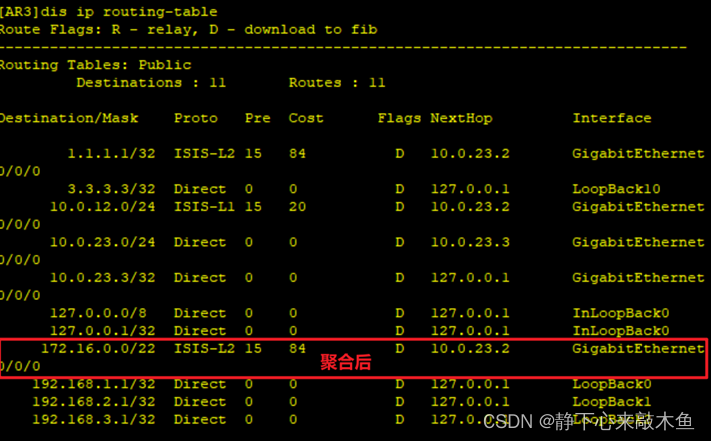
linux实时应用printf输出
文章目录
- linux实时应用printf输出
- 1. 前言
- 2. linux终端输出
- 3. 常见的NRT IO输出方案
- 3.1 一种实现方式
- 3.3 改进
- 3. Xenomai3 printf()接口
- 3.1 应用运行前环境初始化
- 1. GCC特定语法
- 2. libcobalt printf初始化流程
- 3.2 libcobalt printf内存管理
- 1. print_buffer
- 2. entry_head
- 3. printf pool
- 3.2 libcobalt printf工作流程
- 4. 总结
本文介绍为什么linux实时任务不能直接调用
printf(),首先简单介绍一下终端输出原理,然后如何实现终端输出不影响实时任务实时性给出一个方案,最后介绍xenomai中是如何做到优雅的
printf()。
1. 前言
开始前,回顾下实时(Real-Time):
实时的本质是确定性、可预期性。即实时系统是必须在设置的截止时间内对特定环境中的事件做出反应的系统,不仅依赖于计算结果的正确性,还依赖于计算结果的 返回时间。实时任务运行过程中,不论软件硬件,一切造成时间不确定的因素都是实时性的影响因素。

我们在linux上开发普通应用程序时,最常用的调试手段是gdb单步、终端打印。除调试外,一般应用程序运行过程中或多或少都会输出一些应用运行信息、错误信息、警告信息等,这些信息格式化后可能会输出到终端、syslog、记录到文件等(本文仅介绍终端打印操作,其他的类似)。
但如果我们开发的是实时应用程序,还能一样吗?硬实时应用开发调试,部分情况下可以使用gdb跟踪调试,但在一些涉及时间敏感的业务调试时,程序不能停下来,这时好的调试方式只有打印。非调试时也需要打印输出和纪录一些应用信息,总之我们要在实时路径上打印信息,就需要考虑打印这个操作的实时性,即打印操作耗时必须是确定的,同时耗时不能影响实时应用结果输出的deadline。
这个问题的本质是:实时任务该如何进行非实时IO 操作?
(1) 任务具有高优先级,不代表该任务所有IO操作实时 。
(2) 部分IO操作可能会带来严重的不确定性,如实时任务中通过标准输入输出打印、读写文件等。
那glibc中printf()操作是实时的吗?为什么?
2. linux终端输出
在linux中,glibc提供了标准IO接口(printf、fwrite(stdout)…),其底层通过读写linux内核tty设备进行IO输入输出,终端输出简单流程如下所示。

应用程序终端打印可以直接通过系统调用write()输出,这样的话我们要处理更多的底层细节,比如指定文件描述符,要区分向终端打印字符还是写入到文件。为屏蔽底层操作细节,C标准库提供了统一和通用的IO接口,让我们不必关注底层操作系统相关细节,做到一次编码到处编译。
但是,系统调用的过程涉及到进程在用户模式与内核模式之间的转换,过多的系统调用和上下文切换,会将原本运行应用的CPU时间,消耗在寄存器、内核栈以及虚拟内存数据保护和恢复上,缩短应用程序真正运行的时间,其成本较高。为了提升 IO 操作的性能,同时保证开发者所指定的 IO 操作不会在程序运行时产生可观测的差异,标准 IO 接口在实现时通过添加缓冲区的方式,尽可能减少了低级 IO 接口的调用次数。使用标准 IO 接口实现的程序,会在用户输入的内容达到一定数量或程序退出前,再更新文件中的内容。而在此之前,这些内容将会被存放到缓冲区中。
通过系统调用进入系统后,数据经过TTY 核心、线路规程、tty驱动最终到达硬件外设,如果终端是串口的话,由UART driver操作串口外设发送,如果终端是VGA显示器或xtrem虚拟终端,则通过对应的路径进行输出。
综上printf()由linux C标准库提供,其执行时间的长短取决于用户态glibc缓冲方式、内存分配,内核态TTY driver、UART driver的具体实现(全路径是否实时)等。所以glibc提供的标准IO并不是个实时的接口(低端arm平台,实测glibc缓冲后输出到波特率为115200的串口终端,执行需要330ms左右,如果在实时上下文使用,对实时应用来说这就是灾难)。
虽然PREEMPT-RT通过修改Linux内核使linux内核提供硬实时能力,但整个路径不仅仅只有内核,还涉及内核中的各种子系统,还有硬件驱动,应用层的标准库glibc等,存在很多非实时的行为,没有明确说明哪些是执行时间确定的,哪些是不确定的,只能遇到问题解决问题。

3. 常见的NRT IO输出方案
实时应用中,对于此类问题,一般将非实时的IO操作交给非实时任务来处理,实时任务与非实时IO操作任务之间通过实时进程间通信IPC(共享内存、消息队列…)交互,如下所示。

3.1 一种实现方式
根据上图,我们容易实现如下可在实时上下文调用的打印输出接口。

实时与非实时任务使用消息队列通信,创建的消息队列大小固定,实时方通过非阻塞的方式发送消息,非实时方阻塞接收消息。
rt_printf()接口每次调用先分配一片内存msg,然后将要打印的内容通过sprintf()格式化到该内存中,接着将内存首地址通过非阻塞方式放到消息队列,待高优先级的任务让出CPU,低优先级的任务printf_task得到运行后,从消息队列取出消息,最后通过printf()进行输出,输出完成后将内存释放。
该实现方式有没有问题?这个rt_printf接口并不是实时的,我们在一个PREMPT-RT的生产环境中就是这样实现的,在实时应用中应用时发现有很大问题。
你可能觉得不实时是因为不能在实时上下文使用glibc提供的malloc()来动态分配内存,这里malloc()是原因之一,这是显而易见的问题。我们在排查问题时,也一度以为抖动是malloc或实时应用其他业务部分产生的。但经过排查,发现一些过大的抖动产生时与内存分配并没有关系,并且抖动比malloc()分配内存产生的pagefult抖动还大,能达到几百ms,这明显不正常。
这里简单吐槽一下,linux虽然有很多debug和training的工具,如gdb、ftrace、tracepoint、bpf、strace、…,但这些都是会严重影响实时任务的运行实时序,在debug一个实时应用的问题时,由于这些工具的干预,要么问题不复现,要么整个系统卡死等等,特别是在一些资源受限的小型嵌入式linux系统上,很难排查系统或应用实时性问题,共性问题最好在x86上调试。
笔者这里要给大家介绍该实现里我们遇到的坑,从应用角度来看格式化字符串接口sprintf()与打印输出接口printf()是两种行为,他们之间没有什么直接联系。但通过调试发现,在glibc的实现中它们底层共用一个函数,存在锁互斥,就会导致低优先级任务的printf()持有锁刷新缓冲区,前面说到刷新缓冲区的时间可长达300ms,这时候搞优先级任务只能阻塞等待锁释放,影响高优先级实时性。


这里想说的是,用户态的glibc诞生之初就是针对高吞吐量设计的,而非实时性。此外虽然PREEMPT-RT在内核调度层面保证了linux的实时性,但内核中仍有许多机制和子系统、driver是非实时的,最严重的是driver,目前linux内核代码量三千多万行,其中85%以上为bsp驱动,这些驱动来自全球无数开发者和芯片厂商,这些驱动编写之初就不是为实时应用而设计,这只是upstream的代码,代码质量比较优秀,问题相对好查找,但还有未上游化的驱动,那才是痛苦的根源。
由于ARM IP核授权方式,各个芯片厂商不同芯片外设各式各样,这些外设驱动代码并没有上游化,只存在于芯片厂商提供的SDK中,如果厂商没有明确支持PREEMPT-RT,那使用到的实时外设对应的实时驱动基本得debug一遍,特别是一些国产ARM芯片需要注意。
总之我们在开发实时应用时,全路径都需要注意,分清楚哪些实时的哪些是非实时的,这也是为什么xenomai用户库、调度核、中断、驱动到底层硬件全路径实时。
3.3 改进
如何解决这个问题?printf()的作用是输出到终端,所有直接使用fwrite写终端stdout替换即可解决。

需要注意,fwrite需要知道写的数据长度,所以通过消息队列发送给实时任务的就不仅仅是个内存地址了,我们可以为每个输出流添加如下头,申请内存附加这个头,这里就不过多叙述了。
struct out_head {
size_t len; /*数据长度*/
char data[0]; /*格式化后的数据*/
};
到此,只要不是在实时上下文频繁调用,一个基本满足实时应用调试的rt_printf()接口就完成了,如果我们要实现一个完美的rt_printf()接口,那它还有什么不足:
- 存在动态内存分配,导致不确定性增加。
- IPC方式效率过低,消息队列需要内核频繁参与。
- 共用一个消息队列、malloc内存分配,多线程同时调用时这些会成为瓶颈(消息队列在内核中也存在锁),相互影响实时性。
- 消息队列的大小有限,若某个实时线程突发大量信息打印时,可能导致消息队列耗尽,其他实时任务的消息无法输出到终端,造成打印信息丢失。
- 原实时应用源代码需要修改,应用中所有
printf()接口都要修改为rt_printf(),导致应用代码可移植性,可维护性差。 - 使用需要添加初始化代码相关,如消息队列创建、非实时线程创建等。
3. Xenomai3 printf()接口
xenomai3于2015年正式发布,在xenomai3之前的xenomai2,实时应用程序打印需要调用特定的接口rt_printf(),从xenomai3开始实时应用无需修改printf(),只有正确编译链接**实时应用POSIX接口库libcobalt**就可实现实时上下文调用printf()不影响实时性。
需要说明的是:xenomai3支持两种方式构建linux实时系统,分别是cobalt 和 mercury详见【原创】xenomai内核解析之xenomai初探,mercury构建时,printf接口仍是非实时的。
实时应用POSIX接口库libcobalt提供的printf(),完全解决了上节中的不足:
- 应用无需调用额外初始化,编译链接即可使用
- 预先分配打印内存池,无需每次通过glibc动态申请
- IPC使用共享内存,freelock(无锁)
- 引入线程特有数据,多线程安全,临界区无需锁保护
- 无缝连接,应用代码无需修改标准IO接口
以下内容仅做概要,不对源码逐行分析,若有兴趣可自行阅读libcobalt源码。
3.1 应用运行前环境初始化
用户无需调用代码初始化,那只能在应用代码执行前将环境printf相关准备好,如何做?回想我们使用C语言开发裸机程序时,我们通常认为CPU是从main()函数开始执行的,但实际上裸机开发时需要先用汇编为C程序执行准备环境,然后再调用main()开始执行,这种情况下我们可以在main()执行前做一些额外操作。
回到我们linux环境,这时我们要在main()之前做一些操作,又该如何实现?到这熟悉C++的同学应该会联想到C++中全局对象,它们在main()之前就调用构造函数完成全局对象的创建了,而且main()结束后,程序即将结束前其析构函数也会被执行。
1. GCC特定语法
在GCC中,可以通过GCC提供的两个GCC特定语法实现:
- __attribute__((constructor)) 当与一个函数一起使用时,则该函数将会在main()函数之前。
- __attribute__((destructor)) 当与一个函数一起使用时,则该函数将会在main()函数之后执行。
它们的工作原理为:共享文件 (.so) 或者可执行文件包含特殊的部分(ELF上的.ctors Section和.dtors Section,可用通过readelf -S查看Section信息),GCC编译时会将标有构造函数和析构函数属性的函数符号放到这两个Section中,当库被加载/卸载时,动态加载器程序检查这些部分是否存在,如果存在,则调用其中引用的函数。
关于这些,有几点是值得注意的。
a. 当一个共享库被加载时,__attribute__((constructor))运行,通常是在程序启动时。
b. 当共享库被卸载时,__attribute__((destructor))运行,通常在程序退出时。
c. 两个小括号大概是为了区分它们与函数调用。
d. __attribute__是GCC特有的语法;不是一个函数或宏。
使用destructor和constructor的好处是,如果我们有很多模块,原来的方式是每个模块内的初始化都需要去调用一遍,删除某一个模块就需要删除相应的初始化代码,然后重新编译。有了destructor和constructor,我们就可以为每一个模块设置对应的constructor,应用程序使用时就不需要统一写代码一个模块一个模块进行初始化,只需要编译链接需要对应的模块即可,爽歪歪。
xenomai 实时库libcobalt利用该特性在实时应用程序前执行了大量初始化,如如Alchemy API、VxWorks® emulator、pSOS® emulator 等 API环境的初始化,这样我们才能无缝使用libcobalt提供的服务。
这样的应用很多,比如DPDK中,我们需要支持什么网卡驱动直接选中编译链接即可,业务代码还未执行,就已经完成所有网卡驱动注册了,应用程序后续执行扫描硬件,匹配直接执行对应驱动进行probe。

2. libcobalt printf初始化流程

3.2 libcobalt printf内存管理
1. print_buffer
实时线程与负责打印输出的非实时线程通过一片共享内存来实现IPC,该内存为环形队列,print_buffer是管理这片内存的结构,与环形队列缓冲区一一对应,其维护着环形队列生产者与消费者的位置,print_buffer每个线程一个。

2. entry_head
entry_head用来抽象每条消息,从缓冲队列中分配,包含消息长度,序号,目的(stdio、syslog)等信息。
3. printf pool
cobalt_print_init初始化过程中,预先分配打印内存池pool,分配成N份,其分配信息通过bitmap来记录,无需每次通过glibc动态申请,当实时线程第一次调用printf()接口时,查询bitmap未分配的print_buffer,取出设置为该线程的特有数据,并将其添加到全局链表first_buffer。

注:线程特有数据(TSD)是解决多线程临界区需要保护,影响多线程并发性能的一种方式。更多详见《Linux/UNIX系统编程手册 第31章 线程:线程安全与每线程存储》
3.2 libcobalt printf工作流程
实时线程
-
每个实时线程打印时,先从pool中分配printf buffer
-
成功分配后,将分配的buffer设置为线程特有存储数据
pthread_setspecific(buffer_key, buffer),此后该线程只操作这个buffer; -
若线程过多,预先分配的pool已无法分配,使用
malloc增加一个printf buffer,放到全局队first_buffer里,并设置为该线程特有存储数据,供后续每次打印输出使用。 -
将打印消息格式化到buffer的数据区
非实时线程
以一定周期从first_buffer遍历链表,处理每一个buffer中的entry_head,按顺序取出entry_head,按照entry_head指定目的进行IO输出。


到此上个实现中的不足全部解决,其中关于xenomai如何实现"无缝衔接,应用代码无需修改编译链接即可使用",这个已在之前的文章中解析,详见【原创】xenomai内核解析–双核系统调用(二)–应用如何区分xenomai/linux系统调用或服务 。
4. 总结
以上就是一个实时linux下开发实时应用程序,由一个普普通通的printf()引发的实时性能问题解决,可以看出要做好远比我们想象的复杂,做底层就是这样,得坐冷板凳耐得住寂寞。几句话共勉:
“万丈高楼平地起,勿在浮沙筑高台”;
“或许做上层业务能快速出活,快速看到其价值,自然不用了解其内部的实现和对底层的依赖,美其名日“站在巨人的肩膀上”。效率提升了,但同时也导致我们对巨人的成长过程不闻不问。殊不知巨人倒下之后,我们将无所适从,就算巨人只是生个病(发生漏洞)带来的损失也不可估量”。
更多xenomai原理见本博客其他文章,关于更多PREEMPT-RT的原理和坑敬请关注本博客。