目录
- 概述
- 资源
- 解决问题
- 效果
- 环境配置
- 相关包
- 关键代码
- 测试
- 测试结果
概述
在此提供 spark sql 与scala混合开发实现数据入mongodb 相关思路
将部分重复性功能进行通用化(使用SQL与Scala混合开发模式)。
相关组件 hadoop 3.3.6 spark 3.4.2 kyuubi 1.8.0 基于上术组件开发
资源
如遇资源或代码方面问题,可以下载以下内容解决。
| 资源 | 下载地址 |
|---|---|
| 相关jar包 | 地址 |
| 关键代码 | 地址 |
解决问题
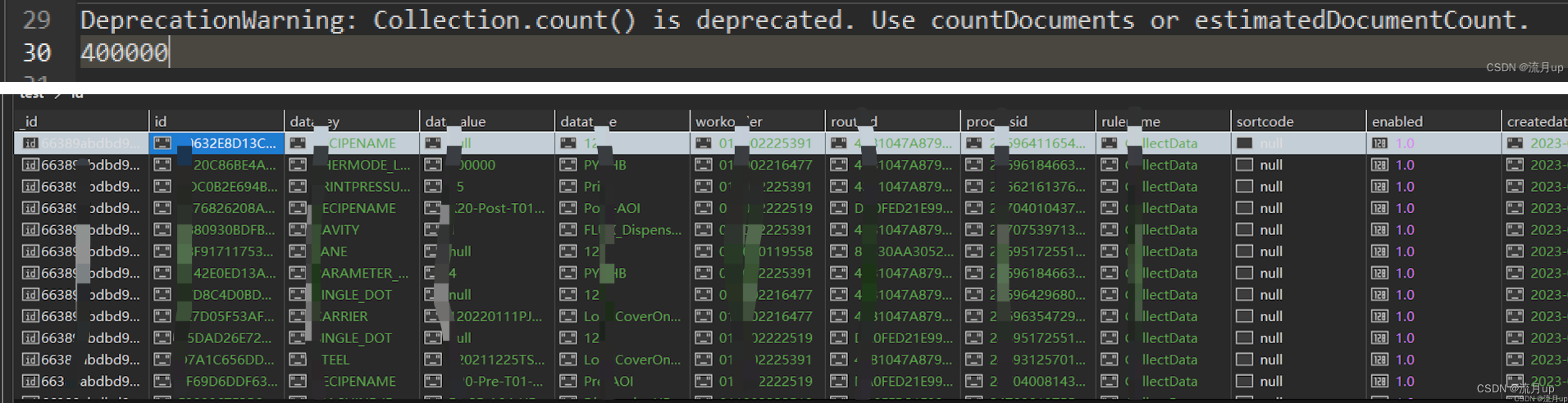
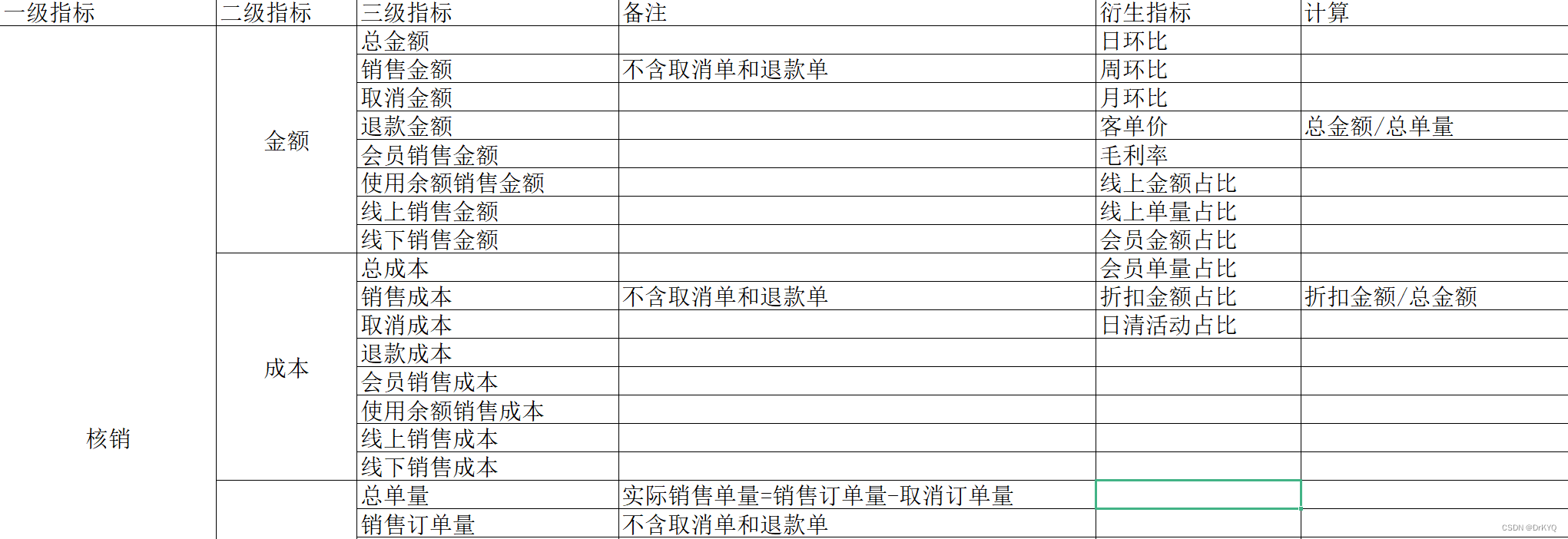
进行数据分析时,会出现上百个字段,几十万的数据量,导致前端拉取慢,而且浏览器老崩。
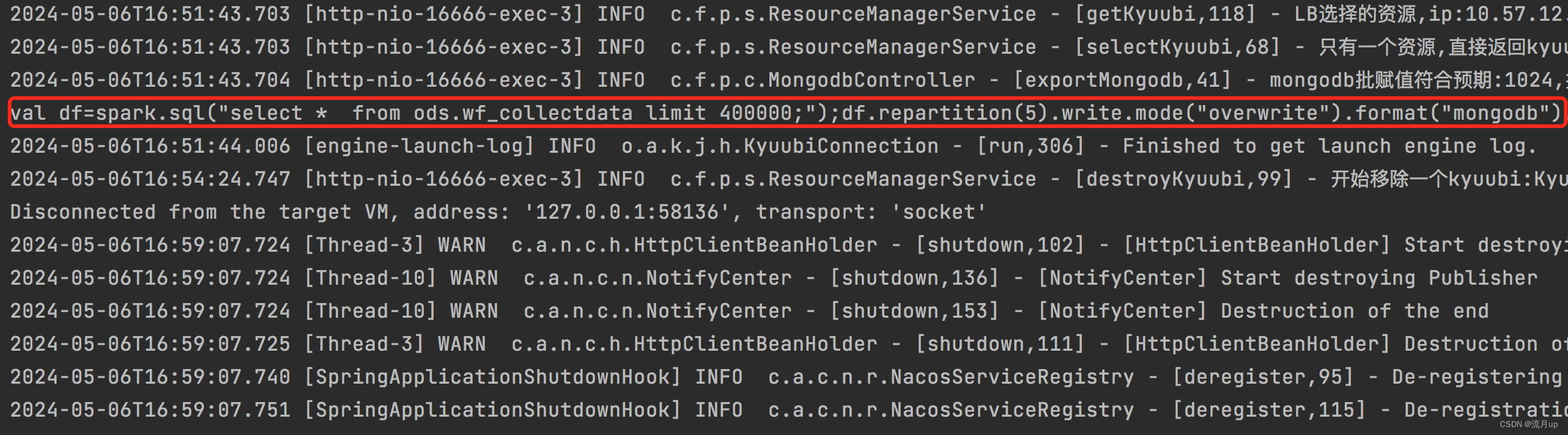
所以需要写入快,能分页,支持索引,为后续功能做扩展,也可能出现,数据过千万的情况,考虑方方面面,最终使用 spark sql 与 Scala 混合开发,完成前端传SQL,后端将 SQL 与 Scala 组合写入 Mongodb,提交给 Spark 执行,即可解决这一类问题。
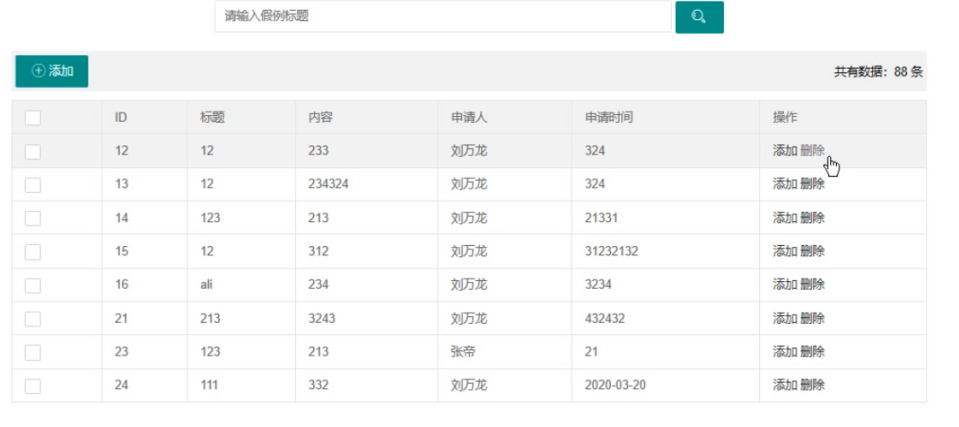
效果

环境配置
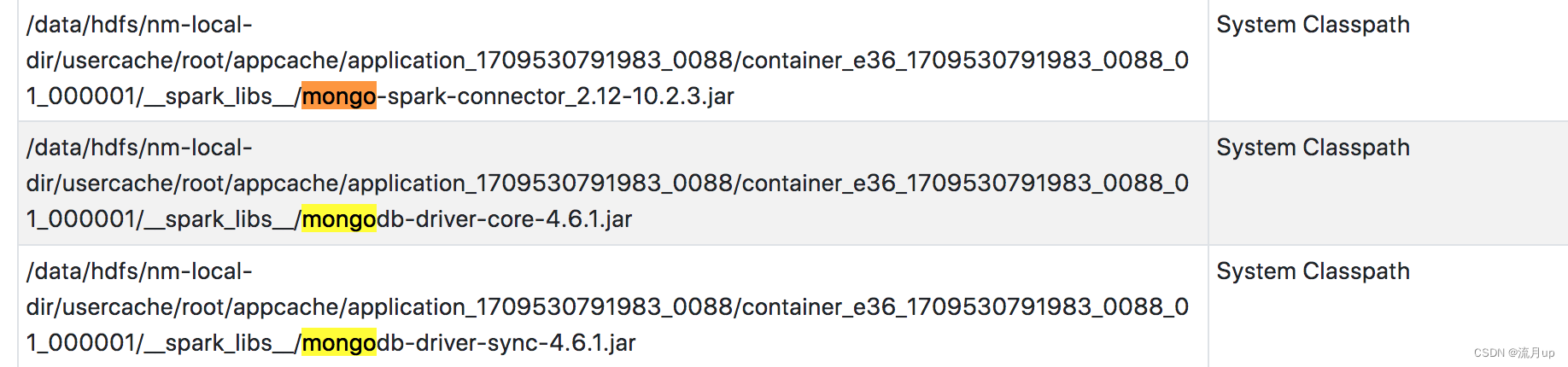
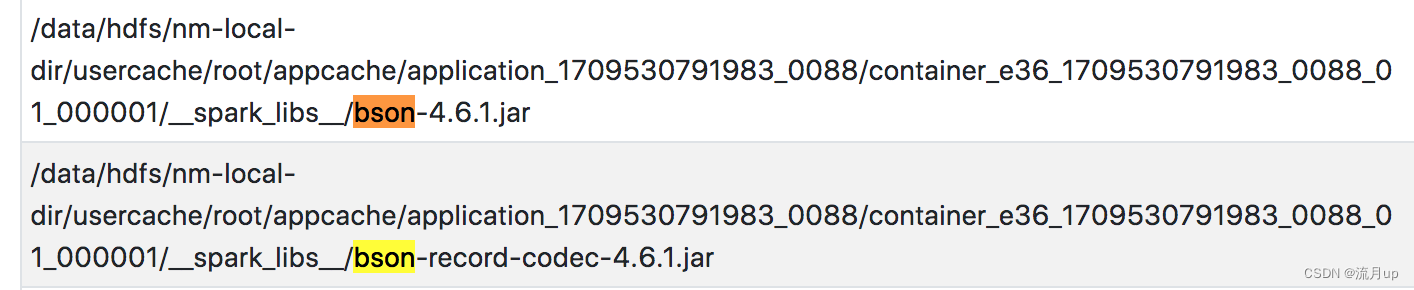
相关包

启动的spark环境中也有对应的包
关键代码
public static boolean exportMongodb(Kyuubi kyuubi, String mongodbUrl, Integer repartition, String database, String collection, Integer maxBatchSize) throws SQLException {
。。。
StringBuilder sb = new StringBuilder();
sb.append("val df=spark.sql(\"").append(kyuubi.getSql()).append("\"").append(");")
.append("df");
if (Objects.nonNull(repartition) && repartition > 0) {
sb.append(".repartition(").append(repartition).append(")");
}
sb.append(".write.mode(\"overwrite\")");
sb.append(".format(\"mongodb\")");
sb.append(".option(\"connection.uri\", ").append("\"").append(mongodbUrl).append("\")");
sb.append(".option(\"database\", ").append("\"").append(database).append("\")");
sb.append(".option(\"collection\", ").append("\"").append(collection).append("\")");
sb.append(".option(\"ordered\", \"false\")");
sb.append(".option(\"maxBatchSize\", ").append("\"").append(maxBatchSize).append("\")");
sb.append(".save();");
System.out.println(sb);
。。。
return true;
}
测试
测试结果