本文给大家带来的百面算法工程师是正则优化函数,文章内总结了常见的提问问题,旨在为广大学子模拟出更贴合实际的面试问答场景。在这篇文章中,我们将总结一些BN、LN、Dropout的相关知识,并提供参考的回答及其理论基础,以帮助求职者更好地准备面试。通过对这些问题的理解和回答,求职者可以展现出自己的算法领域的专业知识、解决问题的能力以及对实际应用场景的理解。同时,这也是为了帮助求职者更好地应对深度学习目标检测岗位的面试挑战,提升面试的成功率和竞争力。
目录
17.1 什么是过拟合和欠拟合
17.2 解决过拟合和欠拟合的方法有哪些
17.3 什么是正则化?
17.4 L1与L2为什么对于特征选择有着不同方式
17.5 正则化有什么作用
17.6 介绍一下BN
17.7 BN训练与测试有什么不同
17.8 BN/LN/IN/GN区别

欢迎大家订阅我的专栏一起学习共同进步
祝大家早日拿到offer! let's go
百面算法工程师专栏:🚀🚀🚀http://t.csdnimg.cn/dfcH3🚀🚀🚀点击即可跳转
17.1 什么是过拟合和欠拟合
过拟合和欠拟合是指机器学习模型在训练过程中的两种常见问题。
- 过拟合(Overfitting):过拟合指的是模型在训练数据上表现得太好,以至于无法很好地泛化到新的、未见过的数据上。这种情况下,模型可能过度地记住了训练数据的细节和噪声,而没有学到数据背后的真正规律。过拟合的模型通常在训练集上表现很好,但在测试集或实际应用中表现不佳。
- 欠拟合(Underfitting):欠拟合指的是模型在训练数据上表现得不够好,无法捕捉到数据中的真实关系。这种情况下,模型可能过于简单,没有足够的能力来拟合数据的复杂性和变化。欠拟合的模型通常在训练集和测试集上表现都不太好。
17.2 解决过拟合和欠拟合的方法有哪些
解决过拟合和欠拟合的方法包括:
- 过拟合:减少模型复杂度(如减少参数数量、增加正则化项)、增加训练数据、使用更简单的模型、数据增强、扩充数据集等。
- 欠拟合:增加模型复杂度(如增加参数数量、增加层级)、优化模型架构、增加特征数量或改进特征工程等。
通过调整模型的复杂度、增加数据量、优化超参数等方法,可以有效地解决过拟合和欠拟合问题,使模型在训练集和测试集上都表现良好,并能够泛化到新的数据上。
17.3 什么是正则化?
正则化是一种用于减少模型过拟合的技术,通过向模型的损失函数中添加额外的惩罚项来控制模型的复杂度。正则化的目标是限制模型的参数大小,防止模型过度拟合训练数据,从而提高模型在未见过的数据上的泛化能力。
在机器学习中,常见的正则化方法包括:
- L1 正则化(Lasso 正则化):向损失函数添加 L1 范数惩罚项,即模型参数的绝对值之和。这使得一些不重要的特征的系数趋向于零,从而实现特征选择的效果,使模型更加稀疏。
- L2 正则化(Ridge 正则化):向损失函数添加 L2 范数惩罚项,即模型参数的平方和。L2 正则化倾向于使所有参数都很小但非零,对模型的影响是均衡的。
- ElasticNet 正则化:同时结合了 L1 和 L2 正则化,通过两种惩罚项来控制模型的复杂度。
正则化的选择通常基于实际问题的复杂度和数据集的特点。适当的正则化可以帮助防止过拟合,提高模型的泛化能力,但需要在正则化项的权衡下进行调整,以避免欠拟合。
17.4 L1与L2为什么对于特征选择有着不同方式
L1范数和L2范数在正则化过程中对特征选择产生不同方式的影响,这是因为它们在惩罚项的计算方式上有所不同。
- L1 正则化(Lasso 正则化):
- 正则化的惩罚项是模型参数的绝对值之和。由于 范数具有稀疏性,即很多参数的取值会被压缩到零,因此 正则化有助于进行特征选择。当使用 正则化时,模型倾向于使一些不重要的特征的系数趋向于零,从而实现了自动特征选择的效果。这样可以减少模型的维度,提高了模型的解释性和计算效率。
- L2 正则化(Ridge 正则化):
- 正则化的惩罚项是模型参数的平方和。相比于 L1 正则化, 正则化对所有参数的影响是均衡的,不会将参数完全压缩到零。虽然 正则化也可以帮助减少过拟合,但它不像 L1 正则化那样能够直接实现特征选择。在 正则化下,模型会倾向于使所有特征都有一定的影响,而不会将某些特征的系数压缩到零。
因此,L1 正则化在特征选择方面更为强大,而 L2 正则化更适用于减少过拟合并提高模型的泛化能力。在实际应用中,选择合适的正则化方法需要根据具体问题的特点以及模型的需求来进行权衡。
17.5 正则化有什么作用
正则化在机器学习中有几个重要的作用:
- 防止过拟合:过拟合是指模型在训练数据上表现得过好,但在未见过的新数据上表现不佳的问题。正则化通过向模型的损失函数中添加额外的惩罚项,限制了模型的复杂度,从而减少了模型对训练数据中噪声和细节的过度拟合,提高了模型在未见过的数据上的泛化能力。
- 特征选择:在 L1 正则化中,由于惩罚项会将一些不重要的特征的系数推向零,因此可以实现自动特征选择的效果。这样可以减少模型的维度,提高了模型的解释性和计算效率。
- 降低模型复杂度:正则化通过控制模型参数的大小,有效地降低了模型的复杂度。这对于防止模型过度拟合和提高模型的稳定性非常重要,尤其是在数据量较少或者特征维度较高的情况下。
- 提高泛化能力:正则化可以帮助模型更好地泛化到未见过的数据上。通过控制模型的复杂度,使其更加平滑和稳定,从而提高了模型的泛化能力,使其能够更好地适应新的、未见过的数据。
17.6 介绍一下BN
批量归一化(Batch Normalization,简称BN)是一种用于加速深度神经网络训练并提高模型性能的技术。它在神经网络的每一层中对输入数据进行归一化处理,使得每一层的输入保持在一个相对稳定的分布上。
批量归一化的主要思想是将每一层的输入数据进行归一化处理,使其均值接近于0,标准差接近于1。这有助于缓解了深度神经网络中的内部协变量偏移问题,即每一层输入数据的分布随着网络参数的更新而发生变化,导致训练过程变得不稳定。通过批量归一化,可以使得每一层的输入数据都保持在一个稳定的分布上,有利于网络的训练和收敛。
批量归一化的操作通常包括以下几个步骤:
- 对每一个mini-batch中的数据进行归一化处理,即将每个特征的值减去该特征在该mini-batch中的均值,然后除以该特征在该mini-batch中的标准差。
- 对归一化后的数据进行线性变换,即将每个特征乘以一个学习参数(缩放参数),然后再加上另一个学习参数(平移参数)。
- 可选地,可以引入一个激活函数对变换后的数据进行非线性处理。
批量归一化的优点包括:
- 加速模型训练:通过缓解深度神经网络中的内部协变量偏移问题,加速了模型的训练过程,使得网络更容易收敛。
- 提高模型性能:批量归一化使得网络更加稳定,能够更快地收敛到更好的局部最优解,从而提高了模型的性能和泛化能力。
- 减少对参数初始化的依赖:批量归一化可以缓解对参数初始化的依赖,使得网络对参数初始化的选择更加鲁棒。
然而,批量归一化也有一些缺点,包括:
- 计算代价:批量归一化需要在每一个mini-batch中对数据进行归一化处理,增加了一定的计算代价。
- 不适用于小批量训练:在小批量训练的情况下,由于每个mini-batch中的样本数量较少,计算得到的均值和标准差可能不够准确,导致归一化效果不佳。
综上所述,批量归一化是一种有效的深度神经网络正则化方法,能够加速模型训练并提高模型性能,但在实际应用中需要根据具体情况权衡其优缺点。
17.7 BN训练与测试有什么不同
在批量归一化(Batch Normalization,简称BN)的训练和测试阶段,存在一些不同之处:
- 训练阶段:
- 在训练阶段,批量归一化会根据每个mini-batch的数据计算均值和标准差,并使用这些统计量对当前的mini-batch进行归一化处理。
- 在训练过程中,批量归一化会利用mini-batch中的数据来计算均值和标准差,因此每个mini-batch的均值和标准差都可能会有所不同。
- 训练时,批量归一化会记录每一层的归一化所需的均值和标准差,这些均值和标准差会在测试阶段用于归一化测试数据。
- 测试阶段:
- 在测试阶段,由于测试数据不再分为mini-batch,因此无法计算mini-batch的均值和标准差。
- 因此,测试阶段会使用在训练阶段计算得到的每一层的均值和标准差来进行归一化处理。
- 在测试过程中,批量归一化使用训练阶段保存的均值和标准差对整个测试集进行归一化处理,而不是使用每个mini-batch的均值和标准差。
总结起来,批量归一化在训练阶段和测试阶段的主要区别在于归一化所使用的统计量不同。在训练阶段,根据每个mini-batch的数据计算均值和标准差进行归一化,而在测试阶段则使用训练阶段计算得到的每一层的均值和标准差对整个测试集进行归一化。

更详细的内容可以参考李宏毅老师的讲解
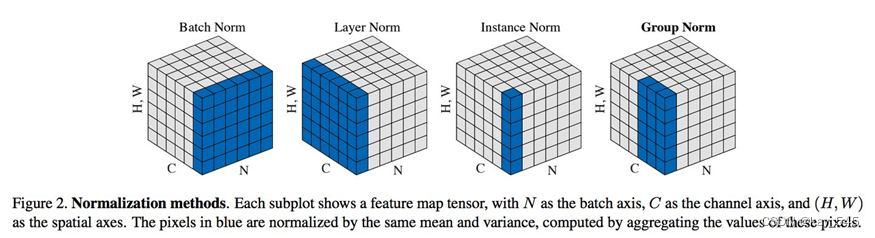
17.8 BN/LN/IN/GN区别
下面是关于批量归一化(BN)、层归一化(LN)、实例归一化(IN)和组归一化(GN)的区别:
| 归一化方法 | 训练阶段统计量 | 归一化对象 | 适用范围 | 实现方式 |
| BN | 每个mini-batch | 每一层的输入数据 | 批量数据(mini-batch) | 参数化 |
| LN | 整个样本集 | 每一层的输入数据 | 每一层的所有样本 | 参数化 |
| IN | 每个样本 | 每一层的输入数据 | 每一层的每一个样本 | 参数化 |
| GN | 每个组 | 每一层的输入数据 | 每一层的特定分组 | 非参数化 |
- 训练阶段统计量:在训练阶段用于归一化的统计量。BN使用每个mini-batch的均值和标准差,LN使用整个样本集的均值和标准差,IN使用每个样本的均值和标准差,而GN则使用每个组(group)的均值和标准差。
- 归一化对象:每一层的输入数据进行归一化的对象。BN、LN、IN和GN都是对每一层的输入数据进行归一化处理,但归一化的对象不同。
- 适用范围:归一化方法适用的数据范围。BN适用于批量数据(mini-batch),LN适用于每一层的所有样本,IN适用于每一层的每一个样本,而GN适用于每一层的特定分组。
- 实现方式:归一化方法的实现方式。BN、LN和IN都是参数化的,即归一化操作会受到训练过程中学习到的参数的影响,而GN则是非参数化的,不会学习到额外的参数。