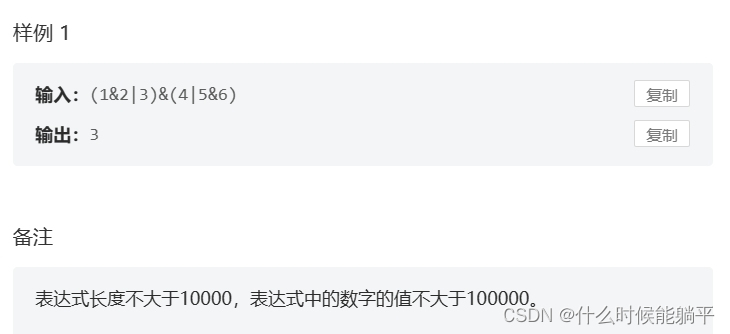
示例代码如下,但你拿到本地之需要做两件事才能运行
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
# 设置Selenium WebDriver
driver_path = r'C:\Users\……\chromedriver-win64\chromedriver-win64\chromedriver.exe' # 替换为您的ChromeDriver路径
url = 'https://data.sh.gov.cn/view/detail/index.html?type=cp&&id=AB6002012300' # 替换为实际的下载页面URL
service = Service(executable_path=driver_path)
# 初始化WebDriver
driver = webdriver.Chrome(service=service)
try:
# 打开下载页面
driver.get(url)
# 等待页面加载完成,这里设置了最长等待时间为10秒
time.sleep(1)
download_button = driver.find_element(By.CSS_SELECTOR, 'span.filebase.xlsx.docType00xlsx')
download_button.click()
# 等待文件下载完成。这里需要根据实际情况设置等待时间或检查下载状态
time.sleep(1)
finally:
# 关闭浏览器
driver.quit()
print("Download end!")1. 需要先下载模拟点击浏览器的软件,并在代码中指定driver_path
Chrome for Testing availability![]() https://googlechromelabs.github.io/chrome-for-testing/#stable2. 然后安装python库
https://googlechromelabs.github.io/chrome-for-testing/#stable2. 然后安装python库
pip install selenium
然后直接运行就好,xlsx文件就下载到浏览器默认文件夹下了,这是政府公开文件,保存的文件名为
各主要国家贸易经济数据-新.xlsx
3. 如果你有别的需求,要在其他网页下载内容,那么最重要的是找到对应的按钮,这个是整个代码中最难的部分,需要打开浏览器的开发者模式,选中左侧按钮,并找到对应按钮的html代码,如我找到的
<span class="filebase xlsx docType00xlsx">xlsx</span>
这个过程可能需要多尝试才能找到正确的按钮,有必要时多求助AI助手