原文链接
[2005.06803] TAM: Temporal Adaptive Module for Video Recognition (arxiv.org)
原文代码
GitHub - liu-zhy/temporal-adaptive-module: TAM: Temporal Adaptive Module for Video Recognition
原文笔记
What:
TAM: Temporal Adaptive Module for Video Recognition
根据视频帧的不同的特征图自适应的生成卷积核:两阶段自适应方案
模型有点:体积小,可插拔,适应性强,效果好
Why:
由于相机运动、速度变化和不同活动等因素,视频数据具有复杂的时间动态。为了有效地捕捉这种多样化的运动模式,本文提出了一种新的时间自适应模块(TAM),根据自己的特征图生成视频特定的时间核。
视频理解的深度学习研究进展相对较慢,部分原因是视频数据的高度复杂性。视频理解的核心技术问题是设计一个有效的时间模块,该模块有望能够以高灵活性捕获复杂的时间结构,同时以低计算量实现对高维视频数据的高效处理
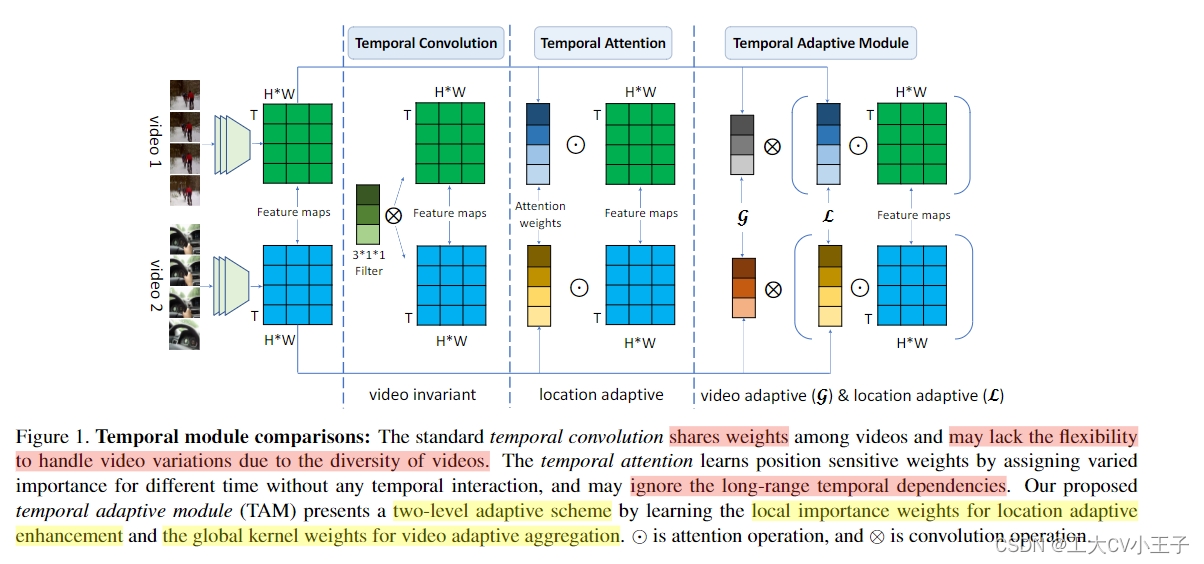
上述所有方法都有一个共同的见解,即它们是视频不变的,而忽略了视频中固有的时间多样性。
3D卷积神经网络(3D CNN)[15,34]已被证明是视频建模的主流架构[1,8,36,27]。3D卷积(时间卷积)仅仅通过使用固定数量的固定参数的视频卷积核可能缺乏足够的表示能力来描述运动多样性,
3D 卷积是2D卷积的直接扩展,并为视频识别提供了一个可学习的算子。然而,这种简单的扩展缺乏对视频数据中的时间属性的特定考虑,并且也可能导致高计算成本。因此,最近的方法旨在通过将轻量级时间模块与 2D CNN 相结合来提高效率(例如 TSN [40]、TSM [23])或设计一个专用时间模块来更好地捕获时间关系(例如,非本地网络 [41]、ARTNet [38]、STM [17]、TDN [39])。然而,如何设计一个具有高效率和强大灵活性的时间模块仍然是一个未解决的问题。因此,我们的目标是沿着这个方向推进当前的视频架构。
Challenge:
如何设计一个有效的时间模块,
1、该模块有望能够以高灵活性捕获复杂的时间结构
2、同时以低计算量实现对高维视频数据的高效处理
Idea:
对于Challenge1:
作者提出根据视频的特征图生成特定的时间核
为了处理视频中如此复杂的时间变化,我们认为每个视频的自适应时间核是有效的,也是描述运动模式所必需的。
我们提出了一种两级自适应建模方案,将视频特定的时间核分解为
1、位置敏感重要性图(location sensitive importance map)专注于从局部视角增强有区别的时间信息,(本文一直说location sensitive importance map,局部分支的作用就是生成这个包含局部信息的全局map,以逐元素点乘的方式将信息聚合到特征里边,详细说明见(下)篇)
2、位置不变(也是视频自适应)聚合核。(location invariant(also viseo adaptive)aggregation kernel)能够通过输入视频序列的全局视角捕获时间依赖性。(作者通过FC层来学习卷积核,所以卷积核都拥有了全局视野,通过卷积操作把信息融入特征中,作者的的 TANet(TANet是将TAMblock整合到网络模块中的网络的统称)通过简单地堆叠更多的 TAM 来捕获长期依赖关系(本质上就是有更多fc层嘛,自然也就捕获了更多的长期依赖关系),并保持网络的效率。详细说明见(下)篇)
为了保持计算效率,L和G分支都是建立在输入数据压缩的基础上的,详细信息见(下)篇。
《Tam》论文笔记(下)-CSDN博客
原文翻译
Abstract
由于相机运动、速度变化和不同活动等因素,视频数据具有复杂的时间动态。为了有效地捕捉这种多样化的运动模式,本文提出了一种新的时间自适应模块(TAM),根据自己的特征图生成视频特定的时间核。TAM提出了一种独特的两级自适应建模方案,将动态核解耦为位置敏感重要性图和位置不变聚合权重。重要性图是在局部时间窗口中学习的,以捕获短期信息,而聚合权重是从全局视图生成的,重点是长期结构。TAM 是一个模块化块,可以集成到 2D CNN 中,以产生强大的视频架构 (TANet),具有非常小的额外计算成本。在Kinetics-400和Something-Something数据集上的大量实验表明,我们的TAM始终优于其他时间建模方法,并在相似复杂度下实现了最先进的性能。该代码可在以下链接获得GitHub - liu-zhy/temporal-adaptive-module: TAM: Temporal Adaptive Module for Video Recognition
1. Introduction
深度学习在图像分类[21,12]、目标检测[28]和实例分割[11]等图像识别任务中取得了很大的进展。这些成功的关键是设计灵活高效的架构,能够从大规模图像数据集[4]中学习强大的视觉表示。然而,视频理解的深度学习研究进展相对较慢,部分原因是视频数据的高度复杂性。视频理解的核心技术问题是设计一个有效的时间模块,该模块有望能够以高灵活性捕获复杂的时间结构,同时以低计算量实现对高维视频数据的高效处理。
3D卷积神经网络(3D CNN)[15,34]已被证明是视频建模的主流架构[1,8,36,27]。3D 卷积是其 2D 对应物的直接扩展,并为视频识别提供了一个可学习的算子。然而,这种简单的扩展缺乏对视频数据中的时间属性的特定考虑,并且也可能导致高计算成本。因此,最近的方法旨在通过将轻量级时间模块与 2D CNN 相结合来提高效率(例如 TSN [40]、TSM [23])或设计一个专用时间模块来更好地捕获时间关系(例如,非本地网络 [41]、ARTNet [38]、STM [17]、TDN [39])。然而,如何设计一个具有高效率和强大灵活性的时间模块仍然是一个未解决的问题。因此,我们的目标是沿着这个方向推进当前的视频架构。
在本文中,我们专注于设计一个自适应模块以更灵活的方式捕获时间信息。有趣的是,我们观察到视频数据由于相机运动和各种速度等因素,沿时间维度具有极其复杂的动态。因此,3D卷积(时间卷积)仅仅通过使用固定数量的固定参数的视频卷积核可能缺乏足够的表示能力来描述运动多样性,为了处理视频中如此复杂的时间变化,我们认为每个视频的自适应时间核是有效的,也是描述运动模式所必需的。为此,如图1所示,我们提出了一种两级自适应建模方案,将视频特定的时间核分解为位置敏感重要性图(location sensitive importance map)和位置不变(也是视频自适应)聚合核。(location invariant(also viseo adaptive)aggregation kernel)这种独特的设计允许位置敏感的重要性图专注于从局部视角增强有区别的时间信息,并使视频自适应聚合能够通过输入视频序列的全局视角捕获时间依赖性。
具体来说,时间自适应模块的设计(TAM)严格地遵循两个原则:高效率和强大的灵活性。为了确保我们的 TAM 计算成本低,我们首先通过使用全局空间池化来压缩特征图,然后以通道方式建立我们的 TAM 以保持效率。我们的 TAM 由两个分支组成:局部分支 (L) 和全局分支 (G)。如图 2 所示,TAM 以有效的方式实现。局部分支采用时间卷积生成位置敏感重要性图来增强局部特征,而全局分支使用全连接层生成位置不变核进行时间聚合。局部时间窗口生成的重要性图侧重于短期运动建模,使用全局视图的聚合内核更关注长期时间信息。此外,我们的 TAM 可以灵活地插入到现有的 2D CNN 中,以产生高效的视频识别架构,称为 TANet。
我们在视频中动作分类任务验证了所提出的 TANet。特别是,我们首先研究了 TANet 在 Kinetics-400 数据集上的性能,并证明我们的 TAM 在捕获时间信息方面比其他几个对应物更好,例如时间池化、时间卷积、TSM [23]、TEINet [24] 和Non-local block [41]。我们的 TANet 能够产生以类似于 2D CNN 的 FLOPs 产生非常有竞争力的准确性。我们进一步在Something-Something的运动主导数据集上测试我们的TANet,我们的模型在这个数据集上实现了最先进的性能。
2 Related Work
视频理解是计算机视觉领域的核心课题。在早期阶段,许多传统的方法[22, 20, 29, 43]设计了不同的手工特征去编码视频数据,但这些方法在推广到其他视频任务时过于不灵活。最近,由于视频理解的快速发展很大程度上得益于深度学习方法[21,32,12],特别是在视频识别中,人们提出了一系列基于cnn的方法来学习时空表示,我们的方法的差异将在后面澄清。此外,我们的工作还涉及 CNN 中的动态卷积和注意力。
CNNs-based methods for action recognition.由于深度学习方法已广泛用于图像任务,因此有许多尝试 [18, 31, 40, 46, 10, 23, 39] 基于2D CNN 专门用于建模视频片段的 。特别是,[40]使用从整个视频稀疏采样的帧,通过聚合最后一个全连接层之后的分数来学习长范围的信息。[23] 以有效的方式沿时间维度移动通道,与 2D CNN 产生了良好的性能。通过对空间域到时空域的简单扩展,提出了三维卷积[15,34]来捕获视频片段中编码的运动信息。由于大规模动力学数据集[19]的释放,3D CNN[1]被广泛应用于动作识别中。它的变体[27,36,44]将三维卷积分解为空间二维卷积和时间一维卷积来学习时空特征。[8]设计了一个具有双路径的网络来学习时空特征,并在视频理解中取得了有希望的准确性。
上述所有方法都有一个共同的见解,即它们是视频不变的,而忽略了视频中固有的时间多样性。与这些方法相比,我们设计了一种两级自适应建模方案,将视频特定操作分解为位置敏感激励和为每个视频片段设计的具有自适应核的位置不变卷积。(这段有点吓胡诌了,我说的是作者不是我)
Attention in action recognition.TAM 中的本地分支主要与 SENet [13] 有关。但是SENet为特征图的每个通道学习调制权重。几种方法 [24, 5] 也诉诸注意力来学习视频中更具辨别力的特征。与这些方法不同的是,我们提出的local branch的局部分支在保留时间信息的同时来学习位置敏感的重要性。[41]设计了一个非局部块,可以看作是自我注意来捕获长期依赖关系。我们的 TANet 通过简单地堆叠更多的 TAM 来捕获长期依赖关系,并保持网络的效率。
Dynamic convolutions.[16]首先提出了视频和立体预测任务的动态滤波器,设计了一种卷积编码器-解码器作为滤波-生成网络。图像任务中的几项工作 [45, 3] 试图为一组卷积核生成聚合权重,然后生成一个动态内核。我们的动机与这些方法不同。我们的目标是使用这个时间自适应模块来处理视频中的时间变化。具体来说,我们设计了一种基于输入特征图的有效形式实现这种时间动态内核,这对于理解视频内容至关重要。
3 Method(见下篇)
《Tam》论文笔记(下)-CSDN博客