前言
今天开始学习 Oracle 数据库,这是实习公司要求的,虽然还没开始实习,但是事先熟练到岗之后就不需要再花费时间学习了。有了 MySQL 的基础,学习 Oracle 应该问题不大,不过 MySQL 一些进阶的内容依然需要再精进一下。
下面的内容不会写太多没用的内容,只把自己在学习 Oracle 过程中遇到的和 MySQL 不一样的地方做一下对比,也没有时间去打那么多字了,敲 SQL 为主。
1、Oracle 数据库
1.1、Oracle 介绍
功能强大,大公司用的比较多,收费!收费当然好了。
我们说的 Oracle 可以指 Oracle 数据库管理系统。 Oracle 数据库管理系统是管理数据库访问的计算机软件,它由 Oracle 数据库(database) 和 Oracle 实例(instance)组成。
这里实例这个概念是MySQL没有的,实例由多个后台进程和一个共享内存池组成,共享的内存可以被所有进程访问。Oracle 用它们来管理数据库访问。用户如果要存取数据库里的数据,必须通过 Oracle 实例才能实现,不能直接读取磁盘上的文件。实际上,Oracle 实例就是平常所说的数据库服务。在任何时刻,一个实例只能与一个数据库关联,访问一个数据库,而同一个数据库可以由多个实例访问。(就像 Kafka 消费者组一样,一个分区只能被一个消费者消费,但是一个消费者可以消费多个分区)
尽管我们说数据库管理系统可以存在多个数据库(比如 MySQL),但事实上,Oracle 数据库不同于别的数据库,它在 windows 操作系统上只有一个数据库,相当于 Oracle 就只有一个大的数据库。
1.2、Oracle 存储结构
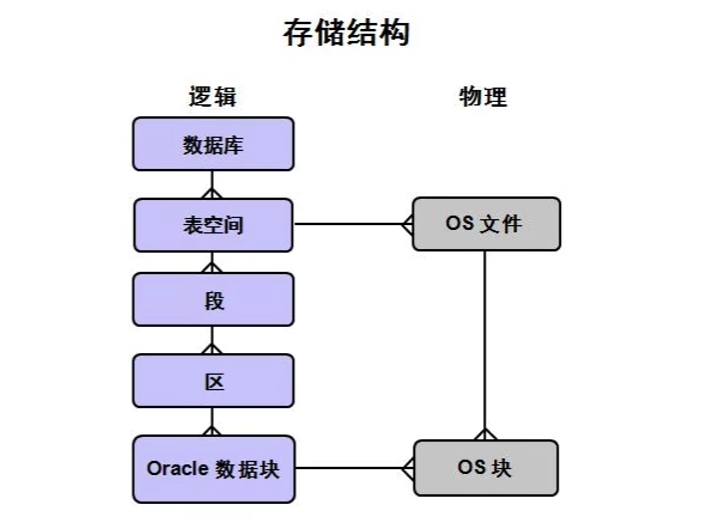
- 数据库:
- Oracle 数据库是数据的物理存储。这就包括(数据文件 ORA 或者 DBF、控制 文件、联机日志、参数文件)。其实 Oracle 数据库的概念和其它数据库不一 样,这里的数据库是一个操作系统只有一个库。可以看作是 Oracle 就只有一 个大数据库。
- 数据库实例:
- 一个 Oracle 实例(Oracle Instance)有一系列的后台进程(Backguound Processes)和内存结构(Memory Structures)组成。一个数据库可以有 n 个实 例。
- 一组 Oracle 后台进程/线程以及一个共享内存区,这些内存由同一个计算机上 运行的线程/进程所共享。这里可以维护易失的、非持久性内容(有些可以刷 新输出到磁盘)。就算没有磁盘存储,数据库实例也能存在。
- 表空间:
- 表空间是一个用来管理数据存储逻辑概念,表空间只是和数据文件(ORA 或 者 DBF 文件)发生关系,数据文件是物理的,一个表空间可以包含多个数据 文件,而一个数据文件只能隶属一个表空间。
- 用户:
- 用户是在实例下建立的,不同的实例可以建相同的用户名。
- Oracle 数据库建好之后,要想在数据库里建表,必须先为数据库建立用户,并为用户指定表空间。
- Oracle 数据库有两个默认的用户:SYSTEM(超级用户,权限等级仅次于 SYS) 和 SYS(超级管理员)。
用户是在某个实例下创建的,用户需要通过实例连接数据库,连接数据库后用户只能访问自己的表空间。
一个实例可以创建多个表空间,而多个用户可以对应不同的表空间,在同一个表空间也可以有多个用户。
1.3、创建用户和表空间
- 以超级管理员身份登录
- 创建表空间
- 创建用户
- 给用户授权
- 查询测试
以超级管理员身份登录:

这里需要使用 sysdba 的身份来连接。
查看实例名称:
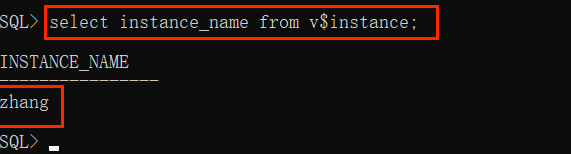
可以看到,这个实例名就是我在安装 Oracle 时自己指定的 SID,之后我们创建其它用户的时候也都是属于这个实例的。
创建表空间:
create tablespace 表命名空间名称 datafile '存储路径\文件名.dbf' size 大小;
可以看到,在我们指定的路径下出现了一个文件:

创建用户:
解锁 scott 用户:
开始菜单打开SQL Plus,登录system/sys用户
解锁:输入指令alter user scott account unlock;
设口令:输入指令alter user scott identified by tiger; 最后的tiger即Scott用户的口令,可以自己设(关于“Scott”有个故事——Scott是Oracle公司创办之初的第一位员工,后来Oracle的CEO就在Oracle数据库默认用户中添加了Scott,还蛮有纪念意义的!而tiger是Scott家养的猫的名字)
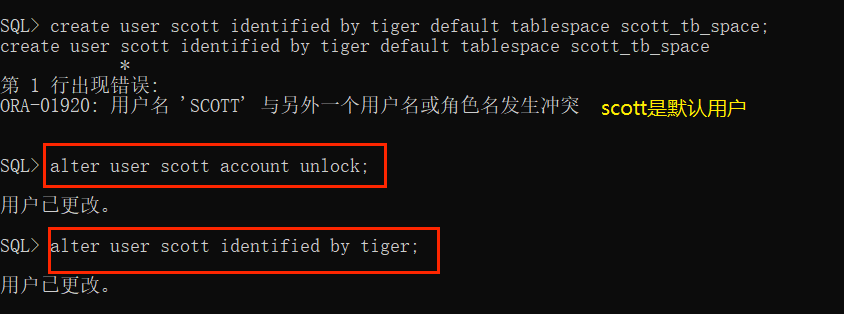
给用户权限:
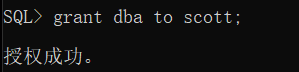
给用户授予 dba 权限:
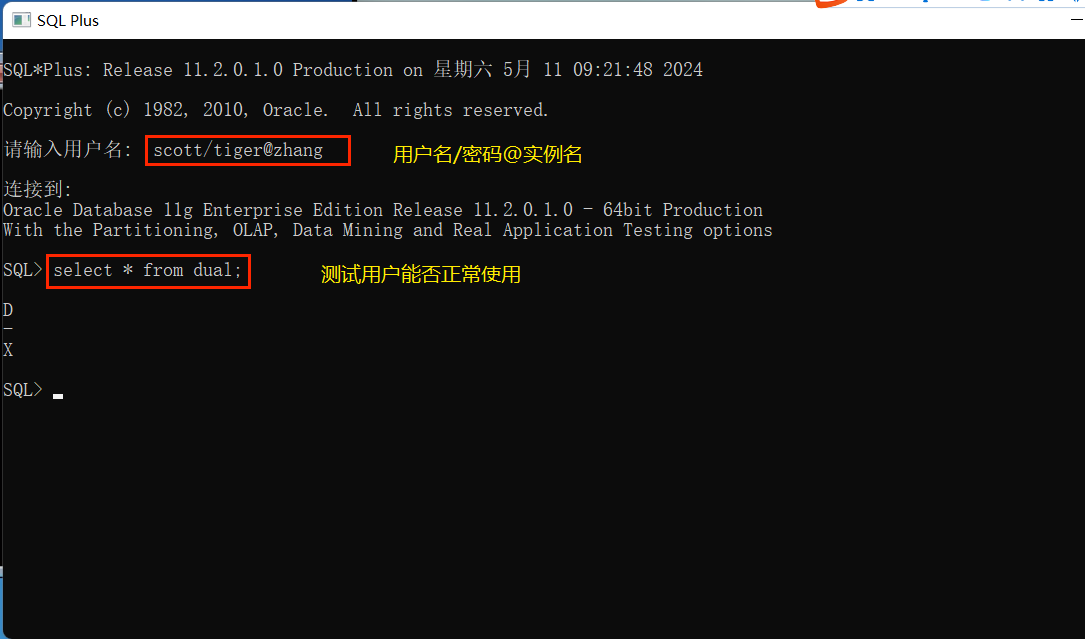
重新登录:
2、Oracle 表设计
2.1、设计原则
好的数据库表设计会影响数据库操作效率。特别是数据特别多的时候,如果表结 构不好的话,操作的时候条件会变得非常复杂。所以为了以后操作简单,表的关系 (内部和外部)要尽量合理的设计。
步骤:
1)找出表要描述的东西
2)列出你想通过这个表得到的相关信息的列表
3)通过上面的信息列表,将信息划分成一块块的小部分,通过这个小块来建表中 的字段;
所以为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规 则。在关系型数据库中这种规则就称为范式。范式是符合某一种设计要求的总结。 要想设计一个结构合理的关系型数据库,必须满足一定的范式。在实际开发中最为 常见的设计范式有三个:
- 第一范式(确保每列保持原子性),属性不可再分
- 第二范式(确保表中的每列都和主键相关),实体唯一
- 第三范式(确保每列都和主键列值直接相关,而不是间接相关),字段没有冗余
基本表及其字段之间的关系,应尽量满足第三范式。但是,满足第三范式的数据 库设计,往往不是最好的设计。为了提高数据库的运行效率,常常需要降低范式标准:适当增加冗余,达到以空间换时间的目的。
更合理的表设计会给每条记录加上一个唯一的识别,就是加上主键。
1)将一个 表字段设为主键要求在表创建的时候就进行设置。
2) 一个表里被设为主键的字段 的值必须是唯一的,也就是说如果一个字段被设为主键,这个表所有的数据列表里 这个字段的值不可能有重复的。
3) 被设为主键的字段不能插入空值。
4) 被设为主键的字段的值是不能更改的。
5) 如果字段被设为是自增长的,主键只能设置一 个且它必须是主键。如果表中没有自增长的字段,则可以设多个字段为主键.
6) 主键最好是一个和表里数据无关的值。比如说另建一个字段:id;而不要设在:name 等这些字段上。
两个表关联.两个表之间数据的关系有三种: 1)一对一;两个表里数据唯一对应; 2)一 对多;表 A 在表 B 里对应多条数据,但表 B 里的一条数据绝对只对就 A 中的一条数据; 3)多对多;A 里的一条数据对应 B 里的多条数据,B 里一条数据也对应 A 中的多条数据.
一对一 的表设计用的不多.可能用到的情况有: a)对一个表中大多数时候不查的字 段,放到另一个表中对应起来.这样可以提高大多数时候查询的效率; b)若表中记录还 有些字段的值未知,可以将这些字段分出来放.这样可以让主表中不存在 NULL; c)不 想轻易就查出来的数据,比如一个人的工资详情,等.可以在主另一表中放着; d)大文 本,通过一个外键关联,这样可以提高查询效率;
一对多 的情况可以如下: 有一个人员信息表 info,里面包括一个外键:email;这个字 段里存的是邮箱表 emailBox 里的主键:id;因为一个人可以对应多个邮箱,但一个邮 箱只能属于一个人(他自己要共用木有办法)
多对多 对优化表设计的用处最大,效果最显著;一个多对多的关系是由一个连接表有 两个一对多的表关系组成的;
另外,同一个表里的各字段之间不要有复杂的依赖关系.各字段只能和主键有依赖关 系.如果非主键和非主键间有依赖关系,就要将它们从主表分离出去,放在另一个表中, 并通过外键进行关联。
2.2、约束
和 MySQL 差不多:
- 主键约束( PRIMARY KEY )
- 唯一约束( UNIQUE )
- 非空约束( NOT NULL )
- 外键约束( FOREIGN KEY )
- 检查约束( CHECK )
2.2.1、主键
主键是定位表中单个行的方式,可以唯一确定表的某一行,关系型数据库要求所有的表都应该有主键,但是Oracle没有遵循此范例的要求,Oracle中的表格没有主见,但是这种情况并不多见。关于组件有几个需要注意的点:
- 键列必须必须具有唯一性,且不能为空,其实主键约束 相当于 UNIQUE+NOT NULL
- 一个表只允许有一个主键
- 主键所在列必须具有索引(主键的唯一约束通过索引来实现),如果不存在, 将会在索引添加的时候自动创建
2.2.2、唯一键
唯一性约束可作用在单列或多列上,对于这些列或列组合,唯一性约束保证每一 行的唯一性。 UNIQUE 允许 null 值,UNIQUE 约束的列可存在多个 null。
2.2.3、非空约束
非空约束作用的列也叫强制列。顾名思义,强制键列中必须有值,当然建表时候 若使用 default 关键字指定了默认值,则可不输入。
2.2.4、外键约束
外键约束定义在具有父子关系的子表中,外键约束使得子表中的列对应父表的主 键列,用以维护数据库的完整性。不过出于性能和后期的业务系统的扩展的考虑, 很多时候,外键约束仅出现在数据库的设计中,实际会放在业务程序中进行处理。 外键约束注意以下几点:
- 外键约束的子表中的列和对应父表中的列数据类型必须相同,列名可以不同
- 对应的父表列必须存在主键约束(PRIMARY KEY)或唯一约束(UNIQUE)
- 外键约束列允许 NULL 值,对应的行就成了孤行了
2.2.5、检查约束
检查约束可用来实施一些简单的规则,比如列值必须在某个范围内。
3、SELECT 语句
这里只介绍和 MySQL 不同的,一样的部分直接跳过(比如基本查询、去重、别名、排序)。
3.1、伪列和表达式
表中不存在的列,但是通过表达式或者常量构造出来的就是伪列:
-- 查询用户姓名和月薪,年薪
SELECT ENAME,SAL,SAL*12 年薪 FROM EMP;NVL 函数
-- 查询员工的月收入(SAL+COMM) 工资+奖金
SELECT ENAME,SAL+NVL(COMM,0) 月收入 FROM EMP;
NULL FIRST | NULL LAST
-- 按照员工的奖金排序 默认升序
SELECT ENAME,COMM FROM EMP ORDER BY COMM NULLS LAST;这里把空放到的最后。
字符串拼接 ||
-- 员工姓名后面+'a'
SELECT ENAME||'a' ENAME FROM EMP;3.2、虚表
虚表其实就是一张虚拟表,就像我们在 Hive 中要计算一些表达式(比如 1+1)或者当前时间,在 Hive 中直接就可以 SELECT 1+1; 但是在 Oracle 中必须 FROM DUAL;
dual 是一个虚表,虚拟表,是用来构成 select 的语法规则,oracle 保证 dual 里面 永远只有一条记录。该表只有一行一列,它和其他表一样,可以执行插入、更新、 删除操作,还可以执行 drop 操作。但是不要去执行 drop 表的操作,否则会使系 统不能用,起不了数据库。
dual 主要用来选择系统变量或是求一个表达式的值。如果我们不需要从具体的表 来取得表中数据,而是单纯地味了得到一些我们想得到的信息,并要通过 select 完 成时,就要借助一个对象,这个对象就是 dual。
-- 计算 1+1
SELECT 1+1 FROM DUAL;3.3、SELECT 语句解析顺序
SELECT ... FROM ... ORDER BY ...- FROM
- SELECT
- ORDER BY
因为 SELECT 是在 ORDER BY 前面执行的,所以我们可以在 ORDER BY 中使用别名:
-- 查询员工的月收入(SAL+COMM) 工资+奖金,并按照月收入降序
SELECT ENAME,SAL+NVL(COMM,0) 月收入 FROM EMP ORDER BY 月收入 DESC ;3.4、模糊查询
模糊查询常用的就两个个符号:'%' 和 '_' ,其中 % 代表任意多个字符, _ 代表一个占位符,用法和 MySQL 一样。
但是如果我们的数据包含 % 或 _ 这种关键字怎么办,我们需要用 escape 这个函数来处理:
3.4.1、escape
escape 函数的意思就是排除
-- 查询员工姓名中包含 % 的员工信息
-- 排除 a 后面的 % 字符
SELECT * FROM EMP WHERE ENAME LIKE '%a%%' ESACPE('a');
-- 查询员工姓名中包含 a% 的员工信息
-- escape 中的a只能表示它后面的一位字符用自己本身来表示,所以 aa是一组,a%也是一组
SELECT * FROM EMP WHERE ENAME LIKE '%aaa%%' ESACPE('a');4、函数
之前在 HQL 中学了很多函数,Oracle 的函数这一块的内容比较简单,等到用到的时候直接查询文档即可。