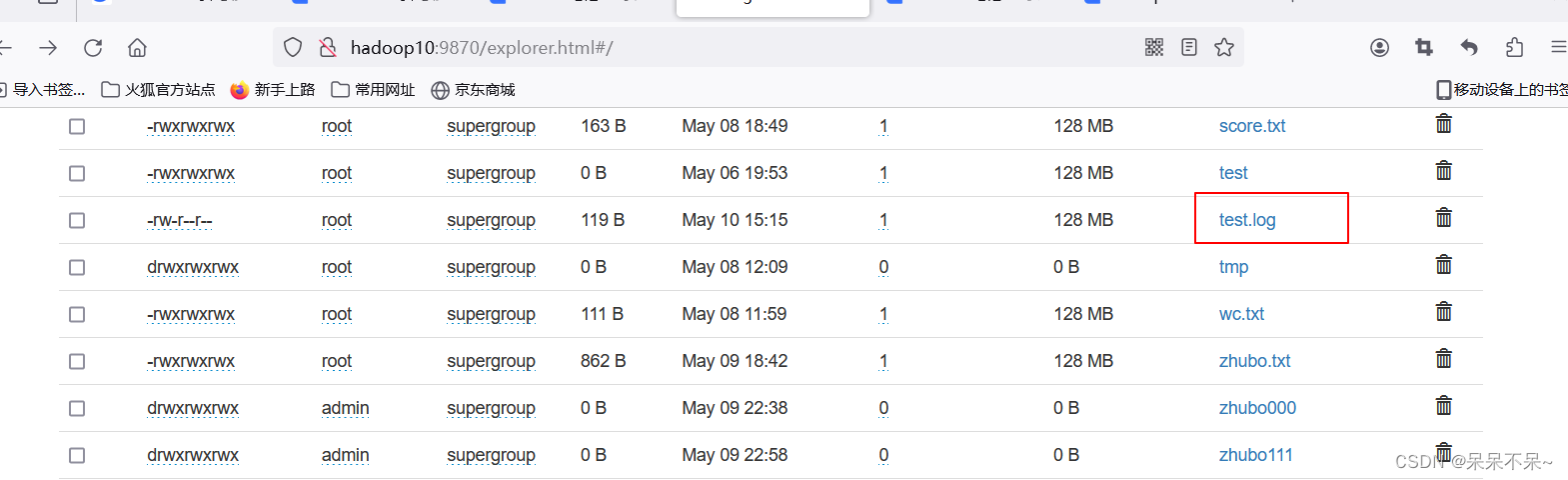
根据提供的数据文件【test.log】
数据文件格式:姓名,语文成绩,数学成绩,英语成绩

完成如下2个案例:
(1)求每个学科的平均成绩
(2)将三门课程中任意一门不及格的学生过滤出来
(1)求每个学科的平均成绩
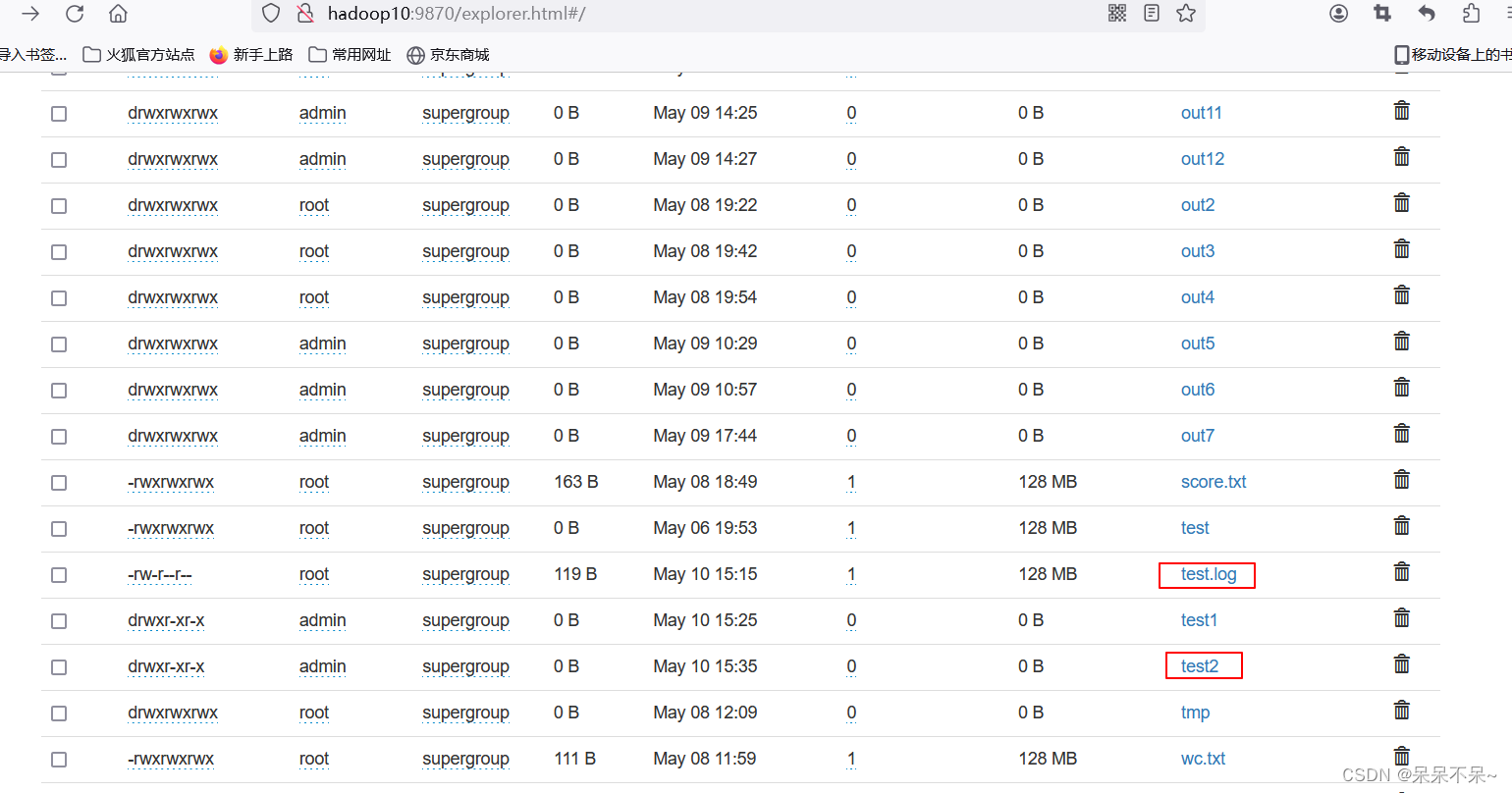
- 上传到hdfs

Idea代码:
package zz;
import demo5.Sort1Job;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class ScoreAverageDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://hadoop10:8020");
Job job = Job.getInstance(conf);
job.setJarByClass(ScoreAverageDriver.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextInputFormat.addInputPath(job,new Path("/test.log"));
TextOutputFormat.setOutputPath(job,new Path("/test1"));
job.setMapperClass(ScoreAverageMapper.class);
job.setReducerClass(ScoreAverageReducer.class);
//map输出的键与值类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//reducer输出的键与值类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
boolean b = job.waitForCompletion(true);
System.out.println(b);
}
static class ScoreAverageMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
// 定义一个Text类型的变量subject,用于存储科目名称
private Text subject = new Text();
// 定义一个IntWritable类型的变量score,用于存储分数
private IntWritable score = new IntWritable();
// 重写Mapper类的map方法
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// 将输入的Text值转换为字符串,并按逗号分割成数组
String[] fields = value.toString().split(",");
// 假设字段的顺序是:姓名,语文成绩,数学成绩,英语成绩
String name = fields[0]; // 提取姓名
int chinese = Integer.parseInt(fields[1]); // 提取语文成绩
int math = Integer.parseInt(fields[2]); // 提取数学成绩
int english = Integer.parseInt(fields[3]); // 提取英语成绩
// 为Chinese科目输出成绩
subject.set("Chinese"); // 设置科目为Chinese
score.set(chinese); // 设置分数为语文成绩
context.write(subject, score); // 写入输出
// 为Math科目输出成绩
subject.set("Math"); // 设置科目为Math
score.set(math); // 设置分数为数学成绩
context.write(subject, score); // 写入输出
// 为English科目输出成绩
subject.set("English"); // 设置科目为English
score.set(english); // 设置分数为英语成绩
context.write(subject, score); // 写入输出
}
}
static class ScoreAverageReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
// 定义一个IntWritable类型的变量average,用于存储平均分数
private IntWritable average = new IntWritable();
// 重写Reducer类的reduce方法
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0; // 初始化分数总和为0
int count = 0; // 初始化科目成绩的个数为0
// 遍历该科目下的所有分数
for (IntWritable val : values) {
sum += val.get(); // 累加分数
count++; // 计数加一
}
// 如果存在分数(即count大于0)
if (count > 0) {
// 计算平均分并设置到average变量中
average.set(sum / count);
// 写入输出,键为科目名称,值为平均分数
context.write(key, average);
}
}
}
}
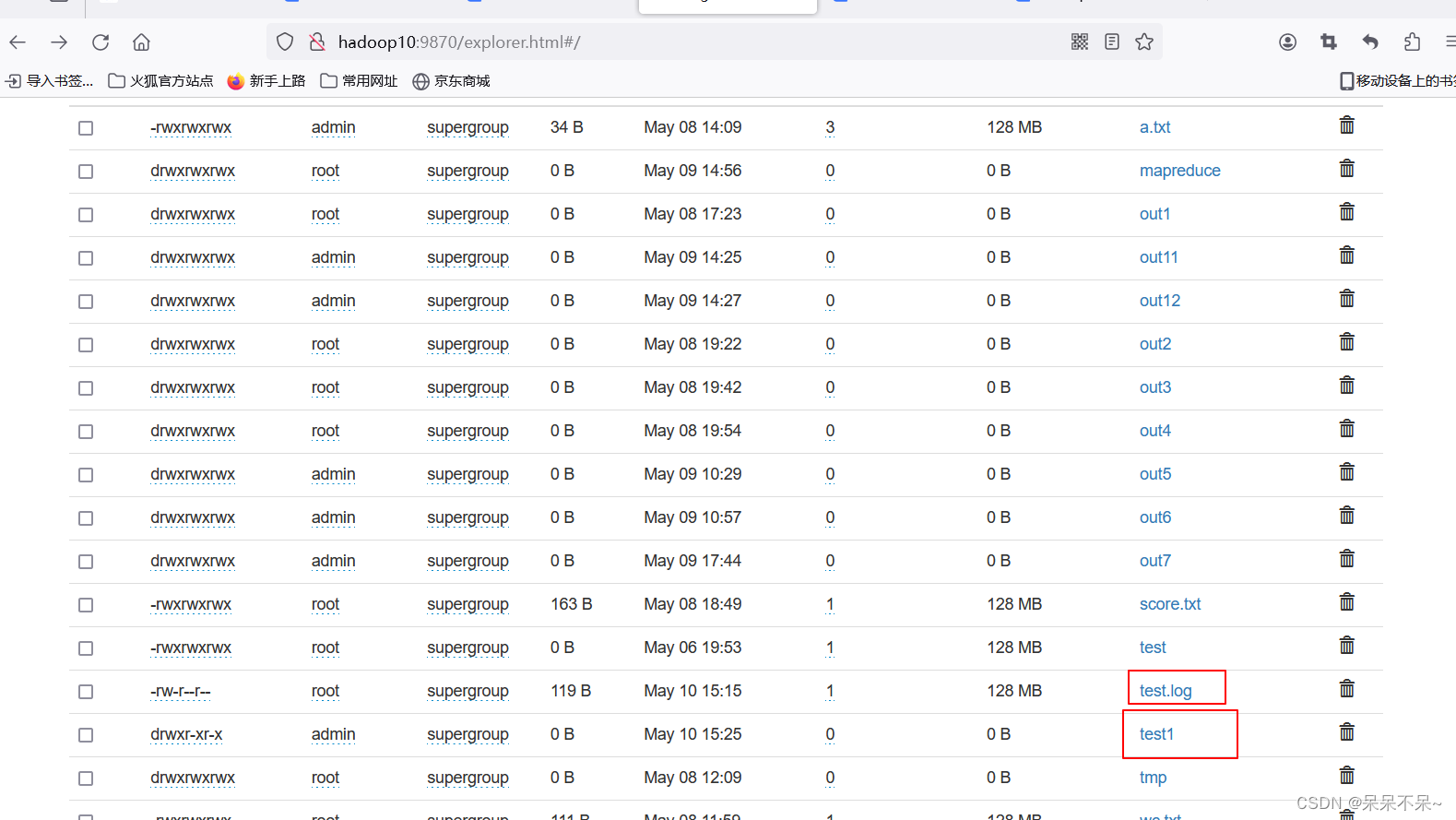
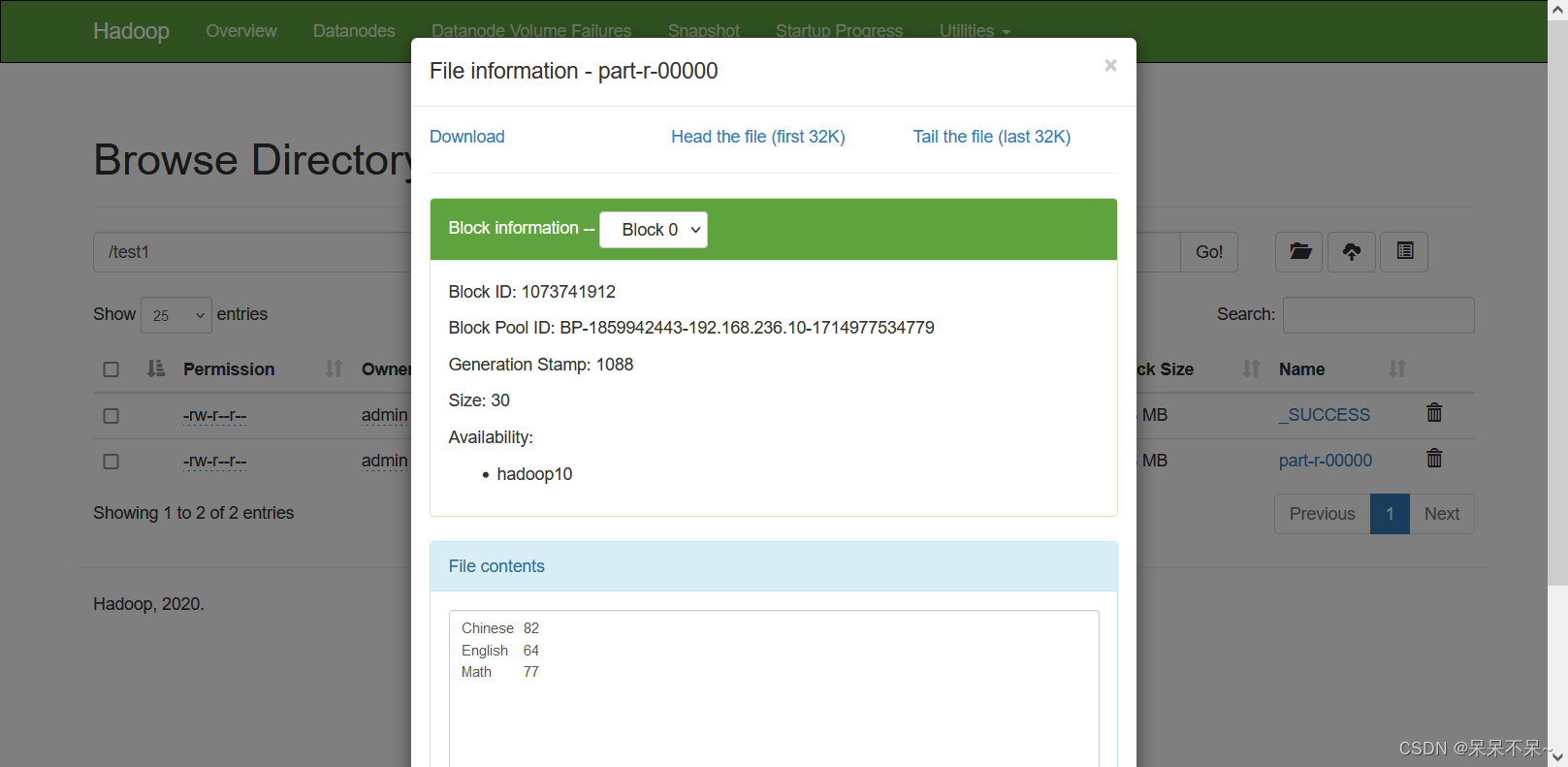
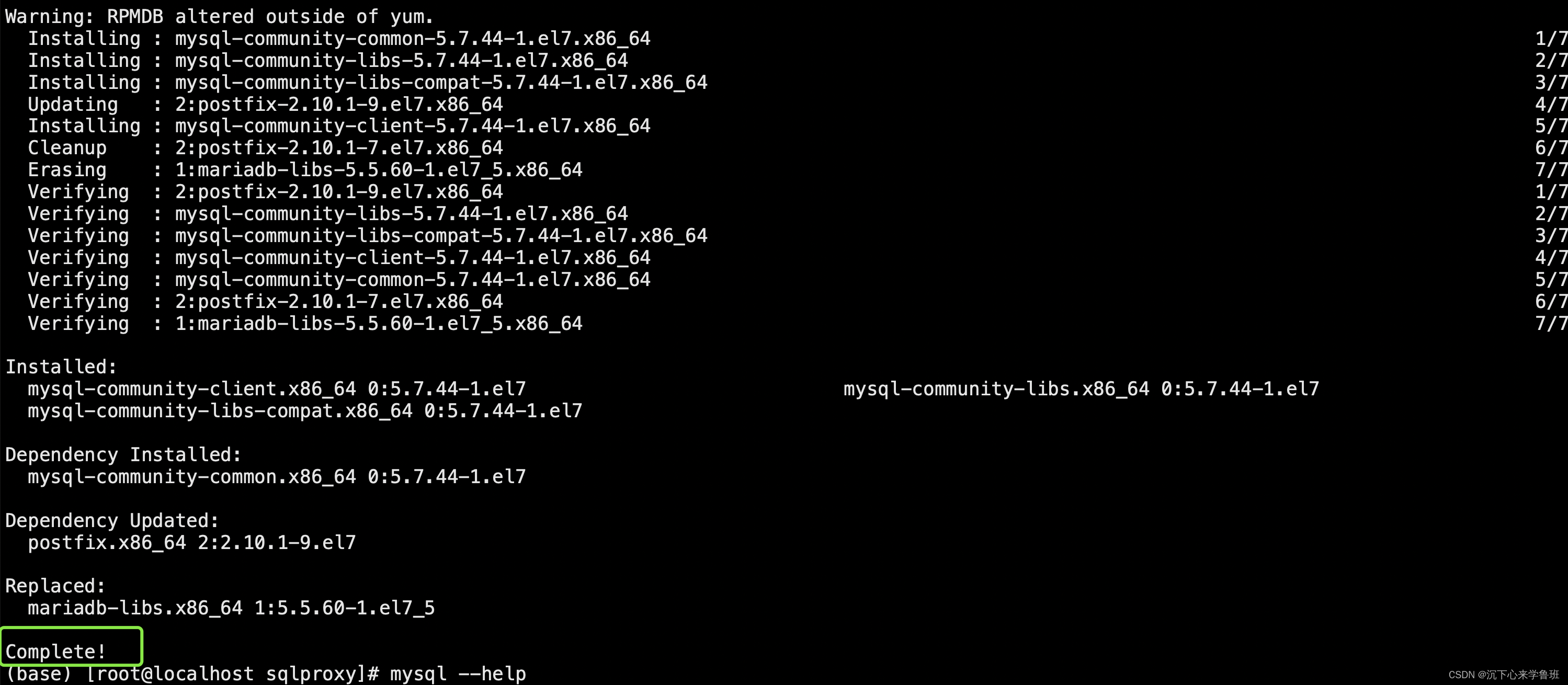
- 结果:
(2)将三门课程中任意一门不及格的学生过滤出来
- Idea代码
package zz;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class FailingStudentDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://hadoop10:8020");
Job job = Job.getInstance(conf);
job.setJarByClass(FailingStudentDriver .class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextInputFormat.addInputPath(job,new Path("/test.log"));
TextOutputFormat.setOutputPath(job,new Path("/test2"));
job.setMapperClass(FailingStudentMapper.class);
//map输出的键与值类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setNumReduceTasks(0);
boolean b = job.waitForCompletion(true);
System.out.println(b);
}
// 定义一个静态类FailingStudentMapper,它继承了Hadoop的Mapper类
// 该Mapper类处理的是Object类型的键和Text类型的值,并输出Text类型的键和NullWritable类型的值
static class FailingStudentMapper extends Mapper<Object, Text, Text, NullWritable> {
// 定义一个Text类型的变量studentName,用于存储不及格的学生姓名
private Text studentName = new Text();
// 定义一个NullWritable类型的变量nullWritable,由于输出值不需要具体的数据,所以使用NullWritable
private NullWritable nullWritable = NullWritable.get();
// 重写Mapper类的map方法,这是处理输入数据的主要方法
@Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
// 将输入的Text值转换为字符串,并按逗号分割成数组
// 假设输入的Text值是"姓名,语文成绩,数学成绩,英语成绩"这样的格式
String[] fields = value.toString().split(",");
// 从数组中取出学生的姓名
String name = fields[0];
// 从数组中取出语文成绩,并转换为整数
int chineseScore = Integer.parseInt(fields[1]);
// 从数组中取出数学成绩,并转换为整数
int mathScore = Integer.parseInt(fields[2]);
// 从数组中取出英语成绩,并转换为整数
int englishScore = Integer.parseInt(fields[3]);
// 检查学生的三门成绩中是否有任意一门不及格(即小于60分)
// 如果有,则将该学生的姓名写入输出
if (chineseScore < 60 || mathScore < 60 || englishScore < 60) {
studentName.set(name); // 设置studentName变量的值为学生的姓名
context.write(studentName, nullWritable); // 使用Mapper的Context对象将学生的姓名写入输出
}
}
}
}
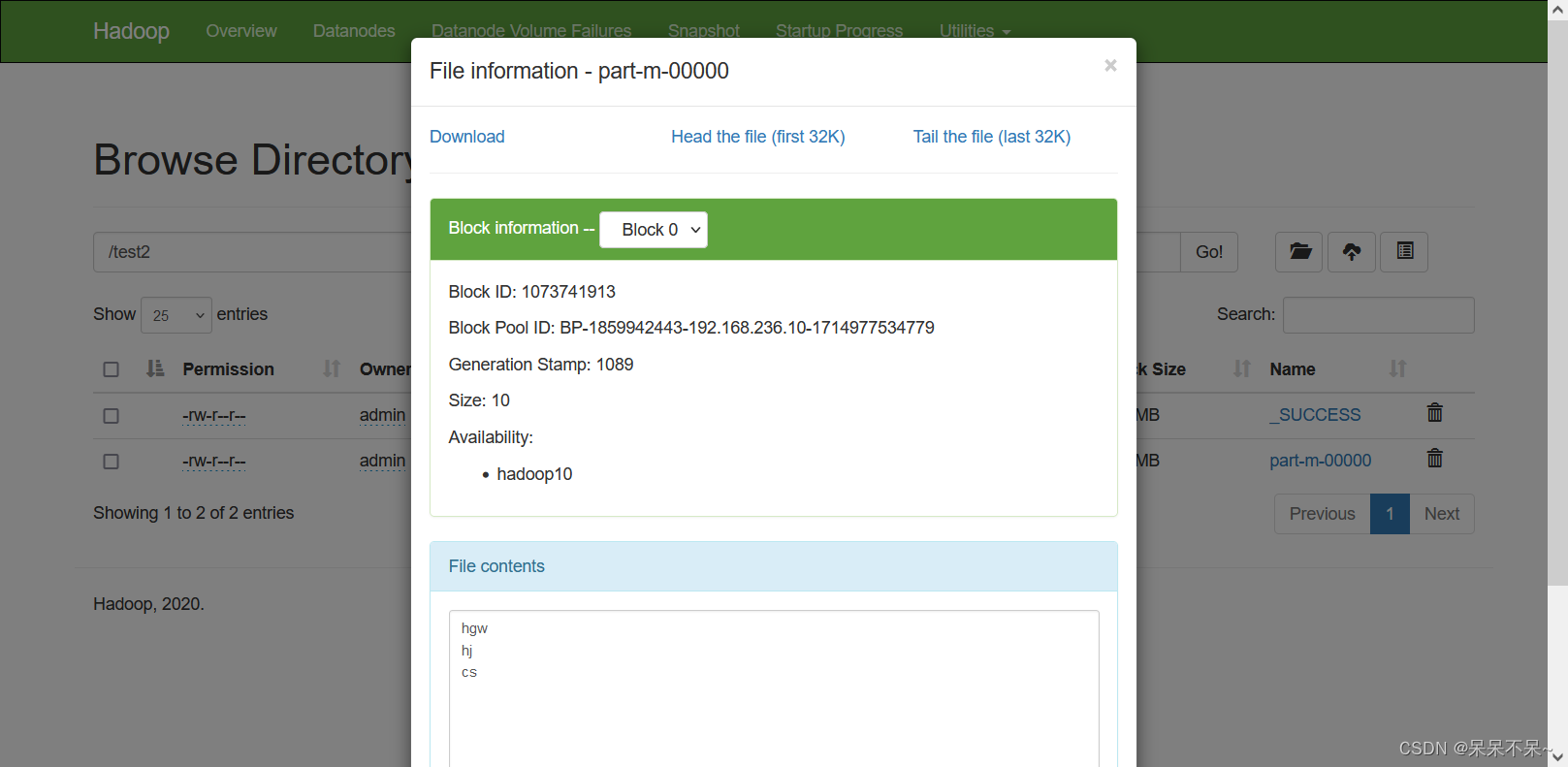
- 结果:









![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-15.4讲 GPIO中断实验-IRQ中断服务函数详解](https://img-blog.csdnimg.cn/direct/069061e7a02d4a35813d0db21ffd3ca0.png)
![weblogic 反序列化 [CVE-2017-10271]](https://img-blog.csdnimg.cn/direct/9c691a45d9e4464ba5addab141b821d7.png)