最近研究了一个项目,利用python代码实现指针式圆形仪表的自动读数,并将读数结果进行输出,若需要完整数据集和源代码可以私信。
目录
🍓🍓1.yolov8实现圆盘形仪表智能读数
🙋🙋2.表盘指针语义分割
🍋2.1数据准备
🍋2.2 模型选择
🍋2.3 加载分割预训练模型
🍋2.4数据组织
🍉🍉3.目标检测训练代码
传送门
整理不易,欢迎一键三连!!!
送你们一条美丽的--分割线--
🍓🍓1.yolov8实现圆盘形仪表智能读数
实现的效果如下:


对整个项目来说,可分为三个大步骤:
- 仪表目标检测
- 仪表表盘指针分割
- 计算读数
此篇主要讲解仪表表盘指针语义分割,将表盘中的刻度位置和指针位置识别出来。
🙋🙋2.表盘指针语义分割
同样采用YOLOv8n模型进行分割任务,将表盘中的刻度位置和指针位置识别任务看做是实例分割任务,用YOLOv8可以简单快速的识别出像素级刻度和指针。
🍋2.1数据准备
首先还是准备数据,我的数据集展示如下:
image:

label可视化显示如下:
 其中要将label转成yolo-seg格式的txt文件,才能进行训练,具体格式如下:
其中要将label转成yolo-seg格式的txt文件,才能进行训练,具体格式如下:

txt文件的第一列仍然为类别信息,后面的数字为归一化后的每个实例要素的边界位置点,红色框里代表一个实例,类别信息可以从第一列进行区分,与目标检测的格式一致。具体可以参考官网给出的数据格式说明。
转换之后的label为:

🍋2.2 模型选择
以YOLOv8n为例,模型选择代码如下:
# Load a model
model = YOLO('yolov8n-seg.yaml') # build a new model from YAML
model = YOLO('yolov8n-seg.pt') # load a pretrained model (recommended for training)
model = YOLO('yolov8n-seg.yaml').load('yolov8n.pt') # build from YAML and transfer weights
其中yolov8n.yaml为./ultralytics/cfg/models/v8/yolov8n-seg.yaml,可根据自己的数据进行模型调整,打开yolov8n-seg.yaml显示内容如下:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8-seg instance segmentation model. For Usage examples see https://docs.ultralytics.com/tasks/segment
# Parameters
nc: 2 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-seg.yaml' will call yolov8-seg.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024]
s: [0.33, 0.50, 1024]
m: [0.67, 0.75, 768]
l: [1.00, 1.00, 512]
x: [1.00, 1.25, 512]
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Segment, [nc, 32, 256]] # Segment(P3, P4, P5)
主要需要修改的地方为nc,也就是num_class,此处如果是自己的数据,那就要换成自己数据的类别数,因为这里数据集只有2类,所以nc=2。
如果其他的模型参数不变的话,就默认保持原版yolov8,需要改造模型结构的大佬请绕行。
🍋2.3 加载分割预训练模型
加载实例分割预训练模型yolov8n-seg.pt,可以在第一次运行时自动下载,如果受到下载速度限制,也可以自行下载好(下载链接),放在对应目录下即可。

🍋2.4数据组织
yolov8还是以yolo格式的数据为例,./ultralytics/cfg/datasets/data-seg.yaml的内容示例如下,仍然是coco格式:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco8 # dataset root dir
train: images/train # train images (relative to 'path') 4 images
val: images/val # val images (relative to 'path') 4 images
test: # test images (optional)
# Classes (80 COCO classes)
names:
0: person
1: bicycle
2: car
# ...
77: teddy bear
78: hair drier
79: toothbrush要注意此处的names是从0开始的,如果是0-79,那上面模型选择的nc=80。这里要特别小心。
训练时的数据加载方式为:
# Train the model
results = model.train(data='data-seg.yaml', epochs=20, imgsz=640)
🍉🍉3.目标检测训练代码
准备好数据和模型之后,就可以开始训练实例分割模型了,train-seg.py的内容显示为:
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n-seg.yaml') # build a new model from YAML
model = YOLO('yolov8n-seg.pt') # load a pretrained model (recommended for training)
model = YOLO('yolov8n-seg.yaml').load('yolov8n.pt') # build from YAML and transfer weights
# Train the model
results = model.train(data='data-seg.yaml', epochs=20, imgsz=640)训练完成后的结果如下:
其中weights文件夹内hi包含2个模型,一个best.pth,一个last.pth。

在此处贴上我的训练结果:
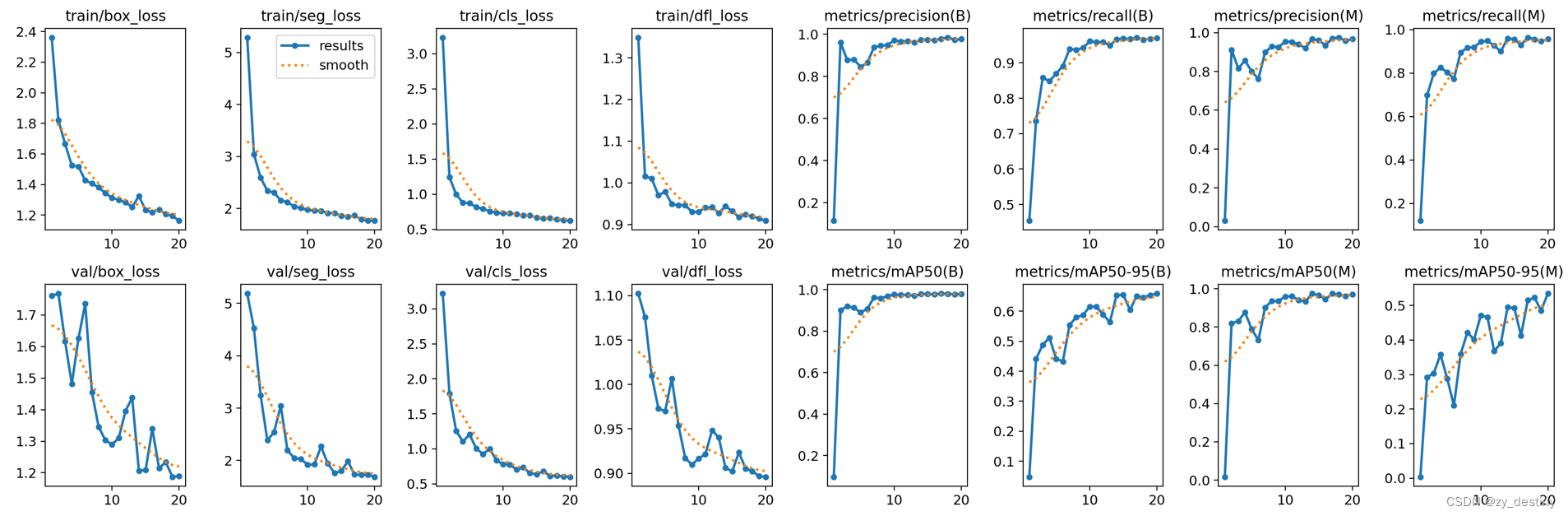
预测效果如下:

显示的太乱,可以屏蔽掉一些输出,比如文字和框等信息,可以参考我的另一篇文章【【YOLOv8】隐藏预测实例分割的目标类别和置信度信息】
至此,表盘实例分割任务就完成了,接下来就可以根据我们的识别结果进行读数计算了,详细信息我们在下一篇进行讲解。
传送门
上一篇:[YOLOv8] 用YOLOv8实现指针式圆形仪表智能读数(一)
下一篇:圆形表盘智能读数
整理不易,欢迎一键三连!!!
送你们一条美丽的--分割线--
🌷🌷🍀🍀🌾🌾🍓🍓🍂🍂🙋🙋🐸🐸🙋🙋💖💖🍌🍌🔔🔔🍉🍉🍭🍭🍋🍋🍇🍇🏆🏆📸📸⛵⛵⭐⭐🍎🍎👍👍🌷🌷