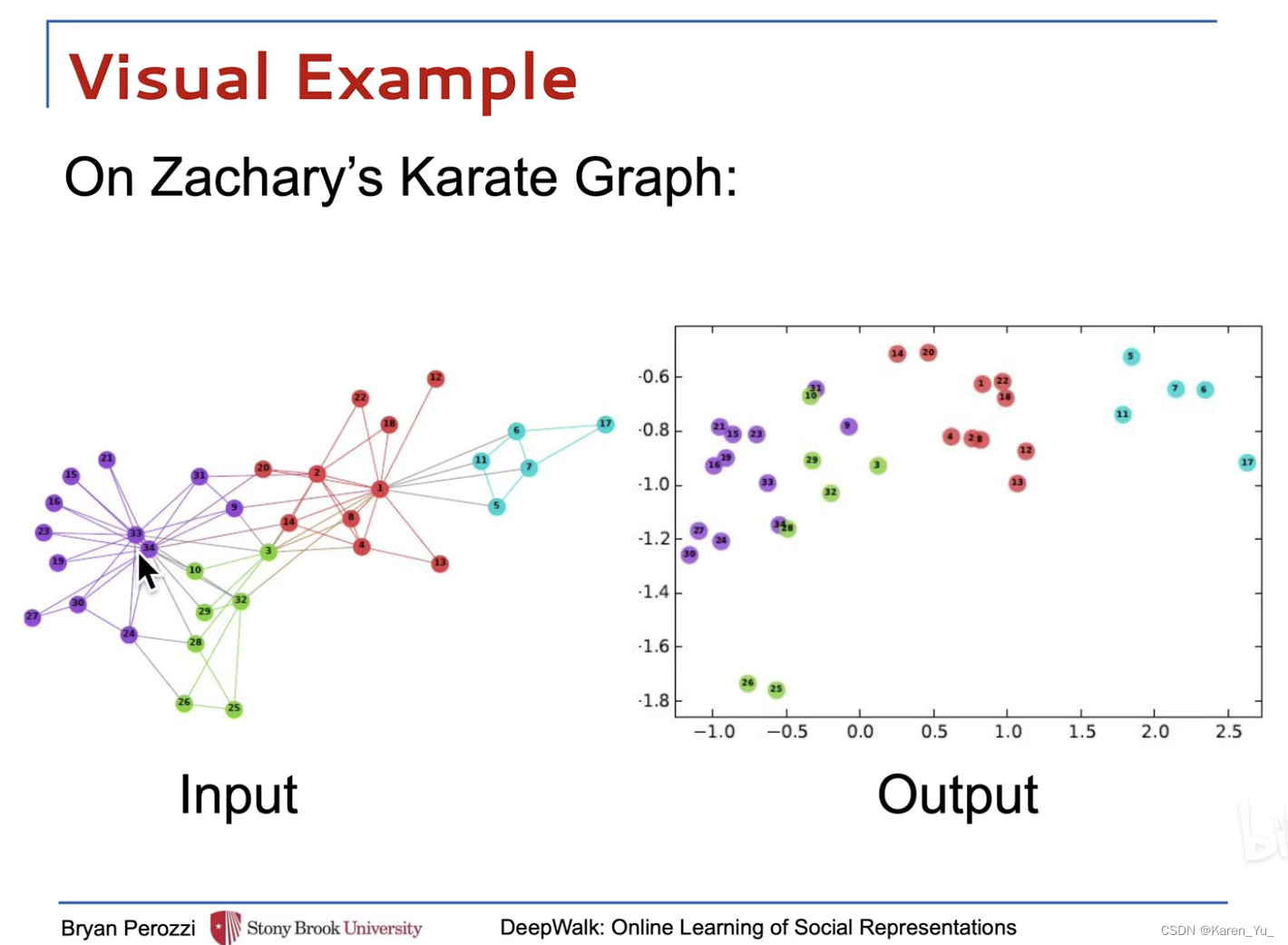
⬅️原图,➡️deepwalk编码后到图
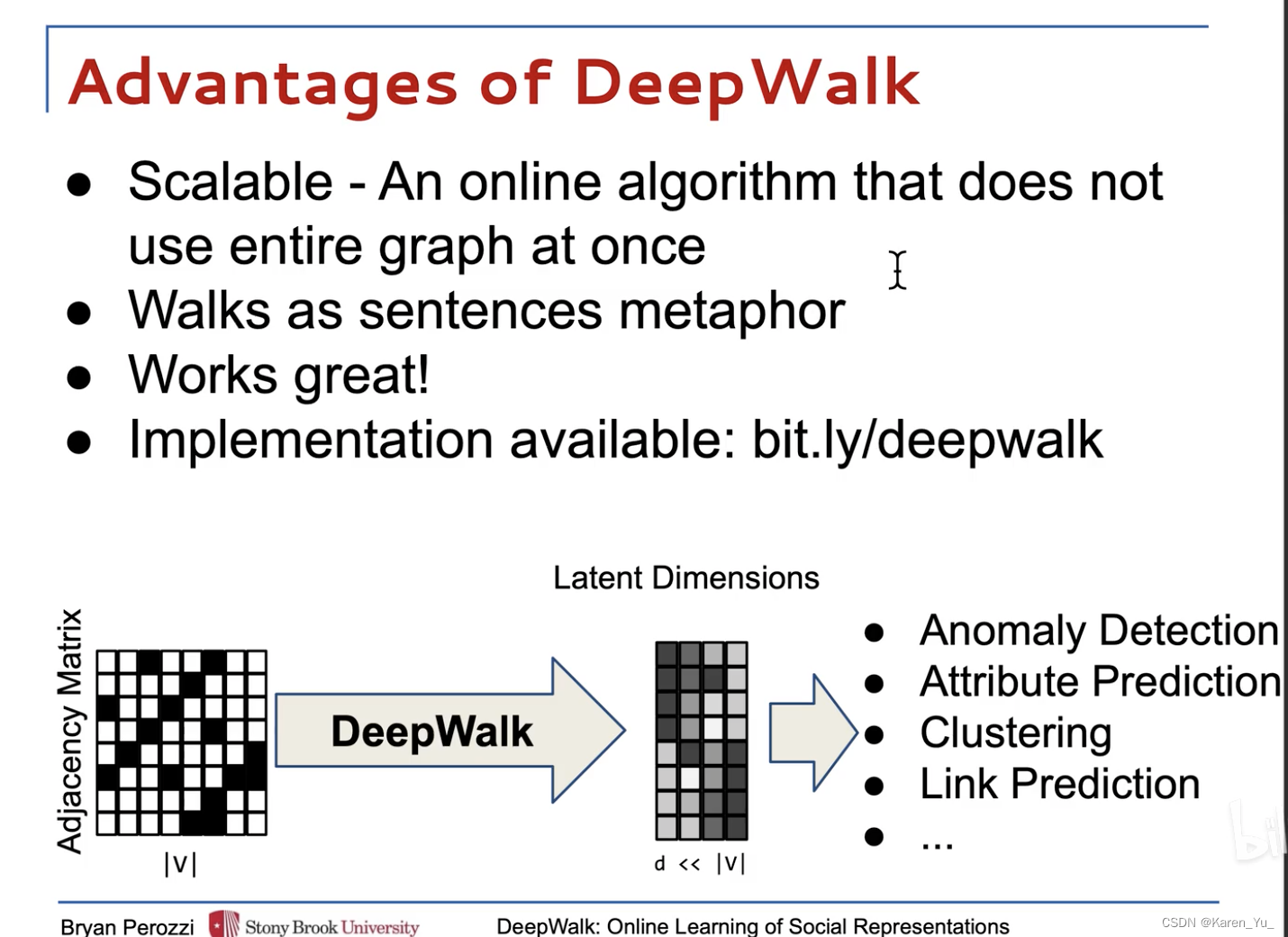
优点:
- 可扩展。来了一个新数据之后,即来即学,即建立一个新连接之后不需要从头训练,只需要把新增的节点和关联,让随机游走采样下来,然后在线训练
- 可以直接套用NLP中的语言模型,把随机游走当作是句子,把节点当作是单词
- 效果不错,尤其在稀疏标记的图分类任务上

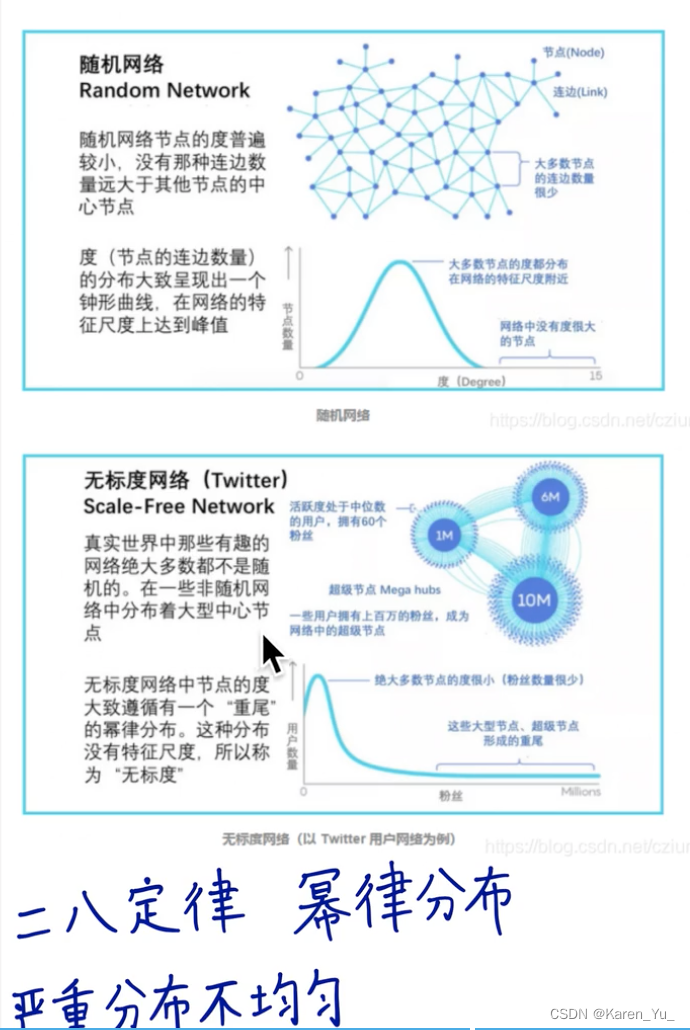
在NLP中有一个现象,称为幂律分布/二八定律/长尾分布
有一些词出现的特别频繁(如:the, and, of, etc.),但是这些词比较少,而大部分的词出现的次数少(但是这些词数量多)
带入到图中,比如网络,很少部分的网站很多人访问,而大部分的网站都没人访问
关于各种分布,可以参考:从幂律分布到特征数据概率分布——12个常用概率分布_数据和特征怎么估计概率分布-CSDN博客
->服从同一分布->可以类比->可以用相同的方法

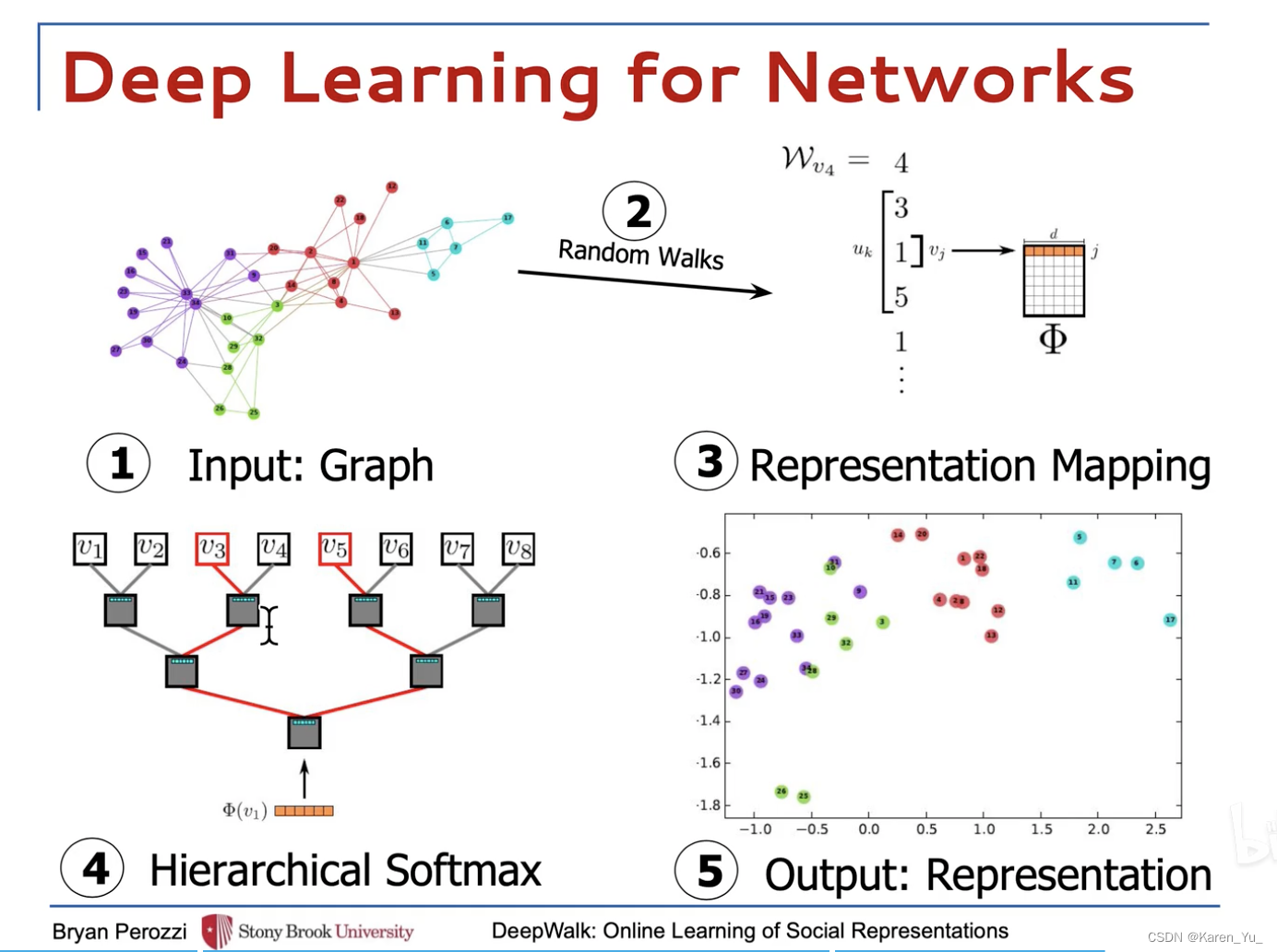
5个步骤:
- 先输入一个图
- 采样随机游走序列
- 用随机游走序列训练word2vec
- 为了解决分类个数过多的问题,加一个分层softmax(or 霍夫曼编码树)
- 得到每一个节点的图嵌入向量表示

首先来看random walk。每一个节点作为起始节点,产生个随机游走序列,每一个随机游走序列的最大长度是
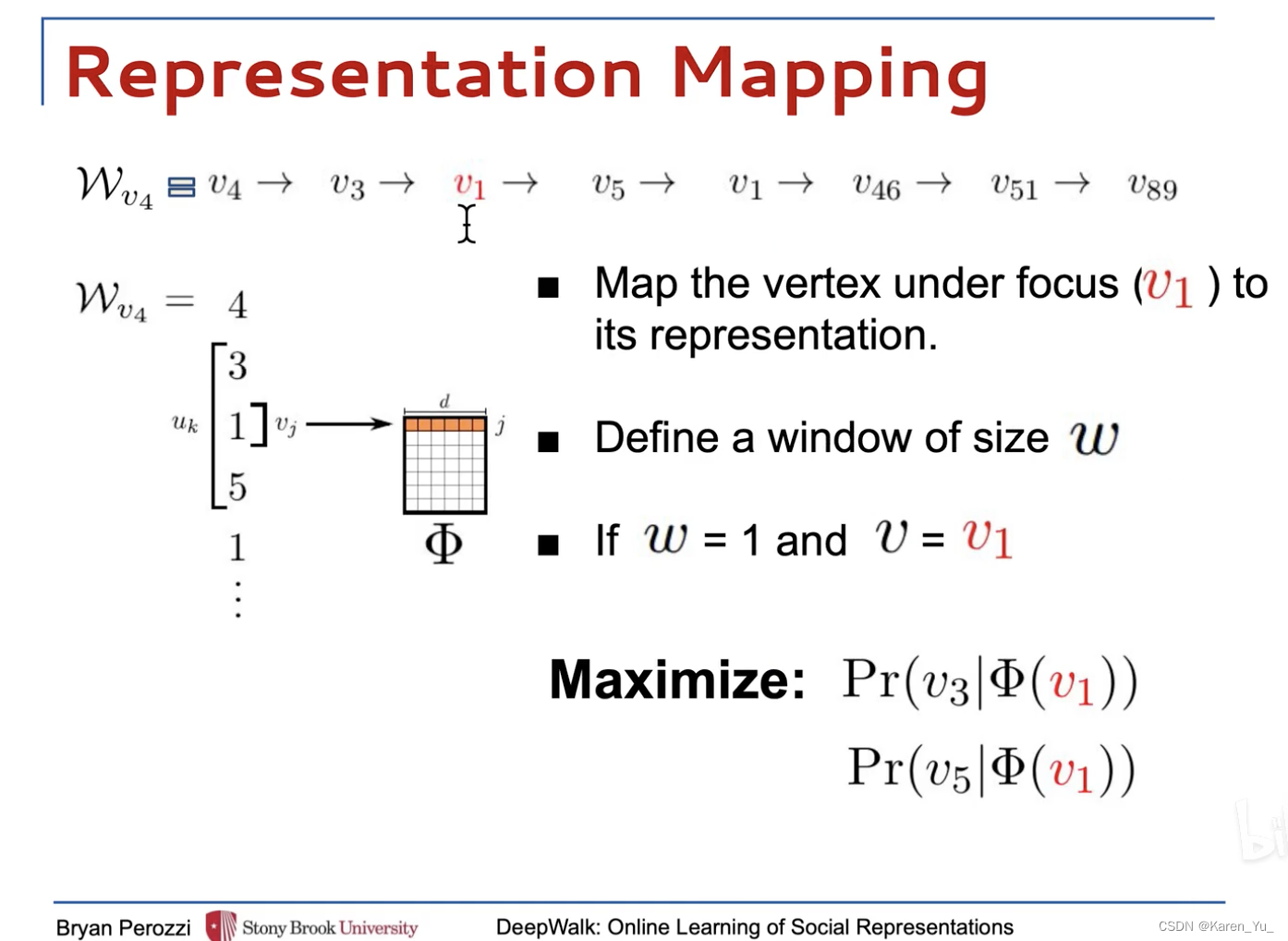
使用得到的随机游走序列去构造skip-gram,输入中心词的编码表示,预测周围词(输入1,预测3 5)
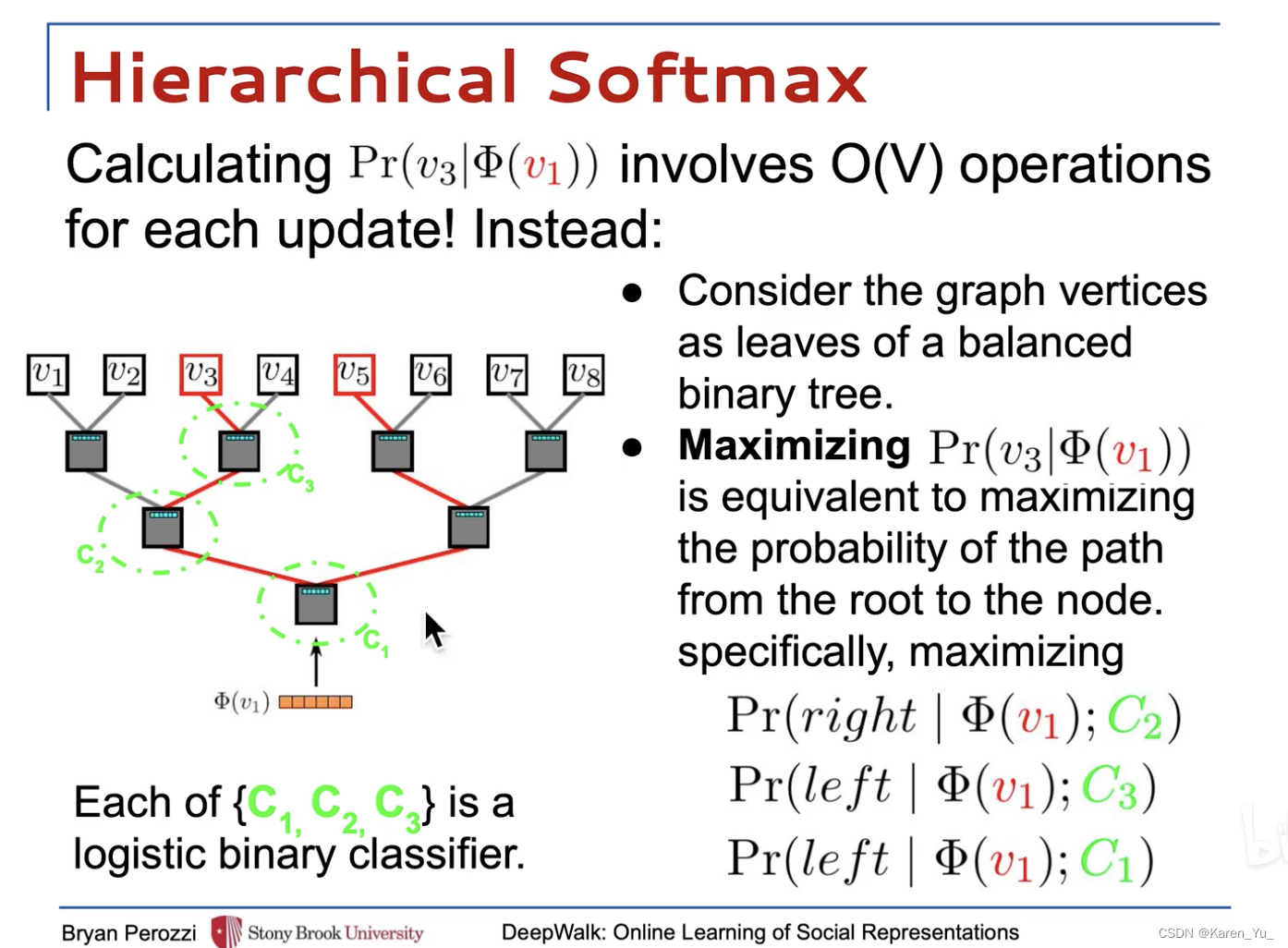
分层的softmax->比如一个八分类问题,分成三个分类任务,这里的每一个分类任务都是一个二分类的逻辑回归。
->复杂度从O(n)降低到O(log n)

有两套要学的参数:节点的表示 & 逻辑回归的权重
节点表示需要优化的是skip-gram的损失函数,逻辑回归是优化最大似然估计的交叉熵损失函数
同时优化
->最后得到每一个节点的向量
优缺点:

DeepWalk论文逐句精读_哔哩哔哩_bilibili
online learning指的是在线学习算法,是一个即来即训的算法,如果图中有新的节点出现or有新的连接出现(比如一个社交网络中有一个新的注册用户/一个新的好友关系的添加,不需要将全图重新训练一遍,而只要把新增的节点/关系构建新的随机游走序列,迭代地更新到原有的模型中。
隐式向量(编码后的结果)就编码了节点的邻域信息和社群信息。->一个连续、低维、稠密的空间。
在图数据结构中,每个节点之间是有关联的,这就违反了传统机器学习的独立同分布假设(比如iris数据集,每一条数据都是一朵独立的鸢尾花,但是都属于鸢尾花),但是图的话,每个节点之间是有关联的,所以不能用传统的机器学习方法(就像红楼梦四大家族一样,互相掣肘)。
deepwalk是无监督学习,与节点的label、特征均无关,只与节点在网络中的社群属性、连接结构相关。
后续的算法可以加上节点本身的信息(但是deepwalk本身不包含)
(弹幕:deepwalk不用,但下游任务用)

word2vec不需要标签,输入中心词,周围的词就是标签