这麽说好像我是James Bond后面那个厉害的Q先生,Q是英文Quartermaster(軍需官)第1個英文字大寫,是007系列英國祕勤局虛構部門Q部門的領導。
Stanford大学的研究者最近发表了一篇名为"From r to Q*: Your Language Model is Secretly a Q-Function"的论文,核心观点是将语言模型解释为最优Q函数,并以此推导出DPO算法在序列决策问题中的应用。这为DPO在序列决策任务中的应用提供了理论基础。本报告探讨了其在多轮对话、智能体建立、端到端生成式AI系统训练等方面的应用前景,并提供了使用DPO在Reddit TL;DR数据集上训练的样本生成结果。

让我们深入探讨一下其中的关键论证。首先,作者定义了语言模型中的token级MDP(Token-level Markov Decision Process),这是一种用于表示语言模型序列决策过程的数学框架。在token级MDP中,每个token都被视为一个独立的决策步骤。其组成要素包括:状态空间S、动作空间A、转移函数f、奖励函数r和初始状态分布 ρ 0 \rho_0 ρ0。由于语言的顺序特性,token级MDP具有独特的树形结构,与一般的MDP(例如棋类游戏)不同,因此许多基于MDP的理论结果在此都有独特的解释。

接着,作者指出在token级MDP中,最优策略 π ∗ \pi^* π∗与最优Q函数 Q ∗ Q^* Q∗之间满足一定关系,语言模型生成每个token的概率分布恰好对应以logits为 Q ∗ Q^* Q∗的softmax函数。作者进一步证明,在token级MDP中,奖励函数r与最优Q函数 Q ∗ Q^* Q∗之间存在一一映射关系,表明我们可以将语言模型视为隐式地表示了某个最优Q函数的奖励函数。DPO算法的目标就是调整模型参数,使其所对应的奖励函数符合人类偏好,同时DPO能够学习任意密集奖励函数对应的最优策略。

这一理论洞见具有重要意义。它揭示了语言模型的潜在强化学习特性,为DPO等对齐算法在序列决策中的应用提供了理论支持,同时也为PPO等传统强化学习算法在语言任务上的应用提供了合适的问题建模。这篇论文开创性地将Q学习与语言模型结合,极大拓展了RLHF的理论框架和算法工具箱。
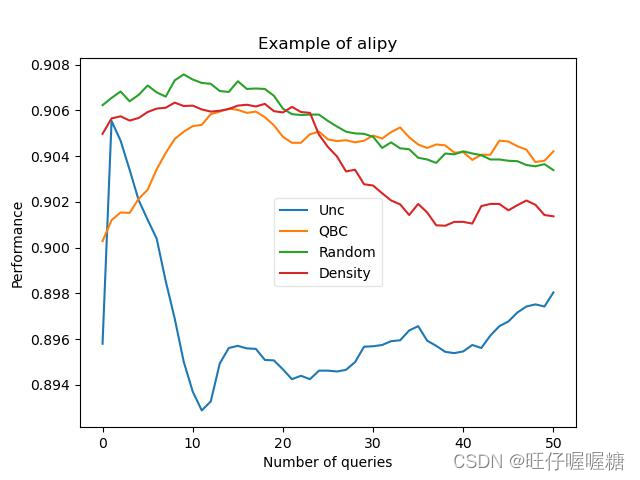
作者还概述了如何使用DPO从人类反馈中端到端训练生成式AI系统。通过在混合MDP中同时优化提示生成器和图像生成器,联合训练可使系统生成更对齐的提示和图像。在Reddit TL;DR数据集上的实验表明,beam search可提高DPO模型的匹配质量但宽度过大会导致冗长,而有无监督式微调(SFT)预训练则显著影响生成摘要的可读性。
这项工作为将DPO扩展到序列决策、强化学习领域奠定了理论基础,并提出了从反馈中学习推理、多轮对话、智能体训练、端到端生成式AI训练等具启发性的潜在应用方向。通过将DPO重新诠释为最佳Q函数学习,它为偏好对齐技术的发展开辟了简洁高效的新路径。未来,大规模实证研究以及在更多任务中的探索,有望进一步推动需要多步交互及端到端优化的语言模型对齐应用。
科普什么是Q函数(可不是Altman家的 Q ∗ Q^* Q∗):
Q函数,全称为动作-价值函数(Action-Value Function),是强化学习中的一个重要概念。它表示在给定策略 π \pi π下,从状态s开始执行动作a,然后继续遵循策略 π \pi π所获得的期望累积奖励。用数学公式表示为:
Q π ( s , a ) = E π [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . ∣ S t = s , A t = a ] Q^\pi(s, a) = E_\pi[R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ... | S_t = s, A_t = a] Qπ(s,a)=Eπ[Rt+1+γRt+2+γ2Rt+3+...∣St=s,At=a]
其中, γ \gamma γ是折扣因子,用于平衡即时奖励和长期奖励的重要性。期望 E π E_\pi Eπ表示在给定策略 π \pi π的情况下对未来奖励的平均值。
Q函数有以下几个关键性质:
-
最优Q函数 Q ∗ ( s , a ) Q^*(s, a) Q∗(s,a)给出了在状态s下采取动作a,然后在之后的所有时间步遵循最优策略 π ∗ \pi^* π∗可以获得的最大期望累积奖励。
-
基于最优Q函数,我们可以很容易地得到最优策略: π ∗ ( a ∣ s ) = arg max a Q ∗ ( s , a ) \pi^*(a|s) = \arg\max_a Q^*(s, a) π∗(a∣s)=argmaxaQ∗(s,a)。即在每个状态下选择Q值最大的动作。
-
Q函数满足贝尔曼最优方程(Bellman Optimality Equation):
Q ∗ ( s , a ) = E [ R t + 1 + γ max a ′ Q ∗ ( S t + 1 , a ′ ) ∣ S t = s , A t = a ] Q^*(s, a) = E[R_{t+1} + \gamma \max_{a'}Q^*(S_{t+1}, a') | S_t = s, A_t = a] Q∗(s,a)=E[Rt+1+γmaxa′Q∗(St+1,a′)∣St=s,At=a]
这个方程表示最优动作价值等于即时奖励加上下一状态的最大Q值(乘以折扣因子 γ \gamma γ)的期望。
在强化学习中,我们通常利用贝尔曼方程作为更新Q函数估计值的依据,例如在Q-learning算法中:
Q ( S t , A t ) ← Q ( S t , A t ) + α [ R t + 1 + γ max a Q ( S t + 1 , a ) − Q ( S t , A t ) ] Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha[R_{t+1} + \gamma \max_a Q(S_{t+1}, a) - Q(S_t, A_t)] Q(St,At)←Q(St,At)+α[Rt+1+γmaxaQ(St+1,a)−Q(St,At)]
其中 α \alpha α是学习率。这个更新规则可以被证明在一定条件下收敛到最优Q函数。
Q函数提供了一种评估动作好坏的方法,使我们能够在不完全了解环境动态的情况下做出最优决策。很多强化学习算法如Q-learning、SARSA、DQN等都是围绕估计和优化Q函数展开的。
近年来,随着深度学习的发展,深度Q网络(DQN)等算法将神经网络用于逼近Q函数,取得了显著的成功,使得Q学习的思想得以扩展到大规模甚至连续的状态-动作空间中。
总之,作为连接策略评估和策略改进的桥梁,Q函数是现代强化学习的核心概念之一。深入理解Q函数的性质和更新方法,对于设计高效的强化学习算法至关重要。同时Q学习在机器人、自动驾驶、游戏AI等领域也有广泛应用。而将Q学习与神经语言模型相结合,更是近年来的一个令人激动的新方向,为对齐大型语言模型行为带来了新的理论视角和技术路径。
Token级MDP(Token-level Markov Decision Process)是一种用于表示语言模型中序列决策过程的数学框架。在这个MDP中,每个token(词汇表中的词)都被视为一个独立的决策步骤。让我详细解释一下它的组成要素:
-
状态空间(State Space, S):包含到目前为止生成的所有token,即 s t = x 0 , . . . , x m , y 0 , . . . , y t s_t=\\{x_0, ..., x_m, y_0, ..., y_t\\} st=x0,...,xm,y0,...,yt,其中 x i x_i xi是输入序列的token, y i y_i yi是生成序列的token。
-
动作空间(Action Space, A):词汇表V中的所有token。在每个状态下,模型从词汇表中选择一个token作为动作。
-
转移函数(Transition Function, f):描述在给定状态s下采取动作a后,环境将转移到哪个新状态s’。在token级MDP中,转移函数是确定性的: f ( s , a ) = s ∣ a f(s, a) = s|a f(s,a)=s∣a,即新状态是原状态与新token的拼接。
-
奖励函数(Reward Function, r):定义在每个状态动作对 ( s , a ) (s, a) (s,a)上的即时奖励值。在RLHF设定中,奖励函数从人类反馈中学习。
-
初始状态分布(Initial State Distribution, ρ 0 \rho_0 ρ0):定义了MDP的初始状态分布,通常对应输入提示的分布。
在token级MDP中,模型的目标是最大化累积期望奖励:
max π E τ ∼ π [ ∑ R ( s t , a t ) ] \max_\pi E_{\tau \sim \pi}[\sum R(s_t, a_t)] maxπEτ∼π[∑R(st,at)]
其中 π \pi π是模型的策略(policy), τ \tau τ是轨迹(trajectory), R ( s t , a t ) R(s_t, a_t) R(st,at)是t时刻的奖励。求解这一目标的经典方法是强化学习,例如近端策略优化(PPO)。
值得注意的是,由于语言的顺序特性,token级MDP具有独特的树形结构(tree structure),即在给定输入提示(初始状态)的情况下,模型的每个决策都会导向一个全新的状态,这与一般的MDP(例如棋类游戏)不同。因此,许多基于MDP的理论结果(如Bellman方程)在这里都有独特的解释。
作者首先定义了语言模型中的token级MDP,其中每个时间步对应生成一个token的决策。接着,他们指出,在这个特殊的MDP中,最优策略 π ∗ \pi^* π∗与最优Q函数 Q ∗ Q^* Q∗之间满足如下关系:
π ∗ ( a t ∣ s t ) = exp ( ( Q ∗ ( s t , a t ) − V ∗ ( s t ) ) / β ) \pi^*(a_t|s_t) = \exp((Q^*(s_t,a_t) - V^*(s_t)) / \beta) π∗(at∣st)=exp((Q∗(st,at)−V∗(st))/β)
其中 V ∗ V^* V∗是最优价值函数, β \beta β是温度参数。换句话说,语言模型生成每个token的概率分布,恰好对应了以logits为 Q ∗ Q^* Q∗的softmax函数。进一步地,Bellman最优方程给出了 Q ∗ Q^* Q∗和环境奖励r之间的递归关系:
Q ∗ ( s t , a t ) = r ( s t , a t ) + β log π r e f ( a t ∣ s t ) + V ∗ ( s t + 1 ) Q^*(s_t,a_t) = r(s_t,a_t) + \beta \log \pi_{ref}(a_t|s_t) + V^*(s_{t+1}) Q∗(st,at)=r(st,at)+βlogπref(at∣st)+V∗(st+1)
作者据此证明,在token级MDP中,奖励函数r与最优Q函数 Q ∗ Q^* Q∗之间存在一一映射关系。这意味着我们可以将语言模型视为一个隐式地表示了某个最优Q函数的奖励函数。DPO算法的目标就是调整模型参数,使其表示的Q函数所对应的奖励函数符合人类偏好。作者进一步论证了DPO能够学习任意密集奖励函数对应的最优策略。