文章目录
- 一、软件体系结构概述
- 1.1 基本概念
- 1.1.1 背景
- 1.1.2 定义
- 1.1.3 系统
- 1.1.3.1 定义
- 1.1.3.2 特性
- 1.1.3.3 系统的体系结构
- 1.1.4 软件设计的层次性
- 1.1.5 体系结构的类别(类型)
- 1.1.6 重要性(意义)
- 1.2 模块及其设计
- 1.2.1 定义
- 1.2.2 模块的内聚性
- 1.2.2.1 含义
- 1.2.2.2 内聚性的层次
- 1.2.2.3 偶然内聚性
- 1.2.2.4 逻辑内聚性
- 1.2.2.5 暂时内聚性
- 1.2.2.6 过程内聚性
- 1.2.2.7 通信内聚性
- 1.2.2.8 信息内聚性
- 1.2.2.9 功能内聚性
- 1.2.3 模块的耦合性
- 1.2.3.1 含义
- 1.2.3.2 耦合的级别
- 1.2.3.3 内容耦合
- 1.2.3.4 共用耦合
- 1.2.3.5 控制耦合
- 1.2.3.6 特征耦合
- 1.2.3.7 数据耦合
- 1.2.4 模块的重用
- 1.2.4.1 定义
- 1.2.4.2 重用的类型
- 1.2.4.3 构建重用
- 1.2.4.4 重用的障碍
- 1.2.5 模块的重要性(意义)
- 1.3 软件工程
- 1.3.1 软件危机
- 1.3.1.1 背景
- 1.3.1.2 定义
- 1.3.1.3 人月神话
- 1.3.1.4 没有银子弹
- 1.3.1.5 有一个银子弹
- 1.3.2 软件工程的复杂性
- 1.3.2.1 建筑工程的经验对软件工程的启发
- 1.3.2.2 软件工程的复杂性
- 1.3.3 软件工程的内容
- 1.4 软件体系结构的意义与目标
- 1.4.1 软件体系结构的意义
- 1.4.2 软件体系结构的目标
- 1.5 软件体系结构的研究现状
- 1.5.1 软件体系统结构的发展
- 1.5.2 软件体系统结构的研究现状
- 1.6 习题
- 二、软件体系结构风格
- 2.1 什么是软件体系结构风格
- 2.1.1 什么是结构风格
- 2.1.2 结构风格的分类
- 2.2 常用结构风格
- 2.2.1 管道/过滤器(Pipes and Filters,P/F)
- 2.2.1.1 系统组织
- 2.2.1.2 评价
- 2.2.2 数据抽象与面向对象组织(Data abstraction and Object-oriented Organization)
- 2.2.2.1 系统组织
- 2.2.2.2 评价
- 2.2.3 事件及隐含激活(Event-Based, Implicit Inovaations)
- 2.2.3.1 系统组织
- 2.2.3.2 评价
- 2.2.4 层次系统(Layers Systems)
- 2.2.4.1 系统组织
- 2.2.4.2 评价
- 2.2.5 仓库(Repositories)
- 2.2.5.1 系统组织
- 2.2.6 解释器(Interpreters)
- 2.2.6.1 系统组织
- 2.3 其他结构风格
- 2.4 案例分析
- 2.4.1 问题描述
- 2.4.2 解决方案
- 2.4.2.1 主程序/子过程调用(Main program/subroutine)
- 2.4.2.2 数据抽象与面向对象组织(Data abstraction and Object-oriented Organization)
- 2.4.2.3 事件及隐含激活(Event-Based, Implicit Inovaations)
- 2.4.2.4 管道/过滤器(Pipes and Filters,P/F)
- 2.5 习题
- 三、分布式体系结构分析
- 3.1 分布式处理结构风格概述
- 3.1.1 系统组织
- 3.1.2 分布式处理结构风格的优缺点
- 3.1.2.1 优点
- 3.1.2.2 缺点
- 3.1.3 构造分布式处理结构风格的主要技术
- 3.2 分布式系统
- 3.2.1 分布式系统是计算机发展的必然产物
- 3.2.2 集中式系统和分布式系统
- 3.2.2 分布式系统的优点
- 3.2.3 分布式系统的不足
- 3.3 客户/服务器(Client/Server)结构
- 3.3.1 C/S结构
- 3.3.2 C/S模型的软件结构的特点
- 3.3.3 C/S模型的工作过程
- 3.3.4 数据共享的方式
- 3.3.5 C/S的连接
- 3.3.6 C/S的服务器设计、实现关键
- 3.3.7 C/S案例
- 3.3.7.1 文件服务器的设计
- 3.3.7.2 文件服务器的C语言实现(部分)
- 四、分布式体系结构关键技术
- 4.1 基于消息传递的通信(分布式进程的通信)
- 4.1.1 发送操作(send primitive)
- 4.1.2 接发操作(receive primitive)
- 4.1.3 阻塞(Blocking)操作
- 4.1.4 非阻塞操作(Nonblocking primitive)
- 4.1.5 非缓冲操作(unbuffered primitives)
- 4.1.6 缓冲通信操作-信箱(mailbox)
- 4.1.7 不可靠(Unreliable)操作
- 4.1.8 可靠(Reliable)操作
- 4.2 远程过程调用(RPC)
- 4.2.1 RPC概述
- 4.2.1.1 RPC的基本思想
- 4.2.1.2 RPC例子
- 4.2.2 RPC的透明性(transparent)
- 4.2.2.1 RPC透明性
- 4.2.2.1 RPC透明性的实现
- 4.2.3 参数传递(Parameter Passing)
- 4.2.4 动态联编(Dynamic Binding)
- 4.2.5 RPC表示错误的语义(Semantics in the Presence of Failures)
- 4.2.6 RPC的实现
- 4.2.6.1 RPC协议是选择面向连接的还是非连接的协议
- 4.2.6.2 RPC协议是选择标准通用的还是RPC专用的协议
- 4.2.6.3 确认机制(Acknowledgement)
- 4.2.6.4 流量控制(flow control)
- 4.2.6.5 临界路径(critical path)
- 4.2.6.6 定时管理(timer)
- 4.2.7 RPC与消息传递通信的比较
- 4.3 分布式同步算法
- 4.3.1 逻辑时钟(Logical Clocks)
- 4.3.2 Lamport 算法
- 4.4 分布式互斥算法
- 4.4.1 集中式算法
- 4.4.2 Ricart & Agrawala's算法
- 4.4.3 令牌环算法(Token Ring)
- 4.4.4 三种算法的比较
- 4.5 分布式系统的可靠性
- 4.5.1 选择算法(Elect Algoriathms)
- 4.5.2 k-容错技术
- 4.5.3 表决算法(voting algorithm)
- 4.6 习题
- 五、层次结构分析
- 5.1 线程技术
- 5.1.1 引入线程的目的
- 5.1.2 线程的概念
- 5.1.3 线程与进程的区别、联系
- 5.1.4 线程的分类
- 5.1.5 线程的执行特性
- 5.1.6 线程的应用
- 5.2 服务器缓冲技术
- 5.2.1 无状态信息(Stateless)服务器
- 5.2.2 有状态信息(State)服务器
- 5.2.3 无状态服务器与有状态服务器的比较
- 5.3 N层结构的特性
- 5.3.1 层次结构设计
- 5.3.2 软件系统的层次结构
- 5.4 N层结构的实现
- 5.5 N层结构的优缺点
- 5.6 一个用于构造分布式系统的层次结构设计
- 5.6.1 表示层——用户界面技术
- 5.6.2 业务逻辑层——应用系统的核心
- 5.6.3 数据逻辑访问层(DAL)
- 5.6.4 数据层
- 5.7 习题
- 六、CORBA技术及应用实例(了解即可)
- 6.1 CORBA概述
- 6.2 CORBA特性
- 6.2.1 OMG接口定义语言(IDL)
- 6.2.2 语言映射
- 6.2.3 操作调用和调度软件
- 6.2.4 对象适配器(Object Adapter)
- 6.2.5 内部ORB协议
- 6.3 CORBA应用程序的一般开发过程
- 6.4 CORBA的基本服务
- 6.4.1 命名服务(Naming Service)
- 6.4.2 交易服务(Trading Service)
- 6.4.3 事件服务(Event Service)
- 七、结构设计空间及其量化
- 7.1 设计空间和规则(design space and rule)
- 7.1.1 设计空间(design space)
- 7.1.2 维(Deimension)
- 7.1.3 设计规则(design rule)
- 7.1.4 设计知识库(design vocabulary)
- 7.1.5 一个设计空间的例子
- 7.2 用户接口结构(user-interface architecture)设计
- 7.2.1 用户接口结构的设计空间
- 7.2.1.1 基本结构模型(a basic structure model)
- 7.2.1.2 功能维例子(sample functional dimensions)
- 7.2.1.3 结构维例子(sample structure dimensions)
- 7.2.2 用户接口结构的设计规则
- 7.3 量化设计空间(Quantified Design Space,QDS)【重点】
- 7.3.1 简介
- 7.3.1.1 质量配置函数(QFD)
- 7.3.2 量化设计空间(QDS)
- 7.4 习题
- 八、软件体系结构描述
- 8.1 软件体系结构形式化的意义
- 8.2 软件体系结构描述的方法
- 8.2.1 主程序和子过程
- 8.2.2 数据抽象和面向对象设计
- 8.2.3 Category Theory(类属理论)
- 8.3 Z Notation简介
- 8.3.1 什么是形式规范(formal specifications)
- 8.3.2 Z notation的思想
- 8.3.3 声明(Declarations)
- 8.3.4 Schema texts
- 8.3.5 Predicates
- 九、J2EE体系结构分析及应用(了解即可)
- 十、区块链技术(补充)
- 10.1 基本概念
- 10.2 区块链在“数据追溯”方面的应用案例
- 10.3 区块链在“共享经济”方面的应用案例
一、软件体系结构概述
1.1 基本概念
1.1.1 背景
现在,计算机软件工业界面临着巨大的挑战:对于日益复杂的需求和运行环境,如何生产一个灵活、高效的软件系统。
随着软件系统的规模和复杂性的增加,软件结构的设计和规范变得越来越重要。对于一个小的程序,人们可以集中考虑其算法选择和数据结构的设计,以及使用哪一种的代码设计语言,可是,对于一个大的系统,软件的结构就显得更重要了,比如,系统由哪些组件(component)构成、组件间的关系如何、每个组件应完成的功能、组件运行的物理位置、如何通讯、同步/异步、数据访问等,这些内容就体现了软件系统结构的思想。
1.1.2 定义
- 一个软件系统的体系结构是指构成这个系统的计算部件、部件间的相互作用关系。
- 部件可以是客户(clients)、服务器(servers)、数据库(databases)、过滤器(filters) 、层等。
- 部件间的相互作用关系(即连接器)可以是过程调用(procedure call)、客户/服务器、同步/异步、管道流(piped stream)等.
1.1.3 系统
1.1.3.1 定义
系统概念是系统理论的最基本的概念,它浓缩和概括了系统理论的最基本内容,然而,由于研究领域的不同、应用对象和理解角度的不同,对系统概念的定义也有不同,尚未有一个统一的定义。
我国著名科学家钱学森认为“系统即由相互作用和相互依赖的若干部分(要素)结合成的具有特定功能的有机的整体,而且这个系统本身又是它所从属的一个更大系统的组成部分”
1.1.3.2 特性
- 集合性
系统由两个或两个以上的可以区别的相互区别的要素(对象)组成。 - 相关性
系统中,各个要素之间具有相互依赖、 相互作用的关系。 - 结构性
系统中,各个要素不是简单的排列,而是有一定的组成形式即结构。相同的几个要素,如果组织的结构不同,将构成不同的系统。 - 整体性
系统中各个要素根据特定的统一要求,共同协作,对外形成个整体。 - 功能性
各个要素完成特定的功能,它们的相互作用完成系统的功能,但系统的功能并不是它的各部分的功能的线性和,具有“整体大于各部分之和” - 环境适应性
任何一个系统都存在于一定的环境之中,受外界的影响,具有开放性。
1.1.3.3 系统的体系结构
- 系统中各要素的组织方式和相互作用方式。
- 常用的有整体性结构、层次结构等
1.1.4 软件设计的层次性
- 结构级
包括与部件相关联的系统的总体性能,部件是指模块,模块的相互关联通过多种方法处理。 - 代码级
包括算法和数据结构的选择,部件指程序语言中的数值、字符、指针等,相互关联是程序中的各种操作,合成如记录、数组、过程等。 - 执行级
包括存储器的映射、数据格式设置、堆栈和寄存器的分配等,部件是指硬件提供的位(bit)模式,相互关联由代码描述。
以前,软件开发人员注意力主要集中在程序语言的层次上,现在,软件的代码和执行层次的问题已经得到很好的解决,而对结构级的理解一直都还停留在直觉和经验上,尽管一个软件系统通常都有文字和图表的说明,但所使用的句法和所表达语义的解释从来没有得到统一。而软件体系结构将在软件的较高层研究软件系统的部件组成和部件间的关系。
1.1.5 体系结构的类别(类型)
服务于软件开发的不同阶段,体系结构可分为
- 概略型
是上层宏观结构的描述,反映系统最上层的部件和连接关系。 - 需求型
对概略型体系结构的深入表达,以满足用户功能和非功能的需求。 - 设计型
从设计实现的角度对需求结构的更深层的描述,设计系统的各个部件,描述各部件的连接关系。这是软件系统结构的主要类别。
1.1.6 重要性(意义)
体系结构的重要性在于它决定一个系统的主体结构、基本功能和宏观特性,是整个软件设计成功的基础,其重要性表现为在项目的:
- 规划阶段
粗略的体系结构是进行项目可行性研究、工程复杂性分析、工程进度计划、投资规模预算、风险预测等的重要依据。 - 需求阶段
在需求分析阶段,需要从项目需求从发,建立更深入的体系结构,这时体系结构成为开发商与用户之间进行需求交互的表达形式,也是交互所产生的结果,通过它,可以准确地表达用户的需求,以及出对应需求的解决方案,并考察系统的各项性能。 - 设计阶段
需要从实现的角度,对体系结构进行更深入的分解和描述。部件的组成、各部件的功能、部件的位置、部件间的连接关系选择等的描述。 - 实施阶段
体系结构的层次和部件是建立人员的组织、分工、协调开发人员等的依据。 - 测评阶段
体系结构是系统性能测试和评价的依据。 - 维护阶段
对软件的任何扩充和修改都需要在体系结构的指导下进行,以维持整体设计的合理性和正确性以及性能的可分析性,并为维护升级和复杂性和代价分析提供依据。
1.2 模块及其设计
1.2.1 定义
- 模块(module)是由一个或多个相邻的程序语句组成的集合。每个模块有一个名字,系统的其他部分可以通过这个名字来调用该模块。
- 模块是一个独立的代码,能够按过程、函数或方法调用方式调用它。
- 宏不是模块,过程、函数是模块,对象是模块,对象内的方法也是模块。
- 一个软件产品可以分解成一些较小的模块。
- 一个好的模块设计应该使模块具有高内聚性和低耦合性。
1.2.2 模块的内聚性
1.2.2.1 含义
模块内聚性是指一个模块内相互作用的程度。
1.2.2.2 内聚性的层次
- 偶然内聚性(不好)
- 逻辑内聚性
- 暂时内聚性
- 过程内聚性
- 通信内聚性
- 信息内聚性
- 功能内聚性(好)
1.2.2.3 偶然内聚性
如果一个模块执行多个完全不相关的动作,那么这个模块就有偶然内聚性。例如,一个模块在一个列表中增加一个新的项或删除一个指定的项。【许多不同类的功能都写在一个模块里面】
具有偶然内聚性的模块有两个严重的缺点:一是在改正性维护和完善性维护方面,这些模块降低了产品的可维护性;二是这些模块不能重用。
造成的原因:“每个模块由35-50个可执行语句组成。”,将两个或多个不相关的小模块不得不组合在一起,从而产生一个具有偶然内聚性的大模块。另外,从管理角度认为在太大的模块内被分割出来的部分将来要组合在一起。
1.2.2.4 逻辑内聚性
当一个模块执行一系列相关的动作,且其中一个动作是作为其他动作选择模块,称其有逻辑内聚性。例如,一个执行对主文件记录进行插入编辑、删除编辑和修改编辑操作的模块;【一类功能写在一个模块里面】
一个模块有逻辑内聚性会带来两个问题:其一,接口部分难于理解,其二,多个动作的代码可能会缠绕在一起,从而导致严重的维护问题,甚至难于在其他产品中重用这样的模块。
1.2.2.5 暂时内聚性
当一个模块执行在时间上相关的一系列动作时,称其具有暂时内聚性。例如,在一个执行销售管理的初始化模块中,其动作有:打开一个输入文件,一个输出文件、一个处理文件,初始化销售地区表,并读入输入文件的第一条记录和处理文件的第一条记录。这个模块的各个动作之间的相互关系是弱的,但是却与其他模块中的动作有更强的联系,就销售地区表来说,它在这个模块中初始化,而更新销售地区表和打印销售地区表这样动作是在其他模块中,因此,如果销售地区表的结构改变了,则若干模块将被改变,这样不仅可能有回归的错误(由于对产品的明显不相关的部分的改变而引起的错误),而且如果被影响的模块的数量很大时,则很可能会忽略一二个模块。而较好的作法是将有关销售地区表的所有操作放入一个模块。【一段时间内的功能写一个模块】
暂时内聚性的模块的缺点:一是降低了产品的可维护性;二是这些模块难以在其他产品中重用。
1.2.2.6 过程内聚性
一个模块有过程内聚性,是指其执行与产品的执行序列相关的一系列动作。比如,从数据库中读出部分数据,然后更新日志文件中的维护记录。过程中的动作有一定的联系,但这种关系也还是弱的。【一个过程写一个模块】
这种模块比暂时内聚性模块有好些,但仍难以重用。
1.2.2.7 通信内聚性
一个模块有通信内聚性,是指其执行与产品的执行序列相关的一系列动作,并且所有动作在相同数据上执行。【一个类写一个模块】
这种模块比过程内聚性模块有好些因为其动作有紧密的联系,但仍难以重用。
1.2.2.8 信息内聚性
如果一个模块执行一系列动作,每一动作有自己的入口点,每一个动作有自己的代码,所有的动作在相同的数据结构上执行,这样的模块称其为信息内聚性模块。【一个接口写一个模块】
对于面向对象的范型来说,信息内聚性是最理想的。信息内聚性的模块本质上是抽象数据类型的实现,而对象本质上就是抽象数据类型的一个实例。
拥有抽象数据结构的优点。
1.2.2.9 功能内聚性
一个只执行一个动作或只完成单个目标的模块有功能内聚性。【一个功能一个模块】
一个有功能内聚性的模块可能经常被重用。因为它执行的那个动作经常需要在其他产品中执行。一个经过适当设计、彻底测试的并且具有良好文档的内聚性模块对一个软件组织来说是一个有价值的资产,应该尽可能多地重用。
具有功能内聚性的模块也比较容易维护。首先,功能内聚有利于错误隔离;另外因为比普通的模块更容易理解从而简化了维护;同时还便于扩充(简单也抛弃旧模块用一个新模块来代替)。
1.2.3 模块的耦合性
1.2.3.1 含义
模块耦合是指模块间的相互作用程度。
1.2.3.2 耦合的级别
- 内容耦合(不好)
- 共用耦合
- 控制耦合
- 特征耦合
- 数据耦合(好)
1.2.3.3 内容耦合
如果一个模块p直接引用另一个模块q的内容,则模块p和q是内容耦合的。比如,模块p分支转向模块q的局部标号。【两个模块代码杂糅】
在产品中,内容耦合是危险的,因为它们是不可分割的,模块q的改变,都需要对模块p进行相应的改变,并且,在新产品中,如果不重用模块q,则不可能重用模块p。
1.2.3.4 共用耦合
如果两个模块都能访问同一个全局变量,则称它们为共用耦合。比如模块a和模块b都需要访问x这个全局变量。【两个模块访问同一个全局变量】
缺点
- 代码不可读,与结构化编程的精神相矛盾;
- 维护困难。如果在一个模块内,对某个全局变量的声明做了维护性修改,那么访问这个全局变量的每一个模块都必须修改,而且,所有的修改都必须是一致的。
- 难以重用。因为重用这类模块时,必须提供相同的全局变量名。
- 数据无法控制。作为共用模块的后果,一个模块也许会被它本身之外的数据改变,使得控制数据访问的努力变得无效。
1.2.3.5 控制耦合
如果一个模块传递一个控制元素给另一个模块,则称这两个模块是控制耦合的。即一个模块明确地控制另一个模块的逻辑。【一个模块的代码运行顺序由另一个模块控制】
控制耦合所带来的问题是:两个模块不是相互独立的——被调用模块必须知道模块p的内部结构和逻辑,降低了重用的可能性;另外,控制耦合一般是与逻辑内聚性的模块的有关,逻辑内聚性的问题也在控制耦合中出现。
1.2.3.6 特征耦合
如果把一个数据结构当作参数传递,而被调用的模块只在数据结构的个别元素上操作,则称两个模块是特征耦合的。【一个模块只需要另一个模块的部分参数】
导致数据无法控制。
1.2.3.7 数据耦合
如果两个模块的所有参数是同一类数据项,则称它们是数据耦合的,也一就是每一个参数要么是简单变量,要么是数据结构,而当是后者时,被调用的模块要使用这个数据结构中的所有元素。【一个模块需要零一个模块完整的参数】
1.2.4 模块的重用
1.2.4.1 定义
重用是指利用一个产品的构件以使开发另一个具有不同性能的产品更容易。可重用的构件不一定是一个模块或一个代码框架,它可能是一个设计、一本手册的一部分、一组测试数据或最后期限和费用的估计。
而可移植的是指,为了使一个产品在另一个编译器/硬件/操作系统上运行,如果修改这个产品比从头编写代码更容易的话,那么这个产品就是可移植的。
1.2.4.2 重用的类型
- 偶然重用
如果一个新产品的开发人员意识到以前所开发的产品中有一个构件在新产品中可重用,那么这种重用即为偶然重用。 - 计划重用
如果利用那些专门为在将来产品中重用而构件的软件构件,则称为计划重用。
计划重用比偶然重用有一个潜在的优点,这就是,专门为在将来的产品中使用而构造的那个构件更容易于重用,而且重用也更加安全。因为这样的构件一般都有健全的文档,并做过全面的测试,另外,它们通常有统一的风格,从而易于维护。
但另一方面在一个公司内实现计划的代价可能是很高的。对一个软件构件进行规格说明、设计、实现、测试和编制文档要花很多的时间,然而,这样一个构件是不是能重用,所投资的成本能否回收不无保证。
1.2.4.3 构建重用
在计算机刚问世时,没有什么东西是可以重用的。每当开发一个产品时,所有项目都是从头开始构造的。然而不久为后,人们意识到这是相当大的工作浪费,于是人们构造了子程序库。这样,程序员在需要时就可直接调用这些以前编写好的例程,这些子程序库越来越成熟,并开始出现运行时的支持程序。
重用可以节省时间,缩短产品的开发期限同,使软件开发公司更有竞争力。开发人员既可以重用自己的例程,也可以重用各种类库或API,从而节省了大量的时间。相反,如果一个软件产品要花经费4年的时间才能进入市场,而一个竞争产品只用2年就交付使用,那么,不管它的质量有多高,它的销路也不会太好。开发过程的时间期限在市场经济中是至关重要的,如果产品在时间方面没有竞争优势,那么谈论怎样才能生产一个好的产品是不切实际的。
软件重用是一项诱人的技术。毕竟,如果可以重用一个现有的构件,就不必再设计、实现、测试这个构件了。
1.2.4.4 重用的障碍
据统计,对于任意软件产品来说,平均只有15%是完全服务于原始的产品目的的,产品的另外85%在理论上可以进行标准化,并在将来的产品中重用。在实际中,通常只能达到40%的重用率并且利用重用来缩短开发周期的组织也很少。因为重用有许多的障碍。
- 自负
从太多的软件专业人员宁愿从头重写一个程序而不愿重用一个由其他人编写的程序。他们认为,不是他们亲自编写的程序不可能是好程序。 - 经济利益
一些开发人员尽力避免编写那些太通用的例程,唯恐使自己失业。当然,从每个软件组织实际上有大量的积压任务的情况来看,这种担心是毫无根据的。 - 检索
一个组织可能有几十万个潜在的可重用的构件,为了提高检索效率,如何存储这些构件? - 代价
重用构件的成本:制作重用构件的成本、重用的成本、定义和实现一个可重用过程的成本。有统计表明,制作一个重用构件在理想情况下可其成本只增加11%,一般情况下增加60%,而有的重用可能会增加200%甚至480%。 - 版权
根据客户和软件开发公司之间的合同,软件产品是属于客户的,当软件开发人员为另一个客户开发一个新产品时,如果重用了另一个客户产品中的一个构件,本质上是一个侵犯第一个客户的版权。
1.2.5 模块的重要性(意义)
- 解决复杂问题的一种有效方法
- Miller法则:一个人任何时候只能将注意力集中在7±2个知识块上。
- 软件开发时,人们的大脑需要在一段时间内集中的知识块数往往远远多于7个。
- 对一个复杂的问题解决转化为对若干个更小问题的解决来实现。
- 集体分工协作的前提
将一个产品分解成几个相对独立的模块,这些模块分配由几个不同的小组开发。 - 产品维护的保障
模块间的相对独立性使得修改其中一个模块的内部代码或数据结构不影响其他模块。不仅为运行时的维护提供了可行性,还减少维护的费用。
1.3 软件工程
1.3.1 软件危机
1.3.1.1 背景
在短短的几十年中,计算机技术成为了现代社会的高科技的核心,其中硬件的发展是其他领域不可比拟的。中央处理器功能、存储器的容量、集成工艺的提高、新兴材料的研制、网络等变革,使得计算机很快从实验室走向应用,进入各行各业。计算机是社会信息化的基础。
然而,在软件技术方面,虽然也以巨大的速度发展,但比起计算机的硬件发展,就是微不足道的了。特别是在应用领域,许多企事业单位、机关 团体中的计算机,其性能远远没有得到充分的发挥。
随着计算机硬件的飞速发展,对计算机软件的功能、结构和复杂性提出了更高的需求,在软件的设计中,软件的局部和整体系统的结构方面,已经越来越显出其重要性,甚至超过了软件算法和数据结构这些常规软件设计的概念。软件体系结构概念的提出和应用,说明了软件设计技术在高层次上的发展并走向成熟。
1.3.1.2 定义
开发大型软件过程中﹐难以汇集参与人员的设计理念然后提供给使用者一致的设计概念(conceptual integrity)﹐因而导致软件的高度复杂性,使得大型软件系统往往会进度落后、成本暴涨及错误百出,就是所谓的软件危机(software crisis)。
1.3.1.3 人月神话
人月神话——二十多年前(1975)﹐IBM大型电脑之父──Frederick P. Brooks 出版的一本书。
人月(man-month)":熟悉软件项目管理的人员都清楚,人们常常根据人月来估计工作量(并相应收费),比如一个项目五人两月完成,那么总工作量就是10人月。
称之为"神话"(Mythical),其用意也并非完全否定作为计量方法的人月,而是要理清这个概念中隐含的种种错觉。
文中论点主要包括:
- 人/月之间不能换算,换言之,两人做五个月完成,不等于说五人做两个月就能完成;
- 在项目后期增加人手,只能使工期进一步推迟;
- 项目越大,单位工作需要的人月越多。
著名的Brooks法则
Adding manpower to a late software project makes it later(对于进度已落后的软件开发计划而言﹐若再增加人力﹐只会让其更加落后。)
"人月"概念可以线性化的神话:无论是开发人员的人数上,还是工作量本身上的变化,都可能导致最终完成时间的非线性变化。
1.3.1.4 没有银子弹
1986年,Brooks发表了一篇著名的论文──"No Silver Bullet: Essence and Accidents of Software Engineering"。他断言﹕在10年内无法找到解决软件危机的根本方法(银弹)(There will be no silver bullet within ten years)。
Brooks认为软体专家所找到的各种方法皆舍本逐末。解决不了软体的根本困难──即概念性结构(conceptual structure)的复杂,无法达到概念完整性。
软件开发的困难来自两个方面:本质的和偶然的。本质的困难是软件开发本身所固有的,无法用任何方式取消的,而偶然的困难是其中的非本质因素,可以通过引入新工具、方法论或管理模式来消除。关键在于,只要本质的困难在软件开发中消耗百分之十以上的工作量,则即使全部消除偶然困难也不可能使生产率提高10倍。
软件的本质
- 复杂性(complexity)
“复杂”是软件的根本特性。可能来自于程序员之间的沟通不良,而产生结构错误或时间延误;也可能因为人们无法完全掌握程序的各种可能状态;也可能来自新增功能时而引发的副作用等等。 - 一致性(conformity)
大型软件开发中,各小系统之界面常会不一致,而且易于因时间和环境的演变而更加不一致。 - 易变性(changability)
软件的所处环境常是由人群、法律、硬体设备及应用领域等各因素融合而成的文化环境,这些因素皆会快速变化。 - 不可见性(invisibility)
软件是看不见的。既使利用图示方法,也无法充分表现其结构,使得人们心智上的沟通面临极大的困难。
1.3.1.5 有一个银子弹
1990年﹐曾首先提出"Software IC"名词的OO大师──Brad Cox针对Brooks的观点而发表了一篇重要文章──"There Is a Silver Bullet"。说明他找到了尚方宝剑──即有些经济上的有利诱因会促使人类社会中的文化改变(culture change)。人们会乐于去制造类似硬体晶片(IC)般的软件组件(software component),将组件内的复杂结构包装得完美,使得组件简单易用。由这些组件整合而成的大型软件,自然简单易用。软件危机于是化解了。
1.3.2 软件工程的复杂性
1.3.2.1 建筑工程的经验对软件工程的启发
桥墩有时会坍塌,但出现的次数远远小于操作系统崩溃的次数。
两种故障的主要区别:土木工程领域和软件领域对崩溃事件的理解态度不同。当桥墩坍塌时人们几乎总是要对桥墩进行重新设计和重新建造,因为桥墩的坍塌说明该桥的最初设计有问题,这将威胁行人的安全,所以必须对设计作大幅度的改动,此外,桥墩坍塌后,几乎桥的所有结构被毁掉,所以唯一合理的做法是将桥墩残留的部分拆除再重新建造。更进一步地,其他所有相同设计的桥都必须仔细考虑,在最坏的情况下,要拆除重新建造。相比之下,操作系统的一次崩溃很少被认真考虑,人们很少立即对它的设计进行考察。当出现操作系统崩溃时,人们很可能只会重新启动系统,希望引起崩溃的环境设计不再重现。在多数情况下,没有去分析关于崩溃原因的证据,而且操作系统的崩溃引起的破坏通常中微不足道的。
也许当软件工程师们以土木工程师们对待桥墩坍塌那样认真的态度来对待操作系统故障时,这种区别就会缩小。当然,人类关于桥梁的设计毕竟经历了几千年的历史,而设计操作系统的经历只不过短短50多年。随着经验的积累,将一定会像理解桥一样充分地理解操作系统,构造出无故障的操作系统。
1.3.2.2 软件工程的复杂性
- 软件在执行时处于离散状态。
主存储器中一个比特位(bit)的改变就会引起软件执行的状态改变,而这种状态总数是巨大的,在设计初期无法完全测试。 - 软件运行环境具有不可再现性。
在采取多道程序设计后,一道程序在同一台机器的多次执行,其运行环境(比如,程序的代码被装入的主存空间的位置、程序执行过程的速度等)几乎不可重现。 - 硬件的复杂性
软件的功能要由硬件来实现,硬件的结构复杂多样性,增加了软件测试的难度。
1.3.3 软件工程的内容
软件工程是以软件系统为对象,合理地、创造性地采用软件系统所需的思想、理论、技术、方法对软系统进行研究分析、设计开发和服务,使软件最大限度地满足需求。
软件工程的生命周期
- 需求分析
- 规格说明
- 计划
- 设计
- 实现
- 集成
- 维护
- 终结
1.4 软件体系结构的意义与目标
1.4.1 软件体系结构的意义
- 软件体系统结构是软件开发过程的初期产品,为以后的开发、集成、测试、维护等阶段提供保证。
- 与软件过程的其他设计活动相比,体系结构的活动成本和代价要要低得多。
- 软件体系结构的正确有效,给软件开发带来极大的便利。
1.4.2 软件体系结构的目标
- 主要目标:建立一个一致的系统及其部件的视图,并以提供能夠满足终端用户和后期设计需要的结构形式。
- 外向目标:建立满足终端用户要求的系统需求。了解用户需要系统应该做些什么,扩展或细化结构,澄清模糊,提高一致性。
- 内向目标:如何使系统满足用户需求。为些需要建立哪些软件模块、分析它们的结构、相互间的关系和规范。正是对这些软件上层部件的及其关系的规划,为以后的系统设计和实施活动提供基础和依据
1.5 软件体系结构的研究现状
1.5.1 软件体系统结构的发展
- 程序抽象
- 20世纪50年代:汇编语言对机器语言的第一层抽象;
- 20世纪60-70年代:高级语言对程序描述的抽象,算法和数据结构的概念从程序中获得抽象,软件设计理论获得根本发展。
- 20世纪80年代:建立在抽象数据类型上的面向对象技术和理论。
- 20世纪90年代:面向对象技术的广泛应用:OLE、动态链接、ODBC、组件、RPC、CORBA、浏览器等,面向网络、跨平的分布式环境等。
- 软件工程
- 软件工程(1967年)是对软件工程设计的方法、技术和管理等方面的研究,为了实现软件的工程设计,要在独立于程序语言之外建立软件构成的表达,就软件所解决的问题建立概念的关系和模型。
- 20世纪70年代开始,提出和发展了软件的结构分析和设计方法,数据字典、数据流成为程序结构的主要描述手段,E-R图成了主要的信息概念模型甚至延用至今。
- 80年代,软件工程设计方法了面向对象的分析和设计。
- 90年代,面向对象方法的广泛发展,提出了诸如UML等多种面向对象的概念模型,并在软件工程中获得应用。
- 从某种意义看,这些模型和表达也是软件体系结构的描述方法,只是它们更多地从信息处理的角度建立起来的。
- 体系结构
- 人们对软件结构的关心,在20世纪50年代就开始了,在机器语言的控制流概念方面,人们尚不知道循环和条件结构描述,而是通过测试分支指令来实现这些结构。
- 高级语言的设计者更是认识到结构的用处,建立一套完整的程序结构描述,如循环、条件、过程调用,并通过开工形式化研究获得进一步的确认。现在几乎没有人认为还需要发明新的循环、条件或其他程序描述结构。
- 直到90年代,软件体系结构才开始受到全面的关注,并形成了新的软件技术和工程的研究热点。
1.5.2 软件体系统结构的研究现状
一个好的结构设计是决定一个软件系统成功的主要因素。
体系统结构的研究现状其现状具体表现在:
- 缺乏系统统一的概念和坚实的理论基础
软件体系结构已经提出,从整体上把握软件设计的重要性,并在结构的部件、部件关系(连接)上取得一致的认识。但部件和关系的描述、体系结构的基础、体系结构与其他软件研究的关系、体系结构与需求分析的关系都没有取得全面统一的认识。 - 缺乏工程知识的系统化和标准化
现有的涉及体系结构部件和连接器标准标准化的规范,都是来自特别应用问题或领域的,没有来处建立在软件体系结构总体认识上。例如,许多有用的结构范例,如管道、层次、C/S等,还只能应用于特定的系统,软件系统的设计者还没有设计出一些公用的系统结构的原理供人们选择。 - 缺乏形式化,没有建立统一的体系结构的工程描述方法
在传统的设计中,人们很早就使用系统框图和非形式描述来表达软件结构,可是这些描述都太含糊了、因人、因事而异,只凭经验、直觉或个人爱好,没有一个标准,不便于交流。
体系结构的形式化研究已经受到极大的关注并取得一定的成果,但它们都只是多某全侧面进行的,尚缺乏全面的适用性。
在这方面Microsoft公司推出的.NET的公共语言规范(Common Language Specification)技术可能是一个重要发展。
目前,软件体系结构已经成为软件工程的从业者一个重要研究领域。
软件体系结构的研究内容
- 风格(styles)
研究部件间的相关关系,及合成和设计规则 - 设计模式(design patterns)
建立在结构化和面向对象的基础上,设计人员积累大量的经验,发现并抽象在众多的应用中普遍存在的软件的结构及其关系,以此为模板实现软件重用 - 结构描述语言(ADL)
研究各种表达软件构成的描述形式,作为软件设计的结构表达的一些规范。
1.6 习题
- 什么是软件体系结构?它有哪三种类型?
一个软件系统的体系结构是指构成这个系统的计算部件、部件间的相互作用关系。部件可以是客户(clients)、服务器(servers)、数据库(databases)、过滤器(filters) 、层等。部件间的相互作用关系(即连接器)可以是过程调用(procedure call)、客户/服务器、同步/异步、管道流(piped stream)等。
服务于软件开发的不同阶段,体系结构可分为概略型——是上层宏观结构的描述,反映系统最上层的部件和连接关系;需求型——对概略型体系结构的深入表达,以满足用户功能和非功能的需求。设计型——从设计实现的角度对需求结构的更深层的描述,设计系统的各个部件,描述各部件的连接关系。这是软件系统结构的主要类别。 - 软件产品在实现时通常分解成一些较小的模块,这种做法的意义是什么?分解时应遵循的原则是什么?
解决复杂问题的一种有效方法;集体分工协作的前提,将一个产品分解成几个相对独立的模块,这些模块分配由几个不同的小组开发;产品维护的保障,模块间的相对独立性使得修改其中一个模块的内部代码或数据结构不影响其他模块。不仅为运行时的维护提供了可行性,还减少维护的费用。
一个好的模块设计应该使模块具有高内聚性和低耦合性。
二、软件体系结构风格
2.1 什么是软件体系结构风格
2.1.1 什么是结构风格
在许多工程学科,设计模式、风格的利用是非常普遍的。事实上,衡量一个工程领域是否成熟的一个重要指标,是看该工程领域是否就建就一套共享的通用设计形式。在软件上也是这样。在结构上,与之联系的有,客户/服务器系统(client-server system,C/S)、管道/过滤器设计(pipe-filer design,P/F)、层次结构(layered architecture)、在设计方法上的面向对象(object-oriented)、数据流(dataflow)等。
在软件设计的实践中,人们发现某些特殊组织结构(如C/S结构,B/S结构、P/F结构)在许多的软件系统中频繁出现,这些特殊结构有很高的应用价值。于是人们就设想能否将这些特殊结构进一步发展规范,使它们成为一种相对固定的设计结构,并应用于新软件产品。
关于一个软件系统的结构风格定义为组织该系统可用的各种结构模式。具体地说,就是系统的组件(component)、连接器(connector),以及它们的组合的约束条件(constraint)。
一个软件系统的结构包括构成系统的所有计算组件(computational component)、组件间相互作用(interacton)即连接器(connector)。用数学中的图的概念描述,一个系统结构图就是由节点(node)和边(edge)组成,这里节点代表组件,边表示组件间的连接器。
2.1.2 结构风格的分类
- 数据流系统(Dataflow systems)
- 批处理序列(Batch sequential)
- 管道/过滤器(Pipes and filters)
- 调用/返回系统(Call-return systems)
- 主程序/子程序(Main program and subroutine)
- 面向对象(OO system)
- 层次结构(Hierarchical layers)
- 独立组件(Independent components)
- 进程通讯(Communicating processes)
- 事件系统(Event systems) ;
- 虚拟机(Virtual machines)
- 解释器(Interpreters)
- 基于规则的系统(Rule-based systems)
- 仓库(Repositories)
- 数据库系统(Databases)
- 超文本系统(Hypertext system)
- 黑板系统(Blackboards)
2.2 常用结构风格
2.2.1 管道/过滤器(Pipes and Filters,P/F)
2.2.1.1 系统组织
- 在一个管道/过滤器组织的系统中,每个组件有一个输入集(input set)和一个输出集(output set),并从输入集中读取数据流,处理后产生的数据流送向输出集。
- 组件称为过滤器(Filters),数据流称为管道(Pipes)。过滤器间按预定的顺序工作,即一个过滤器的的输出作为下一个过滤器的输入。从第一个过滤器的输入开始的,数据被逐步地处理直到完成。
- 从整个系统的输入和输出关系看,各过滤器可以对其输入进行局部的独立处理并产生部分的计算结果,过滤器的活动可以按以下方法激活:
- 后续的组件从过滤器中取出数据;
- 前续的组件向过滤器推入新数据;
- 过滤器处于活跃状态,不断地从前续组件取出、并向后续组件推入数据。
- 前两种情况产生的是被动式过滤器(passive filter),最后的是主动式过滤器(active filter)。被动式过滤器是通过函数或过程调用的,而主动式过滤器是作为独立的程序或线程任务激活的。
- 管道(Pipe)是过滤器之间的连接器(Connector),如果两个主动式过滤器连接在一起,管道将对它们实施同步控制,管道是一个先进先出(FIFO)的数据缓冲区。
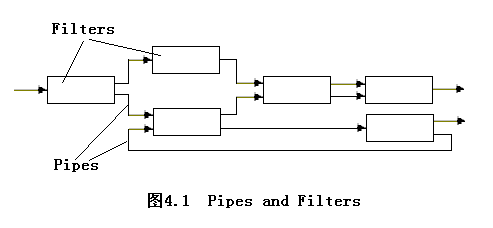
- 过滤器是独立的运行组件。除了输入和输出外,其独立性具体表现在:
- 过滤器(filters)之间不受任何其他的过滤器运行的影响,非相邻的过滤器之间不共享任何状态,甚至对于多次加工而言,过滤器自身也是无状态的即每次加工后回到原始的等待状态;
- 一个过滤器对其前继或后续过滤器的设计和使用没有任何的限制,惟一关心的是其输入的到来形式、加工处理的逻辑和产生的输出形式;
- 在整个结果的正确不依赖于各个过滤器运行的先后次序。对于原始的输入,尽管其最终输出形式的获得需要经过特定的加工、并符合加工的顺序要求,但在系统工作时,各过滤器只在输入具备后独立完成自己的计算,完整的计算过程包含在各个过滤器之间的拓扑结构(topology)中。
- 过滤器的拓扑结构(topology)
- 线性顺序的管道(linear sequences filters)
- 界限管道(bounded pipes): 对管道中的驻留的数据的限制。
- 类型管道(typed pipes):对两个过滤器间的数据有严格的类型定义。
2.2.1.2 评价
优点
- 使得软构件具有良好的隐蔽性和高内聚、低耦合的特点;
- 允许设计者将整个系统的输入/输出行为看成是多个过滤器的行为的简单合成;
- 支持软件重用。重要提供适合在两个过滤器之间传送的数据,任何两个过滤器都可被连接起来;
- 支持快速原型系统的实现。
- 具有自然的并发特性。过滤器可以独立顺序运行,也可以同时并发运行,从而增加了系统运行的灵活性,也使提高运行效率成为可能,尤其是网络环境下的管道。
- 由于是通过独立的过滤器的组合,系统具有清晰的拓扑结构,因而容易进行某些性能方面的分析,例如,数据吞吐量(throughput)、死锁(deadlock)、计算正确性等。
缺点
- 通常导致进程成为批处理的结构。这是因为虽然过滤器可增量式地处理数据,但它们是独立的,所以设计者必须将每个过滤器看成一个完整的从输入到输出的转换。。
- 不适合于需要共享大量数据的应用设计。
- 不适合处理交互的应用。当需要增量地显示改变时,这个问题尤为严重。
- 过滤器之间通过特定格式的数据进行工作,数据格式的设计和转换是系统设计的主要方面,为了确保过滤器的正确性,必须对数据的句法和语义进行分析,这增加了过滤器设计的复杂性。
- 并行运行获得高效率往往行不通。原因,第一,独立运行的过滤器之间的数据传送的效率会很低,在网络传送时尤其如此;第二,过滤器通常是在消耗了所有输入后才产生输出;第三,在单处理器的机器上进程的切换代价是很高的;第四,通过管道对过滤器的同步控制可导致频繁启动和停止过滤器工作。
2.2.2 数据抽象与面向对象组织(Data abstraction and Object-oriented Organization)
2.2.2.1 系统组织
抽象数据类型概念对软件系统有着重要作用,目前软件界已普遍转向使用面向对象系统。这种风格建立在数据抽象和面向对象的基础上,数据以及施加于它们之上的操作封装在一个抽象数据类型或对象中。这种风格的系统中组件(component)是对象(object),或者说是抽象数据类型的实例。对象是一种被称作管理者(manager)的组件,因为它负责资源的表示(representation)。对象间的相互作用是通过函数(founction)和过程(procedure)调用(invocation)实现。连接器(connector)则是激活对象方法(method)的消息(message)。
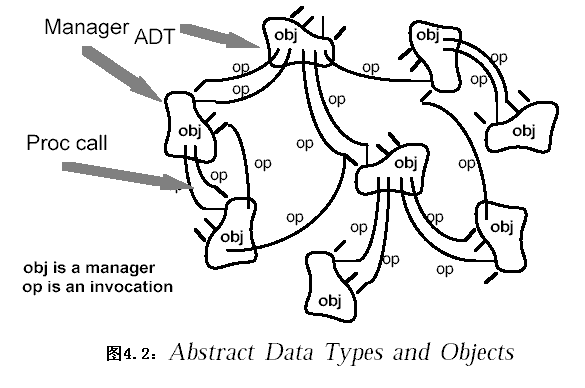
2.2.2.2 评价
优点
- 因为对象对其它对象隐藏它的表示,所以可以改变一个对象的表示,而不影响其它的对象。
- 设计者可将一些数据存取操作的问题分解成一些交互的代理程序的集合。
- 允许多个对象实现并发(concurrent)任务,对象间可有多种接口。
缺点
- 为了使一个对象和另一个对象通过过程调用等进行交互,必须知道对象的标识。只要一个对象的标识改变了,就必须修改所有其他明确调用它的对象。与此相比,管道/过滤器系统中一个过滤器就不必知道另一个过滤器而只需将处理结果按一定的形式输出即可。因此,在面向对象(object-oriented)的系统中,一个对象(组件)的标识的改变,需要修改所有与之相互的对象(组件)。
- 必须修改所有显式(explicitly)调用它的其它对象,并消除由此带来的一些副作用(side-effect)。例如,如果A使用了对象B,C也使用了对象B,那么,C对B的使用所造成的对A的影响可能是料想不到的。
2.2.3 事件及隐含激活(Event-Based, Implicit Inovaations)
2.2.3.1 系统组织
在面向对象的系统中,组件是一组对象,组件间的相互关系是通过直接的过程调用实现,这种方法的不足是组件(对象)标识必须是公开的,众所周知(well-known)的。因此,人们考虑是否可以隐含激活(implicit invocation)或作用集成(reactive integration)。
在一个基于事件的隐含激活系统中,组件不直接调用一个过程,而是触发(announce)或广播(broadcast)一个或多个事件(event)。系统中的组件事先注册(register)它们感兴趣的事件及对应的过程,将来,当一个事件被触发(inovaation),系统自动调用在这个事件中注册的所有过程,这样,一个事件的触发就导致了另一模块中的过程的调用。
从体系结构上说,这种隐含激活风格的组件是一些模块,这些模块是一些过程和一些事件的集合。过程可以用通常的方式调用,也可以在系统事件中注册一些过程,当发生这些事件时,过程被隐含调用。
基于事件的隐含激活风格的主要特点是事件的触发者并不知道哪些组件会被这些事件影响。这样不能假定组件的处理顺序,甚至不知道哪些过程会被调用,因此,许多隐含调用的系统也包含显式调用作为组件交互的补充形式。
支持基于事件的隐含激活的应用系统很多。例如,在数据库管理系统中确保数据的一致性(consistency)约束,在用户界面系统中管理数据,以及在编辑器中支持语法检查。例如在编程环境中,编辑器和变量监视器可以登记相应Debugger的断点(breakpoint)事件。当Debugger在断点处停下时,它声明该事件,由系统自动调用处理程序,程序代码自动滚动(scroll)到到断点,变量监视器刷新变量数值。而Debugger本身只声明事件,并不关心哪些过程会启动,也不关心这些过程做什么处理。
2.2.3.2 评价
优点
- 为软件重用(reuse)提供了强大的支持。当需要将一个组件加入现存系统中时,只需将它注册到系统的事件中。
- 为扩充系统带来了方便。当用一个组件代替另一个组件时,不会影响到其它组件的接口。
缺点
- 组件放弃了对系统计算的控制。一个组件触发一个事件时,不能确定其它组件是否会响应它。而且即使它知道事件注册了哪些组件的构成,它也不能确保这些过程被调用的顺序。
- 数据交换的问题。有时数据可被一个事件传递,但另一些情况下,基于事件的系统必须依靠一个共享的仓库进行交互,在这些情况下,全局性能和资源管理便成了问题。
- 难以保证正确性。
2.2.4 层次系统(Layers Systems)
2.2.4.1 系统组织
层次系统组织成一个层次结构,每一层为上层提供若干服务(service),并作为下层的客户(client)。在一些层次系统中,除了一些精心挑选的输出函数外,内部的层只对相邻的层可见。
这样的系统中组件在一些层实现了虚拟机(在另一些层次系统中层是部分不透明的)。连接器通过决定层间如何交互的协议来定义,拓扑约束限制了对相邻层间交互。
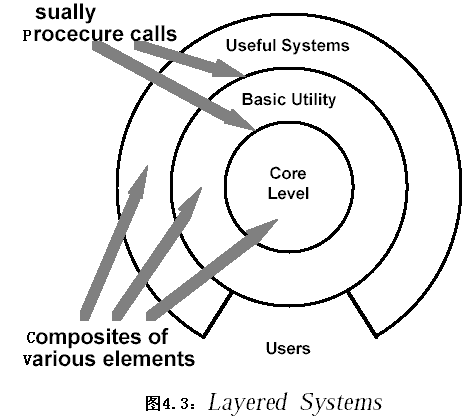
层次系统(Layers Systems)最广泛的应用是分层通信协议(如,OSI/RM)。在这一应用领域中,每一层提供一个抽象的功能,作为上层通信的基础。较低的层次定义低层的交互,最低层通常只定义硬件物理连接。
2.2.4.2 评价
优点
- 支持基于层递增的系统设计,使设计者可以把一个复杂系统按递增的步骤进行分解。
- 支持(enhancement)功能扩充,与管道/过滤器系统一样,因为每一层至多和相邻的上下层交互,因此功能的改变最多影响相邻的上下层。
- 支持重用(reuse)。只要提供的服务接口定义不变,同一层的不同实现可以交换使用。这样,就可以定义一组标准的接口,而允许各种不同的实现方法。
缺点
- 并不是每个系统都可以很容易地划分为分层的模式,甚至即使一个系统的逻辑结构是层次化的,出于对系统性能的考虑,系统设计时不得不把一些低级或高级的功能综合起来。
- 很难找到一个正确层次的抽象方法。如,在通信协议中,虽然OSI/RM定义了7层协议,可是TCP/IP,IPX/SPX也都不是7层。
2.2.5 仓库(Repositories)
2.2.5.1 系统组织
- 在仓库(Repositories)风格的系统中,有两种不同的组件:中央数据结构表示当前状态,一组独立组件执行在中央数据上,仓库与外部组件间的相互作用在系统中会有大的变化。
- 控制原则(control discipline)的选取导致这种风格的两个主要的子类。如果由输入的事务类型触发进程执行,则仓库风格的系统是一种传统的数据库系统;如果由中央数据结构的当前状态触发进程执行,则仓库是一个黑板系统。
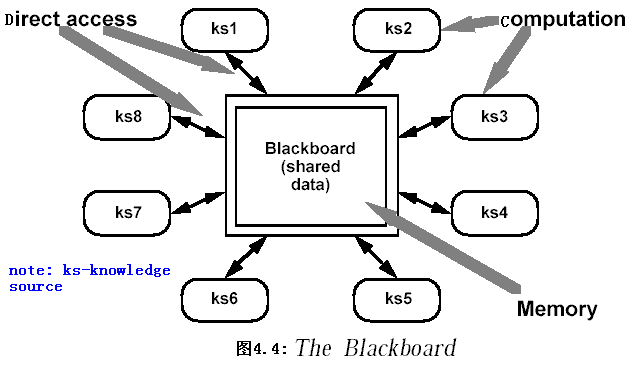
- 黑板系统实现的基本出发点是已经存在一个对公共数据结构进行协同操作的独立程序集合。每个程序专门解决一个子问题,但需要协同工作完成整个问题的求解,这些专门的程序是相互独立的,它们之间不存在互相调用,也不存在右事先确定的操作顺序,操作次序是由问题求解的进程状态决定的。
- 在黑板系统中,有一个中心操作组件,即黑板,它是一个数据驱动或状态驱动的控制机制。它保存着系统的输入、问题求解各个阶段的中间结果和反映整体问题求解进程的状态,这些是由系统的输入和各个求解程序写入的,因此被称为黑板。
- 在问题求解过程中,黑板上保存了所有部分解,它们代表了问题求解的不同阶段。形成了问题的可能解空间,并以不同的抽象层次表达出来,其中,最底层的表达就是系统的原始输入,最终的问题求解在抽象的最高层次。
黑板系统主要由三部分组成
- 知识源(knowledge source)
- 知识源中包含独立的、与应用的问题求解相关的知识(knowledge),知识源之间不直接进行通讯,它们之间的交互只通过黑板来完成。
- 知识源包含参与问题求解的条件的执行的操作,条件部分对黑板的信息和求解进程的状态做出评估,在条件得到满足时执行相应的操作;执行的操作可以是产生新的假设,也可以是对黑板上的数据结构的变换处理,操作的结果可能导致黑板上数据和状态的变化,并引起进一步的处理。
- 黑板数据结构(blackboard data structure)
- 问题求解(problem-solving)的状态数据(state data),是按照与求解进程的相关的层次来组织。通过黑板中知识源的不断改变来体现一个问题的逐步解决。
- 控制(control)
- 控制黑板的数据和状态的变化,并根据变化决定采取的行动。黑板状态的改变决定使用的特定知识。
- 其中有一类特殊的知识源,它们用来确定问题求解的最终目标和终止求解的条件。
黑板系统的传统应用是信号处理领域,如语音和模式识别(speech and pattern recognition)。另一应用是松耦合代理(loosely coupled agent)数据共享存取。一些管道/过滤器系统(如编译器)也可以设计为黑板系统。另个黑板系统也是人工智能广泛使用的系统结构。
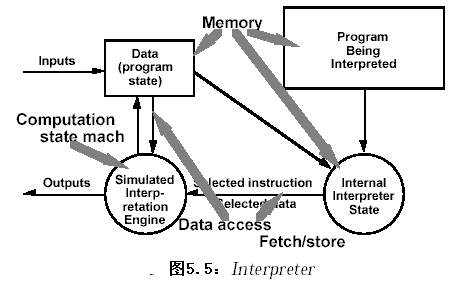
2.2.6 解释器(Interpreters)
2.2.6.1 系统组织
解释器(interpreters)广泛用于建立虚拟机(virtual machine),以减少程序的语义所期望的计算机器与硬件所提供的有效计算机器的差距。JVM-java语言虚拟机。
一个解释器系统由一个程序伪代码(pseudoprogram)和解释机(interpretation engine)。其中程序伪代码包含程序代码和执行的解释中间代码,解释机包含解释器的定义和执行的当前状态的定义。
解释器的由个部件组成
- 解释机(interpretation engine):完成解释工作;
- 程序源码:待解释的程序;
- 伪代码(pseudocode): 用来解释的中间代码。
- 解释机的当前状态(current state of the interpretation engine)。
2.3 其他结构风格
- 分布式处理(Distributed Processes)
分布式系统(distributed systems)多处理器系统的一个组织,客户/服务器(client-server,C/S)结构则是组织分布式系统的主要方式。服务器(server)表现为一个进程,它向其他进程(client)提供服务或数据,通常服务器事先不知道访问它的客户的数量和标识(identity),客户(client)则通过远程过程调用(RPC)或消息传递(message passing)方式请求服务。 - 主程序/子过程调用(Main program/subroutine organiztions)
系统由一个主程序(main program)和一组子过程(subroutines)组成,由主程序驱动调用所需要的子过程,通常主程序是运行一个循环顺序地调用各个子过程。 - 确定域结构(Domain-specific)
一种分布式系统的实现方式,服务程序用域(domain)管理,提供对象引用(reference)给客户程序使用。 - 状态变迁系统(State transition system)
系统有一组状态(state)集、一组状态转换函数,其中状态集包括初始状态集和终止状态。系统接受一个输入集,根据初始状态依次驱动对应的状态转换函数。
2.4 案例分析
2.4.1 问题描述
KWIC-Key Word Index in Contex(关键字索引),由Parnas在1972年提出的,问题描述如下:
The KWIC [Key Word in Context] index system accepts an ordered set of lines; each line is an ordered set of words, and each word is an ordered set of characters. Any line may be “circularly shifted” by repeatedly removing the first word and appending it at the end of the line. The KWIC index system outputs a list of all circular shifts of all lines in alphabetical order.
KWIC[上下文中的关键字]索引系统接受一组有序的行;每一行都是一组有序的单词,每一个单词都是一个有序的字符集。任何一行都可以通过重复删除第一个单词并将其附加在行的末尾来“循环移位”。KWIC索引系统按字母顺序输出所有行的所有循环移位列表。
2.4.2 解决方案
2.4.2.1 主程序/子过程调用(Main program/subroutine)
系统由一个主程序(master control)和四个子过程:input、shift、alphabetize和output组成。
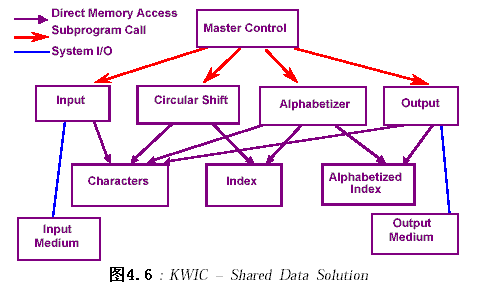
四个子过程在主程序的控制下依次执行,子过程间的数据传递是通过共享的存储区(磁盘)。
在这种方法中,子程序间共享存储区域,使得数据的表示效率高,节省了存储空间;但这也带来一些不足,数据结构的改变将影响到所有的四个子过程,不支持重用(reuse)。
2.4.2.2 数据抽象与面向对象组织(Data abstraction and Object-oriented Organization)
系统同样由五个模块组成。
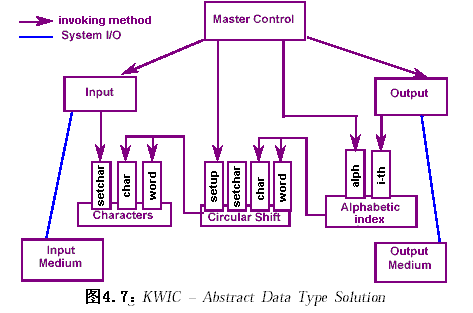
但模块间不再直接共享数据存储区,每个模块定义了一些方法,供其他模块通过激活方法调用。
在这种方法中,算法和数据表示封装在模块内,对它们的修改不影响其他模块;支持重用。但不适合于功能的扩充,当增加一个新功能时,必须修改现有的模块。
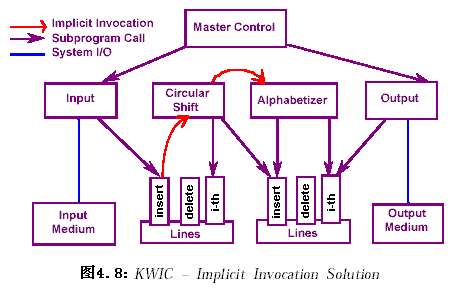
2.4.2.3 事件及隐含激活(Event-Based, Implicit Inovaations)
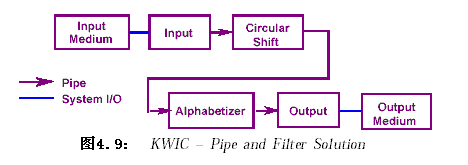
2.4.2.4 管道/过滤器(Pipes and Filters,P/F)
2.5 习题
- 总结P/F结构风格的缺点
(1)通常导致进程成为批处理的结构。这是因为虽然过滤器可增量式地处理数据,但它们是独立的,所以设计者必须将每个过滤器看成一个完整的从输入到输出的转换。
(2)不适合于需要共享大量数据的应用设计
(3)不适合处理交互的应用。当需要增量地显示改变时,这个问题尤为严重。
(4)过滤器之间通过特定格式的数据进行工作,数据格式的设计和转换是系统设计的主要方面,为了确保过滤器的正确性,必须对数据的句法和语义进行分析,这增加了过滤器设计的复杂性。
(5)并行运行获得高效率往往行不通。原因,第一,独立运行的过滤器之间的数据传送的效率会很低,在网络传送时尤其如此;第二,过滤器通常是在消耗了所有输入后才产生输出;第三,在单处理器的机器上进程的切换代价是很高的;第四,通过管道对过滤器的同步控制可导致频繁启动和停止过滤器工作。
三、分布式体系结构分析
3.1 分布式处理结构风格概述
3.1.1 系统组织
组件:系统由多个可以独立运行机制的部件组成,每个部件称为组件;同时系统由多台机器运行这些组件,这些机器共同协作完成系统的所有功能。
透明性:系统中的每个组件不需要关心其他组件的运行位置、实现方式及数量。
可靠性:当系统中的一个或少数几个组件出现故障(关闭或崩溃)时,系统仍然可以工作,所出现的故障造成的影响多只是系统运行速度。
3.1.2 分布式处理结构风格的优缺点
注:3.1.2 小节来自CSDN文章《分布式优缺点》
3.1.2.1 优点
- 增大系统容量。我们的业务量越来越大,而要能应对越来越大的业务量,一台机器的性能已经无法满足了,我们需要多台机器才能应对大规模的应用场景。所以,我们需要垂直或是水平拆分业务系统,让其变成一个分布式的架构。
- 加强系统可用。我们的业务越来越关键,需要提高整个系统架构的可用性,这就意味着架构中不能存在单点故障。这样,整个系统不会因为一台机器出故障而导致整体不可用。所以,需要通过分布式架构来冗余系统以消除单点故障,从而提高系统的可用性。
- 因为模块化,所以系统模块重用度更高
- 因为软件服务模块被拆分,开发和发布速度可以并行而变得更快
- 系统扩展性更高
- 团队协作流程也会得到改善
3.1.2.2 缺点
- 架构设计变得复杂(尤其是其中的分布式事务)
- 部署单个服务会比较快,但是如果一次部署需要多个服务,部署会变得复杂
- 系统的吞吐量会变大,但是响应时间会变长
- 运维复杂度会因为服务变多而变得很复杂
- 架构复杂导致学习曲线变大
- 测试和查错的复杂度增大
- 技术可以很多样,这会带来维护和运维的复杂度
- 管理分布式系统中的服务和调度变得困难和复杂
3.1.3 构造分布式处理结构风格的主要技术
层次结构:组件的一种组织方式。
技术基础:进程通信
RPC:进程通信的发展
组件技术:RPC的发展,如CORBA、J2EE等
云计算技术:分布式处理技术的最新发展。
区块链:【具体内容在第十讲】
3.2 分布式系统
3.2.1 分布式系统是计算机发展的必然产物
- 不断推出功能强大的微处理器,价格便宜
自1945年计算机的出现至1985年,计算机系统经历了一场代替革命。开始,计算机系统庞大价格昂贵,各单位、组织的计算机拥有量很少,并且也仅仅是彼此独立的。到了80年代中期,计算机领域的两项新技术改变了这种状况。 - 强有力的微处理器的发展
开始是8位机,很快普及到16位.32位,甚至64位的微处理器,这些处理器的价格便宜。开始,一台机器1千万美元,每秒1条指令,现在1台机器1千美元,每秒1千万条指令。 - 高带速网络的发展
使得局域网可将同一单位几百台的计算机连接起来,它们中少量数据可在1μs内在机间传输,而广域网则能够将全球范围内成千上万的机器连成一体协调工作。
网络的发展造成异构不可避免。一个原因是网络技术随着是不断地改进,不同时间最好的网络技术可能在同一网络中共存;另一个原因是网络大小不是固定不变的,任何一种计算机、操作系统、网络平台的组合都是为了能在一个网络内使得某一部分的性能达到最好;还有一个原因就是在一个网络内的多样化使得它具有可选余地,因为在某一机器类型,操作系统或应用程序所出现的问题可能在其他操作系统和应用程序上不成其为问题。 - 在计算机网络中工作站的CPU浪费严重
在计算机网络中,工作站之间的CPU无法共享、负载不平衡,在一个网络中,计算中心的工作站的CPU往往承担大量的计算,而许多办公室中的工作站其CPU又多数是空闲。 - 单个微处理器的发展有极限
处理器芯片集成度高,比特位的传输又产生巨大的热量,虽然在理论上传输速度可以达到光速,而实际上,在远远未达到这处速度之前,可能会使处理器烧毀。
3.2.2 集中式系统和分布式系统
- 集中式
只有一个CPU以及相应的存储器.外围设备和几个终端组成的计算机系统。 - 分布式
在硬件方面,很容易将若干台机器通过物理线路连接起来,并且也可以实现对一些资源的共享,如数据、外围设备。这些都只是计算机网络的概念,但是要能实现CPU的共享、分散各地的CPU能协调地完成某项任务,还需要软件的支持,这就是分布式操作系统。
一个分布式系统就是一个由若干独立的计算机组成的一个系统,该系统对其用户来说,操作起来就就像一台计算机一样。
一个常见的分布式系统的例子
某学校的网络中,每台工作站都可以独立工作,我们将网络中的各个工作站的CPU组成一个CPU池,每个CPU并不指定分配某个工作站的用户而是可以根据需要动态地将某个CPU分配给某个用户。在这个网络中,也只有一个文件系统,所有机器都可以用同一方式和同样的路径来访问系统中的所有文件。比如一个用户在自己的工作终端上输入一个命令,系统将找到一个最佳的位置为其运行命令,可能是在自己的工作站上,也可能是在某一台机器上暂时没有工作的CPU上执行,或者是系统中某个尚未分配出去的CPU上执行。如果这个系统看上去像一个整体,而又像单处理器系统那样工作,我们就可称之为分布式系统。
3.2.2 分布式系统的优点
- 经济上——分布式系统提供更高的性能/价格比
通常价格与处理器能力的平方成正比。
假定一个分布式系统由 n 个独立的计算机组成,其中计算机 i 有一个CPU其计算能力为 Pi,那么这个分布式系统的计算能力 P = ∑ i = 1 n P i P=\sum_{i=1}^n P_i P=∑i=1nPi - 运行速度
分布式系统的计算能力是系统中各个独立计算机计算能力的总和。这使得分布式系统不仅有更高的性能/价格比,并且其计算能力是集中式系统不可达到的。比如:
由 10 000 个CPU组成的分布式系统,每个CPU的执行速度为 50MIPS,该系统总的执行能力为 50MIPS*10,000。而对单个处理器而言,要达到这个程度,一条指令必须在 0.002ηs 内完成,这在理论上都是不可能的(因为将要求电子在芯片中的运行速度要超过光速). - 应用领域的需要
有些应用领域需要是分布式系统:比如商业分布式系统。超市连锁店系统中,对每个分店,可独立营销,时刻掌握本店的库存情况,而高层管理人员也需要时刻了解各个分店的情况。最好的作法就是建立一个分布式系统将各个分店连结起来形成一个整体。
另外,计算机支持协调工作:有一群决策成员彼此分散各地,而共同完成一个主题。 - 可靠性
分布式系统比集中式系统具有更高的可靠性,由于分布式系统有多个机器,单个芯片的故障,不会影响整个系统的工作,而至多只是降低系统的计算能力。 - 扩充性
计算能力可以逐步增加。 - 适应性
在分布式系统中,工作量以有效的方式分布于可使用的机器上
3.2.3 分布式系统的不足
- 软件——适用于分布式系统的软件很少
到目前为止,还没有一个成熟的实用的分布式操作系统、程序设计语言、以及适合的应用软件。
可喜的是,这方面的研究工作不断进展,软件问题将不再存在。OMG组织的CORBA规范就是一个很好的例子,可用于开发分布式应用系统。 - 通讯网络——网络饱和以及其他问题
分布式系统的硬件基础是计算机网络,网络使分布式系统的优点受到影响。
当现有的网络饱和时,必须重新规划新的网络或增加第二个网络,从而带来布线等方面的不便和开销
网络通信信息可能会丢失,为此需要特殊的软件来恢复,但它将使网络负荷增加。 - 安全性——保密的数据也变得容易存取
数据容易有利有弊:如果人们很容易地访问系统上的所有数据,他们也可很方便地查看与他们无关的数据。为此人们不喜欢自己的机器上网。
尽管有这些潜在的问题,人们还是觉得利大于弊,并预计分布式系统将越来重要,事实上,不久的将来,有更多的组织、单位要求连接自己的机器构成一个大的分布式系统,提供更好、更经济、更方便的服务。一个独立的计算机系统在中、大型企业、组织将不再存在。
3.3 客户/服务器(Client/Server)结构
3.3.1 C/S结构
在一个信息处理系统中,通常由若干台计算机组成。其中用于提供数据和服务的机器,称为服务器(Server),向服务器提出请求数据和服务的计算机称为客户(Client),这样的系统工作模型称为客户/服务器(Client/Server)模型,简称C/S模型。
在广义上说,客户、服务器也可以是进程。因此,C/S模型可以在单处理器的计算机系统中实现。
在多计算机或多任务的单处理器系统中,C/S模型有多种组织方式:单客户单服务器、单客户多服务器、多客户单服务器、多客户多服务器等。
3.3.2 C/S模型的软件结构的特点
- 简化软件产品的设计
这种结构把软件分成两个部分,客户部分可专门解决应用问题、界面设计、人机交互等方面,服务器则侧重于服务操作的实现、数据的组织,以及系统性能等。 - 提高软件的可靠性
在这种结构风格的系统中,不仅客户与服务器是独立的,服务器与服务器之间也是独立的,一个服务由一个服务器完成,它不影响其他服务器的工作。 - 适合分布式计算环境
C/S模型的软件中,Client与服务器之间的通信通常是以消息传递方式实现,对客户来说,它只关心服务请求的结果能正确地获得,而至于服务的处理是在本地还是在远程并不重要。
3.3.3 C/S模型的工作过程
- 客户方处于主动,向服务器提出服务请求,而服务器处于被动,服务器进程启动后,就处于等待接收客户的请求,当请求到达时被唤醒;
- 客户方以通常的方式发出服务请求,由客户机上的通信软件把它装配成请求包,再经过传输协议软件把请求包发送给服务器方;
- 服务器中的传输协议软件接收到请求包后,对该包进行检查,若无错误便将它提交给服务器方的通信软件进行处理;
- 服务器通信软件根据请求包中的请求,完成相应的处理或服务,并将服务结果装配成一个响应包,由传输协议软件将其发送给客户;
- 由客户的传输软件协议把收到的响应包转交给客户的通信软件,由通信软件做适当的处理后提交给客户。
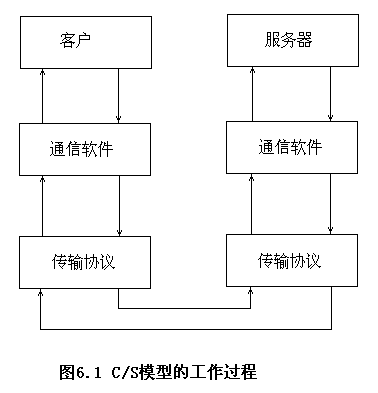
3.3.4 数据共享的方式
- 数据移动共享
- 计算移动共享
3.3.5 C/S的连接
- 使用消息传递的方式
这就是上讲中的基于消息传递的通信方式,连接可以是同步的也可以是异步的。 - 使用过程的方式
每个部件之间通过良好的接口定义与其他部件通信,这种方式的技术被称为过程过程调用(Remote procedure call,即RPC),通常RPC是采用同步的连接。 - 使用对象引用方式
这是目前普遍采用一个跨平台分布式软件的设计技术。
3.3.6 C/S的服务器设计、实现关键
- 服务器的调度任务和调度方式
服务器的调度任务是解决多客户和多请求同时执行的问题。作为独立工作的服务器,无法确定什么时间会发生多少的客户请求,所以它必须随时准备,处理来自不同的客户的请求,如果服务器已经无能为力处理新的请求,它必须以一定的策略建立等待队列或通知客户不能立即处理请求。
现在,基于应用层的服务器都是运行于多任务的操作系统上,甚至是支持线程的操作系统,使用服务器对客户的请求可以采用进程调度方式(process scheduling) 和线程调度(thread scheduling)方式。
当有多个请求到达时,服务器必须按一定的方式来为每个请求服务,这种方式称为服务器的调度方式。
基于进程的调度方式:主服务器进程每收到一个消息,就创建一个子进程并回到循环的顶部,由子进程(从服务器(salve))负责消息的处理。 - 线程技术
【第4讲进行介绍】 - 服务器缓冲技术
【第4讲进行介绍】
3.3.7 C/S案例
3.3.7.1 文件服务器的设计
- 消息格式设计
发送进程标识(source)
接收进程标识(dest)
请求服务类型(opcode)
传送的字节数(count)
文件读/写指针(offset)
备用1(reserved1)
备用2(reserved2)
服务结果(result)
访问的文件(name)
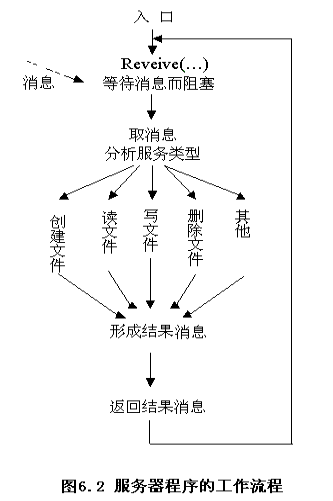
数据缓冲区(data) - 服务器的工作流程
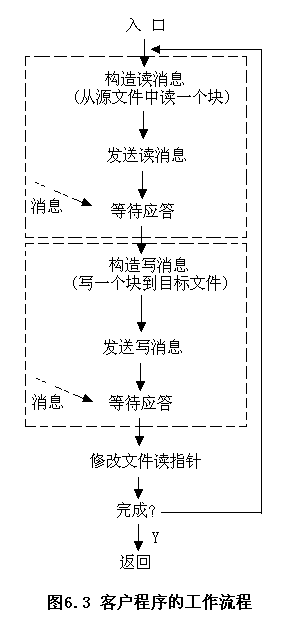
- 客户程序工作流程
客户程序将服务器中的一个文件的信息写到另一个空文件(目标文件)中
3.3.7.2 文件服务器的C语言实现(部分)
- 头文件 header.h
#define MAX_PATH 255
#define BUF_ZISE 1024
#define FILE_SERVER 243
#define CREATE 1
#define READ 2
#define WRITE 3
#define DELETE 4
#define OK 0
#define E_BAD_OPCODE -1
#define E_BAD_PARAM -2
#define E_IO -3
struct message{
long source;
long dest;
long opcode;
long count;
long offset;
long result;
char name[MAX_PATH];
char data[BUF_SIZE];
};
- 服务器程序
#include <header.h>
int main() {
struct message m1,m2;
int r;
while (1) {
receive (FILE_SERVER, &m1);
switch (m1.opcode) {
case CREATE:
r=do_create(&m1,&m2);
break;
case READ:
r=do_read(&m1,&m2);
break;
case WRITE:
r=do_write(&m1,&m2);
break;
case DELETE:
r=do_delete(&m1,&m2);
break;
default:
}
m2.result=r;
send (m1.source, &m2);
}
}
- 客户端程序
long copy(char *src,char *dst) {
struct message m1;
long position;
long client = 110;
initialize();
position=0;
do {
m1.opcode=READ;
m1.offset=position;
m1.source=client;
m1.count=BUF_SIZE;
strcpy(m1.name,src);
send(FILE_SRVER,&m1);
receice(client,&m1);
if(m1.result<=0)
break;
m1.opcode=WRITE;
m1.offset=position;
m1.count=m1.result;
m1.source=client;
strcpy(m1.name,dst);
send(FILE_SERVER,&m1);
receive(client,&m1);
position+=m1.result;
} while(m1.result>0);
return(m1.result>=0?OK:m1.result);
}
四、分布式体系结构关键技术
4.1 基于消息传递的通信(分布式进程的通信)
4.1.1 发送操作(send primitive)
格式:send(dest;&mptr)
参数:dest——把消息发送具有dest标识符的进程,mptr——表示要发送的消息的地址。
作用:将指定的消息发送到接收进程
4.1.2 接发操作(receive primitive)
格式:receive(addr;&mptr)
参数:addr——等待消息到达的接收进程的地址,mptr——指针,表标消息到后存放何处。
作用:用地址addr侦听,所需的消息。
4.1.3 阻塞(Blocking)操作
阻塞操作也称同步操作(synchronous primitive)
- 阻塞发送操作(Blocking send primitive)
当一个进程调用一个send操作时,它指定一个目标进程和一个缓冲区,调用send后,发送进程便处于阻塞状态,直到消息完全发送完毕,send操作的后继指令才能继续执行。 - 阻塞接收操作(Blocking receive primitive)
当一个进程调用receive操作时,并不返回控制,而是等到把消息实际接收下来并把它放入参数mptr所指示的缓冲区后,才返回控制,并执行该操作的后继指令。在这段时间里进程处于阻塞状态。
特点
- 通信可靠,缓冲区可以重复使用;
- CPU空等,不具有并行性。
4.1.4 非阻塞操作(Nonblocking primitive)
非阻塞操作也称异步操作(asynchronous primitive)
- 非阻塞send操作
如果send操作是非阻塞的,它在消息实际发送之前,就立即把控制返回给调用进程,即发送进程在发送消息时并不进入阻塞状态,它不等消息发送完成就继续执行其后继指令。 - 非阻塞receive操作
当进程调用receive操作时,便告诉内核缓冲区的位置,内核立即返回控制,调用者不阻塞状态。
非阻塞操作的特点
- 提高系统的并行性
发送进程可在消息实际发送过程中进行连续的并行计算,而不是让CPU等待。 - 缓冲区只能使用一次
发送进程在消息发送完之前,进程不能修改缓区,在消息传送期间进程改写消息缓冲区可能引起可怕的后果,而何时允许使用缓冲区,却无法得知。这样缓冲区只能使用一次。
非阻塞操作的两种改进方法
- 带拷贝的非阻塞send操作(Nonblocking with copy to kernel)
让内核把消息拷贝到内核的内部缓冲区,然后允许进程继续运行。
优点:调用进程一旦得到控制,就可以使用缓冲区;消息是否发送完成,对发送进程没有影响。
缺点:每个被发送的消息都要从用户空间拷贝到内核空间(额外拷贝),使系统的性能大大降低其后,网络接口将消息拷贝到硬件传送的缓冲区) - 带中断非阻塞send操作 (Noblocking with interrupt)
当消息发送完毕后,中断发送进程,通知发送进程此时缓冲区可用。
优点:不需要消息的拷贝,从而节省时间;高效且提高了并行性。
缺点:由于用户中断,使编程的难度增加;程序不能再现,给程序调试带来困难;基于中断的程序很难保证正确且出错后几乎不能跟踪。
4.1.5 非缓冲操作(unbuffered primitives)
系统提供一个消息缓冲区,用于存放到来的消息。接收进程调用receive(addr,&mptr)时,机器用地址addr在网上侦听,当消息到来后,内核将它拷贝到缓冲区,并将唤醒接收进程。
- 非缓冲通信操作-抛弃非期望消息 (discard the unexpected message)
receive(addr,&mptr)告诉它所在的机器上的内核,用地址addr 侦听,并准备去接收发送给addr的一个消息,当有消息到达后,如果非该地址的消息则抛弃,否则接收进程的内核将它拷贝到mptr所指示的缓冲区,并唤醒该接收进程。
特点- 一个地址联系一个进程;
- 若服务器调用在客户调用send之前,非常有效。
- 如果send操作在receive之前已经完成,则服务器内核就不知道到达的消息拷贝何处。只好抛弃这个非期望的消息,并采用超时重传机制。
- 假定有两个或更多个客户使用同一个服务器,当服务器从他们之中的一个客户收到一个消息后,在它未完成处理之工作之前,不再用这个地址去侦听发送,在它返回到循环顶部重新调用receive之前,由于要进行相应的处理工作需要花费一些时间而其他客户可能多次尝试发送消息给它,并且有些客户可能放弃。在这种情况下,客户是否继续重发,取决于重 发计时器的值以及他们的忍耐程度。
- 消息丢失的机会大。
- 非缓冲通信操作-消息保留一段时间(keep incoming messages for a little while)
让接收内核对传送来的消息保留一段时间,以便使得一个合适的receice操作能很快地接收:一个非期望的消息到来时,就启动一个计时器,如果计时器在走完之前仍无合适的receive出现,就将该消息丢弃。
特点- 减少消息丢失的机会;
- 如何存储和管理过早到达的消息存在问题。
4.1.6 缓冲通信操作-信箱(mailbox)
一个希望接收消息的进程要告诉内核为其创建一个信箱,并在网络消息包中指定一个可供查询的地址,然后,包含这个地址的所有到达的消息都被放进信箱。现在调用receive就可以从信箱中取出一个消息,如果没有消息就阻塞(假定用阻塞操作)。
特点
- 减少消息丢失和客户放弃消息所引起的一系列问题;
- 信箱是有限的,有可能装满而造成消息的丢失。
4.1.7 不可靠(Unreliable)操作
不可靠send操作:系统不保证消息能被对方正确接收,要想实现可靠的的通信,由用户自己完成。
4.1.8 可靠(Reliable)操作
- REQ—ACK—REP—ACK
客户向服务器发送一个请求(REQ),服务器对这一请求由内核向客户机内核返回一个确认(ACK),当客户机内核接收到这一确认后,释放这一用户进程。
说明- 确认(ACK)只在内核间传递,客户和服务器进程都看不到这样的过程;
- 服务器到客户的应答也存在REP-ACK的过程。
- REQ—REP—ACK
客户在发送一个消息后被阻塞,服务器内核并不返回一个确认(ACK),而是利用应答(REP)本身作为一个确认(ACK),客户如果等待时间太长,其内核可重发一个请求,以防请求消息丢失。客户在收到应答(REP)后,向服务器发送一个确认(ACK),服务器在发送应答后处于阻塞状态,直到确认(ACK from client’s kernel),服务器也可以采用超时重传机制。 - REQ—(ACK—)REP—ACK
是一种折衷的方案:当一个请求到达服务器内核时,就启动一个定时器,如果服务器送回应答足够快(计时器时间未到)则应答(REP)充当一个确认(ACK);如果定时器时间到就送一个单独的确认(ACK)。于是大多数情况下,仅需要两条消息:请求和应答,在复杂情况下,需要另一个确认(Acknowledgement)消息。
4.2 远程过程调用(RPC)
4.2.1 RPC概述
4.2.1.1 RPC的基本思想
(1984年,Birrell,Nelson)允许程序调用位于其他机器上的过程,当机器A上的一个进程调用机器B上的过程时,在A上调用进程被挂起,在B上执行被调用过程,过程所需的参数以消息的形式从调用进程传送到被调用过程,被调用过程处理的结果也以消息的形式返回给调用进程。而对程序员来说,根本没有看出消息传递过程和I/O处理过程,这种方式称为远程过程调用(remote procedure call——RPC)。
4.2.1.2 RPC例子
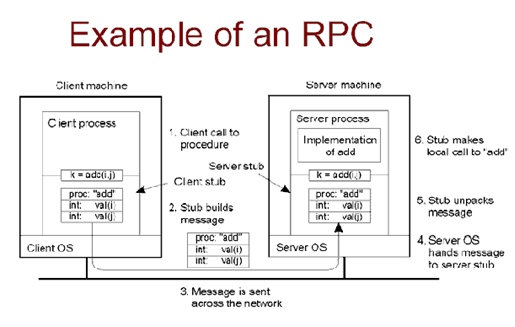
传统的过程调用
count = read(fd, buf, nbytes)
操作系统隐藏了具体的写数据,对程序员来说也看不到这一过程。
参数传递的方式:
- 按值传送(call-by-value)
- 按地址传送(call-by-reference)
- 拷贝/恢复(call-by-copy/restore)
4.2.2 RPC的透明性(transparent)
4.2.2.1 RPC透明性
客户——调用进程所在的机器
服务器——被调用过程所在的机器
RPC透明性的思想使得远程过程调用尽可能象本地调用(内部过程调用)一样,即调用进程不关心也不必知道被调用过程的位置(在本地或远程另一台计算机);反过来也是如此,被调用过程也不关心是哪台机器上的进程调用,只要参数符合要求即可。
4.2.2.1 RPC透明性的实现
- 客户代理(client stub)
将参数封装成消息,
请求内核将消息送给服务器
调用receive操作进入阻塞状态
当消息返回到客户时,内核找到客户进程,消息被复制到缓冲区,并且客户进程解除阻塞
客户代理检查消息,从中取出结果,并将结果复制给它的调用进程 - 服务器代理(server stub)
调用receive操作,处于阻塞状态,并等待消息的到来当消息到达后,代理被唤醒
将消息分解,并取出参数
以通常方式调用服务器的过程
调用结束并获得控制后,把结果封装成消息
调用send操作发送给客户重新调用receive等待下一个消息
RPC的工作步骤
- 客户进程以通常方式调用客户代理
- 客户代理构造一个消息,并自陷进入内核
- 客户内核发送消息给远程内核(服务器)服务器
- 内核把消息送给代理服务器
- 服务器代理从消息中分解出参数,并调用服务器进程
- 服务器进程完成其工作,并返回给代理
- 服务器代理封装结果,并自陷内核
- 远程内核发送消息给客户内核
- 客户内核将消息传给客户代理
- 代理分解消息取出结果,返回给调用进程。
4.2.3 参数传递(Parameter Passing)
客户代理的功能之一是取出参数,将它们封装成消息,然后发送给服务器代理。表面上看,好像很简单,但实现起来并不是如此。下面我们将讨论RPC系统中参数传递的有关问题。
- 参数整理(Parameter Marshaling)
将参数封装成消息的工作 - 参数传递中存在的问题
- 系统中不同机器的字符集可能不同
- 分布式系统中客户机与服务器可以是不同类型的
例如:IBM工作站使用EBCDIC字符集,而 IBM PC机使用ASCii字符集 - 系统中不同机器的数据存储方式可能不同
Intel CPU 整数从右到左存储(小端),SPARC CPU 整数从左到右存储(大端) - 浮点数的位数可能不同
- 布尔值的表示
- 网络传送按字节
解决方案
- 参数按值传递
设置一个基本类型的标准,正则表(canonical form),描述字符集类型,数据存储方式及长度(位数)等。过程所需的参数,客户代理在进行参数整理时按canonical form转换为标准类型,然后封装成消息发送。服务器代理收到消息后,也根据该标准映射到本地机器的字符集和数据类型。 - 参数按地址传递
1:copy/restore方法
2:指出是输入参数(in parameter)还是输出参数(out parameter) - 指针参数的传递
动态传送:指针值存入寄存器,通过寄存器间接寻址 - 用户定义类型的数据传递
4.2.4 动态联编(Dynamic Binding)
问题的提出:客户端如何定位到服务器
方法:动态联编
联编(binder)——一个程序,功能:
- 登记(register)
- 查找(lookup)
- 撤销(unregister)
服务器(export):启动时 register,unregister
客户:lookup
动态性:
- 服务器启动时,export for register
- 服务器关闭时,export for unregister;
- 服务器故障时,定期轮询(客户代理),对无响应的过程 unregister。
联编表(list)
| name | version | handle | unique id |
|---|---|---|---|
| read | 3.1 | 1 | 1 |
| write | 3.1 | 1 | 2 |
| close | 3.1 | 1 | 3 |
动态联编的灵活性(flexible)
- 均衡工作量(load balancing)
支持多服务器(support multiple servers),把客户均衡地分布于各个服务器上; - 容错性(fault tolerance)
定期转询服务器(poll the server perodically),对无响应的过程unregister,到达一定程度的容错性 - 支持权限
服务器可以指定由哪些用户使用,这样联编对非授权的用户拒绝接受。
动态联编的缺点(disadvantages)
- 花费系统时间:the extra overhead of exporting and importing interfaces costs time.(导出和导入接口的额外开销会耗费时间。)
- 客户进程往往执行时间短,但每次每个进程要重新 import to binder(导入动态联编)
- 瓶颈(bottleneck):use multiple binders(使用多重绑定)
4.2.5 RPC表示错误的语义(Semantics in the Presence of Failures)
RPC的设计目标是隐藏通信过程,使得远程过程调用像本地调用一样,但也有一些另外,如不能处理全局变量,事实上,只要客户和服务器能正常工作,RPC就应该可以正常工作。下面的问题是当客户或服务器出错误时的处理方法。
RPC可能出现的错误及处理方法
- 客户不能找到服务器(client cannot locate the server)
客户不能找到合适的服务器,可能原因:服务器可能关闭或服务器软件升级。
这种错误目前尚无好的办法,需要指出,我们不能试图通过返回错误代码来实现,因为代码可能刚好是一个正常的返回值。 - 从客户到服务器的消息丢失(lost request)
客户发出的请求到达服务器之前丢失,服务器根本不能响应。
解决方法:超时重传机制 - 从服务器到客户的应答丢失(lost reply)
丢失应答非常难以处理,简明的解决方法是依赖于超时重传机制,发出的请求在一个合理的时间内没有应答,就再发送一个请求。这种方法的问题是,客户内核无法确定为什么没有应答,是否请求或应答丢失?或许只是服务器速度慢?
同一有效性(idempotent):服务器上有些操作可以安全地重复执行多次,而对数据不影响,如果某一请求的操作具有这一属性,则称为同一有效性(ide不mpotent)。多数请求都不具有同一有效性。
解决方案:客户内核给每个请求一个序列号,服务器内核则保留每个请求最近接收到的序列号。这样,服务器就可以通过这个序列号来区别一个请求是重发的还是原来的,对重传的请求拒绝响应。另外,也可以在消息中增加一个位来提示该请求消息是原来的还是重发的,对于原请求可以安全地进行处理,对于重发的请求,则处理要十分小心(服务器保留一个副本,是一种有效的办法)。 - 服务器接收了请求后崩溃(server crash)
重传机制的语义- 至少一次语义(at least once semantice):客户等等直到服务器重启并再次执行操作:客户继续重试,直到获得一个应答为止。可保证RPC至少执行一次。
- 至多一次语义(at most once semantics):立即放弃报告失败。保证RPC至多执行一次,但可能没有执行。
- 精确一次语义(exactly once semantics):精确一次处理意味着一个消息只处理一次,造成一次的效果,不能多也不能少。
- 客户发送请求后崩溃(client crash)
客户在发送给服务器请求后而在应答收到之前崩溃的情况。
孤报(orphan)及其存在的问题- 孤报(orphan):a computation is active and no parent is waiting for result. Such unwanted computation is call Orphan.(计算是活跃的,并且没有父级在等待结果。这种不需要的计算被称为Orphan。)
- 孤报(orphan)存在的问题:
- 浪费CPU时间;
- Orphan可能锁住某些文件或占用有价值的资源;
- 当客户机重启时,来自Orphan的应答造成应答混乱.
- 孤报(orphan)的解决方法【1981年Nelson提出了四种的解决方法】
- 消灭(extermination)
思想:客户代理在发送RPC消息后,代理进行事务登录(log),记录发送的请求,重启时,检查事务登录,Orphan被撤消。
缺点:磁盘空间浪费;orphan可能引起新的RPC导致更多的orphan,客户重启后,无法找到它们;网络分区:网络被分成两个独立的部分,客户所在的另一个部分中的orphan仍能活动(不是一种可靠的方法)。 - “再生”(reincarnation)
思想:将时间按顺序分成时间段,每一段的一个序号,当客户重启时,广播一个消息告诉所有的主机新的时间段的开始。机器收到这样的广播消息后, 所有的过程计算被撤消。对于已发出的应答,由于消息中含有时间段序号而客户可以很容易地区别它们。
缺点:那些有效的计算也被删除 - 合理再生(Reasonable regeneration)
思想:当机器收到新的时间段的广播广消息后,每台机器检查是否有远程计算,如果有则试着找出它们的客户,若能找到客户(主人),则继续它的计算,否则将远程计算撤消。
缺点:系统开销大。 - 期满(expiration)
思想:每个RPC都给对方一个标准的时间量T,来作为它的工作期限,如果它在T时间内不能完成工作,客户必须重新请求,以保证每个RPC就可以在T时间内完成。当有客户崩溃后,在客户机重起之前等待一个时间量T,这样可保证所有的Orphan已发送。
缺点:时间量T的取值比较复杂。
- 消灭(extermination)
4.2.6 RPC的实现
4.2.6.1 RPC协议是选择面向连接的还是非连接的协议
- 面向连接的协议
优点:通信实现容易:内核发送消息后,它不必关心它是否会丢失,也无须处理确认,而这些方面都由支持连接的软件来实现。
缺点:性能较差(需要额外的软件)。 - 面向非连接的协议
优点:性能较好
缺点:信息可能丢失
在单一建筑物和校园内使用的分布式系统可以采用面向连接的协议。
4.2.6.2 RPC协议是选择标准通用的还是RPC专用的协议
要使用自定义的RPC协议就得完全自己设计一些分布式系统使用IP(or UDP)作为基本协议,原因是:IP/UFP协议已经设计,可节约相当可观的工作消息包可在几乎所有的Unix系统中传送和接收IP/UDP消息支持许多现存的网络总之,IP/UDP很容易使用,并且适合现存的Unix系统和网络关于性能,IP是无连接的协议,在它之上可建立起可靠的TCP协议(面向连接的),IP协议支持网关的报文分组,使报文从一介网络进入另一个网络(物理网络)。
4.2.6.3 确认机制(Acknowledgement)
- stop-and-wait protocol
思想:逐包确认。
特点:一个包丢失了,可独立重传;容易实现。 - blast protocol
思想:一个消息的所有包都发送完成后等待一个确认,而不是一个一个确认。
特点:报文丢失时,有两种选择:- 全部放弃:等待重传整个消息的所有包,容易实现;
- 选择重传:请求丢失包重传,占用网络的带宽少。(对局域网这种方法较少使用,广域网络普遍采用)。
4.2.6.4 流量控制(flow control)
通常网络接口芯片可以接收连续不断到来的包,但是由于芯片中缓冲区的限制,总是对连续到来的包的个数有个数量限制"超载"(overrun):一个消息到来而接收它的机器无法接收,以至于到来的消息丢失。超载是一个很严重的问题,它比因噪声等其他破坏引来的包丢失普遍得多。
上面两种确认机制对超载问题有所不同
- stop-and-wait protocol(超载的可能性小)
因为第二个包在没有收到明确的确认之前不能被收送。(在拥有多个发送用户的情况下可能存在) - blast protocol(接收方超载是很可能的)
- 由于网络接口芯片引起的超载(因接收方处理一个进程而来不及处理到来的消息包)。
解决方法:- 忙等待:CPU空操作,应用短延时的网络环境;
- 中断:发送进程挂起,CPU重新调度,应用在长延时网络环境;
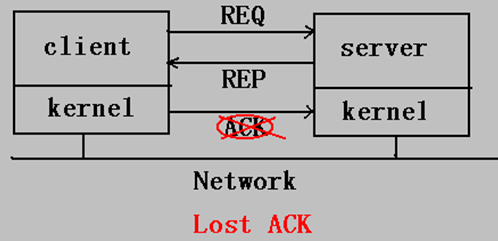
- 由于网络接口芯片缓冲区容量引起的超载
解决方法:设有n个缓冲容量,发送进程每连接发送n个消息包时,便等待一个确认(由协议完成)确认丢失问题(lost ACK)
- 由于网络接口芯片引起的超载(因接收方处理一个进程而来不及处理到来的消息包)。
图中"ACK"包丢失,造成的问题。
解决:对确认(ACK)进行确认(ACK),“超时确认”。
4.2.6.5 临界路径(critical path)
分布式系统是否成功依赖于它的性能的好坏,而系统性能的好坏又依赖于它的通信速度,通信速度与系统的具体实现有关,下面我们进一步讨论从客户到服务器执行一个RPC的过程。
临界路径(critical path):每个RPC的指令执行的顺序是从客户调用客户代理,自陷进入内核,消息传送,服务器中断,服务器代理,最后到达进行请求处理并返回应答的服务器。RPC的这一系列步骤称为(从客户到服务器的)临界路径。临界路径(critical path)图示
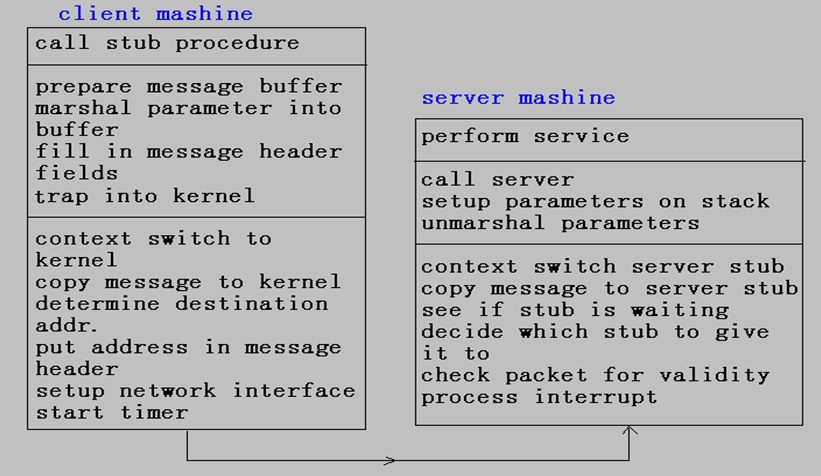
- 客户调用 stub procedure
申请一个缓冲区用来整理外出的消息,有些系统有一定数量的缓冲区,也有一些是一个缓冲区池,从中选择一个合适的供服务器使用。 - 参数整理
参数整理成适合的格式,并与消息一起插入消息缓冲区中。以备传送,自陷进入内核。 - 切换进入内核
内核获得控制,保存CPU寄存器及内存映像,建立新的内存映像。 - 拷贝消息到内核
因为用户和内核是不连接的,内核必须明确地把拷贝到内核缓冲区。 - 填入目标地址
将其拷贝到网络接口,到此客户临界结束。
原则上,启动计时器不属于计算RPC时间的部分,启动计时机后,系统有两种方式:忙等待和重新调度。
在服务器端,当字节到达后,被存入板上缓冲区或主存,当消息包的所有字节都到达后,服务器将形成一个中断。
检查消息包的有效性,并决定将其送给一个代理,若没有等待的代理则放弃或保存至缓冲区。
假定有一个等待的代理,那么,消息被拷贝到代理并切换到服务器代理,恢复寄存器及主存映像,代理调用receive原语,分解参数,建立服务器的调用环境,进行请求处理。
临界路径(critical path)的开销-拷贝
在考虑临界路径的时间开销问题时,其中最重大的部分是拷贝
- copy1:客户代理->内核
- copy2:内核->网络接口板
- copy3:网络接口板->目标机器
- copy4:网络接口板->内核
- copy5:内核->服务器代理。
4.2.6.6 定时管理(timer)
所有的协议都是以通过通信介质交换消息为目的的,而事实上,所有的系统中,消息都有可能丢失,或许是因为噪声或是超载。所以,多数协议都设置定时器,当消息发送出去后,期待应答(确认)的到来,若没有消息到来而定时器期满(expiration),则重发。这个过程可以重复几直到发送方放弃。
设置定时器:建立一个数据结构来指定定时器何时期满,以及期满时如何处理。
多个进程的定时器组织成列表方式:
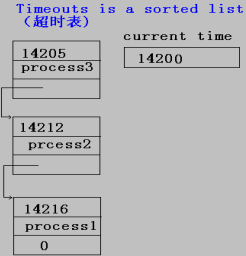
当一个确认或应答在超时之前到来,列表中查出对应进程所在的项,将它删除,实际上,只有少数的进程可能超时,但每一个进程都要进入超时表后再删除,这些大量的工作多数是多余的。另外,定时器也不需要精确的时间,但定时太短引起过多的超时,定时太长则对包丢失的情况又过多的等待。
实现方法:
在PCB中增加一个字段,称为定时器,当发出一个RPC时,将允许延迟的时间加上当前的时钟的值并存于PCB中定时器字段,如果不需要超时重传的,其值规定为0,这样,内核定期扫描PCB链表,如果定时器值非0且小于当前时间,则该进程超时。
4.2.7 RPC与消息传递通信的比较
RPC结构性好,使用方便,消息传递通信更灵活,但结构性差。RPC只有一个返回,而消息传递通信可以向多个客户返回。RPC返回的结果或参数的值最好是少量的,消息传递通信可适合于大批量数据的传递。
4.3 分布式同步算法
4.3.1 逻辑时钟(Logical Clocks)
时间在同步中起重要的作用,首先,我们来看分布式系统中时间的度量(measured)。
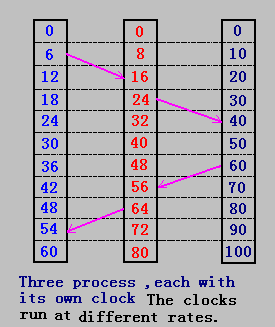
几乎所有的计算机是使用电路来记录时间,尽管普遍使用时钟这个概念来表示这些设备,但它们并不是真正意义是的时钟(clock),更确切地说,计算机中使用的只是计时器(timer),由有规律振荡的晶体来产生。因为加工工艺等原因,不可能有两个晶体时钟是一致,从而不同的计算机其时钟不可能完全一样。
假使两台或几台机器时钟可以非常精确,但大型分布式系统允许两台机器仅次于地球的两个时区上,这样它们的时钟仍是不一致的。
因此,在分布式系统中,需要考虑另一种时间的度量,即逻辑时钟。在这方面有重大贡献的是Lamport,他在1978年提出时钟同步是可能的,并给出一些算法,这些观点为分布式系统奠定了重要的理论基础。
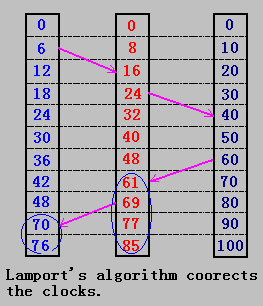
4.3.2 Lamport 算法
Lamport指出:时钟同步不需要绝对的(精确时间),如果进程间没有相互作用,就不需要时钟同步。并且进程所关心的不是什么时间做什么工作(由于进程的运行过程由多种因素决定,有不确定性),它们所关心的是事件发生的顺序。
思想:
- happen before
如果事件a是在事件b之前发生,则记a->b,即a happen before b。特别地,在一次通信中,如果发送进程发送消息的事件是a,接收进程接收消息的事件为b,则a->b。
happen before 是可传递的,即如果a->b、b->c,则a->c。 - timestamp
在分布式系统中,每一台机器都设置一个整型变量作为“时钟”(它并不是真实的时钟),当一个事件a发生时,用这个时钟的值作为事件a的timestamp(时间戳),记作C(a)。这样,如果a->b,则C(a)<C(b);在同一机器上的任两个事件a和b,都有C(a) != C(b);
在进程通信中,消息中含有发送时的时间戳,消息到达目标机器时,它的内核检查其时间戳,如果它的当前时钟小于所收到消息的时间戳,则修改它的时钟,使其时钟值大于接收消息的时间戳。
Lamport算法-逻辑时钟修改
个人理解:
- 如果接收的时间戳大于自身的的时间戳,则修改自身时间戳为接收的时间戳+1;
- 如果增加了自身的时间戳则后续的时间戳也需要增加相同的增量(增量可以由自身时间戳间隔确定)
4.4 分布式互斥算法
4.4.1 集中式算法
【在分布式系统中最直接的方法是模仿单处理器系统中的作法实现互斥】
基本思想
指定一个进程为协调者(Coordinator),当一个进程要进入临界区时,它发送一个请求消息给协调者进程表示它的要进入临界区并要求给一个许可(permission),如果当前没有进程在临界区执行,协调者进程返回一介许可的应答,当许可的应答收到时,要求进程则可以进入执行,当它的临界区执行完成时,再发送一个要求释放临界区的消息。【向协调者申请许可,谁有许可谁进入临界区,退出临界区,归还许可】
优点
- 可以保证临界区的互斥
- 具有公平性(fare)
- 容易实现
- 可以用于其他的资源分配
缺点
- 协调者进程的错误将使用整个系统无法工作
- 死锁不容易检测
- 协调者进程可能出现瓶颈
4.4.2 Ricart & Agrawala’s算法
基本思想
当一个进程要进入临界区时,它建立一个包含它要进入的临界区名、进程号、和当前时间戳(timestamp),并把消息发送给所有的进程,理论上也包括它自己,消息传送是可靠的,每个消息要求有确认,如果网络支持可靠的组通信,则可用于代替单个的通信。
当一个进程收到另一个进程的一个请求时,它采取的工作依赖于消息中临界区名,这有三种情况:
- 如果它不在相关临界区内,并且也不想进入,它返回一个许可(OK)的应答;
- 如果它已经在临界区内,它不返回任何应答,而是将消息加入场专门的请求队列中;
- 如果它想进入临界区执行(但前还没有进入),它把消息中的时间戳,与它发送给其他进程的请求消息的时间戳进行比较,时间戳小的则获得进入临界区的许可。如果当前收到的消息的时间戳小,就发送一个OK消息,否则,如果进程自己发送的消息中的时间戳小,就不做发送任何消息而是将收到的请求加入请求队列中。【先来先进,自身时间戳小于收到的时间戳,则执行情况2;否则,执行情况1;】
进程在发送了请求进入临界区的请求消息后,就等待其他进程的许可(OK)消息,一旦它得到所有进程的许可(OK),就可以进入临界区执行。
进程退出临界区时,向在该进程的请求队列中的所有进程发送OK消息,并从队列中删除这些进程的请求消息。【告诉请求队列的进程我退出临界区】
优点:
- 可以实现互斥,并保证不出现死锁(deadlock)或饿死(starvation)【本质是先来先服务,不会发生死锁和饿死】
缺点:
- 每次请求进入临界区要2(n-1)次通信(假定系统中的n个进程)【向n-1个进程发送请求,接收n-1个进程的ok消息,一共2(n-1)】
- 任何一个进程的崩溃,将使用算法无法完成
4.4.3 令牌环算法(Token Ring)
基本思想
【所有进程围成一个圆,令牌在圆中依次传递,在谁手上谁可以访问临界区,不需要访问临界区或者退出临界区,则把令牌给下一个进程】
将系统中所有进程建立一个逻辑环(logical ring),环中进程的顺序可以按进程地址排序或其他方法排序,只要环中一进程能知道它的下一个进程是谁即可。
环被初始化后,进程0得到一个令牌(Token),令牌沿环逐个下传,从k到中k+1(当k+1为环中进程时取0)。
当一个进程从它的上一个得到令牌时, 如果它要进入临界区,则就可以进入执行,临界区执行完成后,再把令牌传给下一个。
每获得一个令牌,至多只能执行一个临界区。
优点
- 可以实现互斥,不会出现饿死
缺点
- 令牌丢失时要建立一个新的令牌,但很难确认是否已经丢失
- 任何一个进程的崩溃,将使用算法无法完成
4.4.4 三种算法的比较
| 进/出临界区花费的代价 | 进入临界区等待时间 | 问题 | |
|---|---|---|---|
| 集中式算法 | 3 | 2 | 协调者奔溃 |
| RA算法(分布式算法) | 2 (n-1) | 2 (n-1) | 任一进程奔溃 |
| 令牌环算法 | 1 — ∞ \infin ∞ | 0 — (n-1) | 令牌丢失、任一进程奔溃 |
次数说明:
【3次 —— 申请许可、给予许可、返回确认】【2次 —— 申请许可、收到许可】
【2(n-1) —— 向n-1个进程发送请求,接收n-1个进程的ok消息,一共2(n-1)】
【1 —
∞
\infin
∞ —— 1 表示令牌传递需要一次,无穷 表示 即使当前所有进程都没有申请进入临界区运行,令牌也要沿环不断地传递;因此,当一个进程要进入临界区执行是,令牌消息传递的个数是不确定的,可以有任意多次,即 无穷。】【0 — (n-1) —— 0表示令牌刚好在手上,n-1 表示令牌刚好传递给下一个进程】
4.5 分布式系统的可靠性
4.5.1 选择算法(Elect Algoriathms)
在分布式系统的许多算法中都要有一个进程充当协调者、发起者、序列生成器、或其他特殊的角色,如集中式(互斥)算法中的协调者进程。通常,由哪个进程充当这个角色均可,但总得有一个进程来承担。这一节介绍选择这种协调者的算法即选择算法。
几个假定
- 系统中每一个进程都有一个唯一的标识,如进程号;
- 系统中每个进程都知道其他进程的标识,但为些进程可能是活动的,也可能是关闭或崩溃;
- 选择算法的目标:保证在选择算法执行后,所有进程都认可某个进程成为了新的协调者。
Bull算法
当某个进程发现协调者(Coordinator)无法响应它的请求时,该进程就启动一个选择过程。进程P,执行的选择过程如下:
- P向所有的进程号(优先级)比它高的进程发送Election消息;
- 如果得不到其他进程的响应,进程P获胜,成为协调者;
- 如果有一个进程号(优先级)更高的进程响应,该进程就接管选择过程。进程P的任务完成;
任何时刻进程都可能收到进程号(优先级)比它小的进程发送来的Election消息,该消息到达时,消息的接收者就向发送者发送一个OK消息,说明它仍是活动进程,而且它将接管选择过程。接收者接管选择过程,除非它已经接管一个选择;最后,其他进程都放弃只剩一个进程时,该进程成为新的协调者,然后它向所有的进程发送消息,通知这些进程从此刻起,它是新的协调者。
环算法(Ring Algorithm)
对所有进程进行物理或逻辑的排序,这样每个进程都知道它的下一个进程是谁。
任何一个进程发现协调者不起作用时,就创建一个包含该进程号(优先级)的Election消息,并将该消息发送给它的下一个(即后继)进程;
如果后继进程已经中止,就跳过它发送给下一个,依此类推,直到找到一个活动进程为止;
每个进程收到Election消息时,就将自己的进程号(和优先级)加入到Election消息的进程表中;
最后Election消息会回到创建它的进程(通过判断进程表中是否含的自己的进程号),它从进程表中选择最大进程号(或优先级)的进程作为新的协调者,并构造一个Coordinator消息通知所有其他进程。
4.5.2 k-容错技术
如果系统允许有k个组件出错,而仍能正常工作,这种容错技术称为k-容错技术。那么,Fail-silent faults【非拜占庭失败】须提供k+1个备份。Byzantine Faults则须提供2k+1个备份。
“两支军队”问题(two-army problem)
【说明即使两个处理器是正常的,但它们要达成一致的意见是困难的。】
一支红色军队,5000人,驻在山谷。两支蓝色的军队,每支3000人,驻扎在山角监视着山谷。两支蓝色的军队只有同时向红色军队发动进攻,才能获胜,任何一支单独出击都将失败。现在,两支蓝色军队的目标就是对进攻的时间达成一致的意见,然而他们的协同只能通过互派信使来交换意见,但信使随时可能被俘虏。
假设一支蓝色军队的将军Alxander,决定在第二天凌晨2:00进攻,并派出一个信使将这个决定通知另一支蓝色军队的将军Bonaparte,之后就下达自己的军队,准备第二天凌晨2:00进攻;
然而,到了第二于凌晨,Alexander担心,Bonaparte不知道信使已经安全返回,可能不会轻易进攻,结果,Alexander又派一个信使把确认的消息传给Bonaparte;假如信使也安全到达Bonaparte,这时,轮到Bonparte担心,Alexander不知道确认是否安全到达,可能不会按时进攻。这样Bonaparte只好也派一个信使将确认通知Alexander。
这样,两个将军将来回确认,永远无法到成协议。因为最后一个发送消息的人不知道消息为对方接收,如果最后一个消息丢失,则所有协议都无效,无法进攻,并进入死循环。
问题是:通信是不可靠的,下列我们假设通信是完善可靠的,仅仅是处理器可能出错。
Byzantine generals problem 【拜占庭失败问题】
一支红色军队安营在山谷中,有n个将军率领n支蓝色军队扎营在山下周围,他们可以点对点完善地通信。假设其中有m(m<n)个将军可能是是背叛者(出错),并且阻碍军队达成一致的意见(修改消息),现在问题是正规军(非背叛的)能否达成协同?
不失一般性,我们把这里的协同的含义稍作修改,即假设每个将军都掌握自己的军队的力量,问题的目标是各个将军能交换他们的部队力量,这样,算法结束时,每个将军就有一个向量表示盟军的力量, 如果将军是正规军,用i表示他的军队的力量,否则没有定义。
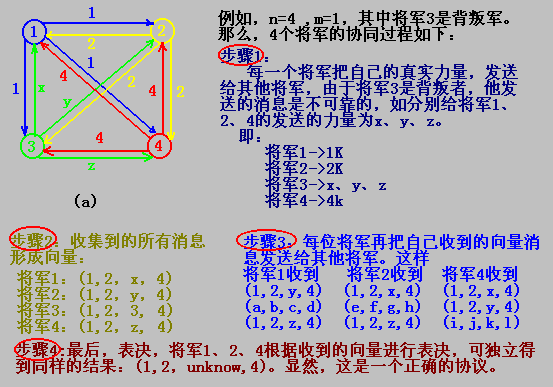
现在来看另一个例子
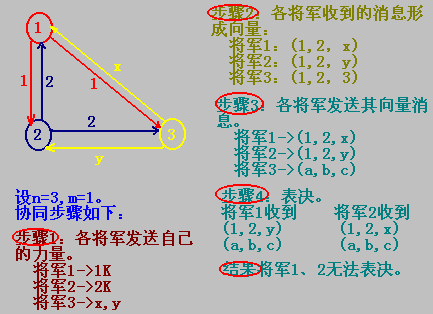
1982年,Lamport证明在一个系统中,有m个出错的处理器时,协同形成需要2m+1个正常工作的处理器,即总数是3m+1。协同形成需要约三分之二的人通过。
4.5.3 表决算法(voting algorithm)
表决技术(votings)
客户读或写一个备份文件的操作前,先向所有的服务器发送请求,并得到多数服务器的许可后才能进行。
设备份服务器有N个,并规定客户对备份文件的更新要经多数服务器的许可,即至少(N+1)/2个服务器的许可后,存取工作才可以进行,复制文件并形成新的版本(具有一版本号,对新修改的备份文件其版本号应该是相同的。)
“许可”,可以是一个含有版本号的应答消息。
这样,读一个备份文件的步骤是:
- 向至少半数以上的服务器([N+1]/2)发送读操作请求消息,要求返回文件的版本号
- 如果所有的返回版本号是一致的,则说明该版本号是最近的,文件是最新的。因为其余的服务器个数不足半数,如果他们的版本号高,则说明其更新操作是无效的。如果更低,则说明上一次访问操作已经确认,只是这些服务器尚未更新。
例如,有5个服务器,某客户得到3个服务器的版本号是8,则其余的两个服务器的版本号不可能是9,因为版本号从8到9要得到半数以上的服务器的许多,而不是2个。
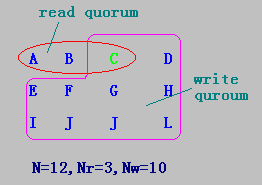
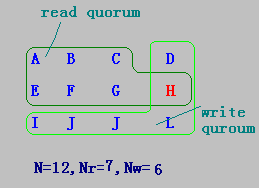
表决算法(voting algorithm)
某文件系统有N个备份服务器,定义Nr和Nw分别表示读法定人数(read quorum)和写法定人数(write quorum):
- 当客户的一个读操作得到Nr个服务器的相同版本号的许可时,可执行该读操作;
- 当客户的一个写操作从Nw个服务器中得到相同的版本号的许可时,则可执行该写操作。
- 其中Nr+Nw>N。
例子
-
N=12,Nr=3,Nw=10
-
N=12,Nr=7,Nw=6
-
N=12,Nr=1,Nw=12
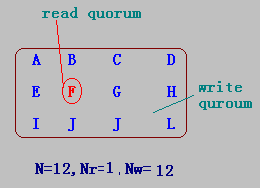
特别地,Nr=1,Nw=12,意味着写操作要求所有的服务器表决,则读操作可以从中任选一个。
说明
- 由于读操作比写操作更经常发生,为提高算法效率,可规定Nr<Nw。
- 当Nw接近N时,只要少数服务器的关闭,写操作就不能允许。
4.6 习题
- 在分布式令牌环互斥算法中,一个进程进入临界区执行需要令牌消息传递的个数是
1
−
∞
1-\infin
1−∞ ,解释这里
∞
\infin
∞ 的含义。
在分布式令牌环互斥算法中,算法保持一个令牌在环中传递,一个进程只有在得到令牌时才能进入临界区执行,以便实现互斥;即使当前所有进程都没有申请进入临界区运行,令牌也要沿环不断地传递;因此,当一个进程要进入临界区执行是,令牌消息传递的个数是不确定的,可以有任意多次,即 ∞ \infin ∞ 。 - 解释RPC透明性的含义。
使得远程过程调用尽可能象本地调用(内部过程调用)一样,即调用进程不关心也不必知道被调用过程的位置(在本地或远程另一台计算机);反过来也是如此,被调用过程也不关心是哪台机器上的进程调用,只要参数符合要求即可。 - PRC中客户代理(client stub)实现什么主要功能?
将参数封装成消息;请求内核将消息送给服务器;调用receive操作进入阻塞状态;当消息返回到客户时,内核找到客户进程,消息被复制到缓冲区,并且客户进程解除阻塞;客户代理检查消息,从中取出结果,并将结果复制给它的调用进程
五、层次结构分析
5.1 线程技术
5.1.1 引入线程的目的
- 系统工作单位的粒度减小,提高并行程度
- 减少处理器切换的开销
5.1.2 线程的概念
进程的有效细化,是进程内可独立执行(调度)的实体。
5.1.3 线程与进程的区别、联系
- 一个进程可分为多个线程,这些线程共享同一个进程的地址空间
- 进程的活动由它的线程的活动来体现
- 只有一个线程的进程与进程没有区别
- 同一个进程的几个线程之间需要同步控制
- 线程可以并发执行,也可以并行执行(多CPU时)
- 进程是资源分配的基本单位,线程是处理器分配、调度的基本单位
- 进程的地址空间是私有的,进程间的处理器切换时现场的保护/恢复的开销大;而同一进程的线程之间进程处理器切换时现场的保护/恢复的开销小
5.1.4 线程的分类
- 用户级线程
- 线程的管理是在用户空间实现
- 可以在不支持线程的OS中实现
- 线程间切换不要进程内核,减小系统的开销
- 未能实现并行程序的提高
- 系统级线程
- 线程的管理由OS实现
- 并行程度得到提高
- 但在内核的切换影响到系统开销
5.1.5 线程的执行特性
- 线程的生命期-动态性
派生、阻塞、激活、调度、结束 - 线程的同步
同一进程的线程共享该进程的地址空间,需要同步或互斥
5.1.6 线程的应用
- 服务器:文件系统或通信
- 分派/处理结构(dispath/worker)
- 队列结构(Team)
- 管道结构(Pipe)
- 客户:前后台处理
- 异步处理:进程中若有两个或多个任务,它们之间的处理顺序没有规定,则每个任务可以由一个线程处理
5.2 服务器缓冲技术
5.2.1 无状态信息(Stateless)服务器
当一个客户发送的一个请求给服务器时,服务器执行请求,返回结果,然后删除该请求的有关所有信息,这样的一个服务器称为无状态信息的。
5.2.2 有状态信息(State)服务器
有状态信息服务器(Stateful information server):文件服务器拥有打开、关闭、读、写等操作,当一个文件被打开后,服务器将保存是哪一个客户打开的,打开的是哪一个文件,并生成一个文件描述符(file discroptor)。
一个客户如果已经打开了一个文件,那么它的后续操作,只要给出文件描述符及有关的参数即可,服务器收到请求后,根据文件描述符就知道哪一个文件。
状态信息(Stateful information)是一个映射表,文件描述符映射到它的文件。
5.2.3 无状态服务器与有状态服务器的比较
对于无状态服务器
- 每一个请求都要求是完备的、独立的,包含完整的文件名、偏移量,以便服务器的工作,请求消息长度增加。
- 无状态信息服务器具有更高的容错性。
- Open/Close调用没有必要,从而减少传送消息的次数。
- 服务器不会因为保留状态信息而浪费空间,因为某一时刻当有大量客户要打开大量文件时,表将填满而新文件不能打开,客户的请求得不到服务,正确的程序将不能正确地工作,无状态信息服务器将消除这个问题。
- 客户机崩溃也不会产生问题。
- 文件加锁是不可能的,因为无状态可登记,这种情况下,无状态信息服务器不得不使用加锁服务器。
对于有状态信息服务器
- Read/Write消息中不必包含文件名,它们的长度将缩短,从而占用更少的网络带宽;
- 由于打开的文件在内存中,读、写操作速度更快,性能得到提高;
- 因为更经常的是读操作,所以可以事先成块读到内存而减少延时;
- 同一有效性容易实现,如果客户因超时重传同样的请求,服务器有两个接收的情况下,由于内存中保存了状态信息,很容易通过比较每个消息的序号而发现;
- 文件加锁是可能的。
5.3 N层结构的特性
【层次结构是解决复杂问题时最常用的软件结构】
5.3.1 层次结构设计
- 层次
- 完成若干功能或服务的模块,这些功能具有独立性;
- 一个层次是一个服务的提供者;
- 一个层次还可以进一步分层;
- 层次间的单向依赖关系
同一系统的层次之间构成单向的依赖关系,一个层次依赖于较低的层次。这种依赖关系是通过接口实现的。 - 层次的隐藏性
层次间的单向依赖关系使得每个层次具有隐藏性。一个层次可以隐藏其内部的实现细节,向上提供一个一致的服务。使高层次可以不必了解低层次的细节,如物理特性、存储方式、位置等。 - 分层的原则
第n层存在的必要性:它对n-1进一步完善和扩充,并提供n+1的服务接口更简单可靠。从这个意义上说,层次的隐藏性是不完全的,如果第n层中的一项服务已经足够完善,则该服务就不必在n+1层中继续存在,这样,第n+2层在需要该服务时可直接使用第n层中的服务。
5.3.2 软件系统的层次结构
【研究表明,任何软件的完整结构都具有层次关系】
- 硬件基础层
这是软件得以运行的物质基础,它包括:处理器、存储器、时钟、中断及其控制、I/O端口、I/O通道、快速缓存、DMA等。软件是针对特定硬件的构成而设计的,反映对硬件的支持的需要,即硬件发生变化后,原则上软件也需要做出相应的为变更。 - 软化的硬件层
在对硬件结构和性能进行描述的基础上,实现硬件的操作和控制描述,这就是软化的硬件层。在该层次上,处理器被软化为状态和指令的集合,中断被描述为状态和中断服务的集合等。该层是软件构成的基础,其程序设计工具主要是汇编语言(assemble language)。 - 基础控制描述层
主要包括高级语言的所支持的程序控制和数据描述。程序控制的概念有:顺序、条件、选择、循环、变量、参数、生存期、程序、过程/函数等,数据描述的概念有:数组、结构/记录、队列、树、图、指针等,以及面向对象中的类、对象、继承、多态、重载等。该层次的工具是程序设计语言、结构化或面向对象的分析设计。 - 资源和管理层
在基础控制要描述层建立的一切对象和数据都需要在操作系统的协调和控制下才能实际地实现其设计的作用和功能。该层提供了基于操作系统结构的任务管理、消息处理、系统输入/输出控制,其他系统级别的资源和功能服务。该层的某些服务的定义在基础控制描述层中,但功能的实现是建立在操作系统管理层的。 - 系统结构模型层
我们知道,软件体系结构是软件的“高层(high level)结构”,该层包括的概念如:解释器、管道/过滤器,C/S、黑板等 - 应用层
这是纯粹从应用领域出发所建立的系统结构概念,该层包括的概念如:企业管理、公文处理、控制系统、CAD系统等。

N层结构——C/S或B/S结构称为2层结构,我们把层次结构中3层或3层以上统称为N层结构。
5.4 N层结构的实现
一个产品的软件体系结构风格如果采用N层结构。则可能按下面的步骤实施:
- 定义为合适的分层而采取的抽象标准:在软件开发中,根据距硬件接近或距应用接近的程度建立分层,比如某个应用可能建立如下的分层:用户界面、特定功能模块、公共服务、操作系统接口、操作系统、硬件层。
- 抽象标准决定模型层次的数目:分层的原则是对于第n+1层来说,如果第n层提供的功能不会比第n-1层简单,则第n层就不必存在。
- 给每个层次命名和分配任务:在层次结构中最高层的任务就是整个系统从用户出发的任务。如果采用自底向上的设计方法,较高层次是建立在较低层次之上的,这要求对系统具有丰富的经验和敏锐的洞察力,以便在确定高层前找到低层次的合适抽象。
- 规范服务:层次之间要严格分开,确保没有部件会跨越两层以上,层J函数的参数、返回值和错误类型者应限定在程序语言的类型、层J定义的类型或从共享数据模块中引用的类型。
- 为每个层次定义接口:在层J中定义一套良好的供层J+1层使用的服务接口(interface),使用层J+1看不到层J对接口对应的服务的实现细节,
- 设计错误处理策略:尽可能把错误处理在更低层次上,避免高陷入更多的错误。
例如:
Window NT的层次结构
- 系统服务层
- 资源管理层
- 内核
- 硬件抽象层
- 硬件层
5.5 N层结构的优缺点
优点
- 层次的利用性:如果层次中很好地体现了抽象、并且具有定义良好、文档化的接口,那么该层能在多个环境中使用。
- 对标准化的支持:清晰定义并广泛接受的抽象层次能够促进实现标准化的任务和接口开发,相同接口的不同实现能够互换使用,这样就允许在不同的层使用来自不同组织的产品。
- 依赖性本地化:层次的标准接口通常把代码的变化的影响限制在其所在的层次上,支持了系统的可移植性和可测试性。
- 可替换性:独立层次的实现能够轻易地被功能相同的模块替换。如果层次之间的联系在代码中是固定的,那么联系能够根据新层次实现的名称来更新。比如,硬件的可替换性,新的硬件I/O设备通过安装正确的驱动程序就能够使用,互操作性不影响高层次,高层次的接口不要改变,可以像以前一样继续向低层请求服务。
- 位置透明性:通常低层次把服务所在的网络物理位置隐藏起来,使高层次的请求可以不关心其服务是在本地或是在远程。
缺点
- 改变行为的连锁效应:当某个层次的构成和行为发生变化时会生产生严重的连锁效应,在维护升级时,如果必须在许多层次上做大量的工作,那么层次结构将变成一种缺点。
- 低效率:分层结构通常要比单层结构的效率低。如果高层服务严重地依赖于底层服务,那么必须穿越许多中间层进行数据的拷贝。
- 分层是有限制的:并不是所有的产品都可以分层,同一产品需要分成几个层次没有统一的标准。
5.6 一个用于构造分布式系统的层次结构设计

5.6.1 表示层——用户界面技术
【划分UIC和UIPC,进一步抽象,提高代码的重用性和降低模块的耦合度】
【UI与UI之间的调用的代码不要写在UIC中,由UIP处理,提高重用性】
- UI——用户和应用进行交互的接口
提供的功能- 输入方面
- 辅助用户输入,提供各种提示和帮助,在输入的同时会有一些校验,如日期等
- 响应用户操作所触发的各种事件(可能会展现出其他的UI)。
- 限制用户的输入,在数据改变的时候,可能会有一些相关联的操作(如,单价的改变,影响到总价)。
- 处理一些特殊的操作(如drap-drop,剪贴板等)
- 输出方面
- 格式化数据(如金额、日期等)
- 特殊显示(坏帐号用特殊颜色标识出来)
- 将一些编码转换成有意义的名称
- 个性化(Web页面,Winfrom(dialog,MDI,SDI))
- 其他(状态、分页显示查询结果等)
- 输入方面
- UIPC——处理用户UI的流程控制
- MVC模型

- View——用户操作界面
- Model——内部数据结构,状态数据
- Controller——控制流程,UIPC的核心
- 什么是UIPC
根据状态改变决定使用哪一个UI。
应用场景:- 有些UI之间的相互作用,存在明确的处理顺序(向导界面的上一、下一等,购物网站的浏览、选择并加入购物车到收银台结帐)。处理这种流程的控制器称为UIP
- 这些类型的界面操作的特点:
- 用户操作流程可以用一张流程(导航)图来描述)
- 导航图上每一个节点是一个用户界面(窗口、页面)
- 界面之间的跳转由用户操作触发的
- UIPC的好处
- 隔离UI与业务逻辑层
- 对流程中的UI进行管理
- 提供状态保存和传递机制
- 状态保存
Server状态和Client状态,状态有效期? - Smart Client
- 智能安装和版本更新
- Connected。选择一个合适的有效的Service
- 能够利用本地资源(CPU、HD等)
- 离线能力。在不连接网络上工作,连线时提交数据
- MVC模型
5.6.2 业务逻辑层——应用系统的核心
- Business Component
- 含义
实现业务规则及执行业务工作的组件,负责发起事务,实现业务功能。 - 特点
- 由用户处理层的UIPC、服务接口、以及其他业务组件调用,包含一些业务数据和操作,以及复杂的数据结构
- 是事务的发起者,参与事务的提交
- 必须验证输入和输出
- 通过调用数据层组件获取数据或修改应用数据
- 设计
- PIPELine Parttern,顺序规定
- Event Parttern,顺序不固定
- 含义
- Business Workflow
- 含义
- 具有各种不同功能的活动相连的一组有相互绕道而行关系的任务。
- 业务流程有起点和终点,而且它们都是可重复的
- 由多个Business Components组成,有一定的顺序。
- 特点
- 迅速实现商业规则和商业目标的改变的能力
- 将每一步业务操作、资源管理以及流程独立分离
- 以前后一致的方式定义、改变和实现业务流程
- 种类
- 基本于人的业务流程:他要完成、批准、执行的文档
- 基于规则的自动化流程:应用程度彼此连接,在无人干预的情况下进行合作
- 实现
- 流程引擎--Business Workflow的核心
实现业务流程,同时管理活动的启动和终止,或业务功能 - 资源管理
使实现商业功能或活动所必须的资源具有可用性 - 调度程序
资源可用性的限制,商业功能经常受时间约束,需要调度程序以使时间约束和资源可用性相匹配 - 审计管理
关键组件,跟踪谁操作什么 - 安全管理
资格授权
- 流程引擎--Business Workflow的核心
- 含义
- Business interface
- 含义
服务接口是一组软件实体,为实现处理映射和转换服务的外观组件(facade),把业务逻辑表现为服务,为服务提供进入点。 - 作用
- 提供业务处理的调用点
- 实现缓冲、映射、以及简单的格式和结构转换
- 不实现业务逻辑
- 进行信息安全控制,有的需要安全身份验证
- 分隔内部系统的实现
- 对内部实现进行更新时,不需要变更服务接口
- 需要验证传入的消息
- 特点
- 将服务接口视为应用程序的信任界限
- 同一功能的服务发布多种服务接口,不同接口执行不同的服务等级义协议(SLA)
- 尽可能提高与其它平台和服务的互操作性
- 实现
- 服务接口使得使用者和提供者之间能够交换信息,负责实现通信时的所有细节
- 网络协议
应该封闭使用者和通信所使用的网络协议(如,服务由TCP/IP上的http向使用者提供,则服务接口可以实现为ASP.NET组件,发布URL,http请求、响应和返回等) - 数据格式
负责对使用者的数据格式和服务所期望的数据格式的转换 - 安全性
信任边界,敏感操作授权使用 - 服务等级协议(SLA)
Service Level Agreement,服务接口缓冲、缩短响应时间、节省网络传输等,负载平衡功能、容错技术等
- 方法
- XML Web 服务
- 消息队列方式(MQ)
- 优点
- 接口与应用逻辑分离(重用、维护)
- 部署灵活(代码与服务分离)
- 缺点
- 接口粒度设计
- 增加在更改服务所需的工作量
- 增加复杂性和性能开销
- 含义
- Business Entities (BE)
- 含义
应用程序的逻辑可能在设计中需要考虑多种数据格式,UI层的数据与数据库中的数据格式、外部服务提供的数据格式等可以不同。BE提供了一个中间层。 - 作用
- 将显示数据与实际存储隔离,保证业务实体的独立性,提高重用性
- 业务实体一般是在应用程序中内部使用
- 不同业务其数据格式不同
XML、dataset、datareader
- 含义
5.6.3 数据逻辑访问层(DAL)

优点
- 增加代码重用性,可以被业务逻辑层在多个地方反复引用
- 尽可能消除业务逻辑层对数据源的依赖(由于数据源改变造成的影响极小化),DAL可以通过配置文件进行改变(如Oracle改变为MS SQL Server),隐藏了数据操作的细节
- 需要一个Helper来帮助完成数据操作,管理连接、缓冲等
Helper的作用
- 为DAL提供通用的数据访问接口
- 减少数据访问操作代码(简化执行SQL语句和调用存储过程的代码)
- 进行数据连接管理
- 在不同的数据源之间,可以提供统一的接口
5.6.4 数据层
数据源:关系数据库、文件系统、Exchange Server、Web Storage等
5.7 习题
- 在C/S结构中,有状态信息服务器和无状态信息服务器相比,哪一种服务器对同时使用的用户数有限制?为什么?
有状态信息服务器对同时使用的用户数有限制。因为有状态信息服务器需要设计一个状态信息表,用于登记当前的用户操作请求,当状态信息表填满时,新用户的操作被推迟,意味着同时使用的用户数受限制。
六、CORBA技术及应用实例(了解即可)
6.1 CORBA概述
解决分布式系统的应用程序开发问题的两条规则
- 寻求独立于平台的模型和抽象
- 在不牺牲太多性能的前提下,尽可能隐藏低层的复杂细节
这两条规则不仅用于分布式系统,对于开发任何一个可移植的应用程序都是是适用的。使用合适的抽象和模型建立一个能提供异构的应用程序开发层(分布计算环境),系统异构的复杂性集中在这个层次,在这一层次上,低层的细节被隐藏起来,并且允许应用程序的开发人员只解决他们自己的开发问题,而不必面对需求所涉及到的、由于不同计算机平台所带来的低层的网络细节。
对象管理组(OMG)
对象管理组(Object Management Group),是一个非赢利的组织,建立于1989年4月,总部在美国,起由11个公司参与组建,现在拥有800多个成员,目前它是世界上最大的软件团体,其目标就是解决异构系统的可移植、分布式应用程序的开发问题、制定的技术对一些具体的问题作了合理高层抽象,并隐藏低层细节。
OMG使用两个相关的模型来描述如何与平台无关的分布式体系结构
- 对象模型(Object Model)
用来定义在一个异构环境中,如何描述分布式对象接口,它将对象定义为永恒不变的、始终是唯一的、被封装过的实体,这些实体只能被严格定义的接口(interface)访问,即客户机通过向对象发请求,才能使用对象的服务,对象的实现细节和它的位置对客户中隐藏的。 - 引用模型(Reference Model)
用来说明对象间如何交互。它提供一组服务接口。- 对象服务接口(Object Services,OS),这是一组与领域无关的接口,这些对象服务允许应用和谐查找和发现对象引用( Object Reference),被认为是构造分布式计算环境的核心部分,常见的有命名服务(Name Service)、交易服务(Trading Service)、事件服务(Event Service)等。
- 领域接口(Domain Interface),起着与对象服务种类相似的作用,对象服务接口是与领域无关的水平定向接口,只是领域接口针对领域而已,它与领域有关垂直定向接口,允许对象引用跨越不同的网络。
- 应用程序接口(Application Interface),是专门为特定的应用程序而开发的,它们并不是OMG所制定的标准,但是如果某些应用程序的接口出现在许多的应用程序中,

CORBA(Common Object Request Broker Architecture):公共对象请求代理的体系结构,第一版于1991年问世,当时只规范了如何在C语言中使用它,1994年推出CORBA2.0规范,目前普遍使用的是CORBA2.X,现在CORBA3规范已经建立,它主要新增了Java和internet、服务质量控制以及CORBA组件包等方面。
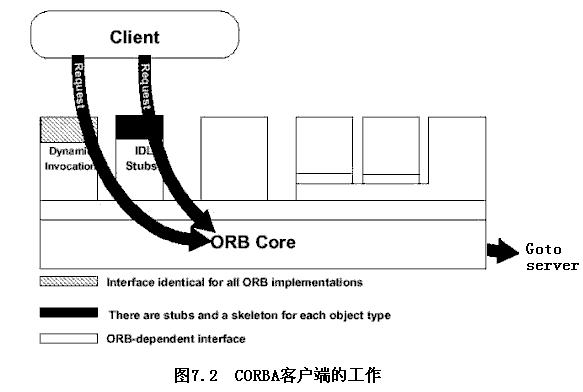
CORBA简化了C/S模式
在传统的client/server应用中,开发者使用自己设计的标准或通用标准来的协议(如Socket)。协议定义与实现的语言、网络传输及其w他网络因素有关。而CORBA简化了这一过程,它使用IDL来定义客户与服务器之间的接口协议。
- CORBA客户端的工作
- CORBA服务器端的工作
6.2 CORBA特性
6.2.1 OMG接口定义语言(IDL)
为了调用一个分布式对象的操作,客户程序必须了解由这个对象所提供的接口,一个对象的接口是由它所支持的操作和能够来回传输这些操作的数据类型所组成的。
在CORBA中,对象接口是按OMG接口定义语言(Interface Define Language,IDL)来定义的,与C++、JAVA等高级语言不同,IDL不是编程语言,所以对象和应用程序不能用IDL实现,IDL在客户和服务器程序之间建立一个契约,用它来描述在应用程序中需要用到的类型和对象接口,这些描述与实现的语言无关,可以不用考虑客户程序的编程语言是否与服务器程序的编程语言一致。正是IDL的语言独立性,使CORBA成为异构系统的集成技术。
IDL是一个纯说明性的语言,它使用程序员把焦点集中在对象接口、接口所支持的操作和操作时可能引发的异常上。它有一整套词法规则,供程序员定义接口。有关这些词法的使用,将在下一讲中作简要介绍。
IDL的一个重要特性是,一个接口可以继承一个或多个其他的接口。
6.2.2 语言映射
因为IDL只是一种说明性语言,它不能用于编写实际的应用程序,它不是提供控制结构或变量,所以它不能被编译或多用解释成一个可执行的程序,它只适用于说明我对象的接口,定义用于对象通信的数据类型。
语言映射指定如何把IDL翻译成不同的编程语言,目前OMG IDL语言映射可适用于C、C++、Java、COBOL、Smalltalk、Ada等。
IDL语言映射是开发应用程序的关键,它们提供CORBA所支持的抽象概念和模型的具体实施。IDL经过语言映射后,被翻译成特定语言的存根和框架,用于客户端和服务器端的程序的组成部分。
6.2.3 操作调用和调度软件
CORBA应用程序是以接收CORBA对象的请求或调用CORBA对象的请求这种形式工作的。
调用请求的两种方法
- 静态调用和调度
采用这种方法,IDL被被翻译成特定语言的存根(stub)和框架(Skeleton),这些存根和框架被编译成应用程序,一个存根(Stub)是一个客户端函数,它允许请求调用作为平常的本地函数调用,框架(Skeleton)是服务器端的一个函数,它允许由服务器接收到的请求调用被调度给合适的伺服程序(Servant procedure)。
这种方法很受欢迎,它提供了一个更自然的编程模式。 - 动态调用和调度
这种方法涉及到CORBA请求的结构和调度是在运行时进行的,而不是在编译时产生的,因为疫有编译状态信息,所以在运行时请求创建和解释需要访问服务程序,由它们来提供有关的接口和类型信息。
调用请求的过程
- 定位目标对象;
- 调用服务器应用程序;
- 传递调用这个对象所需的参数;
- 必要时,激活这个对象的伺服程序;
- 等待请求结束;
- 如果调用成功,返回结果值和参数值;如果失败,返回一个异常。
对象引用(Object Reference)
客户程序通过发送消息来控制对象,每当客户调用一个操作时,ORB发送一个消息给服务器对象。为了能发送一个消息给一个对象,客户必须拥有该对象的对象引用(Object Reference),对象引用起着一个句柄的作用,句柄标识唯一的一个对象,并且封装了要将所有消息发送给正确的目标ORB所需要的信息。
对象引用与C++中的类的实例指针有相同有语义,Java中没有指针的概念而用引用。每个对象引用必须准确地标识一个对象;一个对象可以有多个引用;引用可以是空的;
引用的获取
对象引用是客户程序获得目标对象唯一的途径,引用由服务器以某种方式发布的,常见的有:
- 返回一个引用作为一个操作;
- 以某些已知的服务程序公告一个引用(Naming Service 或Trading Service)
- 通过将一个对象引用转换成一个字符串和将它写在一个文件上,来公布一个对象的引用;
- 通过其他可以外传的方式来传送一个对象引用(电子邮件等)
请求调用的特征
- 定位透明性
客户不知道也不必关心目标对象是否在本地的,是否在同一机器上不同的进程中实现,或者是在不同的机器上同一个进程中实现的。服务器进程也不必始终保留在同一台机器上。 - 服务器透明性
客户不必知道哪个服务器实现了哪些对象; - 语言独立性
客户机无须关心服务器使用何种语言。 - 实现独立性
客户并不知道实现是如何工作的。 - 体系结构独立性
客户不必顾及服务器使用的CPU结构体系,并且屏蔽了字节的顺序等细节问题。 - 操作系统独立性
客户不必考虑服务器使用何种的操作系统,甚至服务器程序可以在不需要操作系统支持下实现(比如一些嵌入式系统)。 - 协议独立性
客户不知道发送消息是采用什么通信协议,如果服务器可以采用多个通信协议,那么ORB可以在运行时任意选择一个。 - 传输独立性
客户机忽略消息传送过程中网络的传输层和数据层,ORB可以透明地使用各种网络技术。
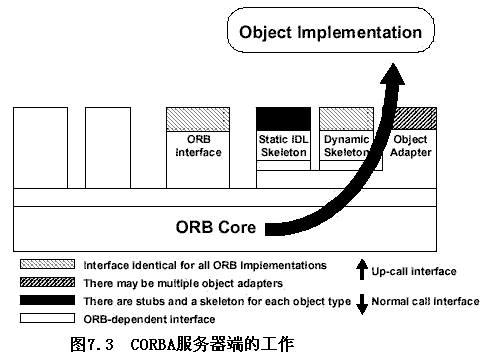
6.2.4 对象适配器(Object Adapter)
- 伺服程序(Servant)
它是一个编程语言的实体,用来实现一个或多个CORBA对象。伺服程序也称具体化的CORBA对象,它存在于服务器应用程序的上下文(Context)中,比如,在C++或Java中伺服程序一个特定类的一个对象实例。 - 一个对象适配器是一个对象,它将一个对象接口配置给调用程序所需要的不同接口,CORBA对象适配器满足下面三个要求:
- 创建允许客户程序对对象寻址的对象引用;
- 确保每个目标对象都应由一个伺服程序来具体化;
- 获取由服务器端的ORB所调度的请求,并进一步将请求产直传送给已具体化的目标对象的伺服程序。
- 基本对象适配器(BOA,Baisc Object Adapter)
CORBA早期版本(2.1之前)的规范中只有基本对象适配器,只能支持C语言的伺服程序,伺服程序没有注册。 - 可移植对象适配器(POA,Portable Object Adapter)
CORBA2.2引入了可移植对象适配器(POA,Portable Object Adapter)来取代BOA,它提供了编程语言的伺服程序在由不同的厂家提供的ORB之间的可移植性,POA提供的基本服务有:对象创建、伺服程序的注册、请求调度(Dispatch)。
6.2.5 内部ORB协议
CORBA 2.0引入一个通用的ORB互操作性结构体系,称为GIOP(General Inter-ORB Protocol,通用ORB协议)。
GIOP是一类抽象的协议,它指定了转换语法和一个消息格式的标准集,以便允许独立开发的ORB可以在任何一个面向连接的传递中进行通信。IIOP是internet网上的ORB协议(Interent Inter-ORB Protocol, IIOP),它是GIOP在TCP/IP上的实现。
服务器应用程序的事件处理模型
下图表明了ORB、POA管理器、POA和伺服程序之间的关系。

6.3 CORBA应用程序的一般开发过程
基于CORBA的系统包括客房客户程序和服务器程序两部分。通常需要执行以下几个步骤:
- 确定应用程序对象,定义它们在IDL中的接口
- 将定义的IDL文件进行语言映射
- 声明和实现服务器程序中的伺服类
- 编写应用服务器程序。
- 编写客户程序
6.4 CORBA的基本服务
6.4.1 命名服务(Naming Service)
命名服务是CORBA最基本的服务,它提供从名称到对象引用的映射:给定一个名称,该服务返回一个存储在此名称下的一个对象引用。很像internet上的DNS。
命名服务给客户程序带来的好处
- 客户程序可以给对象起个有意义的名称而不必处理字符串化的对象引用;
- 通过改变在某个名称下的公告的引用值,客户程序可以在不改变源代码的情况下使用不同接口的实现,即客户程序使用同一个名称却获得不同的引用;
- 命名服务可以使应用程序的组元访问一个应用程序的初始引用。在命名服务中公告这些引用,可以避免将引用变为字符串化的引用并存储在文件中的必要性。
命名图(naming graph)
- 名称绑定(name binding)
将名称映射为对象引用,称为名称绑定(name binding)。同一个对象引用可以使用不同的名称而多次被存储,但是每个名称只能准确也确定一个引用。 - 命名上下文(naming context)
一个存储名称绑定(name binding)的对象,称为命名上下文(naming context)。每一个上下文对象实现一个从名称到对象引用的映射表,这个表中的命名可以表示某个应用程序的对象引用,也可以表示命名服务中的另一个上下文对象。
一个上下文和名称绑定(name binding)的层次结构称为命名图(naming graph)。 - 一个简单的命名图
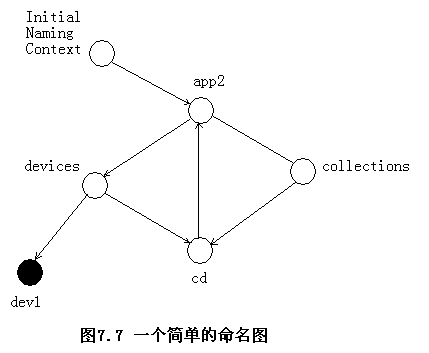
名称解析(name resolve)
命名服务提供(resolve)操作,由命名服务器将客户程序中一个指定的名称转换为对应的对象引用并返回。
6.4.2 交易服务(Trading Service)
命名服务允许一个客户程序通过一个符号名来定位对象的引用,这种机制对于客户程序定位一个对象很有用,但这要求客户程序必须确切知道要使用什么对象。
往往客户程序需要多种机制来定位一个对象,例如,一个客户程序可能只知道所需要的对象类型,对要做出精确选择的其他必要信息并不清楚。这时CORBA的交易服务(Trading Service)提供了这种功能。允许客户程序借助交易来定位对象。
与命名服务类似,一个交易用来存储对象引用及其服务描述,客户程序执行动态查找服务,此服务是基于查询服务描述的。
基本的交易概念
- 公告
也称服务提供源(service offer),用于存储交易服务,一个service offer包含此服务的描述(一组属性)和一个提供此服务的对象引用和服务类型。 - 导出
放置一个公告的行为称为导出(export)操作,放置一个公告的程序称为导出者或服务提供者(service provider)。 - 导入
为一个符合一定标准的服务提供者搜索交易的行为称为导入(import)
交易服务的基本轮廓
一个交易就是一个用于存储属性描述对象引用的数据库,我们可以导出(增加)新对象引用和它的描述,或者收回它们。
6.4.3 事件服务(Event Service)
前面我们介绍的CORBA请求调用是基于同步的请求调用,在同步请求上,一个主动的客户程序向被动的服务器调用请求,在发送一个请求后,客户程序阻塞并等待返回结果。
CORBA事件服务允许服务器向客户发送消息,即将C/S方式转化为对待方式(peer-peer)。
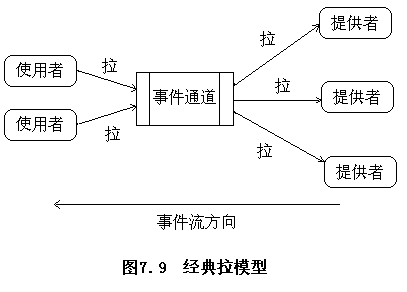
CORBA的事件服务模型
提供者(suppliers)生成事件而使用者(consumers)接收事件,提供者和使用者都连接一个事件通道(event channel)上,事件通道将事件从提供者传送到使用者,而且不需要提供者事先了解使用者的情况,反之亦然。事件通道在事件服务中起着关键作用,它同时负责提供者和使用者的注册,可靠地将事件发送给所有注册的使用者,并且负责处理那些与没有响应的使用者有关的错误。
事件服务发送事件的模型
-
推模型(push model)
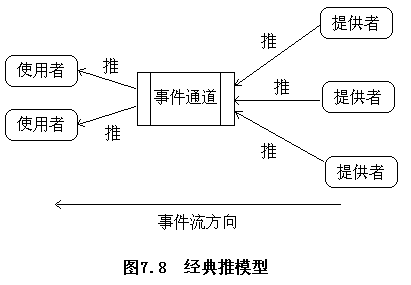
-
拉模型(pull model)
七、结构设计空间及其量化
7.1 设计空间和规则(design space and rule)
7.1.1 设计空间(design space)
把能用来描述、分类,并可供系统设计员选择的有效的结构集合称为设计空间。
一个指定的应用系统的设计空间(desigm space)是指在建立该系统设计时所有可供选择的功能维(functional dimensions)和结构维(structure dimensions)的集合。
7.1.2 维(Deimension)
- 设计空间是多维的,每个维描述系统的一个特征(characteristic)或需求(requirement)的变化(variation),维的值表示维所对应的特征或需求所有可选择范围。
- 功能维(functional dimensions)表示问题空间(ploblem space),即功能设计或性能设计的可选择的各个方面。
- 结构维(structure dimensions)表示方法空间(solution space),即实现一个特征的所有可选择的方法。
- 设计空间的维通常是不连续的,并且没有度量单位。表示也可能是。表示结构的维通常是一组离散的(discrete)值的集合,它们可能是没有任何意义的序列,如状态转换图(state transition diagram)、菜单(menu)、表单(form)等。有一些维在理论上是连续的(如表示性能的维),我们通常把它分成几个不连续的部分,如low、medium、high等。
7.1.3 设计规则(design rule)
设计空间中的维数,可能是相关的,也可能是独立的,设计规则(design rule,简称规则)是指维之间的所有关系,主要两种类型:有功能维与结构维的关系规则、结构维内部之间的关系规则。
规则(rule)可用正(positive)、负(negative)权值(weight)表示,这样规则体现了维之间关系的紧密程度或选定一种组合的好、坏。
一旦从设计空间中选定一个设计,那么就可以通过权值来计算这个设计的得分(score),如果能将一个应用的设计空间的所有设计的得分计算出来,就可以比较各种设计的得分,以找出一个最合适的设计。
对于一个经验丰富的高级设计员,可以建立一个足够完备(complete)和可靠(reliable)的规则,作为自动系统设计(automated system design)的基础。但是并不是说有了规则,就可以设计出一个完善的或一个最有可能的系统。规则可以帮助一个初级设计员(journeyman designer)像高级设计员(master designer)一样去选择一个合适的、没有大错误的设计。一个自动系统设计(automated system design)的实现将是一个漫长的过程。
7.1.4 设计知识库(design vocabulary)
设计知识库(design vocabulary)
表示软件设计的知识(knowledge),一种好的方法就是建立一个设计知识库(design vocabulary),一组容易理解(well-understood)、可重用(reusable)的设计概念(concept)和模式(pattern)。
使用设计知识库的好处(major benefit)
- 便于建立新系统(mental building blocks);
- 帮助理解和预见(predicting)一个设计的属性(property);
- 减少了学习新的概念的数量,因而减少用于理解他人的设计的努力(effort)。
比如,程序结构由控制流程的少数几个标准概念【条件(conditional)、循环(iteration)、子过程调用(subroutine call)等】来描述,程序避免了早期所使用的复杂的底层测试和分枝等操作,而直接使用这些大家普遍理解和接受的控制流程模型,并把精力集中于这些模型的属性(如循环语句中的条件变量、结束条件等),这样不仅容易编写、容易阅读而且更加可靠。
随着软件工程的成熟和研究关注转向大的系统,我们期待类似于程序结构的标准也会在大型软件系统中出现,现存中型(medium-size)软件的结构模型的正在不断走向成熟,人们已经注意到(anticipate)对于一个大型系统更高层的抽象是必要的。
7.1.5 一个设计空间的例子
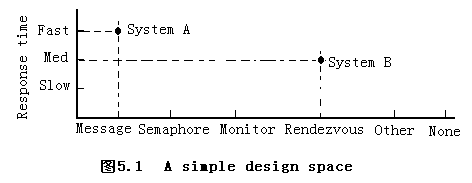
上面,我们主要介绍由不同的系统结构构成的多维设计空间(multidimensional design space)的概念,设计空间中的每个维描述了系统的一个特征及其可选择的范围,维上的值(即规则)则表示了需求与选定设计(design choices)的关系程度。比如,在一个并发进程的同步机制(interprocess synchronization mechanism)中,响应时间(response time)作为一个维,需求为Fast,Med和Slow,同步机制作为另一个维,结构有Message,Semaphore,Monitor,Rendezvous,Other,None等。
一个设计空间中不同维之间不一定是独立的(independent),事实上,为了建立设计规则,发现维之间的关系是非常重要的。
构造设计空间的关键是选择维,一些维反映需求或评估标准(evaluation criteria),如功能、性能等,另一些维则反映结构及其可用的设计。在维之间找出关系可以提供直接的设计指导,因为这些关系表明了设计选择是否最符合新系统的功能需求。在图5.1的例子,假设message机制能提供Fast的响应时间,而Rendezvous机制只能提供Med的响应时间。
设计空间的组成
- 功能设计空间(functional design space):描述设计空间中功能(function)和性能(performence)方面的需求。
- 结构设计空间(structure design space):表示设计空间可用的结构。
比如,在瀑布模型(watefall model)中功能设计空间表示需求分析的结果,而结构设计空间则是指设计阶段初始系统的分解(decomposition)
7.2 用户接口结构(user-interface architecture)设计
7.2.1 用户接口结构的设计空间
下面,我们介绍一个设计用户交互接口的软件的设计空间的建立。
7.2.1.1 基本结构模型(a basic structure model)
为了描述可用的结构,我们需要定义几个术语(terminology)用于表示系统的组件,这些术语要求是通用的,主要有:
- 特定应用组件(aplication-specific component):组件应用于一个特定的应用程序,不期望在其他程序中重用,这些组件主要是应用程序的功能核心(functional core)。
- 可共享用户接口(shared user interface)组件:这些组件是供多个应用程序使用的用户接口。如果一个软件要求能适应(accommodate)各种不同的I/O设计,那么只有能应用于所有这些设备类型的组件才作为可共享用户接口组件。
- 依赖设备(device-dependent)组件:这些组件依赖于特定的设备类型且不是特定应用组件。
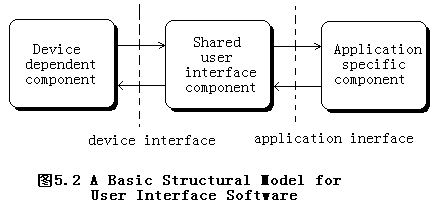
在一些简单的系统中,可以没有后两种组件,比如,系统可能没有设备驱动程序的代码,或者系统不要求提供支持多类型设备的应用。
在一些中等规模的设计空间中,接口分成两种设备接口(device interface)和应用接口(application interface),图5.2表示了用户接口的一种基本结构模型。
7.2.1.2 功能维例子(sample functional dimensions)
有研究表明一个完整的用户接口系统的设计空间包括25个功能维和19个结构维,这里我们只能选择一些有代表性的6个功能维和5个结构维。
用户接口系统的功能维
- 1.外部事件处理
- 无外部事件
- 在等待输入时处理事件
- 外部事件剥夺用户命令
- 2.用户定制
- 高级
- 中级
- 低级
- 3.适应跨设备的用户接口
- 无
- 局部行为改变
- 全局行为改变
- 应用语义改变
- 4.计算机系统组织
- 单一处理
- 多重处理
- 分布式处理
- 5.基本接口类型
- 菜单选择
- 表单填写
- 命令语言
- 自然语言
- 直接操作
- 6.应用程序对用户接口风格的适应
- 高级
- 中级
- 低级
以上6个功能维可分为3组
- External requirements(外部需求):这组维数主要包括特定应用、用户、I/O设备的支持需求,以及周围计算机系统的约束。
- Basic interactive behavior(基本交互行为):这组维数主要包括影响内部结构的用户接口行为。
- Practical considerations(考虑实际应用):主要指系统的适应性。
1.External requirements(外部需求)
- External event handling(外部事件处理)
这是一个反映赋于应用程序影响(impose)外部需求的维,指出应用程序是否需要响应外部事件、何时响应等这方面的选择。维的取值如下:- No external events(没有外部事件)
应用程序不受外部事件(external events)的影响,或者只是在执行到指定的用户命令时自动检查外部事件。例如,一个电子邮件程序可能检查是否有新的邮件,这种检查仅仅是在执行指定的命令时才进行。用户接口(user-interface)如果选择这种类型将为支持外部事件。 - Process events while waiting for input(等待输入时处理事件)
应用程序必需处理外部事件(external events),但响应时间的要求不是很严格(stringent),只是在执行用户输入命令时响应中断。 - External events preempt user commands(外部事件剥夺用户命令)
要求外部事件具有较高的优先级, 随时中断用户命令的执行,这种需求在实时控制系统(real-time control )中是很普遍的。
- No external events(没有外部事件)
- User customizability(用户定制)
这是一个反映赋于用户影响外部需求的维,设计空间可取三种值:- High(高级)
用户可以添加新的命令或重定义原命令的执行,同时也修改用户接口的细节。 - Medium(中级)
用户可以修改不影响命令语义(semantics)的用户接口细节,如,菜单项中的命令名、窗口的大小、颜色等允许用户自己定制。 - Low(低级)
很少或没有用户自定义的接口需求。
- High(高级)
- User Interface adaptability across devives(适应跨设备的用户接口)
该维依赖于应用程序中用户接口支持的I/O设备。它反映当改变不同的I/O设备类型时用户接口行为的改变程度(extent),设计空间取值有:- None(无)
对于系统所支持的所有设备,所有的接口行为都是一样的,即无需任何改变。 - Local behavior change(局部行为改变)
当设备改变时,只允许改变个别的接口细节,如修改菜单的外观(appearance)。 - Global behavior change(全局行为改变)
跨越不同设备时,用户接口行为在表面上有较大的改变,比如需要改变用户接口类型。 - Application semantics change(应用语义改变)
需要根本上修改命令的语义。
- None(无)
- Computer system organization(计算机系统组织)
该维反映应用程序执行的周围环境。主要有- Uniprocessing(单一处理)
一个时间内只有一个应用程序 - Multiprocessing(多重处理)
多个应用程序并发执行(concurrent) - Distributed processing(分布式处理)
计算环境是网络的、多CPU的和不可忽略的(non-negligible) 通信开销等。
- Uniprocessing(单一处理)
2.Basic interactive behavior(基本交互行为)
- Basic interface class(基本接口类型)
该维表示用户接口所支持的人-机交互能力- Menu selection(菜单选择)
可以从事先定义的菜单中选择执行,每次选择后对应命令的执行也显示出来,允许多次选择。 - Form filling(表单填写)
通过填写表单中指定的参数,决定程序的运行。 - Command language(命令语言)
提供一种人工的符号语言,扩充过程定义,类似于一种程序语言。 - Natural language(自然语言)
接口操作基于一种自然语言(如英语)的子集,关键问题是解释那些不明确的(ambiguous)输入。 - Direct manipulation(直接操作)
接口操作直接基于图形表示
- Menu selection(菜单选择)
需要提出,上述中只有菜单选择和表单填写可以支持同一种系统结构,其他类型的需求是单一的。
3.Practical considerations(考虑实际应用)
- Application portability across user interface styles(应用程序对用户接口风格的适应)
该维定义了用户接口系统的适应性级别,表明用户接口对特定应用(aplication-specific)组件的隔离程度。- High(高级)
应用程序可以交叉使用不同的用户接口风格, 比如命令语言和菜单。 - Medium(中级)
应用程序独立于用户接口的少量风格变化,如菜单的外观。 - Low(低级)
没有考虑用户接口的改变,或者当用户接口以改变时应用程序的改变是可以接受的。
- High(高级)
7.2.1.3 结构维例子(sample structure dimensions)
用户接口的结构维
- 1.应用接口抽象层
- 单一程序
- 抽象设备
- 工具包
- 固定数据类型的交互管理
- 可扩展数据类型的交互管理
- 可扩展交互管理
- 2.抽象设备可变性
- 观念设备
- 参数化设备
- 可变操作的设备
- 专用设备
- 3.用户接口定义符号
- 隐含在可共享用户接口代码
- 隐含在应用代码
- 外部说明符号
- 外部过程符号
- 内部说明符号
- 内部过程符号
- 4.基本通信
- 事件
- 纯状态
- 状态提示
- 状态+事件
- 5.控制线程机制
- 不支持
- 标准线程
- 轻量级线程
- 非抢占式线程
- 事件处理
- 中断服务程序
以上5种结构维可分为3组:
- Division of functions and knowledge among modules(模块中功能和信息的划分):这组维主要说明模块中功能的确定、模块间的连接、以及每个模块所包含的信息。
- Representation issues(表示问题):这组主要考虑系统中使用的数据表示方法,也就是说要既要考虑在用户接口中使用的实际数据,又要考虑用于指定用户接口行为和外观的元数据(metadata),系统中元数据可以是显式的(explicitly),比如,用于描述对话框外观的数据结构,也可以是隐含的(implicitly)。
- Control flow、communication、synchronization issues(控制流程、通信、同步问题):这组主要考虑用户接口的动态行为(dynamic behavior)。
1.Division of functions and knowledge among modules(模块中功能和信息的划分)
- Application interface abstraction level (应用接口抽象层)
在一定程度上,该维是一个关键的结构维,将其设计空间分为6个应用接口通过类型,它们由通信的抽象层来区分。- Monolithic program (单一程序)
将所有接口功能集中在一个单一的程序中,没有区分特定应用程序和共享程序,只有一个模块也就不存在模块间的接口。主要适合于小的系统或是一些对用户接口的细节考虑全面的特殊系统。 - Abstract device(抽象设备)
共享组件是一些简单的设备驱动程序,为应用程序提供抽象设备的操作,接口行为的多数是由应用程序控制,少数也可由共享组件完成。在这类中应用程序接口就设备接口。 - Toolkit (工具包)
共享组件提供一个交互技术库(工具箱),如菜单、滚动条,应用程序则负责选择工具箱元素,并将它们组合成一个完整的接口。这样共享组件只能控制局部的用户接口风格部分,接口的全局行为由应用程序控制。共享组件和应用程序组件之间的交互是按照指定的交互技术(如得到菜单的选择)。对于工具箱中没有提供的交互技术,应用程序可以直接访问抽象设备层, 此时应用程序负责实现特定应用的数据类型和面向设备的表示间的转换(conversion)。 - Interaction manager with fixed data types (固定数据类型的交互管理)
共享组件控制局部和全局的交互顺序(sequence)t 和格式(stylistic)的决定,它与应用程序的交互被表示为抽象信息的传递,这些抽象传递使用一组标准的数据(如整数、字符串),应用程序必须以标准的类型解释它的输入和输出。 - Interaction manager with extensible data types(可扩展数据类型的交互管理)
在上一种功能的基础上,可能扩展数据类型,包括输入和输出的数据转换也要求是新的数据类型,要完整地使用这种方式,一般要求接口的外部表示与应用主程序分开。 - Extensible interaction manager(可扩展交互管理)
应用程序与共享组件间的通信也是通过抽象信息传递,应用程序可以定制扩展交互管理,这要求有而面向对象语言和继承机制。
- Monolithic program (单一程序)
- Abstract device variability (抽象设备可变性)
这是描述设备接口(device interface)的关健维,为了设备独立性的操作我们把设备接口视为抽象设备(abstract device)。- Ideal device(观念设备)
在观念设备中,操作及其结果经过详细说明(specify),比如,广泛使用的postScript的图像模型,可以不考虑实际的打印机或显示器的分辨率。在这种方法中,设备可变性都由设备驱动层隐藏,因此应用程序的可移植性很强,当观念设备与实际设备偏离很小时,这种方法非常有用。 - Parameterized device(参数化设备)
设备按一些指定的参数分类,如参数可以是屏幕大小、颜色数、鼠标的键数等。设备独立性组件能根据参数值调整其行为,操作和结果也是经过详细说明的,但要依赖于对应的参数,这种方式的好处是可以设备以最适合的参数操作,但它使得设备独立性代码要分析设备的参数所有范围,在应用程序中实现开销很大。 - Device with variable operations(可变操作的设备)
拥有一组良定义的设备操作,但设备独立性代码在选择操作实现时可能有很大地偏离(leeway),操作的结果也就可能不明确。这种方法在设备操作的选择在在抽象层而驱动程序可以在很大范围内选择时可以发挥作用。 - Ad-hoc device(专用设备)
在很多实际系统中,抽象设备定义局限于一种特别的方式,设备的不同其操作行为也改变,这样应用程序可使用的设备种类的范围很小,也就是说应用只能使用专门的设备。
- Ideal device(观念设备)
2.Representation issues(表示问题)
- Notation for user interface definition (用户接口定义符号)
这是一个表示维,它说明用于定义用户接口外观和行为的技术。- Implicit in shared user interface code(隐含在可共享用户接口代码)
这是一种完全可接受的方式,比如,菜单的可视外观是隐含中工具箱提供的菜单过程中。 - Implicit in application code(隐含在应用代码)
用户接口外观和行为隐含在应用中,可用于当应用程序中紧含着用户接口的情况。 - External declarative notation(外部说明符号)
用户接口外观和行为在非过程部分定义,与应用程序分开。这种方式支持用户自定义。 - External procedural notation (外部过程符号)
用户接口外观和行为在一个过程中定义并与应用程序分开,这种方式较灵活但使用困难。 - Internal declarative notation (内部说明符号)
- Internal procedural notation(内部过程符号)
- Implicit in shared user interface code(隐含在可共享用户接口代码)
3.Control flow、communication、synchronization issues(控制流程、通信、同步问题)
- Basic of communication (基本通信)
这是一个通信维,该维按模块间的可共享状态(shared state)、事件(event)通信方法区分。事件(event)是指发生在一个离散时间的信息传递。- Event(事件)
- Pure state (纯状态)
- State with hints (状态提示)
- State plus events(状态+事件)
- Control thread mechanism (控制线程机制)
描述是否支持逻辑多线程,在用户接口系统中支持多线程是很重要的。- None(不支持)
只使用一个单独的线程(只有一个线程的进程) - Standard processes (标准线程)
- Lightweight processes (轻量级线程)
- Non-preemptive processes (非抢占式线程)
- Event handlers (事件处理)
- Interrupt service routines(中断服务程序)
- None(不支持)
7.2.2 用户接口结构的设计规则
规则指示了维之间的关系程度,主要有两种类型
- 功能维与结构维的关系规则
允许系统需求驱动结构设计 - 结构维内部之间的关系规则
描述系统内部的一致性(consistency),这种规则使要发现一个具有更高得分的设计变得复杂。
规则例子(sample rules)
如果外部事件处理需要抢占用户命令,那么抢占控制线程机制(标准进程、轻量级进程或中断服务例程)是非常受欢迎的。如果没有这样的机制,必须对所有用户界面和应用程序处理施加非常严格的约束,以保证足够的响应时间。
高用户可定制性要求有利于用户界面行为的外部表示法。隐式和内部符号通常比外部符号更难访问,并且更紧密地耦合到应用程序逻辑。
分布式系统组织支持基于事件的通信。基于状态的通信需要共享存储器或一些等效的存储器,在这样的环境中访问这些存储器通常是昂贵的。
7.3 量化设计空间(Quantified Design Space,QDS)【重点】
7.3.1 简介
人们对软件产品(artifact)的分析已经有多年的研究和实践。在理论和经验上,系统的性能(performance)、复杂性(complexity)、可靠性(reliable)、可测试性(testability)以及其他所期望的质量的度量已经成为软件工程的主要组成(integral part)。然而软件产品作为软件开发过程的最后一个阶段,对其分析的是重要的。现在已经达到共识:软件产品可以与开发过程所依赖的设计一样好。
在过去,软件分析工具的开发并没伴随(accompany)人们对软件设计的逐惭关注而发展。原型技术( prototyping techniques)能证明(demonstrate)设计阶段的可行性(feasibility)或研究(investigate)设计中的特殊问题。形式软件检查(inspection)可以在后期开发阶段展开之前尽早地发现设计上的错误。形式描述语言(formal specification language)可以用于描述一个设计。但现在不没有一个能从理论和质量上对设计进行分析的工具。这样的工具应能提供一些度量设计符合产品所拥有的需求的程度,而无需构造一个原型,并且能使一个设计者将自己的知识应用于一个应用领域或致力于软件设计和构造。
量化设计空间(Quantified Design Space,QDS)是美国卡内基.梅隆(Carnegic Mellon)大学(CMU)提出的。QDS的目标是分析和比较一个指定应用的各种软件设计,QDS的思想是基于设计空间(design space)和质量配置函数(quality function deployment,QFD),是一种将系统需求转换为可选择的功能和结构设计,量化(quantified)分析各种的可能选择及其组合。QDS作用是可以为一个期望系统(desired system)制作(produce)一个设计模型,也可以用来分析和对比已有的设计,或对现有的设计提出改进建议。
7.3.1.1 质量配置函数(QFD)
QFD是一个质量保证(assurance)技术,其作用是将客户的需求转换为产品从需求分析到设计开发各个阶段的技术需求,或转换为制造(manufacturing)和维护(support)。1997年QFD应用于日本的汽车制造并获得显著的效果,现在已经在日本和美国得到普遍应用。QFD的基本目标(fundamental)是“客户的声音”(voice of customer)出现在(manifested)产品开发过程的各个阶段。QFD的观点(philosophy)是让所有的投资者对产品开发达成一个共识(common understanding)。
QFD技术带来的好处
- 问题(issues)发现在开发阶段,并且是问题形成之前。
- 决定(decision)记录在一个有结构的框架中,必要时可以跟踪(trace)。
- 在开发过程中过程的各个阶段需求(requrement)不容易被误解(misinterpreted)。
- 重复工作(rework)减少,需求改变最小化,减少产品进入市场所花的时间。
- 由定义的框架表示产品知识(knowledge),不仅可供现有产品开发使用,还可用于将来的工作。
- 最终产品更接近的客户需求。
QFD过程
QFD的基本原理(philosophy)是通过一组详细说明的图形符号和用于开发过程各个阶段的良好定义的转换机制(将需求转换为实现)。QFD实现协作工程的多用户设计系统的产品分析(同时有多用户从从的单个设计侧面协同工作)。
QFD过程的步骤如下:
-
步骤1:建立产品或服务开发的范围,招集投资者代表参与QFD工作,收集各阶段的用户需求(这些需求用户可按它们自己的语言表示),由交叉功能小组分析这些需求并达成共识,将这些需求加入到QFD表(如图5.4)的左边列中。

-
步骤2:QFD小组选择满足用户需求的实现机制(realization mechanism),这些机制组织在QFD图表的上端,建立用户需求对实现机制的关系矩阵。
-
步骤3:为每个实现机制建立目标值(target value),并填入QFD图表的关系矩阵的下方,这些目标可以是量化数值或量化目标,但这些目标都是可以主观验证的(verifiable)。
-
步骤4:建立机制与需求的关系(relationship),以确定不实现用户需求哪一种机制是最重要的每一种关系可用图形符号表示其程度(high、medium、Weak),如果某个机制不满足一个需求,则对应的关系矩阵的值为空。例如,图中,database manager机制与需求Work with large designs有强(strong)的系统性能关系,但与需求Apply expert knogledge系统能力上关系较弱(Weak)。这些关系赋于一个权值(weight)以便计算每个实现机制的重要性。分析这些关系是QFD的主要能力(strength)之一,比如,图5.4中,起始可能认为database manager机制主要满足Support cooperative design,但更进一步分析表明,有效的数据库database manager机制对需求work with large designs也有很好的性能,这种“副效益”(side-benefit)在QFD框架中可以很清楚地表示出来。
-
步骤5:计算机制间的相关性(correlations)即各种实现机制间的正、负关系,正数关系表示两种机制彼此都很好,负数关系表示一种机制的实现会干扰(interfere)另一个机制的实现。这些关系在QFD图表的上方,用图形符号表示关系程度,空格表示两个机制没有联系。比如,图5.4中表明ASCII文件的使用与数据库管理有很严重的负关系。
-
步骤6:估计(assess)每一种机制的实现难度也根据组织的强弱,困难等级(rating)记录在QFD图表中target value的上方。
-
步骤7:计算每种机制的重要等级:一种机制的各关系值乘以QFD表右边列(customer importance)对应客户值的并相加得到这种机制的技术绝对值。为了明确起见,可以再将这些绝对值转换为相对值,它们分别记录在QFD图表的底部。
-
步骤8::建立了关系(relationship)和相关性(correlation)后,FQD小组就可以分析该框架,选择在产品中使用的机制。
- a.确定每种机制的目标值;
- b.检查(inspect)每种相关性,找出可能冲突的机制,这突出某种机制允许为其相关性赋于一个权值,组织困难等级用数据表示出来。
- c.排除具有负相关性、高困难等级、风险性和低技术重要性的机制
- d.对于尚未充足表达的需求,可以再次检查。
过程的结果可以作为下一阶段的产品开发。
QFD总结:
为完成这个QFD例子,每个实现机制 (realization mechanism)要指出其目标值(target value),实现机制的各列要按相对技术重要性重排。这个框架还可以作为下一个QFD的输入,比如选定database manager机制,另个指定通信使用(client-server),作为下一阶段QFD的输入。
7.3.2 量化设计空间(QDS)
QDS原理
- QDS的内容是设计空间的概念和QFD技术。
- QDS从设计空间中提取概念、一个设计分解成维及其可选择的设计、设计维间的正负相关性,分析需求与实现机制间的关系,应用QFD过程。
- 这种基于QFD框架的设计空间的实现称为量化设计空间(QDS)
应用QFD框架实现一个设计空间
QFD过程的共同目标是获取设计知识,即关于实现机制与客户需求间的关系和机制间相关性的知识。设计空间的规则(rule)能从QFD框架中的关系和相关性获得。比如,一个规则表明一个“distributed system”不能在一个“monolithic program”可实现。
通用功能设计空间(Generalized Functional Design Space)
客户需求列在表的左边,赋于这些客户需求的权置于表中另一个列,功能维及其可选择的设计空间位于表的上方,并与需求构成的关系矩阵,关系值越大表明功能越能满足需求,计算每个功能的“calculated weight”,及各需求的权,表的“design decision”中1表示可选用的功能。“effective weight”为“calculated weight”与“design decision”的积。

通用结构设计空间(Generalized Structure Design Space)

结构设计可选择相关性(Corrlation of Structural Deisgn Alternative)

量化设计空间值(score)

设E1、E2、…、En 是每个选定结构设计备选方案的有效重量;设Cmn为备选方案m和n的相关系数。
对于每个选定的结构设计方案,将设计方案的有效权重与其他选定方案的有效权相加,并将总和的每个项乘以矩阵中的相关因子。然后将乘积总和相加,得出设计的最终得分: S r o c e = ∑ C i j ( E i + E j ) Sroce=\sum C_{ij}(E_i+E_j) Sroce=∑Cij(Ei+Ej)
7.4 习题
- 简述QDS的思想、作用及目标。
QDS的思想是基于设计空间和质量配置函数,是一种将系统需求转换为可选择的功能和结构设计,量化分析各种的可能选择及其组合。
QDS作用是可以为一个期望系统制作一个设计模型,也可以用来分析和对比已有的设计,或对现有的设计提出改进建议。
QDS的目标是分析和比较一个指定应用的各种软件设计;
八、软件体系结构描述
8.1 软件体系结构形式化的意义
通常,好的结构设计是决定软件系统成功的主要因素,然而,目前许多有应用价值的结构,如管道/过滤器、层次结构、C/S结构等,他们都被认为是一种自然的习惯方法,并应用在特定的形式。因此,软件系统的设计师还没有完全开发出系统结构的共性,制定出设计间的选择原则,从特定领域中研究出一般化的范例,或将自己的设计技能传授他人。
要使软件体系结构的设计更具有科学性,一个重要的步骤是就是要有一个合适的形式化基础。这一章我们将介绍软件体系结构的形式化描述(formal specification)。
人们已经认识到,对于一个成熟的工程学科,形式模型(formal model)和形式化分析技术(techniques for formal analysis)是基础(cornerstone),只是不同工程学科他们使用的形式不同。形式化方法可以提供精确、抽象的模型,提供基于这些模型的分析技术,作为描述指定工程设计的表示法,也有助于模拟系统行为。因此在软件体系结构领域,它的形式化描述也有很多的用处:
- The architecture of a specific system(指定系统的体系结构)
这种类型的形式化,可以提供从软件结构来设计一个特定的系统,这些形式化方法可以作为功能规格说明书的一个部分,扩充系统结构的非形式的特征,还可以详细分析一个系统。 - An architecture style(软件结构风格)
这种类型的形式化,可以阐明一般结构化概念的含义,如,结构化连接、层次结构化的表示、结构化风格,在理想的情况下,这种形式化方法可以提供在结构一级基于推理方法分析系统。 - Formal semantics for architectural description language(结构描述语言的形式语义)
这种类型的形式化,是用语言的方法描述结构,并应用传统语言的技术表示描述语言的语义。
8.2 软件体系结构描述的方法
软件体系结构描述的方法分为
- 一般描述方法(或非形式的方法)
- 形式化描述方法。
常用的一般描述方法
- 主程序和子过程
- 数据抽象和面向对象设计
- 层次结构
常用的形式化描述方法
- Category Theory(类属理论)
- Z Notation(Z标记语言)。
8.2.1 主程序和子过程
在结构化范型中,将系统结构映射为主程序和一系列具有调用关系的子过程(或子函数)的集合。主程序充当子过程的调用者,子过程之间又存在着复杂的过程调用关系。过程之间通过参数传入和传出数据。这是软件设计最直接、最基本的结构关系。更复杂的系统设计包含了模块、包、库、程序覆盖等概念。
- 库
提供了系统设计支持的公用的二进制代码,它是设计和调试好的子过程的集合。 - 包
通常是是针对特定应用的类别所提供的公用子过程集合,它可以是源代码或二进制代码形式的。为了支持上运行时组装,通常需要为包提供初始化操作,以维持包的初始状态。 - 模块
具有与包类似的结构,但支持上层功能的转换操作,可以看成是具有独立主程序和子过程结构的功能块。 - 程序覆盖
是在有限的存储空间条件下,支持功能模块和包对换的机制。
优点
- 是一切软件结构的最本质、最基础的形式,一切软件的结构问题都可以通过在此层次上的代码得追溯;
- 只要设计得当,代码的效率可以得到最大限度的发挥和提高。
缺点
- 部件的连接关系不明显。直观的部件关系只是过程的调用,但实际支持的连接可以复杂,为把握部件之间的连接关系造成困难。
- 代码的维护性差。简单的过程调用关系为代码的维护带来困难,特别是数据据结构的变化会引起复杂的关联变化。
- 代码的重用性差。单纯的过程概念不能反应复杂的软件结构关系,难以成为软件重用的基本单元,不能构成大规模的重用基础。
8.2.2 数据抽象和面向对象设计
数据抽象和面向对象设计是在主程序和子过程设计方法的基础上建立和发展起来的重要的软件描述方法。数据抽象是面向对象设计的理论基础,类和对象是该描述方法的基础粒度。
类是数据抽象的载体,由数据成员和操作方法构成,成员的类型和取值范围定义了数据运算的域,方法定义了对数据的运算及其遵循的公理,这样,数据以及对它们的操作就被安然完整地封装在一起而形成了抽象数据类型。
对象是类的实例,是软件系统的可运行实体,它全面复制了类的数据组成和操作方法,对象的数据反映了对象的生存状态。对象之间是通过操作方法的调用建立相互作用关系,方法调用采用<对象名>.<方法名>(<参数>)的形式。这就是对象的信息隐藏性和封装性,它保证了行为正确的对象在外界环境不出现意外时永远是正确的。
类的继承性是一种重用机制。通过继承类的数据和操作,并加以扩充,可以快速建立(或导出)起新的类。另外,封装性保证了类或对象作为独立体的完整性。
多态性是同一行为名,作用在不同类的对象上时,对应的性质相同但操作细节不同的特性,保证了系统中部件要可替换兼容性。
动态链接是在可环境中实现多态性的机制,也是运行代码重用的机制,为运行代码的扩充、升级提供了可能。
8.2.3 Category Theory(类属理论)
类属理论是一种表达对象关系的数学语言,最初的研究是Samuel Eilenberg 和 Sanders Maclane提出的。广泛用于描述软件体系结构中的部件和连接器。
8.3 Z Notation简介
Z Notation是由牛津大学(University of Oxford )的Programming Research Group研究的一种数学语言,基于一阶谓词逻辑(firs-order logic)和集合论(set theory)。使用标准的逻辑操作符(∧、∨、→等)和集合操作符(∩、∪、∈等)以及它们的标准常规定义。
使用Z Notation可以描述数学对象的模型,这些对象与程序计算对象相似,这是Z可作为体系结构和软件工程描述的原因。
8.3.1 什么是形式规范(formal specifications)
形式规范(formal specifications)是用数学表示法(notation)精确地描述信息系统的属性,而不过分注重实现这些属性的方法,也就是说,这些规范描述系统应该做什么而不关心系统如何实现。这种抽象使用得形式规范对开发计算机系统的过程很有意义,因为它们使得系统的问题能够可信赖地回答,没有必要解决大量的程序代码细节。
形式规范为客户需求分析、程序实现、系统测试或编写系统用户手册等人员提供一个单一、可靠的资料,因为一个系统的形式规范独立于程序代码,可以在系统开发之前完成。虽然在这些规范在系统设计阶段或客户需求变化时需要改变,但它们是促进对系统达成共识的一个有效方法。
8.3.2 Z notation的思想
Z notation的思想是把描述一个系统的规范分解成若干图表(schema,也称架构或模式), 图表(schema)可以再分解更小的图表。在Z中,图表(schema)用于描述系统的静态和动态方面:
- 静态方面(static aspects)包括:
- 系统的状态;
- 维持系统从一个状态向另一个状态转换的不变关系(invariant relationships);
- 动态方面(dynamic aspects)包括:
- 系统的可能操作;
- 输入与输出关系;
- 状态的变化的产生。
例子:

8.3.3 声明(Declarations)
声明满足属性的各种变量或变量的取值,在Z中有两种基本的声明方法。

- 声明的变量是某集合的一组元素,显式地列出。
X1,X2,…,Xn : E - 声明的变量是schema的引用(reference),以schema作为组件。
声明变量时,还可以指定是输入或输出,在变量后加上“?”表示该变量从用户输入;在变量后加上“!”表示输出。
声明的变量的适用范围由它出现的上下文(context)决定,可以是适合整个规范的全局变量,作为schema的组件,也可以是适合于某个谓词或表达式的局部变量。
8.3.4 Schema texts
一个schema文本是由声明和或选择的谓词列表。
Schema-Text ::= Declaration [Predicate; : : : ; Predicate]
8.3.5 Predicates


∀ d e c l ∣ p r e d 1 ∗ p r e d 2 \forall decl\; |\; pred1 * pred2 ∀decl∣pred1∗pred2:它被读作“对在 decl 中满足谓词 pred1 的所有变量,都使得谓词 pred2 为真”;
∃ d e c l ∣ p r e d 1 ∗ p r e d 2 \exists decl\; |\; pred1 * pred2 ∃decl∣pred1∗pred2:它被读作“存在 decl 中满足谓词 pred1 的一个或多个变量,使得谓词 pred2 为真”;
九、J2EE体系结构分析及应用(了解即可)
详情可以访问下面博客
JavaEE
十、区块链技术(补充)
【10.2和10.3任选一题即可,回答要写明题目,技术名称和意义】
10.1 基本概念
- 账本
按区块存储交易记录,下一个区块存储上一个区块的哈希值,形成链接的关系。 - 交易
节点之间发生的支付。 - 挖矿
在最新区块链的数据上,生成一个符合条件的区块,链入区块链的过程,即区块链上通过其特定计算公式,最快得到正确答案的机器就获得相应虚拟货币奖励的过程。这一过程就是挖矿,即通过PoW工作量证明算法,解决数学问题,来争取记账权。 - 共识
就是所有分布式节之间怎么达成共识,通过算法来生成和更新数据,去认定一个记录的有效性,这既是认定的手段,也是防止篡改的手段。以比特币为例,采用的是“工作量证明”(Proof Of Work,简称POW)。工作量是需要算力的,通过工作量证明,有效的防止了篡改和伪造,因为如果要达到伪造和篡改的工作量,大概需要上亿元成本跟的算力。
【共识机制是通过特殊节点的投票,在很短的时间内完成对交易的验证和确认;对一笔交易,如果利益不相干的若干个节点能够达成共识,我们就可以认为全网对此也能够达成共识。】 - 智能合约
是一种旨在以信息化方式传播、验证或执行合同的计算机协议。智能合约允许在没有第三方的情况下进行可信交易,这些交易可追踪且不可逆转。智能合约概念于1995年由Nick Szabo首次提出。智能合约的目的是提供优于传统合约的安全方法,并减少与合约相关的其他交易成本。一般解释:智能合约实际上就是运行在以太坊网络中的一段开放源代码的程序,满足触发条件自动执行
【以信息化方式传播、验证或执行合同的计算机协议,允许在没有第三方情况下进行可信交易,这些交易可追踪且不可逆转,也就是运行在以太网网络中的一段开源程序,满足触发条件自动执行。】
10.2 区块链在“数据追溯”方面的应用案例
- 食品溯源
将牛肉生产的所有信息写入文件,将文件的哈希值保存在区块中;在食用每块牛肉前,可以清楚知道这块牛肉的来源,包括大到牛肉是来自哪一头牛身上的哪一部位,牛的健康状况,小到每一片牛肉是由谁切的,所有信息都可以追溯。;区块链的信息无法篡改,保证每一条信息都是真实可靠的。任何人都不可能更改区块链中的信息,所以所有信息都是可信任的 - 物流溯源
区块链技术可以记录物流的全流程信息,包括货物的来源、运输、存储、配送等,确保物流过程的真实性和可追溯性,从而提高物流效率和安全性。 - 交易溯源
使用区块链,交易的执行、清算和结算可以同时进行,交易完成后,自动写入分布式账本里,同时更新其他节点的账本,大幅缩短结算周期;结合智能合约,当交易发生时,可以准确、迅速的自动进行处理。 - 数字版权
通过hash算法等区块链加密技术,将作品的权属信息变成唯一的、真实的且不可篡改的区块,保存在区块链中。由作品的产生开始,版权的每一次授权、转让,都能够被恒久的记录和追踪。通过秘钥检验使用者是否被授权,没有权限则拒绝任何访问。这样可以很好的保护数字版权,版权泄露时可以容易查出源头。
10.3 区块链在“共享经济”方面的应用案例
德国Innogy共享充电桩
德国能源巨头Innogy和物联网平台企业Slock.it合作推出基于区块链的电动汽车点对点充电项目。用户无需与电力公司签订任何供电合同,只需在智能手机上安装Share&Charge APP,并完成用户验证,即可在Innogy广布欧洲的充电桩上进行充电,电价由后台程序自动根据当时与当地的电网负荷情况实时确定。由于采用了区块链技术,整个充电和电价优化过程是完全可追溯和可查询的,因此极大地降低了信任成本。需要充电时,从APP中找到附近可用的充电站,按照智能合约中的价格付款给充电站主人。
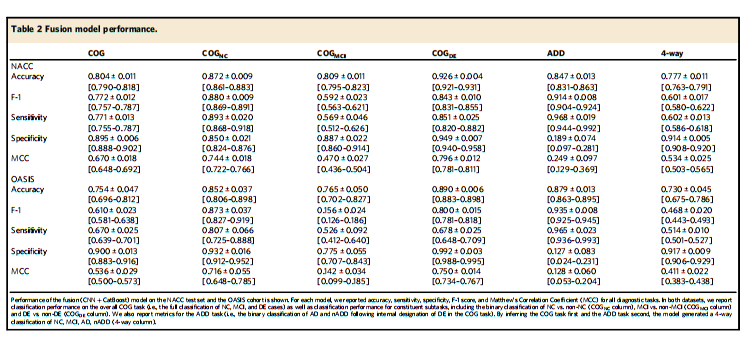


![[开发|安卓] Android Studio 开发环境配置](https://img-blog.csdnimg.cn/direct/8567451675dd400bba1f881c182619d2.png)