作者 |张马也
编辑 |德新

就在前两天,英国AI公司Wayve宣布获得新一轮10.5亿美元融资,投资方为软银、英伟达和现有投资人微软,可以说是顶级豪华阵容。
作为一家英国公司,Wayve这轮融资也创造了英国AI公司有史以来最大的单笔融资。甚至英国首相也在一份声明中表示,它「巩固了英国作为人工智能超级大国的地位」。
在通用人工智能领域,Open.ai在过去两年成为全球顶级的热门标的;而智能驾驶领域,曾经获得过10亿美金级融资的公司不多,只有Waymo、Argo、Cruise等少数几家。
Wayve的巨额融资也勾起人们对于未来的强烈好奇:它有没有可能成为智能驾驶领域的Open.ai,又或者说,成为端到端这代技术上的Waymo/Cruise?
到目前为止,Wayve已完成三轮融资,累计融资金额超过13亿美元。除了资本大鳄和商业巨头,有「深度学习三巨头」美誉、现Meta首席人工智能科学家Yann LeCun,也是Wayve的投资人。
Wayve上一次引发关注是在不久前3月份,原Mobileye中国区的负责人 Erez Dagan加入Wayve担任总裁,主要负责产品、业务和战略。
本轮融资后,Wayve将加速推出首款用于量产车辆的自动驾驶软件,包括L2+智驾软件以及实现完全自动驾驶的软件系统。Erez加入后,其重点关注的方向也是面向OEM的交付。据说,Wayve正在与全球前几大车厂商洽谈合作。
一、自动驾驶2.0:押注端到端
Wayve由Alex Kendall(联创兼现任CEO)和Amar Shah(已离开)于2017年共同创立,两为均来自剑桥大学。
其公司总部英国伦敦,目前约有300名左右的员工。

Wayve称自己是第一个在公共道路上,开发和测试端到端深度学习自动驾驶系统的公司。
2015年,Alex Kendall与Vijay Badrinarayanan(现任AI副总裁)、Roberto Cipolla等人,一起提出了SegNet,这是第一个使用端到端深度学习进行语义分割的实时方法,无需高精地图即可理解复杂环境。
从2017年开始,Wayve就在汽车上对神经网络强化学习的一些早期成果进行了应用。公司把这套系统在道路上进行了模拟部署,随后逐渐扩大规模,最终实现在伦敦市中心的交通环境下进行真实驾驶。
Wayve将自己的智驾系统称为AV2.0。
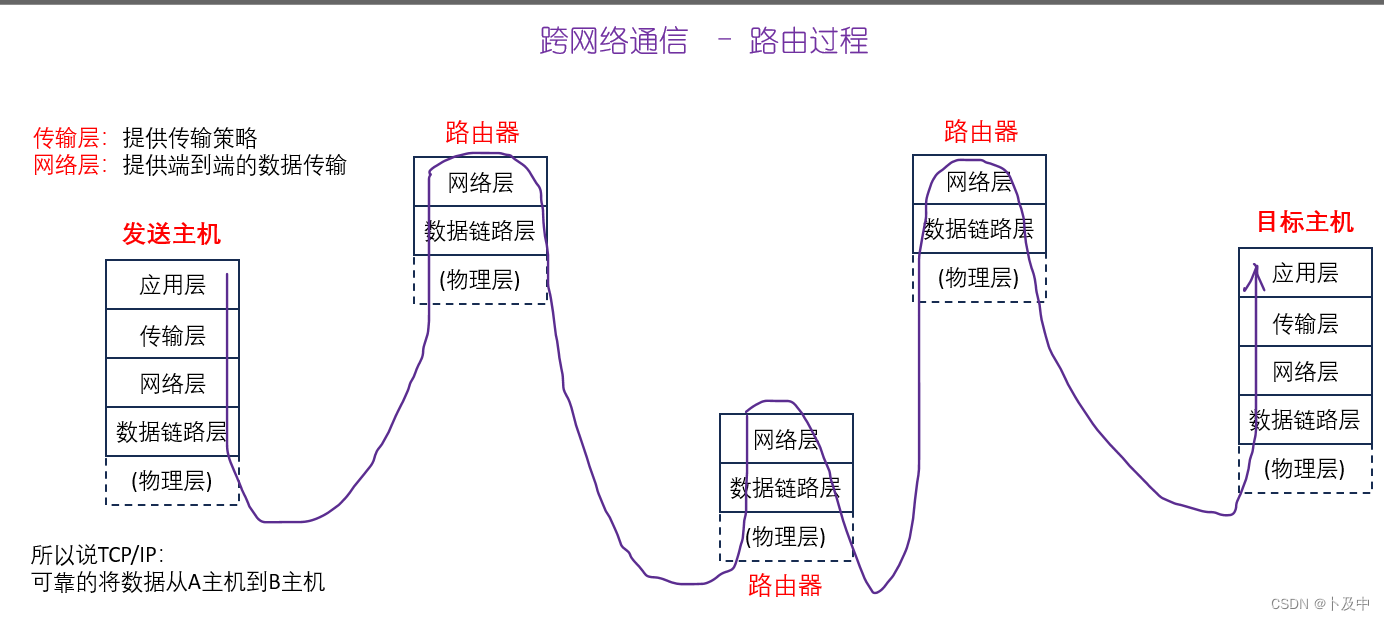
Wayve认为,基于传统机器学习方法的AV1.0架构,所面临的根本问题是技术可扩展性。
因为它依赖复杂的传感器、高精度地图和手工编码的规则,使得系统成本居高不下,在行为预测、规划和处理长尾场景问题上,效果很难提升。
AV2.0不依赖传统的高清地图和手工编码的规则,而是专注于构建数据驱动的学习型驾驶系统,而且可以扩展、适应、推广到系统从未见过的场景。
AV2.0的特点如下:
- 采用端到端深度学习网络架构;
- 无需高精地图;
- 以安全为核心设计,符合行业安全期望;
- 传感器灵活性,兼容纯视觉到包括雷达和激光雷达的多种架构;
- 通过数据驱动进行泛化扩展;
- 在全球范围内,经济适用;
其中最重要的,就是端到端架构。
它抛弃传统的「感知 - 规划 - 执行」的架构,将车辆传感器原始的输入数据,直接转换为驾驶操作输出。
在行业内,端到端的方法已经得到了初步的验证。特斯拉此前发布的FSD v12,就采用了端到端架构。国内外很多用户试用过后,普遍的评价是,基本达到了人类驾驶的水准。
这种方法的核心是自我监督学习。就像大语言模型LLM预测下一个单词一样,驾驶系统可以从原始的、未标记的数据中进行无监督学习。
自动驾驶和大型语言模型之间有许多相似之处,从根本上讲,它们都是大型的、高数据量的、复杂的决策问题。输入模型的数据越多,AI模型的特定应用就越丰富,越具有表现力,无需人工输入即可对大量驾驶记录进行训练。
二、核心技术栈:解决可解释性,建立人机信任
Wayve为自动驾驶的迭代升级开发了一个快速、连续和无缝的学习循环系统Fleet Learning Loop,不断记录数据、训练模型、评估性能和部署更新的模型,以此循环。
在量产车队中,它能从OEM的各种车辆中收集真实世界的驾驶数据,然后上传到云端处理,再将迭代后的模型部署到车端,升级车辆的自动驾驶功能。
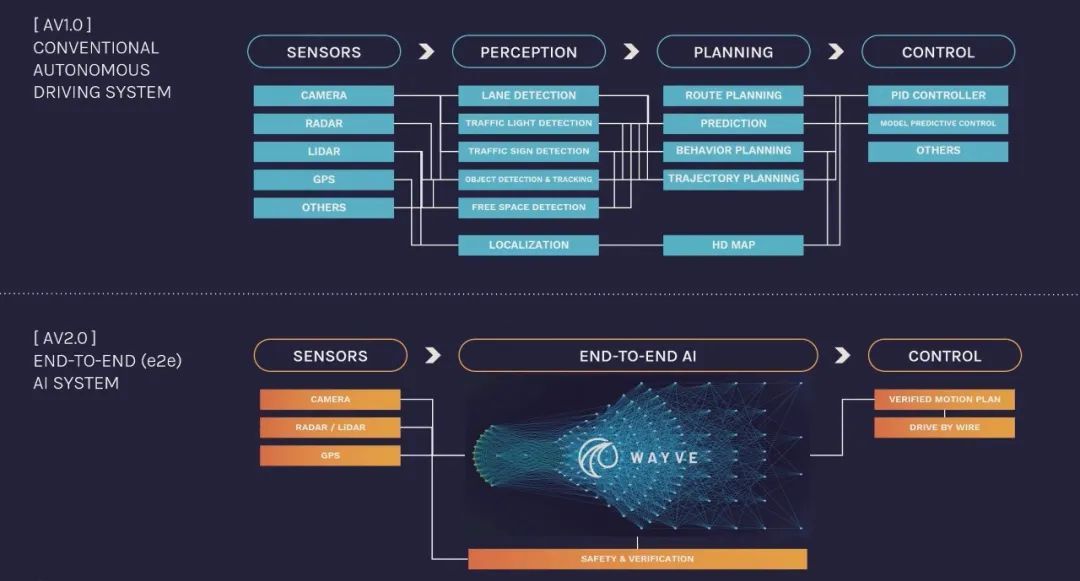
Wayve还一直在开发智能驾驶基础模型(foundation model for driving)。该模型利用多模态数据,包括文本和非驾驶视频源,来优化对驾驶环境的内部表征。
Wayve认为,这能增强AI模型的驾驶能力,允许从不同来源交叉学习与驾驶相关的概念,并提高与驾驶任务目标的一致性。
简单来说,就是通过从多个数据源学习,可以提高车辆对传感器流中最有意义和可操作性的方面的理解,从而提高智能驾驶的流畅度和安全性。
除此之外,Wayve还开发了LINGO和GAIA两个模型,用来解决智驾场景的可解释性和信任等问题。
行业内对端到端架构的其中一大担忧是它是一个黑盒方案,其过程不可解释。LINGO能用自然语言描述自己的驾驶决策,并解释决策的原因。
例如在行驶过程中,LINGO做出了绕行路边停靠车辆的判断时,它可以向用户输出判断依据:由于交通堵塞,我正在缓慢靠近;我正在经过一辆停在路边的车;因为前方道路畅通,所以我加速前进。
Wayve在去年下半年推出过LINGO-1,当时该模型以视觉和语言信息为输入,但只能输出语言结果。LINGO-2的输入和输出都可以是视觉和语言信息,甚至也包括驾驶行为,也就是能控制车辆的行驶。
按官方说法,LINGO-2是一种将视觉、语言和行动综合起来,以解释和确定驾驶行为的驾驶模型,是第一个在公开道路上测试的,闭环「视觉-语言-行动」驾驶模型(VLAM)。
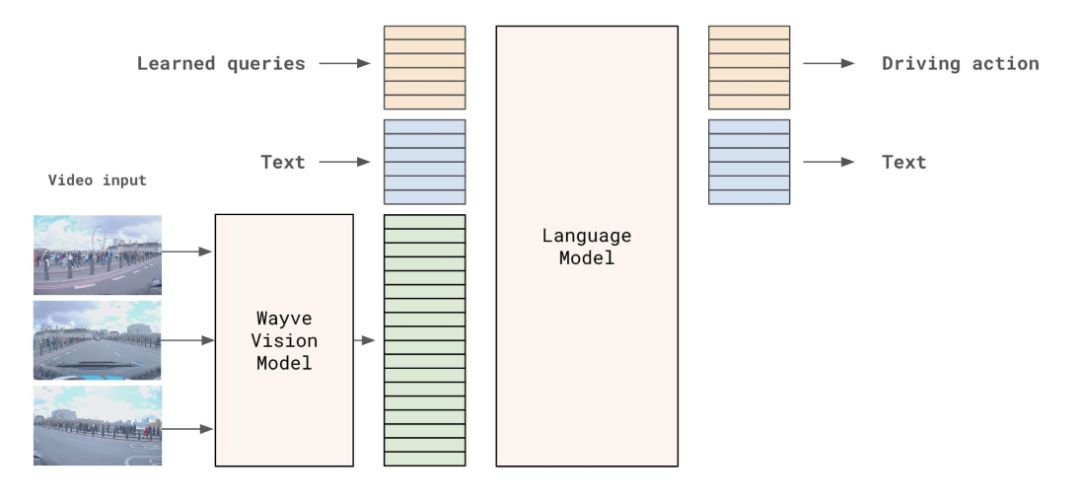 LINGO-2 架构
LINGO-2 架构
LINGO-2 的亮点在于:通过语言提示,调整驾驶行为。
可以使用一些限定的导航命令,如「靠边停车」、「右转」等,让LINGO-2调整车辆的行为。这也能帮助模型训练,并且增强人车交互。
 LINGO-2在指令的要求下停车
LINGO-2在指令的要求下停车
 LINGO-2回答场景问题,并解释驾驶操作
LINGO-2回答场景问题,并解释驾驶操作
通过直接将语言和动作联系起来,LINGO可以一定程度上揭示出AI系统如何做出决策,使得自动驾驶模型不再是一个「黑盒子」。
更重要的是,LINGO可以增强人类对智能驾驶系统的信任。
目前,LINGO-2还只在Ghost Gym模拟器中进行了验证,在现实世界中用语言控制汽车的行为是否可以可靠、安全地完成,还需要更多研究。
三、将世界模型融入驾驶模型
对于长尾场景,Wayve给出的一个解决方法是GAIA-1,一个为智能驾驶打造的生成式世界模型。
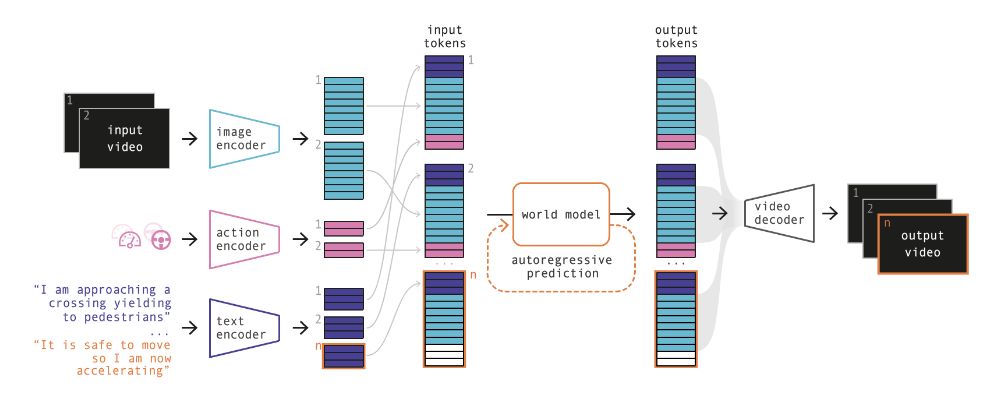 GAIA-1架构
GAIA-1架构
GAIA-1首先是一个多模态生成模型,利用视频、文本和动作输入,生成逼真的驾驶场景视频。它能够对车辆的行为和其他基本场景特征,进行细粒度控制。无论是改变车辆的行为,还是修改整体场景,模型都能完成。
这样,GAIA-1可以作为仿真模拟中的重要一环,生成无限的数据,来训练和验证自动驾驶系统,解决极端场景,特别是在获取真实世界数据成本高或风险大的情况下。
 GAIA-1可根据各种提示,生成驾驶场景
GAIA-1可根据各种提示,生成驾驶场景
它还是一个真实的世界模型,可以学习、理解驾驶中的重要概念,比如什么是卡车、公共汽车、行人、骑自行车的人、道路布局、建筑物和交通信号灯。
所谓世界模型,是对环境及其未来动态的表征,能实现对周围环境的结构化理解,就像人类对自己周围的环境进行建模理解一样。
将世界模型整合到驾驶模型中,使得自动驾驶车辆能够预测未来事件,从而提前规划行动,在复杂或未知的情况下做出更加明智的决策。
目前版本的GAIA-1拥有超过90亿个可训练参数,训练数据集包含了2019年至2023年在伦敦收集的4700小时的专有驾驶数据。模型可以预测视频序列中的后续帧,从而在不需要任何标签的情况下,实现自回归预测能力。
四、迈向商业化量产
目前,Wayve在商业化上的作为不多。
此前,它一直在英国生鲜配送公司Ocado的车上训练模型,这家公司也是投资方之一,曾投资了1360万美元。

据称,Wayve已经在全球100多个城市开始了系统测试。
本轮融资后,Wayve将加速推出首款用于量产车辆的自动驾驶软件,包括L2+智驾系统,以及实现完全自动驾驶的软件系统。
它也在与全球前几大车厂商洽谈合作,但具体名单未知。
原Mobileye中国区的负责人Erez Dagan加入Wayve担任总裁,其重要的关注方向也是面向OEM的交付。Erez在Mobileye工作了20年,是全世界第一款纯视觉ADAS产品的创始团队成员,后来担任产品和战略执行副总裁,并在Mobileye被收购后担任英特尔集团副总裁。
联系到此前马斯克表示,特斯拉将于今年8月8日发布Robotaxi,种种迹象似乎表明完全自动驾驶的技术路线正在逐渐清晰。
Wayve的目标甚至不止于此。在最近Techcrunch的一次采访中,Alex Kendall说到,Wayve的驾驶大模型不仅在驾驶数据上进行训练,还对互联网规模的文本和其他来源进行训练,甚至使用英国政府的PDF文档来训练模型。
Wayve正在构建具身AI(Embodied AI)基础模型,一个基于非常多样化的数据进行训练的通用系统,能够在复杂的现实世界环境中感知、行动、学习和适应人类行为。智能驾驶只是这一系统目前最大的应用场景。