文章目录
- 1. LLM推理attention优化技术
- KV Cache
- PageAttention显存优化
- MHA\GQA\MQA优化技术
- FlashAttention优化技术
- 稀疏Attention
- 1. Atrous Self Attention
- 2. Local Self Attention
- 3. Sparse Self Attention
- 2. LLM数据处理关键
- 去重
- 多样性保证
- 构造扩充数据
- 充分利用数据
- 参考文献
1. LLM推理attention优化技术
首先LLM推理的过程是一个自回归的过程,也就是说前i次的token会作为第i+1次的预测数据送入模型,拿到第i+1次的推理token。
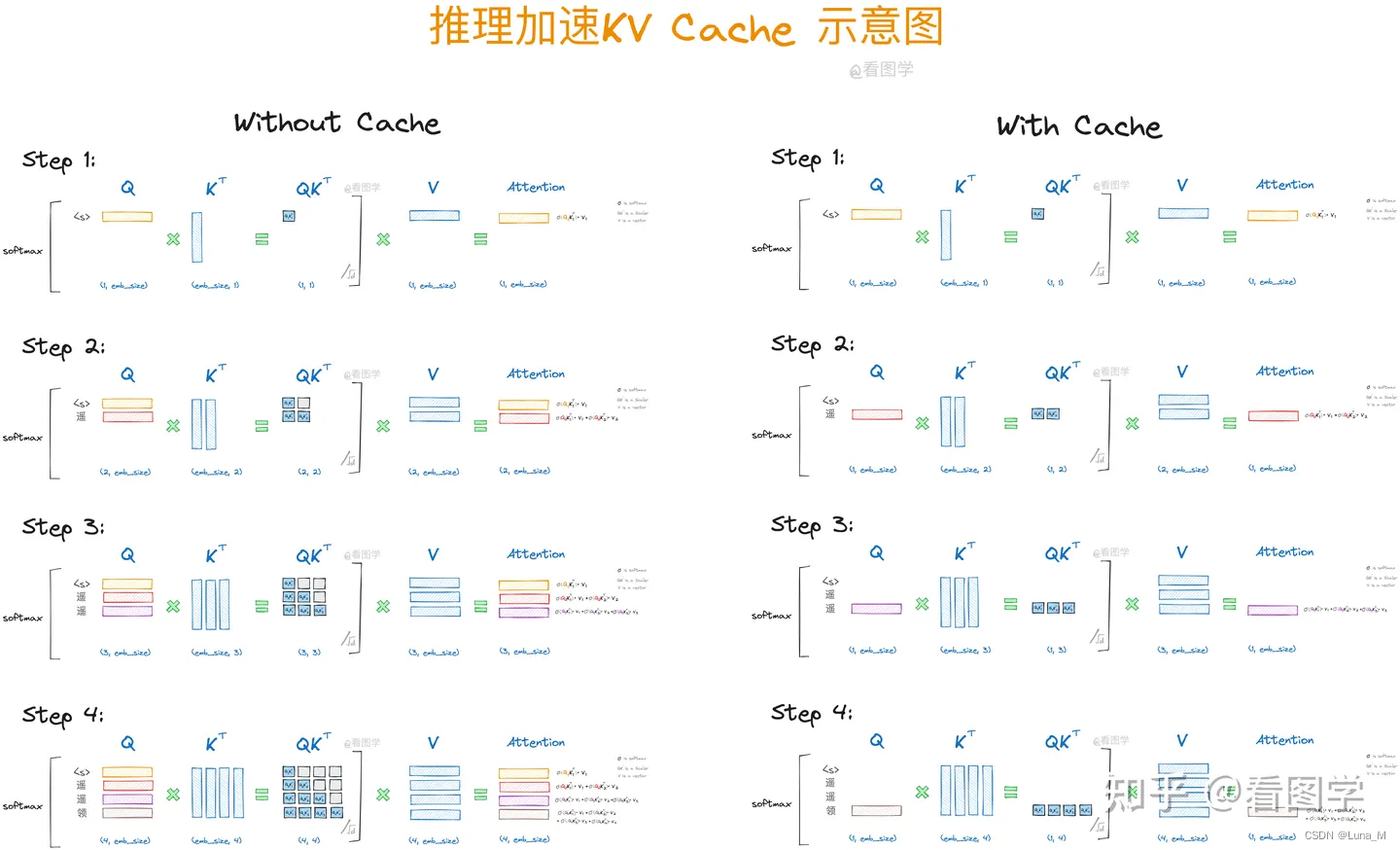
kv cache是为了避免每次采样token时重新计算键值向量。利用预先计算好的k值和v值,可以节省大量计算时间,尽管这会占用一定的存储空间。
KV Cache
KV Cache是Transformer标配的推理加速功能,transformer官方use_cache这个参数默认是True,但是它只能用于Decoder架构的模型,这是因为Decoder有Causal Mask,在推理的时候前面已经生成的字符不需要与后面的字符产生attention,从而使得前面已经计算的K和V可以缓存起来。
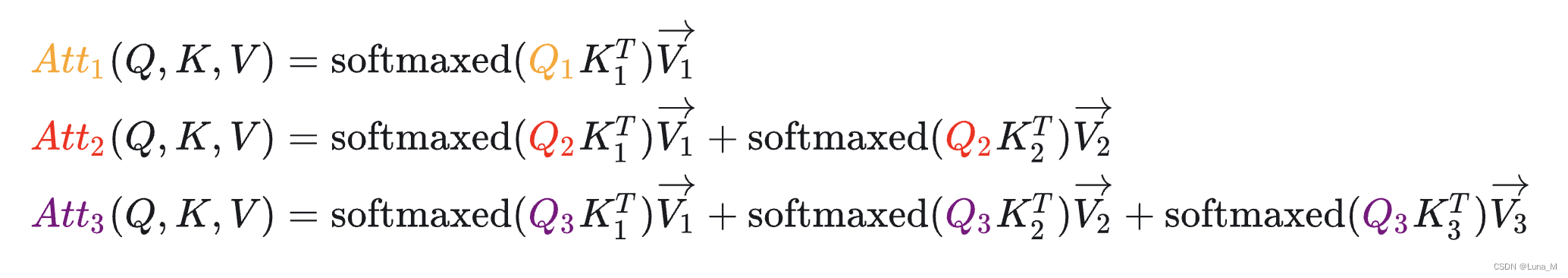
我们每一步其实之需要根据
Q
k
Q_k
Qk计算
A
t
t
k
Att_k
Attk就可以,之前已经计算的Attention完全不需要重新计算。但是
K
K
K和
V
V
V 是全程参与计算的,所以这里我们需要把每一步的
K
K
K和
V
V
V 缓存起来。所以说叫KV Cache好像有点不太对,因为KV本来就需要全程计算,可能叫增量KV计算会更好理解。
当前轮输出token与输入tokens拼接,并作为下一轮的输入tokens,反复多次。可以看出第i+1轮输入数据只比第i轮输入数据新增了一个token,其他全部相同!因此第i+1轮推理时必然包含了第i轮的部分计算。KV Cache的出发点就在这里,缓存当前轮可重复利用的计算结果,下一轮计算时直接读取缓存结果。
注:KVCache是推理加速用的,训练无需。
所以未来LLM推理优化的方案就比较清晰了,就是尽可能的减少推理过程中kv键值对的重复计算,实现kv cache的优化。
目前减少KV cache的手段有许多,比如page attention、MQA、MGA等,另外flash attention可以通过硬件内存使用的优化,提升推理性能。
PageAttention显存优化
PageAttention是目前kv cache优化的重要技术手段,目前最炙手可热的大模型推理加速项目VLLM的核心就是PageAttention技术。在缓存中,这些 KV cache 都很大,并且大小是动态变化的,难以预测。已有的系统中,由于显存碎片和过度预留,浪费了60%-80%的显存。PageAttention提供了一种技术手段解决显存碎片化的问题,从而可以减少显存占用,提高KV cache可使用的显存空间,提升推理性能。
首先,PageAttention命名的灵感来自OS系统中虚拟内存和分页的思想。可以实现在不连续的空间存储连续的kv键值。另外,因为所有键值都是分布存储的,需要通过分页管理彼此的关系。序列的连续逻辑块通过 block table 映射到非连续物理块。
MHA\GQA\MQA优化技术
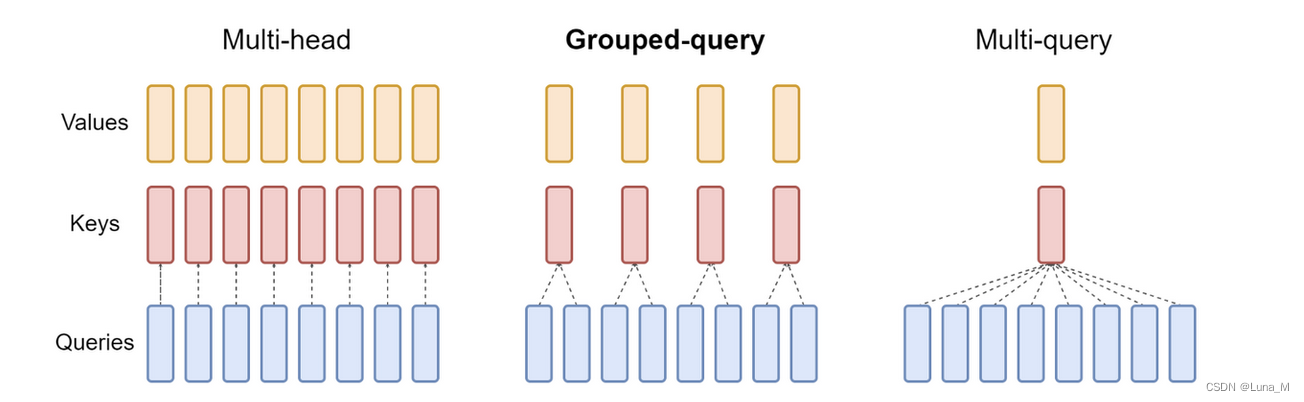
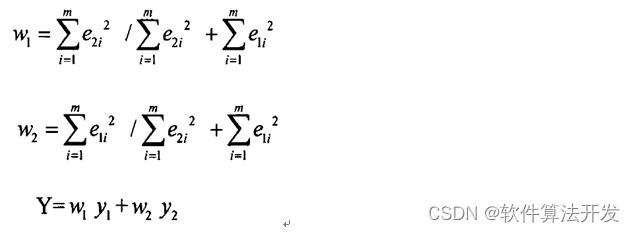
MQA,全称 Multi Query Attention, 而 GQA 则是前段时间 Google 提出的 MQA 变种,全称 Group-Query Attention。MHA(Multi-head Attention)是标准的多头注意力机制,h个Query、Key 和 Value 矩阵。MQA 让所有的头之间共享同一份 Key 和 Value 矩阵,每个头只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量。GQA将查询头分成N组,每个组共享一个Key 和 Value 矩阵。
如上图,GQA以及MQA都可以实现一定程度的Key value的共享,从而可以使模型体积减小,GQA是MQA和MHA的折中方案。这两种技术的加速原理是(1)减少了数据的读取(2)减少了推理过程中的KV Cache。需要注意的是GQA和MQA需要在模型训练的时候开启,按照相应的模式生成模型。
FlashAttention优化技术
Flash attention推理加速技术是利用GPU硬件非均匀的存储器层次结构实现内存节省和推理加速,通过合理的应用GPU显存实现IO的优化,从而提升资源利用率,提高性能。
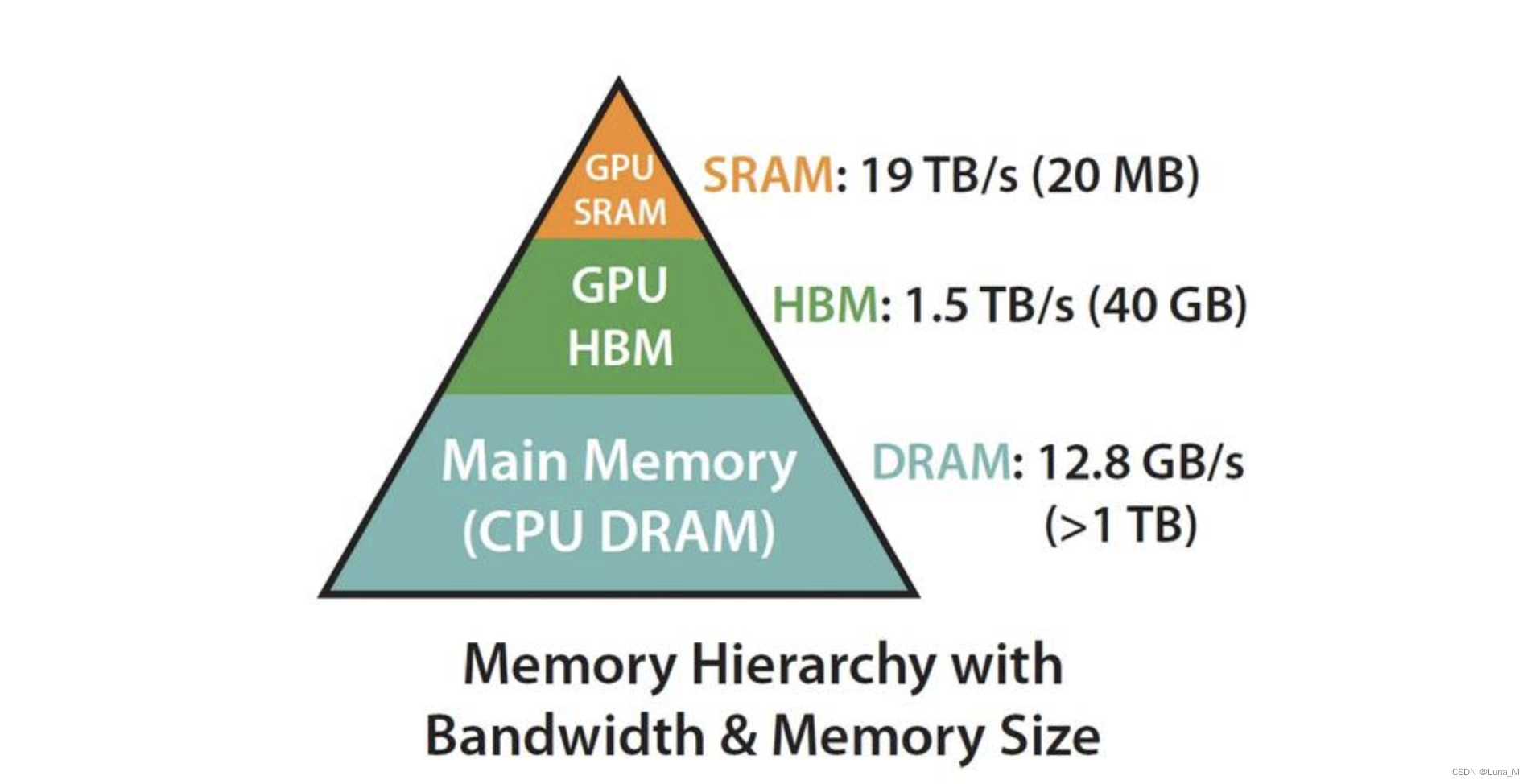
稀疏Attention
Attention中,QK的维度为nd,可以发现Q和K的乘积会产生一个nn的矩阵,而计算这种大型矩阵的行方向softmax的复杂度是 O ( n 2 ) O(n^2) O(n2)。
对于超长序列,计算全局自注意力(每个元素与其他每个元素相乘)会变得非常困难,因此也就有了后来的一些研究对自注意力机制的复杂度进行优化,当然这样做也可能会失去自注意力能够处理长距离上下文的优势。
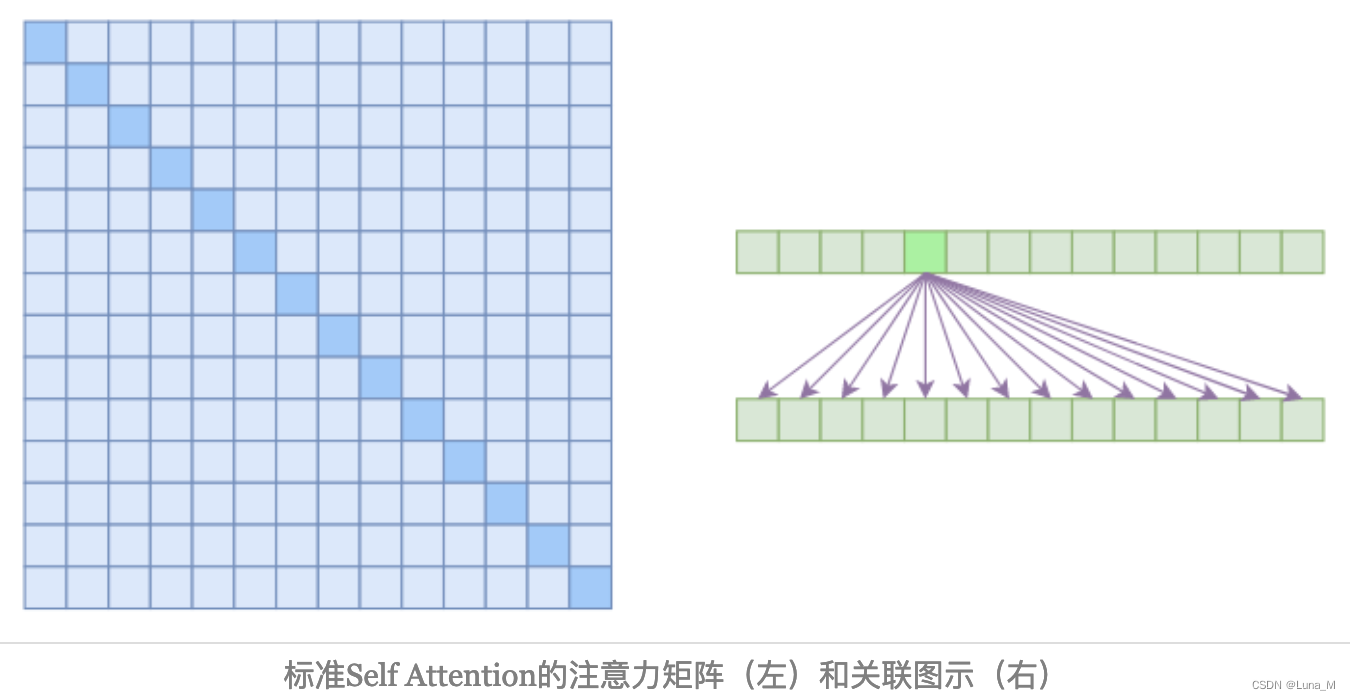 在上图中,左边显示了注意力矩阵,右边显示了关联性,这表明每个元素都跟序列内所有元素有关联。
在上图中,左边显示了注意力矩阵,右边显示了关联性,这表明每个元素都跟序列内所有元素有关联。
所以,如果要节省显存,加快计算速度,那么一个基本的思路就是减少关联性的计算,也就是认为每个元素只跟序列内的一部分元素相关,这就是稀疏Attention的基本原理。
1. Atrous Self Attention
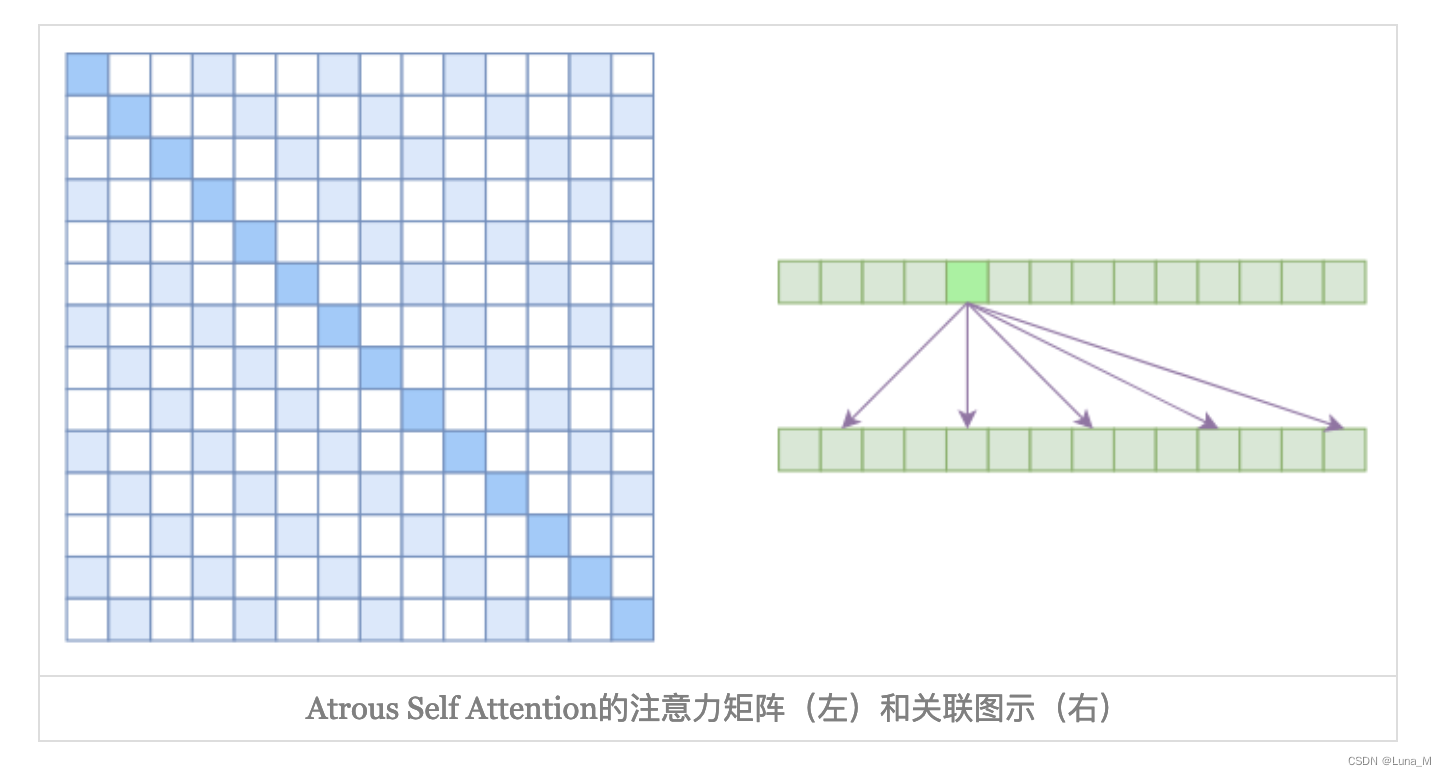
Atrous Self Attention就是启发于“膨胀卷积(Atrous Convolution)”,如下右图所示,它对相关性进行了约束,强行要求每个元素只跟它相对距离为k,2k,3k,…的元素关联,其中k>1是预先设定的超参数。
由于现在计算注意力是“跳着”来了,所以实际上每个元素只跟大约n/k个元素算相关性,这样一来理想情况下运行效率和显存占用都变成了 O ( n 2 / k ) O(n^2/k) O(n2/k),也就是说能直接降低到原来的1/k。
2. Local Self Attention
另一个要引入的过渡概念是Local Self Attention,中文可称之为“局部自注意力”。具体来说也很简单,就是约束每个元素只与前后k个元素以及自身有关联,如下图所示:
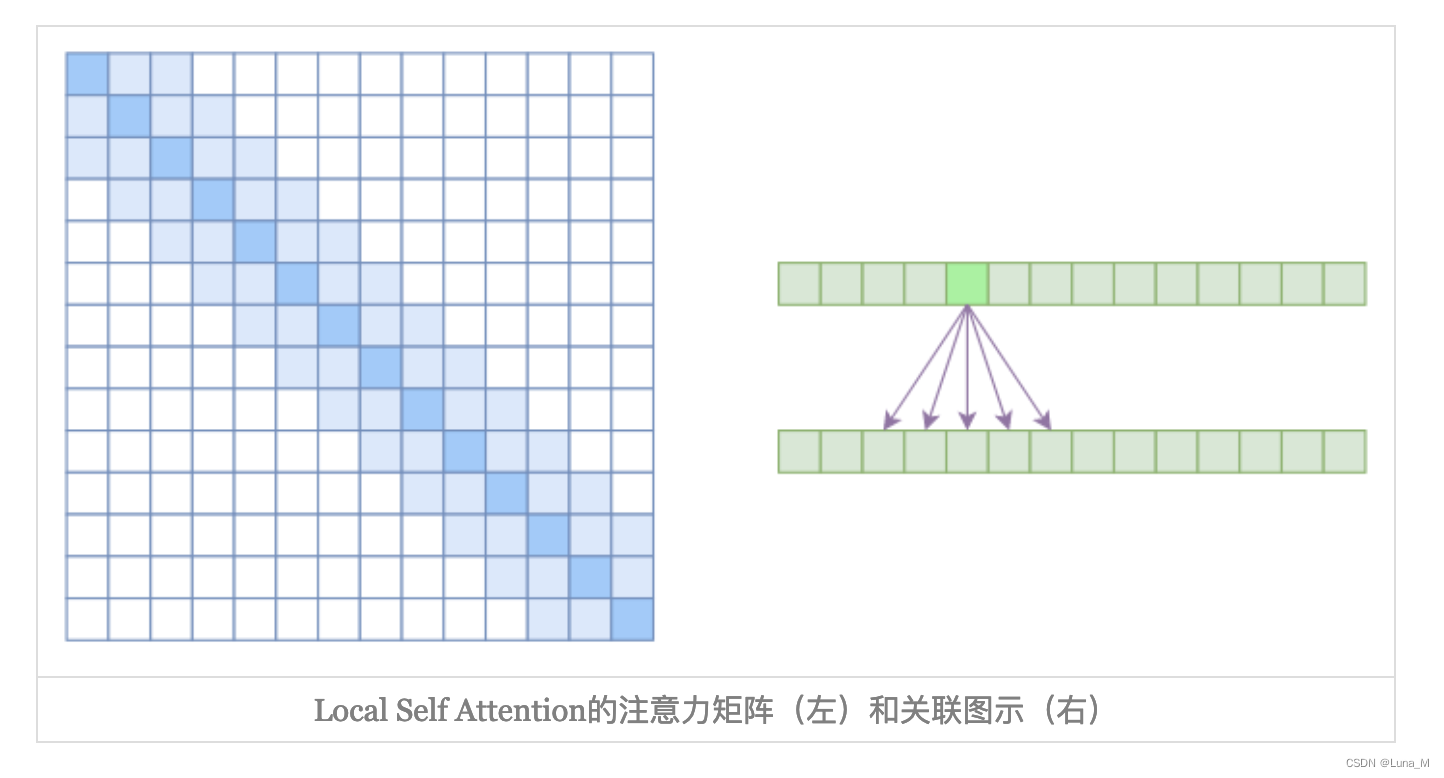
其实Local Self Attention就跟普通卷积很像了,都是保留了一个2k+1大小的窗口,然后在窗口内进行一些运算,不同的是普通卷积是把窗口展平然后接一个全连接层得到输出,而现在是窗口内通过注意力来加权平均得到输出。对于Local Self Attention来说,每个元素只跟2k+1个元素算相关性,这样一来理想情况下运行效率和显存占用都变成了𝒪((2k+1)n)∼𝒪(kn)了,也就是说随着n而线性增长,这是一个很理想的性质——当然也直接牺牲了长程关联性。
3. Sparse Self Attention
Atrous Self Attention是带有一些洞的,而Local Self Attention正好填补了这些洞,所以一个简单的方式就是将Local Self Attention和Atrous Self Attention交替使用,两者累积起来,理论上也可以学习到全局关联性,也省了显存。
直接将两个Atrous Self Attention和Local Self Attention合并为一个:
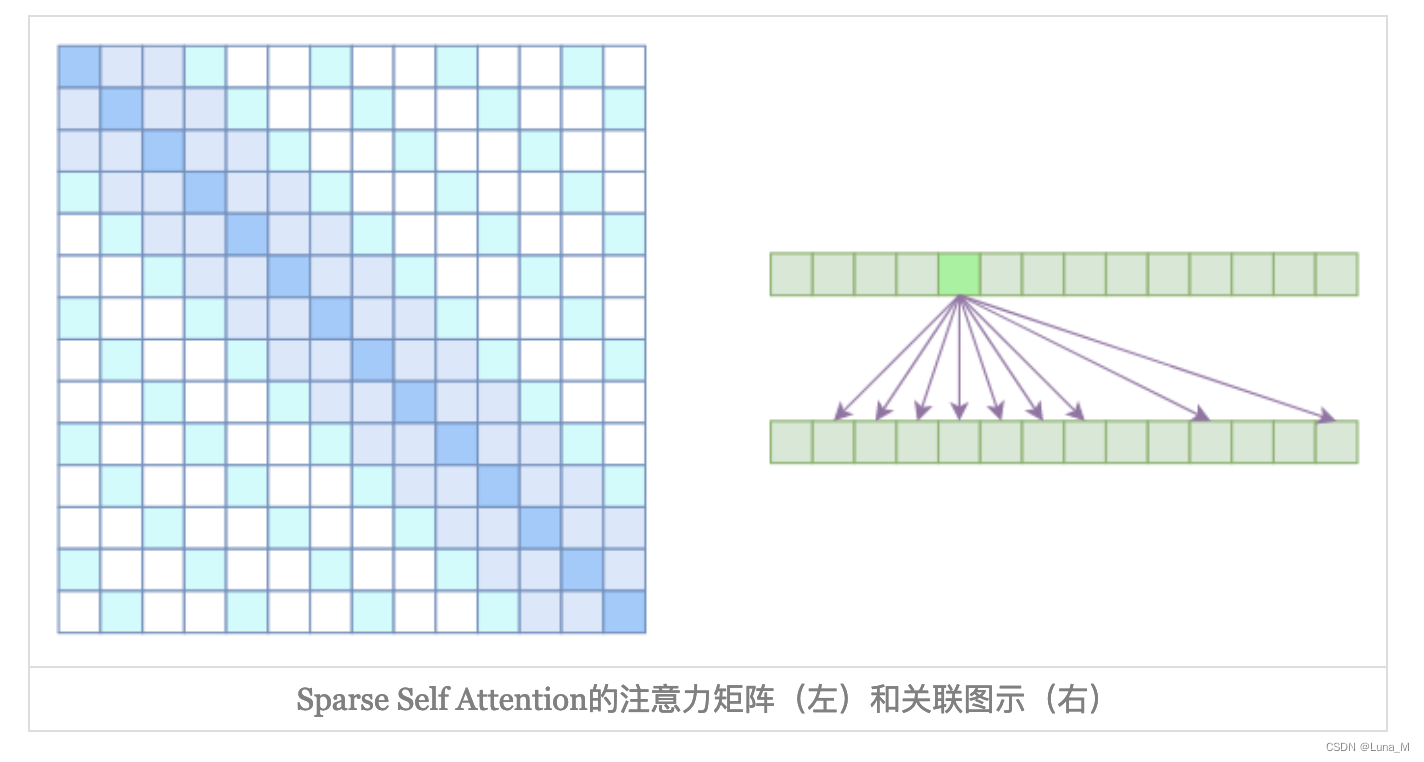 从注意力矩阵上看就很容易理解了,就是除了相对距离不超过k的、相对距离为k,2k,3k,…的注意力都设为0,这样一来Attention就具有“局部紧密相关和远程稀疏相关”的特性,这对很多任务来说可能是一个不错的先验,因为真正需要密集的长程关联的任务事实上是很少的。
从注意力矩阵上看就很容易理解了,就是除了相对距离不超过k的、相对距离为k,2k,3k,…的注意力都设为0,这样一来Attention就具有“局部紧密相关和远程稀疏相关”的特性,这对很多任务来说可能是一个不错的先验,因为真正需要密集的长程关联的任务事实上是很少的。
2. LLM数据处理关键
去重
重复数据、冲突数据识别
minHash、Kmeans
多样性保证
构造扩充数据
例如:表格问答 利用GPT4答案扩写
充分利用数据
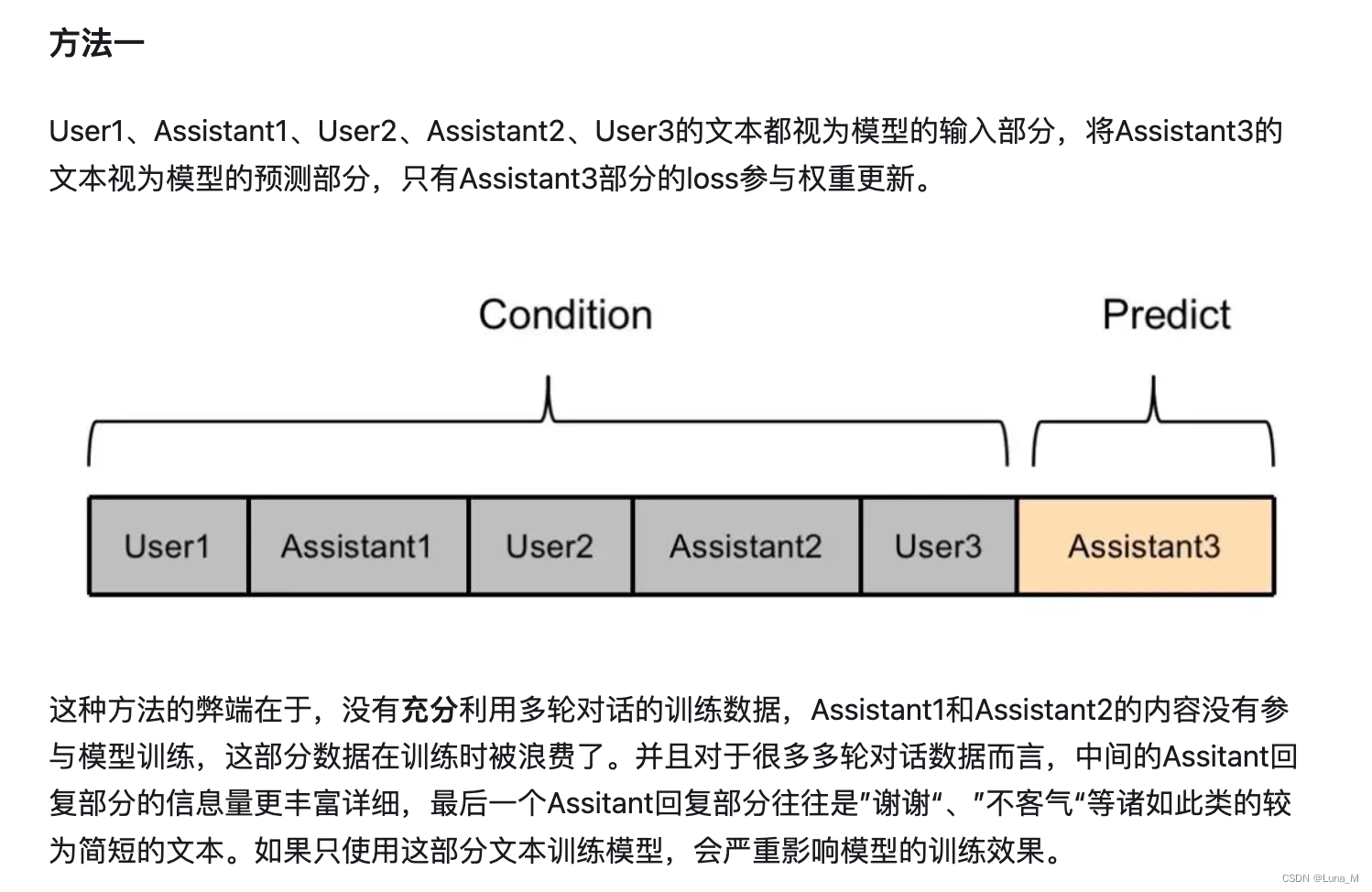
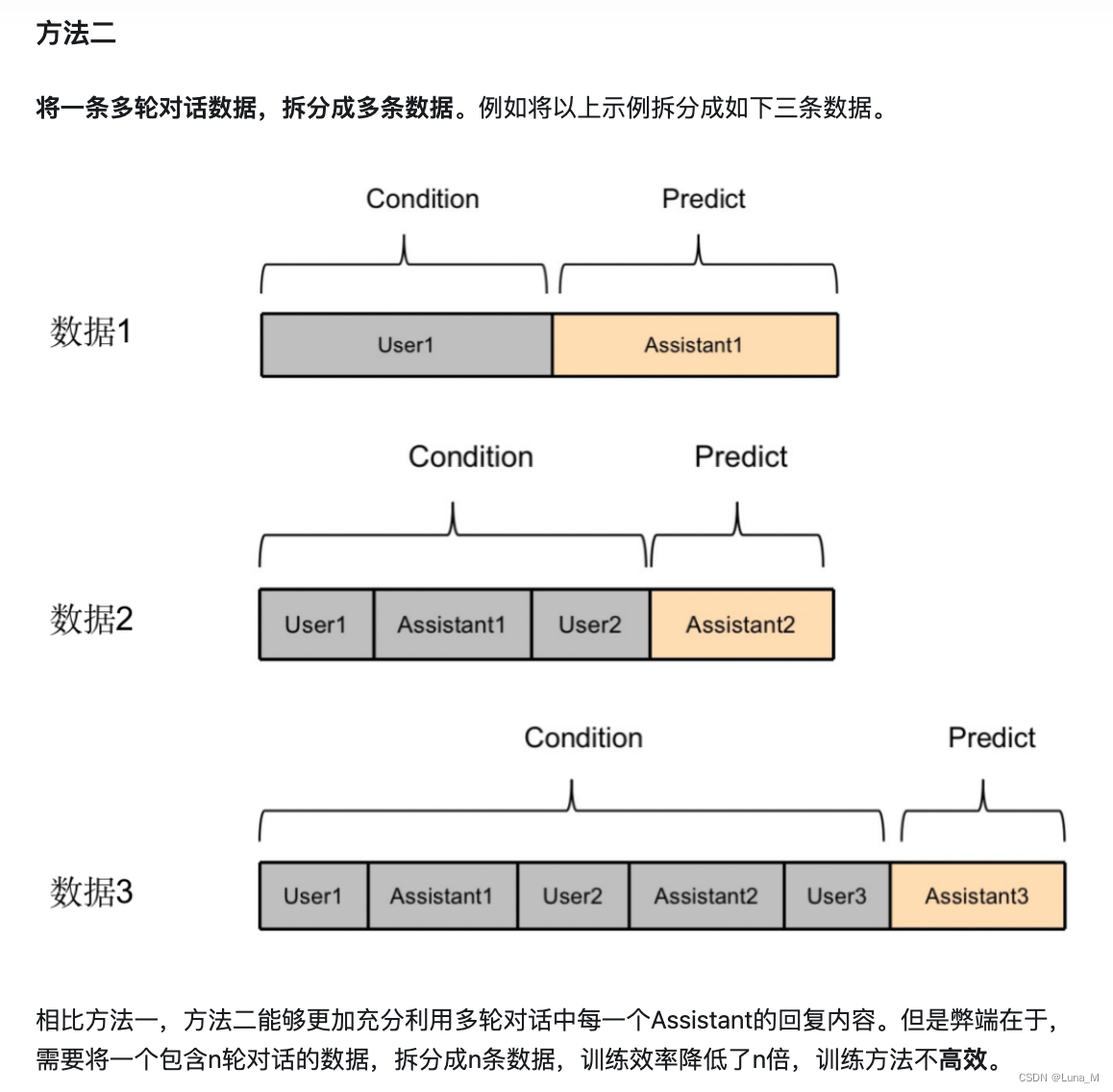
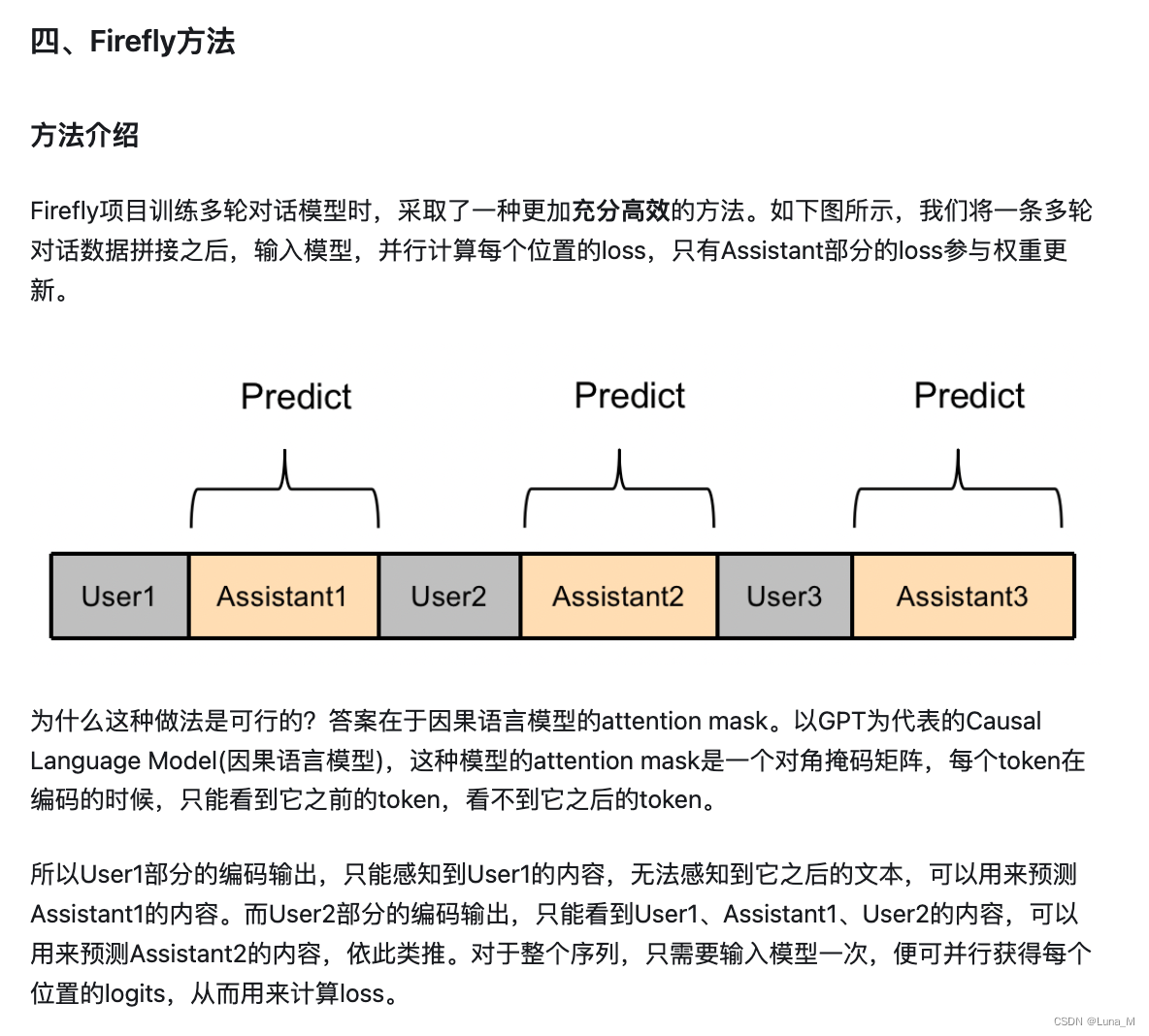
例如:多轮对话数据利用
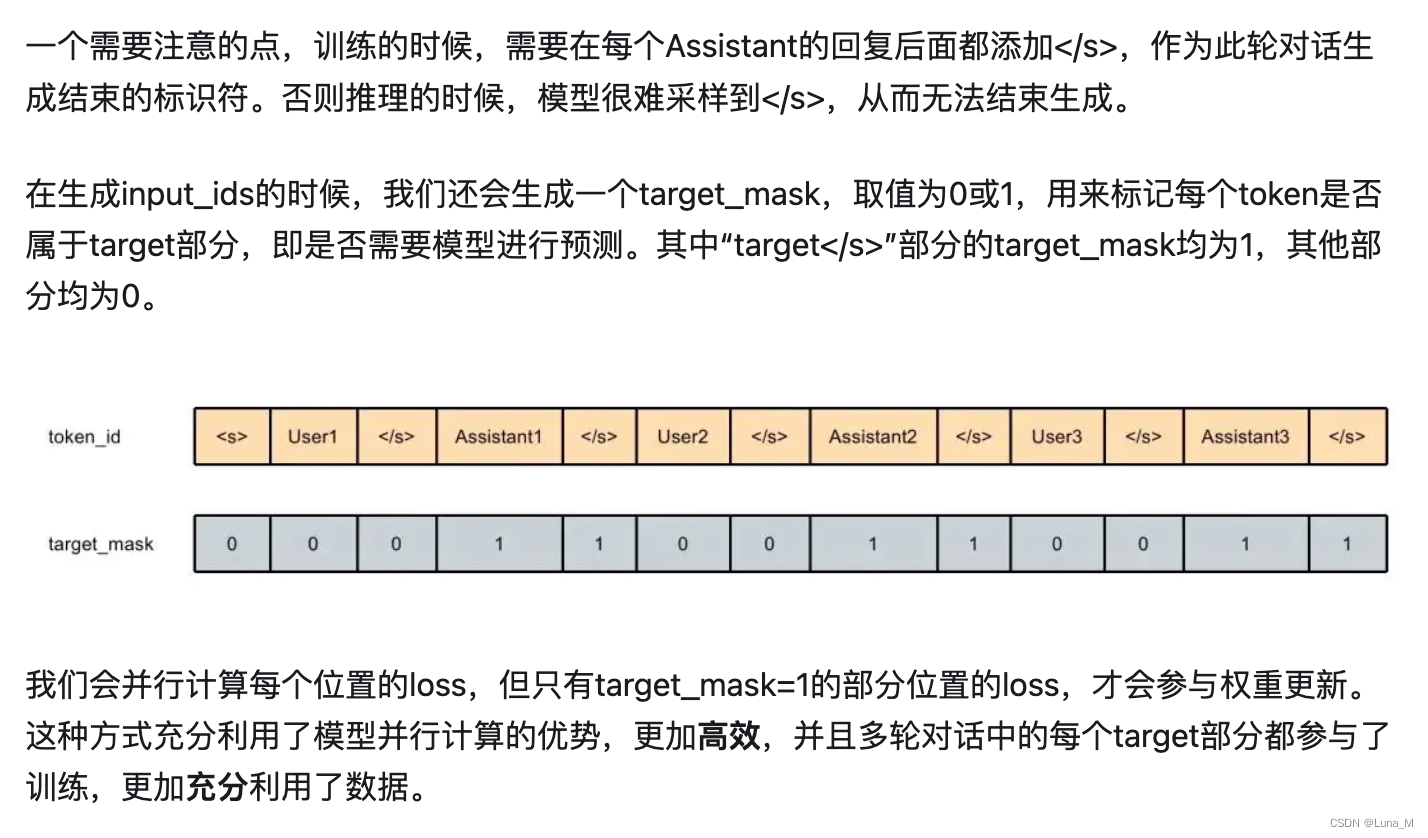

参考文献
看图学KV Cache
LLM推理优化技术综述
从标准Attention到稀疏Attention
如何充分高效训练多轮对话大模型
![[python:django]:web框架搭建项目](https://img-blog.csdnimg.cn/direct/193b5c513a904b28a648c3529dd8ddde.png)
![[蓝桥杯]真题讲解:合并数列(双指针+贪心)](https://img-blog.csdnimg.cn/direct/e26e6d2185fe4561bf107ed0eac4694f.png)
![YOLOv8训练流程-原理解析[目标检测理论篇]](https://img-blog.csdnimg.cn/direct/a358c400b05b45cca1d63ca631eab1fc.png)

![[C/C++] -- 大数的加减法](https://img-blog.csdnimg.cn/direct/211a7346d99a4fa09f3d1f286b1d8340.png)