在SCI论文中,我们不可避免和缺失数据打交道,特别是在回顾性研究,对于缺失的协变量(就是混杂因素),我们可以使用插补补齐数据,但是对于结局变量和原因变量的缺失,我们不能这么做。部分人的做法是直接删除掉这部分的数据(如SEER数据库),有些高分SCI杂志的审稿人会问你缺失数据的情况和你是怎么处理的,如果我们能附上一个缺失数据和未缺失数据比较的表格,可以起到一表抵千言万语的作用,如下图。
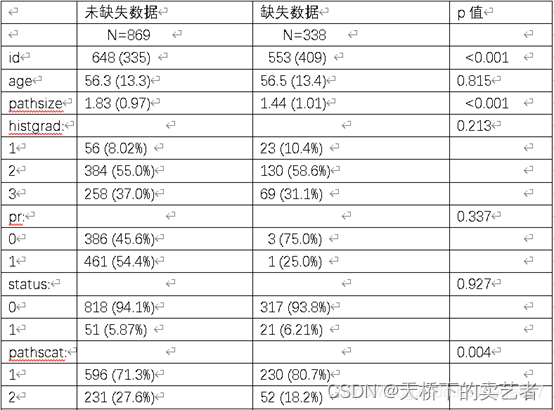
如表格所示,如果比较出缺失数据和未缺失数据P值大于0.05,说明数据为随机缺失,删除后对数据分布没有影响,但如果小于0.05,你删除这部分数据则要说明删除原因。
今天咱们视频演示一下如何R语言做出上面的表格
R言语处理数据中的缺失值
代码
library(foreign)
library("survival")
library(tidyverse)
library(compareGroups)
bc<-read.spss("E:/r/test/Breast cancer survival agec.sav",
use.value.labels=F, to.data.frame=T)
head(bc,10)
# age表示年龄,pathsize表示病理肿瘤大小(厘米),lnpos表示腋窝淋巴结阳性,histgrad表示病理组织学等级,
# er表示雌激素受体状态,pr表示孕激素受体状态,status结局事件是否死亡,pathscat表示病理肿瘤大小类别(分组变量),
# ln_yesno表示是否有淋巴结肿大,time是生存时间,后面的agec是我们自己设定的,不用管它。
#假设我们想知道er表示雌激素受体状态和结局死亡的关系,我们看到er还是有很多缺失值的,我们先要把这部分缺失值提出来
bc1<-bc%>%
mutate(
cancelled=is.na(er)
)
bc1$cancelled<-ifelse(bc1$cancelled=="TRUE",1,0)
##分类变量转成因子
bc1$lnpos <- factor(bc1$lnpos)
bc1$histgrad <- factor(bc1$histgrad)
bc1$pr <- factor(bc1$pr)
bc1$status<- factor(bc1$status)
bc1$pathscat<- factor(bc1$pathscat)
bc1$ln_yesno<- factor(bc1$ln_yesno)
bc1$cancelled<-factor(bc1$cancelled)
###生成表格
descrTable(cancelled~ .-er, data = bc1) ##要减掉er这个变量
# status: 0.927
# 0 818 (94.1%) 317 (93.8%)
# 1 51 (5.87%) 21 (6.21%)
#换个方式
descrTable(status~cancelled, data = bc1)
# cancelled: 0.927
# 0 818 (72.1%) 51 (70.8%)
# 1 317 (27.9%) 21 (29.2%)