1. tr 命令——替换、压缩、删除
tr (Text Replacer) 命令常用来对来自标准输入的字符进行替换、压缩和删除。
命令格式 :tr [选项]... SET1 [SET2]
(SET 是一组字符串,一般都可按照字面含义理解)
选项:
-d 删除
-s 压缩
tr 1 a //遇到1换成
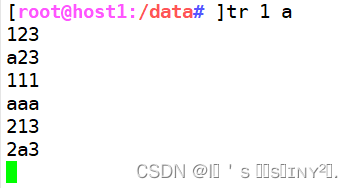
tr -d 1 //把1删除

tr -s 1 //压缩连续的1
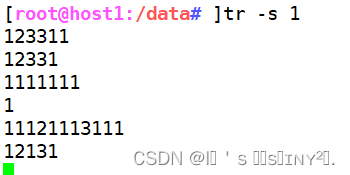
tr -s " "//压缩连续的空格

tr '[a-z]''[A-Z]' //将所有小写字母替换为大写

`cat file | tr [选项] 参数`
生成随机密码:
cat /dev/urandom |tr -dc '[:alnum:]'|head -c12
2. cut命令——切列
cut 命令可以提取文本文件数据的指定列。
命令格式 : cut [选项]... [文件]...
选项:
-d 指明分隔符
-f 想要获取的字段
#: 第#个字段,例如 3
#,#[,#]:离散的多个字段,例如 1,3,6
#-#:连续的多个字段, 例如 1-6
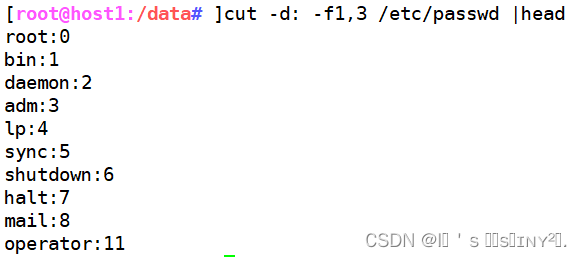
cut -d: -f1,3/etc/passwd |head //以冒号作为分隔的条件,取文件的第1列和第3列
`cat file | cut [选项] 参数`
注意!不能将连续的字符当作分隔符
df文件系统
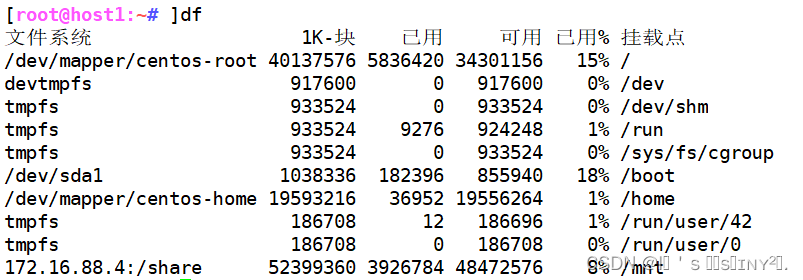
df |cut -d" " -f1,5 //以空格为分隔符,取第1和第5列文件系统
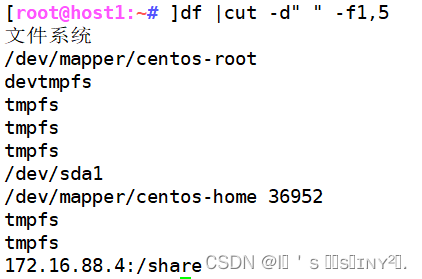
//内容错误,因为有连续的空格,不能将连续的字符当作分隔符!
df |tr -s " "|cut -d" "-f1,5//先将空行压缩成一个,再提取文件系统 已用%

df |tail -n +2|tr -s " " |cut -d " " -f5|tr -d % //去除百分号,对比数字

3. sort命令——排序
把整理过的文本显示在屏幕上,不改变原始文件。sort将文件的每一行作为一个单位相互比较,比较原则是从首字符向后依次按ASCII码进行比较,最后将它们按升序输出。
命令格式 : sort [options] file(s)
选项:
- -n 按照数字大小进行排序(默认升序)
- -r 倒序排序
- -k 指定列
- -t 指定分隔符
4. uniq命令——去重
uniq(unique 唯一)是一个用于文本处理中删除重复行的工具(只能将连续的重去掉),常与sort命令结合使用。
命令格式 : uniq [OPTION]... [FILE]...
选项:
-c 显示每行重复出现的次数
-u 仅显示不曾重复的行
-d 仅显示重复过的行
去重
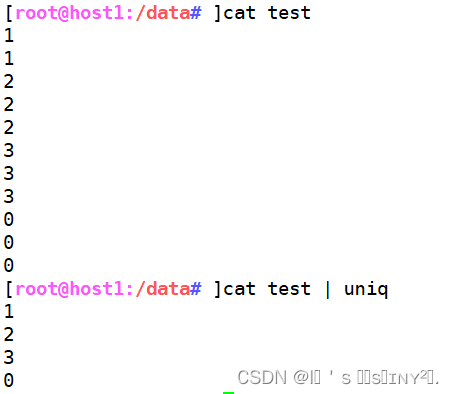
显示每行重复出现的次数
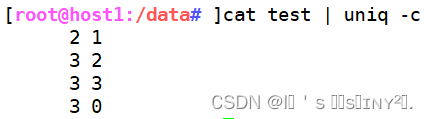
仅显示不曾重复的行
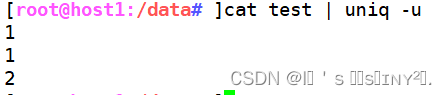
仅显示重复过的行
`cat file | uniq 选项`
`面试题:`查看访问日志,找出访问前10名的用户
cat access_log |cut -d " " -f1 |sort -n |uniq -c |sort -nr |head
cat access_log |cut -d" " -f1 //先取地址
cat access_log |cut -d" " -f1|sort //再排序一样的ip地址在一起
cat access_log |cut -d" " -f1|sort|uniq -c //去重
cat access_log |cut -d" " -f1|sort|uniq -c|sort -nr |head //再数字排序,取前10行

5. seq命令
seq命令是 sequence 的缩写,用于打印数字序列。
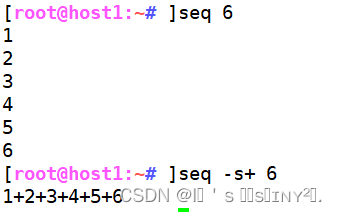
求1-6的和,bc是计算命令21







![[YOLOv8] 用YOLOv8实现指针式圆形仪表智能读数(一)](https://img-blog.csdnimg.cn/direct/ba085bb9febf41a2867be7e3601ccd4a.png)