CLUENER数据准备
data = []
with open("data/train.json", 'r') as f:
for line in f.readlines():
data.append(eval(line))
data

特征提取
import jieba
import jieba.posseg as pseg
def process(text, labels=None):
words = [i for i in text]
words_flags = pseg.cut(text)
flags = []
BME = []
for word, tag in words_flags:
flags += [tag] * len(word)
word_bme = ['M'] * len(word)
# word_bme[-1] = 'E'
word_bme[0] = 'B'
BME += word_bme
features = list(zip(words, flags, BME))
text_tag = None
if labels:
text_tag = ["O"] * len(text)
for ent_type in labels:
entities = labels[ent_type]
for entity in entities:
locs = entities[entity]
for loc in locs:
s,e = loc[0], loc[1]
for i in range(s+1, e+1):
text_tag[i] = "I-" + ent_type
text_tag[s] = "B-" + ent_type
return features, text_tag
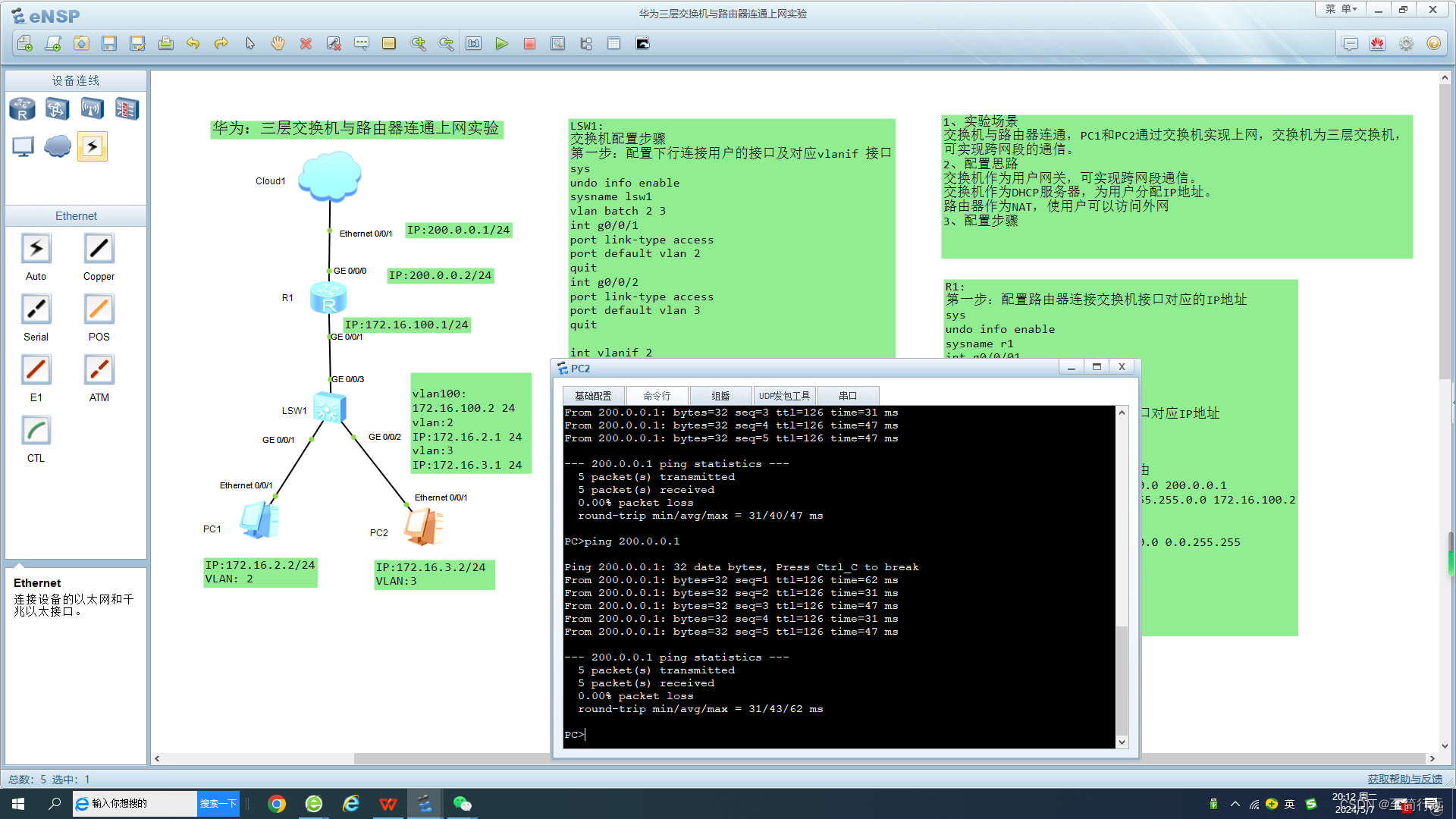
process("浙商银行企业信贷部叶老桂博士则从另一个角度对五道门槛进行了解读。")

特征提取,在单字的基础上,加了结巴分词给出的词性和是否分词起始位置
训练数据文件
from tqdm.notebook import tqdm
output = []
for d in tqdm(data):
text = d['text']
labels = d['label']
features, word_labels = process(text, labels)
for f, l in zip(features, word_labels):
output.append('\t'.join(f) + '\t' + l)
output.append('')
with open('train-crf.txt', 'w') as f:
for o in output:
f.write(o)
f.write('\n')
!head -n 100 train-crf.txt
CRF++ 模板
template = """# Unigram
U00:%x[-2,0]
U01:%x[-1,0]
U02:%x[0,0]
U03:%x[1,0]
U04:%x[2,0]
U001:%x[-1,0]/%x[0,0]
U002:%x[0,0]/%x[1,0]
U10:%x[-2,1]
U11:%x[-1,1]
U12:%x[0,1]
U13:%x[1,1]
U14:%x[2,1]
U111:%x[-2,1]/%x[-1,1]
U112:%x[-1,1]/%x[0,1]
U113:%x[0,1]/%x[1,1]
U114:%x[1,1]/%x[2,1]
U20:%x[-2,2]
U21:%x[-1,2]
U22:%x[0,2]
U23:%x[1,2]
U24:%x[2,2]
U221:%x[-2,2]/%x[-1,2]
U222:%x[-1,2]/%x[0,2]
U223:%x[0,2]/%x[1,2]
U224:%x[1,2]/%x[2,2]
U120:%x[-2,1]/%x[-2,2]
U121:%x[-1,1]/%x[-1,2]
U122:%x[0,1]/%x[0,2]
U123:%x[1,1]/%x[1,2]
U124:%x[2,1]/%x[2,2]
U12121:%x[-2,1]/%x[-2,2]/%x[-1,1]/%x[-1,2]
U12122:%x[-1,1]/%x[-1,2]/%x[0,1]/%x[0,2]
U12123:%x[0,1]/%x[0,2]/%x[1,1]/%x[1,2]
U12124:%x[1,1]/%x[1,2]/%x[2,1]/%x[2,2]
U1110:%x[-2,1]/%x[-1,1]/%x[0,1]
U1111:%x[-1,1]/%x[0,1]/%x[1,1]
U1112:%x[0,1]/%x[1,1]/%x[2,1]
# Bigram
B
"""
with open("crf-template.txt", 'w') as f:
f.write(template)
crf_learn 参数
>>> crf_learn -h
CRF++: Yet Another CRF Tool Kit
Copyright (C) 2005-2013 Taku Kudo, All rights reserved.
Usage: crf_learn [options] files
-f, --freq=INT use features that occuer no less than INT(default 1)
-m, --maxiter=INT set INT for max iterations in LBFGS routine(default 10k)
-c, --cost=FLOAT set FLOAT for cost parameter(default 1.0)
-e, --eta=FLOAT set FLOAT for termination criterion(default 0.0001)
-C, --convert convert text model to binary model
-t, --textmodel build also text model file for debugging
-a, --algorithm=(CRF|MIRA) select training algorithm
-p, --thread=INT number of threads (default auto-detect)
-H, --shrinking-size=INT set INT for number of iterations variable needs to be optimal before considered for shrinking. (default 20)
-v, --version show the version and exit
-h, --help show this help and exit
开始训练
!crf_learn -f 3 -e 0.001 crf-template.txt train-crf.txt ./crf-model
CRF++: Yet Another CRF Tool Kit
Copyright (C) 2005-2013 Taku Kudo, All rights reserved.
reading training data: 100.. 200.. 300.. 400.. 500.. 600.. 700.. 800.. 900.. 1000.. 1100.. 1200.. 1300.. 1400.. 1500.. 1600.. 1700.. 1800.. 1900.. 2000.. 2100.. 2200.. 2300.. 2400.. 2500.. 2600.. 2700.. 2800.. 2900.. 3000.. 3100.. 3200.. 3300.. 3400.. 3500.. 3600.. 3700.. 3800.. 3900.. 4000.. 4100.. 4200.. 4300.. 4400.. 4500.. 4600.. 4700.. 4800.. 4900.. 5000.. 5100.. 5200.. 5300.. 5400.. 5500.. 5600.. 5700.. 5800.. 5900.. 6000.. 6100.. 6200.. 6300.. 6400.. 6500.. 6600.. 6700.. 6800.. 6900.. 7000.. 7100.. 7200.. 7300.. 7400.. 7500.. 7600.. 7700.. 7800.. 7900.. 8000.. 8100.. 8200.. 8300.. 8400.. 8500.. 8600.. 8700.. 8800.. 8900.. 9000.. 9100.. 9200.. 9300.. 9400.. 9500.. 9600.. 9700.. 9800.. 9900.. 10000.. 10100.. 10200.. 10300.. 10400.. 10500.. 10600.. 10700..
Done!4.97 s
Number of sentences: 10748
Number of features: 1912554
Number of thread(s): 40
Freq: 3
eta: 0.00100
C: 1.00000
shrinking size: 20
iter=0 terr=0.99280 serr=1.00000 act=1912554 obj=1223179.51267 diff=1.00000
iter=1 terr=0.26686 serr=1.00000 act=1912554 obj=641377.87041 diff=0.47565
iter=2 terr=0.26686 serr=1.00000 act=1912554 obj=662774.14395 diff=0.03336
iter=3 terr=0.26686 serr=1.00000 act=1912554 obj=492583.32670 diff=0.25679
iter=4 terr=0.26686 serr=1.00000 act=1912554 obj=479412.24836 diff=0.02674
iter=5 terr=0.26686 serr=1.00000 act=1912554 obj=441358.40268 diff=0.07938
iter=6 terr=0.26702 serr=1.00000 act=1912554 obj=403504.00220 diff=0.08577
iter=7 terr=0.26450 serr=0.99935 act=1912554 obj=363372.27884 diff=0.09946
iter=8 terr=0.25407 serr=0.99423 act=1912554 obj=319318.95629 diff=0.12123
iter=9 terr=0.25369 serr=0.99181 act=1912554 obj=294240.56337 diff=0.07854
iter=10 terr=0.25344 serr=0.98986 act=1912554 obj=253903.96828 diff=0.13709
iter=11 terr=0.26491 serr=0.97125 act=1912554 obj=234504.88076 diff=0.07640
iter=12 terr=0.24329 serr=0.97144 act=1912554 obj=218156.27505 diff=0.06972
iter=13 terr=0.24345 serr=0.97441 act=1912554 obj=209718.44064 diff=0.03868
iter=14 terr=0.24626 serr=0.97274 act=1912554 obj=198188.60816 diff=0.05498
iter=15 terr=0.24575 serr=0.97609 act=1912554 obj=184293.09969 diff=0.07011
...
iter=321 terr=0.02049 serr=0.22079 act=1912554 obj=14981.64606 diff=0.00024
iter=322 terr=0.02009 serr=0.22041 act=1912554 obj=14957.42015 diff=0.00162
iter=323 terr=0.01992 serr=0.21920 act=1912554 obj=14933.93002 diff=0.00157
iter=324 terr=0.01971 serr=0.21706 act=1912554 obj=14918.42218 diff=0.00104
iter=325 terr=0.02012 serr=0.21948 act=1912554 obj=14914.71563 diff=0.00025
iter=326 terr=0.01983 serr=0.21809 act=1912554 obj=14903.42455 diff=0.00076
iter=327 terr=0.01968 serr=0.21706 act=1912554 obj=14894.01060 diff=0.00063
Done!11985.11 s
验证集
datadev = []
with open("data/dev.json", 'r') as f:
for line in f.readlines():
datadev.append(eval(line))
output = []
for d in tqdm(datadev):
text = d['text']
labels = d['label']
features, word_labels = process(text, labels)
for f, l in zip(features, word_labels):
output.append('\t'.join(f) + '\t' + l)
output.append('')
with open('dev-crf.txt', 'w') as f:
for o in output:
f.write(o)
f.write('\n')
!head -n 100 dev-crf.txt
import os
os.system("crf_test -m crf-model dev-crf.txt > dev_result.txt")
pred, labels = [], []
with open('dev_result.txt', 'r') as f:
for i in f.readlines():
if len(i.strip()) > 0:
elements = i.strip().split('\t')
pred.append(elements[-1])
labels.append(elements[-2])
from seqeval.metrics import classification_report
print(classification_report([labels], [pred]))
precision recall f1-score support
address 0.53 0.49 0.51 373
book 0.77 0.60 0.67 154
company 0.76 0.72 0.74 378
game 0.79 0.81 0.80 295
government 0.77 0.76 0.76 247
movie 0.70 0.66 0.68 151
name 0.77 0.76 0.76 465
organization 0.79 0.70 0.75 367
position 0.81 0.71 0.76 433
scene 0.62 0.46 0.53 209
micro avg 0.74 0.68 0.71 3072
macro avg 0.73 0.67 0.70 3072
weighted avg 0.74 0.68 0.71 3072
pipeline
class Pipeline:
def __init__(self, model, feature_func):
self.model = model
self.process = feature_func
import os
os.environ['LD_LIBRARY_PATH'] = '/usr/local/lib/'
def __call__(self, text, ):
features, _ = self.process(text)
output = []
for f in features:
output.append('\t'.join(f))
output.append('')
temp_file = 'temp-text.txt'
with open(temp_file, 'w') as f:
for o in output:
f.write(o)
f.write('\n')
temp_result = 'predict.txt'
os.system(f"crf_test -m {self.model} {temp_file} > {temp_result}")
with open(temp_result, 'r') as f:
res = f.read()
res = res.strip().split('\n')
res = [i.split('\t') for i in res]
features = [i[-1].split('-')[0] for i in res]
entities = [i[-1].split('-')[-1] for i in res]
tags = ''.join(features)
pattern = re.compile('BI*')
ne_label = re.finditer(pattern, tags)
ne_list = []
for ne in ne_label:
start, end = int(ne.start()), int(ne.end())
entity = entities[start]
ne_list.append({
"word": ''.join(text[start: end]),
"start": start,
"end": end,
"entity_group": entity
})
return ne_list
pipe = Pipeline('crf-model', process)