earning 3D Geometry and Feature Consistent Gaussian Splatting for Object Removal
学习3D几何和特征一致的高斯溅射目标去除
HKUST &Qianyi Wu Monash University &Guofeng Zhang Zhejiang University &Dan Xu HKUST
香港科技大学&吴倩怡莫纳什大学&张国锋浙江大学&徐丹香港科技大学
Abstract 摘要 [2404.13679] Learning 3D Geometry and Feature Consistent Gaussian Splatting for Object Removal
This paper tackles the intricate challenge of object removal to update the radiance field using the 3D Gaussian Splatting [15]. The main challenges of this task lie in the preservation of geometric consistency and the maintenance of texture coherence in the presence of the substantial discrete nature of Gaussian primitives. We introduce a robust framework specifically designed to overcome these obstacles. The key insight of our approach is the enhancement of information exchange among visible and invisible areas, facilitating content restoration in terms of both geometry and texture. Our methodology begins with optimizing the positioning of Gaussian primitives to improve geometric consistency across both removed and visible areas, guided by an online registration process informed by monocular depth estimation. Following this, we employ a novel feature propagation mechanism to bolster texture coherence, leveraging a cross-attention design that bridges sampling Gaussians from both uncertain and certain areas. This innovative approach significantly refines the texture coherence within the final radiance field. Extensive experiments validate that our method not only elevates the quality of novel view synthesis for scenes undergoing object removal but also showcases notable efficiency gains in training and rendering speeds. Project Page: GScream
本文解决了物体去除的复杂挑战,使用3D高斯溅射更新辐射场[ 15]。这项任务的主要挑战在于保存的几何一致性和维护纹理的连贯性存在的大量离散性质的高斯基元。我们引入了一个专门为克服这些障碍而设计的强大框架。我们的方法的关键见解是增强可见和不可见区域之间的信息交换,促进几何和纹理方面的内容恢复。我们的方法从优化高斯基元的定位开始,以提高移除区域和可见区域的几何一致性,并通过单目深度估计提供的在线注册过程进行指导。 在此之后,我们采用了一种新的特征传播机制来增强纹理的一致性,利用交叉注意设计,将来自不确定区域和特定区域的高斯采样桥接起来。这种创新的方法显着细化最终辐射场内的纹理相干性。大量的实验验证,我们的方法不仅提高了质量的新的视图合成的场景进行对象删除,但也展示了显着的效率收益的训练和渲染速度。项目页面:https://w-ted.github。新闻/出版物/gscream
1Introduction 一、导言
3D object removal from pre-captured scenes stands as a complex yet pivotal challenge in the realm of 3D vision, garnering significant attention in computer vision and graphics, particularly for its applications in virtual reality and content generation. This task extends beyond the scope of its 2D counterpart, i.e. image in-painting [3], which primarily focuses on texture filling. In 3D object removal, the intricacies of geometry completion become equally crucial, and the choice of 3D representation plays a significant role in the effectiveness of the model and rendering quality. [13; 10; 11; 9; 31; 17; 37].
从预先捕获的场景中去除3D对象是3D视觉领域中一个复杂而关键的挑战,在计算机视觉和图形学中获得了极大的关注,特别是在虚拟现实和内容生成中的应用。这项任务超出了其2D对应物的范围,即图像修复[ 3],其主要关注纹理填充。在3D对象移除中,几何完成的复杂性变得同样重要,并且3D表示的选择在模型的有效性和渲染质量中起着重要作用。[ 13; 10; 11; 9; 31; 17; 37]。
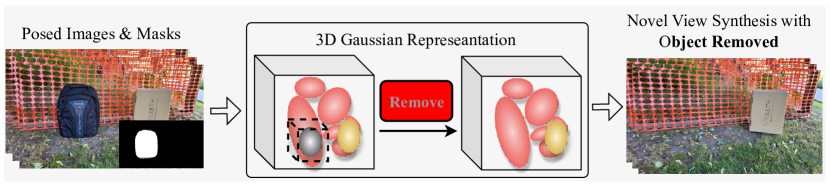
Figure 1:Illustration of the Object Removal using 3D Gaussian Representations. Given a set of multi-view posed images and object masks, our goal is to learn a 3D consistent Gaussian representation modeling the scene with the object removed, which enables the consistent novel view synthesis without the specific object.
图1:使用3D高斯表示的对象移除图示。给定一组多视点姿态图像和对象掩模,我们的目标是学习一个3D一致的高斯表示模型的场景与对象删除,这使得一致的新视图合成没有特定的对象。
Recently, the radiance field representation has revolutionized the community due to the superior quality of scene representation and novel view synthesis. Among these, the Neural Radiance Field (NeRF) [21] has emerged as the groundbreaking implicit 3D representation approach, offering photo-realistic view synthesis quality. The high-quality rendering capabilities of NeRF have spurred further development in 3D object removal techniques based on it [17; 23; 41; 42; 22]. However, the intrinsic drawbacks of implicit representation, particularly its slow training and rendering speeds, pose severe limitations for practical applications based on object removal. For instance, it is highly expected that the system can quickly model the scene given any object mask condition for object removal, which enforces a straight requirement in terms of training efficiency. Another critical issue is that the object removal task relies on a flexible scene representation that can learn effective multi-view consistency to synthesize high-quality scene images with objects masked.
最近,辐射场表示已经彻底改变了社区由于上级质量的场景表示和新颖的视图合成。其中,神经辐射场(NeRF)[21]已成为突破性的隐式3D表示方法,提供照片般逼真的视图合成质量。NeRF的高质量渲染能力刺激了基于它的3D对象去除技术的进一步发展[17;23;41;42;22]。然而,隐式表示的固有缺点,特别是其缓慢的训练和渲染速度,对基于对象去除的实际应用造成严重限制。例如,高度期望系统能够在给定用于对象移除的任何对象掩模条件的情况下快速地对场景建模,这在训练效率方面强制执行直接要求。 另一个关键问题是,对象移除任务依赖于灵活的场景表示,该场景表示可以学习有效的多视图一致性以合成具有被掩蔽对象的高质量场景图像。
To effectively address the dual challenges of producing an enhanced radiance field for object removal, we introduce a pioneering strategy leveraging 3D Gaussian Splatting (3DGS) [15]. Unlike implicit representations, 3DGS explicitly models the 3D scene using tons of Gaussian primitives. This approach has demonstrated notable advances in rendering efficiency and quality, surpassing traditional NeRF-based methods [24; 1]. However, applying 3DGS to object removal presents unique challenges, primarily from two aspects: 1) Geometry Accuracy: The inherently discrete nature of a significant number of Gaussians can result in an inaccurate representation of the underlying geometry in the standard 3DGS model. This inaccuracy poses a considerable challenge in executing geometry completion and ensuring geometric consistency in the object removal areas within a 3D space. 2) Texture Coherence: Filling the region behind the removed object with consistent textures under the 3DGS framework represents another unexplored challenge. Achieving texture coherence across various viewing angles is essential, yet the methodologies to realize this goal within the 3DGS paradigm are currently underdeveloped.
为了有效地解决为物体去除产生增强辐射场的双重挑战,我们引入了利用3D高斯溅射(3DGS)的开创性策略[15]。与隐式表示不同,3DGS使用大量高斯基元显式地对3D场景进行建模。这种方法在渲染效率和质量方面取得了显着进步,超过了传统的基于NeRF的方法[24;1]。然而,将3DGS应用于对象移除提出了独特的挑战,主要来自两个方面:1)几何精度:大量高斯的固有离散性质可能导致标准3DGS模型中底层几何的不准确表示。这种不准确性在执行几何完成和确保3D空间内的对象移除区域中的几何一致性方面提出了相当大的挑战。 2)纹理连贯性:在3DGS框架下,用一致的纹理填充被移除对象后面的区域代表了另一个未探索的挑战。在不同的视角实现纹理的一致性是必不可少的,但在3DGS范式内实现这一目标的方法目前还不发达。
The cornerstone of our approach lies in augmenting the interaction between Gaussians in both the in-painted and visible regions, encompassing geometry and appearance enhancements. Initially, to bolster geometric consistency across the removal and visible areas, our method incorporates monocular depth estimation from multi-view images as a supplementary geometric constraint. This enhances the precision of 3D Gaussian Splatting (3DGS) placements. Employing a novel online depth alignment strategy, we refine the spatial arrangement of Gaussians within the removal area, ensuring improved alignment with adjacent regions. In terms of texture synthesis, our goal is to achieve a seamless blend between the visible and in-painted regions. Distinct from approaches tailored for implicit representations, which predominantly rely on image domain guidance for supervision, such as generating multi-view in-painted images [23; 42; 41] or simulating pseudo-view-dependent effects from NeRF [22], the explicit characteristic of Gaussian representations opens the door to innovative solutions. We introduce a novel method that facilitates feature interactions between Gaussian clusters from both visible and in-painted regions. This is achieved through a meticulously designed attention mechanism, which significantly improves the alignment of apparent and in-painted appearances. By sampling Gaussians positioned within both masked and unmasked areas, we refine their features via cross-attention in preparation for the final rendering. This self-interaction strategy capitalizes on the explicit nature of Gaussians to fine-tune the feature distribution in 3D spaces, culminating in enhanced coherence in the rendered outcomes. Furthermore, to mitigate the computational burden associated with directly manipulating millions of diminutive Gaussians, we implement a lightweight Gaussian Splatting architecture, Scaffold-GS [19], as our base model. Scaffold-GS introduces a novel paradigm that organizes Gaussians around anchor points, using the features associated with these anchors to decode attributes for the respective Gaussians. This approach not only streamlines the processing of Gaussian data but also significantly enhances the efficiency and effectiveness of our rendering process.
我们的方法的基石在于增强高斯在绘画和可见区域之间的相互作用,包括几何和外观增强。最初,为了支持整个移除和可见区域的几何一致性,我们的方法将多视图图像的单目深度估计作为补充几何约束。这增强了3D高斯溅射(3DGS)放置的精度。采用一种新的在线深度对齐策略,我们改进了去除区域内高斯的空间排列,确保与相邻区域的对齐得到改善。在纹理合成方面,我们的目标是实现可见区域和已绘制区域之间的无缝融合。 与为隐式表示量身定制的方法不同,隐式表示主要依赖于图像域指导进行监督,例如生成多视图内画图像[ 23; 42; 41]或模拟NeRF的伪视图依赖效果[ 22],高斯表示的显式特性为创新解决方案打开了大门。我们介绍了一种新的方法,促进高斯聚类之间的功能相互作用,从可见光和在画的区域。这是通过精心设计的注意力机制来实现的,该机制显着改善了外观和绘画外观的对齐。通过对位于掩蔽和未掩蔽区域内的高斯进行采样,我们通过交叉注意来细化它们的特征,为最终渲染做准备。这种自交互策略利用高斯的显式性质来微调3D空间中的特征分布,最终增强了渲染结果的一致性。 此外,为了减轻与直接操纵数百万个小型高斯相关的计算负担,我们实现了一个轻量级的高斯溅射架构Scaffold-GS [ 19]作为我们的基础模型。Scaffold-GS引入了一种新的范例,该范例围绕锚点组织高斯,使用与这些锚相关联的特征来解码各个高斯的属性。这种方法不仅简化了高斯数据的处理,而且显着提高了我们的渲染过程的效率和有效性。
To the end, we propose a holistic solution coined GScream for object removal from Gaussian Splatting while maintaining the geometry and feature consistency. The contribution of our paper is threefold summarized below:
最后,我们提出了一个整体的解决方案,创造GScream从高斯飞溅对象删除,同时保持几何和特征的一致性。我们的论文的贡献是三重总结如下:
- •
We introduce GScream, a model that employs 3D Gaussian Splatting for object removal, specifically targeting and mitigating issues related to geometric inconsistencies and texture incoherence. This approach not only achieves significant efficiency but also ensures superior rendering quality when compared to traditional NeRF-based methods.
·我们引入了GScream,这是一种采用3D高斯溅射进行对象移除的模型,专门针对和缓解与几何不一致和纹理不一致相关的问题。与传统的基于NeRF的方法相比,这种方法不仅实现了显着的效率,而且还确保了上级渲染质量。 - •
To overcome the geometry inconsistency in the removal area, we incorporate multiview monocular depth estimation as an extra constraint. This aids in the precise optimization of Gaussian placements. Through an online depth alignment process, we enhance the geometric consistency between the removed area and the surrounding visible areas.
·为了克服去除区域中的几何不一致性,我们将多视图单目深度估计作为额外的约束。这有助于精确优化高斯放置。通过在线深度对齐过程,我们增强了移除区域与周围可见区域之间的几何一致性。 - •
Addressing the challenge of appearance incoherence, we exploit the explicit representation capability of 3DGS. We propose a unique feature regularization strategy that fosters improved interaction between Gaussian clusters in both the in-painted and visible sections of the scene. This method ensures coherence and elevates the appearance quality of the final rendered images.
·解决外观不连贯的挑战,我们利用3DGS的显式表示能力。我们提出了一种独特的特征正则化策略,该策略可以改善场景中的绘画和可见部分中高斯聚类之间的交互。这种方法确保了一致性,并提高了最终渲染图像的外观质量。
2Related Works 2相关作品
2.1Radiance Field for Novel View Synthesis
2.1一种新的视图合成方法
Photo realistic view synthesis is a long-standing problem in computer vision and computer graphics [30; 16; 32; 18]. Recently, the radiance field approaches [21] revolutionized this task by only capturing scenes with multiple photos and brought the reconstruction quality to a new level with the help of neural implicit representations [33; 25] and effective positional encoding [21; 35]. While the implicit representation benefits the optimization, the extensive queries of the network along the ray for rendering make the entire rendering speed costly and time-consuming [1; 2]. Recently, there have been several attempts to facilitate the rendering speeds [7; 26; 24; 15]. Among all of them, the 3D Gaussian splitting (3DGS) representation [15; 19] stands as the most representative one which reaches a real-time rendering with state-of-the-art visual quality. 3DGS represents the radiance field as a collection of learnable 3D Gaussian. Each Gaussian blob includes information describing its 3D position, opacity, anisotropic covariance, and color features. With the dedicated design of a tiled-based splatting solution for training, the rendering of 3DGS is real-time with high quality. However, 3DGS is only proposed for novel view synthesis. It remains challenging to tame it if we want to remove objects from the pre-captured images.
照片真实感视图合成是计算机视觉和计算机图形学中的一个长期存在的问题[30;16;32;18]。最近,辐射场方法[21]通过仅捕获具有多张照片的场景彻底改变了这项任务,并在神经隐式表示[33;25]和有效位置编码[21;35]的帮助下将重建质量提高到一个新的水平。虽然隐式表示有利于优化,但用于渲染的网络沿着光线的广泛查询使得整个渲染速度昂贵且耗时[1;2]。最近,有几个尝试,以促进渲染速度[7;26;24;15]。在所有这些方法中,3D高斯分裂(3DGS)表示[15;19]是最具代表性的一种,它达到了具有最先进视觉质量的实时渲染。3DGS将辐射场表示为可学习的3D高斯的集合。 每个高斯斑点包括描述其3D位置、不透明度、各向异性协方差和颜色特征的信息。通过专门设计的基于平铺的飞溅解决方案进行训练,3DGS的渲染是实时的,具有高质量。然而,3DGS仅被提出用于新颖的视图合成。如果我们想从预先捕获的图像中删除对象,那么驯服它仍然具有挑战性。
2.2Object Removal from Radiance Field
2.2从辐射场移除对象
As the fidelity of 3D scene reconstruction advances, the ability to edit pre-captured 3D scenes becomes increasingly vital. Object removal, a key application in content generation, has garnered significant interest, particularly within the realm of radiance field representation. Several methods have been proposed to tackle this challenge [17; 41; 42; 23; 22]. For instance, NeRF-in [17] and SPInNeRF [23] utilize 2D in-painting models to fill gaps in training views and rendered depths. However, these approaches often result in inconsistent in-painted images across different views, leading to “ghost” effects in the removed object regions. View-Subtitude [22] offers an alternative by in-painting a single reference image and designing depth-guided warping and bilateral filtering techniques to guide the generation in other views. Despite these innovations, the underlying issue of slow training and rendering speed persists in these NeRF-based methods. The recent 3DGS-based general editing framework, GaussianEditor [6], includes the operation of deleting objects. However, despite its faster editing efficiency compared to NeRF-based methods, it still lacks specific constraints in the 3D domain. For the object removal task, purely fitting the 2D priors provided by the image in-painting model can also result in discontinuities in the 3D domain.
随着3D场景重建的保真度的提高,编辑预先捕获的3D场景的能力变得越来越重要。物体去除是内容生成中的一个关键应用,已经引起了人们的极大兴趣,特别是在辐射场表示领域。已经提出了几种方法来应对这一挑战[17;41;42;23;22]。例如,NeRF—in [17]和SPInNeRF [23]利用2D in—painting模型来填充训练视图和渲染深度中的间隙。然而,这些方法通常导致跨不同视图的不一致的内绘图像,从而导致移除的对象区域中的"重影"效果。View—Subtitude [22]提供了一种替代方案,通过对单个参考图像进行内部绘制,并设计深度引导扭曲和双边过滤技术来引导其他视图中的生成。尽管有这些创新,但这些基于NeRF的方法仍然存在训练和渲染速度缓慢的根本问题。 最近基于3DGS的通用编辑框架GaussianEditor [ 6]包括删除对象的操作。然而,尽管与基于NeRF的方法相比,它的编辑效率更快,但它仍然缺乏3D领域的特定约束。对于对象移除任务,纯粹拟合由图像修补模型提供的2D先验也可能导致3D域中的不连续性。
In response to these limitations, our work proposes a novel solution utilizing the 3D Gaussian Splatting (3DGS) [15] representation to achieve efficient object removal. The 3DGS method offers a more rapid training and rendering process, making it a suitable candidate for this application. However, 3DGS, in its standard form, primarily focuses on RGB reconstruction loss, leading to less accurate underlying geometry for complex scenes. To make it suitable for recovering a scene without a selected object, we approach the problem in two stages: depth completion followed by texture propagation. We first enhance the geometric accuracy of 3DGS using monocular depth supervision. With a more refined geometric base, we then employ this improved structure to propagate 3D information outside the in-painted region to refine the texture in the in-painted region. These processes ensure not only the efficient removal of objects but also the maintenance of the scene’s visual and geometric integrity.
为了应对这些限制,我们的工作提出了一种新的解决方案,利用3D高斯溅射(3DGS)[ 15]表示来实现有效的对象去除。3DGS方法提供了更快速的训练和渲染过程,使其成为该应用的合适候选者。然而,3DGS在其标准形式中主要关注RGB重建损失,导致复杂场景的底层几何结构不太准确。为了使其适合于恢复没有选定对象的场景,我们分两个阶段来处理这个问题:深度完成,然后是纹理传播。我们首先使用单目深度监督来提高3DGS的几何精度。有了一个更精细的几何基础,我们然后采用这种改进的结构来传播3D信息以外的绘画区域,以改善在绘画区域的纹理。这些过程不仅确保了物体的有效去除,而且还保持了场景的视觉和几何完整性。
3The Propose Framework: GScream
3建议框架:GScream
As illustrated in Fig. 1, given 𝑁 multi-view posed images {𝐼𝑖|𝑖=0,…,𝑁} of a static real-world scene with the corresponding binary masks specifying the object {𝑀𝑖|𝑖=0,…,𝑁}. The object mask 𝑀𝑖 is a binary mask with the object region set as 1 and the background set as 0. We assume these masks are provided for training, which can be obtained trivially by video segmentation [17; 8] or a straightforward 3D annotation [42; 5]. Our goal is to learn a 3D Gaussian representation to model the real-world scene with the object removed. To address this problem, we propose a novel framework named GScream, and the overview of it can be found in Fig. 2. First, we select one view as the reference view and perform the 2D in-painting [27; 28] to complete the content by the corresponding mask. Without loss of generality, we denote the selected view with index 0 and the in-painted image as 𝐼¯. We use the in-painted one single image to train the final 3DGS. The overview of our proposed GScream is shown in Fig. 2.
如图1所示,给定静态现实世界场景的 𝑁 多视图姿态图像 {𝐼𝑖|𝑖=0,…,𝑁} ,其中对应的二进制掩码指定对象 {𝑀𝑖|𝑖=0,…,𝑁} 。对象掩模 𝑀𝑖 是二进制掩模,其中对象区域被设置为 1 并且背景被设置为 0 。我们假设这些掩模用于训练,可以通过视频分割[ 17; 8]或直接的3D注释[ 42; 5]来轻松获得。我们的目标是学习一个3D高斯表示来建模去除对象的真实世界场景。为了解决这个问题,我们提出了一个名为GScream的新框架,它的概述可以在图2中找到。首先,我们选择一个视图作为参考视图,并执行2D inpainting [ 27; 28]以通过相应的掩码完成内容。不失一般性,我们用索引 0 表示所选视图,用 𝐼¯ 表示所绘图像。我们使用一个单独的图像来训练最终的3DGS。我们提出的GScream的概述如图所示。 2.
The organization of this section is presented as follows: we will introduce the preliminary about 3D Gaussian Splatting and its variants in Sec. 3.1, and then dive into the details about the core design of our framework in terms of geometry consistency and appearance coherence in the following subsection.
本节的组织如下:我们将在第二节中介绍关于3D高斯溅射及其变体的初步内容。3.1,然后在下面的小节中深入讨论我们框架的核心设计在几何一致性和外观一致性方面的细节。
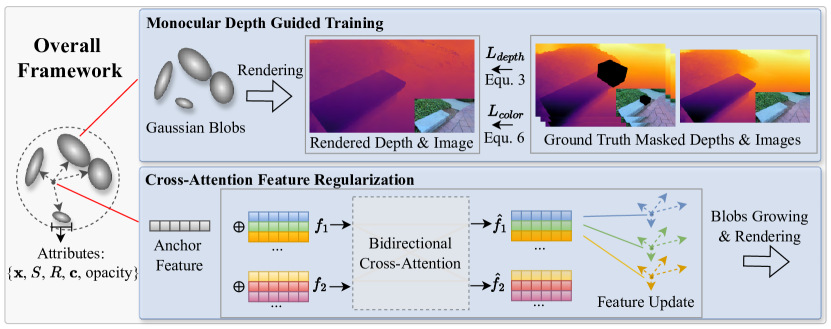
Figure 2:Illustration of our GScream framework. It consists of two novel components, which are monocular depth guided training and cross-attention feature regularization. Our 3D Gaussian splatting (3DGS) representation is initialized by the 3D SfM points and supervised by both images and multi-view monocular depth estimation. The additional depth losses help refine the geometry accuracy within the 3DGS framework. The following 3D feature regularization performs texture propagation to refine the appearance within the 3D in-painted region.
图2:我们的GScream框架的插图。它包括两个新的组件,这是单目深度引导训练和交叉注意特征正则化。我们的3D高斯飞溅(3DGS)表示初始化的3D SfM点和监督的图像和多视图单目深度估计。额外的深度损失有助于改进3DGS框架内的几何精度。下面的3D特征正则化执行纹理传播以优化3D内绘区域内的外观。
3.1Preliminary: 3D Gaussain Splatting
3.1初步:3D Gaussain飞溅
3D Gaussian Splatting We use the 3D Gaussian representation as our underlying modeling structure. Each Gaussian blob has the following attributes: 3D coordinates 𝝁, scale matrix 𝑆, rotation matrix 𝑅, color features 𝒄, and its opacity. With these attributes, the Gaussians are defined by the covariance matrix Σ=𝑅𝑆𝑆𝑇𝑅𝑇 centered at point 𝝁:
我们使用3D高斯表示作为我们的底层建模结构。每个高斯斑点具有以下属性:3D坐标 𝝁 、缩放矩阵 𝑆 、旋转矩阵 𝑅 、颜色特征 𝒄 及其不透明度。利用这些属性,高斯由以点 𝝁 为中心的协方差矩阵 Σ=𝑅𝑆𝑆𝑇𝑅𝑇 定义:
| 𝐺(𝑥)=exp−12(𝒙−𝝁)𝑇Σ−1(𝒙−𝝁). | (1) |
This Gaussian is multiplied by the opacity in the rendering process. By projecting the covariance onto the 2D plane following Zwicker et al. [45], we can obtain the projected Gaussian and adopt the volume rendering (𝛼-blending) [20] to render the color in the image plane.
在渲染过程中,该高斯分布乘以不透明度。通过将协方差投影到2D平面上,遵循Zwicker等人。[ 45],我们可以获得投影高斯,并采用体绘制( 𝛼 -混合)[ 20]来渲染图像平面中的颜色。
| 𝐶^=∑𝑘=1𝐾𝒄𝑘𝛼𝑘∏𝑗=1𝑘−1(1−𝛼𝑗), | (2) |
where 𝐾 means the number of sampling points along the ray and 𝛼 is given by evaluating the projected Gaussian of 𝐺(𝑥) and the corresponding opacity. The initial 3D coordinates of each 3D Gaussian blob are initialized as the coordinates of the SfM points [29]. All the attributes of Gaussians are optimized by the reconstruction loss of the image. More details can be found in [15].
其中 𝐾 表示沿光线沿着的采样点的数量,而 𝛼 通过评估 𝐺(𝑥) 的投影高斯和相应的不透明度来给出。每个3D高斯斑点的初始3D坐标被初始化为SfM点的坐标[ 29]。利用图像的重建损失对高斯的所有属性进行优化。更多的细节可以在[ 15]中找到。
Scaffold-GS While the sparse initial points are insufficient to model the entire scene, 3DGS designs a densification operation to split and merge Gaussians to capture more details. It will result in better rendering quality while leading to a heavy storage burden. Therefore, we adopt a lightweight Gaussian Splatting structure, Scaffold-GS [19]. The key contribution of it is to use anchors to generate new Gaussian attributes with several decoders. There will be a learnable feature embedding attached to each anchor, and all the new Gaussian attributes can be extracted from the anchor features. With the densification performed in the anchor points, the storage requirement of Scaffold-GS can be significantly reduced and benefit the modeling of the radiance field. We adopt it as our base model to propose an efficient object removal solution for Gaussian Splatting. More details can be found in [19].
Scaffold-GS虽然稀疏的初始点不足以对整个场景进行建模,但3DGS设计了一个致密化操作来分割和合并高斯以捕获更多细节。这将导致更好的渲染质量,同时导致沉重的存储负担。因此,我们采用轻量级高斯溅射结构,Scaffold-GS [ 19]。它的主要贡献是使用锚来生成新的高斯属性与几个解码器。每个锚都有一个可学习的特征嵌入,所有新的高斯属性都可以从锚特征中提取出来。通过在锚点进行致密化,可以显著降低支架-GS的存储需求,并且有利于辐射场的建模。我们采用它作为我们的基础模型,提出了一个有效的对象去除解决方案高斯飞溅。更多的细节可以在[ 19]中找到。
3.2Improve Geometry Consistency by Monocular Depth Guidance
3.2用单目深度制导提高几何一致性
One of the challenges to performing object removal upon 3DGS is the underlying geometry is too noisy [15], which further leads to difficulty when performing geometry completion for the removal region. To improve the quality, we propose to leverage the guidance from estimated monocular depth as extra supervision. Concretely, we use the depth estimation model [14] to extract the depth 𝒟={𝐷𝑖|𝑖=0,…,𝑁} of each image from the in-painted image 𝐼¯ and other views ℐ. Here 𝐷0 corresponds to the estimated depth of 𝐼¯.
在3DGS上执行对象移除的挑战之一是底层几何结构太嘈杂[ 15],这进一步导致在对移除区域执行几何结构完成时的困难。为了提高质量,我们建议利用来自估计的单眼深度的指导作为额外的监督。具体地,我们使用深度估计模型[ 14]来从绘画图像 𝐼¯ 和其他视图 ℐ 中提取每个图像的深度 𝒟={𝐷𝑖|𝑖=0,…,𝑁} 。这里 𝐷0 对应于 𝐼¯ 的估计深度。
Online Depth Alignment and Supervision The monocular depth estimation is not a metric depth [14]. Therefore, we propose an online depth alignment design to utilize the depth guidance. However, the inconsistent depth estimation of 𝐼¯ and ℐ brings an additional issue. The ℐ contains the object that we want to remove, while 𝐼¯ depicts an image without the object. Therefore, we propose the following weighted depth loss to solve this problem:
在线深度对准和监督单目深度估计不是度量深度[ 14]。因此,我们提出了一个在线深度对齐设计,利用深度指导。然而, 𝐼¯ 和 ℐ 的不一致的深度估计带来了额外的问题。 ℐ 包含我们要删除的对象,而 𝐼¯ 描绘了没有对象的图像。因此,我们提出以下加权深度损失来解决这个问题:
| ℒdepth=1𝐻𝑊∑𝑀𝑖′‖(𝑤𝐷^𝑖+𝑞)−𝐷𝑖‖, | (3) |
| 𝑀𝑖′={𝜆1𝑀𝑖+𝜆2(1−𝑀𝑖), if 𝑖=0𝜆3(1−𝑀𝑖), if 𝑖≠0. | (4) |
Where 𝐷^𝑖 is the rendered depth map from 3D Gaussian Splatting calculated similar to the Equ. 2 by:
其中, 𝐷^𝑖 是类似于等式1计算的来自3D高斯溅射的渲染深度图。2人:
| 𝐷^=∑𝑘=1𝐾𝑡𝑘𝛼𝑘∏𝑗=1𝑘−1(1−𝛼𝑗), | (5) |
where 𝑡𝑘 is the z-coordinates of Gaussian mean 𝜇𝑘 in the corresponding camera coordinate system. The depth obtained from the monocular estimator 𝐷𝑖 and the rendered depth 𝐷^𝑖 by the 3D Gaussians have different numerical scales, so we cannot directly calculate the loss. We employ an online alignment method to address the scale issue. Specifically, we align the rendered depth using scale and shift parameters, denoted as 𝑤 and 𝑞, to match the scale of the monocular depth before calculating the loss. The scale and shift are obtained by solving a least-squares problem [14; 43]. For the image in ℐ, we only use the points outside the mask region, and the resulting scale and shift are applied to the entire depth map. We design different weights to calculate the depth loss as in Equ. 4. With this design, the depth supervision is applied to the entire depth map 𝐷0 for the reference view, while it is applied on the background region for other views’ depth {𝐷𝑖|𝑖=1,…,𝑁}. The 𝜆1,𝜆2,𝜆3 are hyper-parameters to balance the influence of mask weights. In addition to the point-wise L1 loss, we also enforce a total variation loss to enforce smoothness in the depth difference as follows:
其中 𝑡𝑘 是高斯平均值 𝜇𝑘 在对应相机坐标系中的z坐标。从单目估计器 𝐷𝑖 获得的深度和通过3D高斯绘制的深度 𝐷^𝑖 具有不同的数值尺度,因此我们不能直接计算损失。我们采用在线对齐方法来解决规模问题。具体来说,我们使用标度和移位参数(表示为 𝑤 和 𝑞 )对齐渲染的深度,以在计算损失之前匹配单眼深度的标度。通过求解最小二乘问题获得尺度和移位[ 14; 43]。对于 ℐ 中的图像,我们只使用遮罩区域之外的点,并且将产生的缩放和移位应用于整个深度图。我们设计了不同的权重来计算深度损失,如等式中所示。4.利用该设计,深度监督被应用于参考视图的整个深度图 𝐷0 ,而深度监督被应用于其他视图的深度 {𝐷𝑖|𝑖=1,…,𝑁} 的背景区域。 𝜆1,𝜆2,𝜆3 是用于平衡掩码权重的影响的超参数。 除了逐点L1损失之外,我们还强制执行总变差损失以强制执行深度差的平滑性,如下所示:
| ℒtv=1𝑁∑𝑀𝑖′∥∇((𝑤𝐷^𝑖+𝑞)−𝐷𝑖))∥ | (6) |
Color Loss Following [15; 19], we also apply the multi-view color reconstruction loss for both the training:
在[ 15; 19]之后,我们还将多视图颜色重建损失应用于两个训练:
| ℒcolor=1𝐻𝑊∑𝑀𝑖′ | ((1−𝜆𝑠𝑠𝑖𝑚)∥𝐶^𝑖−𝐼𝑖∥ | (7) | ||
| +𝜆𝑠𝑠𝑖𝑚𝑆𝑆𝐼𝑀(𝐶^𝑖,𝐼𝑖)), |
where 𝐶^ is the rendered image from 3DGS. Thanks to the rendering efficiency of 3DGS, we can render the entire image and perform a structural image reconstruction loss [40] SSIM to constrain the RGB image reconstruction. The overall training loss is the weighted sum of depth and color loss:
其中 𝐶^ 是来自3DGS的渲染图像。由于3DGS的渲染效率,我们可以渲染整个图像并执行结构图像重建损失[ 40] SSIM以约束RGB图像重建。总训练损失是深度和颜色损失的加权和:
| ℒtotal=𝜆𝑑𝑒𝑝𝑡ℎℒdepth+𝜆𝑡𝑣ℒtv+ℒcolor | (8) |
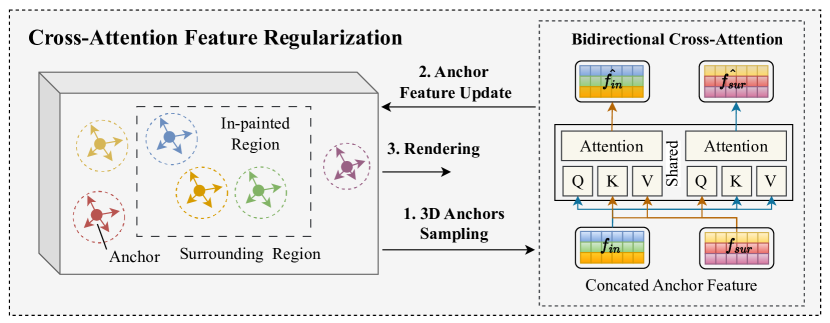
Figure 3:Illustration of the Cross-attention Feature Regularization. Our regularization module consists of 3D Gaussian Sampling and a Bidirectional Cross-Attention Module, propagating the 3D feature from surrounding blobs to the in-painted region. As a complement to the 2D prior, the cross-attention mechanism enables the transmission of information among 3D Gaussian blobs, further ensuring the similarity of appearance between the in-painted region and its surroundings.
图3:交叉注意力特征正则化的图示。我们的正则化模块由3D高斯采样和双向交叉注意模块组成,将3D特征从周围的斑点传播到绘画区域。作为对2D先验的补充,交叉注意机制使3D高斯斑点之间的信息传输成为可能,进一步确保了绘画区域与其周围环境之间的外观相似性。
3.3Cross-Attention Feature Regularization
3.3交叉注意特征正则化
Through monocular depth-guided training, we enhance the geometry of the 3D Gaussian representation. The following question is how we can refine the texture in the missing region from the surrounding environment.
通过单目深度引导训练,我们增强了3D高斯表示的几何形状。接下来的问题是我们如何从周围环境中细化缺失区域中的纹理。
Prior approaches in the realm of 3D object removal commonly employ a strategy that involves generating pseudo-RGB guidance to refresh the scene’s information. This typically relies on leveraging multi-view in-painted images to update NeRF/3DGS models [23; 42; 6], or on producing view-dependent effects as a form of guidance [22]. However, these methods tend to be sensitive to the quality of the pseudo-ground truth and often overlook the intrinsic relationships between the in-painted regions and their visible counterparts.
在3D对象移除领域中的现有方法通常采用涉及生成伪RGB指导以刷新场景信息的策略。这通常依赖于利用多视图内绘图像来更新NeRF/3DGS模型[ 23; 42; 6],或者作为一种指导形式产生视图相关效果[ 22]。然而,这些方法往往对伪地面实况的质量敏感,并且常常忽略了内部绘制区域与其可见对应物之间的内在关系。
The key insight of our model is to propagate the accurate texture in the surrounding region into the in-painted region in a certain manner. The explicit nature of 3DGS provides us the possibility to use the information from visible parts to update the content in the in-painted region. We expect this propagation can provide reliable information for the in-painted region in 3D space and ensure the propagated content is consistent across multiple viewpoints. Specifically, as shown in Fig. 3, we perform a two-stage procedure to achieve texture propagation, i.e., 3D anchors sampling, and subsequent bidirectional cross-attention.
我们的模型的关键见解是以某种方式将周围区域中的准确纹理传播到绘画区域中。3DGS的显式性质为我们提供了使用可见部分的信息来更新内画区域中的内容的可能性。我们期望这种传播可以为3D空间中的绘画区域提供可靠的信息,并确保传播的内容在多个视点之间是一致的。具体地,如图3所示,我们执行两阶段过程来实现纹理传播,即,3D锚点采样,以及随后的双向交叉关注。
3D Gaussian Sampling First, for each view 𝑖, we sample the patch that can simultaneously cover both the inside and the outside of the mask 𝑀𝑖. Then, we project the center coordinates of the 3D Gaussian anchors to the current view, to determine which anchor’s 2D projection falls within the sampled 2D patch. After we identify the clusters of Gaussian anchors whose projections fall within the patch, we can easily categorize them into two groups based on whether their 2D projections are inside or outside the 2D mask. In this way, we sample 3D Gaussian anchors in both the in-painted and surrounding regions. Our goal is to sample 3D points in both the in-painted region and the surrounding region, as shown in the left part of Fig. 3. Although there are alternative sampling methods such as using depth for point back-projection, we believe that our approach based on 2D mask back-projection is sufficient to achieve our objectives.
3D高斯采样首先,对于每个视图 𝑖 ,我们对可以同时覆盖掩模 𝑀𝑖 的内部和外部的补丁进行采样。然后,我们将3D高斯锚点的中心坐标投影到当前视图,以确定哪个锚点的2D投影福尔斯落在采样的2D补丁内。在我们识别出投影落在补丁内的高斯锚点集群之后,我们可以很容易地根据它们的2D投影是在2D掩码内部还是外部将它们分为两组。通过这种方式,我们在内画区域和周围区域中对3D高斯锚点进行采样。我们的目标是在内画区域和周围区域中采样3D点,如图3的左侧部分所示。虽然有替代的采样方法,如使用深度的点反投影,我们相信,我们的方法的基础上2D掩模反投影是足以实现我们的目标。
Bidirectional Cross-Attention After obtaining the 3D Gaussian anchors from both regions, we perform bidirectional cross-attention between the two sets of Gaussian features to propagate information between the anchors. Specifically, we concatenate the two sets of Gaussian features as two tokens and take them as input to a bidirectional cross-attention structure following the classical definition [36] Attention(𝐐,𝐊,𝐕)=softmax(𝐐𝐊𝑇𝑑𝑘)𝐕, where 𝑑𝑘 is the token length.
双向交叉关注在从两个区域获得3D高斯锚点之后,我们在两组高斯特征之间执行双向交叉关注,以在锚点之间传播信息。具体来说,我们将两组高斯特征连接为两个标记,并将它们作为遵循经典定义的双向交叉注意结构的输入[ 36] Attention(𝐐,𝐊,𝐕)=softmax(𝐐𝐊𝑇𝑑𝑘)𝐕 ,其中 𝑑𝑘 是标记长度。
The output of the cross-attention structure, which represents the updated features, is then assigned back to the corresponding Gaussian anchors. The bidirectional structure of the cross-attention is designed to facilitate bidirectional information propagation between the features inside and outside the in-painted regions. It can be seen as two sets of shared-parameter cross-attention modules, enabling information exchange between the two sets of features. As shown in Fig. 3, let us assume that the sampled tokens in the in-painted and surrounding regions are represented by the 𝑓𝑖𝑛 and 𝑓𝑠𝑢𝑟. After passing them through the cross-attention module, the updated features can be denoted as 𝑓^𝑖𝑛 and 𝑓^𝑠𝑢𝑟:
交叉注意力结构的输出(代表更新的特征)然后被分配回相应的高斯锚。交叉注意的双向结构被设计为促进在内部绘制区域内部和外部的特征之间的双向信息传播。它可以被看作是两组共享参数的交叉注意模块,使两组特征之间的信息交换成为可能。如图3所示,让我们假设内画和周围区域中的采样标记由 𝑓𝑖𝑛 和 𝑓𝑠𝑢𝑟 表示。在通过交叉注意模块之后,更新的特征可以表示为 𝑓^𝑖𝑛 和 𝑓^𝑠𝑢𝑟 :
| 𝑓^𝑖𝑛 | =Attention(𝐐=𝑓𝑖𝑛,𝐊=𝑓𝑠𝑢𝑟,𝐕=𝑓𝑠𝑢𝑟) | (9) | ||
| 𝑓^𝑠𝑢𝑟 | =Attention(𝐐=𝑓𝑠𝑢𝑟,𝐊=𝑓𝑖𝑛,𝐕=𝑓𝑖𝑛) |
As shown in Fig. 2, when the sampled anchors complete the feature updates, all anchors undergo neural blobs growing and differentiable rendering as usual in [19]. The rendered depth map and image under the current viewpoint are then supervised by the total loss introduced in 8.
如图2所示,当采样的锚点完成特征更新时,所有锚点都会像[ 19]中一样进行神经斑点生长和可微渲染。然后通过在8中引入的总损失来监督当前视点下的渲染深度图和图像。
The 3D Gaussian sampling strategy together with the shared bidirectional cross-attention augments the anchor feature with similarity towards higher consistency. Through the gradients backpropagated to the anchors’ features in the visible region, the similar anchors in the unpainted region can also be updated due to the attention mechanism. This design improves the consistency between the in-painted region and visible certain areas, which leads to better texture coherence in our experiments.
3D高斯采样策略与共享的双向交叉注意一起增强了具有相似性的锚特征,以实现更高的一致性。通过将梯度反向传播到可见区域中的锚点特征,由于注意力机制,未绘制区域中的相似锚点也可以被更新。这种设计提高了绘画区域和可见区域之间的一致性,从而在我们的实验中实现了更好的纹理一致性。