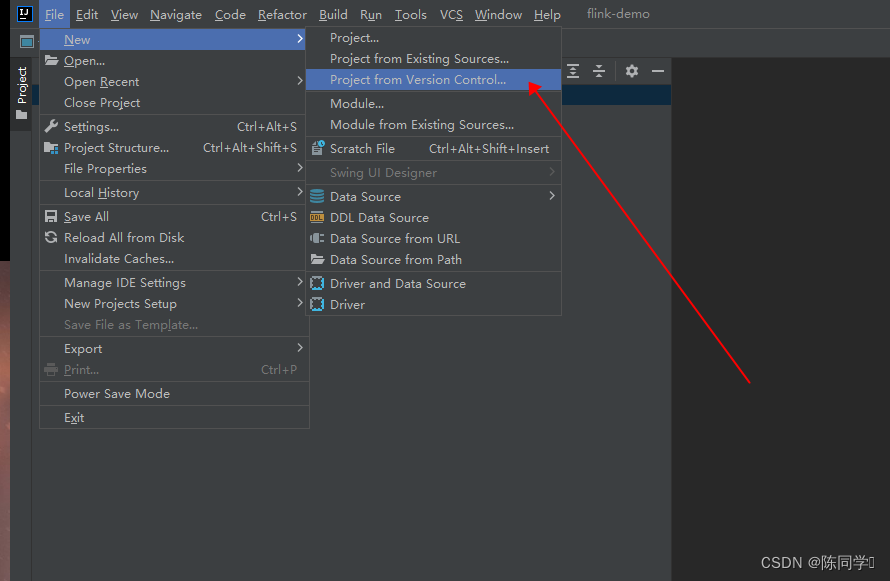
理解地质灾害形成机理与成灾模式;从空间数据处理、信息化指标空间数据库构建、致灾因子提取,空间分析、危险性评价与制图分析等方面掌握GIS在灾害危险性评价中的方法;运用地质灾害危险性评价原理和技术方法
原文链接:基于GIS、Python机器学习技术的地质灾害风险评价、易发性分析与信息化建库及灾后重建中的实践应用
//专题一 基本概念与平台讲解[基础篇】
1、基本概念
地质灾害类型
地质灾害发育特征与分布规律
地质灾害危害特征
地质灾害孕灾地质条件分析
地质灾害诱发因素与形成机理

2、GIS原理与ArcGIS平台介绍
-
GIS简介
-
ArcGIS基础
-
空间数据采集与组织
-
空间参考
-
空间数据的转换与处理
-
ArcGIS中的数据编辑
-
地理数据的可视化表达
-
空间分析: 数字地形分析 叠置分析 距离制图 密度制图 统计分析 重分类 三维分析


添加图片注释,不超过 140 字(可选)
-
空间数据库建立及应用

添加图片注释,不超过 140 字(可选)
1)地质灾害风险调查评价成果信息化技术相关要求解读
2)数学基础设计
比例尺;坐标系类型:地理坐标系,投影坐标系;椭球参数;投影类型;坐标单位;投影带类型等。
3)数据库内容及要素分层
图层划分原则;图层划分及命名;图层内部属性表

添加图片注释,不超过 140 字(可选)
4)数据库建立及入库
创建数据库、要素集、要素类、栅格数据和关系表等。

添加图片注释,不超过 140 字(可选)
矢量数据(shp文件)入库
Table表入库:将崩塌、滑坡、泥石流等表的属性数据与灾害点图层关联。
栅格数据入库
栅格数据集入库:遥感影像数据、DEM、坡度图、坡向图、降雨量等值线图以及其他经过空间分析得到的各种栅格图像入库。
5)数据质量控制
利用Topology工具检查点线面及其之间的拓扑关系并修改;图属一致性检查与修改。
//专题二 空间信息数据库建设【基础篇】
空间数据库建立及应用

添加图片注释,不超过 140 字(可选)
1)地质灾害风险调查评价成果信息化技术相关要求解读
2)数学基础设计
比例尺;坐标系类型:地理坐标系,投影坐标系;椭球参数;投影类型;坐标单位;投影带类型等。
3)数据库内容及要素分层
图层划分原则;图层划分及命名;图层内部属性表
添加图片注释,不超过 140 字(可选)
4)数据库建立及入库
创建数据库、要素集、要素类、栅格数据和关系表等。

添加图片注释,不超过 140 字(可选)
矢量数据(shp文件)入库
Table表入库:将崩塌、滑坡、泥石流等表的属性数据与灾害点图层关联。
栅格数据入库
栅格数据集入库:遥感影像数据、DEM、坡度图、坡向图、降雨量等值线图以及其他经过空间分析得到的各种栅格图像入库。
5)数据质量控制
利用Topology工具检查点线面及其之间的拓扑关系并修改;图属一致性检查与修改。
//专题三 地质灾害风险评价模型与方法【实战篇】

添加图片注释,不超过 140 字(可选)
1、地质灾害易发性评价模型与方法
评价单元确定
易发性评价指标体系
易发性评价模型
权重的确定
2、滑坡易发性评价
-
评价指标体系
地形:高程、坡度、沟壑密度、地势起伏度等。
地貌:地貌单元、微地貌形态、总体地势等。
地层岩性:岩性特征、岩层厚度、岩石成因类型等
地质构造:断层、褶皱、节理裂隙等。
地震:烈度、动峰值加速度、历史地震活动情况等
工程地质:区域地壳稳定性,基岩埋深,主要持力层岩性、承载力、岩土体工程地质分区等。
-
常用指标提取
坡度、坡型、高程、地形起伏度、断裂带距离、工程地质岩组、斜坡结构、植被覆盖度、与水系距离等因子提取

添加图片注释,不超过 140 字(可选)
-
指标因子相关性分析
(1)相关性系数计算与分析

添加图片注释,不超过 140 字(可选)
(2)共线性诊断

添加图片注释,不超过 140 字(可选)
-
评价指标信息量

添加图片注释,不超过 140 字(可选)
-
评价指标权重确定
-
滑坡易发性评价结果分析与制图
滑坡易发性综合指数
易发性等级划分
易发性评价结果制图分析

添加图片注释,不超过 140 字(可选)
2、崩塌易发性评价
3、泥石流易发性评价
-
泥石流评价单元提取
-
水文分析,沟域提取
√无洼地DEM生成
√水流方向提取
√汇流累积量
√水流长度
√河网提取
√流域分割
√沟壑密度计算
√模型构建器
-
泥石流评价指标
崩滑严重性、泥沙沿程补给长度比、沟口泥石流堆积活动、沟谷纵坡降、区域构造影响程度、流域植被覆盖度、工程地质岩组、沿沟松散堆积物储量、流域面积、流域相对高差、河沟堵塞程度等
-
典型泥石流评价指标选取

添加图片注释,不超过 140 字(可选)
-
评价因子权重确定
-
泥石流易发性评价结果分析与制图
泥石流易发性综合指数计算
泥石流的易发性分级确定
泥石流易发性评价结果

添加图片注释,不超过 140 字(可选)
4、地质灾害易发性综合评价
综合地质灾害易发值=MAX [泥石流灾害易发值,崩塌灾害易发值,滑坡灾害易发值]
//专题四 常用数据来源及预处理【进阶篇】
1、数据类型介绍
2、点数据获取与处理
-
灾害点统计数据获取与处理

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
-
气象站点数据获取与处理
√气象站点点位数据处理
√气象数据获取
√数据整理
√探索性分析
√数据插值分析

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
3、矢量数据的获取与处理
-
道路、断层、水系等矢量数据的获取
-
欧氏距离
-
核密度分析
-
河网密度分析

添加图片注释,不超过 140 字(可选)
4、栅格数据获取与处理
-
DEM,遥感影像等栅格数据获取
-
影像拼接、裁剪、掩膜等处理
-
NoData值处理
-
如何统一行列号

添加图片注释,不超过 140 字(可选)
5、NC数据获取与处理
-
NC数据简介
-
NC数据获取
-
模型构建器
-
NC数据如何转TIF?

添加图片注释,不超过 140 字(可选)
6、遥感云计算平台数据获取与处理
-
遥感云平台数据简介
-
如何从云平台获取数据?
-
数据上传与下载
-
基本函数简介
-
植被指数提取
-
土地利用数据获取

添加图片注释,不超过 140 字(可选)
//专题五 GIS在灾后重建中的应用实践【拓展篇】
1、土方纵坡分析
-
由等高线产生不规则三角网
-
计算工程填挖方
-
利用二维线要素纵剖面
-
临时生成剖纵面线
2、应急救援路径规划分析
-
表面分析、成本权重距离、栅格数据距离制图等空间分析;
-
利用专题地图制图基本方法,制作四川省茂县地质灾害应急救援路线图,
-
最佳路径的提取与分析
3、灾害恢复重建选址分析
-
确定选址的影响因子
-
确定每种影响因子的权重
-
收集并处理每种影响因子的数据:地形分析、距离制图分析,重分类
-
恢复重建选址分析
4、震后生态环境变化分析
使用该类软件强大的数据采集、数据处理、数据存储与管理、空间查询与空间分析、可视化等功能进行生态环境变化评价。

添加图片注释,不超过 140 字(可选)
//专题六 基于机器学习的滑坡易发性分析【高阶篇】

添加图片注释,不超过 140 字(可选)
1、Python编译环境配置
-
Python自带编辑器IDLE使用
-
Anaconda集成环境安装及使用
-
PyCharm环境安装及使用

添加图片注释,不超过 140 字(可选)
2、Python数据清洗
-
Python库简介与安装
-
读取数据
-
统一行列数
-
缺失值处理
-
相关性分析/共线性分析
-
主成分分析法(PCA)降维
-
数据标准化
-
生成特征集

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
相关概念:
√训练前是否有必要对特征归一化
√为什么要处理缺失值(Nan值)
√输入的特征间相关性过高会有什么影响
√什么是训练集、测试集和验证集;为什么要如此划分
√超参数是什么
√什么是过拟合,如何避免这种现象
模型介绍:
√逻辑回归模型
√随机森林模型
√支持向量机模型
实现方案:

添加图片注释,不超过 140 字(可选)
一、线性概率模型——逻辑回归
√介绍
√连接函数的选取:Sigmoid函数
√致灾因子数据集:数据介绍;相关性分析;逻辑回归模型预测;样本精度分析;分类混淆矩阵
√注意事项
二、SVM支持向量机
√线性分类器
√SVM-核方法:核方法介绍;sklearn的SVM核方法
√参量优化与调整
√SVM数据集:支持向量机模型预测;样本精度分析;分类混淆矩阵
三、Random Forest的Python实现
√数据集
√数据的随机选取
√待选特征的随机选取
√相关概念解释
√参量优化与调整:随机森林决策树深度调参;CV交叉验证定义;混淆矩阵;样本精度分析
√基于pandas和scikit-learn实现Random Forest:数据介绍;随机森林模型预测;样本精度分析;分类混淆矩阵
四、XGBoost(Extreme Gradient Boosting)
XGBoost 是一种基于决策树的梯度提升算法。它通过连续地训练决策树模型来最小化损失函数,从而逐步提升模型性能
√数据划分:
将数据集划分为训练集和测试集,采用随机划分或按时间序列划分的方法。
√特征工程
对数据进行特征工程,包括特征缩放、特征变换、特征组合等。
√构建模型
选择合适的模型参数,如树的数量、树的深度、学习率等。
√模型优化:
通过交叉验证来调整模型参数,以提高模型的泛化能力。
√模型训练
使用训练集对 XGBoost 模型进行训练。
通过迭代优化损失函数来提高模型性能。
√模型评估
使用测试集对训练好的模型进行评估。
使用一些常见的评估指标,如准确率、召回率、F1 分数等。
绘制 ROC 曲线或者计算 AUC 值来评估模型的性能。
√结果解释与应用:
对模型的预测结果进行解释,分析模型的重要特征和决策规则。
五、神经网络模型
√TensorFlow主要架构

添加图片注释,不超过 140 字(可选)
√神经网络:ANN\CNN\RNN
√导入数据集
√分割数据集
√定义网络架构
添加图片注释,不超过 140 字(可选)
-
调用tf.keras.models.Sequential()或tf.keras.layers.Layer()创建模型
-
Sequential: 将多个网络层封装,按顺序堆叠神经网络层
-
Dense: 全连接层
-
activation: 激活函数决定神经元是否应该被激活
√编译模型
-
通过compile 函数指定网络使用的优化器对象、 损失函数类型, 评价指标等设定
-
优化器(optimizer):运行梯度下降的组件
-
损失(loss):优化的指标
-
评估指标(metrics):在训练过程进行评估的附加评估函数,以进一步查看有关模型性能
√训练模型
-
通过 fit()函数送入待训练的数据集和验证用的数据集,返回训练过程中的损失值和指定的度量指标的变化情况,用于后续的可视化和模型性能评估。
-
循环迭代数据集多个 Epoch,每次按批产生训练数据、 前向计算,然后通过损失函数计算误差值,并反向传播自动计算梯度、 更新网络参数
√评估模型
-
Model.evaluate()测试模型的性能指标
√模型预测
-
Model.predict(x)方法即可完成模型的预测
√参数优化
六、集成学习方法
stacking集成算法

添加图片注释,不超过 140 字(可选)
√准备数据集:
-
将数据集分为训练集和测试集。
√创建基本模型:
-
选择多个不同类型的基本模型,如决策树、随机森林、支持向量机、神经网络等。
√使用训练集对每个基本模型进行训练
√生成基本模型的预测结果
√使用训练集对每个基本模型进行预测
-
对于分类问题,每个模型都会生成一个概率矩阵,每一列代表一个类别的预测概率;对于回归问题,每个模型会生成一个预测值向量。
√构建元模型:
-
将基本模型的预测结果作为新的特征,构建一个元模型。
-
元模型可以是任何机器学习模型,通常选择简单的模型如逻辑回归、线性回归或者简单的决策树。
√使用元模型进行预测
-
将测试集输入到每个基本模型中,得到预测结果。
-
将基本模型的预测结果输入到元模型中进行最终的预测。
Blending融合
√准备数据集:
训练集
验证集
测试集

添加图片注释,不超过 140 字(可选)
√创建基本模型:
选择多个不同类型的基本模型,如决策树、随机森林、支持向量机、神经网络等。
使用训练集对每个基本模型进行训练。
√生成基本模型的预测结果:
使用训练集对每个基本模型进行预测。
对于分类问题,每个模型会生成一个概率矩阵,每一列代表一个类别的预测概率;
对于回归问题,每个模型会生成一个预测值向量。
√创建元模型:
将基本模型的预测结果作为输入特征,结合验证集的真实标签,训练一个元模型。
元模型可以是任何机器学习模型
√使用元模型进行预测:
将测试集输入到每个基本模型中,得到它们的预测结果。
将这些基本模型的预测结果作为输入,输入到元模型中进行最终的预测。
四、方法比较分析
√模型性能评估:K 折交叉验证的方法
√精度分析:accuracy;precision;recall;F1-score,AUC

添加图片注释,不超过 140 字(可选)
√结果对比分析

添加图片注释,不超过 140 字(可选)
//专题七 论文写作分析
1、论文写作要点分析
2、论文投稿技巧分析

添加图片注释,不超过 140 字(可选)
3、论文案例分析


添加图片注释,不超过 140 字(可选)