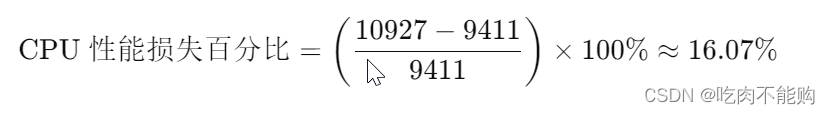论文标题
《Decoupled Optimisation for Long-Tailed Visual Recognition》
长尾视觉识别的解耦优化
作者
Cong Cong、Shiyu Xuan、Sidong Liu、Shiliang Zhang、Maurice Pagnucco 和 Yang Song、
来自新南威尔士大学计算机科学与工程学院、北京大学计算机学院多媒体信息处理国家重点实验室和麦考瑞大学澳大利亚健康创新研究所
初读
摘要
- 当在长尾数据集上进行训练时,传统的学习算法往往会对样本数量较大的类别表现出偏见。我们的研究发现,这种带有偏见的学习倾向源于模型参数,这些参数被训练为不成比例地贡献给以其样本数量为特征的类别(例如,多、中、少类别)。
- 为了平衡所有类别的整体参数贡献,我们研究了每个模型参数对不同类别组学习的重要性,并提出了一种多阶段参数解耦和优化(DO)框架,
- 该框架将参数解耦到不同的组中,每个组学习特定的一部分类别。
- 为了优化参数学习,我们应用了不同的训练目标,并采取协作优化步骤来学习关于每个类别组的互补信息。
- 在包括 CIFAR100、Places-LT、ImageNet-LT 和 iNaturaList 2018 在内的长尾数据集上进行的广泛实验表明,我们的框架与最先进的方法相比取得了具有竞争力的性能。
结论
- 在这项工作中,我们提出了一种用于长尾视觉识别的新型参数解耦和优化框架。
- 所提出的框架通过将模型参数解耦到不同的组中,每组针对一个单独的类别划分进行优化,从而在所有类别之间最佳地平衡参数的重要性。
- 广泛的实验已经证明了所提出框架的有效性。
再读
Section 1 Introduction
-
长尾分布
- 现实世界的数据集通常表现出长尾类别分布,其中某些类别拥有大量的样本,而罕见类别的样本数量则有限。
- 这种类别不平衡在训练深度卷积神经网络时带来了重大挑战,因为拥有大量实例的头部类别倾向于通过影响大多数梯度的学习来压倒尾部类别的模型学习,从而导致在少数类别上的性能不佳。
- 这是一个关键问题,特别是在自动驾驶和计算机辅助诊断等领域,因为在这些领域中,需要在长尾数据集上训练的模型能够在所有类别上展示出高性能。
-
相关方法:
- 早期尝试缓解这一问题包括对稀有类别进行上采样、知识迁移和损失重新加权。
- 最近的研究发现,改善特征质量,特别是通过自监督学习可以有效提高模型在不平衡数据集上的性能。
- 一些研究发现特征学习和分类器学习偏好不同的学习策略,因此应用两阶段解耦学习方案可以进一步改进性能。
- 此外,基于多专家学习的模型集成代表了最先进的技术,每个专家模型专注于数据分布的不同划分。
-
我们的分析表明,每个模型参数在学习不同类别组时具有不同程度的重要性。
-
这里参数重要性的衡量类似于模型剪枝时所使用的概念,即通过从模型中移除它引起的最终损失的变化来估计。
-
在长尾分类中,模型参数通常对于样本数量较多的类别更为重要,即多类别组。
-
图 1(b)展示了通过不同的长尾学习方法,在各个类别组之间平均的参数重要性。

- 图片注解:图 1:a) 比较基准 ResNet 模型、PaCo、CMO、RIDE以及我们提出方法的不同类别组分类准确率。b) 比较各种方法的平均参数重要性。我们注意到准确性与参数重要性之间存在正相关关系。更多的可视化结果在补充材料中提供。
-
发现每个类别组的准确性与该类别组的参数平均重要性之间存在正相关关系。
- 当朴素的 ResNet 模型(Base)在长尾 ImageNet 数据集上进行训练时,它表现出对多类别组的高度偏见参数重要性,导致这个组的准确性显著高于其他组。
- 相反,长尾方法在中等和少量类别组上展示了增强的性能,以及在这些特定类别组上增加了参数重要性。
-
-
多阶段优化框架:
- 上述观察结果说明了在类别组之间重新平衡参数重要性以改善不平衡分类的优势。这激励我们提出一种新的多阶段优化框架,旨在实现所有类别之间参数重要性的均衡。
- 具体来说,
- 该框架将模型参数解耦为不同的子集,每个子集都针对训练集中的特定类别组进行优化。
- 在每一个阶段,
- 我们首先应用一个协作参数优化(CPO)过程,该过程旨在提高对特定类别组的参数重要性。
- 在此之后,我们采用一种泰勒引导的参数解耦(TPO)方法来选择对当前偏好类别组学习具有重要性的参数。
- 然后将重要性较小的参数重新初始化,并在后续阶段用于优化。
- 在每一阶段的最后,构建一个子模型,包含对当前学习阶段具有重要性的参数。
- 在推理阶段,使用实例级测试时学习机制聚合这些子模型的输出以获得最终预测。
- 如图 1 所示,我们的方法在所有类别组之间展示了良好的平衡参数重要性,从而显著提高了性能。
-
具体来说,我们的贡献总结如下:
- 我们提出了一种多阶段参数解耦和优化(DO)框架,能够在所有类别之间很好地平衡参数的重要性。
- 我们的框架采用了一种协作参数优化(CPO)程序,该程序采用群体增强的采样策略和补偿损失,以强制模型参数学习关于不同类别的互补信息。
- 我们采用了一种泰勒引导的参数解耦(TPD)方法,该方法采用泰勒展开来近似参数的重要性,并使用它来选择对不同类别组重要的参数。
- 提出了一种新颖的实例级测试时学习算法,用于在组装具有不同专业知识的模型时获得更精确的预测。
- 在CIFAR100、ImageNet-LT、Places-LT 和 iNaturalist18 上的广泛实验表明,我们的方法在许多、中等和少量类别组上取得了优于最近方法的性能提升。
Section 2 Related Work
-
长尾学习(Long-tailed learning)
长尾学习旨在训练模型以处理遵循长尾类别分布的数据集。现有的算法可以大致分为单一模型不平衡学习(single model imbalance learning)和多专家不平衡学习(multi-expert imbalance learning)两大类。
-
单一模型不平衡学习
这些工作可以进一步分为三个子类别:重新平衡(re-balancing)、知识迁移(knowledge transfer)和多阶段学习(multi-stage learning)
- 重新平衡通常通过类别重采样和损失重新加权来增强模型训练过程中少数类的影响。这些方法在类别或实例级别为少数类样本分配更高的权重。
- 其他研究尝试通过分布校准或增强将多数类的知识迁移到缺乏知识的少数类。
- 多阶段学习是长尾分类的有效训练方案,因为特征学习和分类器学习偏好不同的训练策略。
- 自监督学习(SSL)已被用于在以前的研究中改善特征质量,表明 SSL 产生了对类别不平衡更鲁棒的特征,并在长尾分类中显著提高了模型性能。
- 其他方法已被提出以改善两个学习阶段之间的校准。例如,
- (Li, Wang和Wu,2021)实现了一个额外的自蒸馏阶段,以更好地在多阶段学习中结合标签相关性。
- 此外,Zhang 等人使用轻量级的分布对齐模块来校准分类分数,从而改进了当前的两阶段方法。
-
多专家不平衡学习
现有的单一模型方法减少了少数类的模型偏差,但增加了所有类的模型方差,导致多数类的准确性下降。因此,提出了多专家不平衡学习框架,例如
- RIDE 允许多个专家模型捕捉互补知识。
- 沿着这条研究路线,NCL 被提出,通过在线蒸馏模块增强专家之间的知识转移,
- SADE 明确专注于每个专家不同的数据分布,并使用自监督的测试时聚合机制来融合专家的输出。
- 此外,SHIKE 结合了不同层的特征,以利用网络不同深度的编码信息,
- 而 BalPoE 通过对数调整和 Mixup 鼓励无偏置和良好校准的集成。
-
-
持续学习(Continual Learning)
- 我们的工作从持续学习中获得灵感,在持续学习中,模型参数不断调整以适应非静止数据分布。
- 当前的方法可以分为三类。
- 基于正则化的方法,使用额外的正则化项,旨在在先前任务和当前任务之间找到平衡。虽然它们显示出了有效性,但当处理具有挑战性的设置或复杂的数据集时,它们可能会遇到困难。
- 另一方面,基于排练的技术使用紧凑的内存缓冲区或额外的生成模型来存储或生成先前任务的代表性数据。许多近期研究通过整合知识蒸馏或自监督学习(SSL)来增强这一概念。然而,这些方法的适用性通常受到内存需求的限制。
- 基于架构的方法专注于构建特定于任务的参数。在为每个任务分配参数时,模型架构可以是固定的或动态的大小。
-
与之前工作的差异:
- 单一模型方法在少数类上显示了性能的改进,但可能会降低多数类的准确性。虽然多专家模型可以缓解这个问题,但它们在子模型之间缺乏有效的交互,并且通常在模型初始化时固定专家的能力。
- 相比之下,我们的工作在动态地将模型参数分配到子组方面改进了传统的多专家训练,并探索了如何有效地提高少数类的性能,而不会损害多数类的准确性,并进一步增强参数交互。
- 我们在方法中融入了基于架构的持续学习的概念。然而,我们的重点是设计更可靠的准则来量化参数重要性并在所有类别之间平衡它们的重要性,以增强长尾分类。
Section 3 Methodology
-
由于每个类别组的准确性与相应的参数重要性之间存在正相关关系,我们提出了一种名为解耦优化(Decoupled Optimisation,DO)的新型优化框架,用于长尾视觉识别,以显式地平衡类别组之间的参数重要性。
-
图 2 展示了我们框架的工作流程。

- 图片注解:图 2:DO 的整体工作流程。在训练期间,使用多阶段训练方案。在每一阶段,我们首先应用一个 CPO 步骤,该步骤策略性地针对一组可学习参数,并训练它们以携带与特定类别组相关的互补信息。然后应用一个 TPD 步骤,以保留当前学习阶段的重要参数,并将剩余的参数设置为后续阶段的学习参数。在推理阶段,使用实例级测试时学习来获得聚合权重,以融合来自每个子模型的输出来获得最终预测。
-
给定一个由 θ \theta θ 参数化的分类模型 F \mathcal{F} F,我们在 T T T 个阶段上对长尾数据集 D \mathcal{D} D 进行训练,并将 θ \theta θ 解耦为 T T T 个不同的组 { θ 1 , θ 2 , ⋯ , θ T } \{\theta_1,\theta_2,\cdots,\theta_T\} {θ1,θ2,⋯,θT},其中每个组专注于特定的一组类别 { Y 1 , Y 2 , ⋯ , Y T } \{Y_1,Y_2,\cdots,Y_T\} {Y1,Y2,⋯,YT}。
-
根据之前的长期研究,我们在 D \mathcal{D} D 上定义了三个类别组(多、中组和少组),我们设置 T = 3 T=3 T=3,并在第一阶段从多组开始学习,然后逐渐过渡到样本较少的组。
-
在每一阶段 t t t,首先进行协作参数优化( C P O CPO CPO)过程,鼓励 θ t \theta_t θt 在表示特定类别组 t t t 时携带重要信息。
-
参数 w i ∈ θ t w_i\in\theta_t wi∈θt 对类别 y y y 的重要性通过 w i w_i wi 周围的一阶泰勒展开来近似,即, E w i y = ( w i g w i y ) 2 \mathcal{E}^y_{w_i}=(w_ig^y_{w_i})^2 Ewiy=(wigwiy)2,其中 g w i y g^y_{w_i} gwiy 表示关于类别 y y y 的一阶导数。
-
一旦 θ t \theta_t θt 在该阶段被优化,我们就根据参数重要性应用泰勒引导的参数解耦( T P D TPD TPD)方法将 θ t \theta_t θt 解耦为重要部分 θ t ˉ \bar{\theta_t} θtˉ 和不重要部分 θ t ^ \hat{\theta_t} θt^。然后, θ t ˉ \bar{\theta_t} θtˉ 被固定, θ t ^ \hat{\theta_t} θt^ 被重新初始化,以便对其他类别组进行进一步优化,
除了最后一个阶段,即 θ t ˉ = θ T \bar{\theta_t}=\theta_T θtˉ=θT 。
-
为了在下一阶段 t t t 进行 C P O CPO CPO 过程,之前阶段的 θ ˉ t − 1 \bar{\theta}_{t-1} θˉt−1也被激活。这提供了双重好处。
- 首先,跨不同阶段优化的参数协同交互,放大了整体性能。
- 其次,来自先前阶段的知识库有助于当前阶段的学习。
这种设置对于学习样本较少的类别尤其重要,因为它们在学习参数中的代表性较低。
-
-
为了在推理过程中最优地平衡参数重要性,采用了两个操作:
- 在每个训练阶段的结束时,将 { θ ˉ 1 ⋯ t − 1 ∪ θ ˉ t } \{\bar{\theta}_{1\cdots t-1}\cup\bar{\theta}_t\} {θˉ1⋯t−1∪θˉt} 存储为子模型;
- 应用实例级测试时学习算法,根据这些 T T T 个子模型的预测稳定性获得聚合权重 λ t \lambda_t λt。最终结果是这 T T T 个子模型的加权和。
-
3.1 Collaborative Parameter Optimisation
协作参数优化
-
CPO 过程旨在显式地提高关于特定类别组的参数重要性。这是通过群体偏好的采样策略和优化的补偿损失来实现的。
- 定义 N i N_i Ni 为第 i i i 类的图像数量,
- K K K 为总类别数,
- L = [ N i / ∑ j ∈ K N j : i ∈ 1 ⋯ K ] L=[N_i/\sum_{j\in K}N_j:i\in1\cdots K] L=[Ni/∑j∈KNj:i∈1⋯K] 是包含标签频率的列表。
-
组首选采样策略(Group-preferred sampling strategy)
-
通过改变每个类的采样比例,模型改变其学习偏好。
-
在我们的方法中,我们为每个阶段使用不同的采样策略 p t ( x , y ) p_t(x,y) pt(x,y),其中 ( x , y ) (x,y) (x,y) 表示数据样本 x x x 及其相应的类别标签 y y y。
-
具体来说,
-
我们在第一阶段采用原始长尾分布进行数据采样,以偏好学习许多类,即 p 1 ( x , y ) = L [ y ] p_1(x,y)=L[y] p1(x,y)=L[y],
-
并在第三阶段采用逆长尾分布,即 p 3 ( x , y ) = 1 / N y p_3(x,y)=1/N_y p3(x,y)=1/Ny 进行少数类偏好的学习。
-
在第二阶段学习中等组类别时,我们引入了中等增强比例 ρ m \rho_m ρm,并使用以下方程定义 p 2 p_2 p2:
p 2 ( x , y ) = { ρ m y ∈ Y 2 1 − ρ m e l s e ( 1 ) \left.p_2(x,y)=\left\{\begin{array}{cc}\rho_m&\quad y\in Y_2\\1-\rho_m&\quad else\end{array}\right.\right.\qquad(1) p2(x,y)={ρm1−ρmy∈Y2else(1)- 在这里, ρ m \rho_m ρm 控制我们想要增强中等组学习的程度。关于 ρ m \rho_m ρm 影响的进一步讨论和洞察在消融研究中提供。
-
-
-
补偿损失(Compensation loss)
-
常用的交叉熵损失将每个类别平等对待,这可能导致在强调从特定类别学习时性能不佳。为了解决这个限制,我们建议将补偿项 α t \alpha_t αt 整合到动态增强当前偏好的类别组相关的某些模型参数的重要性中。
L c o m p t = 1 n ∑ x ∈ D − y log σ ( F θ t ( x ) − log α t ) ( 2 ) \mathcal{L}_{comp}^t=\frac1n\sum_{x\in D}-y\log\sigma(\mathcal{F}_{\theta_t}(x)-\log\alpha_t)\quad(2) Lcompt=n1x∈D∑−ylogσ(Fθt(x)−logαt)(2)-
其中 σ \sigma σ 是 softmax 函数, α t \alpha_t αt 根据以下方式在不同阶段交替:
α t = { 1.0 t = 1 ρ m t = 2 τ ( y ) t = 3 ( 3 ) \left.\alpha_t=\left\{\begin{array}{cc}1.0&\quad t=1\\\rho_m&\quad t=2\\\tau(y)&\quad t=3\end{array}\right.\right.\qquad(3) αt=⎩ ⎨ ⎧1.0ρmτ(y)t=1t=2t=3(3)- 在这里, τ ( y ) = R ( L ) [ y ] \tau(y)=\mathcal{R}(L)[y] τ(y)=R(L)[y],其中 R ( ⋅ ) \mathcal{R}(·) R(⋅) 表示逆序操作。
- 补偿项 α t \alpha_t αt 作为边际,施加更强的正则化,鼓励模型优先学习当前偏好的类别组。
-
-
3.2 Taylor-guided Parameter Decoupling
泰勒引导的参数解耦
-
并非所有参数在学习中都具有同等的重要性,移除那些重要性低的参数可能不会对模型的性能产生显著影响。参数的重要性可以通过移除它对模型损失变化的影响来估计。
-
我们设计了一种泰勒引导的参数解耦(TPD)方法来近似参数的重要性。具体来说,
-
我们根据 E w i y \mathcal{E}^y_{w_i} Ewiy 对每个参数 w i w_i wi 进行排名,然后剪枝 γ \gamma γ 个参数,保留其余的作为重要参数。
-
我们主张最佳的剪枝比例 γ best \gamma_\text{best} γbest 应该产生最紧凑的模型,同时保持其性能。因此,我们迭代 γ i \gamma_i γi 的值, i ∈ 0 ⋯ 90 i\in0\cdots90 i∈0⋯90,步长为 10 10 10,并记录相关的性能。
- γ best \gamma_\text{best} γbest 是基于记录的性能中观察到的最高变化选择的。
-
此外,我们不是直接剪枝 γ i \gamma_i γi 个参数,而是逐渐剪枝,使用 γ t \gamma_t γt 进行渐进剪枝:
γ t = γ i + 1 + ( γ i − γ i + 1 ) ( 1 − t Δ t ) 3 ( 4 ) \gamma_t=\gamma_{i+1}+(\gamma_i-\gamma_{i+1})(1-\frac t{\Delta t})^3\qquad(4) γt=γi+1+(γi−γi+1)(1−Δtt)3(4)- 其中 γ t \gamma_t γt 从 γ i \gamma_i γi 增加到 γ i + 1 \gamma_{i+1} γi+1 ,步长为 Δ t \Delta t Δt。
- 在我们的实验中,我们发现将 Δ t \Delta t Δt 从 10 10 10 变化到 100 100 100 对性能几乎没有影响,因此我们将 Δ t \Delta t Δt 设置为 10 10 10。
-
在每个涉及 γ t \gamma_t γt 的剪枝步骤之后,我们会进行一次重新训练,确保模型的任务区分能力得以保持。
-
一旦 γ best \gamma_\text{best} γbest 被选定,我们就剪枝掉 γ best \gamma_\text{best} γbest 个总参数,并将它们设置为不重要的参数 θ ^ t \hat{\theta}_t θ^t,这些参数用于进一步的优化和解耦,而保留的参数被视为重要的参数 θ ˉ t \bar{\theta}_t θˉt,它们将保持固定。
-
3.3 Instance-level Test-time Learning
实例级测试时学习
-
训练后,我们得到了 T T T 个子模型,每个子模型包含一组参数( θ ˉ t ∗ = { θ ˉ 1 ⋯ t − 1 ∪ θ ˉ t } \bar{\theta}^∗_t=\{\bar{\theta}_{1\cdots t−1}\cup\bar{\theta}_t\} θˉt∗={θˉ1⋯t−1∪θˉt}),这些参数对每个类别组具有高度的重要性。由于 θ ˉ 1 ⋯ t − 1 \bar{\theta}_{1\cdots t−1} θˉ1⋯t−1 在 θ ˉ t \bar{\theta}_t θˉt 的优化过程中被激活,因此两者都被包括在内。
-
在推理阶段,为了在不同类别之间最优化地平衡参数重要性,我们使用实例级测试时自监督学习方法为每个子模型 f θ ˉ t ∗ f_{\bar{\theta}^*_t} fθˉt∗ 生成基于预测稳定性最大化的聚合权重( λ t \lambda_t λt)。
- 这受到了(Zhang 等人,2022)的启发,后者强调了模型专业知识和预测稳定性之间的正相关关系。然而,他们是在组的层面上生成 λ t \lambda_t λt,即 λ = { λ t } t = 1 T \lambda=\{\lambda_t\}^T_{t=1} λ={λt}t=1T。
- 我们认为,这种粗粒度的 λ \lambda λ 只能部分反映模型在不同类别之间的稳定性。因此,在我们的方法中,我们应用实例级别的聚合,即 λ = { { λ t } t = 1 T } i = 1 U \lambda=\{\{\lambda_t\}^T_{t=1}\}^U_{i=1} λ={{λt}t=1T}i=1U,其中 U U U 表示测试样本的数量。
-
具体来说,给定一个输入测试图像 x x x,我们进行两次随机数据增强来产生 x x x 的两个视图,分别表示为 x 1 x_1 x1 和 x 2 x_2 x2。然后我们获得相应的预测 y ~ 1 = ∑ t = 1 T λ t f θ ˉ t ∗ ( x 1 ) \tilde{y}_1=\sum^T_{t=1}\lambda_tf_{\bar{\theta}^∗_t}(x_1) y~1=∑t=1Tλtfθˉt∗(x1) 和 y ~ 2 = ∑ t = 1 T λ t f θ ˉ t ∗ ( x 2 ) \tilde{y}_2=\sum^T_{t=1}\lambda_tf_{\bar{\theta}^∗_t}(x_2) y~2=∑t=1Tλtfθˉt∗(x2)。我们的目标是使用这些两个视图的预测之间的余弦相似度最大化。
λ = arg max λ y 1 ~ T y 2 ~ (5) \lambda=\arg\max_{\lambda}\tilde{y_1}^T\tilde{y_2}\text{(5)} λ=argλmaxy1~Ty2~(5)- 请注意, λ = [ λ 1 , ⋯ , λ t ] \lambda=[\lambda_1,\cdots,\lambda_t] λ=[λ1,⋯,λt] 是这些函数中唯一可学习的超参数。
- 通过最大化这两个预测之间的余弦相似度,相应的 λ t \lambda_t λt(与 f θ ˉ t ∗ f_{\bar{\theta}^∗_t} fθˉt∗ 相关,对于特定类别样本的预测更加稳定)将被学习到增加。因此,这些学习的 λ t \lambda_t λt 可以有效地反映 f θ ˉ t ∗ f_{\bar{\theta}^∗_t} fθˉt∗ 在预测未见样本时的信心。
- 特定子模型 f θ ˉ t f_{\bar{\theta}_t} fθˉt 在给定类别上的预测稳定性越高,相应的聚合权重 λ t \lambda_t λt 在推理过程中将被更加强调,从而导致该类别的更可靠和准确的总体预测。
Section 5 Experiments
5.1 Datasets
-
ImageNet-LT
ImageNet-LT 是 ImageNet 的长尾版本。它是通过使用幂值 α = 6 \alpha=6 α=6 从 Pareto 分布中采样一个子集生成的。它包含 115,800 张图像,涵盖 1,000 个类别,其中类的大小范围从 5 到 1,280。
-
iNaturalist 2018
iNaturalist 2018 是一个大规模的物种分类数据集。它包含 8,142 个类别,这些类别受到严重的类别不平衡问题的影响,类别的大小范围从 5 到 4,980。
-
CIFAR100-LT
CIFAR100-LT 包含 60,000 张图像,其中 50,000 张用于训练,10,000 张用于验证。这项工作使用了 CIFAR100 的长尾版本,其中不平衡比例( β \beta β)是手动选择的,使用 β = N m a x N m i n \beta=\frac{N_{max}}{N_{min}} β=NminNmax,其中 N m a x N_{max} Nmax 和 N m i n N_{min} Nmin 是最常出现类和最少出现类的实例数。
-
Places-LT
Places-LT 是原始 Places-2 的长尾版本,包含 184,500 张图像,来自总共 365 个类别,其中类的大小范围从 5 到 4,980。
5.2 Implementation Details
实施细节
-
模型选择:
我们在 ImageNet-LT 和 iNaturalist 2018 上使用 ResNet50,在 PlacesLT 上使用 ResNet152,在 CIFAR100-LT 上使用 ResNet32。
-
训练周期、学习率、批量大小与设备:
- 对于第一阶段,我们在 ImageNet-LT、iNaturalist2018 和 Places-LT 上进行 100 个周期的训练,并使用余弦调度器从 0.02 降低到 0 的学习率。
- 对于剩余的两个阶段,由于我们只微调模型的部分部分,所以我们只训练 50 个周期,学习率分别为 ImageNet-LT、iNaturalist2018 和 Places-LT 的 0.002,CIFAR100LT 的 0.005。
- 所有训练都在批量大小为 256 的情况下进行。
- 在所有报告的实验中,我们使用在之前研究中已证明有效的强增强。所有报告的模型都是使用 4 个 NVIDIA Tesla V100 GPU 进行训练的。
-
ρ m \rho_m ρm 设置
在中间增强采样中的 ρ m \rho_m ρm 设置为 ImageNet-LT、iNaturalist 2018 和 Places-LT 的 80%,CIFAR100-LT 的70%。
-
γ b e s t \gamma_{best} γbest 设置
-
为了选择 γ b e s t \gamma_{best} γbest,我们遍历从 0% 到 100% 的十个可能值,步长为 10%。
-
对于所有使用的数据集,第一阶段的 γ b e s t \gamma_{best} γbest 设置为 50%,而对于第二阶段, γ b e s t \gamma_{best} γbest 设置为 ImageNet-LT、PlacesLT 和 CIFAR100( β = 100 \beta=100 β=100)的 80%,iNaturalist 2018 和 CIFAR100( β = 50 \beta=50 β=50)的 60%。
-
我们在验证集上调整参数,并报告 ImageNet-LT 的测试集结果。对于其他仅具有 train-val 集的数据集,相同的验证集用于调整和基准测试。
5.3 Comparison to the Prior Art
与现有技术的比较
-
我们比较了 DO 与之前的最先进方法。我们在 ImageNet-LT(表 1)、iNaturalist2018(表 2)、CIFAR100(表 4 和表 5)和PlacesLT(表 3)上展示了结果。
- 对于所有比较的方法,如果他们在作品中使用了强增强,我们就报告了他们的性能。
- 具体来说,我们选择了基于单一模型的(SE)方法。例如,损失重新加权(BSCE),LADE,GCL、知识迁移(CMO、RSG)、解耦基础方法(MiSLAS、WB)和特征学习(PaCo)以及多专家(ME)方法(RIDE、ACE、SADE、NCL、SHIKE 和 BalPoE。

- 图片注解:表 1:ImageNet-LT 测试精度(%)比较。

- 图片注解:表 2:iNaturalist 2018 测试精度(%)比较。

- 图片注解:表 3:Places-LT测试精度(%)比较。

- 图片注解:表 4: CIFAR100-LT β = 50 \text{CIFAR100-LT}_{\beta=50} CIFAR100-LTβ=50 测试精度(%)比较。

- 图片注解:表5: CIFAR100-LT β = 100 \text{CIFAR100-LT}_{\beta=100} CIFAR100-LTβ=100 测试精度(%)比较。
-
DO 在现有的 SE 方法中表现最佳;
- 例如,它在 ImageNet-LT 和 iNaturalist 2018 上分别比 PaCo 提高了 3.4% 和 2.6%。
- 此外,DO 仅训练了 200 个周期,这比基于对比学习的 ME 方法使用的 400 个周期训练要少得多。
- 与 ME 方法相比,
- DO 在三个特别具有挑战性的数据集上展示了最先进的性能(ImageNet-LT 的 60.4%,iNaturalist 2018 的 75.8%,Places-LT 的 42.8%),并在 CIFAR100-LT 数据集上取得了竞争性的结果(58.2% β = 50 \beta=50 β=50 和 53.8% β = 100 \beta=100 β=100)。
- 然而,大多数 ME 方法在推理过程中使用三个或更多的完整网络作为它们的专家,而我们的 DO 使用只利用整个模型参数子集的子模型,这不仅减少了计算开销,而且实现了可比甚至更优越的性能。
5.4 Discussion & Ablations
讨论与消融
-
ρ m \rho_m ρm 和 γ \gamma γ 的敏感性分析(Sensitivity analysis of ρ m \rho_m ρm and γ \gamma γ )
-
ρ m \rho_m ρm 控制模型集中于中等组学习的程度。
-
图 3 显示,增加 ρ m \rho_m ρm 可以改善中等组的表现,因为可以采样更多中等组中的类别。

- 图片注解:图 3:中等增强采样比 ρ m \rho_m ρm 的敏感性分析。
-
然而,提高 ρ m \rho_m ρm 也会抑制其他两个组的学习。因此,随着 ρ m \rho_m ρm 的增大,改进的程度变得微不足道。
-
-
我们在图 4 中展示了不同阶段不同剪枝比例下的性能变化。
-
当剪枝比例较小时,性能下降也较小。这表明模型可能过于参数化,移除一部分参数不会对性能产生重大影响。
-
此外,随着剪枝比例的增大,例如 ImageNet-LT 的第一阶段 50% 和第二阶段 80%,性能显著下降。
-
因此,我们将其设置为 γ b e s t \gamma_{best} γbest,因为它产生最紧凑的模型,性能下降最低。

- 图片注解:图 4:不同剪枝方法下,不同剪枝比例的性能下降。 γ b e s t \gamma_{best} γbest 是在性能下降最大变化处选择的。
-
-
此外,我们还比较了不同的参数重要性估计方法: L 1 L1 L1 范数、泰勒近似和 Fisher 信息。
- 其中, L 1 L1 L1 范数性能下降最大。
- 相比之下,两种基于梯度的方法提供了更可靠的估计。
- 虽然 Fisher 估计假设所有神经元的权重都是严格正的(这只有在某些情况下才正确,如在(Molchanov 等人,2019年)中指出的那样),
- 但泰勒近似明确估计了损失的变化,并证明是一个更好的重要性估计器。
-
-
阶段选择的影响(Influence of stage selection)
-
在表 6 中,我们列出了所提出框架的两个配置:两阶段和四阶段。
-
前者仅进行多组和少组学习。它为多组和少组实现了良好的性能,但中等组仍需进一步改进。
-
对于四阶段配置,我们将中等组分别均匀地分为中等-高(100∼50 个样本)和中等-低(50∼20 个样本)。这需要更长的训练时间,但仅带来微小的提升。

- 图片注解:表 6:ImageNet-LT 测试精度(%)与不同阶段数量的比较。
-
-
阶段顺序也很重要,如表 7 所示。
-
除了默认设置外,我们还进行了少数组首先学习,这显著提高了中等组的准确性。
-
相比之下,我们的默认设置进一步提高了中等组和少数组的性能。这可能归因于两个原因。
- 首先,第二阶段总是有更多的自由参数,这可以提高中等组的性能。
- 其次,从多类和中等类学到的参数嵌入了大量信息,这可能有助于少数类的学习。

- 图片注解:表7:ImageNet-LT 测试精度(%)与不同阶段顺序的比较。
-
-
-
中等偏好采样策略和 L c o m p \mathcal{L}_{comp} Lcomp 的有效性(Effectiveness of Medium-preferred sampling strategy and L c o m p \mathcal{L}_{comp} Lcomp)
-
如表 8 所示,将均匀采样替换为增强采样策略将性能从 55.8% 提高到 57.6%,表明增强中等组学习是有用的。
-
此外,将损失函数从交叉熵更改为补偿损失是重要的,因为它鼓励每个参数组专注于学习互补信息。通过结合所有提出的组件可以实现最佳性能。

- 图片注解:表 8:ImageNet-LT 的消融研究。 “ A g g i n t / g p / a v g Agg_{int/gp/avg} Aggint/gp/avg”:实例级测试时聚合、组级测试时聚合和平均聚合。“ S u n i / m e d S_{uni/med} Suni/med”:中等组的全局采样或增强采样,以及“ L c o m p / c e L_{comp/ce} Lcomp/ce”:补偿损失或交叉熵损失。
-
-
实例级测试时学习的有效性
-
如表 8 所示,测试时学习对性能改进是有益的。实例级测试时学习策略可以比组级聚合策略提高大约 2% 至 3% 的性能。
-
此外,表 9 的结果显示,我们的实例级测试时学习策略为具有不同专长的子模型学习合适的权重。
-
对于从第一阶段学习的子模型, λ 1 \lambda_1 λ1 对于多组较高,而对于从第三阶段学习的子模型, λ 3 \lambda_3 λ3 对于少组较高。

- 图片注解:表 9:不同组实例的平均 λ t \lambda_t λt。
-
-
为了更好地理解性能与计算成本之间的权衡,在表 10 中,我们比较了 PaCo(一种没有测试时学习的算法)和 SADE(一种具有测试时学习的算法)的测试时成本。
-
结果显示,我们的实例级测试时学习增加了计算开销,但带来了显著优越的结果。
-
为了应对高计算成本的挑战,我们提出了一种替代方法,其中我们用所有子模型的输出平均值替换测试时学习(TTL)。这个版本仍然提供了竞争力的性能,同时显著加快了推理过程。这一结果强调了平衡权重重要性在缓解长尾问题方面的有效性。

- 图片注解:表 10:运行时成本评估。
-
-