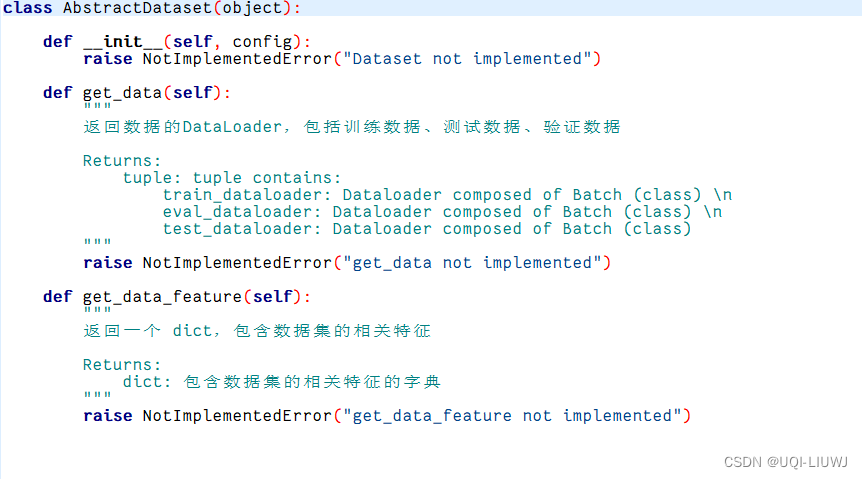
1 AbstractDataset
抽象类,所有数据集的基类
2 TrajectoryDataset
2.1 __init__
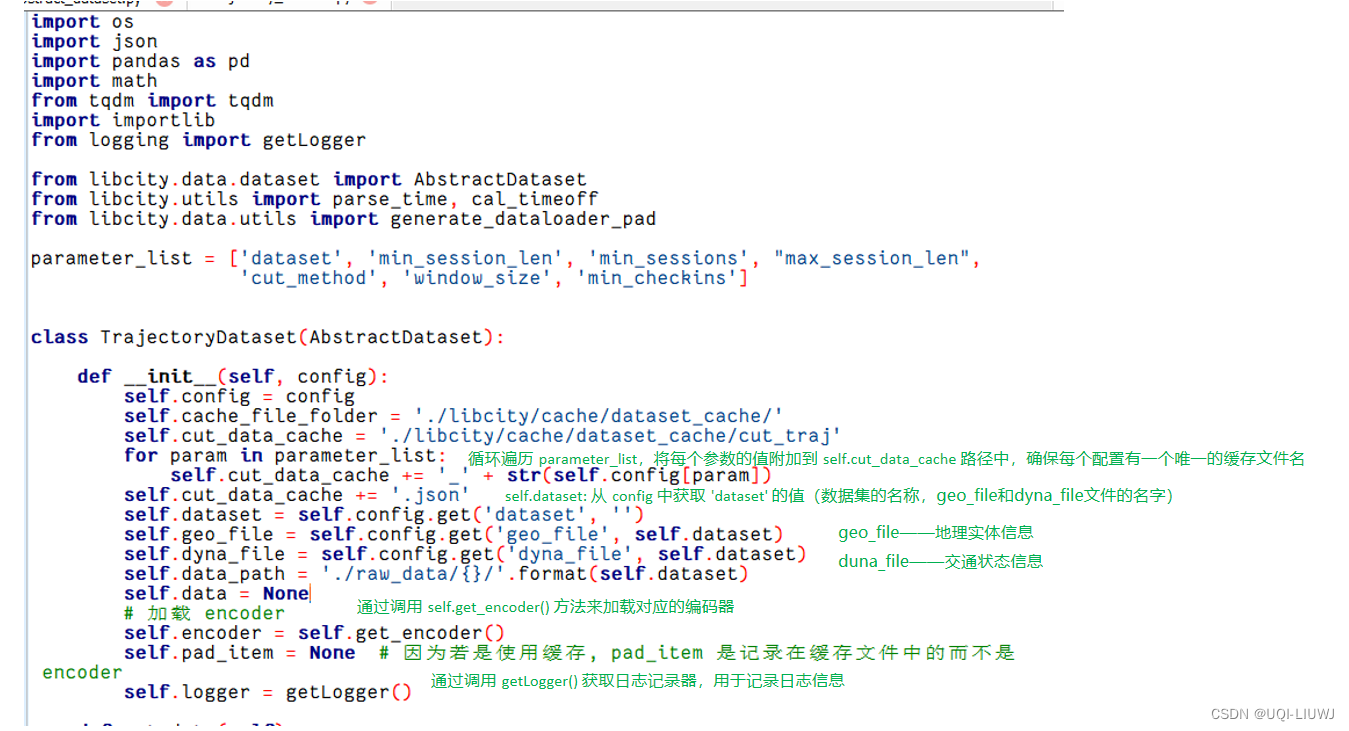
2.2 get_data

2.3 cutter_filter

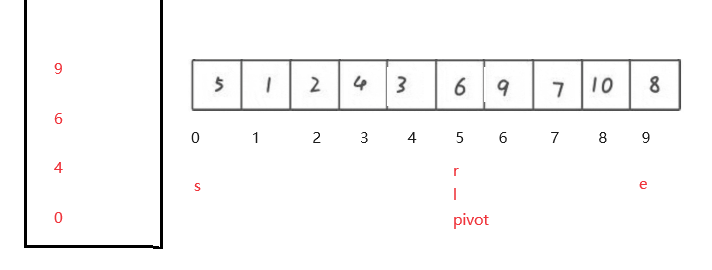
2.3.1 按照时间间隔切割

2.3.2 按照同一天切割

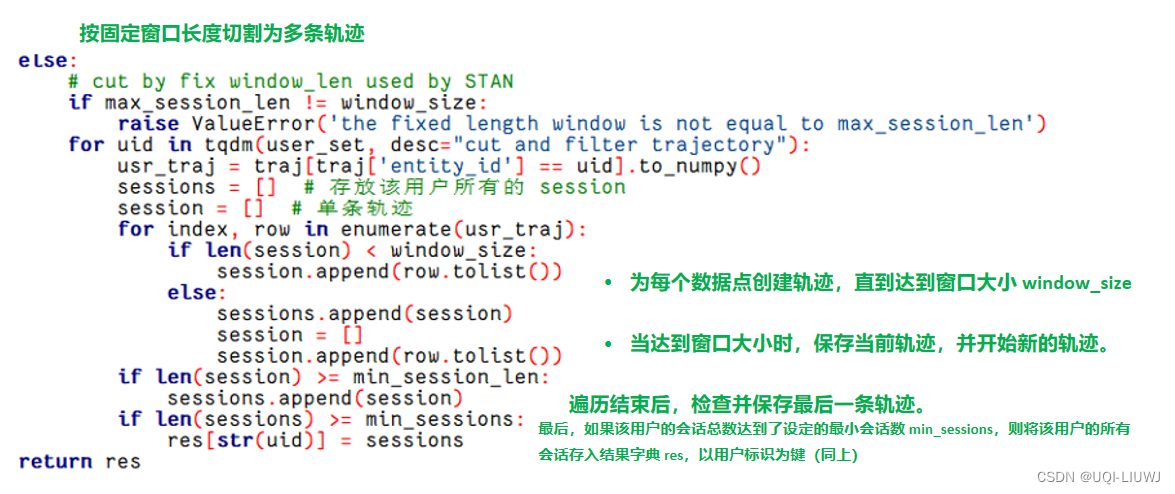
2.3.3 按照固定窗口长度切割
cut完的轨迹样子
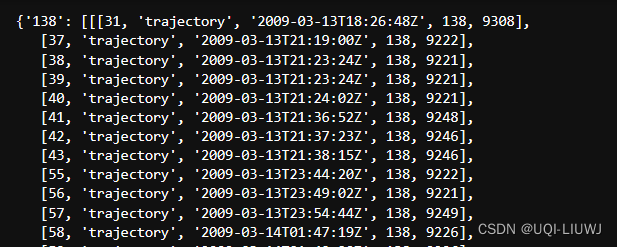
每一个key是一个轨迹的id,对应的value内容类似如下(假如使用的是固定窗口):

2.4 get_encoder

2.5 encode_traj

deta_feature返回内容:
- 'loc_size': 位置标识符的数量,所有可能的位置加上一个填充符。
- 'tim_size': 时间编码的数量,所有可能的时间编码加上一个填充符。
- 'uid_size': 表示数据集中的用户数量。
- 'loc_pad' 和 'tim_pad': 分别存储位置和时间的填充值,这些值在处理输入数据到模型时将用于补全不完整的序列。
pad_item返回内容:

encoded_data返回内容
一个字典,每个键值是user_id,对应的value是一系列历史轨迹(时间)+ground truth点(时间)
完整的返回内容如下:

encoded_data部分相当于一个字典,字典的键值是user_id,内容是一些如下的元素组成的列表

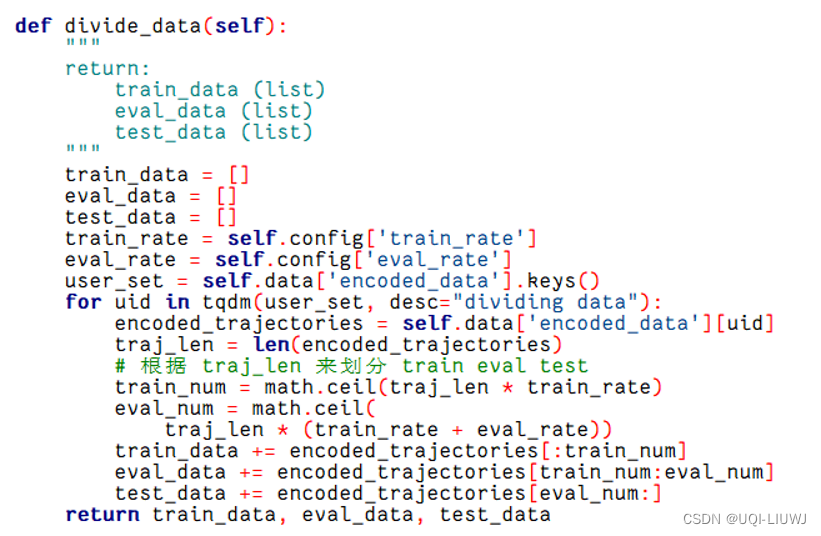
2.6 divide_data
把数据集划分成训练测试验证
self.data内容如下:
对于每个uid,encoded_trajectories 内容是这样的组成的列表:
每个user前x%的列表组成train、中间y%的组成val、后面1-x%-y%的组成test

![[微信小程序] 入门笔记1-滚动视图组件](https://img-blog.csdnimg.cn/direct/718fb92610644f17b92f6d216e1f9f68.png)