一、本文介绍
本文给大家带来的改进机制是利用MobileNetV4的UIB模块二次创新C3,其中UIB模块来自2024.5月发布的MobileNetV4网络,其是一种高度优化的神经网络架构,专为移动设备设计。它最新的改动总结主要有两点,采用了通用反向瓶颈(UIB,也就是本文利用的结构)和针对移动加速器优化的Mobile MQA注意力模块(一种全新的注意力机制)。我将其用于C3的二次创新在V5n上参数量为130W,计算量为3.3GFLOPs,非常适用于想要轻量化网络模型的读者来使用,同时本文结构为本专栏独家创新。
欢迎大家订阅我的专栏一起学习YOLO!

专栏目录:YOLOv5改进有效涨点目录 | 包含卷积、主干、检测头、注意力机制、Neck上百种创新机制
专栏回顾:YOLOv5改进专栏——持续复现各种顶会内容——内含100+创新
目录
一、本文介绍
二、原理介绍
三、核心代码
四、添加教程
4.1 修改一
4.2 修改二
4.3 修改三
4.4 修改四
五、C3UIB的yaml文件和运行记录
5.1 C3UIB的yaml文件1
5.3 C3UIB的训练过程截图
五、本文总结
二、原理介绍

官方论文地址: 官方论文地址点击此处即可跳转
官方代码地址: 官方代码地址点击此处即可跳转

MobileNetV4是MobileNet系列的最新版本,专为移动设备设计,引入了多种新颖且高效的架构组件。其中最关键的是通用反转瓶颈(UIB),它结合了以前模型如MobileNetV2的反转瓶颈和新元素,例如ConvNext块和视觉变换器(ViT)中的前馈网络。这种结构允许在不过度复杂化架构搜索过程的情况下,适应性地并有效地扩展模型到各种平台。
此外,MobileNetV4还包括一种名为Mobile MQA的新型注意力机制,该机制通过优化算术运算与内存访问的比率,显著提高了移动加速器上的推理速度,这是移动性能的关键因素。该架构通过精细的神经网络架构搜索(NAS)和新颖的蒸馏技术进一步优化,使得MobileNetV4能够在多种硬件平台上达到最优性能,包括移动CPU、DSP、GPU和特定的加速器,如Apple的Neural Engine和Google的Pixel EdgeTPU。
此外,MobileNetV4还引入了改进的NAS策略,通过粗粒度和细粒度搜索相结合的方法,显著提高搜索效率并改善模型质量。通过这种方法,MobileNetV4能够实现大多数情况下的Pareto最优性能,这意味着在不同设备上都能达到效率和准确性的最佳平衡。
最后,通过一种新的蒸馏技术,MobileNetV4进一步提高了准确性,其混合型大模型在ImageNet-1K数据集上达到了87%的顶级准确率,同时在Pixel 8 EdgeTPU上的运行时间仅为3.8毫秒。这些特性使MobileNetV4成为适用于移动环境中高效视觉任务的理想选择。
主要思想提取和总结:
1. 通用反转瓶颈(UIB),本文利用的机制:
MobileNetV4引入了一种名为通用反转瓶颈(UIB)的新架构组件。UIB是一个灵活的架构单元,融合了反转瓶颈(IB)、ConvNext、前馈网络(FFN),以及新颖的额外深度(ExtraDW)变体。
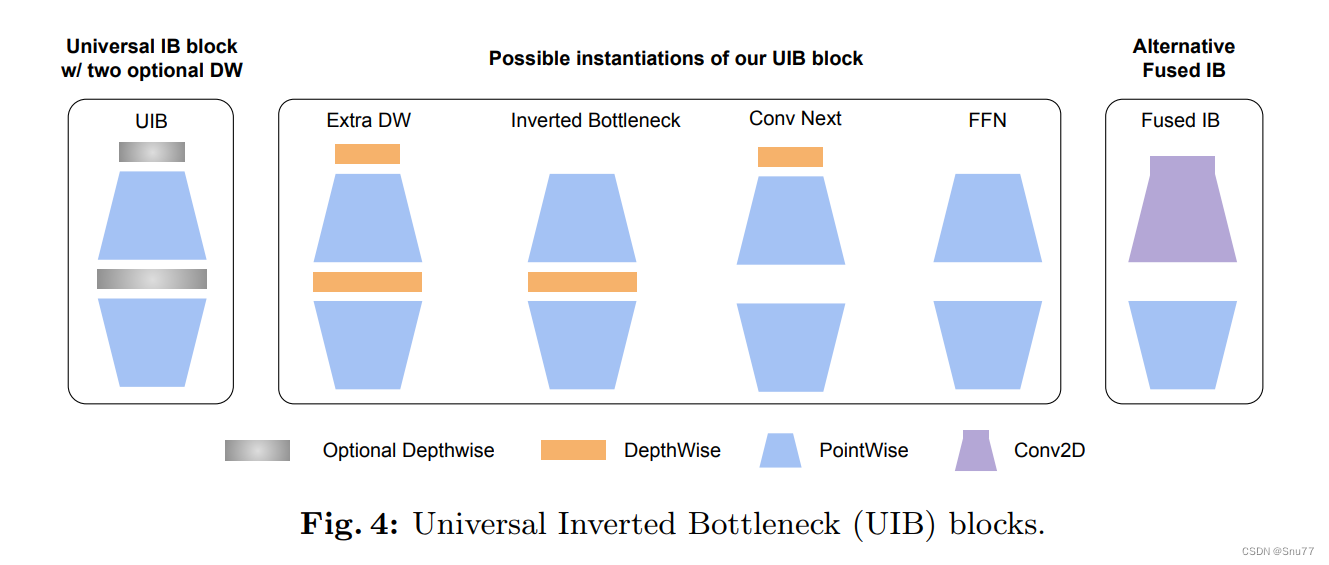
2. Mobile MQA注意力机制:
为了优化移动加速器的性能,MobileNetV4设计了一个特殊的注意力模块,名为Mobile MQA。这一模块针对移动设备的计算和存储限制进行了优化,提供了高达39%的推理速度提升。
3. 优化的神经架构搜索(NAS)配方:
通过改进的NAS配方,MobileNetV4能够更高效地搜索和优化网络架构,这有助于发现适合特定硬件的最优模型配置。
4. 模型蒸馏技术:
引入了一种新的蒸馏技术,用以提高模型的准确性。通过这种技术,MNv4-Hybrid-Large模型在ImageNet-1K上达到了87%的准确率,并且在Pixel 8 EdgeTPU上的运行时间仅为3.8毫秒。
个人总结:MobileNetV4是一个专为移动设备设计的高效深度学习模型。它通过整合多种先进技术,如通用反转瓶颈(UIB)、针对移动设备优化的注意力机制(Mobile MQA),以及先进的架构搜索方法(NAS),实现了在不同硬件上的高效运行。这些技术的融合不仅大幅提升了模型的运行速度,还显著提高了准确率。特别是,它的一个变体模型在标准图像识别测试中取得了87%的准确率,运行速度极快。
三、核心代码
核心代码的使用方式看章节四!
import torch.nn as nn
from typing import Optional
import torch
__all__ = ['C3_UIB']
def make_divisible(
value: float,
divisor: int,
min_value: Optional[float] = None,
round_down_protect: bool = True,
) -> int:
"""
This function is copied from here
"https://github.com/tensorflow/models/blob/master/official/vision/modeling/layers/nn_layers.py"
This is to ensure that all layers have channels that are divisible by 8.
Args:
value: A `float` of original value.
divisor: An `int` of the divisor that need to be checked upon.
min_value: A `float` of minimum value threshold.
round_down_protect: A `bool` indicating whether round down more than 10%
will be allowed.
Returns:
The adjusted value in `int` that is divisible against divisor.
"""
if min_value is None:
min_value = divisor
new_value = max(min_value, int(value + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if round_down_protect and new_value < 0.9 * value:
new_value += divisor
return int(new_value)
def conv_2d(inp, oup, kernel_size=3, stride=1, groups=1, bias=False, norm=True, act=True):
conv = nn.Sequential()
padding = (kernel_size - 1) // 2
conv.add_module('conv', nn.Conv2d(inp, oup, kernel_size, stride, padding, bias=bias, groups=groups))
if norm:
conv.add_module('BatchNorm2d', nn.BatchNorm2d(oup))
if act:
conv.add_module('Activation', nn.ReLU6())
return conv
class UniversalInvertedBottleneckBlock(nn.Module):
def __init__(self,
inp,
oup,
start_dw_kernel_size=3,
middle_dw_kernel_size=3,
middle_dw_downsample=1,
stride=1,
expand_ratio=1
):
"""An inverted bottleneck block with optional depthwises.
Referenced from here https://github.com/tensorflow/models/blob/master/official/vision/modeling/layers/nn_blocks.py
"""
super().__init__()
# Starting depthwise conv.
self.start_dw_kernel_size = start_dw_kernel_size
if self.start_dw_kernel_size:
stride_ = stride if not middle_dw_downsample else 1
self._start_dw_ = conv_2d(inp, inp, kernel_size=start_dw_kernel_size, stride=stride_, groups=inp, act=False)
# Expansion with 1x1 convs.
expand_filters = make_divisible(inp * expand_ratio, 8)
self._expand_conv = conv_2d(inp, expand_filters, kernel_size=1)
# Middle depthwise conv.
self.middle_dw_kernel_size = middle_dw_kernel_size
if self.middle_dw_kernel_size:
stride_ = stride if middle_dw_downsample else 1
self._middle_dw = conv_2d(expand_filters, expand_filters, kernel_size=middle_dw_kernel_size, stride=stride_,
groups=expand_filters)
# Projection with 1x1 convs.
self._proj_conv = conv_2d(expand_filters, oup, kernel_size=1, stride=1, act=False)
# Ending depthwise conv.
# this not used
# _end_dw_kernel_size = 0
# self._end_dw = conv_2d(oup, oup, kernel_size=_end_dw_kernel_size, stride=stride, groups=inp, act=False)
def forward(self, x):
if self.start_dw_kernel_size:
x = self._start_dw_(x)
# print("_start_dw_", x.shape)
x = self._expand_conv(x)
# print("_expand_conv", x.shape)
if self.middle_dw_kernel_size:
x = self._middle_dw(x)
# print("_middle_dw", x.shape)
x = self._proj_conv(x)
# print("_proj_conv", x.shape)
return x
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))
class C3_UIB(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(UniversalInvertedBottleneckBlock(c_, c_) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
if __name__ == '__main__':
x = torch.randn(1, 32, 16, 16)
model = C3_UIB(32, 32)
print(model(x).shape)四、添加教程
4.1 修改一
第一还是建立文件,我们找到如下ultralytics/nn文件夹下建立一个目录名字呢就是'Addmodules'文件夹(用群内的文件的话已经有了无需新建)!然后在其内部建立一个新的py文件将核心代码复制粘贴进去即可。

4.2 修改二
第二步我们在该目录下创建一个新的py文件名字为'__init__.py'(用群内的文件的话已经有了无需新建),然后在其内部导入我们的检测头如下图所示。
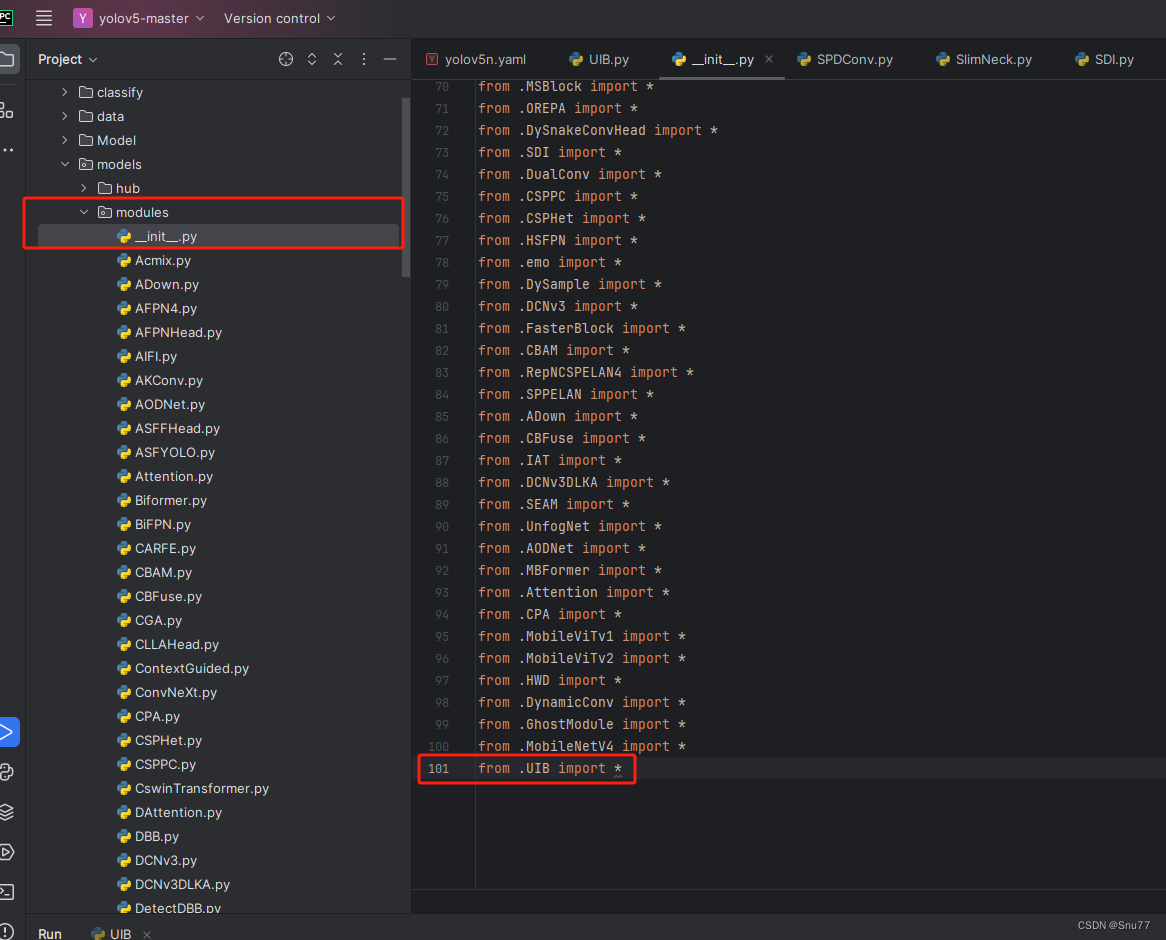
4.3 修改三
第三步我门中到如下文件'ultralytics/nn/tasks.py'进行导入和注册我们的模块(用群内的文件的话已经有了无需重新导入直接开始第四步即可)!
从今天开始以后的教程就都统一成这个样子了,因为我默认大家用了我群内的文件来进行修改!!
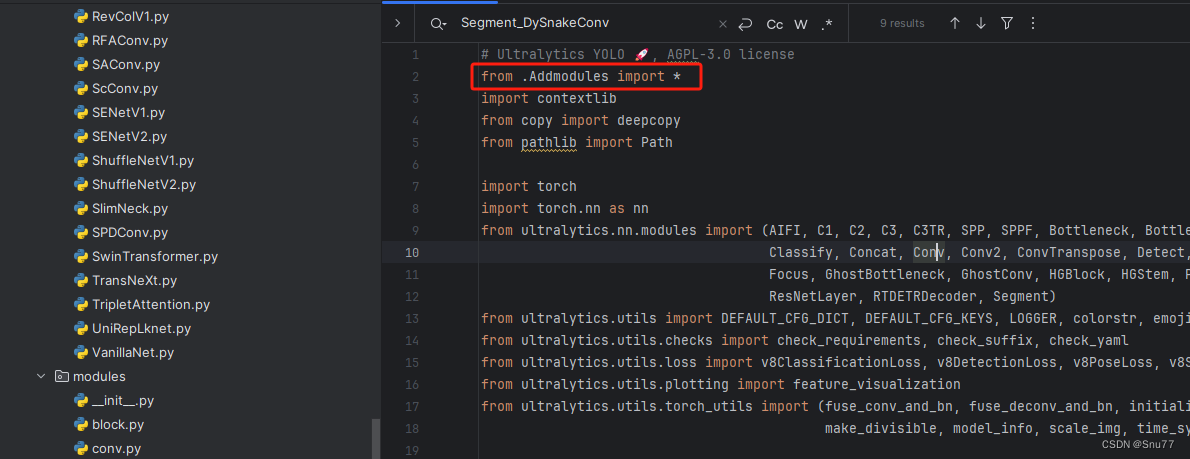
4.4 修改四
按照我的添加在parse_model里添加即可。

到此就修改完成了,大家可以复制下面的yaml文件运行。
五、C3UIB的yaml文件和运行记录
5.1 C3UIB的yaml文件1
主干和Neck全部用上该卷积轻量化到机制的yaml文件。
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3_UIB, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3_UIB, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3_UIB, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3_UIB, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head: [
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3_UIB, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3_UIB, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3_UIB, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3_UIB, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
5.3 C3UIB的训练过程截图
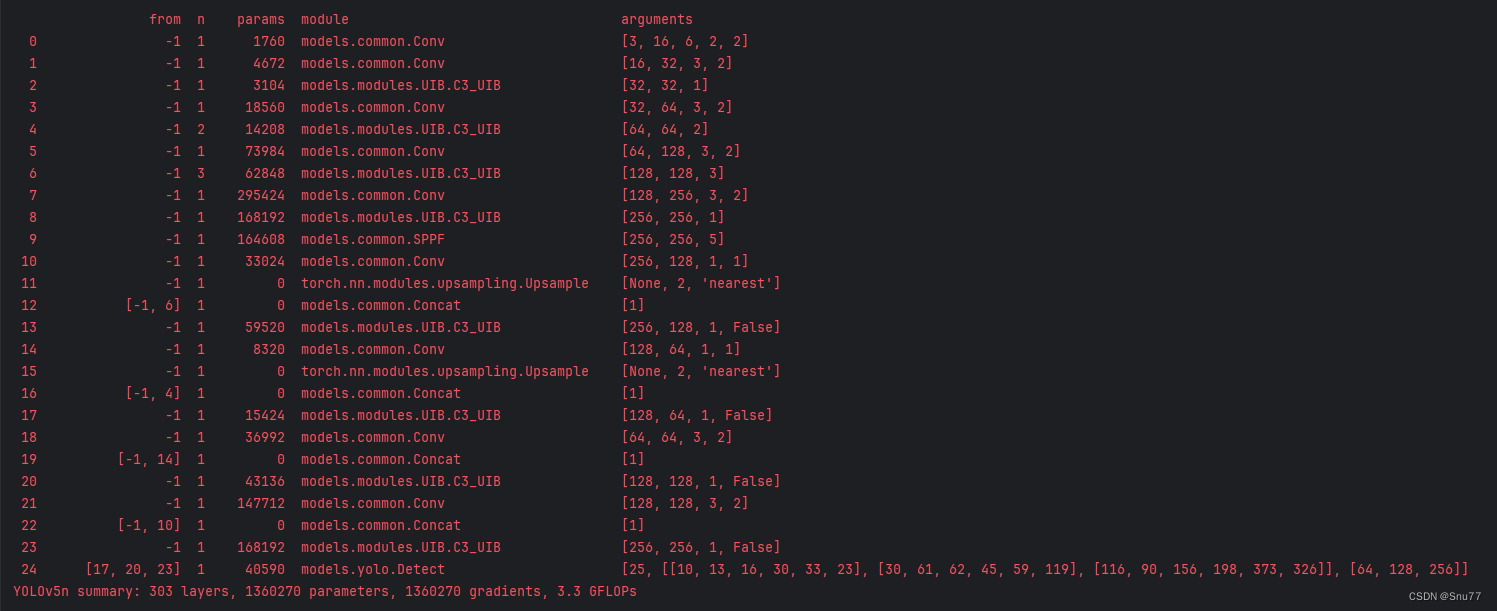
五、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏目录:YOLOv5改进有效涨点目录 | 包含卷积、主干、检测头、注意力机制、Neck上百种创新机制
专栏回顾:YOLOv5改进专栏——持续复现各种顶会内容——内含100+创新