💻博主现有专栏:
C51单片机(STC89C516),c语言,c++,离散数学,算法设计与分析,数据结构,Python,Java基础,MySQL,linux,基于HTML5的网页设计及应用,Rust(官方文档重点总结),jQuery,前端vue.js,Javaweb开发,设计模式、Python机器学习等
🥏主页链接:Y小夜-CSDN博客
目录
🎯实现的功能
🎯ER图
🎯建立表
课程章节表:
课程题库表:
教师表
班级表
学生表:
作业规则表
实验规则表
试卷规则表:
课程作业总表:
课程作业明细表:
课程实验总表:
课程实验明细表
课程试卷总表:
课程试卷明细表:
🎯建立索引
教师表和学生表的姓名索引:
题库表的试题内容、试题答案、题型、难度索引
班级表的班级名称索引
🎯建立视图
班级学生视图(班级表和学生表)
教师学生视图(教师表和班级学生视图)
🎯 插入记录
插入章节表
插入题库表
插入教师表
插入班级表
插入学生表
插入试卷规则表
插入作业规则表:
🎯编写触发器
(一)章节试题数量触发器
(二)班级学生人数触发器
🎯编写存储过程或函数
写出插入一条学生数据的存储过程
写出一次插入多条学生数据的存储过程
生成学生试卷
生成班级试卷
🎯游标知识扩展
🎯实现的功能
(一)学生用户
- 课程作业
- 课程实验
- 课程考试
(二)教师用户:
- 课程的章节管理
- 课程的题库管理
- 教师管理
- 班级管理
- 学生管理
- 作业管理
- 实验管理
- 考试管理
🎯ER图
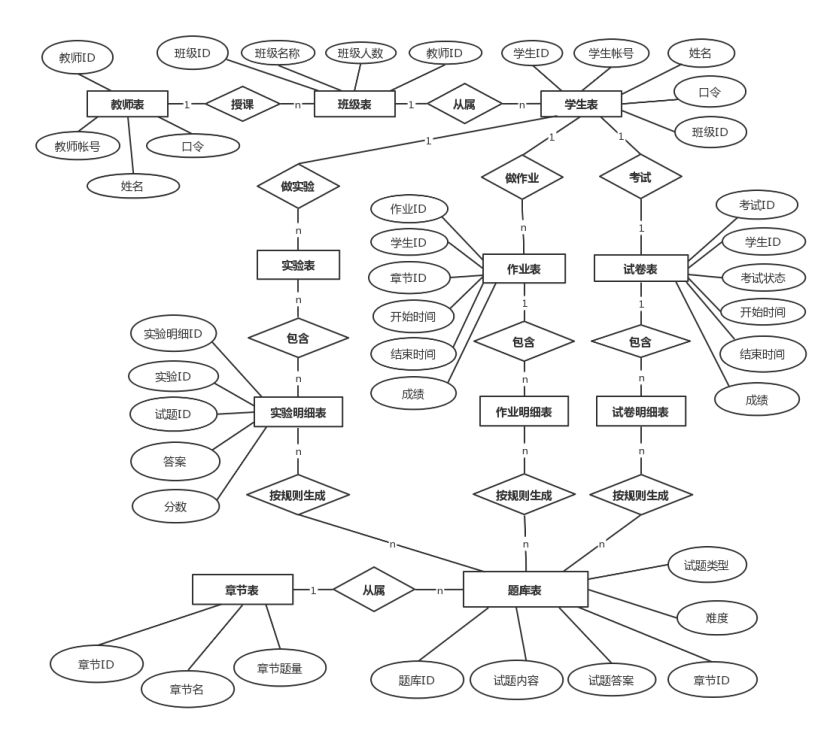
🎯建立表
课程章节表:
CREATE TABLE `chapter` ( `chapterId` int(11) NOT NULL AUTO_INCREMENT, `chapterName` varchar(50) DEFAULT NULL, `questionCount` int(10) unsigned zerofill DEFAULT NULL, PRIMARY KEY (`chapterId`) ) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8;
课程题库表:
CREATE TABLE `questionbank` ( `questionId` int(11) NOT NULL AUTO_INCREMENT, `questionContent` text, `questionAnswer` varchar(2000) DEFAULT NULL, `type` tinyint(3) unsigned zerofill DEFAULT NULL, `difficulty` tinyint(3) unsigned zerofill DEFAULT NULL, `chapterId` int(11) DEFAULT NULL, PRIMARY KEY (`questionId`) ) ENGINE=InnoDB AUTO_INCREMENT=14 DEFAULT CHARSET=utf8;
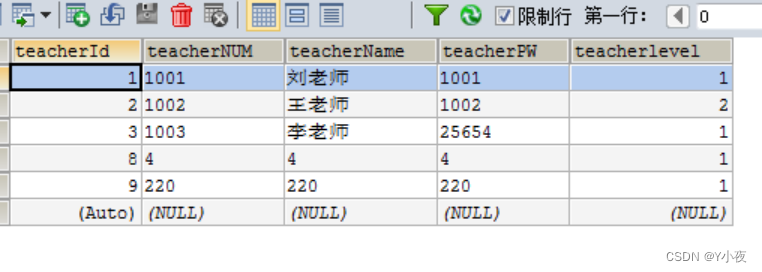
教师表
CREATE TABLE `teacher` ( `teacherId` int(11) NOT NULL AUTO_INCREMENT, `teacherNUM` varchar(20) DEFAULT NULL, `teacherName` varchar(50) DEFAULT NULL, `teacherPW` varchar(20) DEFAULT NULL, KEY `teacherId` (`teacherId`), KEY `teachername` (`teacherName`) ) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
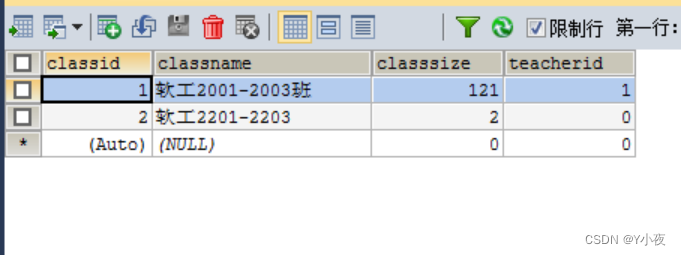
班级表
CREATE TABLE `class` ( `classid` int(11) NOT NULL AUTO_INCREMENT COMMENT '班级ID', `classname` varchar(20) DEFAULT NULL, `classsize` int(11) DEFAULT '0', `teacherid` int(11) DEFAULT '0', PRIMARY KEY (`classid`) ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
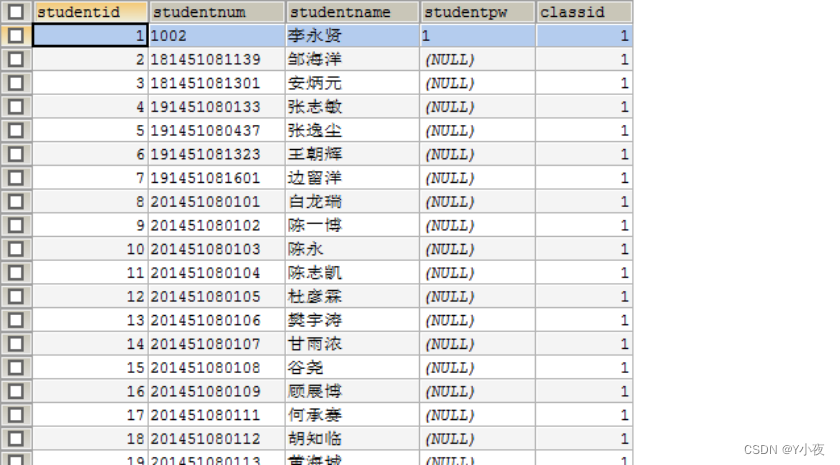
学生表:
CREATE TABLE `student` ( `studentid` int(11) NOT NULL AUTO_INCREMENT, `studentnum` varchar(20) DEFAULT NULL, `studentname` varchar(20) DEFAULT NULL, `studentpw` varchar(20) DEFAULT NULL, `classid` int(11) DEFAULT '0', PRIMARY KEY (`studentid`), KEY `student456` (`studentname`) ) ENGINE=InnoDB AUTO_INCREMENT=122 DEFAULT CHARSET=utf8;
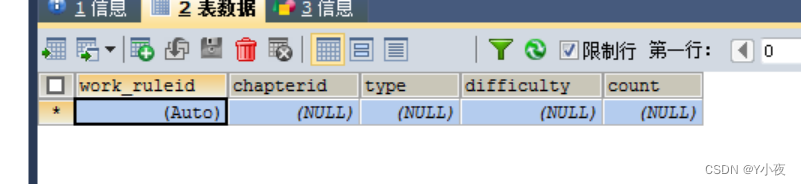
作业规则表
CREATE TABLE `word_rule` ( `work_ruleid` int(11) NOT NULL AUTO_INCREMENT, `chapterid` int(11) DEFAULT NULL, `type` int(11) DEFAULT NULL, `difficulty` int(11) DEFAULT NULL, `count` int(11) DEFAULT NULL, PRIMARY KEY (`work_ruleid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
实验规则表
CREATE TABLE `experiment_rule` ( `experiment_ruleid` int(11) NOT NULL AUTO_INCREMENT, `chapterid` int(11) DEFAULT NULL, `type` int(11) DEFAULT NULL, `difficulty` int(11) DEFAULT NULL, `count` int(11) DEFAULT NULL, PRIMARY KEY (`experiment_ruleid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
试卷规则表:
CREATE TABLE `exam_rule` ( `exam_ruleid` int(11) NOT NULL AUTO_INCREMENT, `fromchapterid` int(11) DEFAULT NULL, `tochapterid` int(11) DEFAULT NULL, `type` int(11) DEFAULT NULL, `difficulty` int(11) DEFAULT NULL, `count` int(11) DEFAULT NULL, PRIMARY KEY (`exam_ruleid`) ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
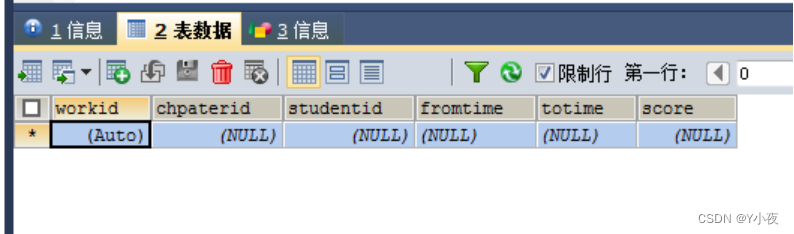
课程作业总表:
CREATE TABLE `work` ( `workid` int(11) NOT NULL AUTO_INCREMENT, `chpaterid` int(11) DEFAULT NULL, `studentid` int(11) DEFAULT NULL, `fromtime` datetime DEFAULT NULL, `totime` datetime DEFAULT NULL, `score` int(11) DEFAULT NULL, PRIMARY KEY (`workid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
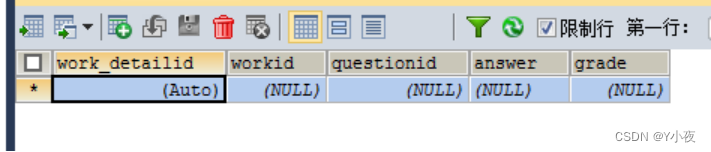
课程作业明细表:
CREATE TABLE `work_detail` ( `work_detailid` int(11) NOT NULL AUTO_INCREMENT, `workid` int(11) DEFAULT NULL, `questionid` int(11) DEFAULT NULL, `answer` varchar(2000) DEFAULT NULL, `grade` int(11) DEFAULT NULL, PRIMARY KEY (`work_detailid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
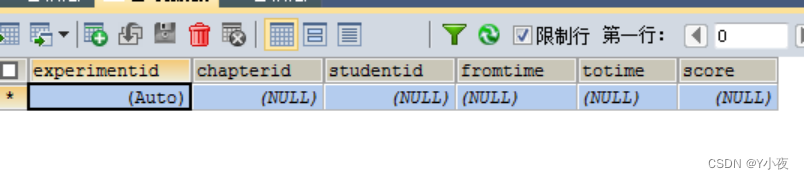
课程实验总表:
CREATE TABLE `experiment` ( `experimentid` int(11) NOT NULL AUTO_INCREMENT, `chapterid` int(11) DEFAULT NULL, `studentid` int(11) DEFAULT NULL, `fromtime` datetime DEFAULT NULL, `totime` datetime DEFAULT NULL, `score` int(11) DEFAULT NULL, PRIMARY KEY (`experimentid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
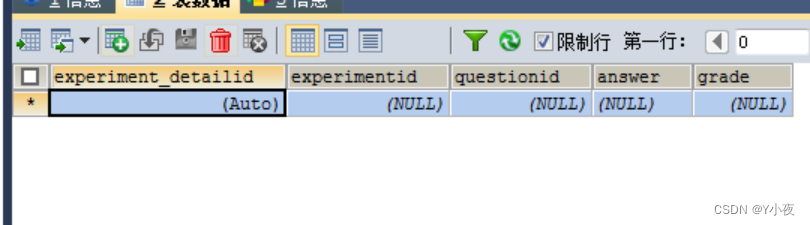
课程实验明细表
CREATE TABLE `experiment_detail` ( `experiment_detailid` int(11) NOT NULL AUTO_INCREMENT, `experimentid` int(11) DEFAULT NULL, `questionid` int(11) DEFAULT NULL, `answer` varchar(2000) DEFAULT NULL, `grade` int(11) DEFAULT NULL, PRIMARY KEY (`experiment_detailid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
课程试卷总表:
CREATE TABLE `exam` ( `examid` int(11) NOT NULL AUTO_INCREMENT, `studentid` int(11) DEFAULT NULL, `fromtime` datetime DEFAULT NULL, `totime` datetime DEFAULT NULL, `state` int(11) DEFAULT NULL, `score` int(11) DEFAULT NULL, PRIMARY KEY (`examid`) ) ENGINE=InnoDB AUTO_INCREMENT=122 DEFAULT CHARSET=utf8;
课程试卷明细表:
CREATE TABLE `exam_detail` ( `exam_detailid` int(11) NOT NULL AUTO_INCREMENT, `examid` int(11) DEFAULT NULL, `questionid` int(11) DEFAULT NULL, `answer` varchar(2000) DEFAULT NULL, `grade` int(11) DEFAULT NULL, PRIMARY KEY (`exam_detailid`) ) ENGINE=InnoDB AUTO_INCREMENT=1681 DEFAULT CHARSET=utf8;


🎯建立索引
教师表和学生表的姓名索引:
create index idx_teacher_name on teacher(teachername); create index idx_student_name on student(studentname);题库表的试题内容、试题答案、题型、难度索引
CREATE INDEX idx_question_content ON questionbank(questionContent); CREATE INDEX idx_question_answer ON questionbank(questionAnswer); CREATE INDEX idx_question_type ON questionbank(`type`); CREATE INDEX idx_question_difficulty ON questionbank(difficulty);班级表的班级名称索引
CREATE INDEX idx_class_name ON class(className);
🎯建立视图
班级学生视图(班级表和学生表)
CREATE VIEW class_student_view AS SELECT c.classId, c.className, c.classSize, c.teacherId, s.studentId, s.studentNUM, s.studentName, s.studentPW FROM class c JOIN student s ON c.classId = s.classId;教师学生视图(教师表和班级学生视图)
CREATE VIEW teacher_student_view AS SELECT t.teacherId AS teacherId_t, t.teacherNUM AS teacherNUM_t, t.teacherName AS teacherName_t, t.teacherPW AS teacherPW_t, csv.* FROM teacher t JOIN class_student_view csv ON t.teacherId = csv.teacherId;
🎯 插入记录
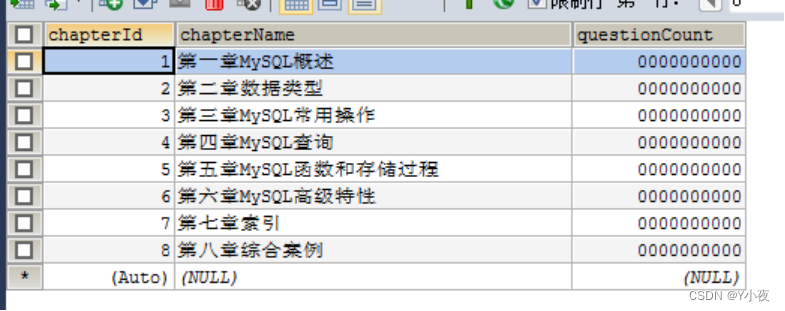
插入章节表
insert into `chapter`(`chapterId`,`chapterName`,`questionCount`) values (1,'第一章MySQL概述',0000000000),(2,'第二章数据类型',0000000000),(3,'第三章MySQL常用操作',0000000000),(4,'第四章MySQL查询',0000000000),(5,'第五章MySQL函数和存储过程',0000000000),(6,'第六章MySQL高级特性',0000000000),(7,'第七章索引',0000000000),(8,'第八章综合案例',0000000000);
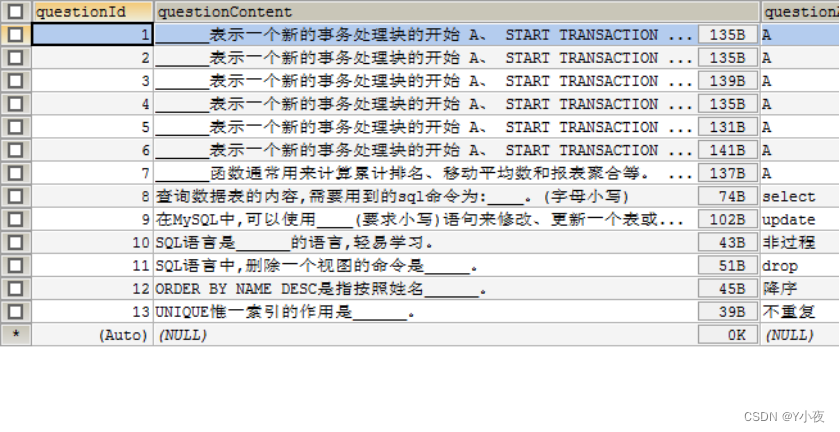
插入题库表
insert into `questionbank`(`questionId`,`questionContent`,`questionAnswer`,`type`,`difficulty`,`chapterId`) values (1,'______表示一个新的事务处理块的开始 \nA、 START TRANSACTION \nB、 BEGIN TRANSACTION \nC、 BEGIN COMMIT \nD、 START COMMIT ','A',001,001,1),(2,'______表示一个新的事务处理块的开始 \nA、 START TRANSACTION \nB、 BEGIN TRANSACTION \nC、 BEGIN COMMIT \nD、 START COMMIT ','A',001,001,1),(3,'______表示一个新的事务处理块的开始 \r\nA、 START TRANSACTION \r\nB、 BEGIN TRANSACTION \r\nC、 BEGIN COMMIT \r\nD、 START COMMIT ','A',001,001,1),(4,'______表示一个新的事务处理块的开始 \nA、 START TRANSACTION \nB、 BEGIN TRANSACTION \nC、 BEGIN COMMIT \nD、 START COMMIT ','A',001,001,1),(5,'______表示一个新的事务处理块的开始 A、 START TRANSACTION B、 BEGIN TRANSACTION C、 BEGIN COMMIT D、 START COMMIT ','A',001,001,1),(6,'______表示一个新的事务处理块的开始 \r\nA、 START TRANSACTION \r\nB、 BEGIN TRANSACTION \r\nC、 BEGIN COMMIT \r\nD、 START COMMIT \r\n','A',001,001,1),(7,'______函数通常用来计算累计排名、移动平均数和报表聚合等。 \r\nA、 汇总 \r\nB、 分析 \r\nC、 分组 \r\nD、 单行','A',001,001,1),(8,'查询数据表的内容,需要用到的sql命令为:____。(字母小写)','select',002,001,1),(9,'在MySQL中,可以使用____(要求小写)语句来修改、更新一个表或多个表中的数据。','update',002,001,1),(10,'SQL语言是______的语言,轻易学习。','非过程',002,001,1),(11,'SQL语言中,删除一个视图的命令是_____。','drop',002,001,1),(12,'ORDER BY NAME DESC是指按照姓名______。','降序',002,001,1),(13,'UNIQUE惟一索引的作用是______。','不重复',002,001,1);
插入教师表
insert into `teacher`(`teacherId`,`teacherNUM`,`teacherName`,`teacherPW`) values (1,'1001','刘老师','1001'),(2,'1002','王老师','1002'),(3,'1003','李老师','25654');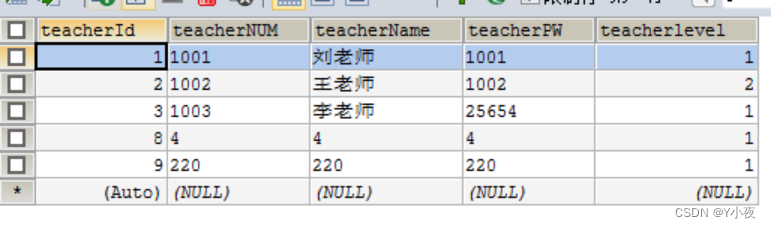
插入班级表
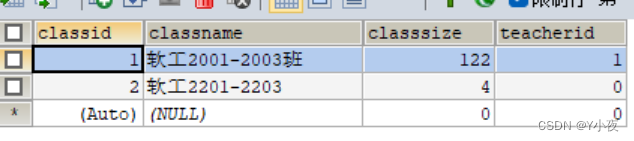
insert into `class`(`classid`,`classname`,`classsize`,`teacherid`) values (1,'软工2001-2003班',121,1);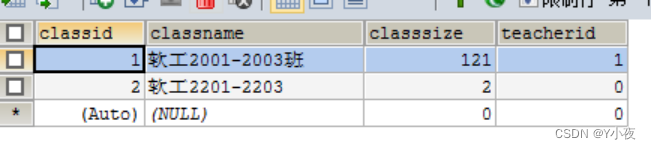
插入学生表
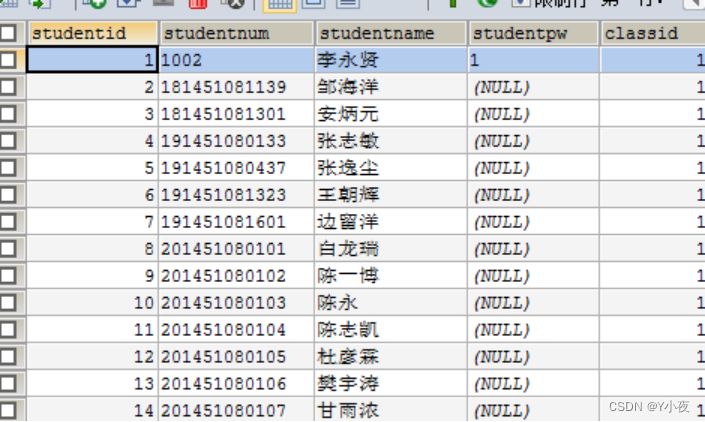
插入试卷规则表
insert into `exam_rule`(`exam_ruleid`,`fromchapterid`,`tochapterid`,`type`,`difficulty`,`count`) values (1,1,1,1,1,6),(2,1,1,2,1,4);
插入作业规则表:
INSERT INTO`word_rule`(`work_ruleid`,`chapterid`,`type`,`difficulty`,`count`) VALUES(1,1,1,1,10);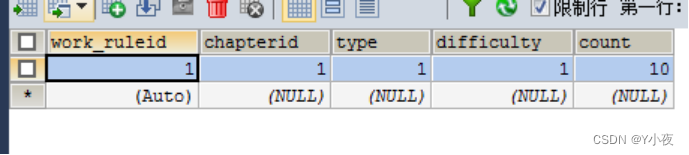
🎯编写触发器
(一)章节试题数量触发器
当插入、删除试题时,修改章节表的试题数量
插入时:
DELIMITER $$ CREATE TRIGGER `network_course`.`insert_chapter_question_count` AFTER INSERT ON `network_course`.`questionbank` FOR EACH ROW BEGIN update `chapter` set `questionCount`=`questionCount`+1 where `chapter`.`chapterId`=new.`chapterId`; END$$ DELIMITER ;删除时:
DELIMITER $$ CREATE TRIGGER `network_course`.`delete_chaper_question_count` BEFORE DELETE ON `network_course`.`questionbank` FOR EACH ROW BEGIN update `chapter` set `questionCount`=`questionCount`-1 where `chapter`.`chapterId`=old.`chapterId`; END$$ DELIMITER ;这段代码是一个MySQL触发器的定义。触发器是数据库中的一种对象,当某个事件(如插入、更新或删除)发生时,它会自动执行一段预定义的SQL语句。
以下是对这段代码的详细解释:
1. `DELIMITER $$`:这是MySQL的语法,用于改变默认的命令结束符。在这里,它将命令结束符从分号(`;`)改为两个美元符号(`$$`)。这是因为在触发器的SQL语句中,我们需要使用分号来结束每个语句,而触发器的SQL语句本身又需要用分号来结束,所以为了避免混淆,我们使用两个美元符号作为结束符。
2. `CREATE TRIGGER`:这是创建触发器的关键字。
3. `network_course.delete_chaper_question_count`:这是触发器的名称。
4. `BEFORE DELETE ON network_course.questionbank FOR EACH ROW`:这是触发器的定义部分。`BEFORE DELETE`表示这个触发器将在删除操作之前执行。`ON network_course.questionbank`表示这个触发器将作用于`network_course`数据库中的`questionbank`表。`FOR EACH ROW`表示这个触发器将对每一行数据都执行一次。
5. `BEGIN ... END$$`:这是触发器的SQL语句部分。在这个部分中,我们定义了当触发器被触发时要执行的操作。
6. `update chapter set questionCount=questionCount-1 where chapter.chapterId=old.chapterId;`:这是触发器要执行的SQL语句。这条语句的作用是将`chapter`表中与被删除的`questionbank`记录相关联的章节的`questionCount`字段减1。`old`关键字表示被删除的记录。
7. `DELIMITER ;`:这是MySQL的语法,用于将命令结束符改回默认的分号(`;`)。
总的来说,这段代码定义了一个触发器,当从`questionbank`表中删除一行数据时,它会将相关联的`chapter`表中的`questionCount`字段减1。
(二)班级学生人数触发器
当插入、删除学生时,修改班级表的学生人数
插入时
DELIMITER $$ CREATE TRIGGER `network_course`.`insert_class_student_count` AFTER INSERT ON `network_course`.`student` FOR EACH ROW BEGIN UPDATE class SET `classsize`=`classsize` + 1 WHERE `classid`= new.classid; END$$ DELIMITER ;删除时:
DELIMITER $$ CREATE TRIGGER `network_course`.`delete_class_student_count` BEFORE DELETE ON `network_course`.`student` FOR EACH ROW BEGIN UPDATE class SET `classsize`=`classsize`-1 WHERE `classid`= old.classid; END$$ DELIMITER ;这段代码是用于在数据库中创建两个触发器,分别用于处理学生表(student)的插入和删除操作。这两个触发器的目的是更新班级表(class)中的班级人数(classsize)。
1. 插入时触发器:`insert_class_student_count`
- 当在`network_course`数据库的`student`表中插入一条新记录时,这个触发器会被激活。
- 触发器的功能是在`class`表中,将对应班级的`classsize`字段值加1,表示有新学生加入该班级。
- 触发器的执行逻辑是:通过`new.classid`获取新插入的学生记录的班级ID,然后在`class`表中查找对应的班级记录,并将其`classsize`字段值加1。2. 删除时触发器:`delete_class_student_count`
- 当在`network_course`数据库的`student`表中删除一条记录时,这个触发器会被激活。
- 触发器的功能是在`class`表中,将对应班级的`classsize`字段值减1,表示有学生离开该班级。
- 触发器的执行逻辑是:通过`old.classid`获取被删除的学生记录的班级ID,然后在`class`表中查找对应的班级记录,并将其`classsize`字段值减1。这段代码使用了MySQL数据库的触发器功能,通过定义触发器,可以在数据表的插入和删除操作后自动执行一些额外的逻辑,从而实现对数据的实时更新和管理。
🎯编写存储过程或函数
写出插入一条学生数据的存储过程
DELIMITER $$ CREATE PROCEDURE `network_course`.`insert_student`( in num0 varchar(20), in name0 varchar(20), in pw0 varchar(20), in classid0 varchar(20) ) BEGIN declare count1 int; select count(*) into count1 from student where studentnum=num0; if count1=0 then insert into student(`studentnum`,`studentname`,`studentpw`,`classid`) value(num0 ,name0,pw0,classid0); end if; END$$ DELIMITER ; 执行:call `insert_student`("aaaaa",'张三',NULL,1);这段代码是一个MySQL存储过程,用于向数据库中的"student"表插入一条新的学生记录。下面是对这段代码的详细解释:
1. 首先,定义了一个名为`insert_student`的存储过程,它接受四个输入参数:`num0`(学生编号),`name0`(学生姓名),`pw0`(学生密码)和`classid0`(班级ID)。
2. 在存储过程内部,首先声明了一个名为`count1`的整型变量,用于存储查询结果。
3. 使用`select count(*) into count1 from student where studentnum=num0;`语句查询"student"表中是否已经存在具有相同学生编号的记录。如果存在,则将查询结果(即记录数)赋值给`count1`。
4. 接下来,使用`if count1=0 then`判断`count1`的值是否为0。如果为0,表示"student"表中不存在具有相同学生编号的记录,可以执行插入操作。
5. 在`if`语句的代码块中,使用`insert into student(`studentnum`,`studentname`,`studentpw`,`classid`) value(num0 ,name0,pw0,classid0);`语句向"student"表中插入一条新的记录。其中,`num0`、`name0`、`pw0`和`classid0`分别对应输入参数的学生编号、姓名、密码和班级ID。
6. 最后,使用`end if;`结束`if`语句,然后使用`END$$`结束存储过程的定义。
7. 在存储过程定义完成后,使用`DELIMITER ;`将分隔符设置回分号(默认值),以便后续的SQL语句可以正常执行。
8. 最后,执行`call `insert_student`("aaaaa",'张三',NULL,1);`语句调用刚刚定义的存储过程,传入学生编号为"aaaaa",姓名为"张三",密码为NULL,班级ID为1的参数。这将向"student"表中插入一条新的学生记录。
class表:
Student表:
写出一次插入多条学生数据的存储过程
学生数据的格式为:“学号1,姓名1,密码1,班级号1;学号2,姓名2,密码2,班级号2;”
DELIMITER $$ CREATE PROCEDURE `network_course`.`insert_student1`( in stustr varchar(5000) ) BEGIN declare str1 varchar(200); declare num0 varchar(20); declare name0 varchar(20); declare pw0 varchar(20); declare classid0 int; declare flag int; while stustr >'' do set str1=mid(stustr,1,locate(';',stustr)-1); set num0=mid(str1,1,locate(',',str1)-1); set str1=mid(str1,locate(',',str1)+1); set name0=mid(str1,1,locate(',',str1)-1); set str1=mid(str1,locate(',',str1)+1); set pw0=mid(str1,1,locate(',',str1)-1); set classid0=cast(mid(str1,locate(',',str1)+1) as signed); call `insert_student`(num0,name0,pw0,classid0); set stustr=mid(stustr,locate(';',stustr)+1); end while; END$$ DELIMITER ; 执行call `insert_student1`("123,bbbb,Null,2;1234,cccc,Null,2;");这段代码是一个存储过程,用于在数据库中插入一个考试记录和相关的考试细节。下面是对代码的详细解释:
1. 首先,使用`USE`语句选择要操作的数据库,这里是`network_course`。
2. 然后,使用`DROP PROCEDURE IF EXISTS`语句删除名为`inset_exam`的存储过程(如果存在)。
3. 接下来,使用`CREATE DEFINER`语句创建一个新的存储过程`inset_exam`,并指定定义者为`root`@`localhost`。
4. 在存储过程的定义中,声明了一些变量,包括`examid0`、`fromc0`、`toc0`、`type0`、`diff0`、`c0`和`done`。其中,`done`变量用于控制循环结束的条件。
5. 使用`DECLARE cur CURSOR FOR`语句创建一个游标`cur`,用于从`exam_rule`表中检索数据。查询结果按照`exam_ruleid`排序。
6. 使用`DECLARE continue HANDLER FOR not found set done=true;`语句定义了一个处理程序,当游标没有找到数据时,将`done`变量设置为`true`,以结束循环。
7. 使用`select count(*) into c0 from exam where studentid=studentid0;`语句查询`exam`表中与给定学生ID匹配的记录数,并将结果存储在变量`c0`中。
8. 如果`c0`等于0,表示该学生尚未参加过考试,那么执行以下操作:
- 使用`insert into`语句向`exam`表中插入一条新的记录,设置学生ID、状态和分数。
- 使用`select @@identity into examid0;`语句获取刚刚插入的记录的ID,并将其存储在变量`examid0`中。
- 打开游标`cur`。
- 使用`FETCH cur INTO fromc0, toc0 ,type0,diff0,c0;`语句从游标中获取一行数据,并将其分别存储在变量`fromc0`、`toc0`、`type0`、`diff0`和`c0`中。
- 进入循环,执行以下操作:
- 使用`insert into`语句向`exam_detail`表中插入多条记录,每条记录包含考试ID、问题ID、答案和成绩。这些记录是根据条件从`questionbank`表中随机选择的,条件包括章节ID范围、类型和难度等。
- 使用`FETCH cur INTO fromc0, toc0 ,type0,diff0,c0;`语句获取下一行数据,并重复循环直到游标遍历完所有数据。
- 关闭游标`cur`。9. 最后,使用`END`语句结束存储过程的定义。
10. 使用`DELIMITER ;`语句将分隔符设置回分号。
11. 运行`call inset_exam(1)`语句调用存储过程,并传入参数1作为学生ID。
class表:
student表:
CAST( 字符串 AS SIGNED); 将字符串类型的数字转化为数字类型的数字
生成学生试卷
输入参数:学生帐号,按照规则生成学生试卷总表以及试卷明细表
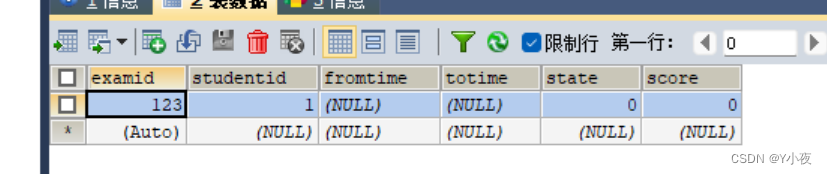
DELIMITER $$ USE `network_course`$$ DROP PROCEDURE IF EXISTS `inset_exam`$$ CREATE DEFINER=`root`@`localhost` PROCEDURE `inset_exam`(in studentid0 int) BEGIN declare examid0 int; declare fromc0 int; declare toc0 int; declare type0 int; declare diff0 int; declare c0 int; declare done int Default false; DECLARE cur CURSOR FOR select `fromchapterid`,`tochapterid`,`type`,`difficulty`,`count` from `exam_rule` order by `exam_ruleid`; DECLARE continue HANDLER FOR not found set done=true; select count(*) into c0 from exam where studentid=studentid0; if c0=0 then insert into `exam`(`studentid`,`state`,`score`)values(studentid0,0,0); select @@identity into examid0; OPEN cur ; FETCH cur INTO fromc0, toc0 ,type0,diff0,c0; while(not done) do insert into `exam_detail`(`examid`,`questionid`,`answer`,`grade`) select examid0 AS examid,`questionid`,'' as answer,0 as grade from questionbank where `chapterId`>=fromc0 and chapterid<=toc0 and `type`=type0 and `difficulty`=diff0 order by rand() limit c0; FETCH cur INTO fromc0, toc0 ,type0,diff0,c0; end while; CLOSE cur; end if; END$$ DELIMITER ; 运行call `inset_exam`(1)exam表:
exam_detail表
生成班级试卷
输入参数:班级ID,按照规则生成班级所有学生的试卷总表以及试卷明细表
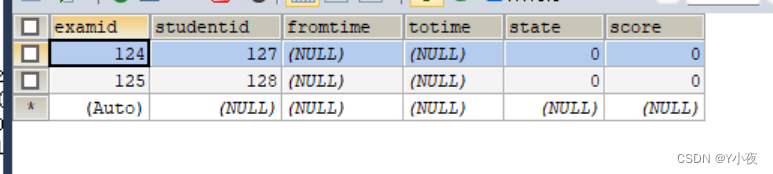
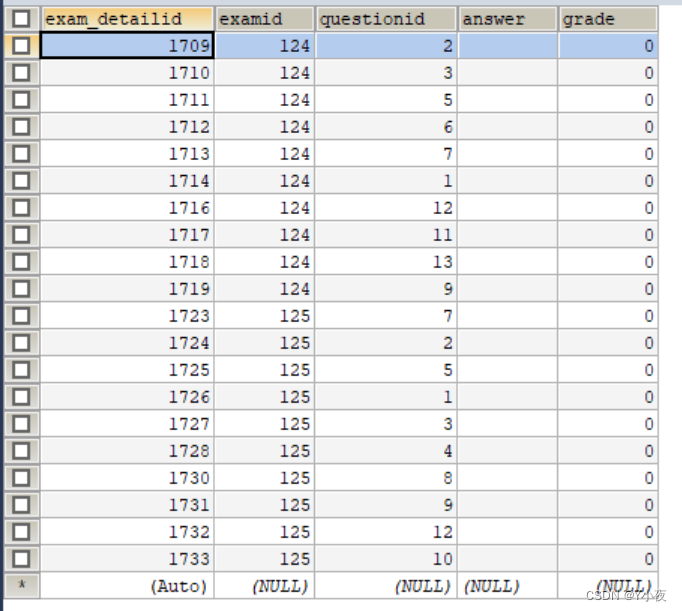
DELIMITER $$ CREATE PROCEDURE `network_course`.`insert_exam0`(in classid0 int) BEGIN declare examid0 int; declare stuid0 int; declare done int default false; DECLARE cur CURSOR FOR select studentid from student where classid=classid0; DECLARE continue HANDLER FOR not found set done=true; OPEN cur ; FETCH cur INTO stuid0; while(not done) do call `inset_exam`(stuid0); FETCH cur INTO stuid0; end while; CLOSE cur ; END$$ DELIMITER ; 执行:call `insert_exam0`(2)这段代码是一个MySQL存储过程,用于为特定班级的所有学生插入考试记录。下面是对这段代码的详细解释:
1. 首先,定义了一个名为`insert_exam0`的存储过程,它接受一个输入参数`classid0`,表示班级ID。
2. 在存储过程内部,声明了三个变量:`examid0`、`stuid0`和`done`。其中,`examid0`用于存储考试ID,`stuid0`用于存储学生ID,`done`用于控制循环结束的条件,默认值为`false`。
3. 使用`DECLARE cur CURSOR FOR`语句创建了一个游标`cur`,用于从`student`表中查询指定班级ID的学生ID。
4. 使用`DECLARE continue HANDLER FOR not found set done=true;`语句定义了一个处理程序,当游标没有找到任何记录时,将`done`设置为`true`,以结束循环。
5. 使用`OPEN cur;`语句打开游标。
6. 使用`FETCH cur INTO stuid0;`语句从游标中获取第一个学生ID,并将其赋值给`stuid0`。
7. 使用`while(not done) do`循环遍历所有学生ID。在循环内部,调用`inset_exam`存储过程为当前学生ID插入考试记录。然后再次使用`FETCH cur INTO stuid0;`获取下一个学生ID。当游标没有更多记录时,循环结束。
8. 使用`CLOSE cur;`语句关闭游标。
9. 最后,使用`END$$`结束存储过程的定义。
10. 设置分隔符为`;`,以便在执行完存储过程后可以继续编写其他SQL语句。
11. 使用`call `insert_exam0`(2);`语句调用存储过程,传入班级ID为2。
这段代码的主要功能是为班级ID为2的所有学生插入考试记录。通过游标遍历学生表,并为每个学生调用`inset_exam`存储过程插入考试记录。
exam表:
exam_detail表




🎯游标知识扩展
1、游标的概念
使用SQL语句查询,结果将返回很多记录,存储过程中,如果要对每一条查询记录做一些处理,需要使用游标来对查询结果集中的记录进行逐条读取,以便于逐条处理。
例如:
- 学生帐号,按照规则生成学生试卷总表以及试卷明细表。
规则表中存储了多条生成规则,要逐条处理。
(2)要根据班级ID,按照规则生成班级所有学生的试卷总表以及试卷明细表。
学生表中存在多条该班级的学生记录,需要逐个学生处理。
- 游标的语法
使用游标一般需要下面几个步骤
- 声明游标
- 异常处理
- 打开光标
- 通过游标获取一条记录(要循环)
- 关闭光标
具体格式如下:
DECLARE cursor_name CURSOR FOR select_statement; DECLARE { EXIT | CONTINUE|UNDO } HANDLER FOR { error-number | { SQLSTATE error-string } | condition } SQL statement; OPEN cursor_name ; FETCH cursor_name INTO var_name[,var_name…] ; CLOSE cursor_name ;说明:
(1)其中cursor_name表示光标的名字,select_statement代表SELECT语句的内容,返回一个用于创建光标的结果集。
(2)当程序出错后自动触发的代码。MySQL允许三种处理器,一种是EXIT处理,遇到错误马上退出。另一种CONTINUE是遇到错误主程序仍然继续运行,第三种是UNDO 遇到错误撤销之前的操作。
(3){ error-number | { SQLSTATE error-string } | condition }:触发条件,主要有
- MYSQL错误代码
- ANSI-standard SQLSTATE code
- 命名条件。可使用系统内置的SQLEXCEPTION,SQLWARNING和NOT FOUND等
3、随机查找表中的n条数据
Select * FROM 表ORDER BY RAND() LIMIT n;