一个设计良好的高可用负载均衡集群,交付使用以后并不能一劳永逸。欲使其高效、稳定、持续对外服务,日常维护必不可少。
对于高可用负载均衡集群来说,有两种类型的维护形式:常规性维护与突发性维护。突发性维护一般指故障处理,而常规性的维护包括的内容大致包括但不限于:变更、监控、升级、
备份与恢复等。本章会列举一些日常维护的实际案例给读者作为经验讲解。
9.1 负载均衡集群故障处理
在高可用负载均衡集群中,一些设施或者应用发生故障虽然不影响用户的使用,但作为维护人员,发现故障应立即排查并进行故障恢复,并对处理进行记录。
故障一般有硬件故障、系统故障、软件故障、性能故障。硬件故障比较容易判断,找出问题所在以后进行维修或者更换。系统故障、软件故障等,排查的诀窍就是日志文件,这一点要牢记于心。
1.故障实例:通过VIP访问不到Web页面
一个刚刚部署好Web服务集群,前端Keepalived + LVS(DR直接路由模式),后端多个真实服务器部署Apache。实施人员反馈故障现象如下:
(1)能通过telnet VIP 80正常访问。
(2)单独访问每个真实服务器的页面,正常。
(3)通过域名访问Web页面(绑定了集群VIP),不正常。
作者认为,排查最有效的策略是先实后虚--先查后端真实服务器,再查前端负载均衡。反之,假使故障在后端真实服务器,却在负载均衡器上找病因,能有效么?
得到授权以后,开始登录后端真实服务器宿主系统,检查Apache服务的配置,一下子就发现问题所在:居然把集群的VIP显式的写在配置文件中(<VirtualHost VIP:80>)。
修改Apache配置文件,将“<VirtualHost VIP:80>”更正为“<VirtualHost *:80>”,保存配置,重启Apache服务,再以VIP地址访问Web页面,一切正常。
2.故障实例:集群性能故障
一个长期运行的负载均衡集群,前端Keepalived + HAProxy,后端真实服务器部署Nginx,提供数十个域名Web访问。在没有做任何市场推广、也没有突然大幅度增加注册用户的情况下,某一个域名的访问异常缓慢,同一个页面用浏览器反复刷新甚至出现“503”错误,而在此负载均衡集群中的其他域名的访问却是正常的。
登录到主负载均衡器宿主系统,粗略查看HAProxy日志,发现大量的日志记录来自于网络爬虫,再以主机名与“spider”做关键字对访问日志做处理,果然是爬虫在耗费网络资源,如图9-1所示。
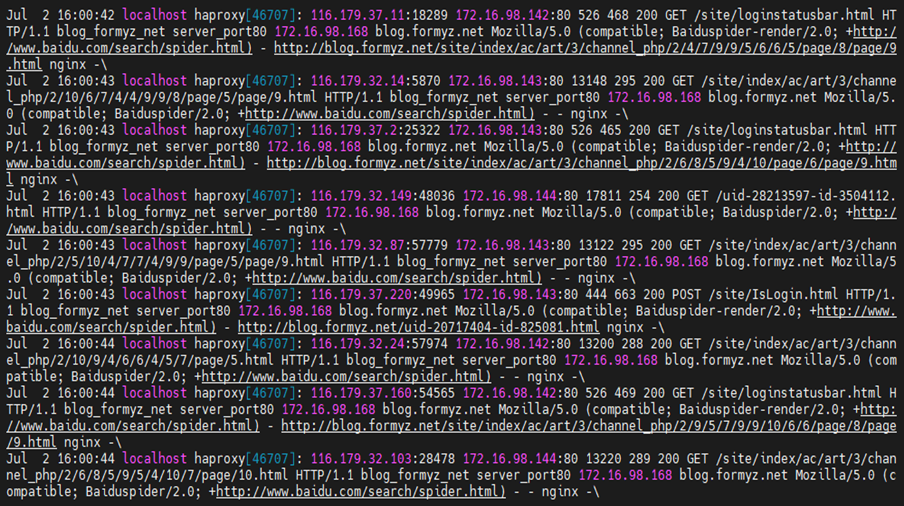 图9- 1
图9- 1
知道了问题所在,接下来的处理从两个方面入手:负载均衡器上限制单个IP地址的最大并发数,同时在Nginx上屏蔽某些恶意的爬虫。
(1)负载均衡器限制同一个网段所有地址的连接总数量。使用系统防火墙工具“iptables”,在从负载均衡器(BACKUP)宿主系统手动执行防火墙策略,确定该指令不会产生异常并能正确发挥作用以后,再应用到主负载均衡器(Master)。限制访问并发数的“iptables”指令如下:
| /usr/sbin/iptables -I INPUT -p tcp --dport 80 -m connlimit --connlimit-above 80 --connlimit-mask 24 -j DROP /usr/sbin/iptables -I INPUT -p tcp --dport 443 -m connlimit --connlimit-above 80 --connlimit-mask 24 -j DROP |
请读者注意:上述语句中有大写与小写、有单横杠与有双横杠,不能混淆。
(2)Nginx限制爬虫。用禁止源地址的方法无法有效的屏蔽爬虫,因此可选的方法之一就是对用户代理(User-Agent)进行处理。在Nginx配置文件中,对爬虫的定义可以是全局,也可以单独针对某个主机名,单独的主机名配置,以“include”的形式包含到主配置文件即可。根据从主负载均衡器(MASTER)访问日志统计出来的恶意爬虫名字,在Nginx的配置文件中加入如下文本块:
| if ($http_user_agent ~* "FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpCli ent|MJ12bot|heritrix|EasouSpider|Ezooms|Sogou spider|Sogou web spider|360Spider|YisouSpider" ) { return 403; } |
请读者注意:小括号“()”里的字符串是一个整行,不要回车断行!保存修改,执行指令“nginx -t”进行语法检查,无误后重启“nginx”服务。以同样的方法,将集群中的其他Nginx做好处理。
通过上述两种方式进行处理后,发生性能故障的Web站点又恢复了正常。
9.2 负载均衡集群变更操作
集群容量扩充或缩减、现有集群中新增项目、变更策略、置换设施等,均在此范围。
对有前后端架构的负载均衡集群,变更操作时,先后端再前端,先从(BACKUP)后主(MASTER)。这样做的目的,是保证集群的服务不因变更操作而受影响。例如,在负载均衡集群中增加后端节点,正确有效的做法通常如下:
- 确认新增的后端,直接访问它承载的服务,状态正常。
- 将新增的后端加入到从负载均衡器(BACKUP)转发队列,客户端访问从负载均衡器(BACKUP)的地址及端口,可正确得到结果,并能跟踪确认用户的最终访问到达新增的节点(可通过负载均衡器日志与节点服务日志相互参照确认)。
- 用户访问量小的夜间,将从负载均衡器(BACKUP)的配置同步到主负载均衡器(MASTER),然后重启主负载均衡器系统或者服务。重启主负载均衡器(MASTER)期间,从负载均衡器(BACKUP)将主动接管主负载均衡的所有任务,不会导致服务不可用的风险。
后端真实服务器节点的撤离,可直接关闭其上的服务甚至是系统,负载均衡器的健康检查将自动将其从转发队列里踢出,不会对用户的访问造成影响,然后再在主从负载均衡器删掉相关条目,即可平稳将节点下线。
9.4 负载均衡集群升级
不论哪一种类型的高可用负载均衡集群,都可以分为系统升级和应用升级两个大项。在进行升级前,做好是否必须升级的评估。升级是否解决已经存在的缺陷?升级是否能大幅度提高整体性能?升级失败是否可以快速、有效回退?
在做好升级测试以后,正式进行升级,一定要按对可用性影响最小的方式进行,这个可参考软件工程“灰度发布”。
9.5 负载均衡集群备份与恢复
运行在Proxmox VE超融合集群上的高可用负载均衡集群,备份轻而易举,它将整个主机进行完整备份。如果不是这样的运行环境,则需要对数据进行选择性备份,并启动定时任务,进行关键数据的自动备份。
Proxmox VE超融合集群从备份进行恢复相当简单和容易,选中需要恢复的主机,单击按钮“还原”, 余下的事情交给时间,如图9-1所示。
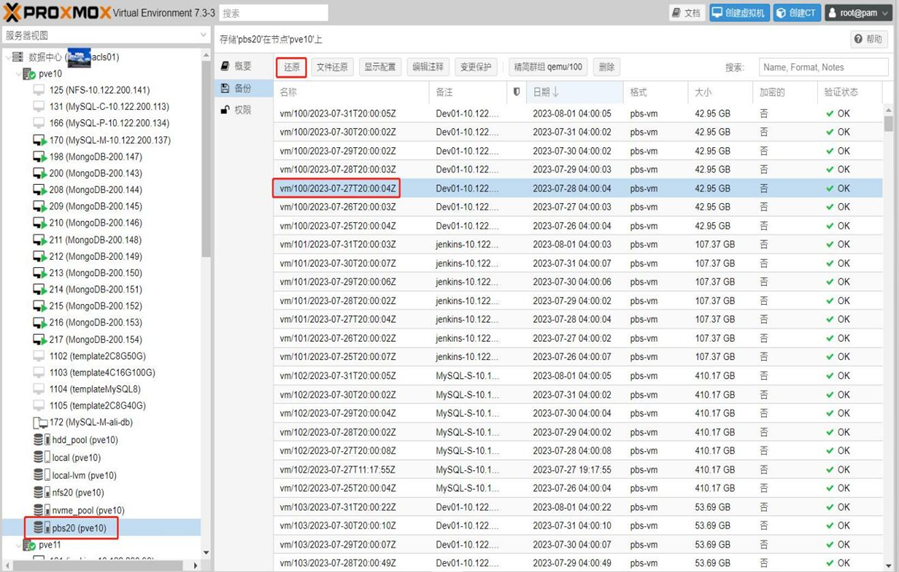 图9- 5
图9- 5
传统方式的恢复,就要复杂和耗时一些。这些过程可能包括:安装系统、安装软件、初始化、复制数据、调试、上线




![[Meachines][Hard]Napper](https://img-blog.csdnimg.cn/img_convert/8a88b784711e3770d01d7495b7458859.jpeg)


![[微信小程序] 入门笔记1-滚动视图组件](https://img-blog.csdnimg.cn/direct/718fb92610644f17b92f6d216e1f9f68.png)