你好,我是 shengjk1,多年大厂经验,努力构建 通俗易懂的、好玩的编程语言教程。 欢迎关注!你会有如下收益:
- 了解大厂经验
- 拥有和大厂相匹配的技术等
希望看什么,评论或者私信告诉我!
文章目录
- 一、前言
- 二、问题排查
- 2.1 查看数据量,发现数据量不大,所以肯定不是因为数据量导致的
- 2.2 因为比较着急,所以想着先增大内存试试,后续在排查问题
- 2.3 没有办法了,只能先排查问题了
- 2.4 进一步排查,查看 GC log
- 2.5 结论
- 三、总结
一、前言
写了一个 Flink 作业基于状态计算各种汇总数据,刚开始没有问题是正常的,做完一个 checkpoint 后,就开始报错,错误内容如下:
2024-05-07 18:17:19.840 INFO org.apache.flink.runtime.resourcemanager.active.ActiveResourceManager - Worker container_e1414_1713947523302_994380_01_000007 is terminated. Diagnostics: Container container_e1414_1713947523302_994380_01_000007 marked as failed.
Exit code:239.
Diagnostics:[2024-05-07 18:17:16.697]Exception from container-launch.
Container id: container_e1414_1713947523302_994380_01_000on id: container_e1414_1713947523302_994380_01_0000007
Exit code: 239
Exception message: Launch container failed
Shell output: main : command provided 1
main : run as user is work
main : requested yarn user is s_workspace_11153_krb
Getting exit code file...
Creating script paths...
Writing pid file...
Writing to tmp file /home/work/hdd7/yarn/zjyprc-hadoop/nodemanager/nmPrivate/application_1713947523302_994380/container_e1414_1713947523302_994380_01_000007/container_e1414_1713947523302_994380_01_000007.pid.tmp
Writing to cgroup task files...
Failed to set effective group id 0 - Operation not permitted
Failed to set effective group id 0 - Operation not permitted
Creating local dirs...
Launching container...
Getting exit code file...
Creating script paths...
一看就是Flink off-heap 超出 container 的内存了,没有多想,按照之前的经验直接调大 Flink 参数
taskmanager.memory.jvm-overhead.fraction
重启后发现 ,Flink TaskManager FullGC 还是很严重
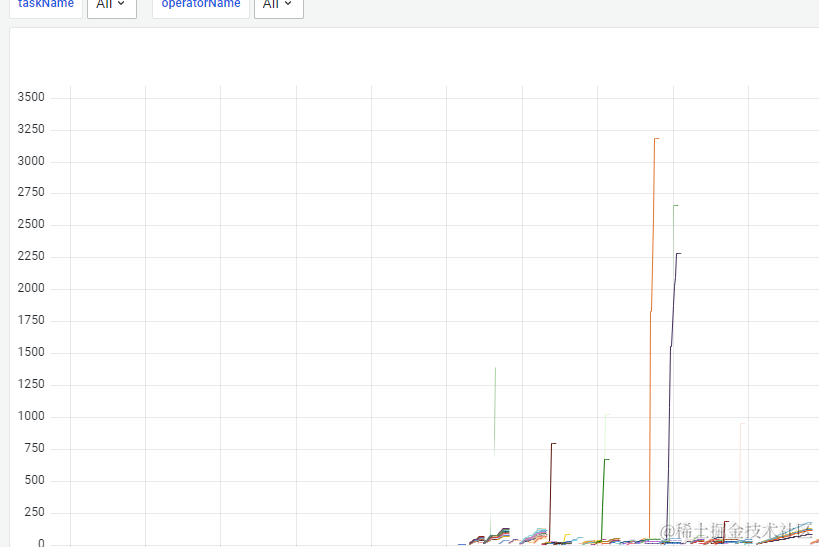
二、问题排查
2.1 查看数据量,发现数据量不大,所以肯定不是因为数据量导致的
2.2 因为比较着急,所以想着先增大内存试试,后续在排查问题
内存从 2G 增加到 4G 最后增加到 16G,问题依然存在
2.3 没有办法了,只能先排查问题了
根据 taskmanager GC 监控找到比较严重几个 container,
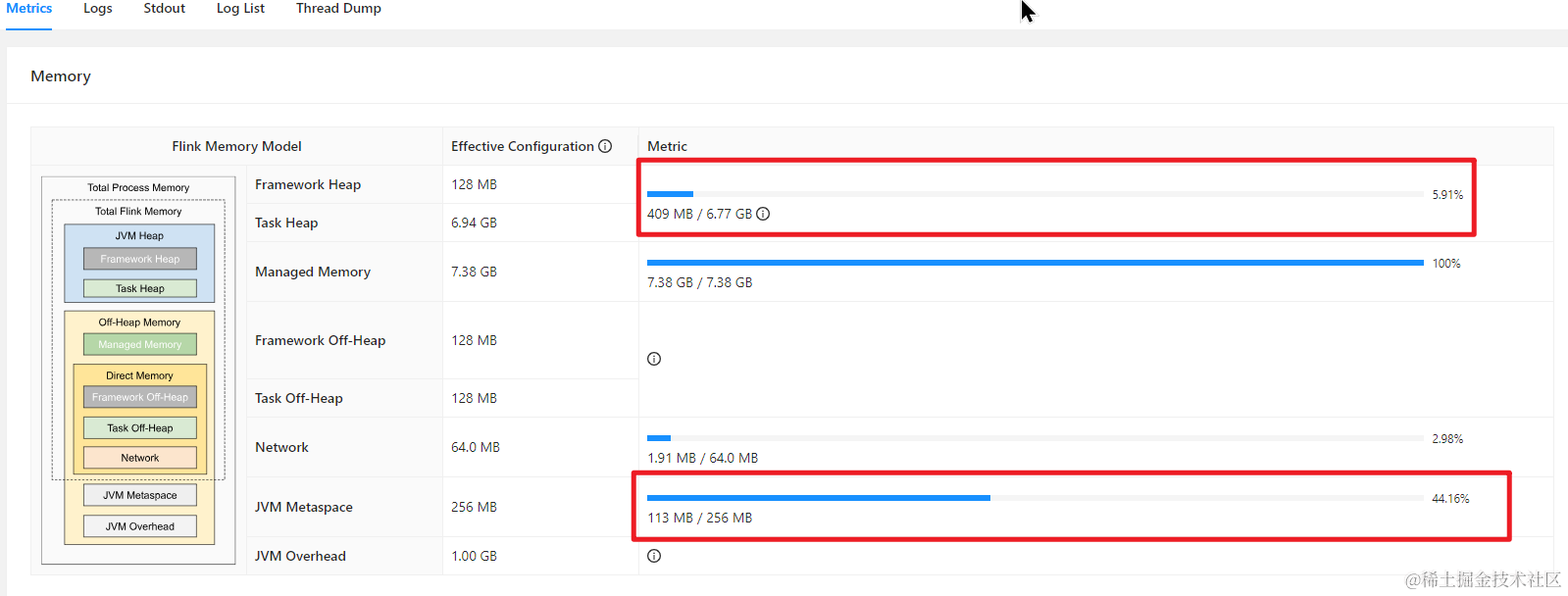
打开 Fink 自带的监控界面观察,目前看怀疑是因为 JVM Metadata 导致的
2.4 进一步排查,查看 GC log
2024-05-08T11:11:35.075+0800: 22.379: [GC (Metadata GC Threshold) [PSYoungGen: 428583K->21165K(2160128K)] 451157K->43747K(7097344K), 0.0344272 secs] [Times: user=0.08 sys=0.02, real=0.04 secs]
2024-05-08T11:11:35.109+0800: 22.413: [Full GC (Metadata GC Threshold) [PSYoungGen: 21165K->0K(2160128K)] [ParOldGen: 22581K->35384K(4937216K)] 43747K->35384K(7097344K), [Metaspace: 34235K->34235K(1079296K)], 0.2253439 secs] [Times: user=0.54 sys=0.03, real=0.22 secs]
log 解释
- GC (Metadata GC Threshold):表示进行的是元数据垃圾回收操作。
- [PSYoungGen: 428583K->21165K(2160128K)]:表示年轻代垃圾回收前后的内存情况,从428583K减少到21165K,总共可用的内存为2160128K。
- 451157K->43747K(7097344K):表示整个Java堆内存垃圾回收前后的内存情况,从451157K减少到43747K,总共可用的内存为7097344K。
- 0.0344272 secs:表示垃圾回收操作的耗时为0.0344272秒。
- [Times: user=0.08 sys=0.02, real=0.04 secs]:表示不同类型的CPU时间耗费,其中用户态CPU时间为0.08秒,内核态CPU时间为0.02秒,实际时间为0.04秒。
确实是因为 Metadata 内存分配失败导致的 full gc
2.5 结论
确实是因为 Metadata 内存分配失败导致的 full gc
于是调大 JVM metadata 阈值
taskmanager.memory.jvm-metaspace.size=512mb
三、总结
在开发Flink作业时遇到FullGC严重的问题,通过查看数据量、增大内存和排查后发现是因为Metadata内存分配失败导致的。最终成功解决了问题,给出了调大JVM metadata阈值的解决方法。