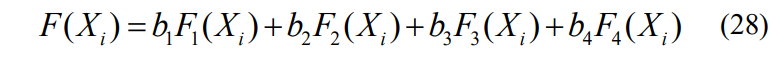文章目录
- 0. 前言
- 1. CelebA数据集
- 1.1 核心特性与规模
- 1.2 应用与用途
- 1.3 获取方式
- 1.4 数据预处理
- 2. DCGAN的模型构建
- 2.1 生成器模型
- 2.2 判别器模型
- 3. DCGAN的模型训练(重点)
- 3.1 训练参数
- 3.2 模型参数初始化
- 3.3 训练过程
- 4. 结果展示
- 4.1 loss值变化过程
- 4.2 生成图像演化过程
- 5. 完整代码
0. 前言
按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解及成果,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。
本文基于PyTorch构建DCGAN(深度卷积生成对抗网络,Deep Convolutional Generative Adversarial Network),并使用CelebA数据集进行训练,最终使用训练好的生成网络生成人脸数据(图像),完整代码附在文章末尾。
本文的重点是基于PyTorch代码讲解DCGAN模型的构建及训练过程,对于GAN的理论部分将直接跳过,如果对于GAN的基础理论以及转置卷积不太了解,强烈建议先读下以下2篇相关内容:
- 【硬核科普】一文读懂生成对抗网络GAN
- 【PyTorch单点知识】深入理解与应用转置卷积ConvTranspose2d模块
本文的写作思路及部分代码借鉴了《PyTorch教程:21个项目玩转PyTorch实战》(北京大学出版社),这真是一本非常不错的书!以及参考了DCGAN的论文 UNSUPERVISED REPRESENTATION LEARNINGWITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS(下面说明以“原文”代表)。
最终DCGAN的生成器通过逐渐学习人脸特征,生成人脸的过程如下:
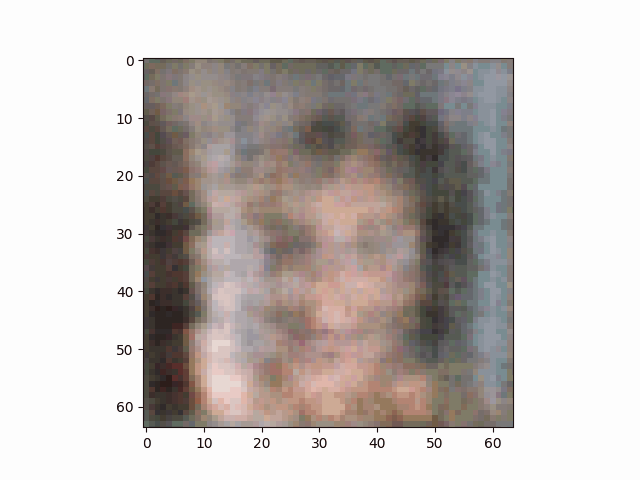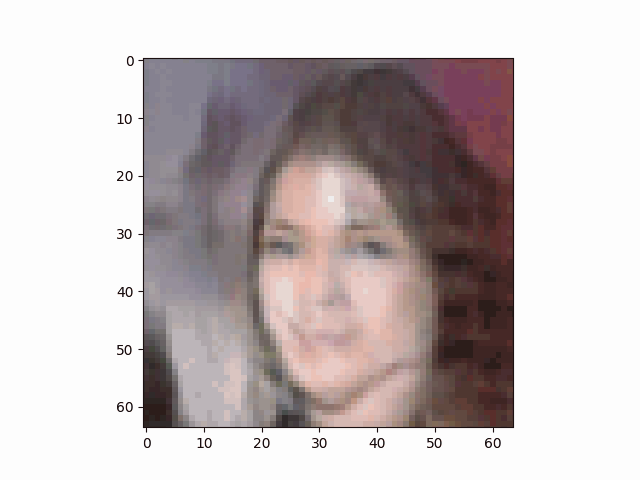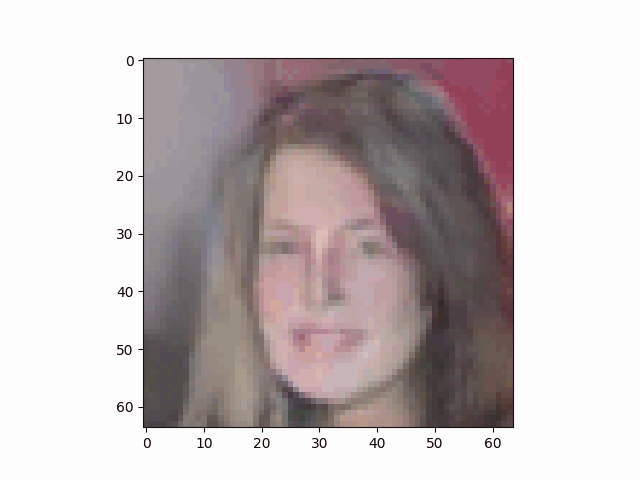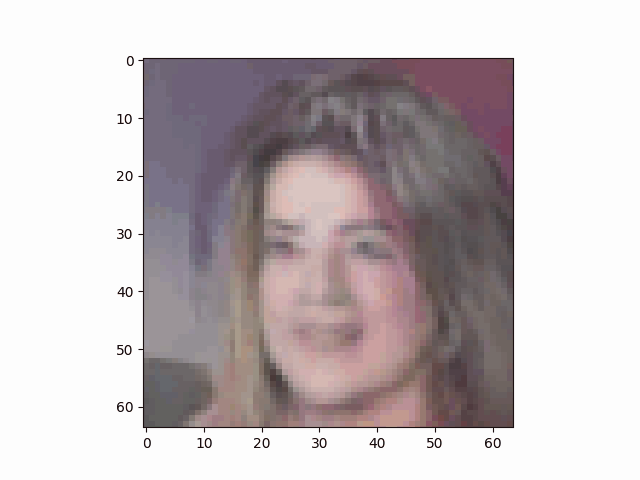
我怀着比较激动的心情在写此篇博客,因为2年前(2022)我就花费了较多时间(debug真的令人血压升高)写了一篇DCGAN相关的博客——基于Pytorch用GAN生成手写数字实例(附代码),但是结果不是特别理想:
在总结了相关经验后终于搞出了正文中的这个比较像样的结果。因为我是使用笔记本电脑(Nvidia RTX 4060 laptop)训练的网络模型,输出图像只能勉强调整到64×64大小。
虽然清晰度较差,但也能明显看出是一位金发美女。

1. CelebA数据集
CelebA 数据集(全称 Large-scale CelebFaces Attributes Dataset)是由香港中文大学多媒体实验室开发并公开提供的一个大规模名人面部属性数据集:

1.1 核心特性与规模
- 包含图片数量: CelebA 数据集包含了超过 202,599 张名人面部图像,对应约 10,177 个不同的名人个体。
- 多样性和复杂性: 数据集中的人脸图像具有丰富的姿态变化和复杂的背景环境,这为模型训练提供了极具挑战性的多样性和现实性,有助于提升模型在真实场景下的泛化能力。
- 属性标注(本文不会用到): 每张图片均附带了详尽的属性标注,共计 40 个不同的面部属性。
- 额外信息(本文不会用到): 除了属性标注外,CelebA 还提供了每张图片的人脸检测边界框(bounding box, bbox)、5个关键点(landmarks)的坐标位置,这对于进行精确的人脸对齐和定位等任务非常有用。
1.2 应用与用途
CelebA 数据集由于其规模大、标注详尽且具有多样性,被广泛应用于计算机视觉领域的各种研究和应用开发,主要包括:
- 人脸识别与属性识别: 用于训练模型识别和分类人脸图像中的特定属性,如性别、发型、表情等。
- 人脸合成与编辑(本文应用!): 作为训练数据,用于生成新的逼真人脸图像或修改现有图像的特定属性,如使用 GAN(如 DCGAN)进行人脸生成或风格迁移。
- 人脸检测与对齐: 利用提供的边界框和关键点信息训练或评估人脸检测和关键点定位算法。
- 深度学习模型验证与基准测试: 作为标准数据集,用于评估新提出的深度学习模型在人脸属性识别、生成或检测任务上的性能。
1.3 获取方式
CelebA 数据集可以从其官方网站直接下载,或者通过官方提供的百度网盘链接获取。由于数据集较大,下载可能需要一定时间。官方网址为:Large-scale CelebFaces Attributes (CelebA) Dataset
1.4 数据预处理
使用ImageFolder和DataLoader进行数据预处理:
dataset = torchvision.datasets.ImageFolder(root='Img', transform=transforms.Compose([
transforms.Resize(64),
transforms.CenterCrop(64),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]))
# print(len(dataset)) 输出202599,总计20万个图像
dataloader = torch.utils.data.DataLoader(dataset, batch_size=128, shuffle=True, num_workers=4, drop_last = True)
如果对预处理方式不太熟悉可以看下往期博客对于这些模块的介绍:ImageFolder、DataLoader、transforms。
2. DCGAN的模型构建
2.1 生成器模型
生成器是一个转置卷积神经网络,由CBR×4+CT串联而成,具体代码如下:
CBR = ConvTranspose+BatchNorm+ReLu
CT = ConvTranspose+Tanh
class Gnet(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.ConvTranspose2d(in_channels=noise_size, out_channels=64 * 8, kernel_size=4, stride=1, padding=0,
bias=False),
nn.BatchNorm2d(64 * 8),
nn.ReLU(),
# 输出特征图尺寸[64*8, 4, 4]
nn.ConvTranspose2d(in_channels=64 * 8, out_channels=64 * 4, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64 * 4),
nn.ReLU(),
# 输出特征图尺寸[64*4, 8, 8]
nn.ConvTranspose2d(in_channels=64 * 4, out_channels=64 * 2, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64 * 2),
nn.ReLU(),
# 输出特征图尺寸[64*2, 16, 16]
nn.ConvTranspose2d(in_channels=64 * 2, out_channels=64, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
# 输出特征图尺寸[64, 32, 32]
nn.ConvTranspose2d(in_channels=64, out_channels=3, kernel_size=4, stride=2, padding=1, bias=False),
nn.Tanh()
# 输出特征图尺寸[3, 64, 64]
)
def forward(self, x):
return self.net(x)
这里有个细节需要说明下:生成器网络模型最终的激活函数为
Tanh(),我原本认为这样并不好,因为Tanh()的取值范围为[-1, 1],这样会导致输出有负数。而负数是无法作为像素值绘图的(因为plt模块接受的像素范围为整数[0, 255]或浮点数[0, 1]),负数的像素值在绘图时会被舍弃。
但是当我尝试把最终的激活函数改为Sigmoid(),训练模型过程中奇怪的现象出现了:生成器和判别器的loss很快收敛为0。这是错误的现象,因为在前文GAN的理论中介绍过:当达到纳什均衡时,判别器的理论输出应该是0.5。判别器的loss必定是一个波动值,不会收敛到0。
对于仅更改最后的激活函数就造成这个现象的机理我还是没太想明白……
2.2 判别器模型
判别器是一个卷积神经元网络,由CL+CBL×3+CS模块构成,具体代码如下:
CL = Conv+LeakyReLu
CBL = Conv+BatchNorm+LeakyReLu
CS = Conv+Sigmoid
class Dnet(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=4, stride=2, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64 * 2, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64 * 2),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64 * 2, out_channels=64 * 4, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64 * 4),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64 * 4, out_channels=64 * 8, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64 * 8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64 * 8, out_channels=1, kernel_size=4, stride=1, padding=0, bias=False),
nn.Sigmoid()
)
def forward(self, x):
return self.net(x)
3. DCGAN的模型训练(重点)
3.1 训练参数
- 损失函数:选用BCE(Binary Cross-Entropy,二元交叉熵);
loss = nn.BCELoss()
- 优化器:生成器和判别器均选用Adams;
opt_G = torch.optim.Adam(G_NET.parameters(), lr=0.0002, betas=(0.5, 0.999)) # 在Adam优化器中,beta1 和 beta2 是两个关键的超参数,分别用于控制梯度一阶动量和二阶动量的衰减速度,进而影响优化器对模型参数的更新方式。
opt_D = torch.optim.Adam(D_NET.parameters(), lr=0.0002, betas=(0.5, 0.999))
- 迭代次数:epoch设定为20,iteration=202599/128,取整后为1582。
3.2 模型参数初始化
这是非常关键的一步!DCGAN的论文建议需要把权重初始化为均值为0,标准差为0.02。
原文如下:

代码实现方式为:
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
print("init:%s"%classname)
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
print("init:%s"%classname)
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
这里的.apply()函数是PyTorch中的nn.Module类提供的一个方法,用于递归地将指定函数应用到模块及其所有子模块的所有参数或缓冲区上,确保模型在训练开始前具有合理的初始权重分布,有助于模型的收敛和性能表现。
3.3 训练过程
首先需要设定真标签和假标签:
true_label = torch.ones(128).to(device) #128为batch_size
false_label = torch.zeros(128).to(device)
DCGAN的训练过程即是生成器和判别器的交替训练过程:
-
判别器训练:
- 从真实数据集中抽取一批真实样本。
- 生成器G生成一批假样本,使用同样的批次大小,输入为采样的随机噪声。
- 将真实样本和生成的假样本混合,组成一个批次的训练数据,并附上对应的标签(真实样本为“真”,生成样本为“假”)。损失值为: l o s s D = B C E ( D ( x d a t a ) , true-label ) + B C E ( D ( G ( z ) ) , false-label ) loss_D = BCE(D(x_{data}), \text{true-label})+ BCE(D(G(z)), \text{false-label}) lossD=BCE(D(xdata),true-label)+BCE(D(G(z)),false-label) , x d a t a x_{data} xdata为真实样本, z z z为符合某种分布的随机向量。
- 利用这些数据和标签训练判别器D,目标是最大限度地提高D正确区分真实数据和假数据的能力。
-
生成器训练:
- 冻结判别器D的参数,使其在本阶段不更新。
- 从噪声分布中再次采样一批新的随机向量作为G的输入。
- 生成器G根据这些输入生成假样本,并将它们传递给判别器D。
- 此时,G试图欺骗D,即让D认为这些生成的样本是真实的。为此,G的训练目标是最大化D对这些假样本判断为“真”的概率。通常,这等同于最小化D给出的“假”概率,即D的输出值。训练过程中可能使用负的D的输出(或相应的损失函数)作为G的损失来更新G的权重。损失值为: l o s s G = B C E ( D ( G ( z ) ) , true-label ) loss_G = BCE(D(G(z)), \text{true-label}) lossG=BCE(D(G(z)),true-label)。
注意:判别器的训练是每隔k步才进行一次的,因为相比于生成器,判别器更容易训练。
4. 结果展示
4.1 loss值变化过程
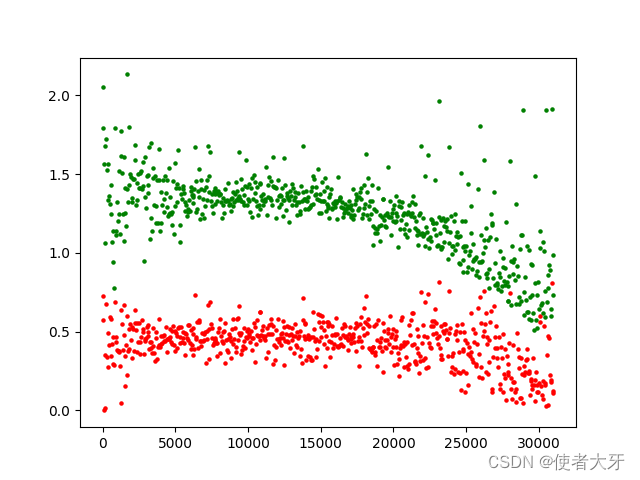
其中红色为生成器的loss,绿色为判别器的loss,横坐标为迭代次数iteration。
4.2 生成图像演化过程
我们可以把0~19个epoch的训练权重结果都保存下来:
随机选取一个batch的4个图像观察生成器从epoch0到epoch20生成图像的演化过程:
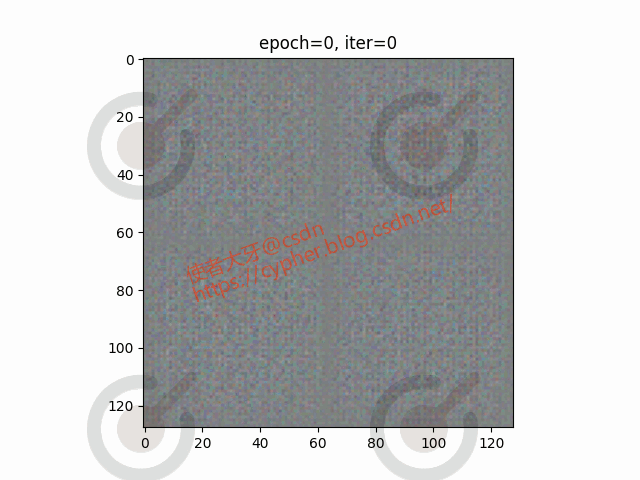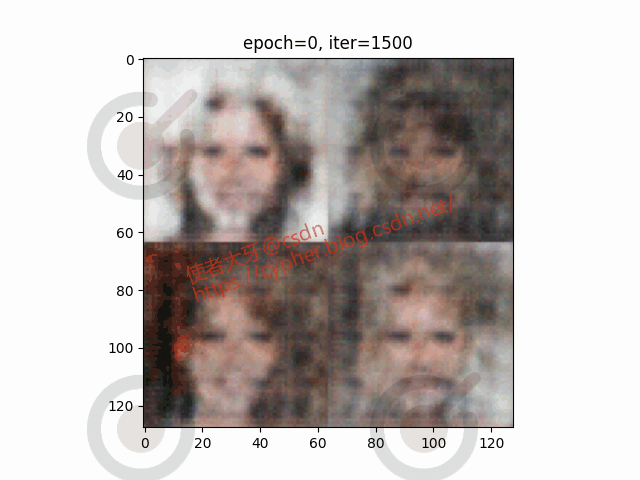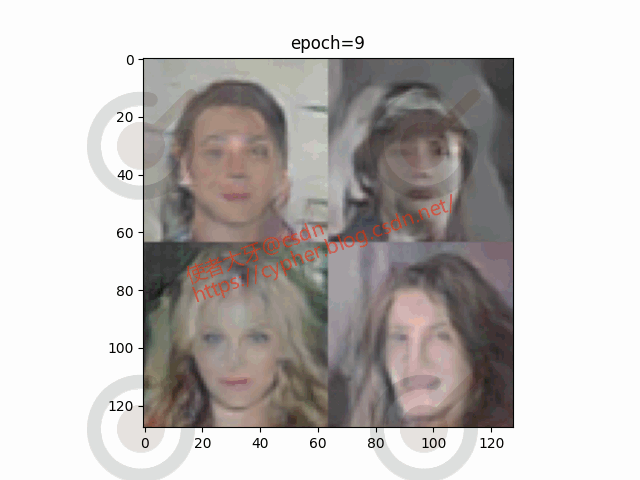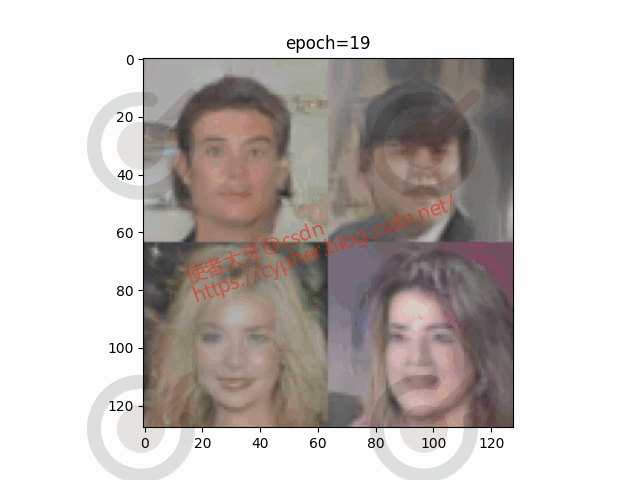
5. 完整代码
- 训练部分:
文件名:
DCGAN_main_revise1,后面验证部分会用到。
import torch
import torchvision
import torch.nn as nn
from torchvision import transforms
import random
from tqdm import tqdm
import matplotlib.pyplot as plt
random.seed(666) #设定随机种子
torch.manual_seed(666)
dataset = torchvision.datasets.ImageFolder(root='Img', transform=transforms.Compose([
transforms.Resize(64),
transforms.CenterCrop(64),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]))
# print(len(dataset)) 输出202599,总计20万个图像
dataloader = torch.utils.data.DataLoader(dataset, batch_size=128, shuffle=True, num_workers=4, drop_last = True)
noise_size = 100
class Gnet(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.ConvTranspose2d(in_channels=noise_size, out_channels=64 * 8, kernel_size=4, stride=1, padding=0,
bias=False),
nn.BatchNorm2d(64 * 8),
nn.ReLU(),
nn.ConvTranspose2d(in_channels=64 * 8, out_channels=64 * 4, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64 * 4),
nn.ReLU(),
nn.ConvTranspose2d(in_channels=64 * 4, out_channels=64 * 2, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64 * 2),
nn.ReLU(),
nn.ConvTranspose2d(in_channels=64 * 2, out_channels=64, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.ConvTranspose2d(in_channels=64, out_channels=3, kernel_size=4, stride=2, padding=1, bias=False),
nn.Tanh()
)
def forward(self, x):
return self.net(x)
class Dnet(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=4, stride=2, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64 * 2, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64 * 2),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64 * 2, out_channels=64 * 4, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64 * 4),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64 * 4, out_channels=64 * 8, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64 * 8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64 * 8, out_channels=1, kernel_size=4, stride=1, padding=0, bias=False),
nn.Sigmoid()
)
def forward(self, x):
return self.net(x)
loss = nn.BCELoss()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
G_NET = Gnet().to(device)
D_NET = Dnet().to(device)
opt_G = torch.optim.Adam(G_NET.parameters(), lr=0.0002, betas=(0.5, 0.999)) # 在Adam优化器中,beta1 和 beta2 是两个关键的超参数,分别用于控制梯度一阶动量和二阶动量的衰减速度,进而影响优化器对模型参数的更新方式。
opt_D = torch.optim.Adam(D_NET.parameters(), lr=0.0002, betas=(0.5, 0.999))
true_label = torch.ones(128).to(device)
false_label = torch.zeros(128).to(device)
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
print("init:%s"%classname)
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
print("init:%s"%classname)
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
if __name__ == '__main__':
G_NET.apply(weights_init) # 进行权重初始化
D_NET.apply(weights_init)
epoch = 20
for e in tqdm(range(epoch)):
for i, (image, label) in enumerate(dataloader): # image的维度为torch.Size([128, 3, 64, 64])
G_NET.zero_grad()
noise = torch.randn(128, noise_size, 1, 1, device=device) # 产生正态分布的噪声
fake = G_NET(noise) # 使用生成器产生假数据
output = D_NET(fake).view(-1)
loss_G = loss(output,true_label)
loss_G.backward()
loss_G_mean = output.mean().item()
opt_G.step()
if i%2 == 0:
D_NET.zero_grad() #梯度清0
real_image = image.to(device)
output_real = D_NET(real_image).view(-1)
loss_D_real = loss(output_real, true_label) # 计算真实数据的损失
output_fake = D_NET(fake.detach()).view(-1) # 使用判别器,此时将它们标记为假数据
loss_D_fake = loss(output_fake, false_label)
loss_D = loss_D_real + loss_D_fake
loss_D_mean = loss_D.mean().item()
loss_D.backward()
opt_D.step()
# 输出训练状态
if i % 50 == 0:
print("epoch:%i/[%i] iter:%i/[1550]"%(e,epoch,i),'|',"loss_D:%f"%loss_D_mean,'|',"loss_G:%f"%loss_G_mean)
iter = e*1550+i
plt.scatter(iter,loss_G_mean, c='r',s = 5)
plt.scatter(iter,loss_D_mean, c = 'g',s = 5)
torch.save(obj=G_NET.state_dict(),f='weight/G_Net_parameter_%i_epoch.pth'%e)
torch.save(obj=D_NET.state_dict(), f='weight/D_Net_parameter_%i_epoch.pth' % e)
plt.show()
- 验证部分:
from DCGAN_main_revise1 import Gnet
import torch
import matplotlib.pyplot as plt
import random
random.seed(888) #设定随机种子
torch.manual_seed(888)
Gnet_test = Gnet()
noise = torch.randn(128, 100, 1, 1)
for i in range(20):
Gnet_test.load_state_dict(torch.load('weight/G_Net_parameter_%i_epoch.pth'%i))
output = Gnet_test(noise)
output = output.detach()
concate1 = torch.concat((output[0].permute(1,2,0),output[2].permute(1,2,0)),dim=1)
concate2 = torch.concat((output[7].permute(1, 2, 0), output[6].permute(1, 2, 0)), dim=1)
concate3 = torch.concat((concate1, concate2), dim=0)
plt.imshow(concate3)
plt.savefig('output_images/composed_%i'%i)
以上,终于写完了~

![[C++基础编程]----预处理指令简介、typedef关键字和#define预处理指令之间的区别](https://img-blog.csdnimg.cn/direct/608e8e0dc539444d836932fdcdf0f46f.png)