随着OpenAI引领的超大模型风潮,大模型的发展日新月异,如同雨后春笋般茁壮成长。在现今的科技舞台上,每周,甚至每一天,我们都能见证到一个全新模型的开源,这些模型的创新性和实用性不断超越前作,彰显出深度学习的无穷潜力。
更重要的是,随着技术的进步和方法的优化,大模型的微调训练成本也大大降低,使得更多的研究者和实践者有机会亲自体验和使用这些大型模型。就如同原本昂贵的奢侈品逐渐走入寻常百姓家,大模型也从曲高和寡的研究领域逐渐扩展到了更广泛、更接地气的应用场景。
1.2.1 大模型的分类
下面我们总结了目前大模型一些分类及其说明,如下所示:
- 主流大模型:GLM-130B、PaLM、BLOOM、Gopher、Chinchilla、LaMDA、CodeGeeX、CodeGen。
- 分布式训练:3D并行(包括张量并行、流水线并行、数据并行)、DeepSpeed、混合精度、Megatron-DeepSpeed。
- 微调:FLAN、LoRA、DeepSpeed。
- 应用:工具(包括Toolformer、ART)。
这种发展趋势不仅预示着大模型将在更多领域得到应用,更重要的是,它为人工智能技术的民主化铺平了道路,使得更多的人可以享受到深度学习带来的便利和乐趣。未来,我们可以期待大模型在医疗、教育、娱乐等各个领域发挥出更大的作用,为我们的生活带来更多的便利和惊喜。
可以看到,大模型的开源和微调训练成本的降低,是深度学习领域的一大进步,也是人工智能技术发展的重要里程碑。这不仅为我们提供了更多的工具和可能性,更为我们的未来描绘出了一幅充满希望和机遇的画卷。在这个新时代里,我们有理由期待大模型继续引领深度学习的发展潮流,为我们的生活和社会带来更多的正面影响。
1.2.2 大模型与普通模型的区别
从上一节我们了解到,大模型指网络规模巨大的深度学习模型,具体表现为模型的参数量规模较大,其规模通常在千亿级别。随着模型参数的提高,人们逐渐接受模型参数越大其性能越好的特点,但是,大模型与普通深度学习模型之间有什么区别呢。
简单地解释,可以把普通模型比喻为一个小盒子,它的容量是有限的,只能存储和处理有限数量的数据和信息。这些模型可以完成一些简单的任务,例如分类、预测和生成等,但是它们的能力受到了很大的限制。
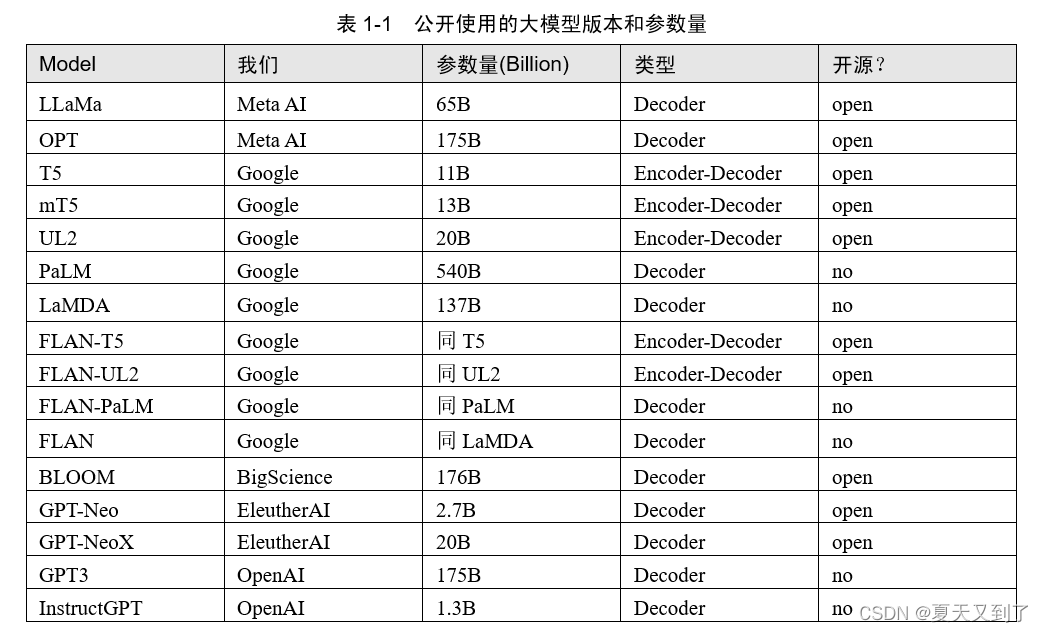
表1-1列出了目前可以公开使用的大模型版本和参数量(B的意思是英文Billion)。
相比之下,大模型就像一个超级大的仓库,它能够存储和处理大量的数据和信息。它不仅可以完成普通模型能完成的任务,还能够处理更加复杂和庞大的数据集。这些大模型通常由数十亿、甚至上百亿个参数组成,需要大量的计算资源和存储空间才能运行。这类似于人类大脑(约有1 000亿个神经元细胞),在庞大的运算单元支撑下,完成更加复杂和高级的思考和决策。
本文节选自《ChatGLM3大模型本地化部署、应用开发与微调》,获出版社和作者授权发布。







![[C++基础编程]----预处理指令简介、typedef关键字和#define预处理指令之间的区别](https://img-blog.csdnimg.cn/direct/608e8e0dc539444d836932fdcdf0f46f.png)