1 Redis数据结构
redis的数据存储在dict.中,其数据结构为(c源码)
ypedef struct dict {
dictType *type; //理解为面向对象思想,为支持不同的数据类型对应dictType抽象方法,不同的数据类型可以不同实现
void *privdata; //也可不同的数据类型相关,不同类型特定函数的可选参数。
dictht ht[2]; //2个hash表,用来数据存储 2个dictht
long rehashidx; /* rehashing not in progress if
rehashidx == -1 */ // rehash标记 -1代表不再rehash
unsigned long iterators; /* number of iterators
currently running */
} dict;
用图表示其存储流程为:
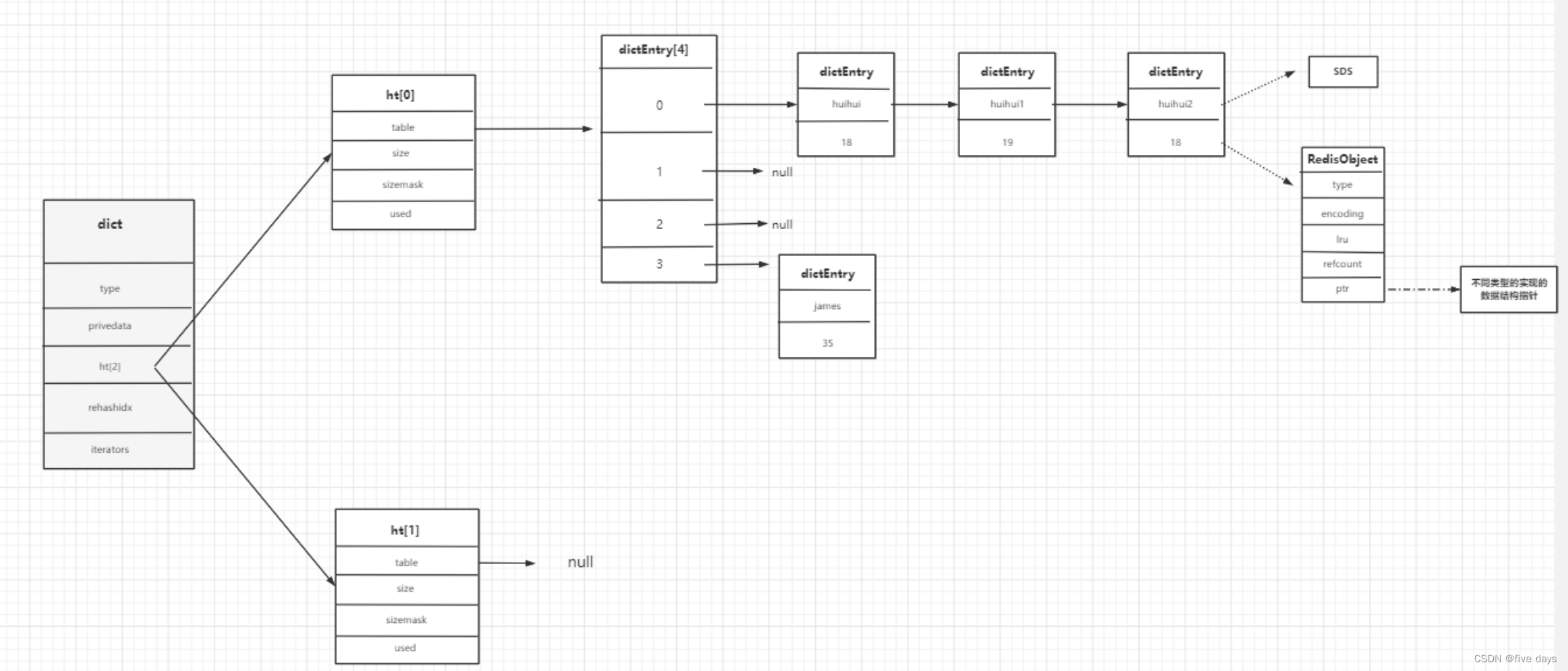
如图,redis在发生哈希冲突时,采用的是从头插法增加Entry的。那么Redis为什么要采用头插?而我们之前讲的HashMap为什么要用尾插呢?
a.头插在并发情况下会形成死链,而Redis是单线程执行,不会存在并发问题,也不会形成死链
b.头插的性能比尾插要高很多,尾插必须找到链表的最后一个位置,而头插只需要加到数据下标,并且把next指向之前的第一个数据就可以了
2 Redis扩容
redis为什么要扩容?
因为不扩容,那么从上面可以看到,每一个Node节点,若发生哈希冲突后,链表就会越来越长,查询的速度就会接近链表的速度O(n)
那么redis是如何进行扩容的呢?
2.1 扩容的时机
通过向redis加数据的时候,我们找到扩容的源码条件(dict.c文件中 _dictExpandIfNeeded方法)
//扩容条件 hash表中已使用的数量大于等于 hash表的大小
if (d->ht[0].used >= d->ht[0].size &&
//并且dict_can_resize为1 或者 已使用的大小大于hash表大
小的 5倍,大于等于1倍的时候,下面2个满足一个条件即可
(dict_can_resize ||
d->ht[0].used/d->ht[0].size >
dict_force_resize_ratio)) // dict_force_resize_ratio默认为5
{
//扩容成原来的2倍
return dictExpand(d, d->ht[0].used*2);
}
分析:何时扩容由if条件可以得出,a.当已使用的数量大于等于hash表的长度时并且dict_can_resize为true时扩容; b.或者当dict_can_resize不为true,而已使用的数量大于hash表长度的5倍时扩容
那么dict_can_resize这个参数是代表着什么呢?(c源码中的默认设置值)
static int dict_can_resize = 1; //默认是1,达到一倍的时候就会
扩容
static unsigned int dict_force_resize_ratio = 5; //5倍dictEnableResize设置允许可以扩容,dictDisableResize会将其设置为0
void dictEnableResize(void) {
dict_can_resize = 1;
}
void dictDisableResize(void) {
dict_can_resize = 0;
}那么这两个方法又是在哪里调用的呢?
void updateDictResizePolicy(void) {
if (!hasActiveChildProcess()) //hasActiveChildProcess如果为true代表有子进程持久化,前面是!
dictEnableResize();
else //有子进程时,就会将dict_can_resize=0
dictDisableResize();
}
/* Return true if there are no active children processesdoing RDB saving,
* AOF rewriting, or some side process spawned by a loadedmodule. */
int hasActiveChildProcess() {
return server.rdb_child_pid != -1 ||
server.aof_child_pid != -1 ||
server.module_child_pid != -1;
}分析:从上面源码我们可以发现,当没有子进程在进行RDB、AOF持久化或者其它的一些辅助进程则会讲dict_can_resize设置为1,否则设置为0。为什么这么做呢?那是因为现在操作系统写时复制(copy-on-write)来优化子进程的使用效率。在子线程进入RDB跟AOF时,如果发生大量内存写操作,会导致进程的性能降低。所以,当在RDB或者AOF时,将扩容阈值放大到了5倍(有兴趣的可以了解下copy-on-write技术)
扩容时机总结: 1.当没有子进程在进行RDB或者AOF时,已使用的数量大于等于hash表的size时就发生扩容;2.当有子进程在进行EDB或者AOF时,已使用的数量需要大于hash表size的5倍时才进行扩容。
2.2 如何扩容
a.当满足扩容条件触发扩容时,判断是否已经在扩容了,如果在扩容或者扩容的大小跟我现在的ht[0].size一样,则这次扩容不做
b.new一个新的dictht,大小为ht[0].used*2(但是必须向上2的幂,比如6,那么大小就为8),并且ht[1]=新创建的dictht
c.我们此时有一个更大的table了,但是需要把数据迁移到ht[1].table,所以将dict的rehashidx(数据迁移的偏移量赋值0),就代表着可以进行数据迁移了,也就是可以rehash了
d.等待数据迁移完成,数据不会马上迁移,而是采用渐进式rehash,慢慢的把数据迁移到ht[1]
e.当数据迁移完成,ht[0].table=ht[1],ht[1].table=NULL、ht[1].size=0、ht[1].sizemask=0、ht[1].used=0
f.把dict的rehashidx=-1
C源码(dict.c文件中的dictExpand方法)
int dictExpand(dict *d, unsigned long size)
{
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
//正在扩容,不允许第二次扩容,或者ht[0]的数据量大于扩容后的数量,没有意义,这次不扩容
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
dictht n; /* the new hash table */
//得到最接近2的幂 跟hashMap思想一样
unsigned long realsize = _dictNextPower(size);
/* Rehashing to the same table size is not useful. */
//如果跟ht[0]的大小一致 直接返回错误
if (realsize == d->ht[0].size) return DICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */
//为新的dictht赋值
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's notreally a rehashing
* we just set the first hash table so that it canaccept keys. */
//ht[0].table为空,代表是初始化
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
//将扩容后的dictht赋值给ht[1]
d->ht[1] = n;
//标记为0,代表可以开始rehash
d->rehashidx = 0;
return DICT_OK;
}2.3 数据如何迁移
redis中假如一次性进行数据迁移会很耗时间,会让单条指令等待很久很久。会形成阻塞,所以,Redis采用的是渐进式Rehash,所谓渐进式,就是慢慢的,不会一次性把所有数据迁移。
那么什么时候会进行渐进式数据迁移呢?
a.每次进行key的crud操作都会进行一个hash桶的数据迁移
b.定时任务serverCron,进行部分数据迁移
CRUD(_dictRehashStep、dictRehash)
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1);
}int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of emptybuckets to visit. */
//要访问的最大的空桶数 防止此次耗时过长
if (!dictIsRehashing(d)) return 0; //如果没有在rehash返回0
//循环,最多1次,并且ht[0]的数据没有迁移完 进入循环
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
//rehashidx rehash的索引,默认0 如果hash桶为空 进入自旋 并且判断是否到了最大的访问空桶数
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx]; //得到ht[0]的下标为rehashidx桶
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) { //循环hash桶的链表 并且转移到ht[1]
uint64_t h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h]; //头插
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
//转移完后 将ht[0]相对的hash桶设置为null
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
//ht[0].used=0 代表rehash全部完成
if (d->ht[0].used == 0) {
//清空ht[0]table
zfree(d->ht[0].table);
//将ht[0] 重新指向已经完成rehash的ht[1]
d->ht[0] = d->ht[1];
//将ht[1]所有数据重新设置
_dictReset(&d->ht[1]);
//设置-1,代表rehash完成
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}将ht[1]的属性复位
static void _dictReset(dictht *ht)
{
ht->table = NULL;
ht->size = 0;
ht->sizemask = 0;
ht->used = 0;
}
分析:CRUD操作每次可访问的hash空桶数为1*10= 10 个hash桶,并且while(n--),n是为1的,也就是说,CRUD操作只会优先查到一个hash桶,然后仅仅把该hash桶中的数据迁移完后就什么也不做了。
定时任务,定时任务的执行频率会根据redis.conf中的hz配置。定时任务也是在规定时间段内会进行部分迁移(每次100+个hash桶),判断一个时间,该时间内能做多少次就做多少次
定时任务的入口方法(server.c文件中的serverCron),最终执行rehash的方法(dictRehashMilliseconds)
int dictRehashMilliseconds(dict *d, int ms) { // ms默认传的是1
long long start = timeInMilliseconds();
int rehashes = 0;
//进入rehash方法 dictRehash 去完成渐进时HASH
while(dictRehash(d,100)) {
rehashes += 100;
//判断是否超时
if (timeInMilliseconds()-start > ms) break;
}
return rehashes;
}可以看到定时任务传给dictRehash方法中的n为100,也就是说,定时任务可访问的最大空桶说为1000,而while循环中,定时任务可以循环100次,可以处理100个hash桶的数据迁移,而ms传值为1,也就是redis中默认的定时任务是在1ms内能处理多少个hash桶就处理多少个hash桶。
3 Redis扩容流程图
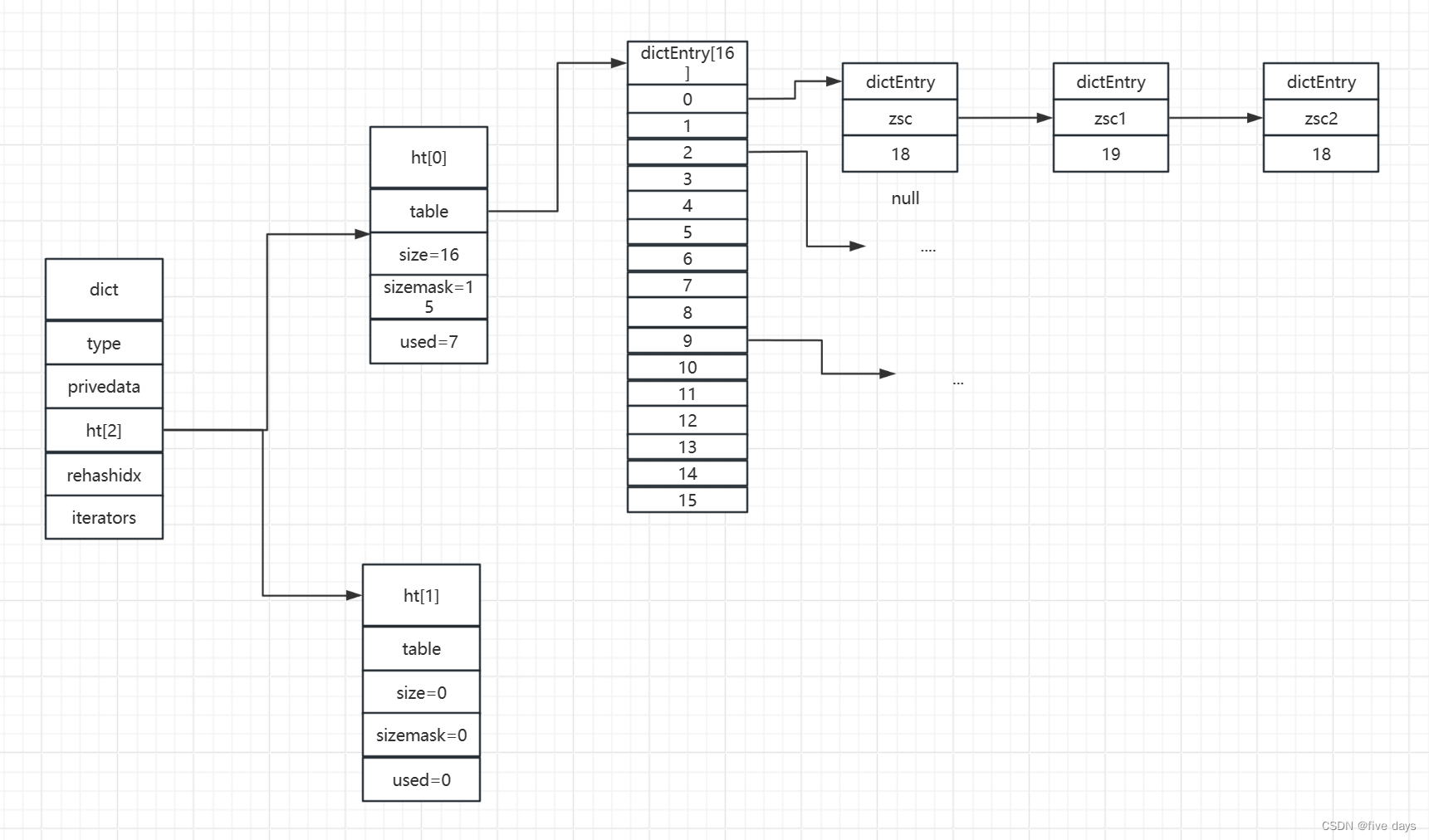
假如我们新增了一个数据jane:36,通过计算hash值得出在dicEntry下标为3的位置上,则就使用头插法挂在dicEntry[3]的链表位置上,此时也没有RDB或AOF子进程在进行,而ht[0].used=7>ht[0].size=4,则触发扩容机制,ht[1].size初始化为2*ht[0].used=14,向上取2的幂得16,于是如图所示:
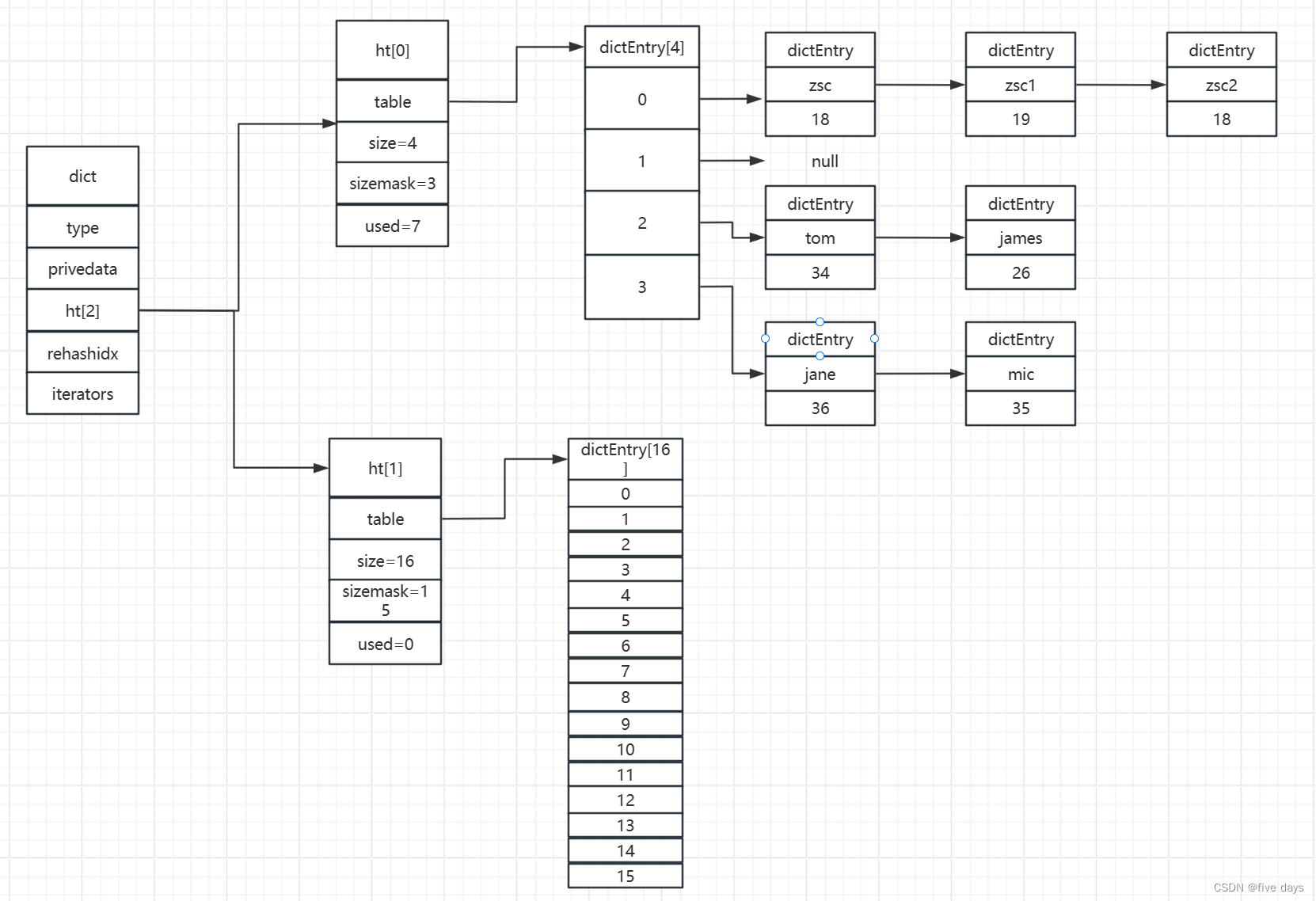
此时满足扩容得条件,则rehashidx=0,即从ht[0].table得下标0处得hash桶开始做迁移,这里为了演示的方便,我们假设索引为0处的hash桶的3个key 重新计算hash后(原下标计算hash(zsc&3) = 0 ,迁移后下标计算hash(zsc) & 15 = 0),下标值仍为0,则迁移后如图所示:

此时代表我们已经成功迁移了一个hash桶,当所有的hash桶都迁移完成后,则将ht[1]赋值为ht[0],ht[1]进行初始化
![[AutoSar]BSW_Diagnostic_004 ReadDataByIdentifier(0x22)的配置和实现](https://img-blog.csdnimg.cn/direct/c84c73a2eab942bba8aeefddae9f851d.png)
![[Java EE] 文件IO(一):文件概念与文件系统操作](https://img-blog.csdnimg.cn/direct/c539adac66b24eaba226cef372cfd33d.png)


![【Linux】- Linux环境变量[8]](https://img-blog.csdnimg.cn/direct/6dfd796f568a44e58aed70d22731b5e0.png)