前言
接着上一篇文章,我们知道了闭散列的弊端是空间利用率比较低,希望今天学习的开散列可以帮我们解决这个问题
引入
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址**,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。**
实现
基本结构
template<class K, class V>
struct HashNode
{
HashNode<K, V>* _next;
pair<K, V> _kv;
};
template<class K,class V>
class HashTable
{
using Node = HashNode<K, V>;
public:
//构造
HashTable(size_t size = 10)
{
_tables.resize(size, nullptr);
_n = 0;
}
//析构
~HashTable()
{
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_tables[i] = nullptr;
}
}
private:
vector<Node*> _tables;
size_t _n = 0;
}
插入
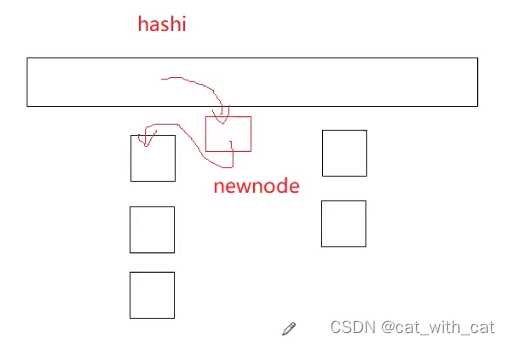
这就是头插
bool Insert(const pair<K, V>& kv)
{
size_t hashi = kv.first % _tables.size(); //找到关键码
Node* newnode = new Node(kv); //创建新节点
newnode->_next = _tables[hashi]; //先链接上
_tables[hashi] = nuwnode; //再更新头节点
}
扩容
(可以参考set和map的扩容,都使用了提供的swap函数)
if (_n == _tables.size())
{
vector<Node*> newTable(_tables.size() * 2, nullptr);
for (size_t i = 0; i < _tables.size(); i++)
{
//遍历旧表,重新计算
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
size_t hashi = cur->_kv, first% newTable.size();
cur->_next = newTable[hashi];
newTable[hashi] = cur;
cur = next;
}
tables[i] = nullptr;
}
_tables.swap(newTables);
}//扩容机制
删除
删除,删的是_key是key的这个桶,
返回值:
可以是bool也可以是下一个桶的指针
bool Erase(const K& key)
{
Hash hs; //取出key的value值,
//可以是仿函数、lambda,看传入的是什么
size_t hashi = hs(key) % _tables.size();
Node* prev = nullptr;
Node* cur = _tables[hashi];
while (cur)
{
if (cur->_kv.first == key)
//满足条件
{
// 删除
if (prev)
{
prev->_next = cur->_next;
}
else
{
_tables[hashi] = cur->_next;
}
delete cur;
--_n;
//桶个数--
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}
对各项的检查函数
void Some()
{
size_t bucketSize = 0;
size_t maxBucketLen = 0;
size_t sum = 0;
double averageBucketLen = 0;
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
if (cur)
{
++bucketSize;
}
size_t bucketLen = 0;
while (cur)
{
++bucketLen;
cur = cur->_next;
}
sum += bucketLen;
if (bucketLen > maxBucketLen)
{
maxBucketLen = bucketLen;
}
}
averageBucketLen = (double)sum / (double)bucketSize;
printf("load factor:%lf\n", (double)_n/ _tables.size());
//负载因子
printf("all bucketSize:%d\n", _tables.size());
//桶的个数
printf("bucketSize:%d\n", bucketSize);
printf("maxBucketLen:%d\n", maxBucketLen);
//桶的最大值
printf("averageBucketLen:%lf\n\n", averageBucketLen);
//桶的平均大小
}
补充
当某个桶数据过多时,我们可以把这个桶指向的节点变成红黑树,但什么时候变目前不去考虑
结语
文章写到这里有点戛然而止的感觉,不过本文主要是为了介绍概念、只实现了插入和删除。