背景
随着全球能源需求的不断增长和对可再生能源的追求,生物质和煤共热解作为一种潜在的能源转化技术备受关注。生物质是指可再生能源,源自植物和动物的有机物质,而煤则是一种化石燃料。** 在共热解过程中,生物质和煤在高温和缺氧条件下一起热解,产生气体、液体和固体产物,其中液体产物被称为热解油或生物油。 **研究生物质和煤共热解油的产率和品质机理对提高能源利用效率、促进资源综合利用和确保能源安全具有重要意义。
实验要求【重点】
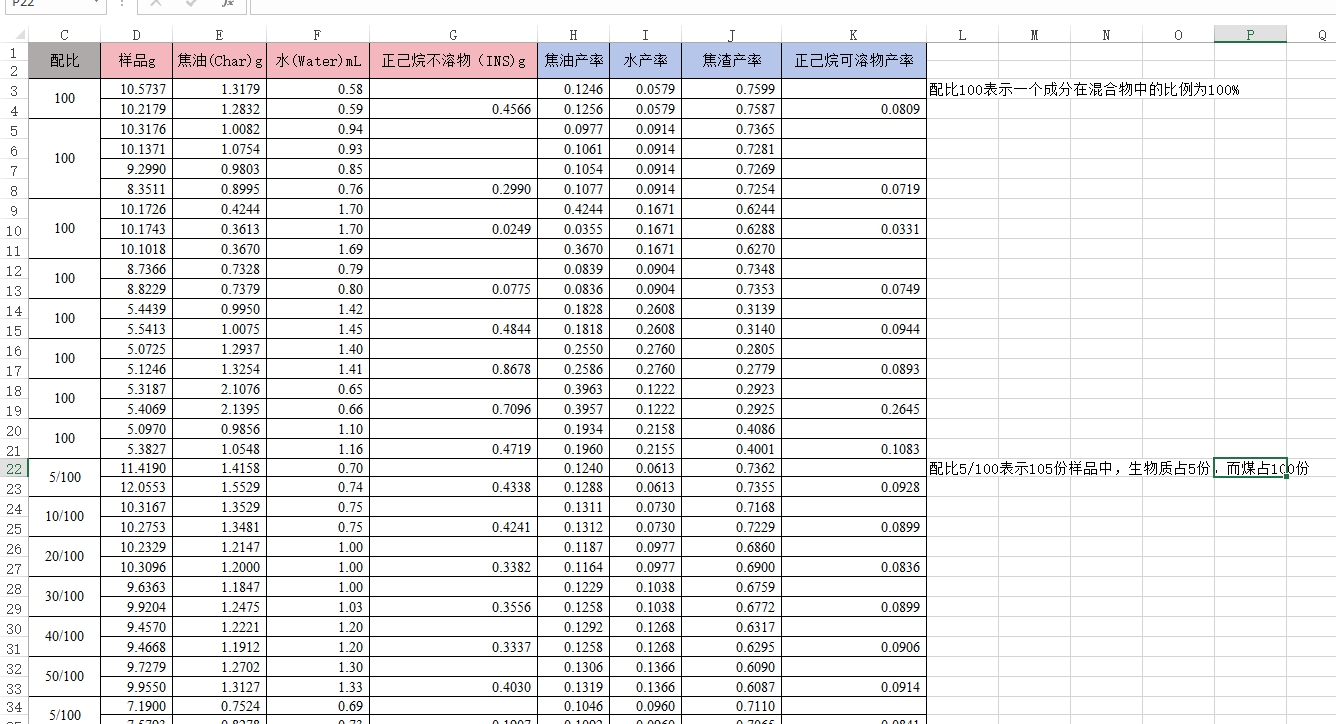
一化工实验室选取棉杆(CS)、稻壳(RH)、木屑(SD)、小球藻(GA)等多种生物质和淮南煤(HN)、神木煤(SM)、黑山煤(HS)、内蒙褐煤(NM)等中低阶煤为共热解原料,并利用管式干馏炉在温和热解条件下研究不同种类和配比原料的共热解对产物分布的影响。 在实验室研究中,微晶纤维素通常被用作一种模型化合物,以代表生物质中的主要纤维素成分,用来分析生物质热解产物的特性和化学反应机理。为进一步研究共热解产物生成机理,该实验室引入微晶纤维素作为模型化合物,分析比较棉杆(CS)热解、神木煤(SM)热解、棉杆/神木煤(CS/SM)共热解和微晶纤维素/神木煤共热解产生的正己烷可溶物(HEX)组分变化。共热解实验以5/100,10/100,20/100,30/100,50/100 为混合比例进行固定热解实验。实验结果如附件1和附件2所示,名词解释见附录。
题目
通过对比不同原料单独热解和共热解的产物组成,分析生物质与煤的协同效应,揭示共热解过程中可能存在的协同效应和相互转化的机制,为深入理解共热解过程提供理论依据和实验数据支持。如果能够建立数学模型对共热解产物预测和优化,将有助于提高生物质与煤共热解过程的效率和产物利用率,同时减少环境污染和资源浪费。请通过数学建模完成下列问题:
第一题
基于附件一,请分析正己烷不溶物(INS)对热解产率(主要考虑焦油产率、水产率、焦渣产率)是否产生显著影响?并利用图像加以解释
第二题
热解实验中,正己烷不溶物(INS)和混合比例是否存在交互效应,对热解产物产量产生重要影响?若存在交互效应,在哪些具体的热解产物上样品重量和混合比例的交互效应最为明显?
问题三
根据附件一,基于共热解产物的特性和组成,请建立模型优化共解热混合比例,以提高产物利用率和能源转化效率。
问题四
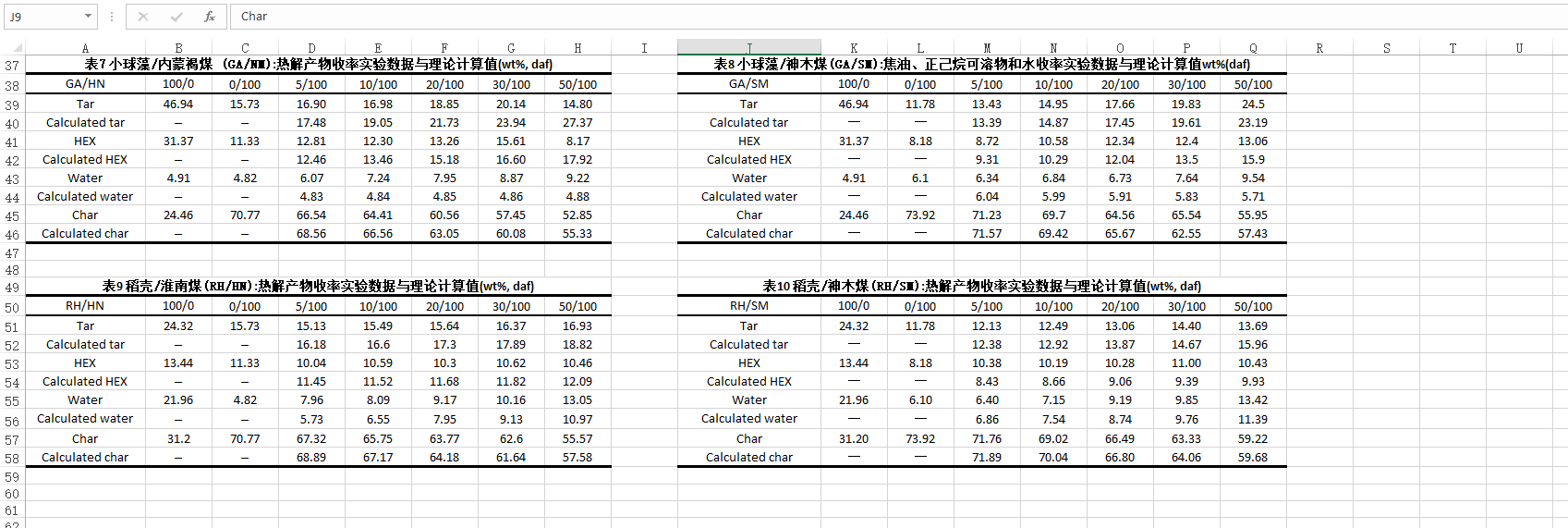
根据附件二,请分析每种共热解组合的产物收率实验值与理论计算值是否存在显著性差异?若存在差异,请通过对不同共热解组合的数据进行子组分析,确定实验值与理论计算值之间的差异在哪些混合比例上体现?
问题五
基于实验数据,请建立相应的模型,对热解产物产率进行预测
附件
附件一:热解数据统计.xlsx
附件二: 热解产物产率计算结果.xls
附录解释(及公式)
单独热解的煤和生物质: 淮南煤(HN)、神木煤(SM)、黑山煤(HS)、内蒙褐煤(NM)、棉杆(CS)、木屑(SD)、小球藻(GA)、稻壳(RH)。
共热解组合: 棉杆/淮南煤(CS/HN)、棉杆/神木煤(CS/SM)、棉杆 /黑山煤(CS/HS)、木屑/黑山煤(SD/HS)、木屑/神木煤(SD/SM)、小球 藻/淮南煤(GA/HN)、小球藻/内蒙褐煤 (GA/NM)、小球藻/神木
煤(GA/SM)、稻壳/淮南煤(RH/HN)、稻壳/神木煤 (RH/SM)。热解产物: 焦油(Tar)、 正己烷可溶物(HEX)、水(Water)、焦渣(Char)
设生物质与煤的热解混合比例为定义如下函数:
f
(
x
,
y
,
θ
(
x
,
y
)
)
=
x
x
+
y
×
f(x, y, \theta(x, y))=\frac{x}{x+y} \times
f(x,y,θ(x,y))=x+yx× 生物质热解的产物收率
+
y
x
+
y
×
+\frac{y}{x+y} \times
+x+yy× 煤热解的产物收率
+
θ
(
x
,
y
)
+\theta(x, y)
+θ(x,y),
其中 f ( x , y , θ ( x , y ) ) f(x, y, \theta(x, y)) f(x,y,θ(x,y))表示在 x y \frac{x}{y} yx混合比例实际产物收率下, θ ( x , y ) ) \theta(x, y)) θ(x,y))生物质与煤共热解的是交叉项,表示生物质与煤共热解的交互作用,以及其他因素的影响等,其作用有可能是促进作用也可能是抑制作用。
“” x x + y \frac{x}{x+y} x+yx × \times × 生物质热解的产物收率 + y x + y \frac{y}{x+y} x+yy × \times × 煤热解的产物收率 "是相当于函数 f ( x , y , θ ( x , y ) ) f(x, y, \theta(x, y)) f(x,y,θ(x,y)) 线性近似部分,附件2中的理论计算值即是用这个线性近似部分计算的。
另外,焦油是共热解产物中主要关注的部分,提高产物产量主要指提高焦油产量,其他产物及成本不予考虑。煤热解得到的焦油通常含有较少的杂质,易于提炼和利用。相比之下,生物质热解得到的焦
油含有较多的杂质,需要更复杂的处理工艺才能提炼出纯净的产品。生物质热解产生的焦油处理成本较高,对环境和资源消耗也有更大的影响。因此,进行共热解实验时,期望得到的产物焦油更偏向于煤焦油。或者说,科研人员更关注煤热解所产生的煤焦油。生物质和煤热解之后得到的焦油其质量等同于煤热解直接产生的焦油。本实验的目的,就是为了通过生物质和煤热解反应得到(比煤直接热解)更多的煤焦油。
所有热解实验的初始温度均为 600℃, 升温 5℃/min。
思路
第一题思路:影响分析和可视化
总体为:数据的简单处理,检验,可视化
- 基本的数据处理和数据转换(参考国赛古风玻璃题目)。
- 显著性检验。介绍参考:为什么要做显著性检验? 相关性检验
2.1 相关性检验:对于正己烷不溶物(INS)与热解产率的相关性分析,可以使用Pearson或Spearman相关系数,根据数据的分布和特性选择合适的方法。相关系数的显著性可以通过计算p值来评估,通常使用t检验的变体来测试相关系数是否显著不为零。
2.2 统计学回归检验。t检验:检验每个自变量的回归系数是否显著不同于零。如果p值低于某个阈值(通常为0.05),则认为该系数在统计上显著,即该变量对响应变量有显著影响。F检验:对整个回归模型进行检验,判断模型中至少有一个预测变量对响应变量有统计显著的影响。【F检验不做也行】
2.3 可视化:绘制散点图和热力图来直观展示相关性和回归结果。
第二题思路:交互效应分析
- 首先对每种热解产物(焦油、水、焦渣、正己烷可溶物)进行基本的统计分析,了解数据。如果有缺失值等,需要进行处理。
- 建立模型:线性混合效应模型或多元线性回归模型,这些模型可以包括交互项。除此之外,还有更高级的模型:如随机森林、梯度提升可以自动捕捉变量间的复杂和非线性关系,第二题回归基本就够了吧。
- 统计检验:显著性检验:进行t检验,判断模型中各项(特别是交互项)的统计显著性。影响度分析:评估交互效应对各产率的具体影响程度,确定哪些组合的交互效应最明显。
- 可视化相关图,两两之间的即可,无需多维度绘制。
- 据图形和统计分析的结果,解释哪些具体的热解产物在哪些样品重量和混合比例的组合下,交互效应表现最为显著。
第三题:优化算法寻优题
- 建立优化模型:在热解产率与原料混合比、正己烷不溶物之间建立数学模型。
- 目标函数和约束:定义优化目标(如最大化焦油产率),设置约束条件(原料比例)。
- 求解优化问题:使用线性或非线性优化算法求解模型,找到最优的原料混合比例。求解可以使用遗传算法等优化算法进行求解。
参考公式:见附录解释(及公式)。
第四题:显著性分析
初步分析:
1)计算每种组合和混合比例下实验值与理论值的差异,通过差异的绝对值或百分比形式表示。
2)制作差异分布图,初步观察哪些组合或比例下差异较大。
方差分析(ANOVA):使用双因素方差分析(考虑共热解组合和混合比例为两个因素),分析这两个因素及其交互作用对差异的影响。
差异的统计显著性检验:
1)对每种组合和比例下的差异进行t检验,评估其统计显著性,可以做个对比可视化结果。
2)根据p值调整方法(如Bonferroni或FDR)调整多重比较的影响,还可以做个敏感性分析了。【可选】
根据ANOVA结果,选择差异最显著的组合和比例进行深入分析。分析这些条件下实验值与理论值差异的可能原因,探讨影响因素如温度、压力、原料特性等。
第五题思路:机器学习预测模型构建
- 选择模型:根据数据特性和问题需求,选择合适的预测模型,如神经网络、随机森林,XGBOOST这种高级模型套上去,或者选多个模型进行比较,得到最佳模型。
- 特征选择和数据准备:确定影响产率的关键因素,进行数据预处理和特征工程。
- 模型训练和验证:使用交叉验证等技术训练和调优模型,评估模型的预测性能。
- 可视化性能
附件具体的使用
使用附件一
附件一包含了各种生物质和煤的单独热解以及共热解的实验数据,主要用于:
- 数据预处理:整理数据格式,处理缺失值和异常值,计算平均值等。
- 显著性检验和相关性分析:
- 计算正己烷不溶物(INS)和其他热解产物(焦油、水、焦渣)的相关性。
- 通过线性回归模型分析正己烷不溶物对热解产率的影响,进行t检验和F检验。
- 可视化:绘制相关性热力图和散点图,展示正己烷不溶物与热解产率之间的关系。
使用附件二
附件二提供了每种生物质和煤的共热解组合下,实验值与理论计算值的对比,主要用于:
- 差异分析:
- 计算实验值与理论计算值之间的差异。
- 制作差异分布图,观察不同组合和混合比例下差异的大小。
- 方差分析(ANOVA):
- 使用双因素方差分析考察共热解组合和混合比例对差异的影响。
- 分析交互作用的统计显著性。
- 显著性检验:
- 对差异进行t检验或非参数检验。
- 调整多重比较的影响,如使用Bonferroni或FDR方法进行p值调整。
具体步骤
- 读取数据:加载附件一和附件二的数据到Python环境中,使用Pandas进行数据处理。
- 数据清洗:统一数据格式,处理缺失数据,可能需要对附件一和附件二中的数据进行合并或关联分析。
- 建模与分析:
- 使用
statsmodels或scikit-learn库进行线性回归分析和显著性检验。 - 使用
matplotlib和seaborn进行数据可视化。
- 使用
- 优化与预测:
- 根据分析结果,使用优化算法调整混合比例以最大化焦油产率。
- 应用机器学习模型(如神经网络、随机森林)进行产率预测。
代码:推荐使用我的GPT
网址:ChatGPT4.0

![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-15.4讲 GPIO中断实验-IRQ中断服务函数详解](https://img-blog.csdnimg.cn/direct/069061e7a02d4a35813d0db21ffd3ca0.png)
![weblogic 反序列化 [CVE-2017-10271]](https://img-blog.csdnimg.cn/direct/9c691a45d9e4464ba5addab141b821d7.png)