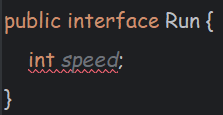
练习3
1.简单文件操作练习
import pandas as pd
# 读取文件
pd.read_csv('pokemon.csv')
# 读取 CSV 文件的函数调用,它将文件中的数据加载到 DataFrame 中,并指定了 'Pokemon' 列作为索引列。
pd.read_csv('pokemon.csv',index_col='Pokemon')
#查看类型
type(pd.read_csv('pokemon.csv',index_col = 'Pokemon'))
# 将DataFrame转为Series
# squeeze(1) 是一个 Series 对象的方法调用,用于将包含单列数据的 DataFrame 转换为 Series。参数 1 表示对列进行压缩,即将 DataFrame 压缩为 Series。
pd.read_csv('pokemon.csv', index_col='Pokemon').squeeze(1)
type(pd.read_csv('pokemon.csv' , index_col = 'Pokemon').squeeze(1))
# squeeze=True 参数表示将 DataFrame 压缩为 Series。这意味着如果读取的数据只有一列,Pandas 将返回一个 Series 而不是 DataFrame。
pd.read_csv('pokemon.csv', index_col='Pokemon', squeeze=True)
type(pd.read_csv('pokemon.csv', index_col='Pokemon', squeeze=True))
# .head() 显示 DataFrame 的前几行,默认情况下是前五行。
pd.read_csv('google_stocks.csv').head()
# 告诉pandas 把 Date 列看做日期处理
pd.read_csv('google_stocks.csv',parse_dates = ['Date']).head()
google = pd.read_csv('google_stocks.csv', parse_dates=['Date'], index_col='Date').squeeze(1)
google
type(google)
pd.read_csv('revolutionary_war.csv').tail()
# NaN: not a number
# pandas用NaN表示缺失值
# NaN是NumPy对象
# 将start time设置为index
# index_col='Start Date' 参数指定将 'Start Date' 列作为 DataFrame 的索引列。
# parse_dates=['Start Date'] 参数告诉 Pandas 将 'Start Date' 列解析为日期时间对象。
pd.read_csv('revolutionary_war.csv' , index_col = 'Start Date', parse_dates = ['Start Date']).squeeze(1).tail()
# 默认read_csv()会读取文件中的所有数据
# 这里我们只取2列,构造一个Series
# 一列是index,一列是value
# usecols=['State', 'Start Date']: 这个参数指定了我们只需要读取 'State' 和 'Start Date' 列的数据。
battles = pd.read_csv(
'revolutionary_war.csv',
index_col = 'Start Date',
parse_dates = ['Start Date'],
usecols = ['State' , 'Start Date']
).squeeze(1)
battles
type(battles)
2.排序
na_positoin
设置缺失值的位置
na_positoin 的默认值为 last,默认情况下缺失值会被放在排序后面。
na_position 参数为 'first',这意味着将缺失值排在非缺失值之前。
dropna()
battles.dropna().sort_values()
去除 Series 中的缺失值后对剩余的非缺失值进行排序
这样做的好处是,在进行排序之前先清除了缺失值,确保排序过程中不会受到缺失值的影响。
ascending
- "ascending=False" 按照降序排列,也就是从大到小的顺序排列
- "ascending=True",则表示按照升序排列,即从小到大的顺序排列
查询最大值最小值
查询最大值nlargest()
对Series的value进行查询,nlargest() 默认n=5
google.nlargest(n=5)查询最小值nsmallest()
google.nsmallest()
注:
nlargest()和nsmallest() 不能用于value是字符串的情况
#默认升序排列
google.sort_values()
# 对字符排序时,默认按照字母顺序排序
pokemon.sort_values()
# 升序排序时,大写字母排在小写字母的前面
# 即大写字母比小写字母要小
pd.Series(['Adam','adam','Ben']).sort_values()
google.sort_values(ascending = False).head()
pokemon.sort_values(ascending = False).head()
# 设置缺失值的位置
# na_positoin 的默认值为 last,默认情况下缺失值会被放在排序后面。
# na_position 参数为 'first',这意味着将缺失值排在非缺失值之前。
battles.sort_values()
battles.sort_values(na_position = 'first')
# 将value为缺失值的数据过滤掉
# dropna() 只适用于Series的value,而不是index
# dropna() 方法去除了 Series 中的缺失值后对剩余的非缺失值进行排序
# 这样做的好处是,在进行排序之前先清除了缺失值,确保排序过程中不会受到缺失值的影响。
battles.dropna().sort_values()
# 按index排序
# 默认按升序排序
pokemon.sort_index()
# 对日期排序,默认从最古老的时间到最新的时间
battles.sort_index()
# NaT: not a time
# NumPy object
# Pandas 用 NaT代表日期缺失值
# 改变带有缺失值数据的位置(缺失值在非缺失值前面)
battles.sort_index(na_position = 'first').head(10)
# 按日期倒序排序
battles.sort_index(ascending = False).head(10)
# 查询最大的几个值和最小的几个值
# 对Series的value进行查询
# nlargest() 默认n=5
# google.nlargest(n=5)
google.nlargest()
google.nsmallest()
# nlargest()和nsmallest() 不能用于value是字符串的情况
3.数据修改
inplace
告诉函数是否要在原始数据上进行修改,而不是返回一个修改后的副本。
实际尽量少用,最好用赋值语句,这样代码更具可读性。
- inplace=True 传递给函数时,函数会在原始数据上直接进行操作,而不会返回一个新的副本。这意味着原始数据会被修改,并且你不需要将函数的输出赋值给一个新的变量。
- inplace=False 或者不传递这个参数,则函数会返回一个修改后的副本,而原始数据则不受影响。
# 之前的方法都没有修改Series中的数据
battles.head(3)
battles.sort_values().head(3)
battles.head(3)
# 修改Series的内容
# 通过 inplace=True
# battles.sort_values(inplace=True)
battles_copy = battles.copy(deep=True)
battles_copy.head()
battles_copy.sort_values(inplace=True)
battles_copy.head()
# 实际中尽量少用 inplace 参数
# 最好使用赋值语句,这样代码具有更好的可读性
battles_new = battles.sort_values()
battles4.统计数据个数
首先查看原始数据
value_counts()
统计Series中每个value出现的次数
value_counts(bins = 10,sort = False)
用于对数据进行分箱并计算每个分箱中数值的频数。
举个例子,如果有一个包含身高数据的 Series, value_counts(bins=10, sort=False) 将身高数据分成 10 个区间,并计算每个区间内身高数据的频数。
- bins=10 参数指定了数据分成的箱子(bin)的数量。这意味着函数将会把数据分成 10 个区间,并计算每个区间中数值的频数。
- sort=False 参数指定了是否对结果进行排序。
len(pokemon.value_counts)
len()函数来计算这个结果的长度,也就是不同数值的数量。pokemon.nunique()
用于计算不同数值的数量。它直接返回数据中不同数值的数量,而不需要额外的操作。通常情况下,这个方法在处理 Pandas 数据时更为方便和高效。
round()
用于控制数字的小数点后位数。你可以使用它来四舍五入到指定的小数点位数。
num = 3.1415926 rounded_num = round(num, 2) print(rounded_num) # 输出: 3.14
normalize=True
参数将结果转换为相对频率
normalize=True参数是value_counts()方法的一个选项,用于指定是否将结果规范化为相对频率而不是绝对计数。当设置为True时,结果中的每个值的计数将除以总数以计算相对频率,即每个值在数据中出现的比例。这对于比较不同类别或值在数据中的相对重要性或分布情况非常有用。
pokemon.head()
# 统计Series中每个value出现的次数
pokemon.value_counts()
# 该方法返回一个新的Series对象
# 新Series的index labels:原Series的value
# 新Series的value:出现的次数
len(pokemon.value_counts())
pokemon.nunique()
# value_counts()方法默认按照计数从大到小排列
# 即默认情况下,参数 ascending=False
pokemon.value_counts(ascending=True)
# 计算每个index label的占比
pokemon.value_counts(normalize = True).head()
# 转换成百分比。给每个值乘以100
pokemon.value_counts(normalize=True).head() * 100
# 控制小数点后的位数
# 保留小数点后2位(四舍五入小数点后的第三位)
# round()方法
(pokemon.value_counts(normalize=True).head() * 100).round(2)
google.value_counts().head()
google.max()
google.min()
# 将股票价格范围划分为多个区间
# [200, 1400], step=200
buckets = [0, 200, 400, 600, 800, 1000, 1200, 1400]
google.value_counts(bins=buckets)
# 上面的结果是按value降序排序(默认)的
# 现在按照index label(区间顺序)进行排序
google.value_counts(bins=buckets).sort_index()
google.value_counts(bins = buckets,sort = False)
# -0.001?
# pandas 在左右方向会自动扩展给定区间,最多0.1%
google.value_counts(bins = 10, sort = False)
battles.head()
# 查看哪个地方的战争最多
battles.value_counts()
# value_counts()默认不统计value为NaN的数据
# 在value_counts()中统计value为NaN的数据
battles.value_counts(dropna = False)
# 查询哪个时间战争最多
# 对Series的index label使用value_count()
battles.index
battles.index.value_counts()5.apply()函数
使用apply()函数处理Series的每个value。
是 Pandas 中用于对 Series 或 DataFrame 中的数据执行自定义函数操作的方法。它可以将一个函数应用到 Series 的每个元素上,或者对 DataFrame 的每一行或每一列执行相同的操作。
import pandas as pd # 创建一个 Series s = pd.Series([1, 4, 9, 16, 25]) # 定义一个函数,用于计算平方根 def square_root(x): return x ** 0.5 # 使用 apply() 函数将函数应用到 Series 的每个元素上 result = s.apply(square_root) print(result)输出:
square_root()函数被定义用于计算一个数的平方根,然后通过apply()函数将这个函数应用到 Series 的每个元素上,得到了一个新的 Series 包含了每个数的平方根。

funcs = [len, max, min]
for current_func in funcs:
print(current_func(google))
# google.apply(func=round)对 google 的 Series 对象中的每个元素应用 round() 函数,即将每个元素四舍五入为最接近的整数。
google.apply(func=round)
def single_or_multi(pokemon_type):
if '/' in pokemon_type:
return 'Multi'
return 'Single'
pokemon.head()
# 将多个数据替换为Multi,单个数据替换为Single
pokemon.apply(single_or_multi)
# 统计单个数据和多个数据的数量
pokemon.apply(single_or_multi).value_counts()6.练习
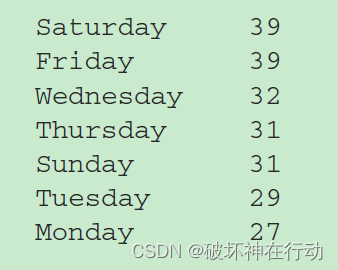
战争期间,一周中哪一天发生的战斗最多
day_of_week函数
day_of_week函数内部使用了strftime('%A')方法,这是 Python 中处理日期时间对象的方法之一,用于将日期时间格式化为指定的字符串表示。
'%A'是一个日期时间格式化指令,代表将日期时间转换为完整的星期几名称,比如 Monday、Tuesday 等。
days_of_war自定义函数
filepath_or_buffer='revolutionary_war.csv': 这是指定要读取的 CSV 文件的文件路径或缓冲区。在这个例子中,文件名为 'revolutionary_war.csv',它应该位于当前工作目录或者指定的路径中。usecols=['Start Date']: 这是一个可选参数,用于指定要读取的列。在这里,只读取了名为 'Start Date' 的列。parse_dates=['Start Date']: 这是另一个可选参数,用于将指定的列解析为日期时间格式。在这里,'Start Date' 列被解析为日期时间格式。.squeeze(1): 这是一个 Series 对象的方法,用于将 DataFrame 对象压缩成 Series 对象。参数1表示如果 DataFrame 只有一列,则返回 Series 对象。
import datetime as dt
def day_of_week(day):
return day.strftime('%A')
days_of_war = pd.read_csv(filepath_or_buffer='revolutionary_war.csv',
usecols=['Start Date'],
parse_dates=['Start Date'],
).squeeze(1)
print(type(days_of_war))
print()
days_of_war
#dropna() 方法会删除 Series 中的任何包含 NaN(缺失值)的行,然后 apply(day_of_week) 会对剩余的每个非空元素应用自定义函数 day_of_week。这个操作将把日期转换为相应的星期几,将结果存储在名为 days 的新 Series 中。
days = days_of_war.dropna().apply(day_of_week)
days
days.value_counts()
练习4
DataFrame
可以将 DataFrame 想象成 Python 环境中的一个强大的电子表格。它是一个二维数据结构,本质上是一个表格,数据以行和列的形式组织。每列可以容纳不同的数据类型,这使得 DataFrame 在处理各种数据集时非常灵活。
关键特性和优势:
结构化数据组织: DataFrame 提供了一种清晰直观的方式来组织数据,类似于电子表格,具有标记的行和列。这种结构简化了数据访问、操作和分析。
异构数据: 与要求统一数据类型的数组不同,DataFrame 允许每列容纳不同的数据类型(例如,整数、浮点数、字符串),使其适用于各种数据集。
基于标签的索引: DataFrame 提供灵活的索引方法。您可以使用标签(列名、行索引)引用行和列,从而使数据选择和操作更加直观。
数据操作的强大工具: Pandas 提供了大量用于数据操作的函数。您可以轻松执行以下任务:
- 根据条件过滤行
- 添加或删除列
- 对数据进行排序
- 处理缺失值
- 合并和连接 DataFrame
- 聚合数据(例如,计算总和、平均值等)
- 以及更多
与其他库集成: Pandas 与 NumPy 和 SciPy 等其他科学 Python 库无缝集成,增强了其数值计算和科学分析的能力。
1.创建 DataFrame
在 Pandas 中创建 DataFrame 有多种方法:
- 从字典创建:
import pandas as pd
data = {'姓名': ['Alice', 'Bob', 'Charlie'], '年龄': [25, 30, 22]}
df = pd.DataFrame(data)
print(df)
- 从列表的列表创建:
data = [['Alice', 25], ['Bob', 30], ['Charlie', 22]]
df = pd.DataFrame(data, columns=['姓名', '年龄'])
print(df)
- 从 NumPy 数组创建:
import numpy as np
data = np.array([['Alice', 25], ['Bob', 30], ['Charlie', 22]])
df = pd.DataFrame(data, columns=['姓名', '年龄'])
print(df)
- 从 CSV 文件创建:
df = pd.read_csv("data.csv")
print(df)2.使用 DataFrame
- 访问数据:
# 按名称访问列
age_column = df['年龄']
# 访问多列
name_and_age = df[['姓名', '年龄']]
# 按索引访问行
first_row = df.iloc[0]
# 访问特定元素
element = df.loc[0, '姓名']
- 数据操作:
# 添加新列
df['城市'] = ['New York', 'Paris', 'London']
# 按年龄排序
df_sorted = df.sort_values(by='年龄')
# 根据条件过滤行
filtered_df = df[df['年龄'] > 25]
# 计算平均年龄
mean_age = df['年龄'].mean()dtypes
返回一个 Series,其中包含了 DataFrame 中每一列的数据类型信息。这些数据类型可以是整数、浮点数、字符串、日期时间等。这个属性对于了解数据集的结构以及进行数据预处理非常有用,因为你可以根据列的数据类型进行相应的处理和分析。
sample()
从 DataFrame 中随机抽取指定数量或百分比的样本。
nba.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)其中参数的含义如下:
n:要抽取的样本数量。frac:要抽取的样本数量的比例(0到1之间的值),与n二选一。replace:是否允许重复抽样,如果为 True,则允许同一样本被抽取多次,如果为 False,则不允许。weights:用于抽样时的权重,可以为每个样本设置一个权重。random_state:随机数生成器的种子,用于可重复的随机抽样。axis:指定抽样的轴,0 表示按行抽样,1 表示按列抽样,默认为 0。# 从 nba DataFrame 中随机抽取 5 条样本 nba.sample(n=5) # 从 nba DataFrame 中按照 30% 的比例抽取样本 nba.sample(frac=0.3) # 从 nba DataFrame 中按照指定权重抽取样本 nba.sample(weights=[0.1, 0.2, 0.3, 0.4])
3.常用操作
-
查看基本信息:
.head()查看前几行数据。.tail()查看后几行数据。.info()查看数据类型、非空值数量等信息。.describe()统计描述性信息(如平均值、标准差、最小值、最大值等)。
-
选择与过滤数据:
- 通过列名选择列:
df['column_name'] - 通过条件选择行:
df[df['Age'] > 30] - 切片操作:
df[start:end]或选择特定索引df.loc[index]/df.iloc[index]
- 通过列名选择列:
-
修改与添加数据:
- 添加新列:
df['NewColumn'] = values - 修改列的值:
df['column_name'] = df['column_name'].apply(func) - 插入列:
df.insert(loc, column_name, values)
- 添加新列:
-
删除数据:
- 删除列:
del df['column_name']或df.drop(columns=['column_name']) - 删除行:
df.drop(index, axis=0)或根据条件过滤df = df[df['Age'] != 30]
- 删除列:
-
数据排序:
- 按列排序:
df.sort_values(by='column_name', ascending=True/False)
- 按列排序:
-
合并与连接数据:
- 使用
.concat()合并DataFrame。 - 使用
.merge()按键(列)合并DataFrame,类似于SQL的JOIN操作。
- 使用
-
分组与聚合:
df.groupby('Name').Age.mean().groupby()进行分组,然后可以应用聚合函数,如求和、平均等。
-
数据透视表:
- 使用
.pivot_table()创建数据透视表,非常适合做复杂的数据汇总。
- 使用
-
缺失值处理:
- 查找缺失值:
df.isnull() - 填充缺失值:
df.fillna(value)或删除含有缺失值的行/列:df.dropna()
- 查找缺失值:
-
字符串操作(对于包含字符串的列):
df['Name'].str.upper()- 使用
.str属性进行字符串操作,如截取、查找、替换等。
- 使用
-
日期时间操作:
- 将列转换为日期时间格式:
pd.to_datetime(df['date_column']) - 提取日期时间的部分,如年、月、日。
- 将列转换为日期时间格式:
import pandas as pd
import numpy as np
# dict创建DataFrame
city_data = {
'City':['New York City', 'Paris', 'Barcelone', 'Rome'],
'Country':['United States', 'France', 'Spain', 'Italy'],
'Population':[8600000, 2141000, 5515000, 2873000]
}
cities = pd.DataFrame(city_data)
cities
# index label 与 column index交换位置
cities.transpose()
cities.T
# 用ndarray创建DataFrame
random_data = np.random.randint(1,101,(3,5))
print(type(random_data))
random_data
pd.DataFrame(data = random_data)
# 设置 row label
row_labels = ['Morning', 'Afternoon', 'Evening']
temperatures = pd.DataFrame(data = random_data,index = row_labels)
temperatures
# 设置column label
column_labels = ('Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday')
pd.DataFrame(data = random_data,index = row_labels,columns = column_labels)
# row label 和 column label 都分别可以包含重复的值
# 但是尽量不要出现重复值
row_labels = ["Morning", "Afternoon", "Morning"]
column_labels = [
"Monday",
"Tuesday",
"Wednesday",
"Tuesday",
"Friday"
]
pd.DataFrame(
data = random_data,
index = row_labels,
columns = column_labels,
)
pd.read_csv('nba.csv')
# pandas导入数据时,日期默认为字符串
# 需要将日期进行设置
nba = pd.read_csv(filepath_or_buffer = 'nba.csv',parse_dates = ['Birthday'])
nba
nba.dtypes
type(nba.dtypes)
nba.dtypes.value_counts()
nba.index
nba.columns
# 获取对象维度,对于DataFrame,ndim通常返回2,因为DataFrame本质上是一个二维结构,它由行和列组成。如果操作的是Series(DataFrame的一列),则ndim会返回1,表示一维数据结构。
nba.ndim
nba.shape
# 查询有多少个数据(包括缺失值NaN的个数)
nba.size
# 如果想在统计数据个数时,排除缺失值,使用count()统计每列中非缺失值的个数
nba.count()
nba.count().sum()
# 当前这个nba数据集中没有缺失值
# 对比 size属性 和 count()
# 创建一个带有缺失值的DataFrame
data = {
'A':[1,np.nan],
'B':[2,3]
}
df = pd.DataFrame(data = data)
df
df.size
df.count()
df.count().sum()
nba.head(2)
nba.tail(3)
# 随机抽取3条数据
nba.sample(3)
# 查看每一列有多少个不同的值
nba.nunique()
nba.max()
nba.min()
# 查询工资最高的4个人
nba.nlargest(4,columns = 'Salary')
# 查询年龄最大的3个人
nba.nsmallest(n=3, columns='Birthday')
# 计算所有人的工资之和
nba['Salary'].sum()
# 计算DataFrame中'Salary'列所有非缺失值的平均值。
nba['Salary'].mean()
# 计算中位数。
nba['Salary'].median()
# 出现次数最多的值
nba['Salary'].mode()
# 计算standard deviation(标准差)
nba['Salary'].std()4.选择指定的行和列
选择一列:nba.Salary
选择多列:nba[ ['Salary' , 'Birthday'] ]
根据数据类型选择列:nba.select_dtypes(include = 'object')或nba.select_dtypes(exclude = 'object')
5.切片操作
nba.sort_index().loc['Otto Porter':'Patrick Beverley']
通过标签(在这里是球员的名字)来选择索引范围内的行。
从名字为'Otto Porter'的行开始,到名字为'Patrick Beverley'的行结束(包括这两行),展示这部分球员的数据。
1. 基于标签的切片 (loc)
- 语法:
df.loc[行标签, 列标签] - 说明:
loc方法用于通过行和列的标签来选择数据。它考虑到了标签的范围,所以当指定起始和结束标签时,包括起始标签,但不包括结束标签,类似于Python的切片操作。
# 假设df是一个DataFrame
df.loc['row_label_start':'row_label_end', 'column_label1':'column_label2']
2. 基于位置的切片 (iloc)
- 语法:
df.iloc[行索引, 列索引] - 说明:与
loc不同,iloc是基于行和列的整数索引来选择数据的。它同样遵循Python的切片规则,即包括起始索引,不包括结束索引。
# 选取第0行到第4行,第1列到第3列的数据
df.iloc[0:5, 1:4]
特殊用法
- 单一标签切片:可以直接用单个标签或索引来选取单行或单列。
df.loc['single_row_label'] # 选取单行
df.iloc[0] # 选取第一行,按位置
df['column_label'] # 选取单列,基于列名
- 条件筛选:虽然不是传统意义上的切片,但通过条件表达式可以实现数据的选择,常与布尔索引结合使用。
df[df['Age'] > 30] # 选取Age列大于30的所有行
- 步长切片:可以像常规Python序列那样使用步长,例如
df.iloc[::2, ::3]选取每第二行和每第三列的元素。