前言
系列专栏:机器学习:高级应用与实践【项目实战100+】【2024】✨︎
在本专栏中不仅包含一些适合初学者的最新机器学习项目,每个项目都处理一组不同的问题,包括监督和无监督学习、分类、回归和聚类,而且涉及创建深度学习模型、处理非结构化数据以及指导复杂的模型,如卷积神经网络、门控循环单元、大型语言模型和强化学习模型
机器学习算法是一种通过训练模型对给定数据进行预测的方法。在预测卡路里消耗这个问题上,可以尝试使用以下几种机器学习算法:
-
线性回归:线性回归是一种基本的机器学习算法,用于建立连续变量和一个或多个自变量之间的线性关系模型。在预测卡路里消耗这个问题上,可以使用线性回归模型来建立卡路里消耗与其他相关变量(如运动时间、体重等)之间的线性关系。
-
岭回归:岭回归是一种回归算法,用于解决多重共线性问题。它通过对模型添加一个正则化项来降低参数的方差。在预测卡路里消耗这个问题上,岭回归可以用来减少参数的过拟合,提高预测的准确性。
-
xgboost回归:xgboost是一种集成学习算法,属于梯度提升树模型。它通过迭代地训练一系列的决策树模型,并将它们组合成一个强大的模型。在预测卡路里消耗这个问题上,xgboost回归可以用来处理非线性关系,提高预测的准确性。
-
Lasso回归:Lasso回归是一种基于L1正则化的线性回归算法,用于特征选择和参数稀疏化。在预测卡路里消耗这个问题上,Lasso回归可以用来筛选出对卡路里消耗影响较大的特征,提高模型的解释性和预测准确性。
-
随机森林回归:随机森林是一种集成学习算法,由多个决策树组成。它通过随机选择特征和样本进行训练,最终将多个决策树的预测结果进行平均或投票来得到最终结果。在预测卡路里消耗这个问题上,随机森林回归可以用来处理非线性关系和特征选择,提高预测的准确性。
目录
- 1. 相关库和数据集
- 1.1 相关库介绍
- 1.2 数据集介绍
- 1.2.1 加载数据
- 1.2.2 数据信息
- 1.2.3 数据描述
- 2. 探索性数据分析
- 2.1 特征相关性
- 2.2 正态分布检验
- 3. 构建机器学习模型
- 3.1 数据准备(拆分为训练集和测试集)
- 3.2 特征缩放
- 3.3 模型构建(LR、XGBoost、Lasso、RF、Ridge)
1. 相关库和数据集
1.1 相关库介绍
Python 库使我们能够非常轻松地处理数据并使用一行代码执行典型和复杂的任务。
Pandas– 该库有助于以 2D 数组格式加载数据框,并具有多种功能,可一次性执行分析任务。Numpy– Numpy 数组速度非常快,可以在很短的时间内执行大型计算。Matplotlib/Seaborn– 此库用于绘制可视化效果,用于展现数据之间的相互关系。Sklearn– 包含多个库,这些库具有预实现的功能,用于执行从数据预处理到模型开发和评估的任务。XGBoost– 这包含 eXtreme Gradient Boosting 机器学习算法,这是帮助我们实现高精度预测的算法之一。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn import metrics
from sklearn.svm import SVC
from xgboost import XGBRegressor
from sklearn.linear_model import LinearRegression, Lasso, Ridge
from sklearn.ensemble import RandomForestRegressor
import warnings
warnings.filterwarnings('ignore')
1.2 数据集介绍
1.2.1 加载数据
现在让我们将数据集加载到 pandas 的数据框中并打印其前五行。
df = pd.read_csv('calories.csv')
df.head()

现在让我们检查数据集的大小。
df.shape
(15000, 9)
1.2.2 数据信息
让我们检查数据集的哪一列包含哪种类型的数据。
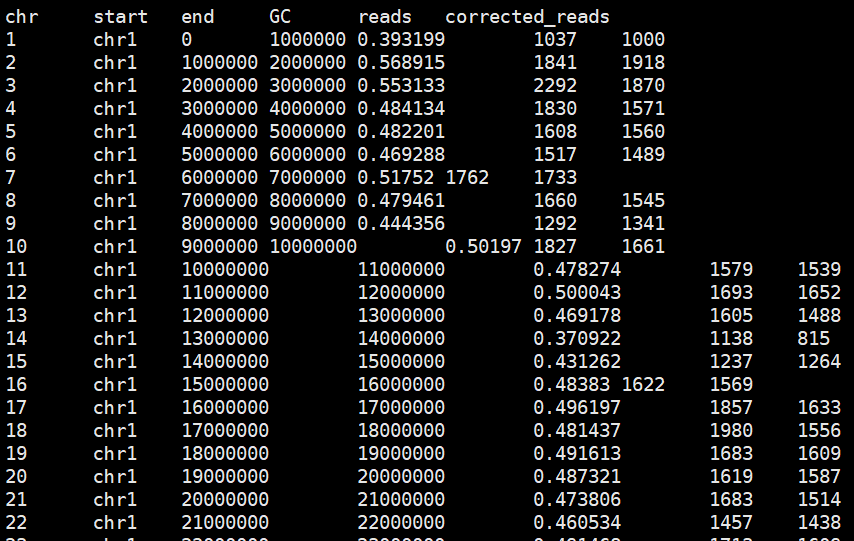
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 15000 entries, 0 to 14999
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 User_ID 15000 non-null int64
1 Gender 15000 non-null object
2 Age 15000 non-null int64
3 Height 15000 non-null int64
4 Weight 15000 non-null int64
5 Duration 15000 non-null int64
6 Heart_Rate 15000 non-null int64
7 Body_Temp 15000 non-null float64
8 Calories 15000 non-null int64
dtypes: float64(1), int64(7), object(1)
memory usage: 1.0+ MB
1.2.3 数据描述
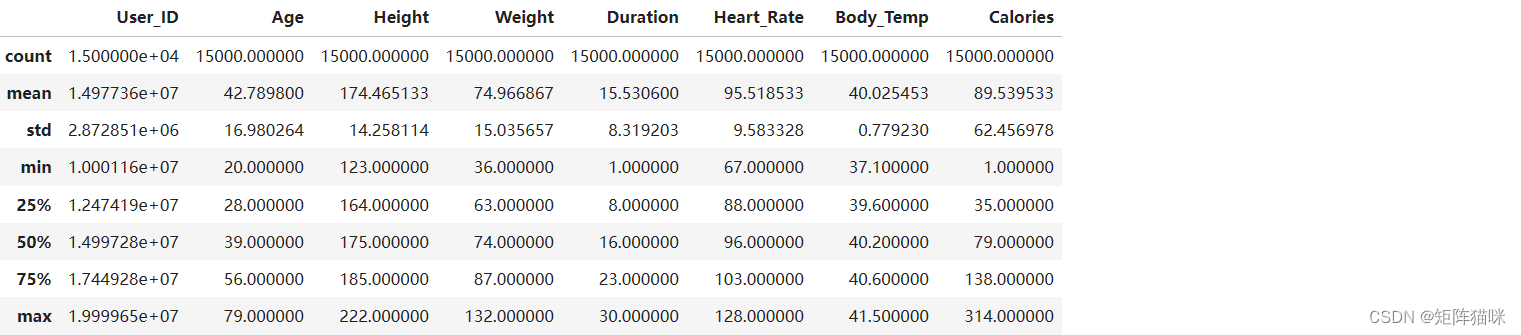
现在我们将检查数据的描述性统计度量。
# Describe `df`
df.describe()
2. 探索性数据分析
EDA是一种使用视觉技术分析数据的方法。它用于发现趋势和模式,或借助统计摘要和图形表示来检查假设。
sns.set()
sns.scatterplot(x= df['Height'], y= df['Weight'])
plt.show()

2.1 特征相关性
features = ['Age', 'Height', 'Weight', 'Duration']
plt.subplots(figsize=(15, 10))
for i, col in enumerate(features):
plt.subplot(2, 2, i + 1)
df_sample = df.sample(1000)
sns.scatterplot(x=df_sample[col], y=df_sample['Calories'])
plt.tight_layout()
plt.show()

正如预期的那样,锻炼时间越长,消耗的卡路里就越多。但除此之外,我们无法观察到卡路里消耗量与身高或体重特征之间的任何关系。
在这里,我们可以观察到一些现实生活中的现象:
- 男生的平均身高高于女生。
- 此外,女生的体重也低于男生。
- 同样的平均锻炼时间,男性消耗的卡路里高于女性。
2.2 正态分布检验
features = ['Age', 'Height', 'Weight', 'Duration', 'Heart_Rate', 'Body_Temp']
plt.subplots(figsize=(15, 10))
for i, col in enumerate(features):
plt.subplot(2, 3, i + 1)
sns.distplot(df[col])
plt.tight_layout()
plt.show()

除了一些特征,如体温和卡路里,连续特征的分布接近正态分布。
df.replace({'male': 0, 'female': 1},
inplace=True)
df.head()

plt.figure(figsize=(7, 6))
sns.heatmap(df.corr() > 0.9, annot=True, cbar=True, cmap='Purples')

这里存在一个严重的数据泄漏问题,因为有一个特征与目标列高度相关,而目标列是卡路里。
to_remove = ['Weight', 'Duration']
df.drop(to_remove, axis=1, inplace=True)
3. 构建机器学习模型
3.1 数据准备(拆分为训练集和测试集)
features = df.drop(['User_ID', 'Calories'], axis=1)
target = df['Calories'].values
X_train, X_val,\
Y_train, Y_val = train_test_split(features, target,
test_size=0.2,
random_state=22)
X_train.shape, X_val.shape
3.2 特征缩放
((12000, 5), (3000, 5))
现在,让我们对数据进行归一化处理,以获得稳定而快速的训练。
# Normalizing the features for stable and fast training.
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_val = scaler.transform(X_val)
3.3 模型构建(LR、XGBoost、Lasso、RF、Ridge)
现在,让我们来训练一些最先进的机器学习模型,比较一下哪种模型更适合我们的数据。
from sklearn.metrics import mean_absolute_error as mae
models = [LinearRegression(), XGBRegressor(),
Lasso(), RandomForestRegressor(), Ridge()]
for i in range(5):
models[i].fit(X_train, Y_train)
print(f'{models[i]} : ')
train_preds = models[i].predict(X_train)
print('Training Error : ', mae(Y_train, train_preds))
val_preds = models[i].predict(X_val)
print('Validation Error : ', mae(Y_val, val_preds))
print()
LinearRegression() :
Training Error : 17.947279968371927
Validation Error : 17.73761909957277
XGBRegressor(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, device=None, early_stopping_rounds=None,
enable_categorical=False, eval_metric=None, feature_types=None,
gamma=None, grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=None, max_bin=None,
max_cat_threshold=None, max_cat_to_onehot=None,
max_delta_step=None, max_depth=None, max_leaves=None,
min_child_weight=None, missing=nan, monotone_constraints=None,
multi_strategy=None, n_estimators=None, n_jobs=None,
num_parallel_tree=None, random_state=None, ...) :
Training Error : 7.674381575814138
Validation Error : 10.473695445229609
Lasso() :
Training Error : 17.971518133905626
Validation Error : 17.74093199010133
RandomForestRegressor() :
Training Error : 3.980961875
Validation Error : 10.59801680952381
Ridge() :
Training Error : 17.947362544638118
Validation Error : 17.737595699188827
在上述所有模型中,我们对 RandomForestRegressor 和 XGB 模型进行了训练,它们在验证数据上的 MAE 相同,性能也相同。