会在某一瞬间突然明白,有些牢笼是自己给自己的
—— 24.5.5
一、数据分析秘笈介绍
1.什么是数据分析
是把隐藏在一些看似杂乱无章的数据背后的信息提炼出来,总结出所研究对象的内在规律。使得数据的价值最大化
案例:
分析用户的消费行为
制定促销活动的方案
制定促销时间和粒康
计算用户的活跃度
分析产品的回购力度
分析广告点击率
决定投放时间
制定广告定向人群方案
决定相关平台的投放
……
数据分析是用适当的方法对收集来的大量数据进行分析,帮助人们做出判断,以便采取适当的行动案例:
保险公司从大量赔付申请数据中判断哪些为骗保的可能
支付宝通过从大量的用户消费记录和行为自动调整花呗的额度
短视频平台通过用户的点击和观看行为数据针对性的给用户推送喜欢的视频
2.为什么学习数据分析
① 有岗位的需求
② 数据竞赛平台。
③ 是Python数据科学的基础
④ 是机器学习课程的基础
3.数据分析实现流程
① 提出问题
② 准备数据
③ 分析数据
④ 获得结论
⑤ 成果可视化
4.内容介绍
① 基础模块使用学习
② 项目实现
③ 金融量化
5.数据分析三剑客
① numpy
② pandas⭐
③ matplotlib
二、修炼准备—环境搭建
1.开发环境介绍
—— anaconda
— 官网:https://www.anaconda.com/
— 集成环境:集成好了数据分析和机器学习种所需要的全部环境
— 注意:安装目录不可以有中文和特殊符号
—— jupyter
— jupyter是anaconda提供的一个基于浏览器的可视化开发工具
—— jupyter的基本使用
— 启动:
在终端中录入:jupyter notebook的指令,按下回车即可
— 新建:
— python3:anaconda中的一个源文件(在文件中写代码)
print("一切都会好的")
— cell有两种模式
— code:编写代码
— markdown:编写笔记
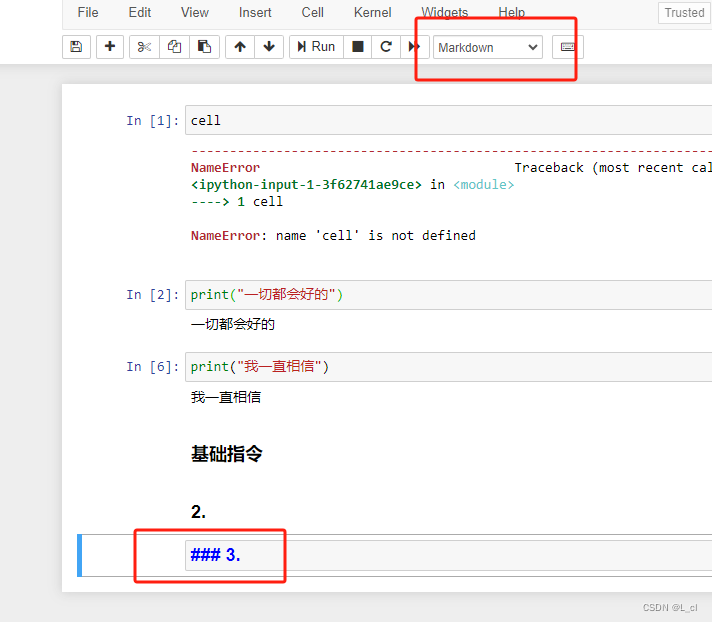
markdown — 编写笔记:### 笔记注释 用markdown运行即可
— 快捷键
— 添加cell:a或者b
— 删除cell:x
— 修改cell的模式:
— m:修改成markdown
— y:修改成code模式
— 执行cell:shift+enter
— tab:自动补全代码
— 打开帮助文档:shift+tab
三、numpy数组三种神秘创建方式
1.numpy模块
Numpy是Python语言中做科学计算的基础库,重在于数值计算,也是大部分Python科学计算库的基础,多用于在大型、多维数组(python中的列表)上执行的数值运算
2.numpy的创建
① 使用np.array()创建
② 使用plt创建
③ 使用np的routines函数创建
① 使用np.array()创建
使用array()创建一个一维数组
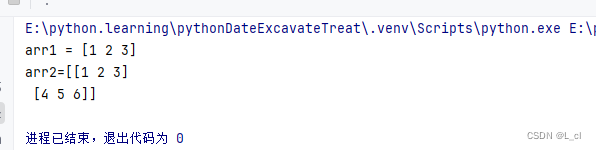
# numpy的创建 # 导入numpy包 import numpy as np # 使用array()创建一个一维数组 arr1 = np.array([1,2,3]) print(f"arr1 = {arr1}")
使用array()创建一个多维数组
# numpy的创建 # 导入numpy包 import numpy as np # 使用array()创建一个多维数组 arr2 = np.array([[1,2,3],[4,5,6]]) print(f"arr2={arr2}")
数组和列表的区别是什么
import numpy as np arr = np.array([1,2,3,'four']) print(arr)

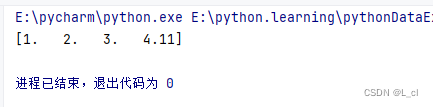
import numpy as np arr = np.array([1,2,3,4.11]) print(arr)
数组中存储的数据元素类型必须是统一类型
优先级:
字符串 > 浮点型 > 整数
② 使用plt创建
改变数组元素的数值对图片的影响
需求:将外部的一张图片读取加载到numpy数组中,尝试改变数组元素的数值查看对原始图片的影响
import matplotlib.pyplot as plt img_arr = plt.imread('./1.jpg') plt.imshow(img_arr)
import matplotlib.pyplot as plt img_arr = plt.imread('./1.jpg') plt.imshow(img_arr) img_arr = img_arr-100 plt.imshow(img_arr)
③ 使用np的routines函数创建
import numpy as np # 三行四列的数组 np.ones(shape=(3,4)) print(np.ones(shape=(3,4))) # 一维的等差数列数组 np.linspace(0,100,num=20) print(np.linspace(0,100,num=20)) # 等差数列 np.arange(10,50,step=2) print(np.arange(10, 50, step=2)) # 0-100范围内五行三列的数组 np.random.randint(0,100,size=(5,3)) print(np.random.randint(0, 100, size=(5, 3)))



四、numpy爆破属性
numpy的常用属性
① shape:数组形状
② ndim:数组维度
③ size:数组元素个数
④ dtype:数组元素类型
import numpy as np # 数组元素0到100随机生成的五行六列的数组 arr = np.random.randint(0,100,size=(5,6)) print(f"arr={arr}") # 返回数组的形状 print(f"arr.shape={arr.shape}") # 返回数组的维度 print(f"arr.ndim={arr.ndim}") # 返回数组的元素个数 print(f"arr.size={arr.size}") # 返回数组元素的类型 print(f"arr.dtype={arr.dtype}") # 返回数组的数据类型 print(f"type(arr)={type(arr)}\n") # 修改数组的元素类型 arr = np.array([1,2,3]) print(f"arr={arr}") print(f"arr.dtype={arr.dtype}") arr=np.array([1,2,3],dtype='int64') print(f"arr.dtype={arr.dtype}") arr.dtype='uint8' print(f"arr.dtype={arr.dtype}")
五、numpy的索引和切片操作
1.索引操作和列表索引操作同理
# 索引操作 import numpy as np from matplotlib import pyplot as plt # 五行六列的数组 arr = np.random.randint(1,100,size=(5,6)) # 打印数组 print(f"arr={arr}") # 通过索引取出numpy数组中下标为1的行数据 print(f"arr[0]={arr[0]}") # 通过索引取出numpy数组中的多行数据 print(f"arr[[1,2,4]]={arr[[1,2,4]]}") print(plt.imshow(img_arr[66:200, 78:200]))2.切片操作
切出前两列数据
切出前两行数据
切出前两行的前两列的数据
数组数据翻转
练习:将一张图片上下左右进行翻转
操作练习:将图片进行指定区域的裁剪
# 切出arr数组的前两行的数据 print(f"arr[0:2]={arr[0:2]}") # arr行切片 # 切出arr数组的前两列的数据 print(f"arr[:, 0:2]={arr[:, 0:2]}") # arr[行切片,列切片] # 切出arr数组前两行的前两列的数据 print(f"arr[0:2,0:2]={arr[0:2, 0:2]}") # 将数组的行倒置 print(f"arr[::-1]={arr[::-1]}") # 将数组的列倒置 print(f"arr[:,::-1]={arr[:,::-1]}") # 所有元素倒置 print(arr[::-1, ::-1]) # 将一张图片进行左右翻转 img_arr = plt.imread('./我始终相信.jpg') print(f"img_arr.shape={img_arr.shape}") print(plt.imshow(img_arr)) print(plt.imshow(img_arr[:, ::-1, :])) # 将一张图片上下进行反转 print(plt.imshow(img_arr[::-1, :, :])) # 图片裁剪的功能 print(plt.imshow(img_arr[66:200, 78:200]))
六、统计&聚合&矩阵操作
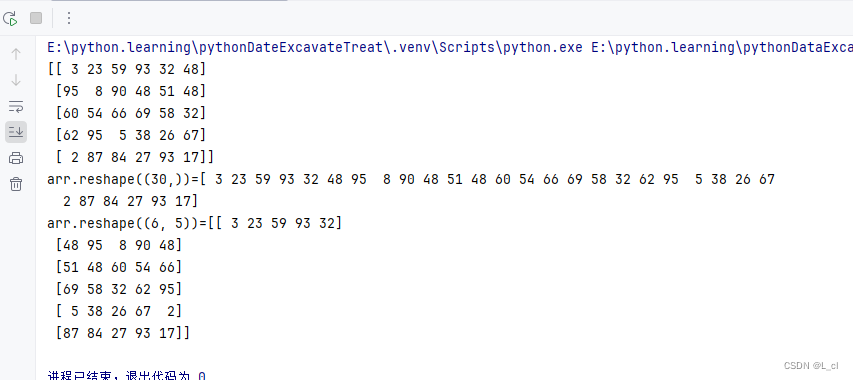
1.变形操作reshape
# 变形操作reshape # 五行六列的二维数组 arr = np.random.randint(1,100,size=(5,6)) print(arr) # 将二维的数组变形成一维 print(f"arr.reshape((30,))={arr.reshape((30,))}") # 将一维数组变成多维的 print(f"arr.reshape((6, 5))={arr.reshape((6, 5))}")
2.级联操作
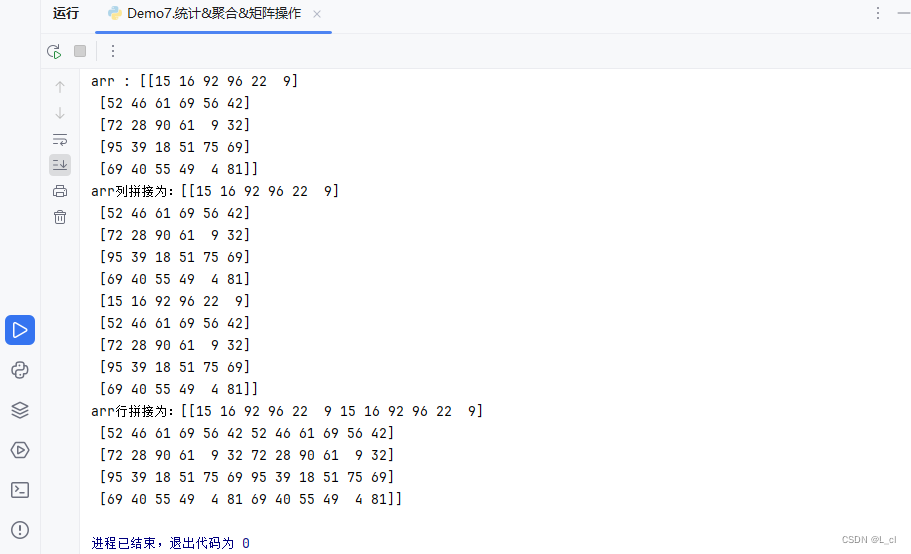
将多个numpy数组进行横向或者纵向的拼接
axis轴向的理解
—— 0:列,纵向
—— 1:行,横向
# 级联操作 # axis轴向的理解 print(f"arr : {arr}") print(f"arr列拼接为:{np.concatenate((arr,arr),axis=0)}") print(f"arr行拼接为:{np.concatenate((arr,arr),axis=1)}")
级联只能是同一维度数组操作
问题:
级联的两个数组维度一样,但是行列个数不一样会如何?
# 问题 arr1 = np.random.randint(1,100,size=(3,4)) arr2 = np.random.randint(1,100,size=(2,4)) print(f"arr1和arr2级联结果是:{np.concatenate((arr1,arr2),axis=1)}")
图片也可以进行横纵拼接
3.常用的聚合操作
①sum ②max ③min ④mean
4.常用的数学函数
NumPy提供了标准的三角函数:sin()、cos()、tan()
numpy.around(a,decimals)函数 返回指定数字的四舍五入值。参数说明:
a: 数组
decimals:舍入的小数位数。默认值为0。如果为负,整数将四舍五入到小数点左侧的位置5.常用的统计函数
numpy.amin() 和 numpy.amax(),用于计算数组中的元素沿指定轴的最小、最大值。
numpy.ptp():计算数组中元素最大值与最小值的差(最大值-最小值)。
numpy.median():函数用于计算数组a中元素的中位数(中值)标准差std():标准差是一组数据平均值分散程度的一种度量。
公式:std=sqrt(mean((x-x.mean())**2))。如果数组是 [1,2,3,4],则其平均值为 2.5。因此,差的平方是 (2.25,0.25,0.25,2.25),并且其平均值的平方根除以4,即std = sqrt(5/4),结果为 1.1180339887498949。
方差var():统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数,即 mean((x-x.mean())**2)。换句话说,标准差是方差的平方根。
3.矩阵相关
NumPy 中包含了一个矩阵库 numpy.matlib,该模块中的函数返回的是一个矩阵,而不是 ndarray 对象。一个的矩阵是一个由行(row) 列(column)元素排列成的矩形阵列。
numpy.matlib.identity() 函数返回给定大小的单位矩阵。单位矩阵是个方阵,从左上角到右下角的对角线(称为主对角线)上的元素均为 1,除此以外全都为 0。① 单位矩阵
eye返回一个标准的单位矩阵
示例:
# 矩阵操作 # eye返回一个标准的单位矩阵 np.eye(9) print(f"np.eye(9)={np.eye(9)}")
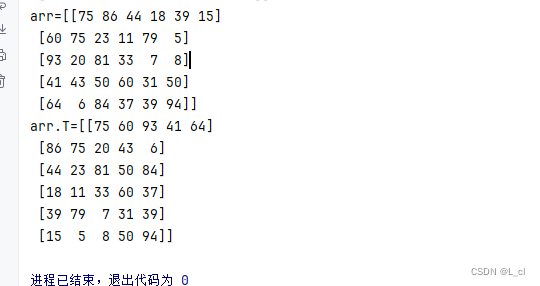
② 转置矩阵
矩阵.T,返回矩阵的转置矩阵
示例:
# 矩阵.T,返回矩阵的转置矩阵 print(f"arr={arr}") print(f"arr.T={arr.T}")
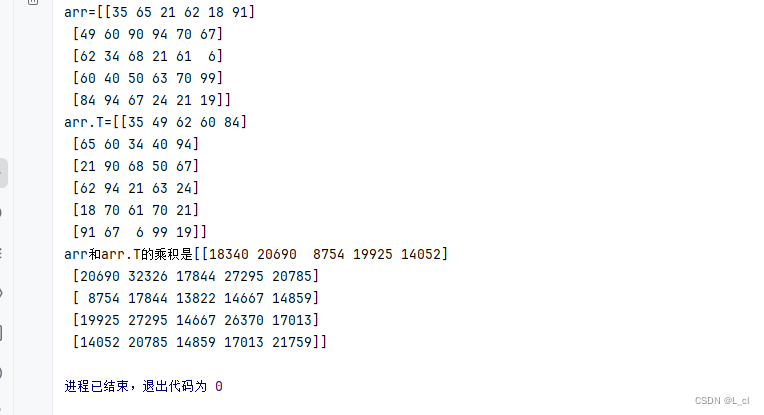
③ 矩阵相乘
numpy.dot(a, b, out=None)
a:ndarray 数组
b:ndarray 数组示例:
# 矩阵相乘 print(f"arr={arr}") print(f"arr.T={arr.T}") print(f"arr和arr.T的乘积是{np.dot(arr, arr.T, out=None)}")
在NumPy中,
np.dot函数用于计算两个数组的点积(或矩阵乘法,如果它们是二维的)。out=None是np.dot函数的一个可选参数,用于指定输出数组。具体来说,
out=None表示函数将分配一个新的数组来存储结果,并返回这个新数组。但如果你提供了一个数组作为out参数的值,np.dot会尝试将结果存储在这个数组中,而不是创建一个新的数组。