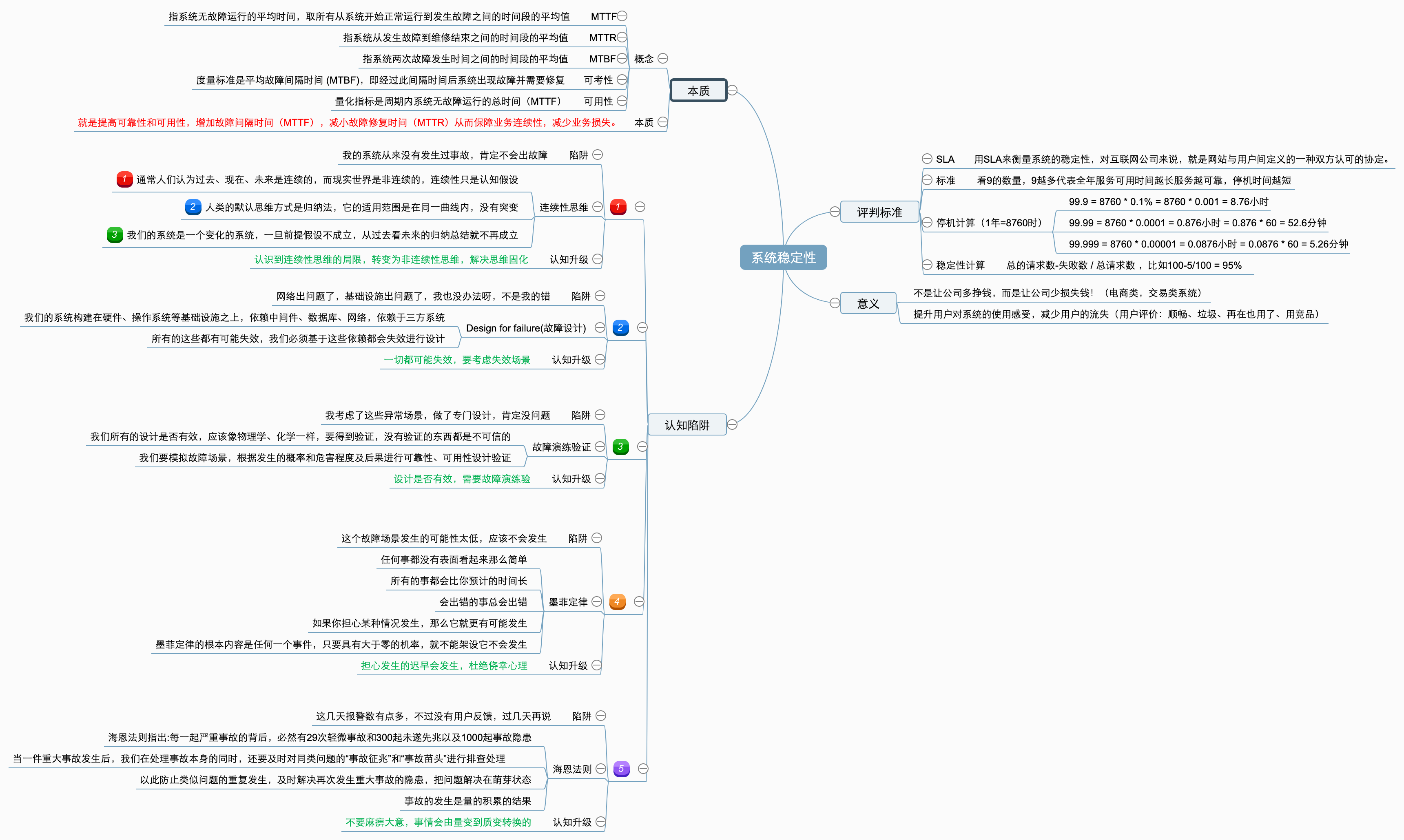
1、系统稳定性的评判标准
在开始谈稳定性保障之前,我们先来聊聊业内经常提及的一个词SLA!业内喜欢用SLA (服务等级协议,全称:service level agreement)来衡量系统的稳定性,对互联网公司来说,就是网站与用户间定义的一种双方认可的协定。
我们平常经常看到互联网公司喊口号,我们今年一定要做到3个9、4个9,即99.9%、99.99%,甚至还有5个9,即99.999%。
9越多代表全年服务的可用时间,时间越长服务越可靠。就以一个标准99.99%为例,停机时间52.6分钟,平均到每周也就是只能有差不多1分钟的停机时间,也就是说网络抖动这个时间可能就没了。
服务稳定性计算标准一般都是,总的请求数-失败数 / 总请求数 ,比如100-5/100 = 95% ,下面列举了几个对应的停机时间。
1年 = 365天 = 8760小时
3个9 99.9 = 8760 * 0.1% = 8760 * 0.001 = 8.76小时
4个9 99.99 = 8760 * 0.0001 = 0.876小时 = 0.876 * 60 = 52.6分钟
5个9 99.999 = 8760 * 0.00001 = 0.0876小时 = 0.0876 * 60 = 5.26分钟2、提高系统稳定性的意义
我认为这是一个非常重要的问题,我们费了那么多资源,投入了许多时间、精力为的是什么,揭高系统稳定性的意义究竟是什么?
- 不是让公司多挣钱,而是让公司少损失钱!(电商类,交易类系统)
- 提升用户对系统的使用感受,减少用户的流失(用户评价:顺畅、垃圾、再在也用了、用竞品)
3、提高系统稳定性的本质
- MTTF (Mean Time To Failure,平均无故障时间),指系统无故障运行的平均时间,取所有从系统开始正常运行到发生故障之间的时间段的平均值。 MTTF =∑T1/ N
- MTTR (Mean Time To Repair,平均故障修复时间),指系统从发生故障到维修结束之间的时间段的平均值。MTTR =∑(T2+T3)/ N
- MTBF (Mean Time Between Failure,平均故障间隔时间),指系统两次故障发生时间之间的时间段的平均值。 MTBF =∑(T2+T3+T1)/ N
- 可靠性:度量标准是平均故障间隔时间 (MTBF),即经过此间隔时间后组件出现故障并需要修复。提高可靠性需要强调减少系统故障的次数,即不出故障或尽可能的少出故障,即增加MTTF时间。
- 可用性:量化指标是周期内系统无故障运行的总时间(MTTF)。提高可用性需要强调减少从灾难中恢复的时间,即减小MTTR时间。
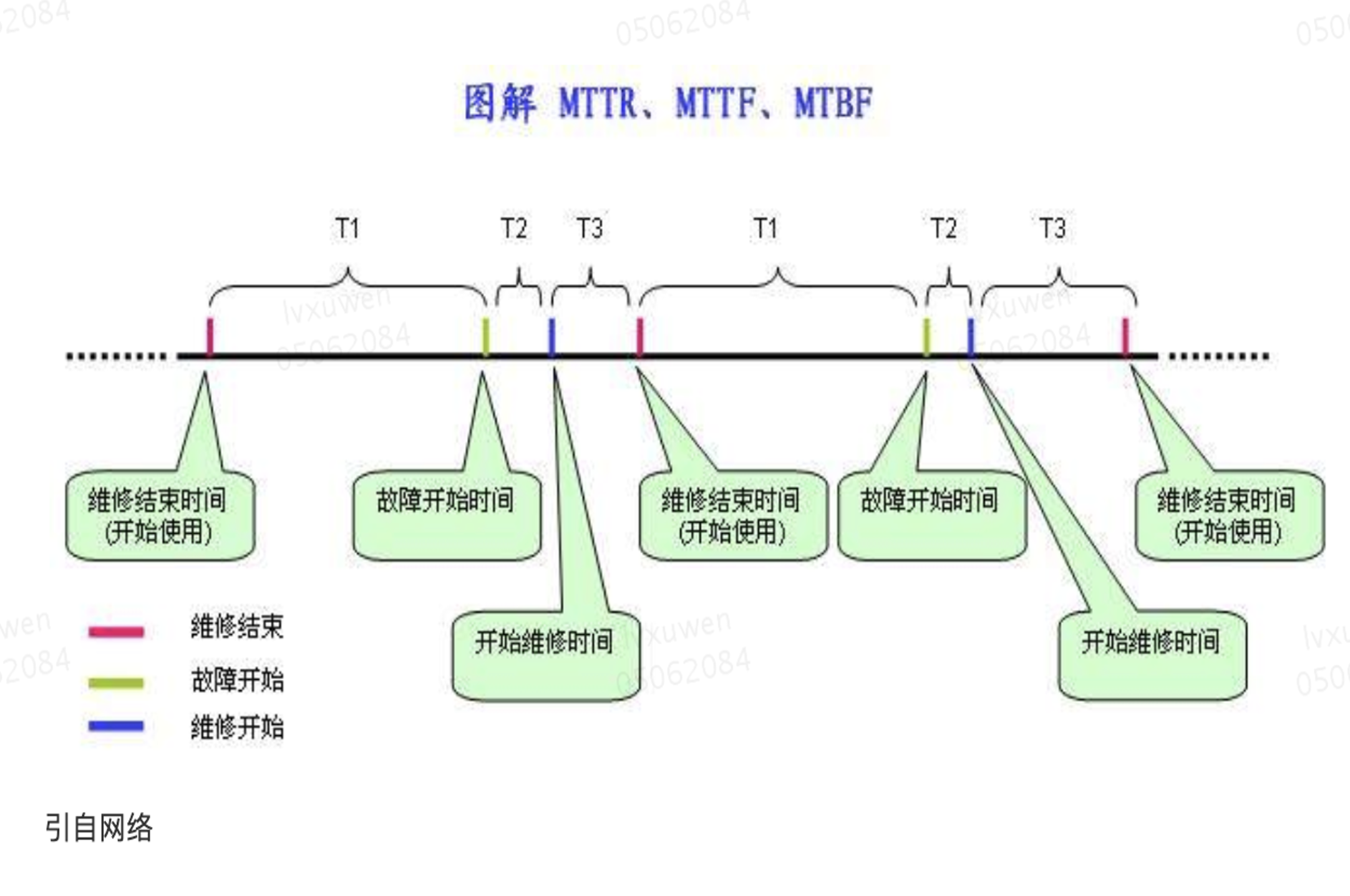
系统稳定性的本质:就是提高可靠性和可用性,增加故障间隔时间(MTTF),减小故障修复时间(MTTR)从而保障业务连续性,减少业务损失。
4、提高系统稳定性认知陷阱
本节大概讲一下,我们在维护系统时的一些常见陷阱,以及我们如何提升我们的认知水平。
陷阱1:我的系统从来没有发生过事故,肯定不会出故障
连续性思维:通常人们认为过去、现在、未来是连续的,而现实世界是非连续的,连续性只是认知假设。人类的默认思维方式是归纳法,它的适用范围是在同一曲线内,没有突变。我们的系统是一个变化的系统,一旦前提假设不成立,从过去看未来的归纳总结就不再成立。
认知升级:认识到连续性思维的局限,转变为非连续性思维,解决思维固化
陷阱2:网络出问题了,基础设施出问题了,我也没办法呀,不是我的错
Design for failure(故障设计):我们的系统构建在硬件、操作系统等基础设施之上,依赖中间件、数据库、网络,依赖于三方系统,所有的这些都有可能失效,我们必须基于这些依赖都会失效进行设计。
认知升级:一切都可能失效,要考虑失效场景
陷阱3:我考虑了这些异常场景,做了专门设计,肯定没问题
故障演练验证: 我们所有的设计是否有效,应该像物理学、化学一样,要得到验证,没有验证的东西都是
不可信的。我们要模拟故障场景,根据发生的概率和危害程度及后果进行可靠性设计验证、可用性设计验证,证明如我们期望的一样运行。
认知升级:设计是否有效,需要故障演练验
陷阱4:这个故障场景发生的可能性太低,应该不会发生
墨菲定律(Murphy's Law):主要内容有四个方面:
- 任何事都没有表面看起来那么简单;
- 所有的事都会比你预计的时间长;
- 会出错的事总会出错;
- 如果你担心某种情况发生,那么它就更有可能发生。
墨菲定律的根本内容是指任何一个事件,只要具有大于零的机率,就不能架设它不会发生。
认知升级:担心发生的迟早会发生,杜绝侥幸心理
陷阱5:这几天报警数有点多,不过没有用户反馈,过几天再说
海恩法则:任何不安全事故都是可以预防的。海恩法则,是航空界关于飞行安全的法则。海恩法则指出:每一起严重事故的背后,必然有29次轻微事故和300起未遂先兆以及1000起事故隐患。
按照海恩法则分析,当一件重大事故发生后,我们在处理事故本身的同时,还要及时对同类问题的“事故
征兆”和“事故苗头”进行排查处理,以此防止类似问题的重复发生,及时解决再次发生重大事故的隐患,把问题解决在萌芽状态。
海恩法则强调两点:一是事故的发生是量的积累的结果;二是再好的技术,再完美的规章,在实际操作层面,也无法取代人自身的素质和责任心
认知升级:不要麻痹大意,事情会由量变到质变转换的
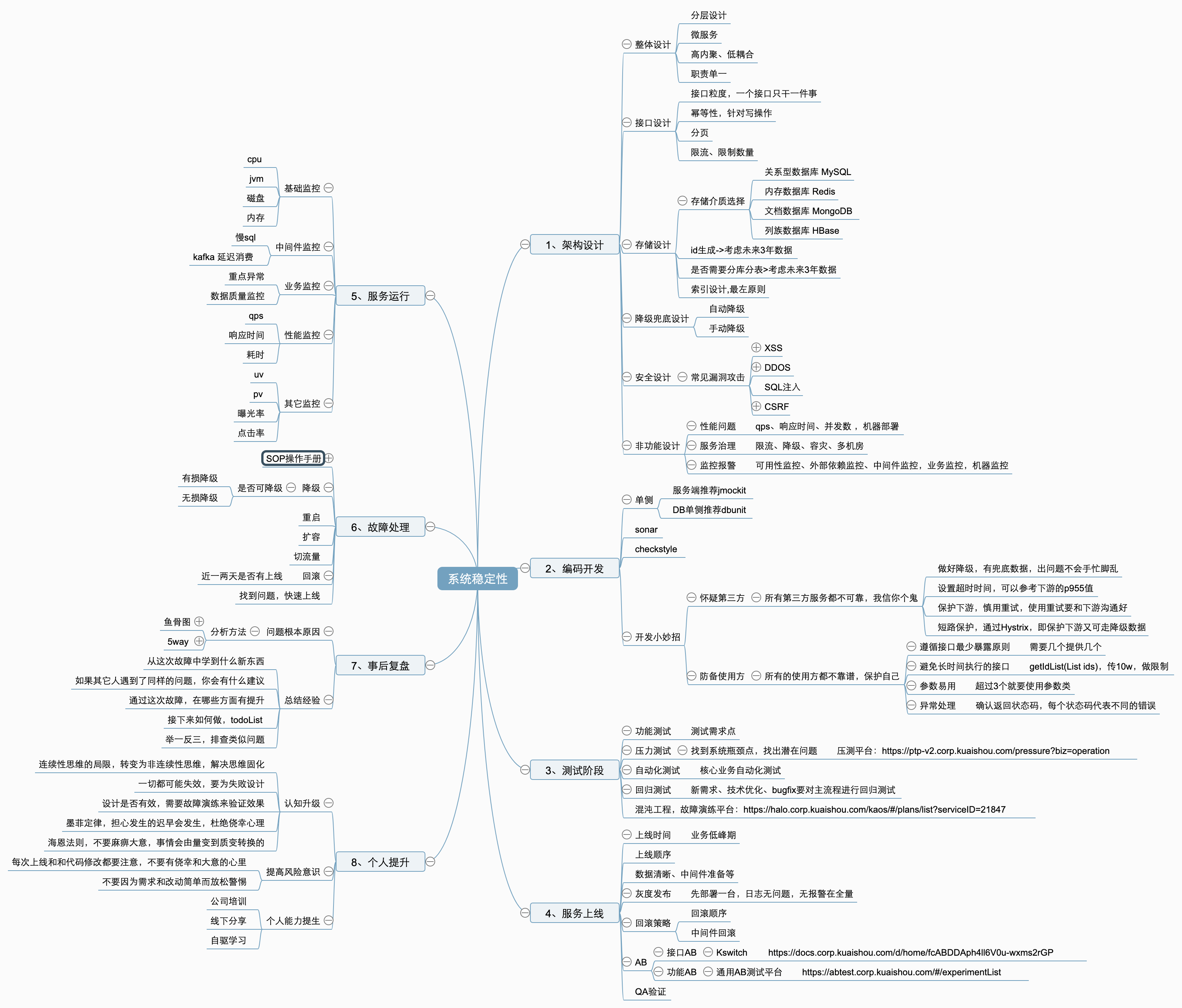
5、提高系统稳定性的具体方法
上面说了一大堆,又是标准,又是意义的,下面的才是干货,我以为自己的角度进行了一下归纳总结。
6、总结
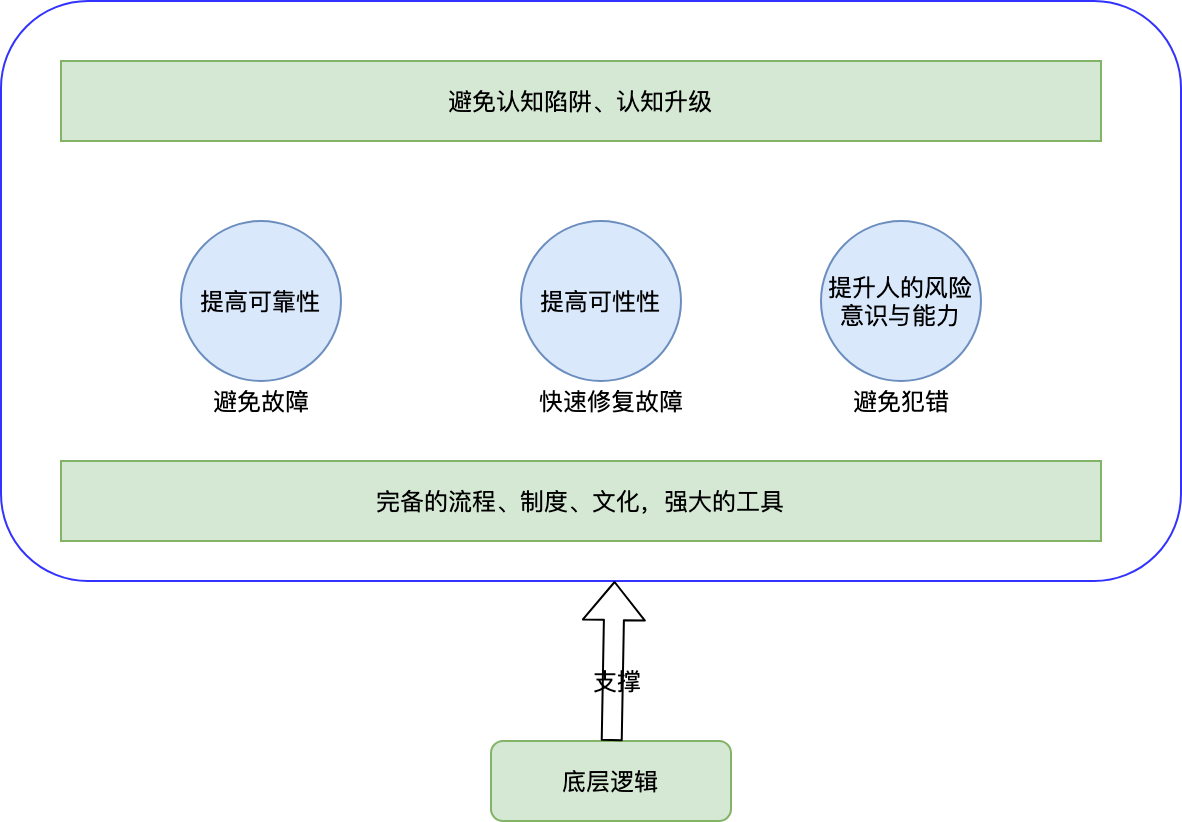
系统就像一辆高速运行的汽车,随时都会有新的需求,新的问题在等着我们,我们不能让这个高速行驶的汽车停下来修复问题,所以我们只能在它运行的时候修复,这是一项风险很高的操作,所以需要我们在各个环节都做好了,才能保证它不出问题。要提高系统稳定性也不一朝一夕的事,是一个长期的过程,所以不要松懈,有问题及时解决。
本是后山人,偶做前堂客。醉舞经阁半卷书,坐井说天阔。写的不好敬请谅解!